 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DLTTA: Dynamic Learning Rate for Test-time Adaptation on Cross-domain Medical Images
May 27, 2022
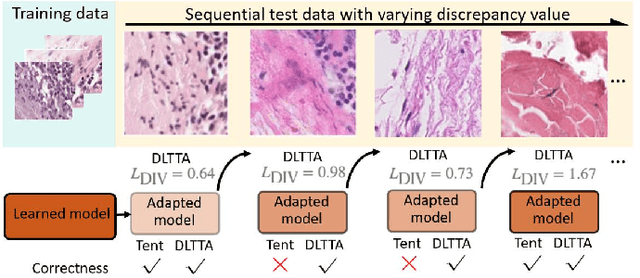
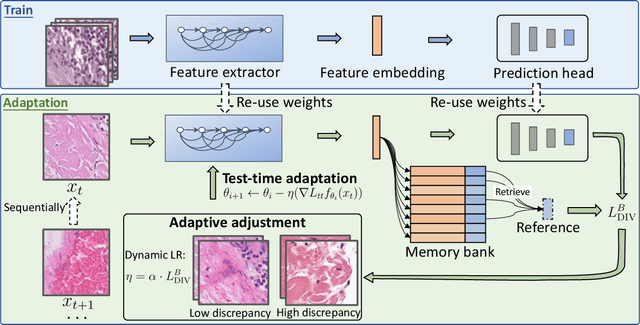
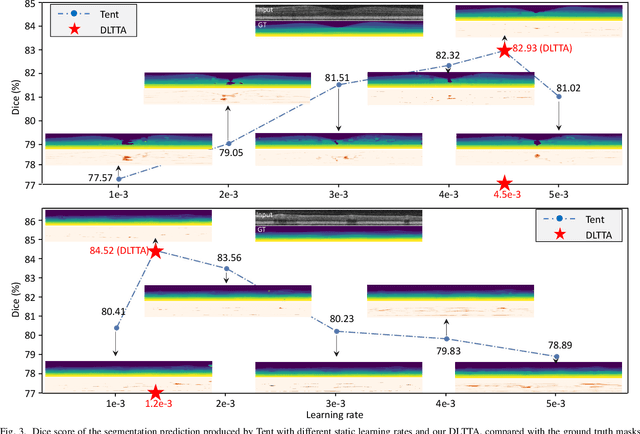
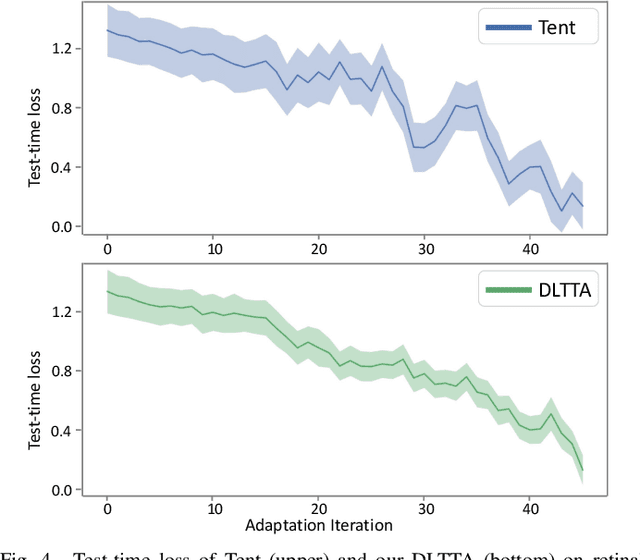
Test-time adaptation (TTA) has increasingly been an important topic to efficiently tackle the cross-domain distribution shift at test time for medical images from different institutions. Previous TTA methods have a common limitation of using a fixed learning rate for all the test samples. Such a practice would be sub-optimal for TTA, because test data may arrive sequentially therefore the scale of distribution shift would change frequently. To address this problem, we propose a novel dynamic learning rate adjustment method for test-time adaptation, called DLTTA, which dynamically modulates the amount of weights update for each test image to account for the differences in their distribution shift. Specifically, our DLTTA is equipped with a memory bank based estimation scheme to effectively measure the discrepancy of a given test sample. Based on this estimated discrepancy, a dynamic learning rate adjustment strategy is then developed to achieve a suitable degree of adaptation for each test sample. The effectiveness and general applicability of our DLTTA is extensively demonstrated on three tasks including retinal optical coherence tomography (OCT) segmentation, histopathological image classification, and prostate 3D MRI segmentation. Our method achieves effective and fast test-time adaptation with consistent performance improvement over current state-of-the-art test-time adaptation methods. Code is available at: https://github.com/med-air/DLTTA.
D2DF2WOD: Learning Object Proposals for Weakly-Supervised Object Detection via Progressive Domain Adaptation
Dec 02, 2022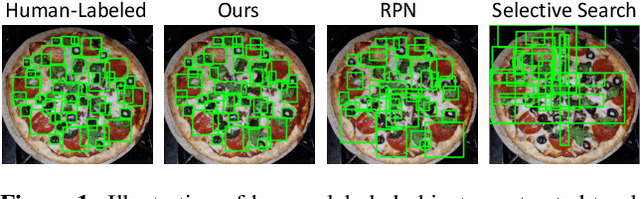
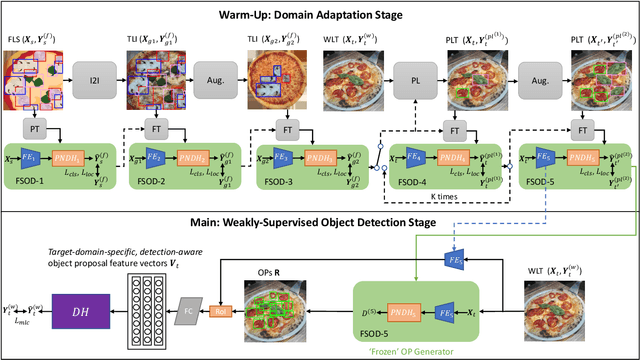


Weakly-supervised object detection (WSOD) models attempt to leverage image-level annotations in lieu of accurate but costly-to-obtain object localization labels. This oftentimes leads to substandard object detection and localization at inference time. To tackle this issue, we propose D2DF2WOD, a Dual-Domain Fully-to-Weakly Supervised Object Detection framework that leverages synthetic data, annotated with precise object localization, to supplement a natural image target domain, where only image-level labels are available. In its warm-up domain adaptation stage, the model learns a fully-supervised object detector (FSOD) to improve the precision of the object proposals in the target domain, and at the same time learns target-domain-specific and detection-aware proposal features. In its main WSOD stage, a WSOD model is specifically tuned to the target domain. The feature extractor and the object proposal generator of the WSOD model are built upon the fine-tuned FSOD model. We test D2DF2WOD on five dual-domain image benchmarks. The results show that our method results in consistently improved object detection and localization compared with state-of-the-art methods.
Cross-Modality Image Registration using a Training-Time Privileged Third Modality
Jul 26, 2022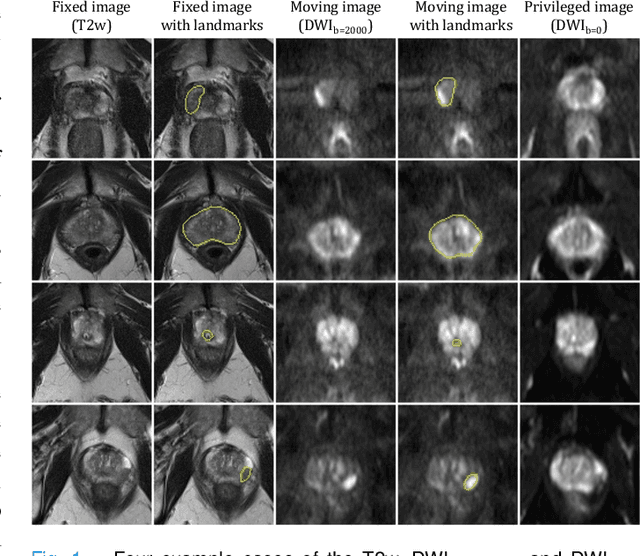
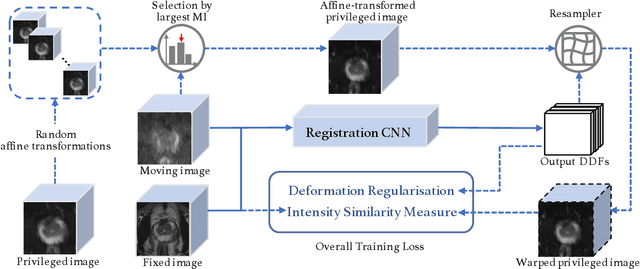
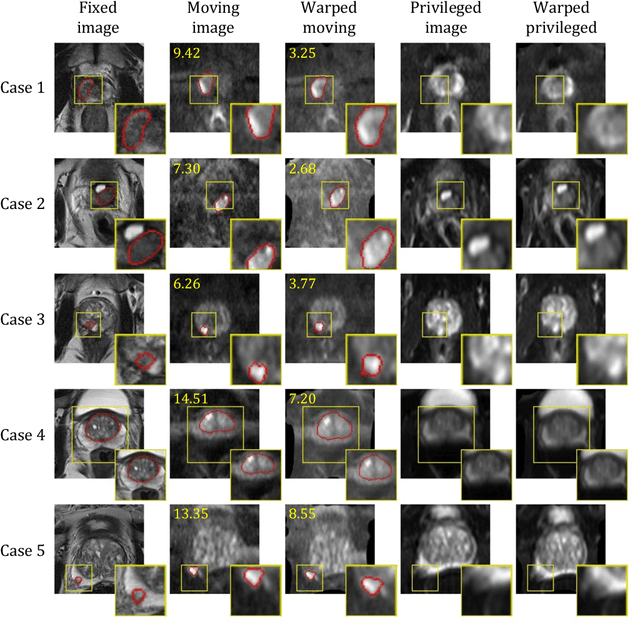
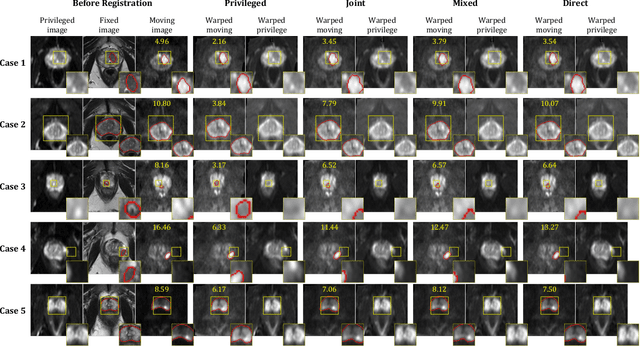
In this work, we consider the task of pairwise cross-modality image registration, which may benefit from exploiting additional images available only at training time from an additional modality that is different to those being registered. As an example, we focus on aligning intra-subject multiparametric Magnetic Resonance (mpMR) images, between T2-weighted (T2w) scans and diffusion-weighted scans with high b-value (DWI$_{high-b}$). For the application of localising tumours in mpMR images, diffusion scans with zero b-value (DWI$_{b=0}$) are considered easier to register to T2w due to the availability of corresponding features. We propose a learning from privileged modality algorithm, using a training-only imaging modality DWI$_{b=0}$, to support the challenging multi-modality registration problems. We present experimental results based on 369 sets of 3D multiparametric MRI images from 356 prostate cancer patients and report, with statistical significance, a lowered median target registration error of 4.34 mm, when registering the holdout DWI$_{high-b}$ and T2w image pairs, compared with that of 7.96 mm before registration. Results also show that the proposed learning-based registration networks enabled efficient registration with comparable or better accuracy, compared with a classical iterative algorithm and other tested learning-based methods with/without the additional modality. These compared algorithms also failed to produce any significantly improved alignment between DWI$_{high-b}$ and T2w in this challenging application.
POCS-based framework of signal reconstruction from generalized non-uniform samples
Dec 10, 2022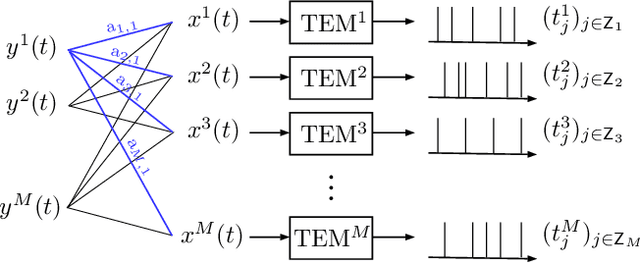
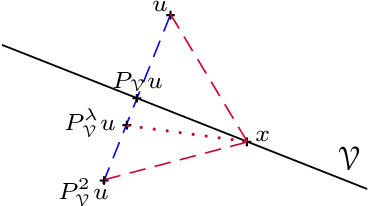
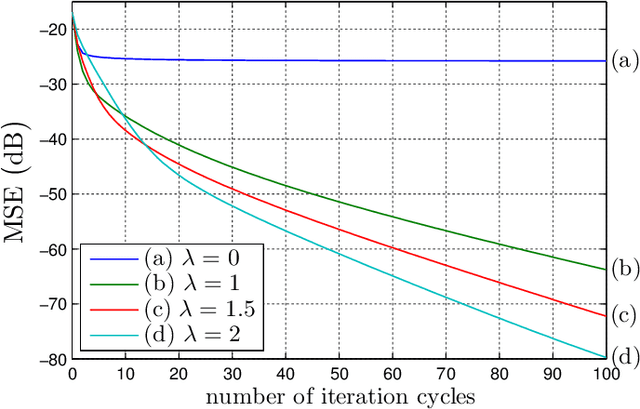
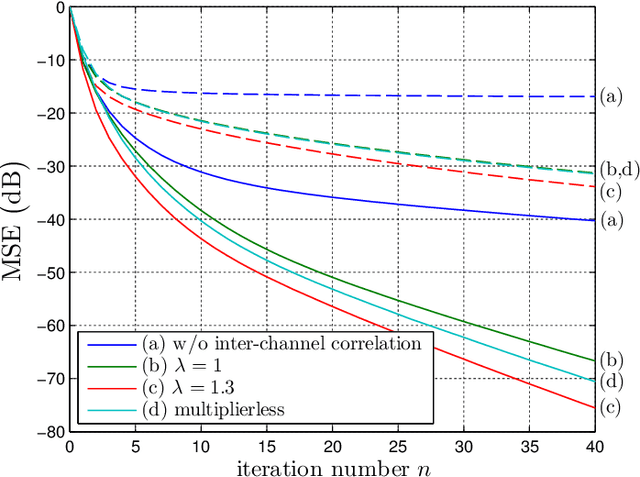
We formalize the use of projections onto convex sets (POCS) for the reconstruction of signals from non-uniform samples in their highest generality. This covers signals in any Hilbert space $\mathscr H$, including multi-dimensional and multi-channel signals, and samples that are most generally inner products of the signals with given kernel functions in $\mathscr H$. An attractive feature of the POCS method is the unconditional convergence of its iterates to an estimate that is consistent with the samples of the input, even when these samples are of very heterogeneous nature on top of their non-uniformity, and/or under insufficient sampling. Moreover, the error of the iterates is systematically monotonically decreasing, and their limit retrieves the input signal whenever the samples are uniquely characteristic of this signal. In the second part of the paper, we focus on the case where the sampling kernel functions are orthogonal in $\mathscr H$, while the input may be confined in a smaller closed space $\mathscr A$ (of bandlimitation for example). This covers the increasingly popular application of time encoding by integration, including multi-channel encoding. We push the analysis of the POCS method in this case by giving a special parallelized version of it, showing its connection with the pseudo-inversion of the linear operator defined by the samples, and giving a multiplierless discrete-time implementation of it that paradoxically accelerates the convergence of the iteration.
DeepJoin: Joinable Table Discovery with Pre-trained Language Models
Dec 15, 2022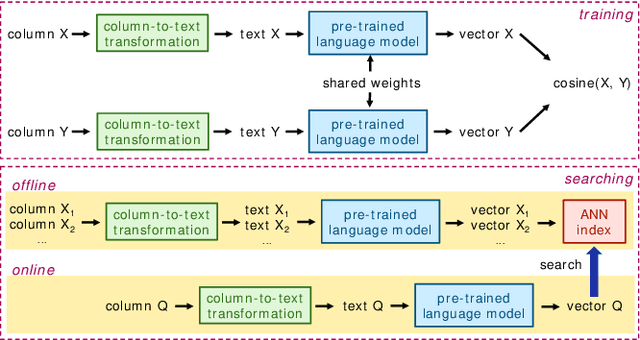

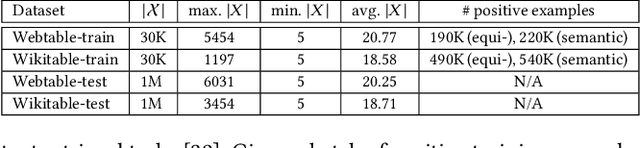
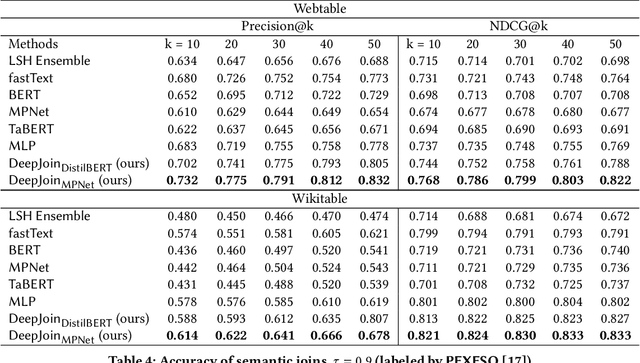
Due to the usefulness in data enrichment for data analysis tasks, joinable table discovery has become an important operation in data lake management. Existing approaches target equi-joins, the most common way of combining tables for creating a unified view, or semantic joins, which tolerate misspellings and different formats to deliver more join results. They are either exact solutions whose running time is linear in the sizes of query column and target table repository or approximate solutions lacking precision. In this paper, we propose Deepjoin, a deep learning model for accurate and efficient joinable table discovery. Our solution is an embedding-based retrieval, which employs a pre-trained language model (PLM) and is designed as one framework serving both equi- and semantic joins. We propose a set of contextualization options to transform column contents to a text sequence. The PLM reads the sequence and is fine-tuned to embed columns to vectors such that columns are expected to be joinable if they are close to each other in the vector space. Since the output of the PLM is fixed in length, the subsequent search procedure becomes independent of the column size. With a state-of-the-art approximate nearest neighbor search algorithm, the search time is logarithmic in the repository size. To train the model, we devise the techniques for preparing training data as well as data augmentation. The experiments on real datasets demonstrate that by training on a small subset of a corpus, Deepjoin generalizes to large datasets and its precision consistently outperforms other approximate solutions'. Deepjoin is even more accurate than an exact solution to semantic joins when evaluated with labels from experts. Moreover, when equipped with a GPU, Deepjoin is up to two orders of magnitude faster than existing solutions.
RT-DNAS: Real-time Constrained Differentiable Neural Architecture Search for 3D Cardiac Cine MRI Segmentation
Jun 13, 2022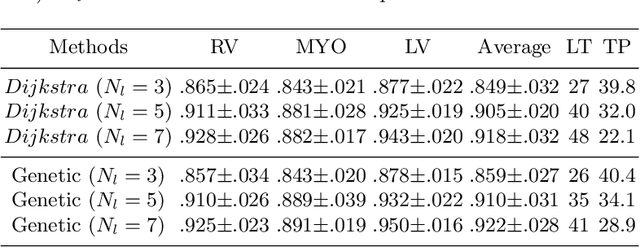

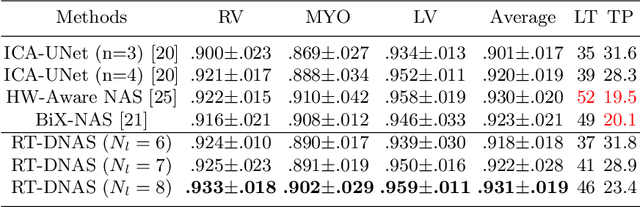
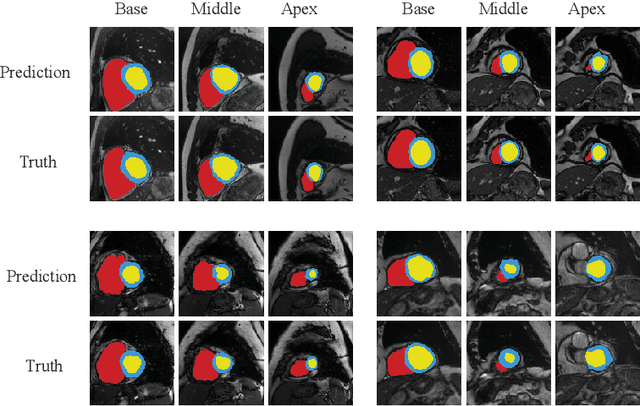
Accurately segmenting temporal frames of cine magnetic resonance imaging (MRI) is a crucial step in various real-time MRI guided cardiac interventions. To achieve fast and accurate visual assistance, there are strict requirements on the maximum latency and minimum throughput of the segmentation framework. State-of-the-art neural networks on this task are mostly hand-crafted to satisfy these constraints while achieving high accuracy. On the other hand, while existing literature have demonstrated the power of neural architecture search (NAS) in automatically identifying the best neural architectures for various medical applications, they are mostly guided by accuracy, sometimes with computation complexity, and the importance of real-time constraints are overlooked. A major challenge is that such constraints are non-differentiable and are thus not compatible with the widely used differentiable NAS frameworks. In this paper, we present a strategy that directly handles real-time constraints in a differentiable NAS framework named RT-DNAS. Experiments on extended 2017 MICCAI ACDC dataset show that compared with state-of-the-art manually and automatically designed architectures, RT-DNAS is able to identify ones with better accuracy while satisfying the real-time constraints.
Neural Network Verification as Piecewise Linear Optimization: Formulations for the Composition of Staircase Functions
Nov 27, 2022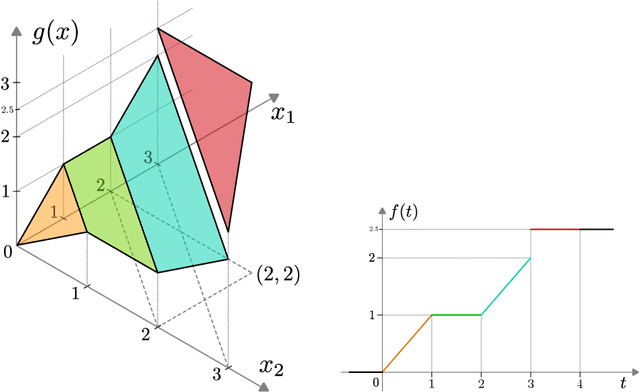
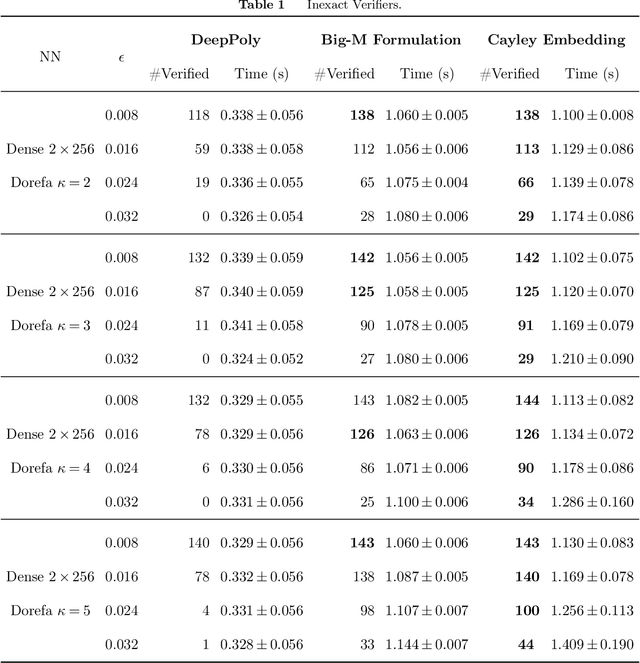
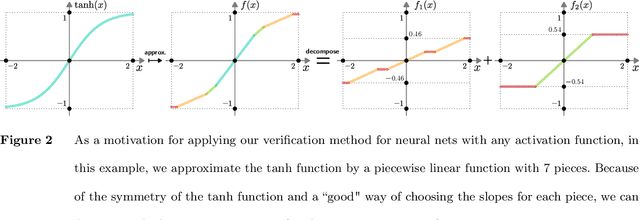
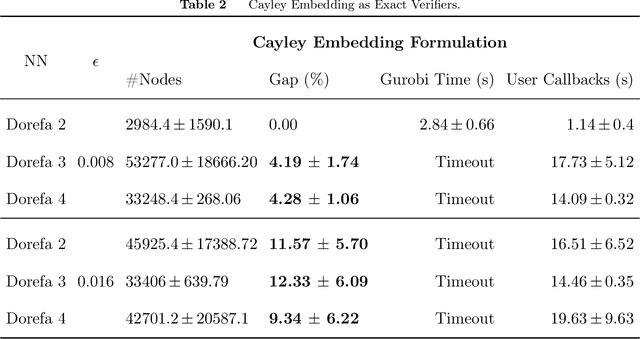
We present a technique for neural network verification using mixed-integer programming (MIP) formulations. We derive a \emph{strong formulation} for each neuron in a network using piecewise linear activation functions. Additionally, as in general, these formulations may require an exponential number of inequalities, we also derive a separation procedure that runs in super-linear time in the input dimension. We first introduce and develop our technique on the class of \emph{staircase} functions, which generalizes the ReLU, binarized, and quantized activation functions. We then use results for staircase activation functions to obtain a separation method for general piecewise linear activation functions. Empirically, using our strong formulation and separation technique, we can reduce the computational time in exact verification settings based on MIP and improve the false negative rate for inexact verifiers relying on the relaxation of the MIP formulation.
Efficient Automated Deep Learning for Time Series Forecasting
May 13, 2022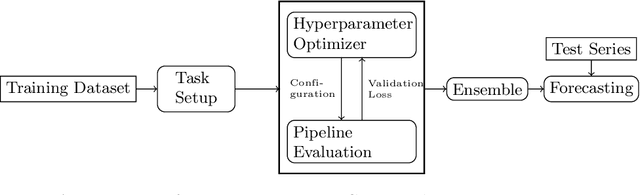
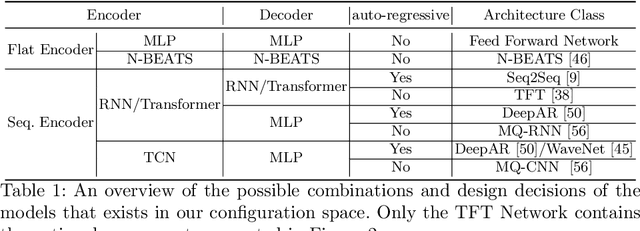
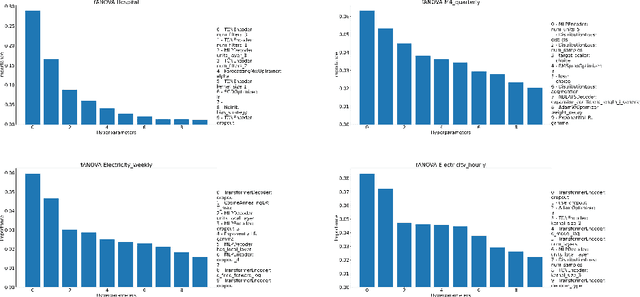
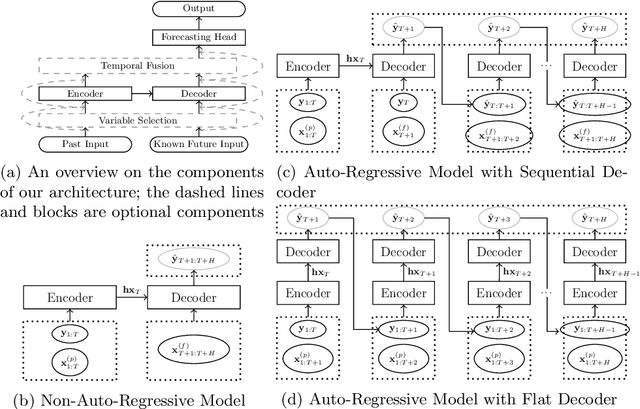
Recent years have witnessed tremendously improved efficiency of Automated Machine Learning (AutoML), especially Automated Deep Learning (AutoDL) systems, but recent work focuses on tabular, image, or NLP tasks. So far, little attention has been paid to general AutoDL frameworks for time series forecasting, despite the enormous success in applying different novel architectures to such tasks. In this paper, we propose an efficient approach for the joint optimization of neural architecture and hyperparameters of the entire data processing pipeline for time series forecasting. In contrast to common NAS search spaces, we designed a novel neural architecture search space covering various state-of-the-art architectures, allowing for an efficient macro-search over different DL approaches. To efficiently search in such a large configuration space, we use Bayesian optimization with multi-fidelity optimization. We empirically study several different budget types enabling efficient multi-fidelity optimization on different forecasting datasets. Furthermore, we compared our resulting system, dubbed Auto-PyTorch-TS, against several established baselines and show that it significantly outperforms all of them across several datasets.
E-TRoll: Tactile Sensing and Classification via A Simple Robotic Gripper for Extended Rolling Manipulations
Dec 08, 2022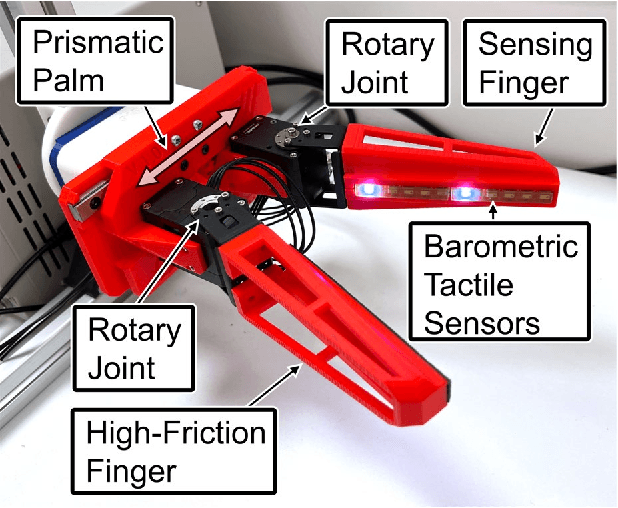
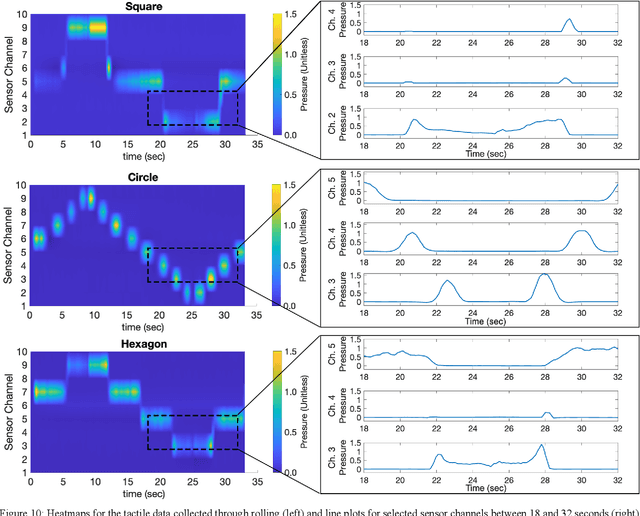
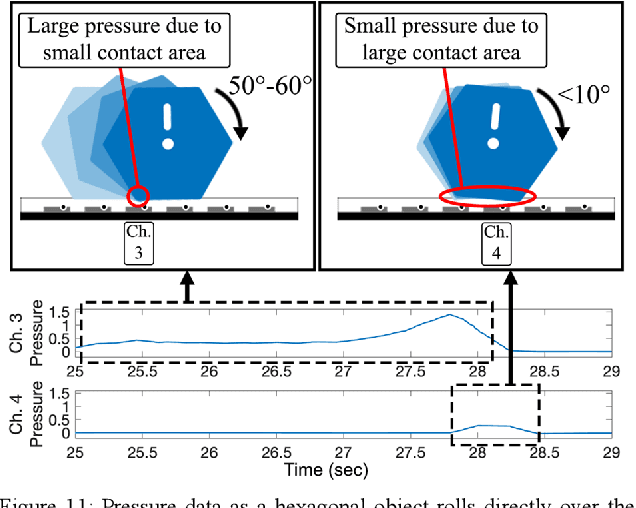
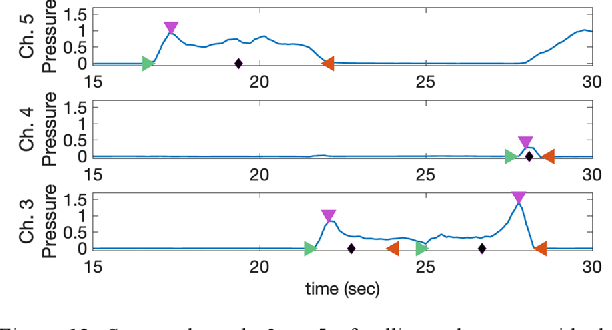
Robotic tactile sensing provides a method of recognizing objects and their properties where vision fails. Prior work on tactile perception in robotic manipulation has frequently focused on exploratory procedures (EPs). However, the also-human-inspired technique of in-hand-manipulation can glean rich data in a fraction of the time of EPs. We propose a simple 3-DOF robotic hand design, optimized for object rolling tasks via a variable-width palm and associated control system. This system dynamically adjusts the distance between the finger bases in response to object behavior. Compared to fixed finger bases, this technique significantly increases the area of the object that is exposed to finger-mounted tactile arrays during a single rolling motion (an increase of over 60% was observed for a cylinder with a 30-millimeter diameter). In addition, this paper presents a feature extraction algorithm for the collected spatiotemporal dataset, which focuses on object corner identification, analysis, and compact representation. This technique drastically reduces the dimensionality of each data sample from 10 x 1500 time series data to 80 features, which was further reduced by Principal Component Analysis (PCA) to 22 components. An ensemble subspace k-nearest neighbors (KNN) classification model was trained with 90 observations on rolling three different geometric objects, resulting in a three-fold cross-validation accuracy of 95.6% for object shape recognition.
FiDO: Fusion-in-Decoder optimized for stronger performance and faster inference
Dec 15, 2022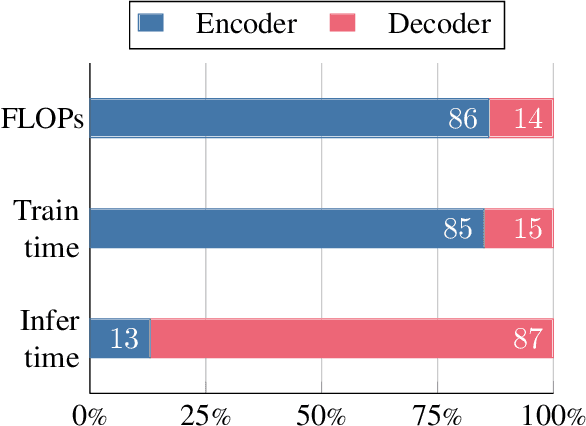

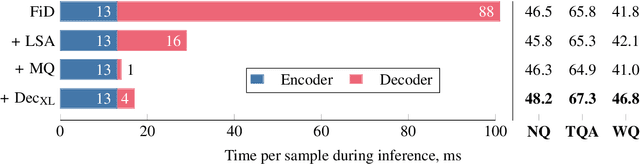
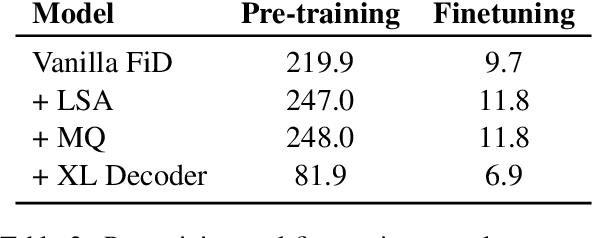
Fusion-in-Decoder (FiD) is a powerful retrieval-augmented language model that sets the state-of-the-art on many knowledge-intensive NLP tasks. However, FiD suffers from very expensive inference. We show that the majority of inference time results from memory bandwidth constraints in the decoder, and propose two simple changes to the FiD architecture to speed up inference by 7x. The faster decoder inference then allows for a much larger decoder. We denote FiD with the above modifications as FiDO, and show that it strongly improves performance over existing FiD models for a wide range of inference budgets. For example, FiDO-Large-XXL performs faster inference than FiD-Base and achieves better performance than FiD-Large.