 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Document-level Relation Extraction with Relation Correlations
Dec 20, 2022

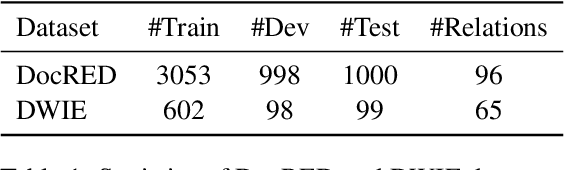
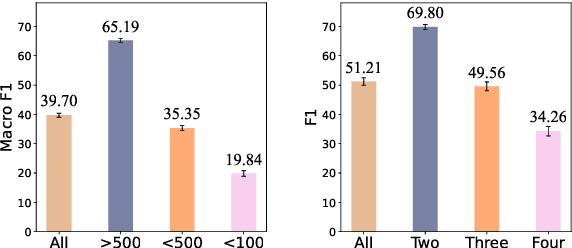
Document-level relation extraction faces two overlooked challenges: long-tail problem and multi-label problem. Previous work focuses mainly on obtaining better contextual representations for entity pairs, hardly address the above challenges. In this paper, we analyze the co-occurrence correlation of relations, and introduce it into DocRE task for the first time. We argue that the correlations can not only transfer knowledge between data-rich relations and data-scarce ones to assist in the training of tailed relations, but also reflect semantic distance guiding the classifier to identify semantically close relations for multi-label entity pairs. Specifically, we use relation embedding as a medium, and propose two co-occurrence prediction sub-tasks from both coarse- and fine-grained perspectives to capture relation correlations. Finally, the learned correlation-aware embeddings are used to guide the extraction of relational facts. Substantial experiments on two popular DocRE datasets are conducted, and our method achieves superior results compared to baselines. Insightful analysis also demonstrates the potential of relation correlations to address the above challenges.
A Physics-Informed Neural Network to Model Port Channels
Dec 20, 2022
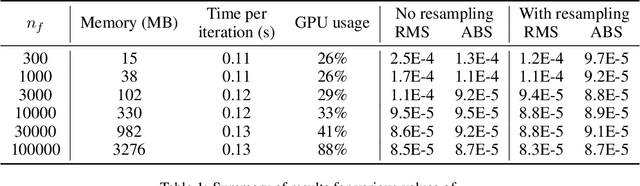
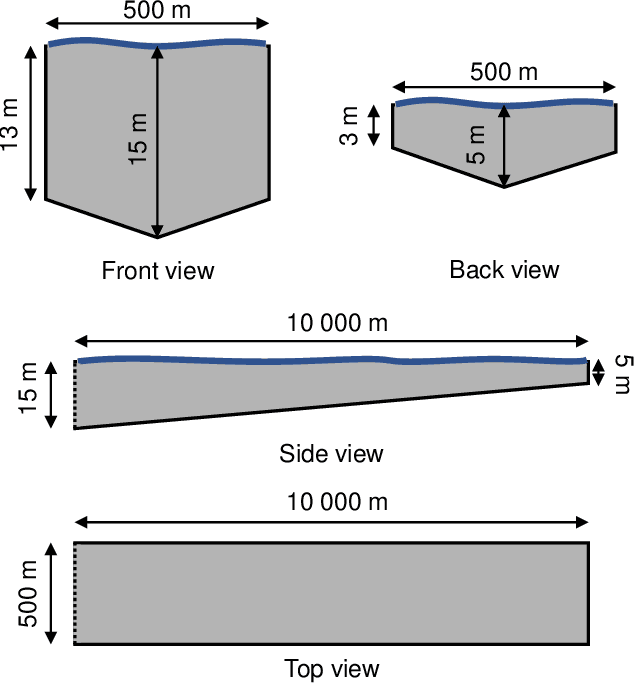
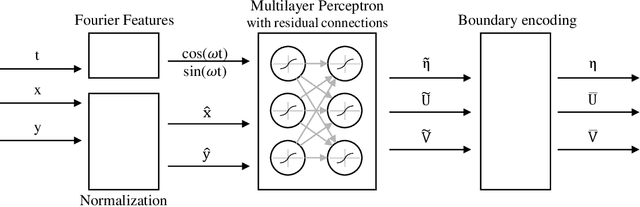
We describe a Physics-Informed Neural Network (PINN) that simulates the flow induced by the astronomical tide in a synthetic port channel, with dimensions based on the Santos - S\~ao Vicente - Bertioga Estuarine System. PINN models aim to combine the knowledge of physical systems and data-driven machine learning models. This is done by training a neural network to minimize the residuals of the governing equations in sample points. In this work, our flow is governed by the Navier-Stokes equations with some approximations. There are two main novelties in this paper. First, we design our model to assume that the flow is periodic in time, which is not feasible in conventional simulation methods. Second, we evaluate the benefit of resampling the function evaluation points during training, which has a near zero computational cost and has been verified to improve the final model, especially for small batch sizes. Finally, we discuss some limitations of the approximations used in the Navier-Stokes equations regarding the modeling of turbulence and how it interacts with PINNs.
Painterly Image Harmonization in Dual Domains
Dec 20, 2022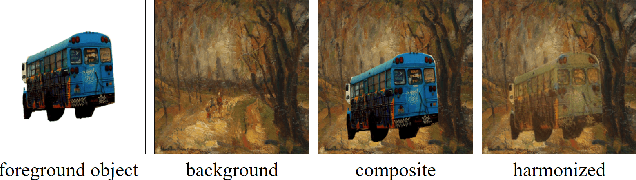

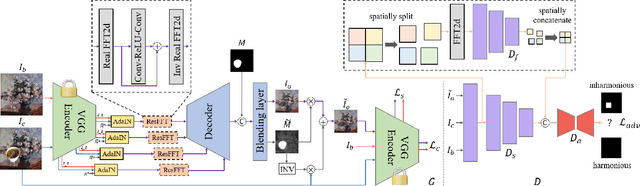
Image harmonization aims to produce visually harmonious composite images by adjusting the foreground appearance to be compatible with the background. When the composite image has photographic foreground and painterly background, the task is called painterly image harmonization. There are only few works on this task, which are either time-consuming or weak in generating well-harmonized results. In this work, we propose a novel painterly harmonization network consisting of a dual-domain generator and a dual-domain discriminator, which harmonizes the composite image in both spatial domain and frequency domain. The dual-domain generator performs harmonization by using AdaIn modules in the spatial domain and our proposed ResFFT modules in the frequency domain. The dual-domain discriminator attempts to distinguish the inharmonious patches based on the spatial feature and frequency feature of each patch, which can enhance the ability of generator in an adversarial manner. Extensive experiments on the benchmark dataset show the effectiveness of our method. Our code and model are available at https://github.com/bcmi/PHDNet-Painterly-Image-Harmonization.
Dynamic Molecular Graph-based Implementation for Biophysical Properties Prediction
Dec 20, 2022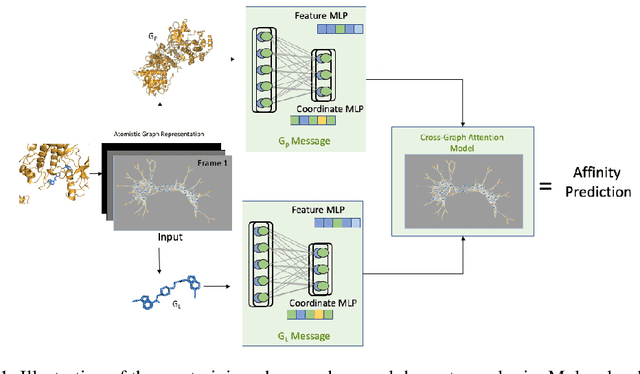
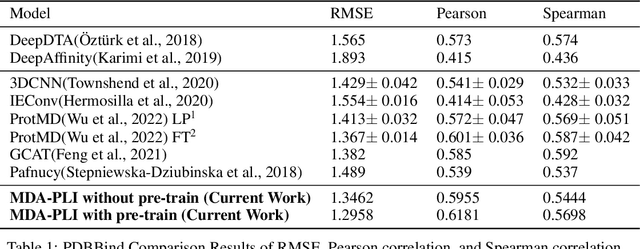
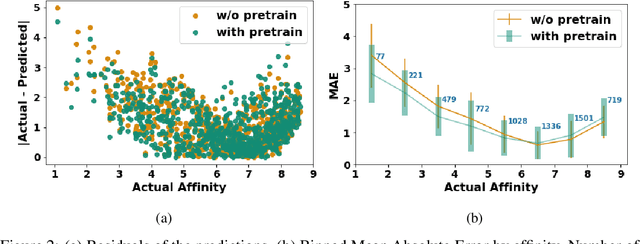
Neural Networks (GNNs) have revolutionized the molecular discovery to understand patterns and identify unknown features that can aid in predicting biophysical properties and protein-ligand interactions. However, current models typically rely on 2-dimensional molecular representations as input, and while utilization of 2\3- dimensional structural data has gained deserved traction in recent years as many of these models are still limited to static graph representations. We propose a novel approach based on the transformer model utilizing GNNs for characterizing dynamic features of protein-ligand interactions. Our message passing transformer pre-trains on a set of molecular dynamic data based off of physics-based simulations to learn coordinate construction and make binding probability and affinity predictions as a downstream task. Through extensive testing we compare our results with the existing models, our MDA-PLI model was able to outperform the molecular interaction prediction models with an RMSE of 1.2958. The geometric encodings enabled by our transformer architecture and the addition of time series data add a new dimensionality to this form of research.
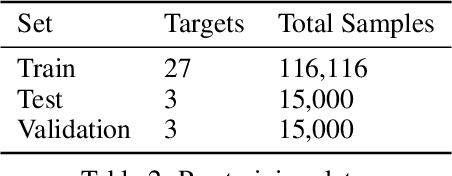
Spatio-Temporal Meta-Graph Learning for Traffic Forecasting
Nov 27, 2022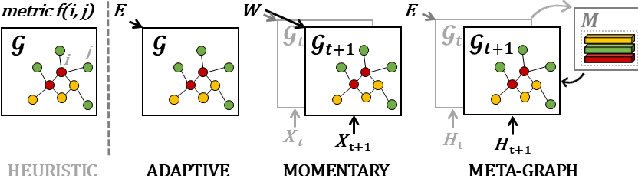

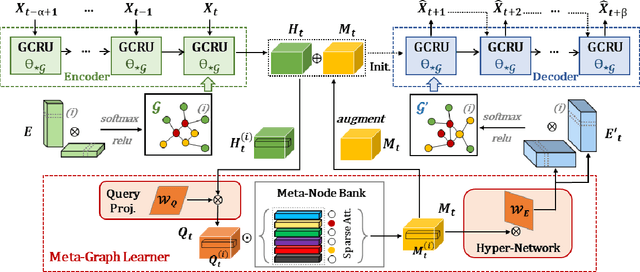
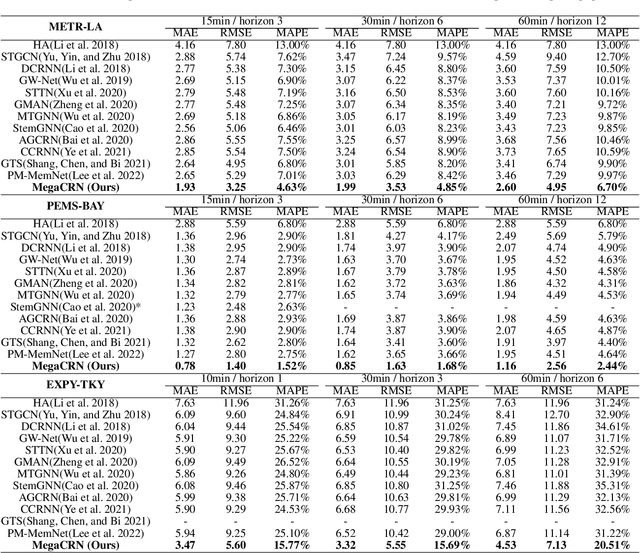
Traffic forecasting as a canonical task of multivariate time series forecasting has been a significant research topic in AI community. To address the spatio-temporal heterogeneity and non-stationarity implied in the traffic stream, in this study, we propose Spatio-Temporal Meta-Graph Learning as a novel Graph Structure Learning mechanism on spatio-temporal data. Specifically, we implement this idea into Meta-Graph Convolutional Recurrent Network (MegaCRN) by plugging the Meta-Graph Learner powered by a Meta-Node Bank into GCRN encoder-decoder. We conduct a comprehensive evaluation on two benchmark datasets (METR-LA and PEMS-BAY) and a new large-scale traffic speed dataset in which traffic incident information is contained. Our model outperformed the state-of-the-arts to a large degree on all three datasets (over 27% MAE and 34% RMSE). Besides, through a series of qualitative evaluations, we demonstrate that our model can explicitly disentangle the road links and time slots with different patterns and be robustly adaptive to any anomalous traffic situations. Codes and datasets are available at https://github.com/deepkashiwa20/MegaCRN.
A Permutation-free Kernel Two-Sample Test
Nov 27, 2022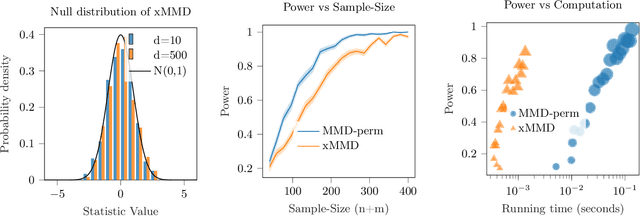
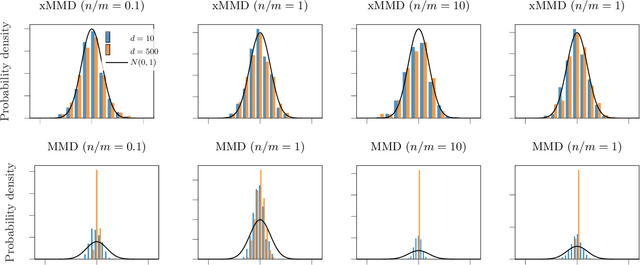
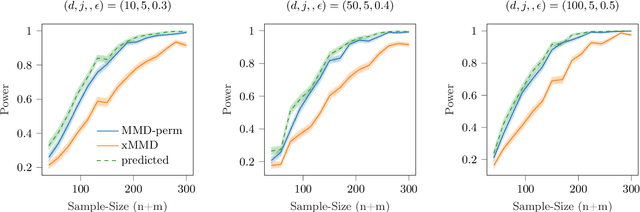
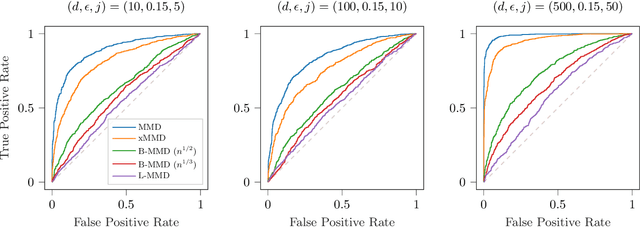
The kernel Maximum Mean Discrepancy~(MMD) is a popular multivariate distance metric between distributions that has found utility in two-sample testing. The usual kernel-MMD test statistic is a degenerate U-statistic under the null, and thus it has an intractable limiting distribution. Hence, to design a level-$\alpha$ test, one usually selects the rejection threshold as the $(1-\alpha)$-quantile of the permutation distribution. The resulting nonparametric test has finite-sample validity but suffers from large computational cost, since every permutation takes quadratic time. We propose the cross-MMD, a new quadratic-time MMD test statistic based on sample-splitting and studentization. We prove that under mild assumptions, the cross-MMD has a limiting standard Gaussian distribution under the null. Importantly, we also show that the resulting test is consistent against any fixed alternative, and when using the Gaussian kernel, it has minimax rate-optimal power against local alternatives. For large sample sizes, our new cross-MMD provides a significant speedup over the MMD, for only a slight loss in power.
Deep learning applied to computational mechanics: A comprehensive review, state of the art, and the classics
Dec 31, 2022
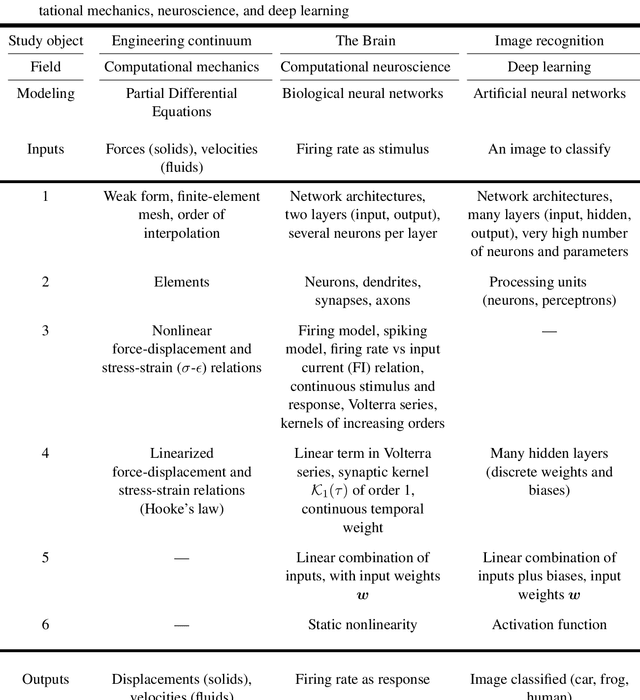


Three recent breakthroughs due to AI in arts and science serve as motivation: An award winning digital image, protein folding, fast matrix multiplication. Many recent developments in artificial neural networks, particularly deep learning (DL), applied and relevant to computational mechanics (solid, fluids, finite-element technology) are reviewed in detail. Both hybrid and pure machine learning (ML) methods are discussed. Hybrid methods combine traditional PDE discretizations with ML methods either (1) to help model complex nonlinear constitutive relations, (2) to nonlinearly reduce the model order for efficient simulation (turbulence), or (3) to accelerate the simulation by predicting certain components in the traditional integration methods. Here, methods (1) and (2) relied on Long-Short-Term Memory (LSTM) architecture, with method (3) relying on convolutional neural networks.. Pure ML methods to solve (nonlinear) PDEs are represented by Physics-Informed Neural network (PINN) methods, which could be combined with attention mechanism to address discontinuous solutions. Both LSTM and attention architectures, together with modern and generalized classic optimizers to include stochasticity for DL networks, are extensively reviewed. Kernel machines, including Gaussian processes, are provided to sufficient depth for more advanced works such as shallow networks with infinite width. Not only addressing experts, readers are assumed familiar with computational mechanics, but not with DL, whose concepts and applications are built up from the basics, aiming at bringing first-time learners quickly to the forefront of research. History and limitations of AI are recounted and discussed, with particular attention at pointing out misstatements or misconceptions of the classics, even in well-known references. Positioning and pointing control of a large-deformable beam is given as an example.
Phase2vec: Dynamical systems embedding with a physics-informed convolutional network
Dec 07, 2022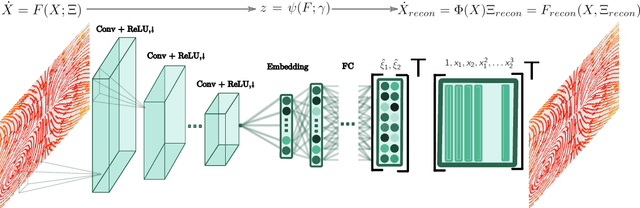
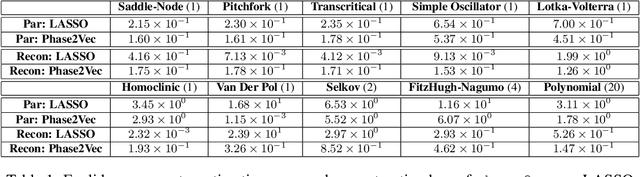
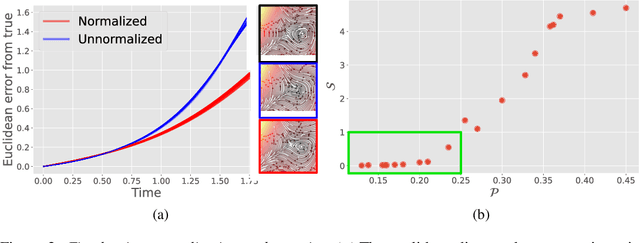
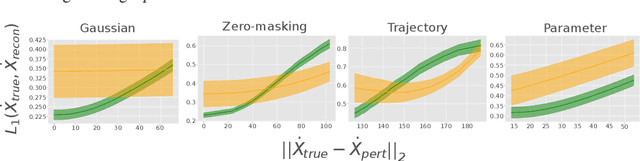
Dynamical systems are found in innumerable forms across the physical and biological sciences, yet all these systems fall naturally into universal equivalence classes: conservative or dissipative, stable or unstable, compressible or incompressible. Predicting these classes from data remains an essential open challenge in computational physics at which existing time-series classification methods struggle. Here, we propose, \texttt{phase2vec}, an embedding method that learns high-quality, physically-meaningful representations of 2D dynamical systems without supervision. Our embeddings are produced by a convolutional backbone that extracts geometric features from flow data and minimizes a physically-informed vector field reconstruction loss. In an auxiliary training period, embeddings are optimized so that they robustly encode the equations of unseen data over and above the performance of a per-equation fitting method. The trained architecture can not only predict the equations of unseen data, but also, crucially, learns embeddings that respect the underlying semantics of the embedded physical systems. We validate the quality of learned embeddings investigating the extent to which physical categories of input data can be decoded from embeddings compared to standard blackbox classifiers and state-of-the-art time series classification techniques. We find that our embeddings encode important physical properties of the underlying data, including the stability of fixed points, conservation of energy, and the incompressibility of flows, with greater fidelity than competing methods. We finally apply our embeddings to the analysis of meteorological data, showing we can detect climatically meaningful features. Collectively, our results demonstrate the viability of embedding approaches for the discovery of dynamical features in physical systems.
LSVL: Large-scale season-invariant visual localization for UAVs
Dec 07, 2022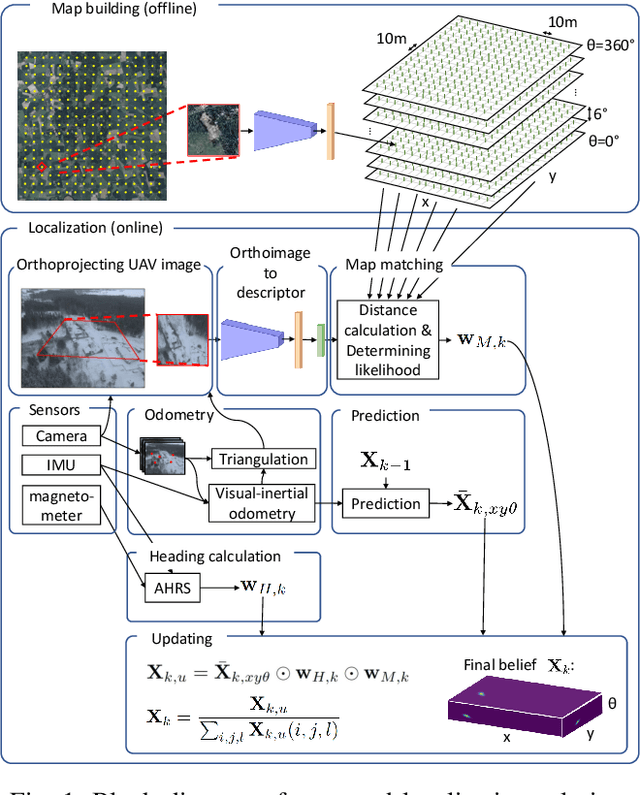
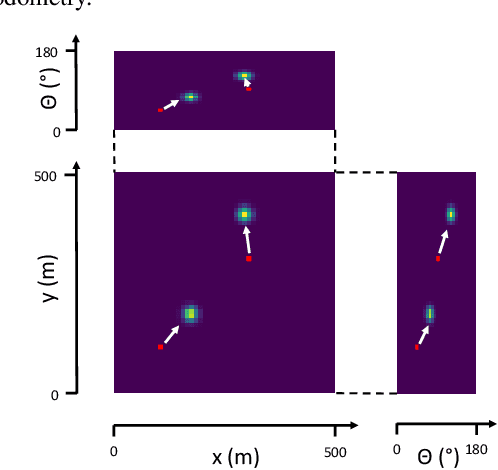
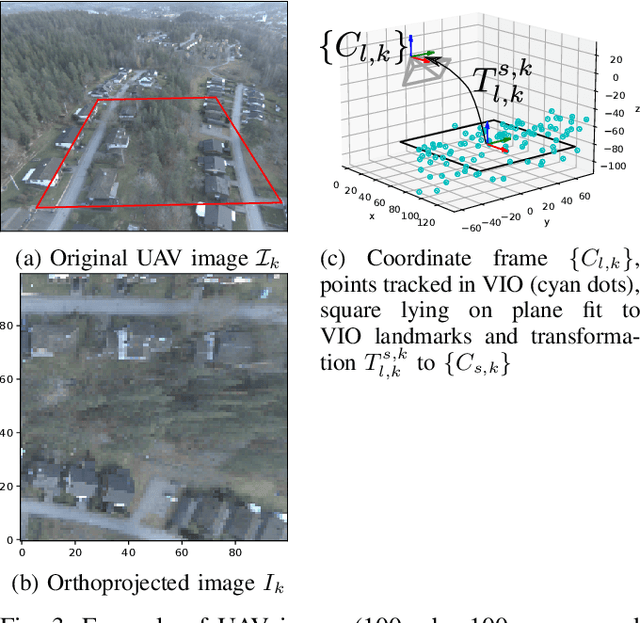
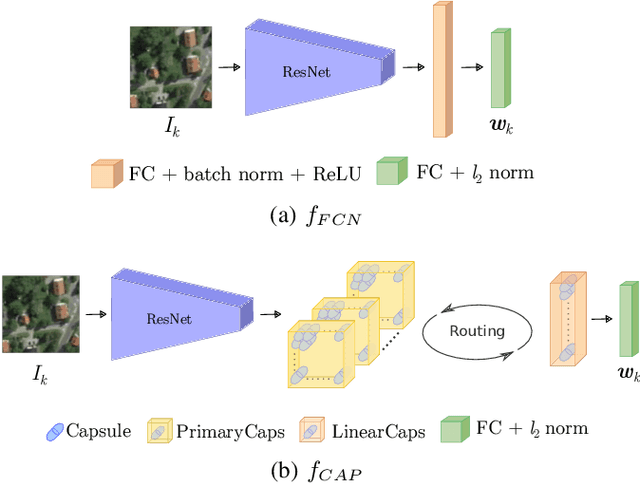
Localization of autonomous unmanned aerial vehicles (UAVs) relies heavily on Global Navigation Satellite Systems (GNSS), which are susceptible to interference. Especially in security applications, robust localization algorithms independent of GNSS are needed to provide dependable operations of autonomous UAVs also in interfered conditions. Typical non-GNSS visual localization approaches rely on known starting pose, work only on a small-sized map, or require known flight paths before a mission starts. We consider the problem of localization with no information on initial pose or planned flight path. We propose a solution for global visual localization on a map at scale up to 100 km2, based on matching orthoprojected UAV images to satellite imagery using learned season-invariant descriptors. We show that the method is able to determine heading, latitude and longitude of the UAV at 12.6-18.7 m lateral translation error in as few as 23.2-44.4 updates from an uninformed initialization, also in situations of significant seasonal appearance difference (winter-summer) between the UAV image and the map. We evaluate the characteristics of multiple neural network architectures for generating the descriptors, and likelihood estimation methods that are able to provide fast convergence and low localization error. We also evaluate the operation of the algorithm using real UAV data and evaluate running time on a real-time embedded platform. We believe this is the first work that is able to recover the pose of an UAV at this scale and rate of convergence, while allowing significant seasonal difference between camera observations and map.
Slimmable Pruned Neural Networks
Dec 07, 2022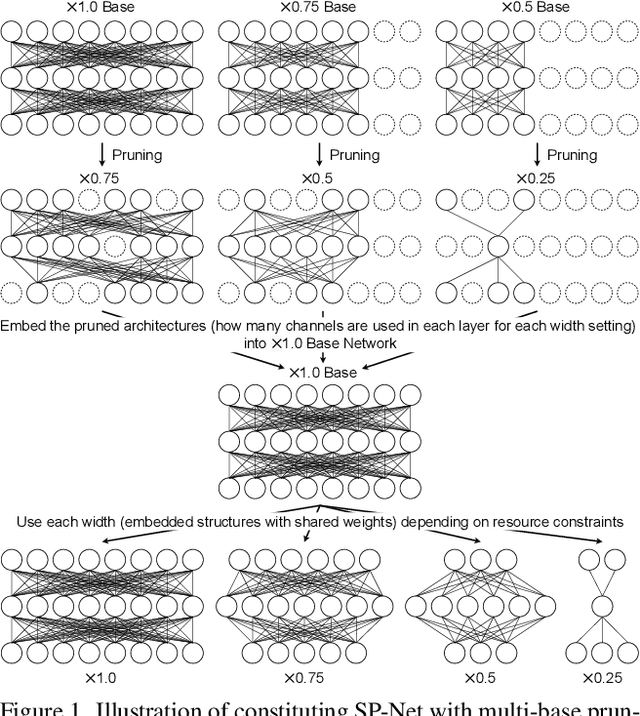

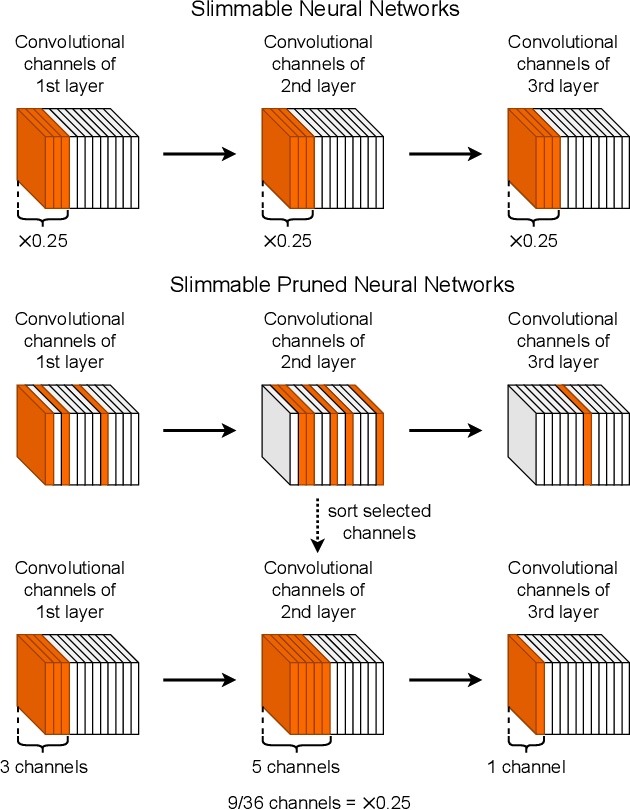
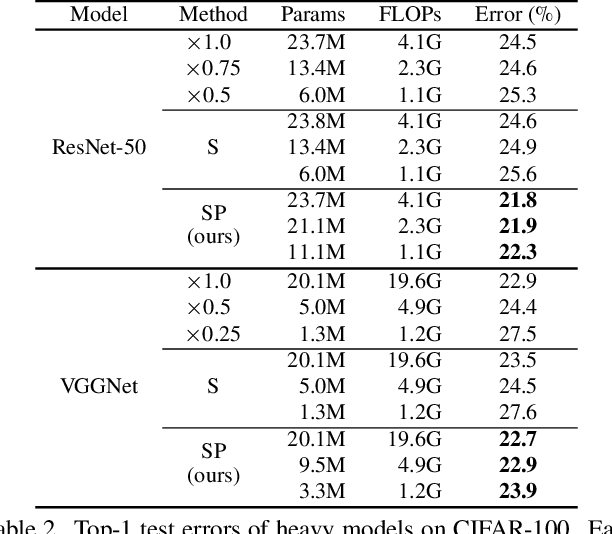
Slimmable Neural Networks (S-Net) is a novel network which enabled to select one of the predefined proportions of channels (sub-network) dynamically depending on the current computational resource availability. The accuracy of each sub-network on S-Net, however, is inferior to that of individually trained networks of the same size due to its difficulty of simultaneous optimization on different sub-networks. In this paper, we propose Slimmable Pruned Neural Networks (SP-Net), which has sub-network structures learned by pruning instead of adopting structures with the same proportion of channels in each layer (width multiplier) like S-Net, and we also propose new pruning procedures: multi-base pruning instead of one-shot or iterative pruning to realize high accuracy and huge training time saving. We also introduced slimmable channel sorting (scs) to achieve calculation as fast as S-Net and zero padding match (zpm) pruning to prune residual structure in more efficient way. SP-Net can be combined with any kind of channel pruning methods and does not require any complicated processing or time-consuming architecture search like NAS models. Compared with each sub-network of the same FLOPs on S-Net, SP-Net improves accuracy by 1.2-1.5% for ResNet-50, 0.9-4.4% for VGGNet, 1.3-2.7% for MobileNetV1, 1.4-3.1% for MobileNetV2 on ImageNet. Furthermore, our methods outperform other SOTA pruning methods and are on par with various NAS models according to our experimental results on ImageNet. The code is available at https://github.com/hideakikuratsu/SP-Net.