 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comprehensive Study on Machine Learning Methods to Increase the Prediction Accuracy of Classifiers and Reduce the Number of Medical Tests Required to Diagnose Alzheimer'S Disease
Dec 01, 2022
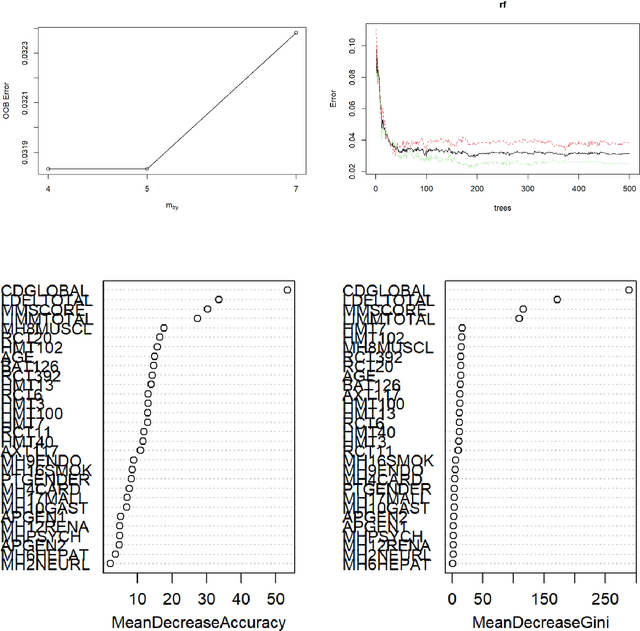
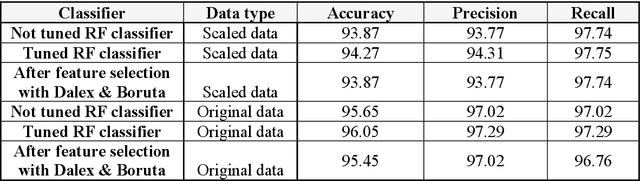
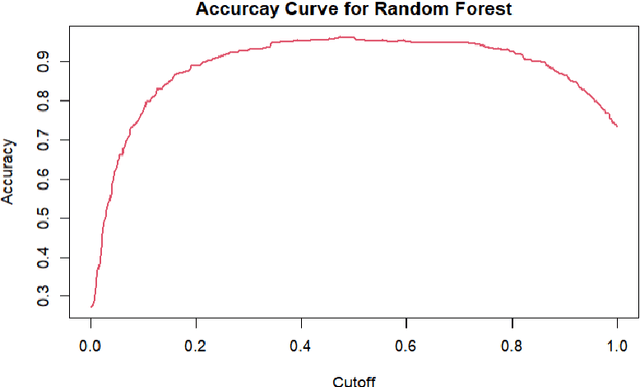
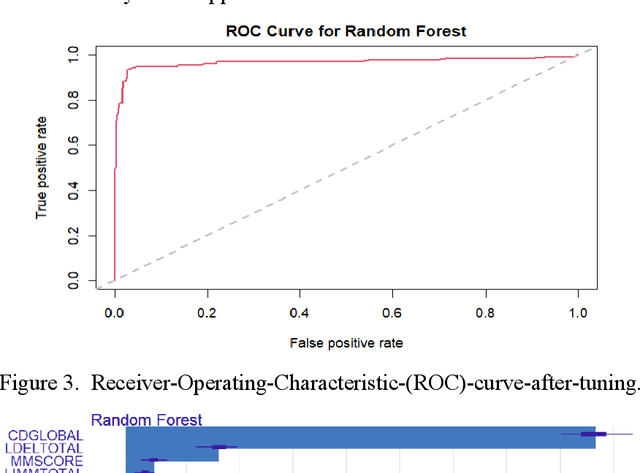
Alzheimer's patients gradually lose their ability to think, behave, and interact with others. Medical history, laboratory tests, daily activities, and personality changes can all be used to diagnose the disorder. A series of time-consuming and expensive tests are used to diagnose the illness. The most effective way to identify Alzheimer's disease is using a Random-forest classifier in this study, along with various other Machine Learning techniques. The main goal of this study is to fine-tune the classifier to detect illness with fewer tests while maintaining a reasonable disease discovery accuracy. We successfully identified the condition in almost 94% of cases using four of the thirty frequently utilized indicators.
Nearly Minimax Optimal Reinforcement Learning for Linear Markov Decision Processes
Dec 12, 2022
We study reinforcement learning (RL) with linear function approximation. For episodic time-inhomogeneous linear Markov decision processes (linear MDPs) whose transition dynamic can be parameterized as a linear function of a given feature mapping, we propose the first computationally efficient algorithm that achieves the nearly minimax optimal regret $\tilde O(d\sqrt{H^3K})$, where $d$ is the dimension of the feature mapping, $H$ is the planning horizon, and $K$ is the number of episodes. Our algorithm is based on a weighted linear regression scheme with a carefully designed weight, which depends on a new variance estimator that (1) directly estimates the variance of the \emph{optimal} value function, (2) monotonically decreases with respect to the number of episodes to ensure a better estimation accuracy, and (3) uses a rare-switching policy to update the value function estimator to control the complexity of the estimated value function class. Our work provides a complete answer to optimal RL with linear MDPs, and the developed algorithm and theoretical tools may be of independent interest.
PathFusion: Path-consistent Lidar-Camera Deep Feature Fusion
Dec 12, 2022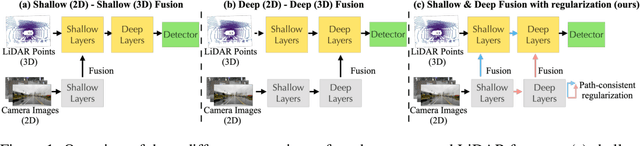
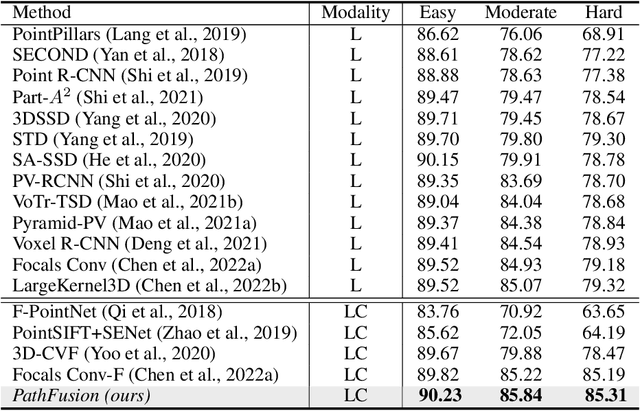
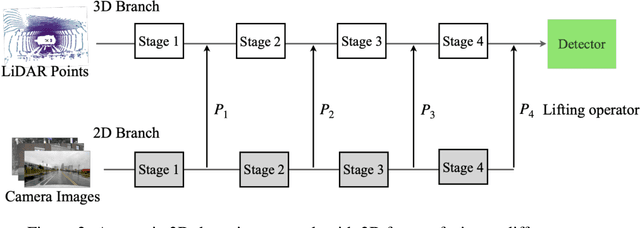

Fusing camera with LiDAR is a promising technique to improve the accuracy of 3D detection due to the complementary physical properties. While most existing methods focus on fusing camera features directly with raw LiDAR point clouds or shallow 3D features, it is observed that direct deep 3D feature fusion achieves inferior accuracy due to feature misalignment. The misalignment that originates from the feature aggregation across large receptive fields becomes increasingly severe for deep network stages. In this paper, we propose PathFusion to enable path-consistent LiDAR-camera deep feature fusion. PathFusion introduces a path consistency loss between shallow and deep features, which encourages the 2D backbone and its fusion path to transform 2D features in a way that is semantically aligned with the transform of the 3D backbone. We apply PathFusion to the prior-art fusion baseline, Focals Conv, and observe more than 1.2\% mAP improvements on the nuScenes test split consistently with and without testing-time augmentations. Moreover, PathFusion also improves KITTI AP3D (R11) by more than 0.6% on moderate level.
Learning on non-stationary data with re-weighting
Dec 12, 2022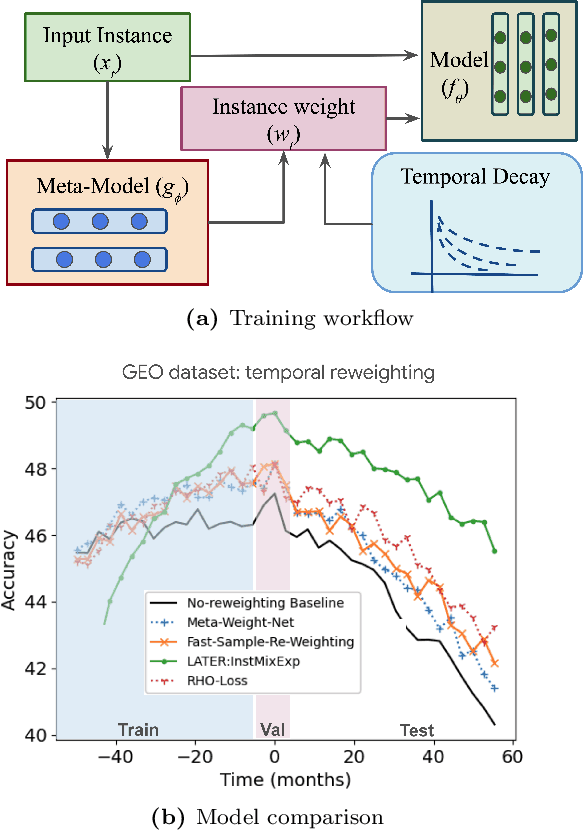
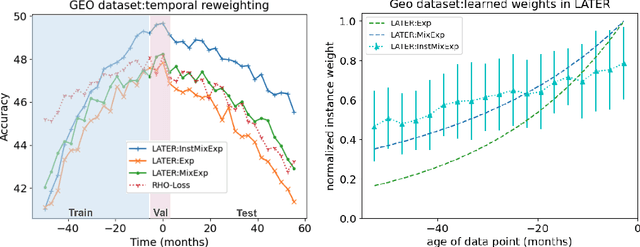
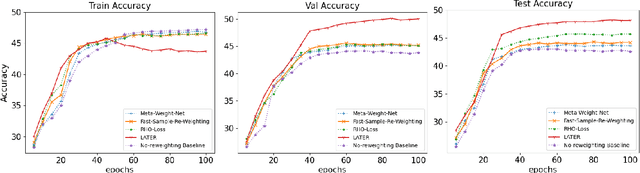
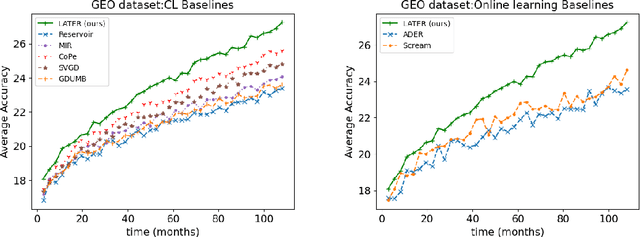
Many real-world learning scenarios face the challenge of slow concept drift, where data distributions change gradually over time. In this setting, we pose the problem of learning temporally sensitive importance weights for training data, in order to optimize predictive accuracy. We propose a class of temporal reweighting functions that can capture multiple timescales of change in the data, as well as instance-specific characteristics. We formulate a bi-level optimization criterion, and an associated meta-learning algorithm, by which these weights can be learned. In particular, our formulation trains an auxiliary network to output weights as a function of training instances, thereby compactly representing the instance weights. We validate our temporal reweighting scheme on a large real-world dataset of 39M images spread over a 9 year period. Our extensive experiments demonstrate the necessity of instance-based temporal reweighting in the dataset, and achieve significant improvements to classical batch-learning approaches. Further, our proposal easily generalizes to a streaming setting and shows significant gains compared to recent continual learning methods.
IDANI: Inference-time Domain Adaptation via Neuron-level Interventions
Jun 01, 2022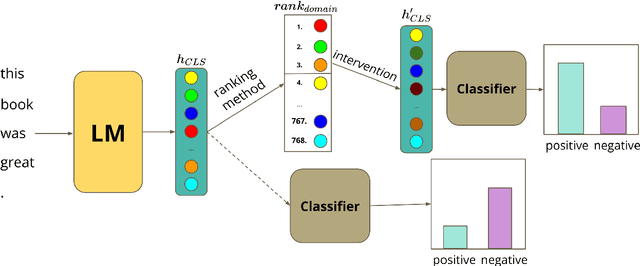
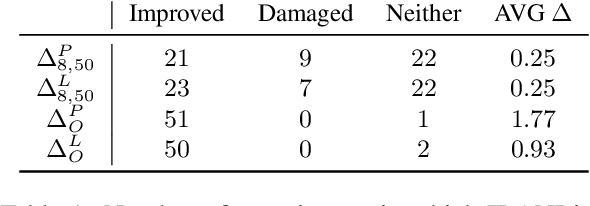
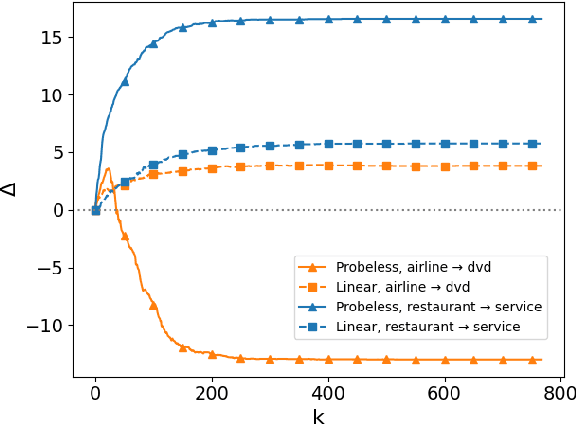

Large pre-trained models are usually fine-tuned on downstream task data, and tested on unseen data. When the train and test data come from different domains, the model is likely to struggle, as it is not adapted to the test domain. We propose a new approach for domain adaptation (DA), using neuron-level interventions: We modify the representation of each test example in specific neurons, resulting in a counterfactual example from the source domain, which the model is more familiar with. The modified example is then fed back into the model. While most other DA methods are applied during training time, ours is applied during inference only, making it more efficient and applicable. Our experiments show that our method improves performance on unseen domains.
Run Time Analysis for Random Local Search on Generalized Majority Functions
Apr 27, 2022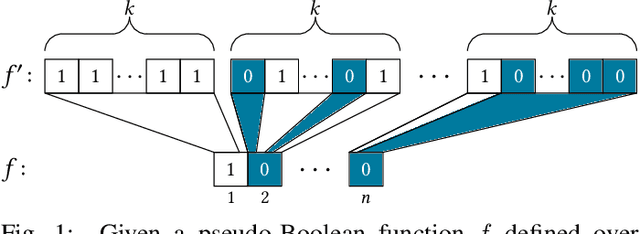
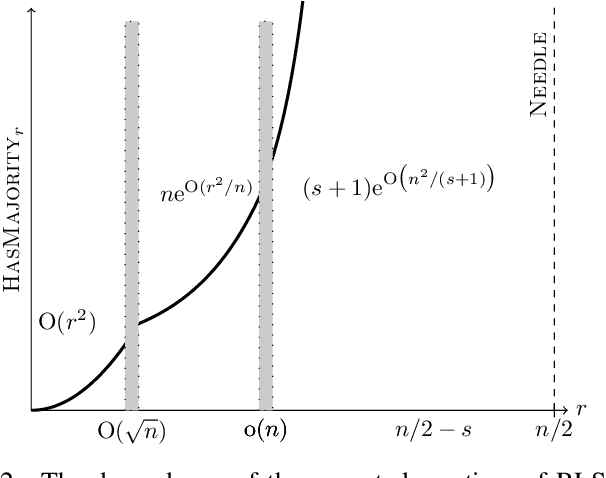
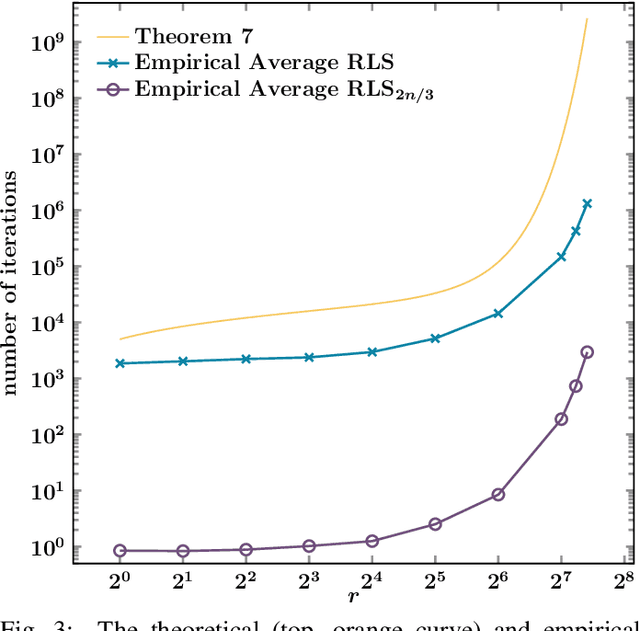
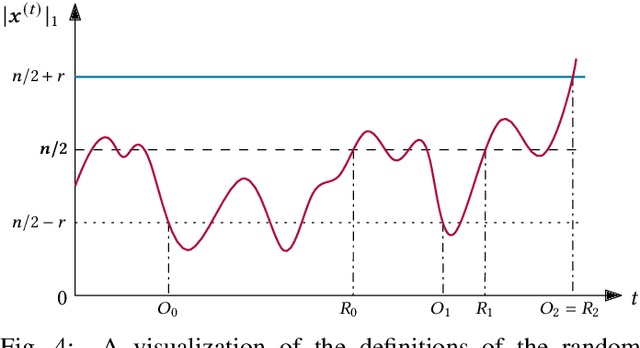
Run time analysis of evolutionary algorithms recently makes significant progress in linking algorithm performance to algorithm parameters. However, settings that study the impact of problem parameters are rare. The recently proposed W-model provides a good framework for such analyses, generating pseudo-Boolean optimization problems with tunable properties. We initiate theoretical research of the W-model by studying how one of its properties -- neutrality -- influences the run time of random local search. Neutrality creates plateaus in the search space by first performing a majority vote for subsets of the solution candidate and then evaluating the smaller-dimensional string via a low-level fitness function. We prove upper bounds for the expected run time of random local search on this MAJORITY problem for its entire parameter spectrum. To this end, we provide a theorem, applicable to many optimization algorithms, that links the run time of MAJORITY with its symmetric version HASMAJORITY, where a sufficient majority is needed to optimize the subset. We also introduce a generalized version of classic drift theorems as well as a generalized version of Wald's equation, both of which we believe to be of independent interest.
Investigation of reinforcement learning for shape optimization of profile extrusion dies
Dec 23, 2022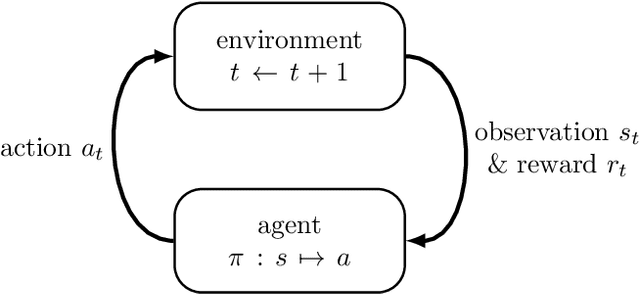

Profile extrusion is a continuous production process for manufacturing plastic profiles from molten polymer. Especially interesting is the design of the die, through which the melt is pressed to attain the desired shape. However, due to an inhomogeneous velocity distribution at the die exit or residual stresses inside the extrudate, the final shape of the manufactured part often deviates from the desired one. To avoid these deviations, the shape of the die can be computationally optimized, which has already been investigated in the literature using classical optimization approaches. A new approach in the field of shape optimization is the utilization of Reinforcement Learning (RL) as a learning-based optimization algorithm. RL is based on trial-and-error interactions of an agent with an environment. For each action, the agent is rewarded and informed about the subsequent state of the environment. While not necessarily superior to classical, e.g., gradient-based or evolutionary, optimization algorithms for one single problem, RL techniques are expected to perform especially well when similar optimization tasks are repeated since the agent learns a more general strategy for generating optimal shapes instead of concentrating on just one single problem. In this work, we investigate this approach by applying it to two 2D test cases. The flow-channel geometry can be modified by the RL agent using so-called Free-Form Deformation, a method where the computational mesh is embedded into a transformation spline, which is then manipulated based on the control-point positions. In particular, we investigate the impact of utilizing different agents on the training progress and the potential of wall time saving by utilizing multiple environments during training.
Lifted Inference with Linear Order Axiom
Nov 02, 2022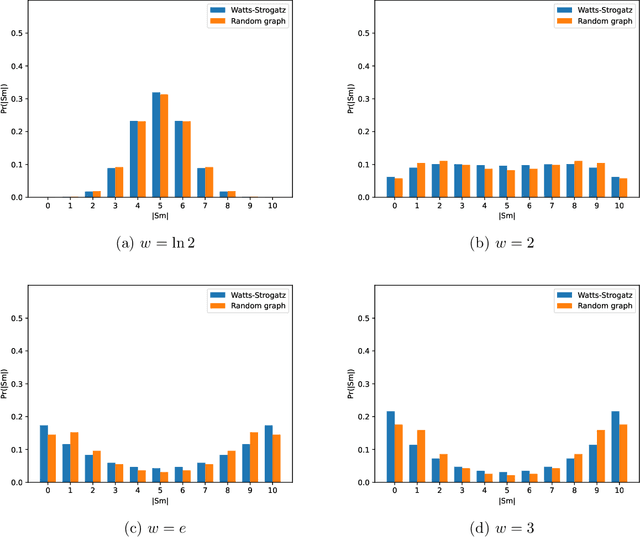
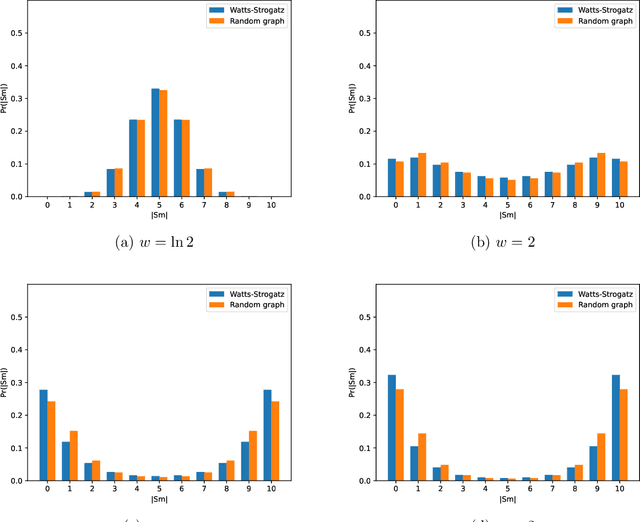
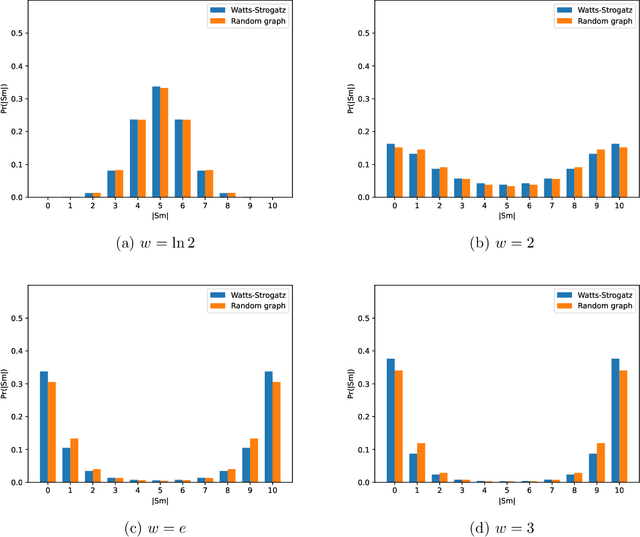
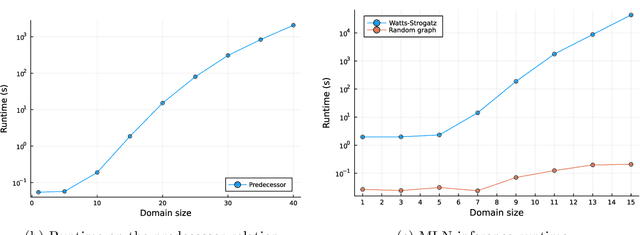
We consider the task of weighted first-order model counting (WFOMC) used for probabilistic inference in the area of statistical relational learning. Given a formula $\phi$, domain size $n$ and a pair of weight functions, what is the weighted sum of all models of $\phi$ over a domain of size $n$? It was shown that computing WFOMC of any logical sentence with at most two logical variables can be done in time polynomial in $n$. However, it was also shown that the task is $\texttt{#}P_1$-complete once we add the third variable, which inspired the search for extensions of the two-variable fragment that would still permit a running time polynomial in $n$. One of such extension is the two-variable fragment with counting quantifiers. In this paper, we prove that adding a linear order axiom (which forces one of the predicates in $\phi$ to introduce a linear ordering of the domain elements in each model of $\phi$) on top of the counting quantifiers still permits a computation time polynomial in the domain size. We present a new dynamic programming-based algorithm which can compute WFOMC with linear order in time polynomial in $n$, thus proving our primary claim.
Masked Wavelet Representation for Compact Neural Radiance Fields
Dec 18, 2022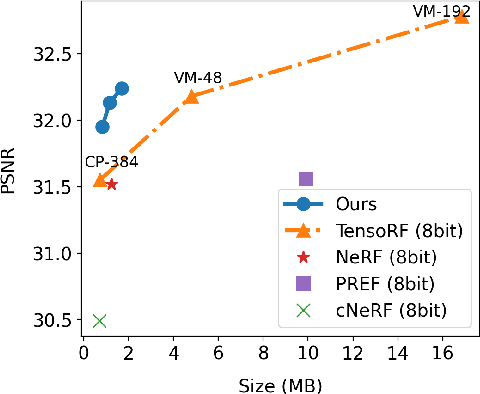
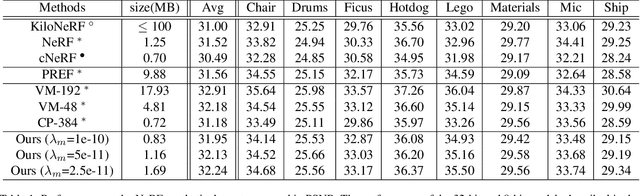
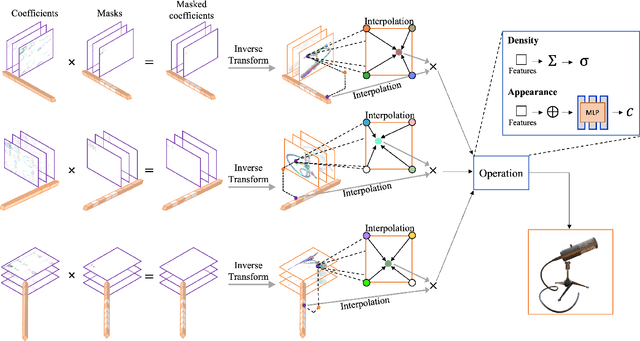
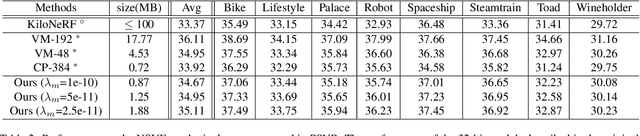
Neural radiance fields (NeRF) have demonstrated the potential of coordinate-based neural representation (neural fields or implicit neural representation) in neural rendering. However, using a multi-layer perceptron (MLP) to represent a 3D scene or object requires enormous computational resources and time. There have been recent studies on how to reduce these computational inefficiencies by using additional data structures, such as grids or trees. Despite the promising performance, the explicit data structure necessitates a substantial amount of memory. In this work, we present a method to reduce the size without compromising the advantages of having additional data structures. In detail, we propose using the wavelet transform on grid-based neural fields. Grid-based neural fields are for fast convergence, and the wavelet transform, whose efficiency has been demonstrated in high-performance standard codecs, is to improve the parameter efficiency of grids. Furthermore, in order to achieve a higher sparsity of grid coefficients while maintaining reconstruction quality, we present a novel trainable masking approach. Experimental results demonstrate that non-spatial grid coefficients, such as wavelet coefficients, are capable of attaining a higher level of sparsity than spatial grid coefficients, resulting in a more compact representation. With our proposed mask and compression pipeline, we achieved state-of-the-art performance within a memory budget of 2 MB. Our code is available at https://github.com/daniel03c1/masked_wavelet_nerf.
Connected Cruise and Traffic Control for Pairs of Connected Automated Vehicles
Dec 04, 2022
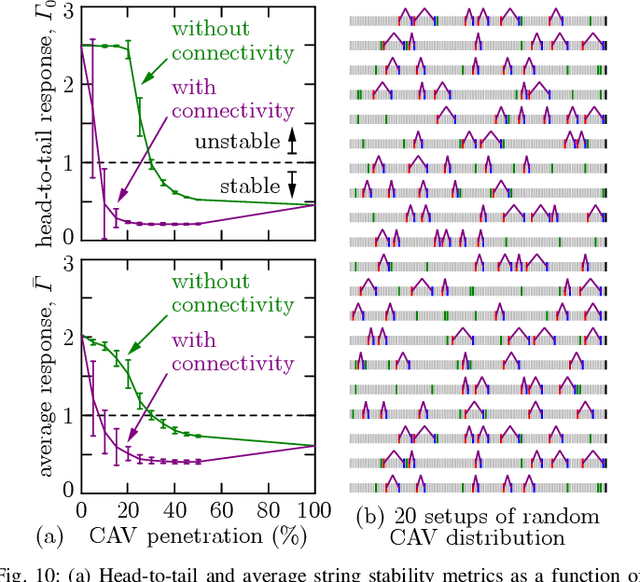
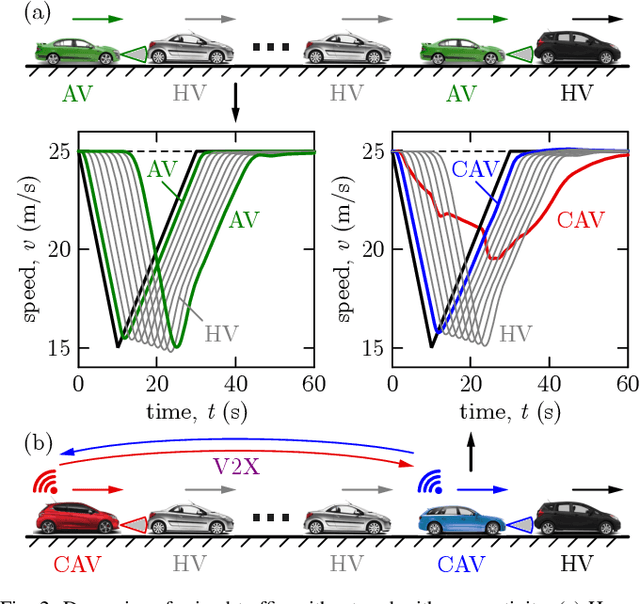
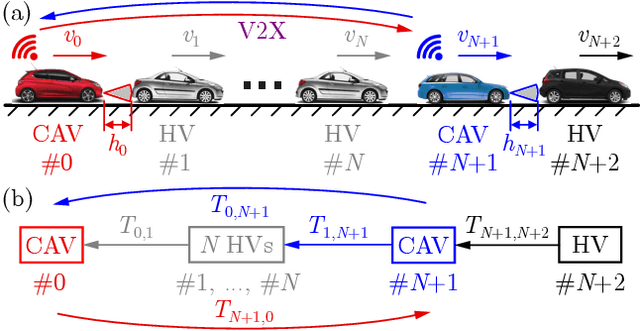
This paper considers mixed traffic consisting of connected automated vehicles equipped with vehicle-to-everything (V2X) connectivity and human-driven vehicles. A control strategy is proposed for communicating pairs of connected automated vehicles, where the two vehicles regulate their longitudinal motion by responding to each other, and, at the same time, stabilize the human-driven traffic between them. Stability analysis is conducted to find stabilizing controllers, and simulations are used to show the efficacy of the proposed approach. The impact of the penetration of connectivity and automation on the string stability of traffic is quantified. It is shown that, even with moderate penetration, connected automated vehicle pairs executing the proposed controllers achieve significant benefits compared to when these vehicles are disconnected and controlled independently.