 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Policy Transfer via Enhanced Action Space
Dec 07, 2022

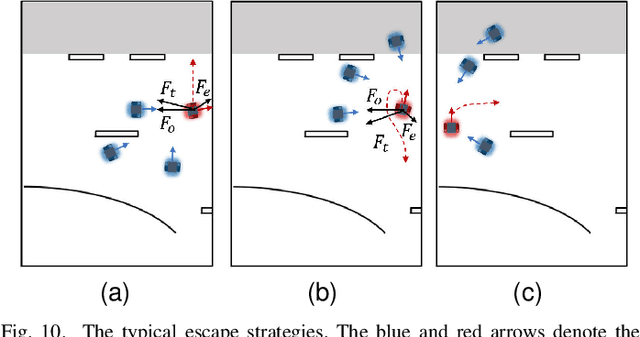
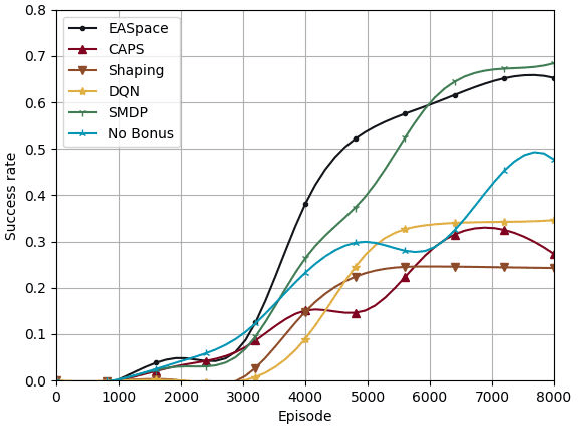
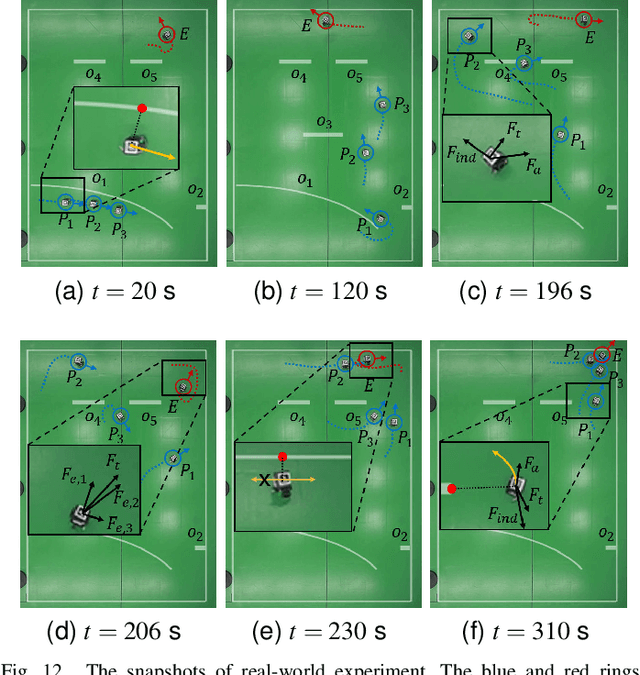
Though transfer learning is promising to increase the learning efficiency, the existing methods are still subject to the challenges from long-horizon tasks, especially when expert policies are sub-optimal and partially useful. Hence, a novel algorithm named EASpace (Enhanced Action Space) is proposed in this paper to transfer the knowledge of multiple sub-optimal expert policies. EASpace formulates each expert policy into multiple macro actions with different execution time period, then integrates all macro actions into the primitive action space directly. Through this formulation, the proposed EASpace could learn when to execute which expert policy and how long it lasts. An intra-macro-action learning rule is proposed by adjusting the temporal difference target of macro actions to improve the data efficiency and alleviate the non-stationarity issue in multi-agent settings. Furthermore, an additional reward proportional to the execution time of macro actions is introduced to encourage the environment exploration via macro actions, which is significant to learn a long-horizon task. Theoretical analysis is presented to show the convergence of the proposed algorithm. The efficiency of the proposed algorithm is illustrated by a grid-based game and a multi-agent pursuit problem. The proposed algorithm is also implemented to real physical systems to justify its effectiveness.
DeepSpeed Data Efficiency: Improving Deep Learning Model Quality and Training Efficiency via Efficient Data Sampling and Routing
Dec 07, 2022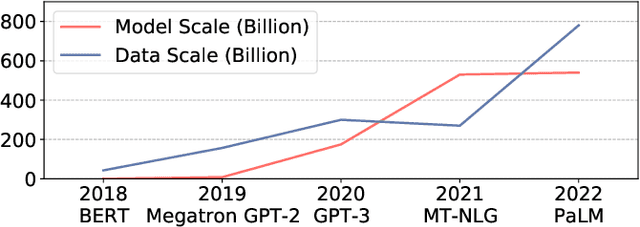
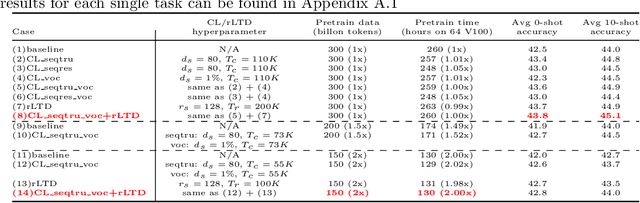

Recent advances on deep learning models come at the price of formidable training cost. The increasing model size is one of the root cause, but another less-emphasized fact is that data scale is actually increasing at a similar speed as model scale, and the training cost is proportional to both of them. Compared to the rapidly evolving model architecture, how to efficiently use the training data (especially for the expensive foundation model pertaining) is both less explored and difficult to realize due to the lack of a convenient framework that focus on data efficiency capabilities. To this end, we present DeepSpeed Data Efficiency library, a framework that makes better use of data, increases training efficiency, and improves model quality. Specifically, it provides efficient data sampling via curriculum learning, and efficient data routing via random layerwise token dropping. DeepSpeed Data Efficiency takes extensibility, flexibility and composability into consideration, so that users can easily utilize the framework to compose multiple techniques and apply customized strategies. By applying our solution to GPT-3 1.3B and BERT-Large language model pretraining, we can achieve similar model quality with up to 2x less data and 2x less time, or achieve better model quality under similar amount of data and time.
Energy Efficiency Optimization of Intelligent Reflective Surface-assisted Terahertz-RSMA System
Nov 21, 2022
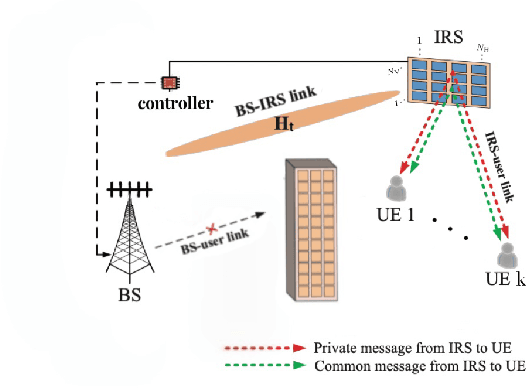

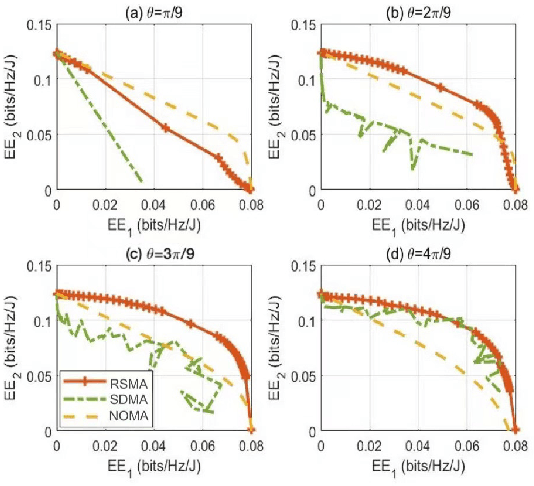
This paper examines the energy efficiency optimization problem of intelligent reflective surface (IRS)-assisted multi-user rate division multiple access (RSMA) downlink systems under terahertz propagation. The objective function for energy efficiency is optimized using the salp swarm algorithm (SSA) and compared with the successive convex approximation (SCA) technique. SCA technique requires multiple iterations to solve non-convex resource allocation problems, whereas SSA can consume less time to improve energy efficiency effectively. The simulation results show that SSA is better than SCA in improving system energy efficiency, and the time required is significantly reduced, thus optimizing the system's overall performance.
Understanding Decision-Time vs. Background Planning in Model-Based Reinforcement Learning
Jun 16, 2022
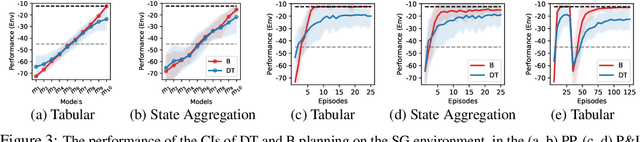
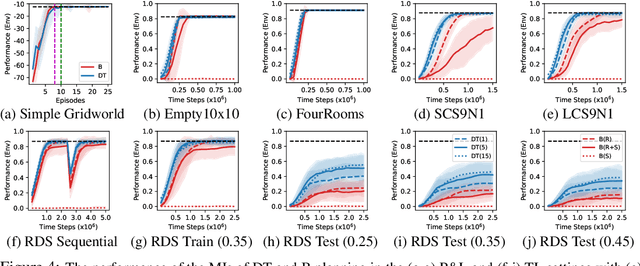
In model-based reinforcement learning, an agent can leverage a learned model to improve its way of behaving in different ways. Two prevalent approaches are decision-time planning and background planning. In this study, we are interested in understanding under what conditions and in which settings one of these two planning styles will perform better than the other in domains that require fast responses. After viewing them through the lens of dynamic programming, we first consider the classical instantiations of these planning styles and provide theoretical results and hypotheses on which one will perform better in the pure planning, planning & learning, and transfer learning settings. We then consider the modern instantiations of these planning styles and provide hypotheses on which one will perform better in the last two of the considered settings. Lastly, we perform several illustrative experiments to empirically validate both our theoretical results and hypotheses. Overall, our findings suggest that even though decision-time planning does not perform as well as background planning in their classical instantiations, in their modern instantiations, it can perform on par or better than background planning in both the planning & learning and transfer learning settings.
RIS-Assisted Receive Quadrature Spatial Modulation with Low-Complexity Greedy Detection
Jan 02, 2023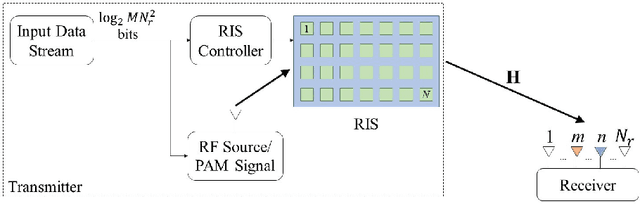
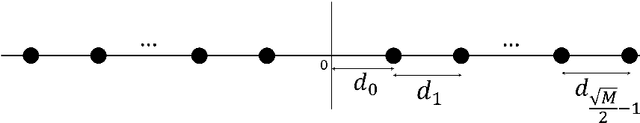
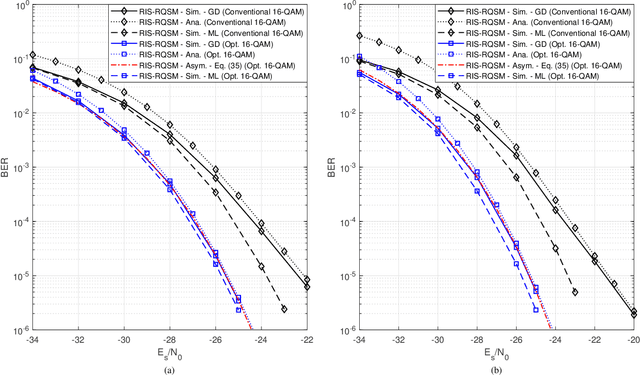
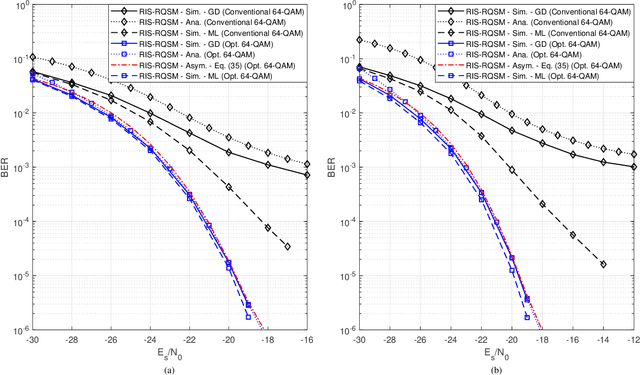
In this paper, we propose a novel reconfigurable intelligent surface (RIS)-assisted wireless communication scheme which uses the concept of spatial modulation, namely RIS-assisted receive quadrature spatial modulation (RIS-RQSM). In the proposed RIS-RQSM system, the information bits are conveyed via both the indices of the two selected receive antennas and the conventional in-phase/quadrature (IQ) modulation. We propose a novel methodology to adjust the phase shifts of the RIS elements in order to maximize the signal-to-noise ratio (SNR) and at the same time to construct two separate PAM symbols at the selected receive antennas, as the in-phase and quadrature components of the desired IQ symbol. An energy-based greedy detector (GD) is implemented at the receiver to efficiently detect the received signal with minimal channel state information (CSI) via the use of an appropriately designed one-tap pre-equalizer. We also derive a closed-form upper bound on the average bit error probability (ABEP) of the proposed RIS-RQSM system. Then, we formulate an optimization problem to minimize the ABEP in order to improve the performance of the system, which allows the GD to act as a near-optimal receiver. Extensive numerical results are provided to demonstrate the error rate performance of the system and to compare with that of a prominent benchmark scheme. The results verify the remarkable superiority of the proposed RIS-RQSM system over the benchmark scheme.
UNeRF: Time and Memory Conscious U-Shaped Network for Training Neural Radiance Fields
Jun 23, 2022
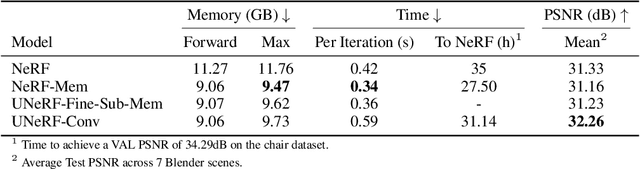
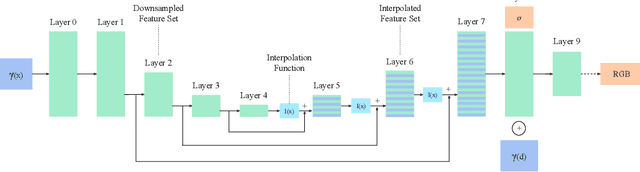

Neural Radiance Fields (NeRFs) increase reconstruction detail for novel view synthesis and scene reconstruction, with applications ranging from large static scenes to dynamic human motion. However, the increased resolution and model-free nature of such neural fields come at the cost of high training times and excessive memory requirements. Recent advances improve the inference time by using complementary data structures yet these methods are ill-suited for dynamic scenes and often increase memory consumption. Little has been done to reduce the resources required at training time. We propose a method to exploit the redundancy of NeRF's sample-based computations by partially sharing evaluations across neighboring sample points. Our UNeRF architecture is inspired by the UNet, where spatial resolution is reduced in the middle of the network and information is shared between adjacent samples. Although this change violates the strict and conscious separation of view-dependent appearance and view-independent density estimation in the NeRF method, we show that it improves novel view synthesis. We also introduce an alternative subsampling strategy which shares computation while minimizing any violation of view invariance. UNeRF is a plug-in module for the original NeRF network. Our major contributions include reduction of the memory footprint, improved accuracy, and reduced amortized processing time both during training and inference. With only weak assumptions on locality, we achieve improved resource utilization on a variety of neural radiance fields tasks. We demonstrate applications to the novel view synthesis of static scenes as well as dynamic human shape and motion.
Sub-quadratic Algorithms for Kernel Matrices via Kernel Density Estimation
Dec 01, 2022
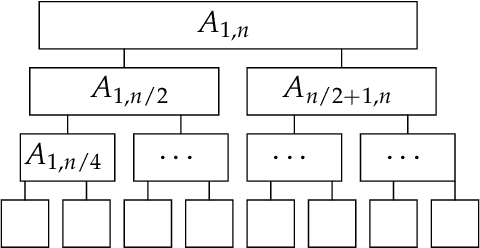

Kernel matrices, as well as weighted graphs represented by them, are ubiquitous objects in machine learning, statistics and other related fields. The main drawback of using kernel methods (learning and inference using kernel matrices) is efficiency -- given $n$ input points, most kernel-based algorithms need to materialize the full $n \times n$ kernel matrix before performing any subsequent computation, thus incurring $\Omega(n^2)$ runtime. Breaking this quadratic barrier for various problems has therefore, been a subject of extensive research efforts. We break the quadratic barrier and obtain $\textit{subquadratic}$ time algorithms for several fundamental linear-algebraic and graph processing primitives, including approximating the top eigenvalue and eigenvector, spectral sparsification, solving linear systems, local clustering, low-rank approximation, arboricity estimation and counting weighted triangles. We build on the recent Kernel Density Estimation framework, which (after preprocessing in time subquadratic in $n$) can return estimates of row/column sums of the kernel matrix. In particular, we develop efficient reductions from $\textit{weighted vertex}$ and $\textit{weighted edge sampling}$ on kernel graphs, $\textit{simulating random walks}$ on kernel graphs, and $\textit{importance sampling}$ on matrices to Kernel Density Estimation and show that we can generate samples from these distributions in $\textit{sublinear}$ (in the support of the distribution) time. Our reductions are the central ingredient in each of our applications and we believe they may be of independent interest. We empirically demonstrate the efficacy of our algorithms on low-rank approximation (LRA) and spectral sparsification, where we observe a $\textbf{9x}$ decrease in the number of kernel evaluations over baselines for LRA and a $\textbf{41x}$ reduction in the graph size for spectral sparsification.
Demand Layering for Real-Time DNN Inference with Minimized Memory Usage
Oct 08, 2022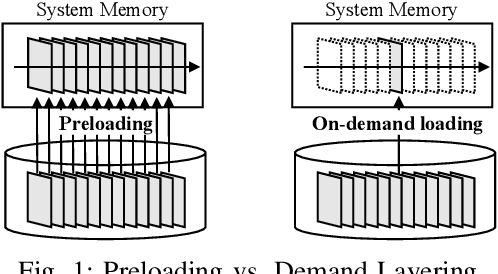
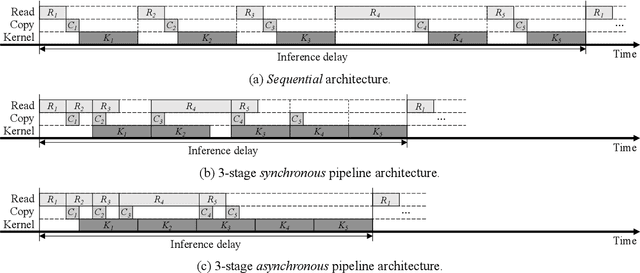
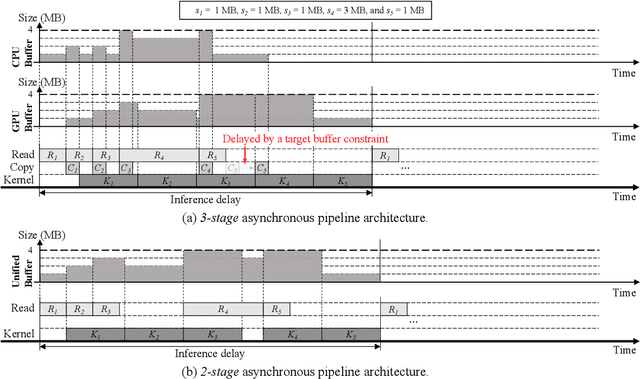
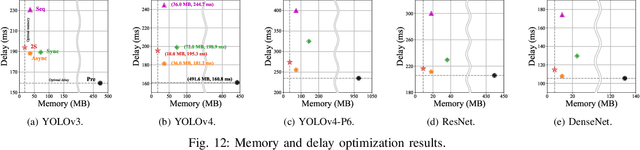
When executing a deep neural network (DNN), its model parameters are loaded into GPU memory before execution, incurring a significant GPU memory burden. There are studies that reduce GPU memory usage by exploiting CPU memory as a swap device. However, this approach is not applicable in most embedded systems with integrated GPUs where CPU and GPU share a common memory. In this regard, we present Demand Layering, which employs a fast solid-state drive (SSD) as a co-running partner of a GPU and exploits the layer-by-layer execution of DNNs. In our approach, a DNN is loaded and executed in a layer-by-layer manner, minimizing the memory usage to the order of a single layer. Also, we developed a pipeline architecture that hides most additional delays caused by the interleaved parameter loadings alongside layer executions. Our implementation shows a 96.5% memory reduction with just 14.8% delay overhead on average for representative DNNs. Furthermore, by exploiting the memory-delay tradeoff, near-zero delay overhead (under 1 ms) can be achieved with a slightly increased memory usage (still an 88.4% reduction), showing the great potential of Demand Layering.
Plant species richness prediction from DESIS hyperspectral data: A comparison study on feature extraction procedures and regression models
Jan 05, 2023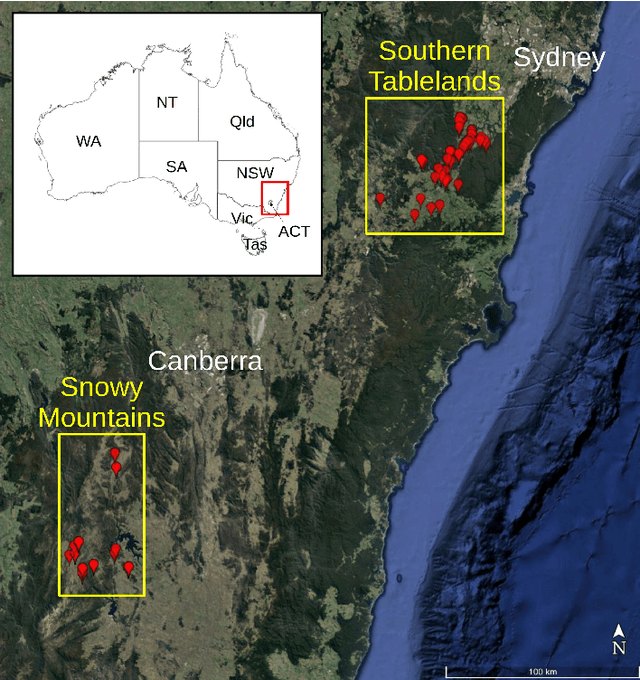
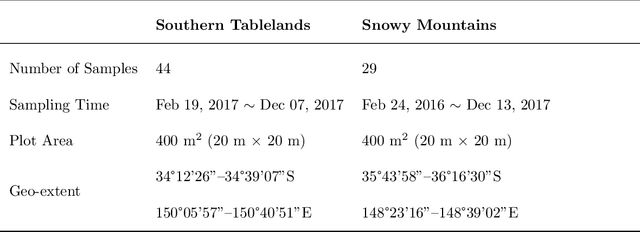
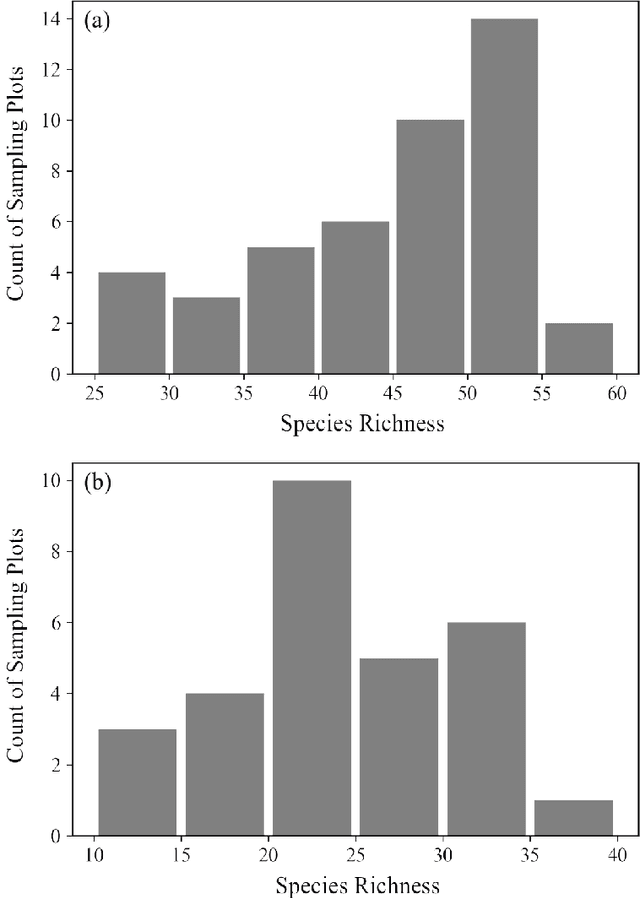
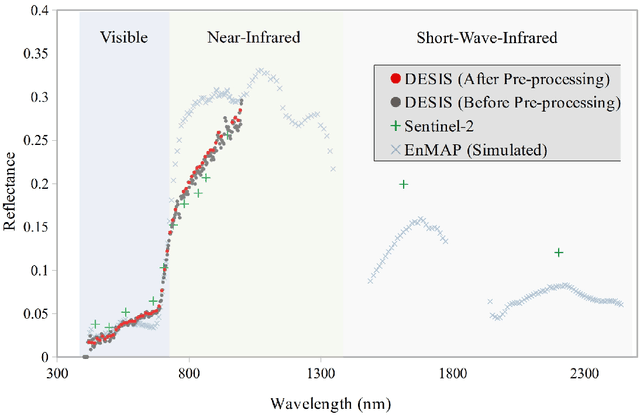
The diversity of terrestrial vascular plants plays a key role in maintaining the stability and productivity of ecosystems. Monitoring species compositional diversity across large spatial scales is challenging and time consuming. The advanced spectral and spatial specification of the recently launched DESIS (the DLR Earth Sensing Imaging Spectrometer) instrument provides a unique opportunity to test the potential for monitoring plant species diversity with spaceborne hyperspectral data. This study provides a quantitative assessment on the ability of DESIS hyperspectral data for predicting plant species richness in two different habitat types in southeast Australia. Spectral features were first extracted from the DESIS spectra, then regressed against on-ground estimates of plant species richness, with a two-fold cross validation scheme to assess the predictive performance. We tested and compared the effectiveness of Principal Component Analysis (PCA), Canonical Correlation Analysis (CCA), and Partial Least Squares analysis (PLS) for feature extraction, and Kernel Ridge Regression (KRR), Gaussian Process Regression (GPR), Random Forest Regression (RFR) for species richness prediction. The best prediction results were r=0.76 and RMSE=5.89 for the Southern Tablelands region, and r=0.68 and RMSE=5.95 for the Snowy Mountains region. Relative importance analysis for the DESIS spectral bands showed that the red-edge, red, and blue spectral regions were more important for predicting plant species richness than the green bands and the near-infrared bands beyond red-edge. We also found that the DESIS hyperspectral data performed better than Sentinel-2 multispectral data in the prediction of plant species richness. Our results provide a quantitative reference for future studies exploring the potential of spaceborne hyperspectral data for plant biodiversity mapping.
Demo: Real-Time Semantic Communications with a Vision Transformer
May 08, 2022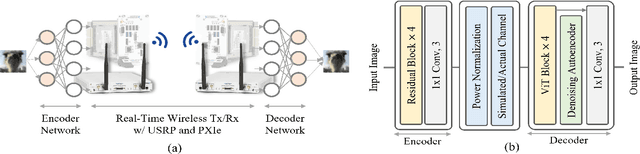
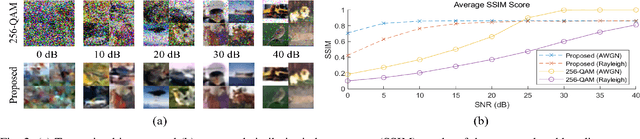
Semantic communications are expected to enable the more effective delivery of meaning rather than a precise transfer of symbols. In this paper, we propose an end-to-end deep neural network-based architecture for image transmission and demonstrate its feasibility in a real-time wireless channel by implementing a prototype based on a field-programmable gate array (FPGA). We demonstrate that this system outperforms the traditional 256-quadrature amplitude modulation system in the low signal-to-noise ratio regime with the popular CIFAR-10 dataset. To the best of our knowledge, this is the first work that implements and investigates real-time semantic communications with a vision transformer.