 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Low-Precision Training for Embeddings in Click-Through Rate Prediction
Dec 12, 2022
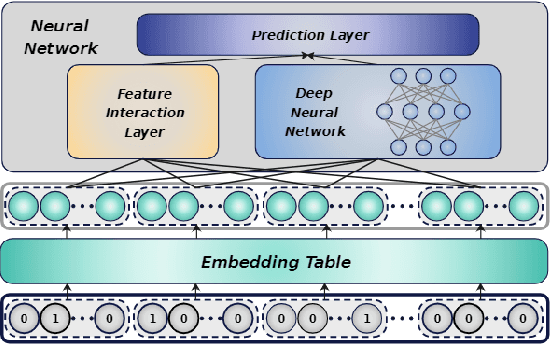
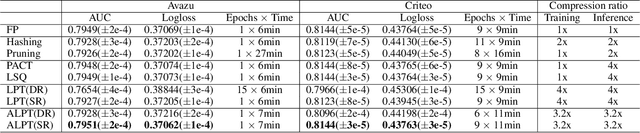
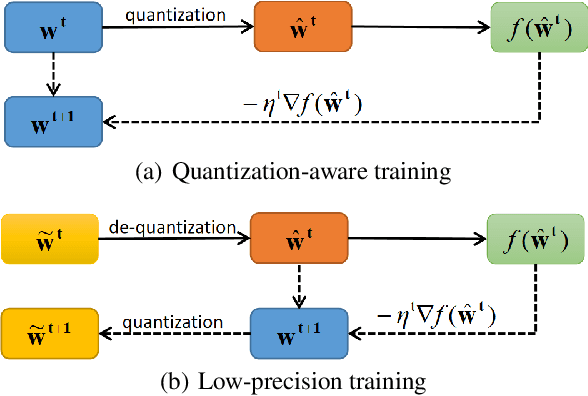
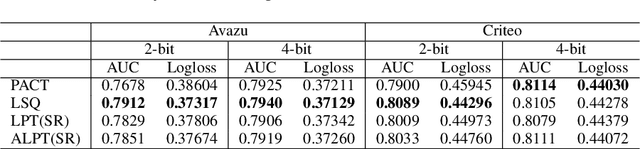
Embedding tables are usually huge in click-through rate (CTR) prediction models. To train and deploy the CTR models efficiently and economically, it is necessary to compress their embedding tables at the training stage. To this end, we formulate a novel quantization training paradigm to compress the embeddings from the training stage, termed low-precision training (LPT). Also, we provide theoretical analysis on its convergence. The results show that stochastic weight quantization has a faster convergence rate and a smaller convergence error than deterministic weight quantization in LPT. Further, to reduce the accuracy degradation, we propose adaptive low-precision training (ALPT) that learns the step size (i.e., the quantization resolution) through gradient descent. Experiments on two real-world datasets confirm our analysis and show that ALPT can significantly improve the prediction accuracy, especially at extremely low bit widths. For the first time in CTR models, we successfully train 8-bit embeddings without sacrificing prediction accuracy. The code of ALPT is publicly available.
Delay Embedded Echo-State Network: A Predictor for Partially Observed Systems
Nov 11, 2022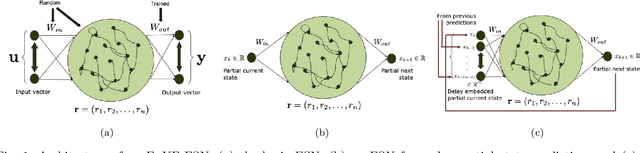

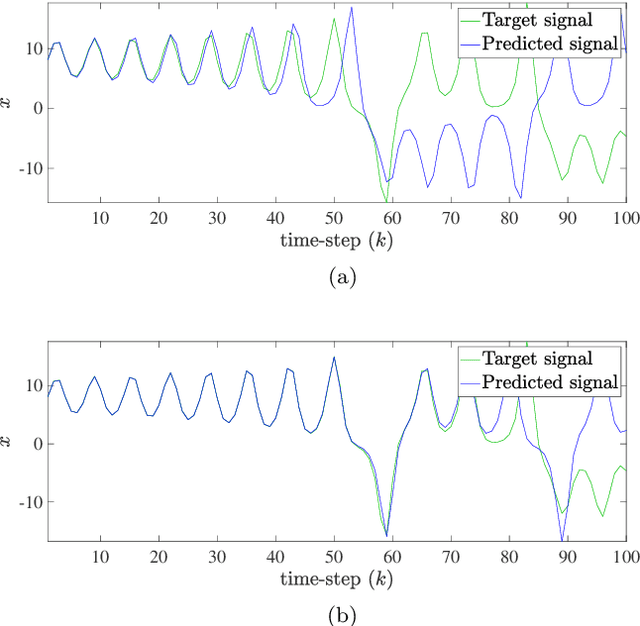
This paper considers the problem of data-driven prediction of partially observed systems using a recurrent neural network. While neural network based dynamic predictors perform well with full-state training data, prediction with partial observation during training phase poses a significant challenge. Here a predictor for partial observations is developed using an echo-state network (ESN) and time delay embedding of the partially observed state. The proposed method is theoretically justified with Taken's embedding theorem and strong observability of a nonlinear system. The efficacy of the proposed method is demonstrated on three systems: two synthetic datasets from chaotic dynamical systems and a set of real-time traffic data.
Recurrent Neural Networks and Universal Approximation of Bayesian Filters
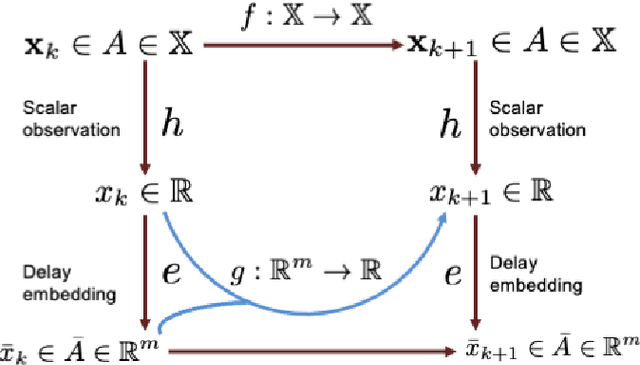
Nov 01, 2022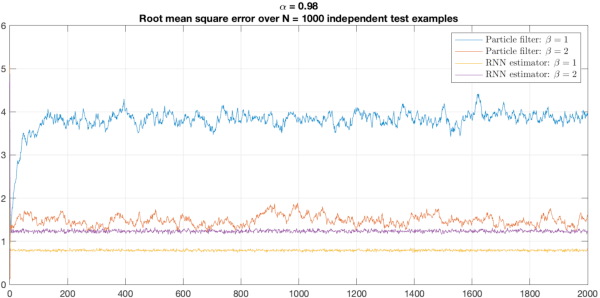
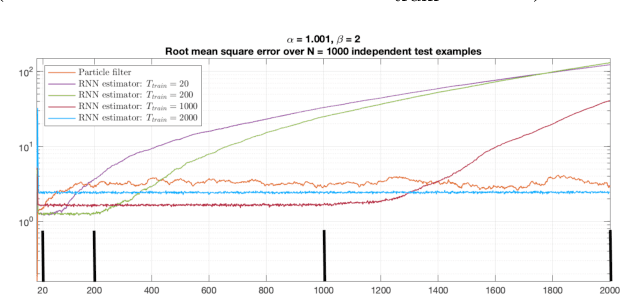
We consider the Bayesian optimal filtering problem: i.e. estimating some conditional statistics of a latent time-series signal from an observation sequence. Classical approaches often rely on the use of assumed or estimated transition and observation models. Instead, we formulate a generic recurrent neural network framework and seek to learn directly a recursive mapping from observational inputs to the desired estimator statistics. The main focus of this article is the approximation capabilities of this framework. We provide approximation error bounds for filtering in general non-compact domains. We also consider strong time-uniform approximation error bounds that guarantee good long-time performance. We discuss and illustrate a number of practical concerns and implications of these results.
Time and the Value of Data
Mar 17, 2022Managers often believe that collecting more data will continually improve the accuracy of their machine learning models. However, we argue in this paper that when data lose relevance over time, it may be optimal to collect a limited amount of recent data instead of keeping around an infinite supply of older (less relevant) data. In addition, we argue that increasing the stock of data by including older datasets may, in fact, damage the model's accuracy. Expectedly, the model's accuracy improves by increasing the flow of data (defined as data collection rate); however, it requires other tradeoffs in terms of refreshing or retraining machine learning models more frequently. Using these results, we investigate how the business value created by machine learning models scales with data and when the stock of data establishes a sustainable competitive advantage. We argue that data's time-dependency weakens the barrier to entry that the stock of data creates. As a result, a competing firm equipped with a limited (yet sufficient) amount of recent data can develop more accurate models. This result, coupled with the fact that older datasets may deteriorate models' accuracy, suggests that created business value doesn't scale with the stock of available data unless the firm offloads less relevant data from its data repository. Consequently, a firm's growth policy should incorporate a balance between the stock of historical data and the flow of new data. We complement our theoretical results with an experiment. In the experiment, we empirically measure the loss in the accuracy of a next word prediction model trained on datasets from various time periods. Our empirical measurements confirm the economic significance of the value decline over time. For example, 100MB of text data, after seven years, becomes as valuable as 50MB of current data for the next word prediction task.
Learning Detail-Structure Alternative Optimization for Blind Super-Resolution
Dec 03, 2022



Existing convolutional neural networks (CNN) based image super-resolution (SR) methods have achieved impressive performance on bicubic kernel, which is not valid to handle unknown degradations in real-world applications. Recent blind SR methods suggest to reconstruct SR images relying on blur kernel estimation. However, their results still remain visible artifacts and detail distortion due to the estimation errors. To alleviate these problems, in this paper, we propose an effective and kernel-free network, namely DSSR, which enables recurrent detail-structure alternative optimization without blur kernel prior incorporation for blind SR. Specifically, in our DSSR, a detail-structure modulation module (DSMM) is built to exploit the interaction and collaboration of image details and structures. The DSMM consists of two components: a detail restoration unit (DRU) and a structure modulation unit (SMU). The former aims at regressing the intermediate HR detail reconstruction from LR structural contexts, and the latter performs structural contexts modulation conditioned on the learned detail maps at both HR and LR spaces. Besides, we use the output of DSMM as the hidden state and design our DSSR architecture from a recurrent convolutional neural network (RCNN) view. In this way, the network can alternatively optimize the image details and structural contexts, achieving co-optimization across time. Moreover, equipped with the recurrent connection, our DSSR allows low- and high-level feature representations complementary by observing previous HR details and contexts at every unrolling time. Extensive experiments on synthetic datasets and real-world images demonstrate that our method achieves the state-of-the-art against existing methods. The source code can be found at https://github.com/Arcananana/DSSR.
Upper Bounds for Continuous-Time End-to-End Risks in Stochastic Robot Navigation
May 17, 2022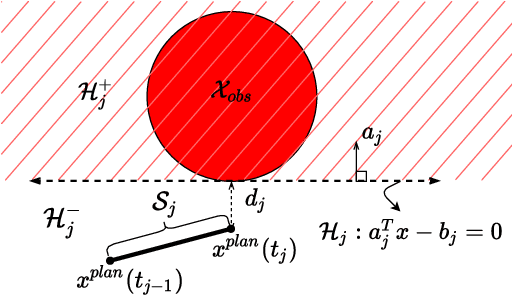
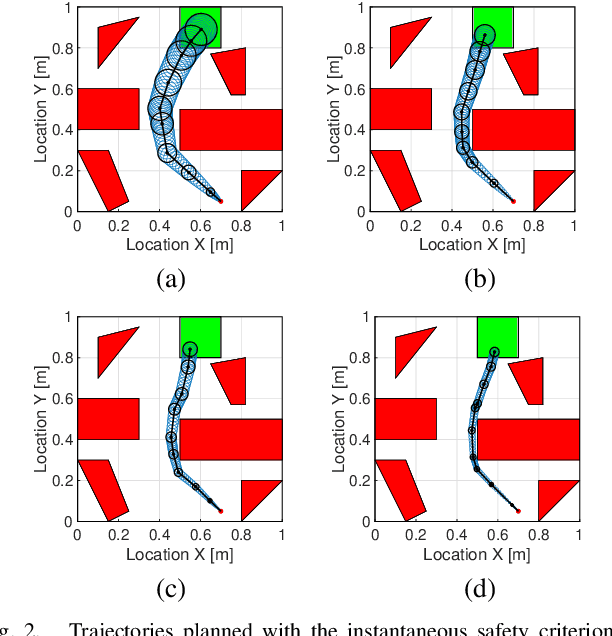
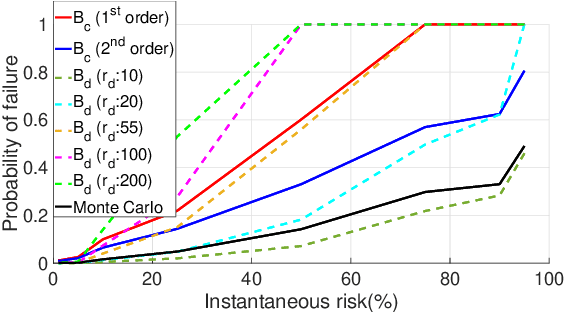
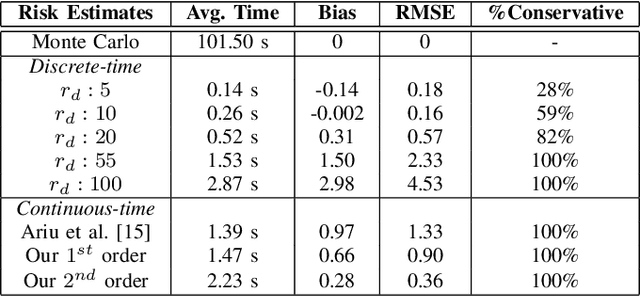
We present an analytical method to estimate the continuous-time collision probability of motion plans for autonomous agents with linear controlled Ito dynamics. Motion plans generated by planning algorithms cannot be perfectly executed by autonomous agents in reality due to the inherent uncertainties in the real world. Estimating end-to-end risk is crucial to characterize the safety of trajectories and plan risk optimal trajectories. In this paper, we derive upper bounds for the continuous-time risk in stochastic robot navigation using the properties of Brownian motion as well as Boole and Hunter's inequalities from probability theory. Using a ground robot navigation example, we numerically demonstrate that our method is considerably faster than the naive Monte Carlo sampling method and the proposed bounds perform better than the discrete-time risk bounds.
Personalized Execution Time Optimization for the Scheduled Jobs
Mar 11, 2022
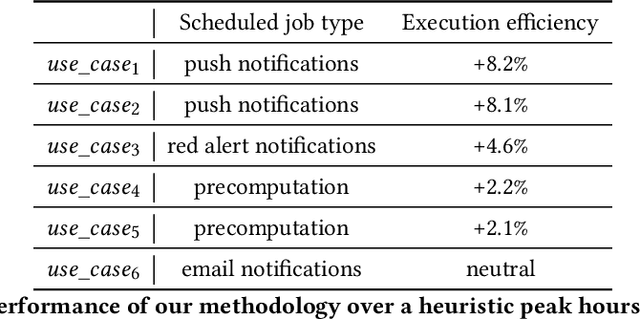
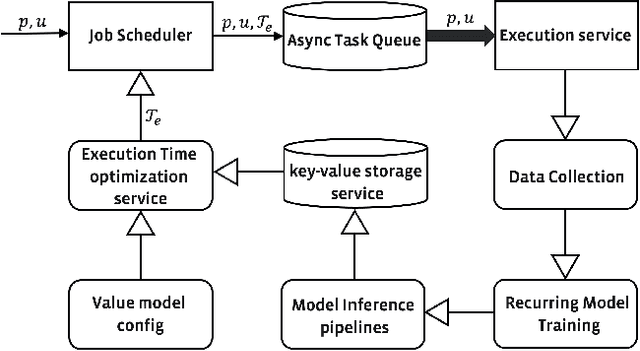

Scheduled batch jobs have been widely used on the asynchronous computing platforms to execute various enterprise applications, including the scheduled notifications and the candidate computation for the modern recommender systems. It is important to deliver or update the information to the users at the right time to maintain the user experience and the execution impact. However, it is challenging to provide a versatile execution time optimization solution for the user-basis scheduled jobs to satisfy various product scenarios while maintaining reasonable infrastructure resource consumption. In this paper, we describe how we apply a pointwise learning-to-rank approach plus a "best time policy" in the best time selection. In addition, we propose a value model approach to efficiently leverage multiple streams of user activity signals in our scheduling decisions of the execution time. Our optimization approach has been successfully tested with production traffic that serves billions of users per day, with statistically significant improvements in various product metrics, including the notifications and content candidate generation. To the best of our knowledge, our study represents the first ML-based multi-tenant solution to the execution time optimization problem for the scheduled jobs at a large industrial scale.
Sketch3T: Test-Time Training for Zero-Shot SBIR
Mar 28, 2022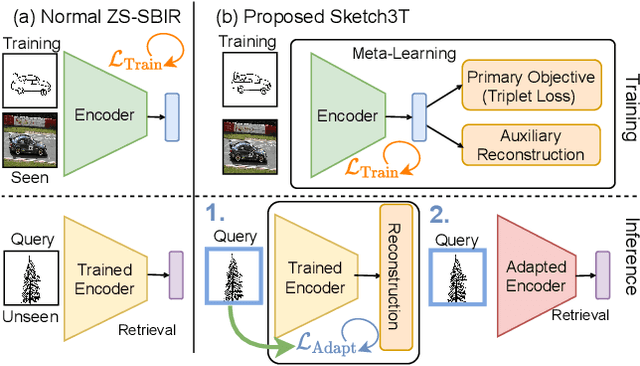
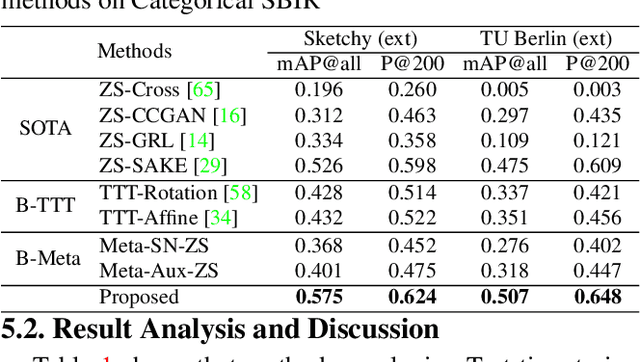
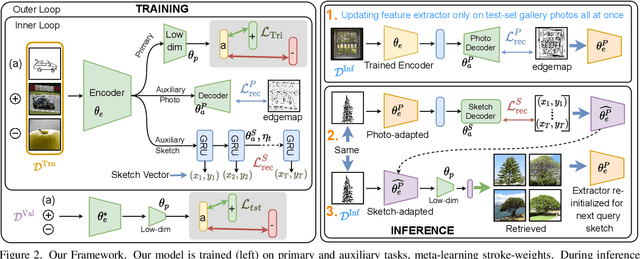
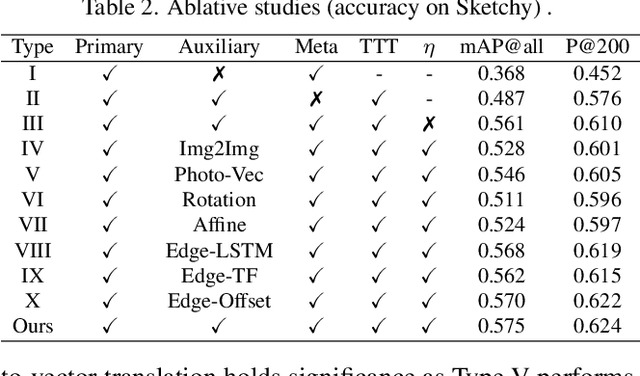
Zero-shot sketch-based image retrieval typically asks for a trained model to be applied as is to unseen categories. In this paper, we question to argue that this setup by definition is not compatible with the inherent abstract and subjective nature of sketches, i.e., the model might transfer well to new categories, but will not understand sketches existing in different test-time distribution as a result. We thus extend ZS-SBIR asking it to transfer to both categories and sketch distributions. Our key contribution is a test-time training paradigm that can adapt using just one sketch. Since there is no paired photo, we make use of a sketch raster-vector reconstruction module as a self-supervised auxiliary task. To maintain the fidelity of the trained cross-modal joint embedding during test-time update, we design a novel meta-learning based training paradigm to learn a separation between model updates incurred by this auxiliary task from those off the primary objective of discriminative learning. Extensive experiments show our model to outperform state of-the-arts, thanks to the proposed test-time adaption that not only transfers to new categories but also accommodates to new sketching styles.
Understanding Postpartum Parents' Experiences via Two Digital Platforms
Dec 22, 2022
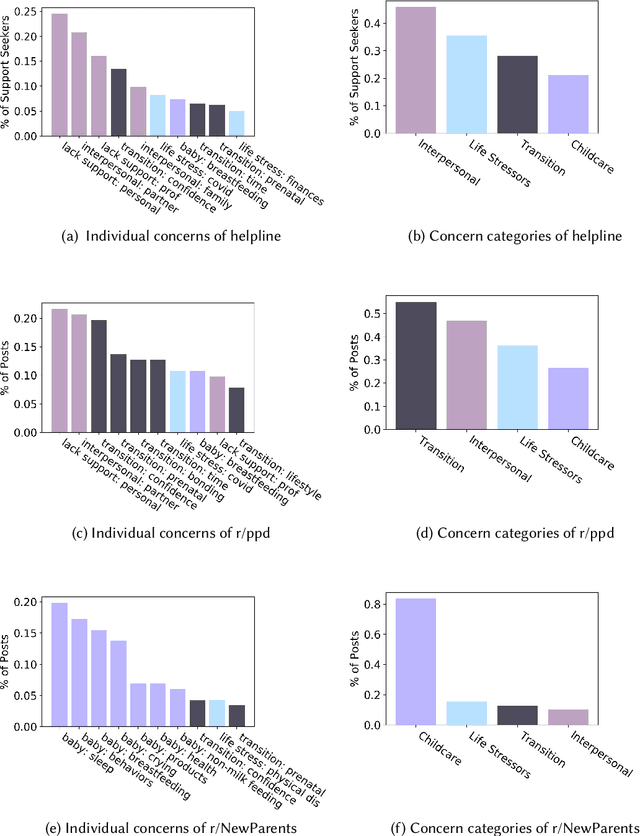
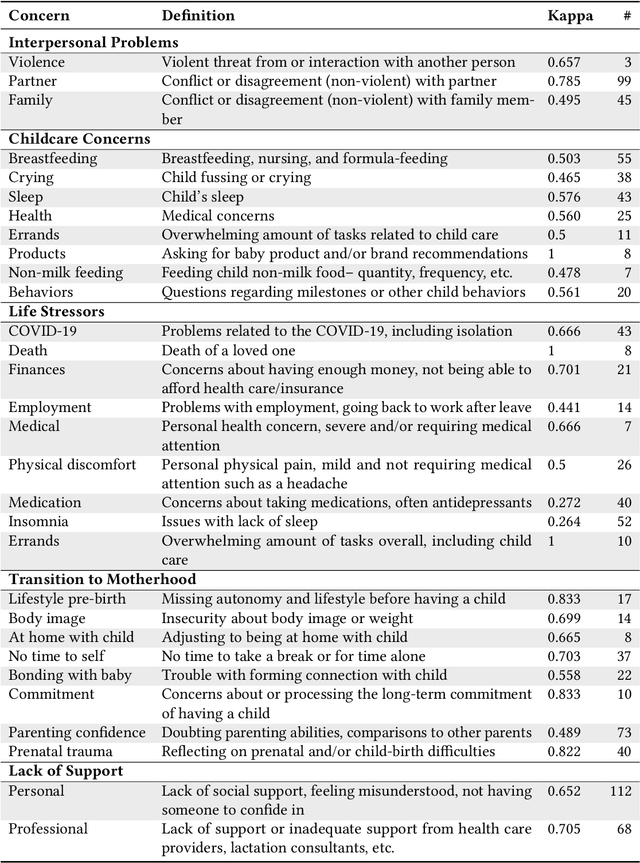
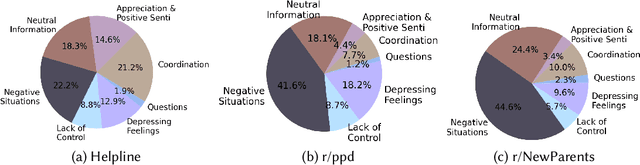
Digital platforms, including online forums and helplines, have emerged as avenues of support for caregivers suffering from postpartum mental health distress. Understanding support seekers' experiences as shared on these platforms could provide crucial insight into caregivers' needs during this vulnerable time. In the current work, we provide a descriptive analysis of the concerns, psychological states, and motivations shared by healthy and distressed postpartum support seekers on two digital platforms, a one-on-one digital helpline and a publicly available online forum. Using a combination of human annotations, dictionary models and unsupervised techniques, we find stark differences between the experiences of distressed and healthy mothers. Distressed mothers described interpersonal problems and a lack of support, with 8.60% - 14.56% reporting severe symptoms including suicidal ideation. In contrast, the majority of healthy mothers described childcare issues, such as questions about breastfeeding or sleeping, and reported no severe mental health concerns. Across the two digital platforms, we found that distressed mothers shared similar content. However, the patterns of speech and affect shared by distressed mothers differed between the helpline vs. the online forum, suggesting the design of these platforms may shape meaningful measures of their support-seeking experiences. Our results provide new insight into the experiences of caregivers suffering from postpartum mental health distress. We conclude by discussing methodological considerations for understanding content shared by support seekers and design considerations for the next generation of support tools for postpartum parents.
Decoding surface codes with deep reinforcement learning and probabilistic policy reuse
Dec 22, 2022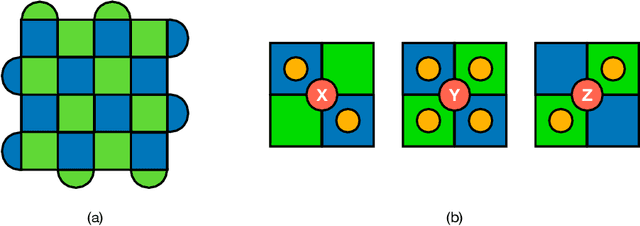
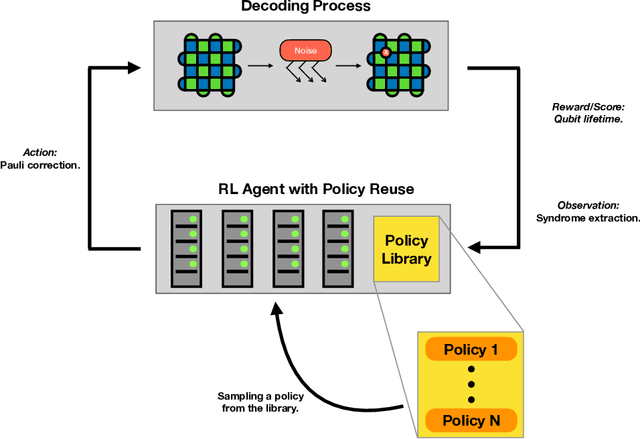
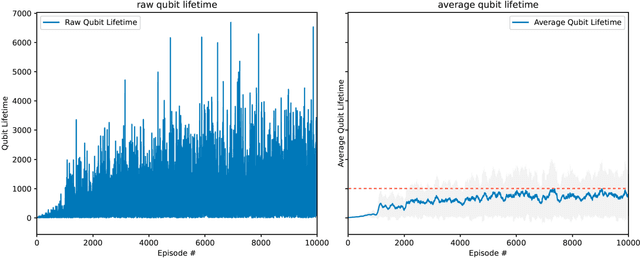
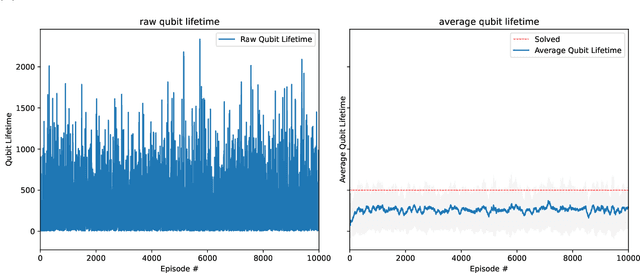
Quantum computing (QC) promises significant advantages on certain hard computational tasks over classical computers. However, current quantum hardware, also known as noisy intermediate-scale quantum computers (NISQ), are still unable to carry out computations faithfully mainly because of the lack of quantum error correction (QEC) capability. A significant amount of theoretical studies have provided various types of QEC codes; one of the notable topological codes is the surface code, and its features, such as the requirement of only nearest-neighboring two-qubit control gates and a large error threshold, make it a leading candidate for scalable quantum computation. Recent developments of machine learning (ML)-based techniques especially the reinforcement learning (RL) methods have been applied to the decoding problem and have already made certain progress. Nevertheless, the device noise pattern may change over time, making trained decoder models ineffective. In this paper, we propose a continual reinforcement learning method to address these decoding challenges. Specifically, we implement double deep Q-learning with probabilistic policy reuse (DDQN-PPR) model to learn surface code decoding strategies for quantum environments with varying noise patterns. Through numerical simulations, we show that the proposed DDQN-PPR model can significantly reduce the computational complexity. Moreover, increasing the number of trained policies can further improve the agent's performance. Our results open a way to build more capable RL agents which can leverage previously gained knowledge to tackle QEC challenges.