 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Decoding surface codes with deep reinforcement learning and probabilistic policy reuse
Dec 22, 2022
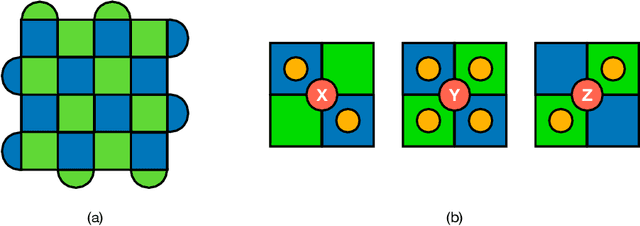
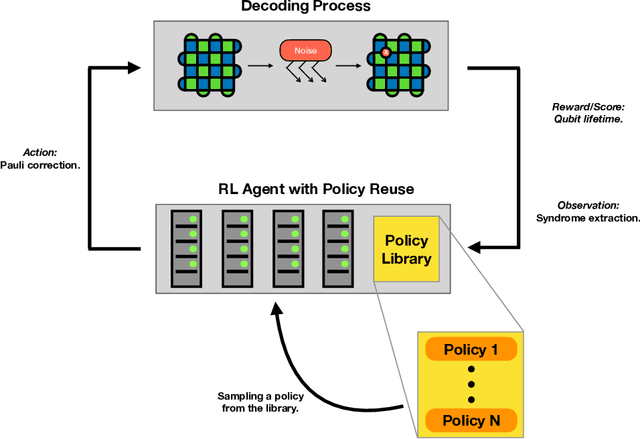
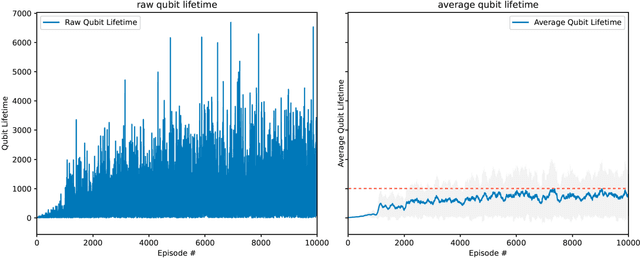
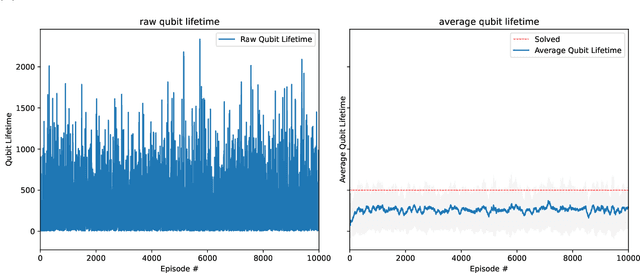
Quantum computing (QC) promises significant advantages on certain hard computational tasks over classical computers. However, current quantum hardware, also known as noisy intermediate-scale quantum computers (NISQ), are still unable to carry out computations faithfully mainly because of the lack of quantum error correction (QEC) capability. A significant amount of theoretical studies have provided various types of QEC codes; one of the notable topological codes is the surface code, and its features, such as the requirement of only nearest-neighboring two-qubit control gates and a large error threshold, make it a leading candidate for scalable quantum computation. Recent developments of machine learning (ML)-based techniques especially the reinforcement learning (RL) methods have been applied to the decoding problem and have already made certain progress. Nevertheless, the device noise pattern may change over time, making trained decoder models ineffective. In this paper, we propose a continual reinforcement learning method to address these decoding challenges. Specifically, we implement double deep Q-learning with probabilistic policy reuse (DDQN-PPR) model to learn surface code decoding strategies for quantum environments with varying noise patterns. Through numerical simulations, we show that the proposed DDQN-PPR model can significantly reduce the computational complexity. Moreover, increasing the number of trained policies can further improve the agent's performance. Our results open a way to build more capable RL agents which can leverage previously gained knowledge to tackle QEC challenges.
Understanding Postpartum Parents' Experiences via Two Digital Platforms
Dec 22, 2022
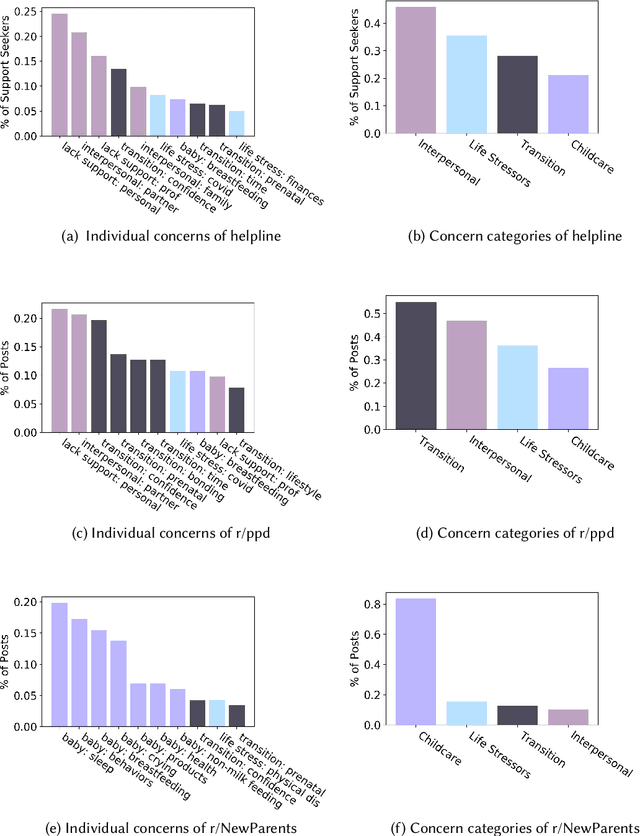
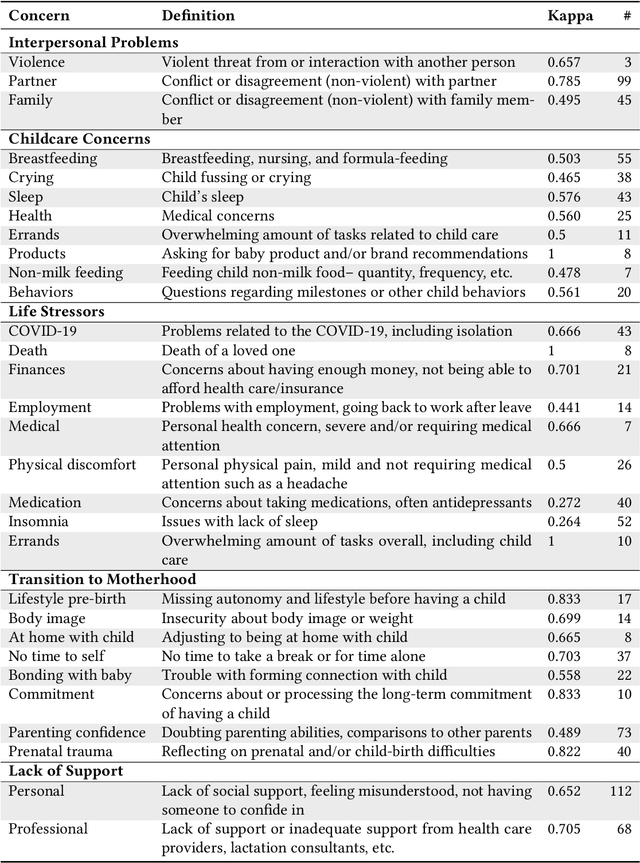
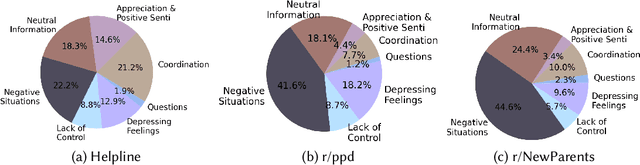
Digital platforms, including online forums and helplines, have emerged as avenues of support for caregivers suffering from postpartum mental health distress. Understanding support seekers' experiences as shared on these platforms could provide crucial insight into caregivers' needs during this vulnerable time. In the current work, we provide a descriptive analysis of the concerns, psychological states, and motivations shared by healthy and distressed postpartum support seekers on two digital platforms, a one-on-one digital helpline and a publicly available online forum. Using a combination of human annotations, dictionary models and unsupervised techniques, we find stark differences between the experiences of distressed and healthy mothers. Distressed mothers described interpersonal problems and a lack of support, with 8.60% - 14.56% reporting severe symptoms including suicidal ideation. In contrast, the majority of healthy mothers described childcare issues, such as questions about breastfeeding or sleeping, and reported no severe mental health concerns. Across the two digital platforms, we found that distressed mothers shared similar content. However, the patterns of speech and affect shared by distressed mothers differed between the helpline vs. the online forum, suggesting the design of these platforms may shape meaningful measures of their support-seeking experiences. Our results provide new insight into the experiences of caregivers suffering from postpartum mental health distress. We conclude by discussing methodological considerations for understanding content shared by support seekers and design considerations for the next generation of support tools for postpartum parents.
An Attention-based Multi-Scale Feature Learning Network for Multimodal Medical Image Fusion
Dec 09, 2022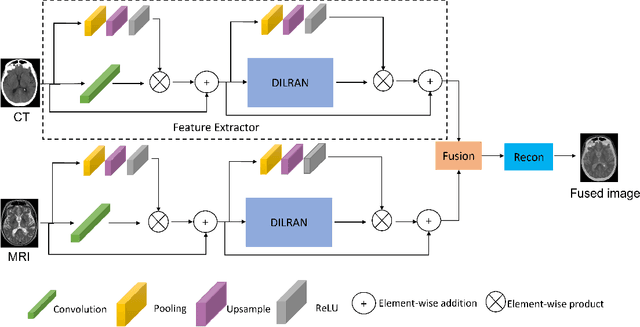
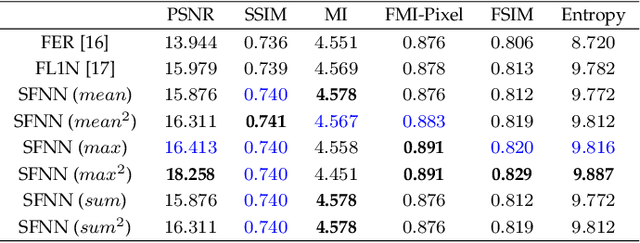
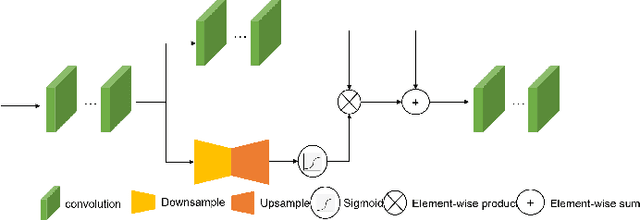
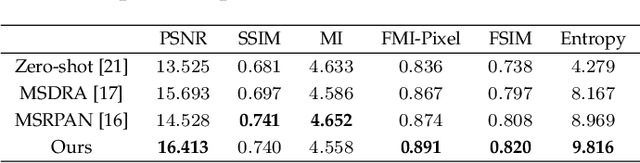
Medical images play an important role in clinical applications. Multimodal medical images could provide rich information about patients for physicians to diagnose. The image fusion technique is able to synthesize complementary information from multimodal images into a single image. This technique will prevent radiologists switch back and forth between different images and save lots of time in the diagnostic process. In this paper, we introduce a novel Dilated Residual Attention Network for the medical image fusion task. Our network is capable to extract multi-scale deep semantic features. Furthermore, we propose a novel fixed fusion strategy termed Softmax-based weighted strategy based on the Softmax weights and matrix nuclear norm. Extensive experiments show our proposed network and fusion strategy exceed the state-of-the-art performance compared with reference image fusion methods on four commonly used fusion metrics.
Reinforcement Learning for Predicting Traffic Accidents
Dec 09, 2022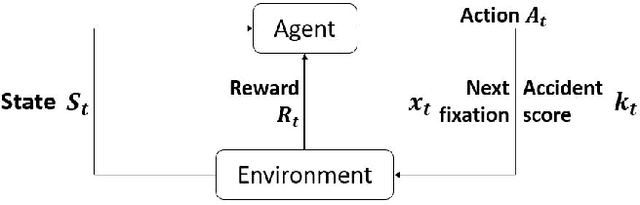
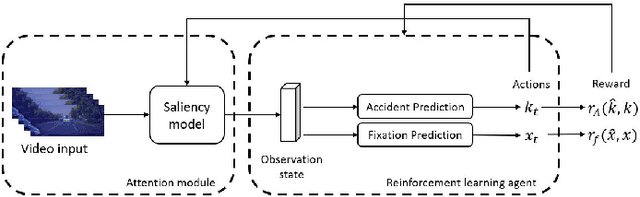
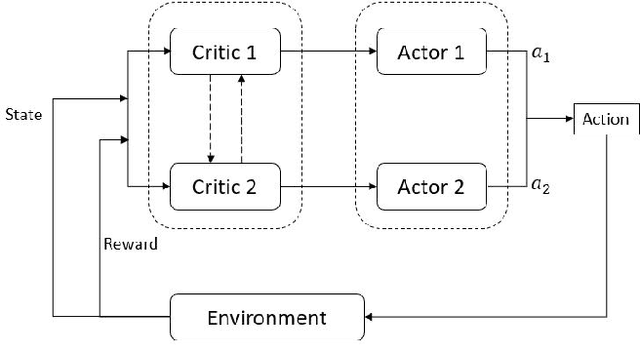
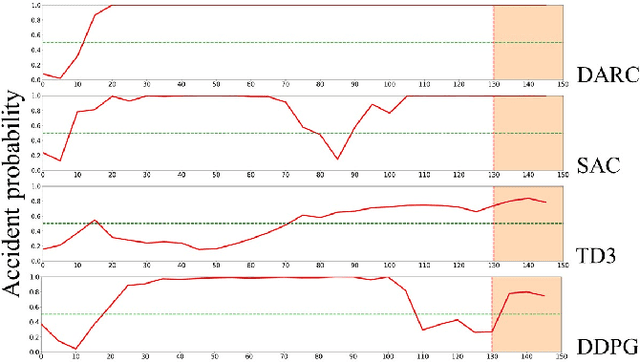
As the demand for autonomous driving increases, it is paramount to ensure safety. Early accident prediction using deep learning methods for driving safety has recently gained much attention. In this task, early accident prediction and a point prediction of where the drivers should look are determined, with the dashcam video as input. We propose to exploit the double actors and regularized critics (DARC) method, for the first time, on this accident forecasting platform. We derive inspiration from DARC since it is currently a state-of-the-art reinforcement learning (RL) model on continuous action space suitable for accident anticipation. Results show that by utilizing DARC, we can make predictions 5\% earlier on average while improving in multiple metrics of precision compared to existing methods. The results imply that using our RL-based problem formulation could significantly increase the safety of autonomous driving.
Minimum time trajectory generation for surveying using UAVs
Mar 05, 2022


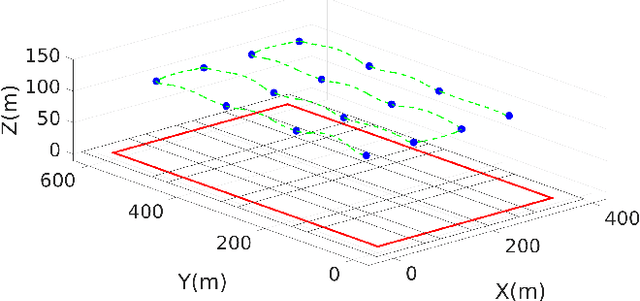
In this paper, we present a motion planning strategy for UAVs that generates a time-optimal trajectory to survey a given target area. There are several situations where completing an aerial survey is time sensitive, such as gaining situational awareness for first responders, surveying hazardous environments, etc. One of the challenges in such cases is to plan a time-optimal trajectory for the drone. To this end, we present an autonomous aerial survey framework that minimizes the time taken to completely explore a target area or volume using drones. In this work, (i) we present an approach, where for a known flight survey pattern, the planner can generate time-optimal flight paths in 3-D (ii) we frame the planning problem as a discrete non-linear program, and reduce the time taken to compute its solution by using an SOCP relaxation (iii) The given path is then executed using a simple trajectory tracking controller on a quadrotor to demonstrate its capability on hardware.
Towards Smooth Video Composition
Dec 14, 2022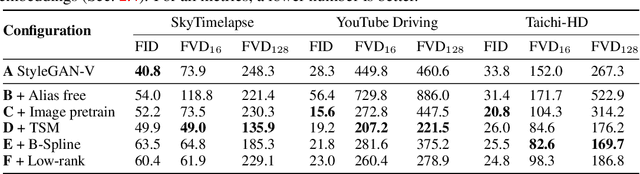

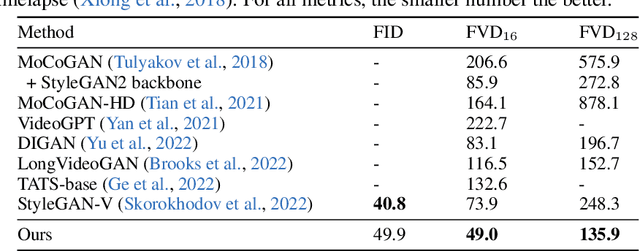

Video generation requires synthesizing consistent and persistent frames with dynamic content over time. This work investigates modeling the temporal relations for composing video with arbitrary length, from a few frames to even infinite, using generative adversarial networks (GANs). First, towards composing adjacent frames, we show that the alias-free operation for single image generation, together with adequately pre-learned knowledge, brings a smooth frame transition without compromising the per-frame quality. Second, by incorporating the temporal shift module (TSM), originally designed for video understanding, into the discriminator, we manage to advance the generator in synthesizing more consistent dynamics. Third, we develop a novel B-Spline based motion representation to ensure temporal smoothness to achieve infinite-length video generation. It can go beyond the frame number used in training. A low-rank temporal modulation is also proposed to alleviate repeating contents for long video generation. We evaluate our approach on various datasets and show substantial improvements over video generation baselines. Code and models will be publicly available at https://genforce.github.io/StyleSV.
A Multi-Modal Machine Learning Approach to Detect Extreme Rainfall Events in Sicily
Dec 14, 2022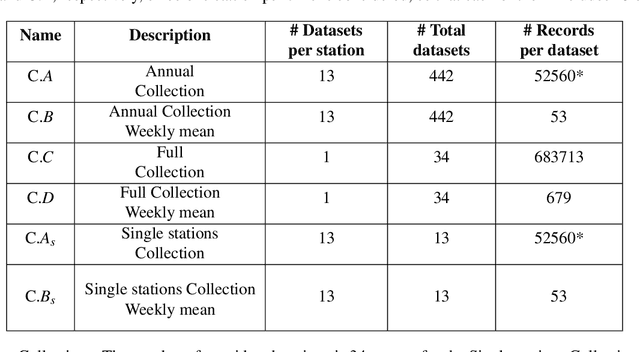
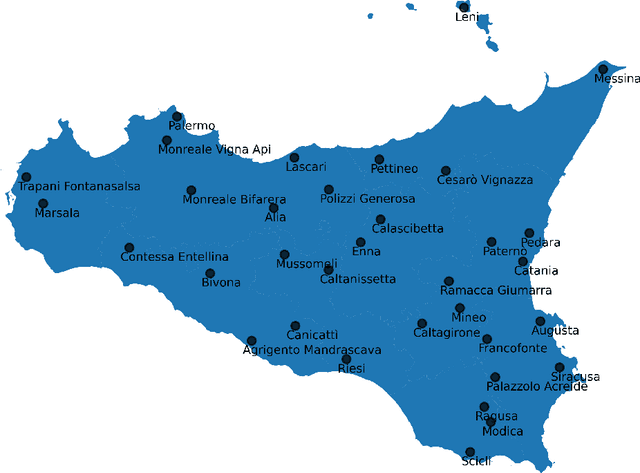
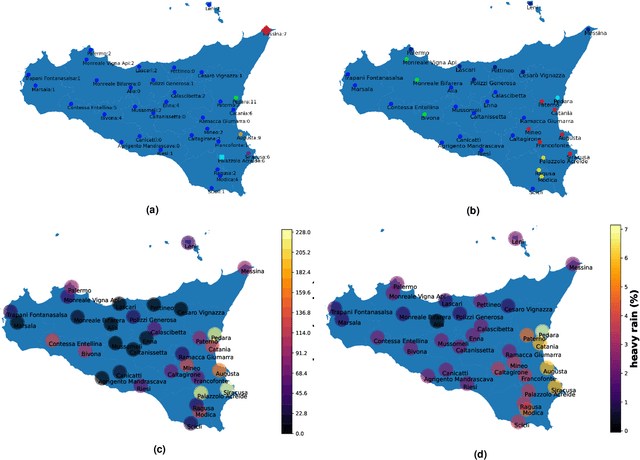
In 2021 300 mm of rain, nearly half the average annual rainfall, fell near Catania (Sicily island, Italy). Such events took place in just a few hours, with dramatic consequences on the environmental, social, economic, and health systems of the region. This is the reason why, detecting extreme rainfall events is a crucial prerequisite for planning actions able to reverse possibly intensified dramatic future scenarios. In this paper, the Affinity Propagation algorithm, a clustering algorithm grounded on machine learning, was applied, to the best of our knowledge, for the first time, to identify excess rain events in Sicily. This was possible by using a high-frequency, large dataset we collected, ranging from 2009 to 2021 which we named RSE (the Rainfall Sicily Extreme dataset). Weather indicators were then been employed to validate the results, thus confirming the presence of recent anomalous rainfall events in eastern Sicily. We believe that easy-to-use and multi-modal data science techniques, such as the one proposed in this study, could give rise to significant improvements in policy-making for successfully contrasting climate changes.
Traffic Flow Prediction via Variational Bayesian Inference-based Encoder-Decoder Framework
Dec 14, 2022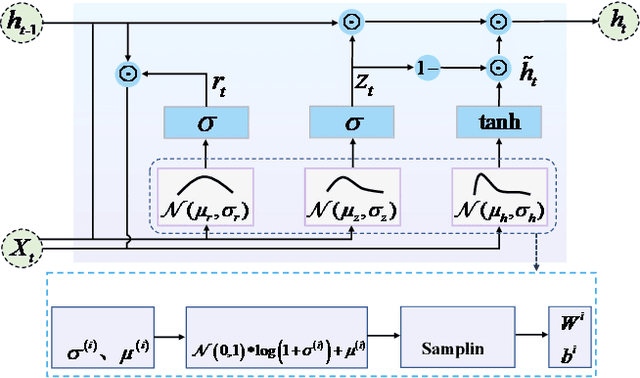
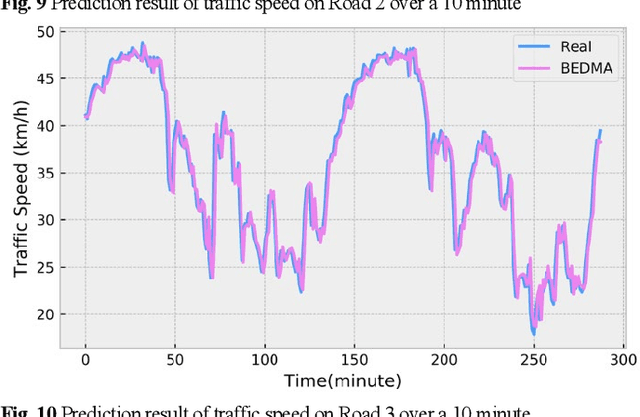
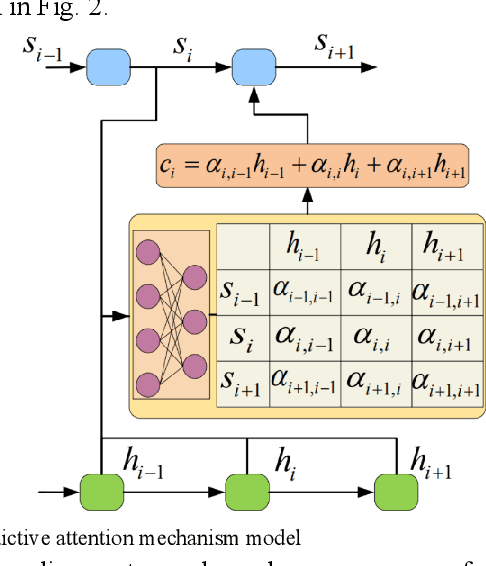
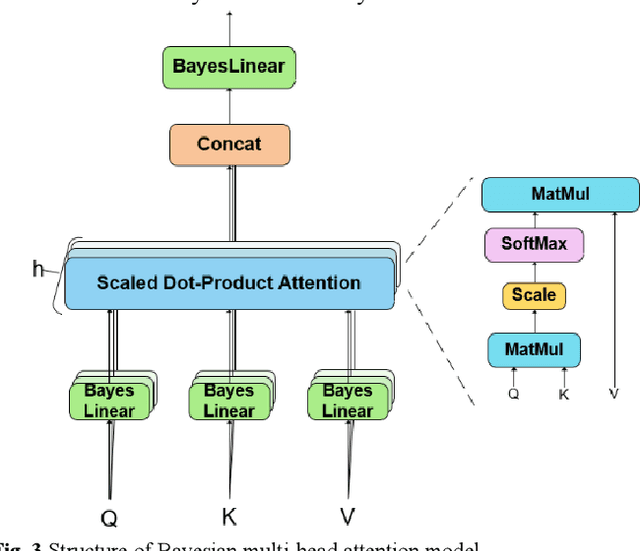
Accurate traffic flow prediction, a hotspot for intelligent transportation research, is the prerequisite for mastering traffic and making travel plans. The speed of traffic flow can be affected by roads condition, weather, holidays, etc. Furthermore, the sensors to catch the information about traffic flow will be interfered with by environmental factors such as illumination, collection time, occlusion, etc. Therefore, the traffic flow in the practical transportation system is complicated, uncertain, and challenging to predict accurately. This paper proposes a deep encoder-decoder prediction framework based on variational Bayesian inference. A Bayesian neural network is constructed by combining variational inference with gated recurrent units (GRU) and used as the deep neural network unit of the encoder-decoder framework to mine the intrinsic dynamics of traffic flow. Then, the variational inference is introduced into the multi-head attention mechanism to avoid noise-induced deterioration of prediction accuracy. The proposed model achieves superior prediction performance on the Guangzhou urban traffic flow dataset over the benchmarks, particularly when the long-term prediction.
On LASSO for High Dimensional Predictive Regression
Dec 14, 2022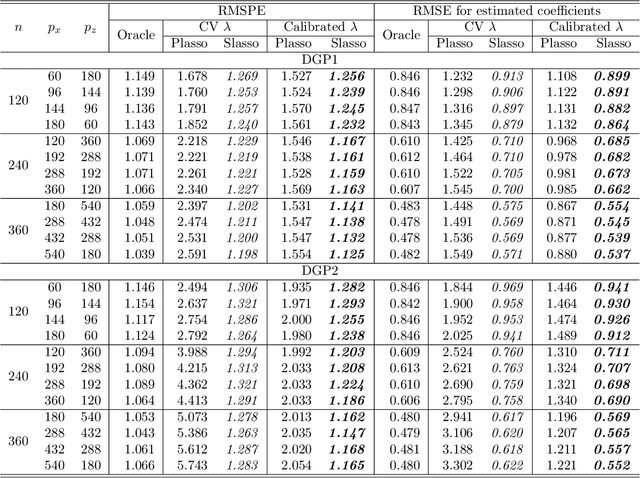
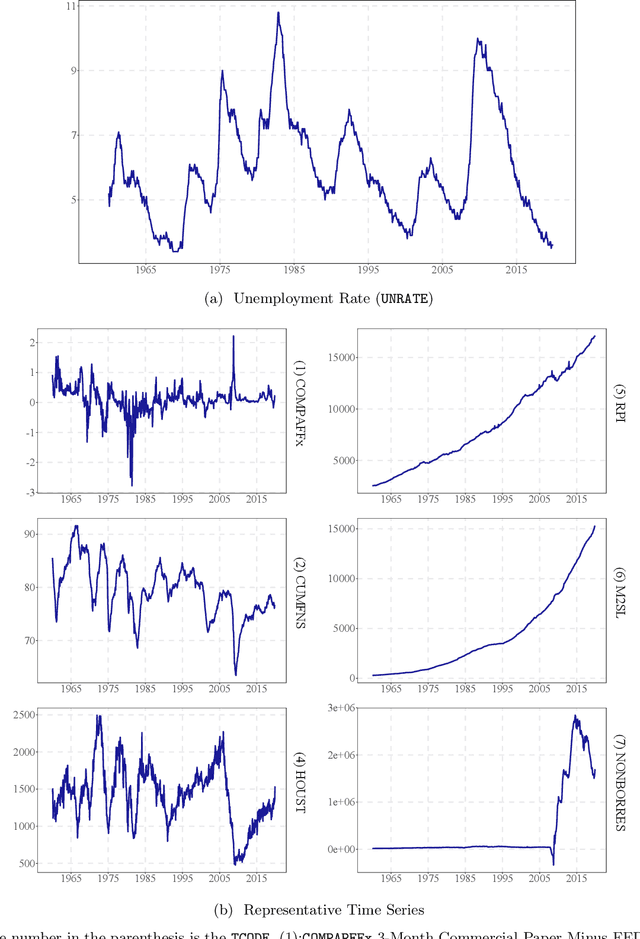
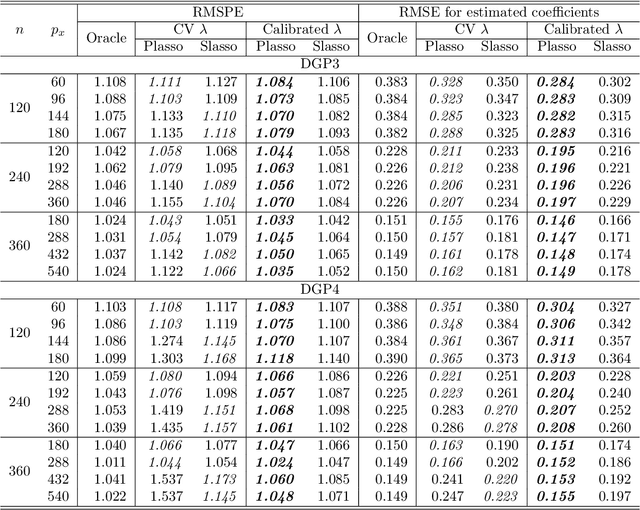
In a high dimensional linear predictive regression where the number of potential predictors can be larger than the sample size, we consider using LASSO, a popular L1-penalized regression method, to estimate the sparse coefficients when many unit root regressors are present. Consistency of LASSO relies on two building blocks: the deviation bound of the cross product of the regressors and the error term, and the restricted eigenvalue of the Gram matrix of the regressors. In our setting where unit root regressors are driven by temporal dependent non-Gaussian innovations, we establish original probabilistic bounds for these two building blocks. The bounds imply that the rates of convergence of LASSO are different from those in the familiar cross sectional case. In practical applications given a mixture of stationary and nonstationary predictors, asymptotic guarantee of LASSO is preserved if all predictors are scale-standardized. In an empirical example of forecasting the unemployment rate with many macroeconomic time series, strong performance is delivered by LASSO when the initial specification is guided by macroeconomic domain expertise.
Calibration-Free Driver Drowsiness Classification based on Manifold-Level Augmentation
Dec 14, 2022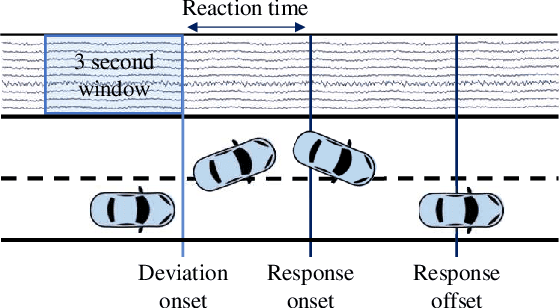
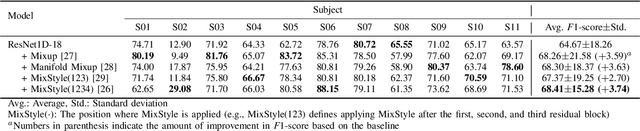
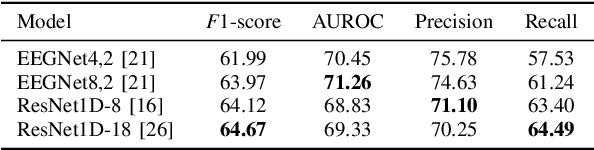
Drowsiness reduces concentration and increases response time, which causes fatal road accidents. Monitoring drivers' drowsiness levels by electroencephalogram (EEG) and taking action may prevent road accidents. EEG signals effectively monitor the driver's mental state as they can monitor brain dynamics. However, calibration is required in advance because EEG signals vary between and within subjects. Because of the inconvenience, calibration has reduced the accessibility of the brain-computer interface (BCI). Developing a generalized classification model is similar to domain generalization, which overcomes the domain shift problem. Especially data augmentation is frequently used. This paper proposes a calibration-free framework for driver drowsiness state classification using manifold-level augmentation. This framework increases the diversity of source domains by utilizing features. We experimented with various augmentation methods to improve the generalization performance. Based on the results of the experiments, we found that deeper models with smaller kernel sizes improved generalizability. In addition, applying an augmentation at the manifold-level resulted in an outstanding improvement. The framework demonstrated the capability for calibration-free BCI.