 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
Mar 12, 2024
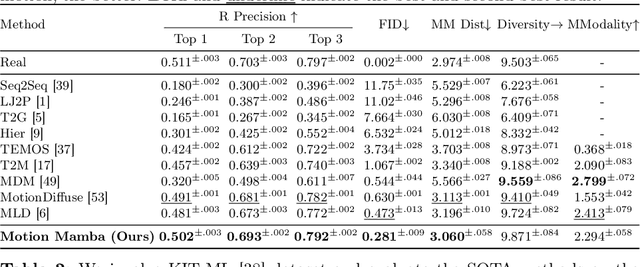
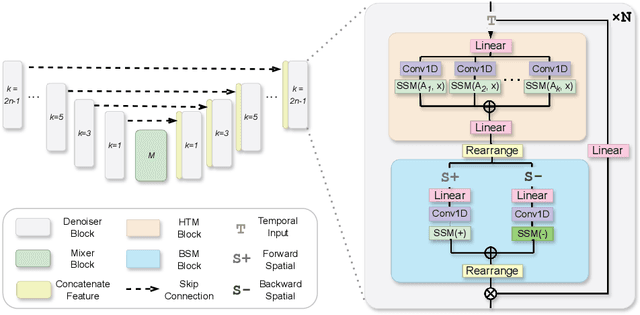
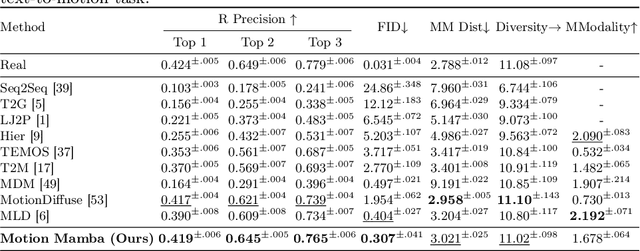
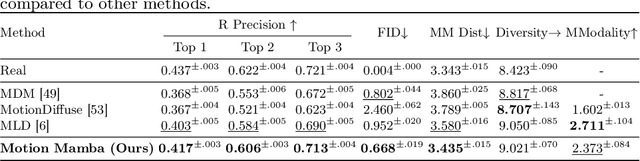
Human motion generation stands as a significant pursuit in generative computer vision, while achieving long-sequence and efficient motion generation remains challenging. Recent advancements in state space models (SSMs), notably Mamba, have showcased considerable promise in long sequence modeling with an efficient hardware-aware design, which appears to be a promising direction to build motion generation model upon it. Nevertheless, adapting SSMs to motion generation faces hurdles since the lack of a specialized design architecture to model motion sequence. To address these challenges, we propose Motion Mamba, a simple and efficient approach that presents the pioneering motion generation model utilized SSMs. Specifically, we design a Hierarchical Temporal Mamba (HTM) block to process temporal data by ensemble varying numbers of isolated SSM modules across a symmetric U-Net architecture aimed at preserving motion consistency between frames. We also design a Bidirectional Spatial Mamba (BSM) block to bidirectionally process latent poses, to enhance accurate motion generation within a temporal frame. Our proposed method achieves up to 50% FID improvement and up to 4 times faster on the HumanML3D and KIT-ML datasets compared to the previous best diffusion-based method, which demonstrates strong capabilities of high-quality long sequence motion modeling and real-time human motion generation. See project website https://steve-zeyu-zhang.github.io/MotionMamba/
Empowering Sequential Recommendation from Collaborative Signals and Semantic Relatedness
Mar 12, 2024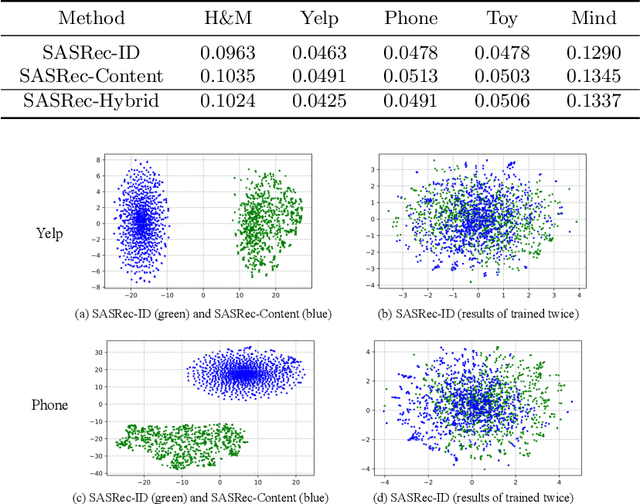
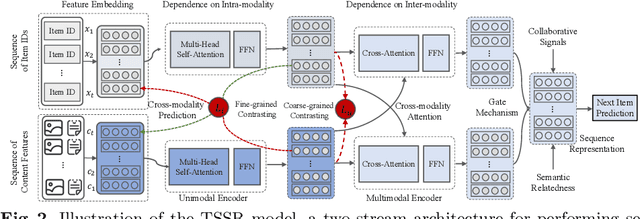

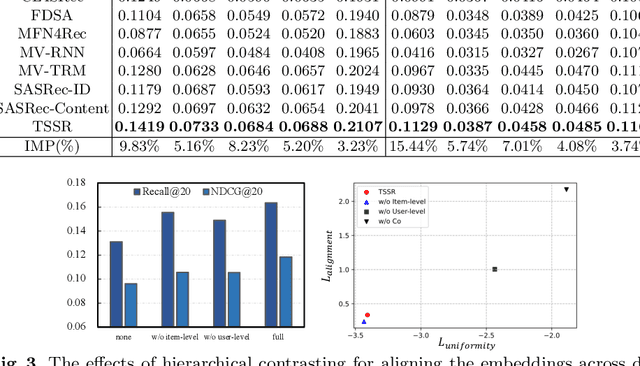
Sequential recommender systems (SRS) could capture dynamic user preferences by modeling historical behaviors ordered in time. Despite effectiveness, focusing only on the \textit{collaborative signals} from behaviors does not fully grasp user interests. It is also significant to model the \textit{semantic relatedness} reflected in content features, e.g., images and text. Towards that end, in this paper, we aim to enhance the SRS tasks by effectively unifying collaborative signals and semantic relatedness together. Notably, we empirically point out that it is nontrivial to achieve such a goal due to semantic gap issues. Thus, we propose an end-to-end two-stream architecture for sequential recommendation, named TSSR, to learn user preferences from ID-based and content-based sequence. Specifically, we first present novel hierarchical contrasting module, including coarse user-grained and fine item-grained terms, to align the representations of inter-modality. Furthermore, we also design a two-stream architecture to learn the dependence of intra-modality sequence and the complex interactions of inter-modality sequence, which can yield more expressive capacity in understanding user interests. We conduct extensive experiments on five public datasets. The experimental results show that the TSSR could yield superior performance than competitive baselines. We also make our experimental codes publicly available at https://anonymous.4open.science/r/TSSR-2A27/.
Multichannel Long-Term Streaming Neural Speech Enhancement for Static and Moving Speakers
Mar 12, 2024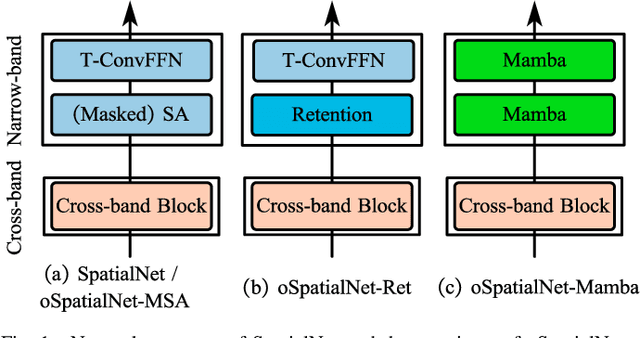
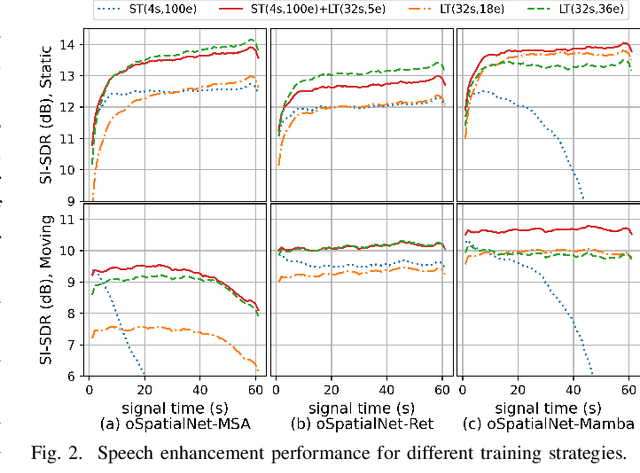
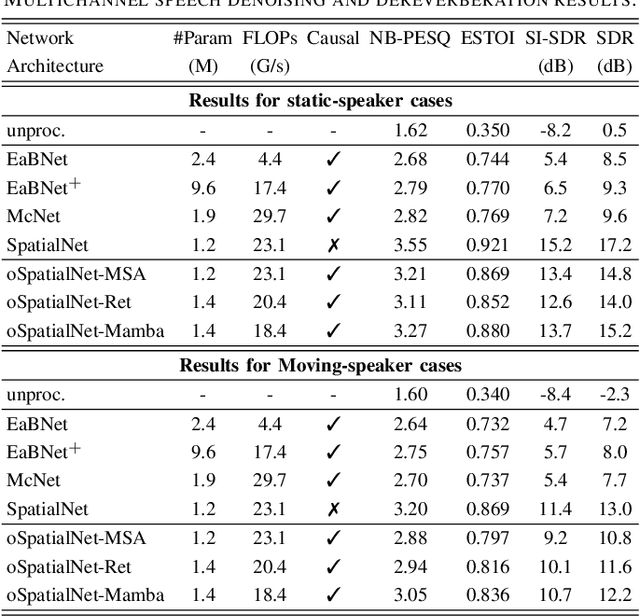
In this work, we extend our previously proposed offline SpatialNet for long-term streaming multichannel speech enhancement in both static and moving speaker scenarios. SpatialNet exploits spatial information, such as the spatial/steering direction of speech, for discriminating between target speech and interferences, and achieved outstanding performance. The core of SpatialNet is a narrow-band self-attention module used for learning the temporal dynamic of spatial vectors. Towards long-term streaming speech enhancement, we propose to replace the offline self-attention network with online networks that have linear inference complexity w.r.t signal length and meanwhile maintain the capability of learning long-term information. Three variants are developed based on (i) masked self-attention, (ii) Retention, a self-attention variant with linear inference complexity, and (iii) Mamba, a structured-state-space-based RNN-like network. Moreover, we investigate the length extrapolation ability of different networks, namely test on signals that are much longer than training signals, and propose a short-signal training plus long-signal fine-tuning strategy, which largely improves the length extrapolation ability of the networks within limited training time. Overall, the proposed online SpatialNet achieves outstanding speech enhancement performance for long audio streams, and for both static and moving speakers. The proposed method will be open-sourced in https://github.com/Audio-WestlakeU/NBSS.
OPEN TEACH: A Versatile Teleoperation System for Robotic Manipulation
Mar 12, 2024


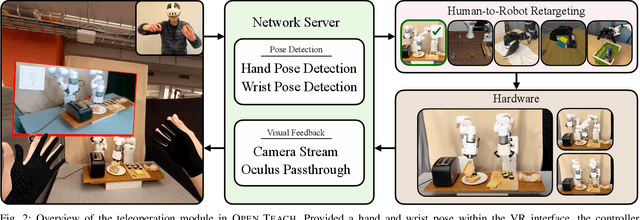
Open-sourced, user-friendly tools form the bedrock of scientific advancement across disciplines. The widespread adoption of data-driven learning has led to remarkable progress in multi-fingered dexterity, bimanual manipulation, and applications ranging from logistics to home robotics. However, existing data collection platforms are often proprietary, costly, or tailored to specific robotic morphologies. We present OPEN TEACH, a new teleoperation system leveraging VR headsets to immerse users in mixed reality for intuitive robot control. Built on the affordable Meta Quest 3, which costs $500, OPEN TEACH enables real-time control of various robots, including multi-fingered hands and bimanual arms, through an easy-to-use app. Using natural hand gestures and movements, users can manipulate robots at up to 90Hz with smooth visual feedback and interface widgets offering closeup environment views. We demonstrate the versatility of OPEN TEACH across 38 tasks on different robots. A comprehensive user study indicates significant improvement in teleoperation capability over the AnyTeleop framework. Further experiments exhibit that the collected data is compatible with policy learning on 10 dexterous and contact-rich manipulation tasks. Currently supporting Franka, xArm, Jaco, and Allegro platforms, OPEN TEACH is fully open-sourced to promote broader adoption. Videos are available at https://open-teach.github.io/.
PeLK: Parameter-efficient Large Kernel ConvNets with Peripheral Convolution
Mar 12, 2024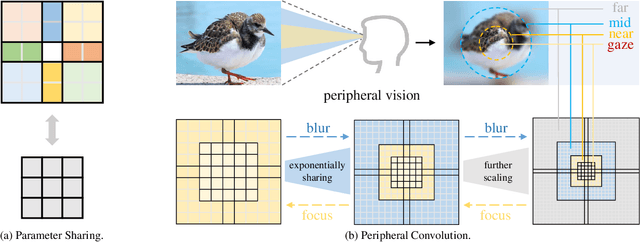

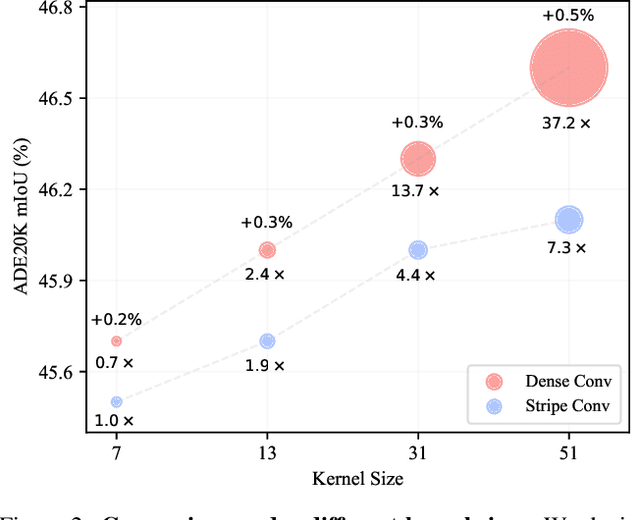
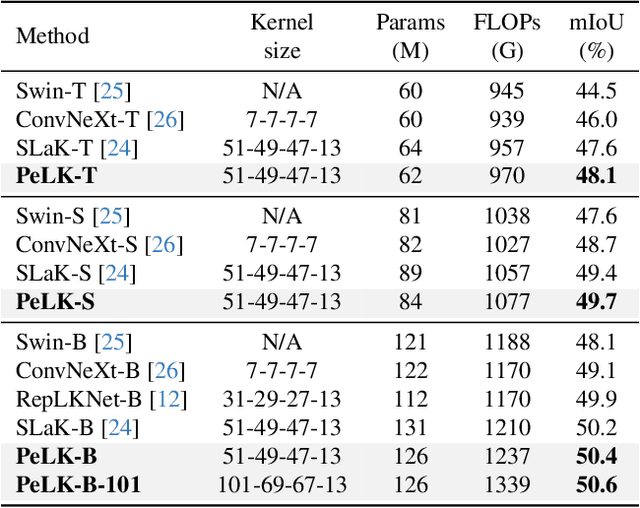
Recently, some large kernel convnets strike back with appealing performance and efficiency. However, given the square complexity of convolution, scaling up kernels can bring about an enormous amount of parameters and the proliferated parameters can induce severe optimization problem. Due to these issues, current CNNs compromise to scale up to 51x51 in the form of stripe convolution (i.e., 51x5 + 5x51) and start to saturate as the kernel size continues growing. In this paper, we delve into addressing these vital issues and explore whether we can continue scaling up kernels for more performance gains. Inspired by human vision, we propose a human-like peripheral convolution that efficiently reduces over 90% parameter count of dense grid convolution through parameter sharing, and manage to scale up kernel size to extremely large. Our peripheral convolution behaves highly similar to human, reducing the complexity of convolution from O(K^2) to O(logK) without backfiring performance. Built on this, we propose Parameter-efficient Large Kernel Network (PeLK). Our PeLK outperforms modern vision Transformers and ConvNet architectures like Swin, ConvNeXt, RepLKNet and SLaK on various vision tasks including ImageNet classification, semantic segmentation on ADE20K and object detection on MS COCO. For the first time, we successfully scale up the kernel size of CNNs to an unprecedented 101x101 and demonstrate consistent improvements.
Graph Data Condensation via Self-expressive Graph Structure Reconstruction
Mar 12, 2024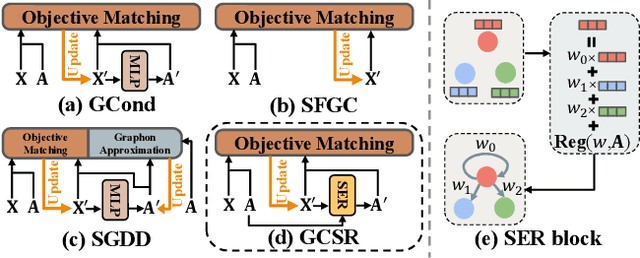
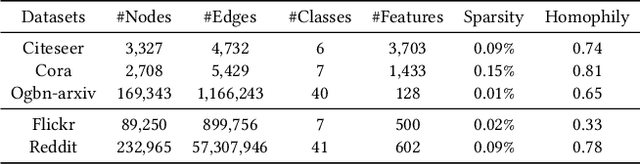
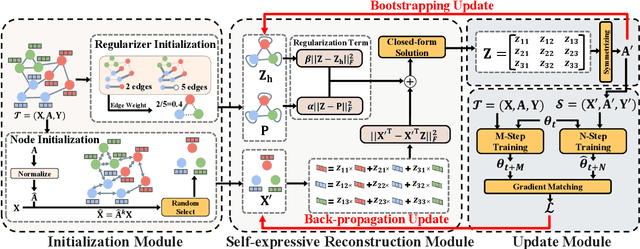
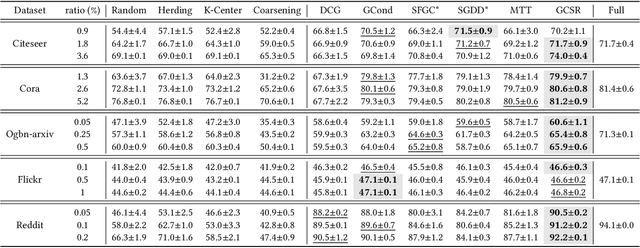
With the increasing demands of training graph neural networks (GNNs) on large-scale graphs, graph data condensation has emerged as a critical technique to relieve the storage and time costs during the training phase. It aims to condense the original large-scale graph to a much smaller synthetic graph while preserving the essential information necessary for efficiently training a downstream GNN. However, existing methods concentrate either on optimizing node features exclusively or endeavor to independently learn node features and the graph structure generator. They could not explicitly leverage the information of the original graph structure and failed to construct an interpretable graph structure for the synthetic dataset. To address these issues, we introduce a novel framework named \textbf{G}raph Data \textbf{C}ondensation via \textbf{S}elf-expressive Graph Structure \textbf{R}econstruction (\textbf{GCSR}). Our method stands out by (1) explicitly incorporating the original graph structure into the condensing process and (2) capturing the nuanced interdependencies between the condensed nodes by reconstructing an interpretable self-expressive graph structure. Extensive experiments and comprehensive analysis validate the efficacy of the proposed method across diverse GNN models and datasets. Our code is available at https://www.dropbox.com/scl/fi/2aonyp5ln5gisdqtjimu8/GCSR.zip?rlkey=11cuwfpsf54wxiiktu0klud0x&dl=0
An Improved Algorithm for Learning Drifting Discrete Distributions
Mar 08, 2024We present a new adaptive algorithm for learning discrete distributions under distribution drift. In this setting, we observe a sequence of independent samples from a discrete distribution that is changing over time, and the goal is to estimate the current distribution. Since we have access to only a single sample for each time step, a good estimation requires a careful choice of the number of past samples to use. To use more samples, we must resort to samples further in the past, and we incur a drift error due to the bias introduced by the change in distribution. On the other hand, if we use a small number of past samples, we incur a large statistical error as the estimation has a high variance. We present a novel adaptive algorithm that can solve this trade-off without any prior knowledge of the drift. Unlike previous adaptive results, our algorithm characterizes the statistical error using data-dependent bounds. This technicality enables us to overcome the limitations of the previous work that require a fixed finite support whose size is known in advance and that cannot change over time. Additionally, we can obtain tighter bounds depending on the complexity of the drifting distribution, and also consider distributions with infinite support.
Node Centrality Approximation For Large Networks Based On Inductive Graph Neural Networks
Mar 08, 2024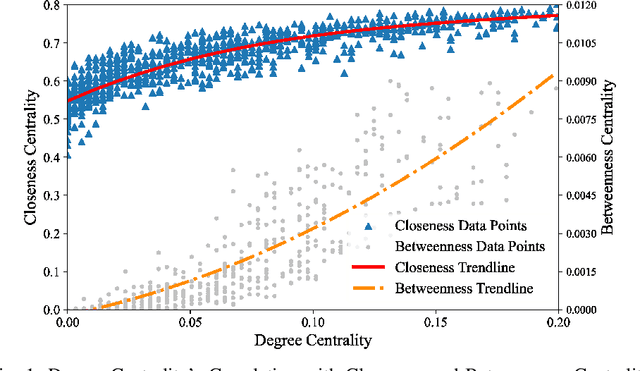
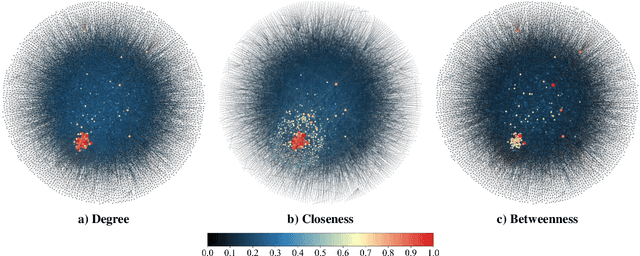
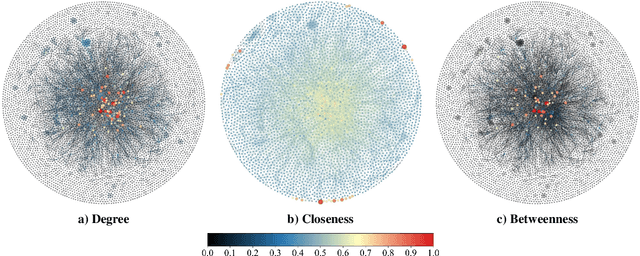
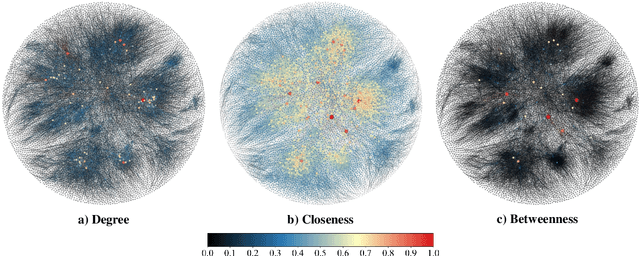
Closeness Centrality (CC) and Betweenness Centrality (BC) are crucial metrics in network analysis, providing essential reference for discerning the significance of nodes within complex networks. These measures find wide applications in critical tasks, such as community detection and network dismantling. However, their practical implementation on extensive networks remains computationally demanding due to their high time complexity. To mitigate these computational challenges, numerous approximation algorithms have been developed to expedite the computation of CC and BC. Nevertheless, even these approximations still necessitate substantial processing time when applied to large-scale networks. Furthermore, their output proves sensitive to even minor perturbations within the network structure. In this work, We redefine the CC and BC node ranking problem as a machine learning problem and propose the CNCA-IGE model, which is an encoder-decoder model based on inductive graph neural networks designed to rank nodes based on specified CC or BC metrics. We incorporate the MLP-Mixer model as the decoder in the BC ranking prediction task to enhance the model's robustness and capacity. Our approach is evaluated on diverse synthetic and real-world networks of varying scales, and the experimental results demonstrate that the CNCA-IGE model outperforms state-of-the-art baseline models, significantly reducing execution time while improving performance.
RF-Flashlight Testbed for Verification of Real-Time Geofencing of EESS Radiometers and Millimeter-Wave Ground-to-Satellite Propagation Models
Feb 28, 2024A simple 'RF-flashlight' (or ground to satellite) interference testbed is proposed to experimentally verify real-time geofencing (RTG) for protecting passive Earth Exploration Satellite Services (EESS) radiometer measurements from 5G or 6G mm-wave transmissions, and ground to satellite propagation models used in the interference modeling of this spectrum coexistence scenario. RTG is a stronger EESS protection mechanism than the current methodology recommended by the ITU based on a worst-case interference threshold while simultaneously enabling dynamic spectrum sharing and coexistence with 5G or 6G wireless networks. Similarly, verifying more sophisticated RF propagation models that include ground topology, buildings, and non-line-of-sight paths will provide better estimates of interference than the current ITU line-of-sight model and, thus, a more reliable basis for establishing a consensus among the spectrum stakeholders.
EarthLoc: Astronaut Photography Localization by Indexing Earth from Space
Mar 11, 2024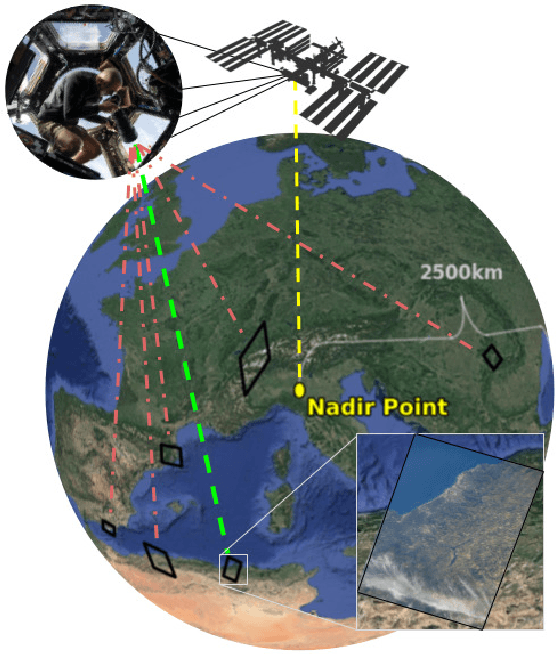
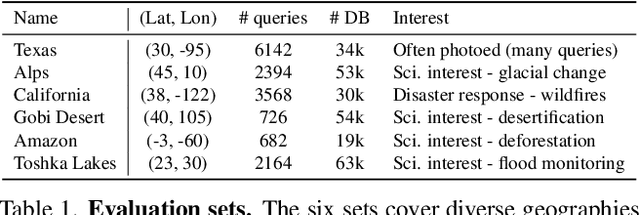

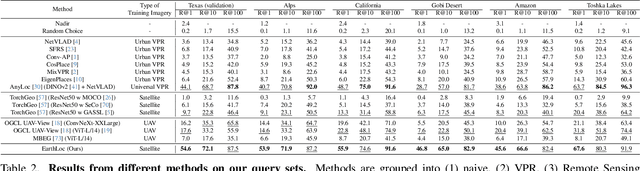
Astronaut photography, spanning six decades of human spaceflight, presents a unique Earth observations dataset with immense value for both scientific research and disaster response. Despite its significance, accurately localizing the geographical extent of these images, crucial for effective utilization, poses substantial challenges. Current manual localization efforts are time-consuming, motivating the need for automated solutions. We propose a novel approach - leveraging image retrieval - to address this challenge efficiently. We introduce innovative training techniques, including Year-Wise Data Augmentation and a Neutral-Aware Multi-Similarity Loss, which contribute to the development of a high-performance model, EarthLoc. We develop six evaluation datasets and perform a comprehensive benchmark comparing EarthLoc to existing methods, showcasing its superior efficiency and accuracy. Our approach marks a significant advancement in automating the localization of astronaut photography, which will help bridge a critical gap in Earth observations data. Code and datasets are available at https://github.com/gmberton/EarthLoc