 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Measuring Competency of Machine Learning Systems and Enforcing Reliability
Dec 02, 2022
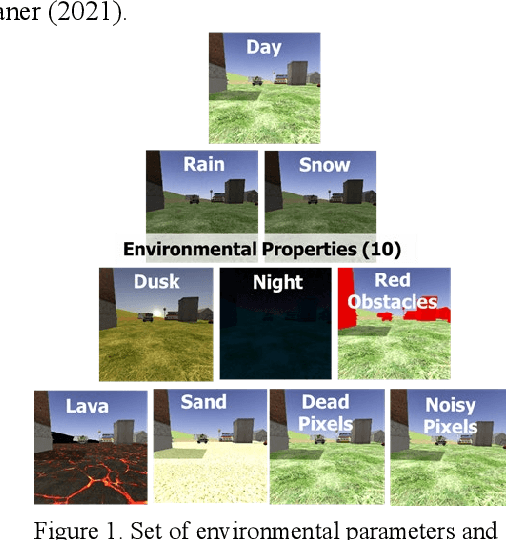
We explore the impact of environmental conditions on the competency of machine learning agents and how real-time competency assessments improve the reliability of ML agents. We learn a representation of conditions which impact the strategies and performance of the ML agent enabling determination of actions the agent can make to maintain operator expectations in the case of a convolutional neural network that leverages visual imagery to aid in the obstacle avoidance task of a simulated self-driving vehicle.
A Probabilistic Autoencoder for Type Ia Supernovae Spectral Time Series
Jul 15, 2022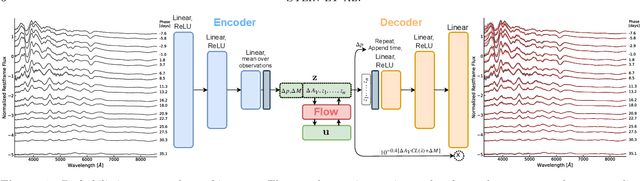
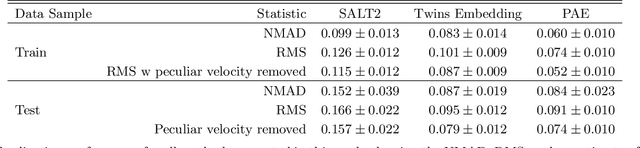
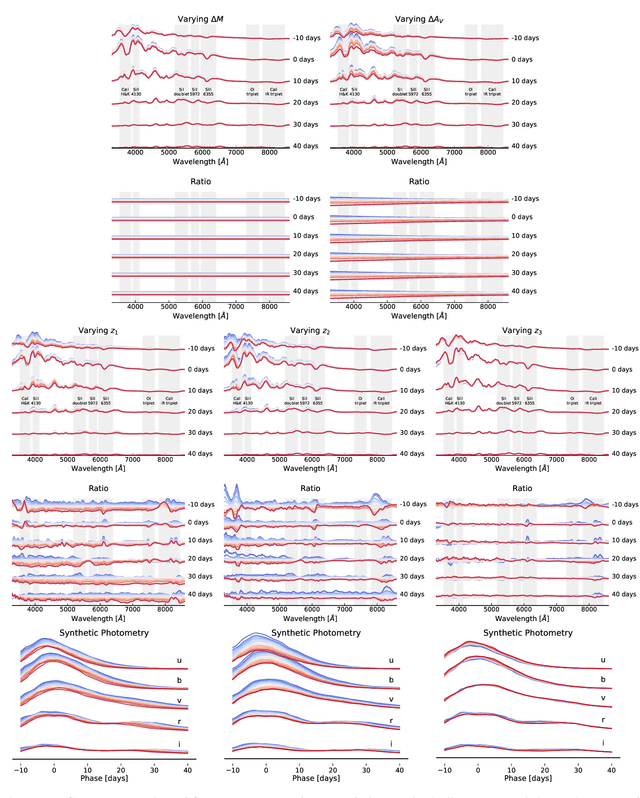
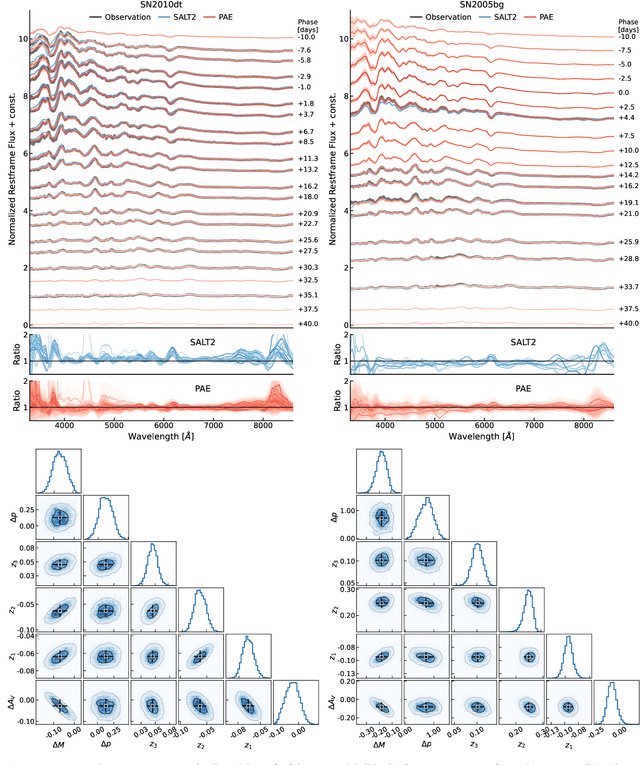
We construct a physically-parameterized probabilistic autoencoder (PAE) to learn the intrinsic diversity of type Ia supernovae (SNe Ia) from a sparse set of spectral time series. The PAE is a two-stage generative model, composed of an Auto-Encoder (AE) which is interpreted probabilistically after training using a Normalizing Flow (NF). We demonstrate that the PAE learns a low-dimensional latent space that captures the nonlinear range of features that exists within the population, and can accurately model the spectral evolution of SNe Ia across the full range of wavelength and observation times directly from the data. By introducing a correlation penalty term and multi-stage training setup alongside our physically-parameterized network we show that intrinsic and extrinsic modes of variability can be separated during training, removing the need for the additional models to perform magnitude standardization. We then use our PAE in a number of downstream tasks on SNe Ia for increasingly precise cosmological analyses, including automatic detection of SN outliers, the generation of samples consistent with the data distribution, and solving the inverse problem in the presence of noisy and incomplete data to constrain cosmological distance measurements. We find that the optimal number of intrinsic model parameters appears to be three, in line with previous studies, and show that we can standardize our test sample of SNe Ia with an RMS of $0.091 \pm 0.010$ mag, which corresponds to $0.074 \pm 0.010$ mag if peculiar velocity contributions are removed. Trained models and codes are released at \href{https://github.com/georgestein/suPAErnova}{github.com/georgestein/suPAErnova}
Elixir: A system to enhance data quality for multiple analytics on a video stream
Dec 08, 2022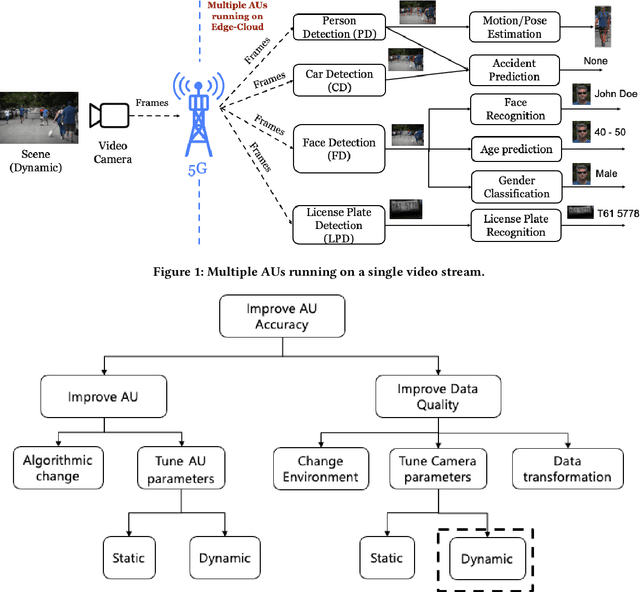
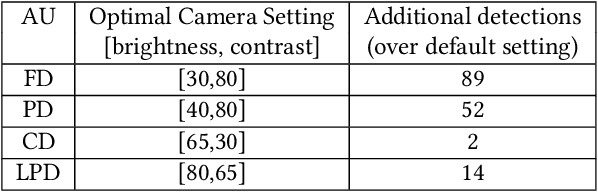
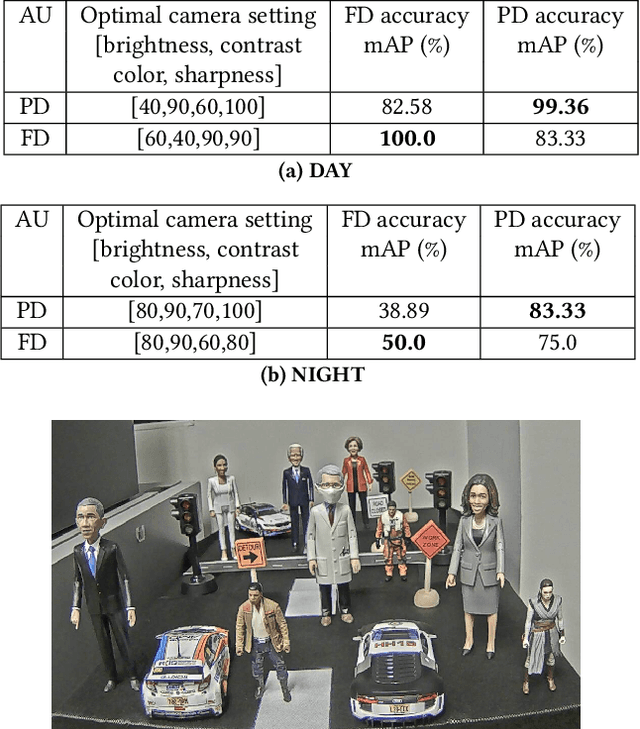

IoT sensors, especially video cameras, are ubiquitously deployed around the world to perform a variety of computer vision tasks in several verticals including retail, healthcare, safety and security, transportation, manufacturing, etc. To amortize their high deployment effort and cost, it is desirable to perform multiple video analytics tasks, which we refer to as Analytical Units (AUs), off the video feed coming out of every camera. In this paper, we first show that in a multi-AU setting, changing the camera setting has disproportionate impact on different AUs performance. In particular, the optimal setting for one AU may severely degrade the performance for another AU, and further the impact on different AUs varies as the environmental condition changes. We then present Elixir, a system to enhance the video stream quality for multiple analytics on a video stream. Elixir leverages Multi-Objective Reinforcement Learning (MORL), where the RL agent caters to the objectives from different AUs and adjusts the camera setting to simultaneously enhance the performance of all AUs. To define the multiple objectives in MORL, we develop new AU-specific quality estimator values for each individual AU. We evaluate Elixir through real-world experiments on a testbed with three cameras deployed next to each other (overlooking a large enterprise parking lot) running Elixir and two baseline approaches, respectively. Elixir correctly detects 7.1% (22,068) and 5.0% (15,731) more cars, 94% (551) and 72% (478) more faces, and 670.4% (4975) and 158.6% (3507) more persons than the default-setting and time-sharing approaches, respectively. It also detects 115 license plates, far more than the time-sharing approach (7) and the default setting (0).
Abnormal Signal Recognition with Time-Frequency Spectrogram: A Deep Learning Approach
May 30, 2022
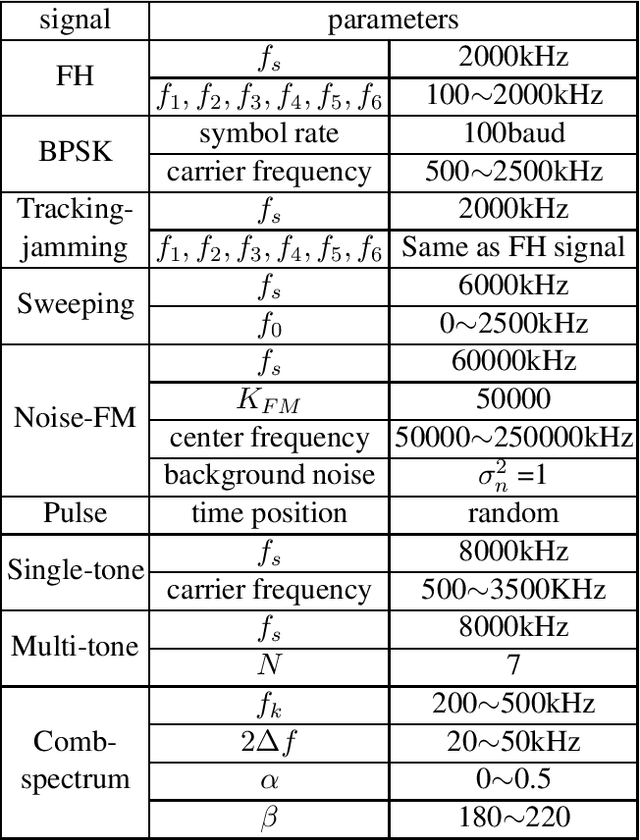


With the increasingly complex and changeable electromagnetic environment, wireless communication systems are facing jamming and abnormal signal injection, which significantly affects the normal operation of a communication system. In particular, the abnormal signals may emulate the normal signals, which makes it very challenging for abnormal signal recognition. In this paper, we propose a new abnormal signal recognition scheme, which combines time-frequency analysis with deep learning to effectively identify synthetic abnormal communication signals. Firstly, we emulate synthetic abnormal communication signals including seven jamming patterns. Then, we model an abnormal communication signals recognition system based on the communication protocol between the transmitter and the receiver. To improve the performance, we convert the original signal into the time-frequency spectrogram to develop an image classification algorithm. Simulation results demonstrate that the proposed method can effectively recognize the abnormal signals under various parameter configurations, even under low signal-to-noise ratio (SNR) and low jamming-to-signal ratio (JSR) conditions.
Deep Learning Framework for Real-time Fetal Brain Segmentation in MRI
May 02, 2022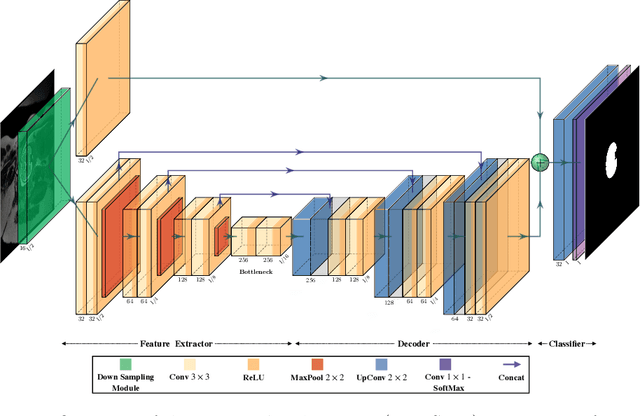
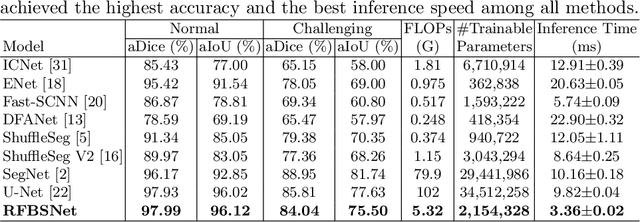
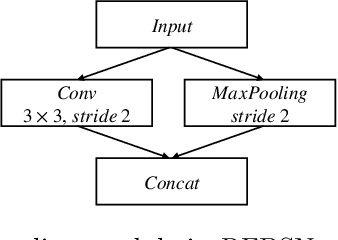
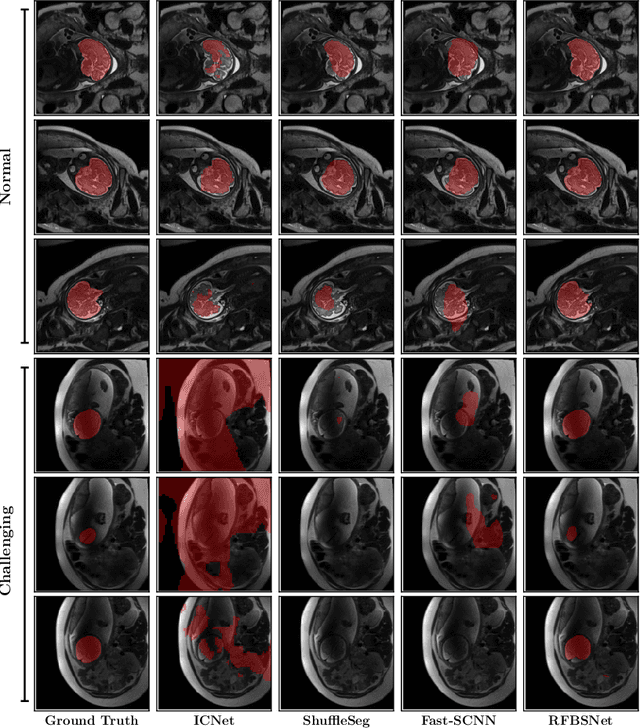
Fetal brain segmentation is an important first step for slice-level motion correction and slice-to-volume reconstruction in fetal MRI. Fast and accurate segmentation of the fetal brain on fetal MRI is required to achieve real-time fetal head pose estimation and motion tracking for slice re-acquisition and steering. To address this critical unmet need, in this work we analyzed the speed-accuracy performance of a variety of deep neural network models, and devised a symbolically small convolutional neural network that combines spatial details at high resolution with context features extracted at lower resolutions. We used multiple branches with skip connections to maintain high accuracy while devising a parallel combination of convolution and pooling operations as an input downsampling module to further reduce inference time. We trained our model as well as eight alternative, state-of-the-art networks with manually-labeled fetal brain MRI slices and tested on two sets of normal and challenging test cases. Experimental results show that our network achieved the highest accuracy and lowest inference time among all of the compared state-of-the-art real-time segmentation methods. We achieved average Dice scores of 97.99\% and 84.04\% on the normal and challenging test sets, respectively, with an inference time of 3.36 milliseconds per image on an NVIDIA GeForce RTX 2080 Ti. Code, data, and the trained models are available at https://github.com/bchimagine/real_time_fetal_brain_segmentation.
Learning Spatiotemporal Frequency-Transformer for Low-Quality Video Super-Resolution
Dec 27, 2022

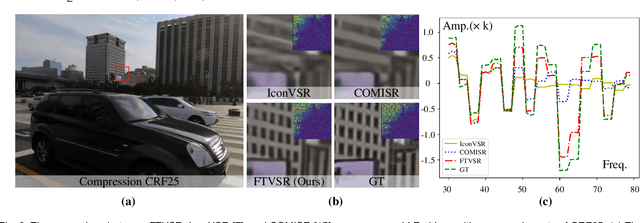
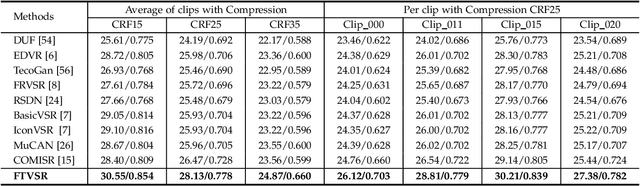
Video Super-Resolution (VSR) aims to restore high-resolution (HR) videos from low-resolution (LR) videos. Existing VSR techniques usually recover HR frames by extracting pertinent textures from nearby frames with known degradation processes. Despite significant progress, grand challenges are remained to effectively extract and transmit high-quality textures from high-degraded low-quality sequences, such as blur, additive noises, and compression artifacts. In this work, a novel Frequency-Transformer (FTVSR) is proposed for handling low-quality videos that carry out self-attention in a combined space-time-frequency domain. First, video frames are split into patches and each patch is transformed into spectral maps in which each channel represents a frequency band. It permits a fine-grained self-attention on each frequency band, so that real visual texture can be distinguished from artifacts. Second, a novel dual frequency attention (DFA) mechanism is proposed to capture the global frequency relations and local frequency relations, which can handle different complicated degradation processes in real-world scenarios. Third, we explore different self-attention schemes for video processing in the frequency domain and discover that a ``divided attention'' which conducts a joint space-frequency attention before applying temporal-frequency attention, leads to the best video enhancement quality. Extensive experiments on three widely-used VSR datasets show that FTVSR outperforms state-of-the-art methods on different low-quality videos with clear visual margins. Code and pre-trained models are available at https://github.com/researchmm/FTVSR.
Noise-aware Learning from Web-crawled Image-Text Data for Image Captioning
Dec 27, 2022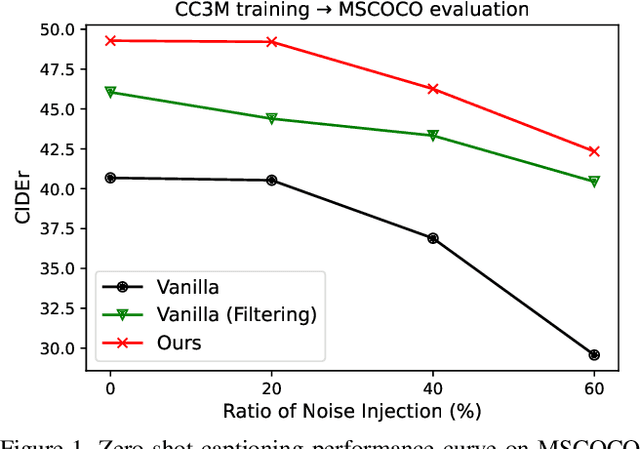
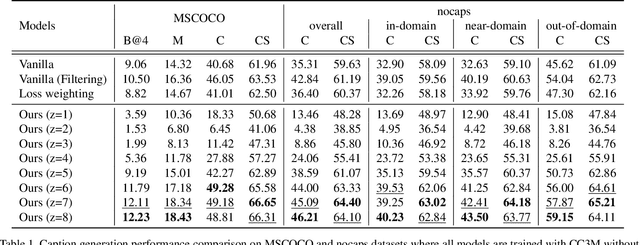

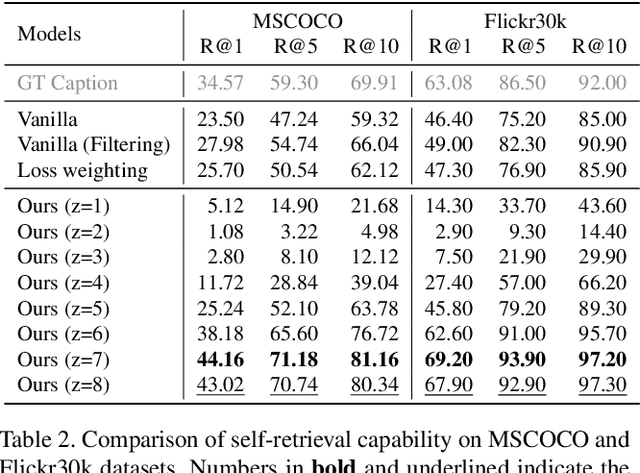
Image captioning is one of the straightforward tasks that can take advantage of large-scale web-crawled data which provides rich knowledge about the visual world for a captioning model. However, since web-crawled data contains image-text pairs that are aligned at different levels, the inherent noises (e.g., misaligned pairs) make it difficult to learn a precise captioning model. While the filtering strategy can effectively remove noisy data, however, it leads to a decrease in learnable knowledge and sometimes brings about a new problem of data deficiency. To take the best of both worlds, we propose a noise-aware learning framework, which learns rich knowledge from the whole web-crawled data while being less affected by the noises. This is achieved by the proposed quality controllable model, which is learned using alignment levels of the image-text pairs as an additional control signal during training. The alignment-conditioned training allows the model to generate high-quality captions of well-aligned by simply setting the control signal to desired alignment level at inference time. Through in-depth analysis, we show that our controllable captioning model is effective in handling noise. In addition, with two tasks of zero-shot captioning and text-to-image retrieval using generated captions (i.e., self-retrieval), we also demonstrate our model can produce high-quality captions in terms of descriptiveness and distinctiveness. Code is available at \url{https://github.com/kakaobrain/noc}.
Learning to Control under Time-Varying Environment
Jun 06, 2022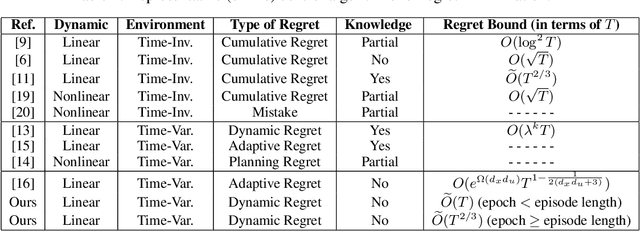
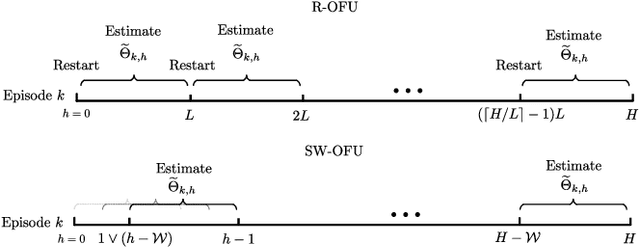
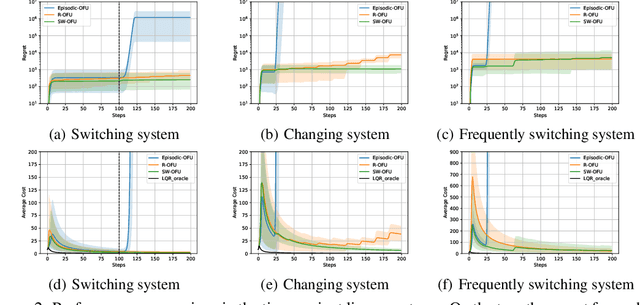
This paper investigates the problem of regret minimization in linear time-varying (LTV) dynamical systems. Due to the simultaneous presence of uncertainty and non-stationarity, designing online control algorithms for unknown LTV systems remains a challenging task. At a cost of NP-hard offline planning, prior works have introduced online convex optimization algorithms, although they suffer from nonparametric rate of regret. In this paper, we propose the first computationally tractable online algorithm with regret guarantees that avoids offline planning over the state linear feedback policies. Our algorithm is based on the optimism in the face of uncertainty (OFU) principle in which we optimistically select the best model in a high confidence region. Our algorithm is then more explorative when compared to previous approaches. To overcome non-stationarity, we propose either a restarting strategy (R-OFU) or a sliding window (SW-OFU) strategy. With proper configuration, our algorithm is attains sublinear regret $O(T^{2/3})$. These algorithms utilize data from the current phase for tracking variations on the system dynamics. We corroborate our theoretical findings with numerical experiments, which highlight the effectiveness of our methods. To the best of our knowledge, our study establishes the first model-based online algorithm with regret guarantees under LTV dynamical systems.
High Quality Audio Coding with MDCTNet
Dec 08, 2022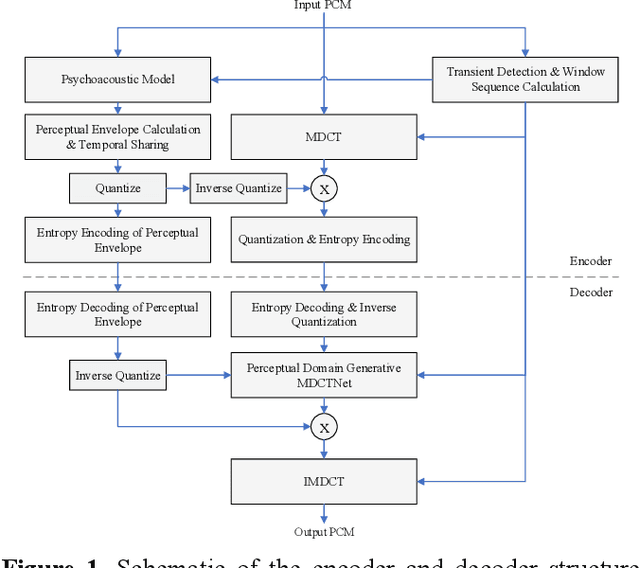
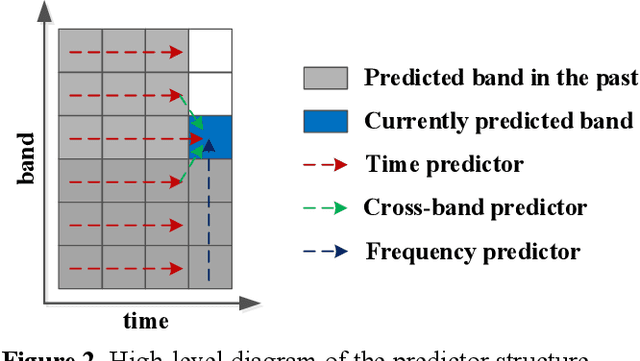
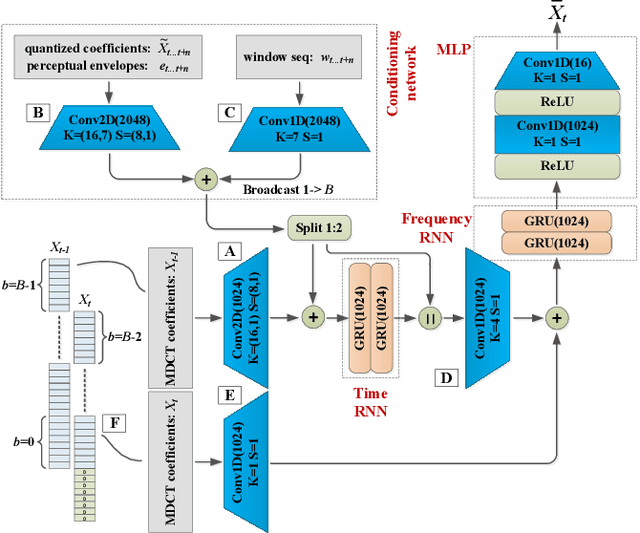
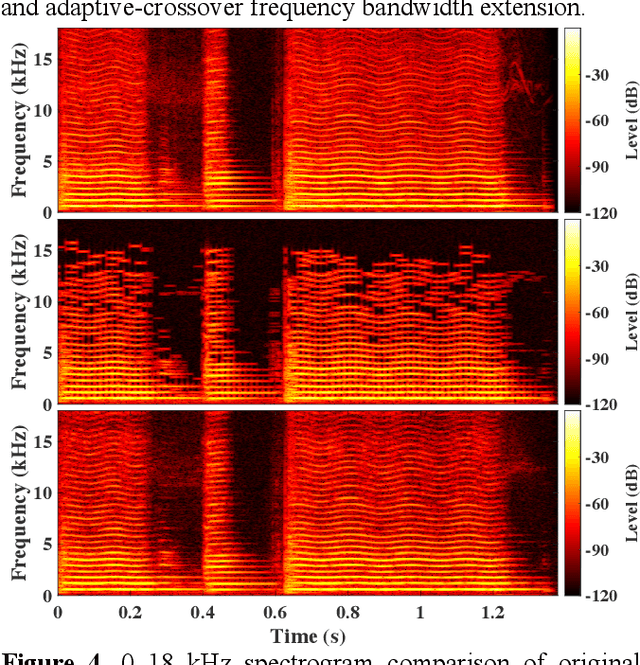
We propose a neural audio generative model, MDCTNet, operating in the perceptually weighted domain of an adaptive modified discrete cosine transform (MDCT). The architecture of the model captures correlations in both time and frequency directions with recurrent layers (RNNs). An audio coding system is obtained by training MDCTNet on a diverse set of fullband monophonic audio signals at 48 kHz sampling, conditioned by a perceptual audio encoder. In a subjective listening test with ten excerpts chosen to be balanced across content types, yet stressful for both codecs, the mean performance of the proposed system for 24 kb/s variable bitrate (VBR) is similar to that of Opus at twice the bitrate.
Automated Reachability Analysis of Neural Network-Controlled Systems via Adaptive Polytopes
Dec 14, 2022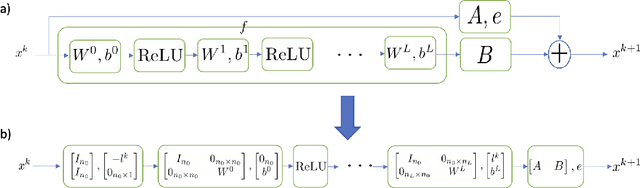
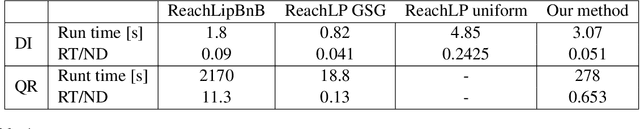
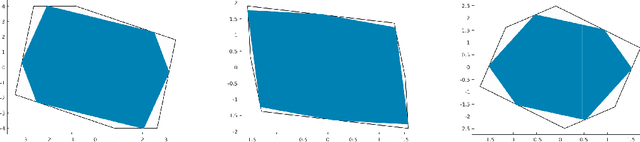

Over-approximating the reachable sets of dynamical systems is a fundamental problem in safety verification and robust control synthesis. The representation of these sets is a key factor that affects the computational complexity and the approximation error. In this paper, we develop a new approach for over-approximating the reachable sets of neural network dynamical systems using adaptive template polytopes. We use the singular value decomposition of linear layers along with the shape of the activation functions to adapt the geometry of the polytopes at each time step to the geometry of the true reachable sets. We then propose a branch-and-bound method to compute accurate over-approximations of the reachable sets by the inferred templates. We illustrate the utility of the proposed approach in the reachability analysis of linear systems driven by neural network controllers.