 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Videogenic: Video Highlights via Photogenic Moments
Nov 22, 2022

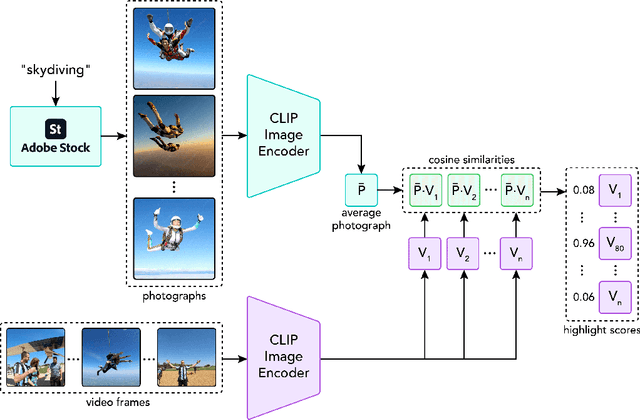
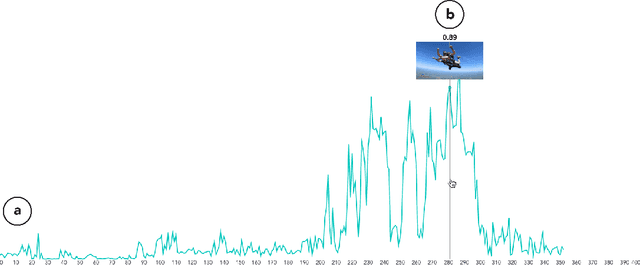
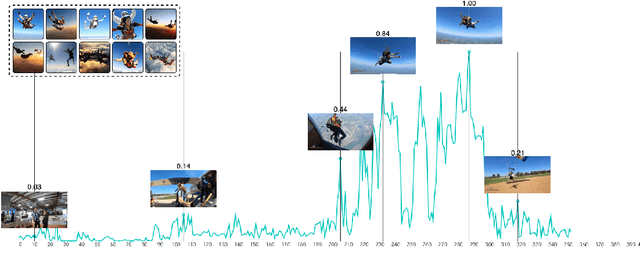
This paper investigates the challenge of extracting highlight moments from videos. To perform this task, a system needs to understand what constitutes a highlight for arbitrary video domains while at the same time being able to scale across different domains. Our key insight is that photographs taken by photographers tend to capture the most remarkable or photogenic moments of an activity. Drawing on this insight, we present Videogenic, a system capable of creating domain-specific highlight videos for a wide range of domains. In a human evaluation study (N=50), we show that a high-quality photograph collection combined with CLIP-based retrieval (which uses a neural network with semantic knowledge of images) can serve as an excellent prior for finding video highlights. In a within-subjects expert study (N=12), we demonstrate the usefulness of Videogenic in helping video editors create highlight videos with lighter workload, shorter task completion time, and better usability.
Real-World Compositional Generalization with Disentangled Sequence-to-Sequence Learning
Dec 12, 2022
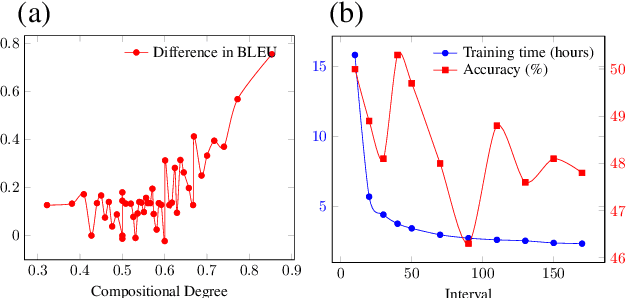
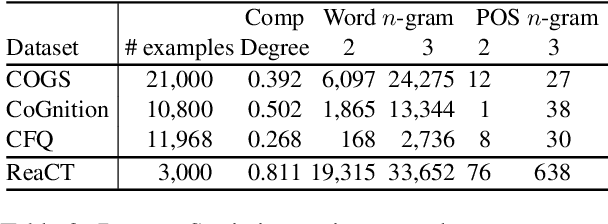
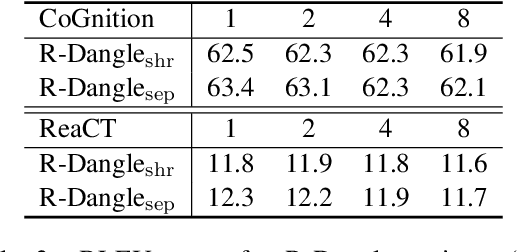
Compositional generalization is a basic mechanism in human language learning, which current neural networks struggle with. A recently proposed Disentangled sequence-to-sequence model (Dangle) shows promising generalization capability by learning specialized encodings for each decoding step. We introduce two key modifications to this model which encourage more disentangled representations and improve its compute and memory efficiency, allowing us to tackle compositional generalization in a more realistic setting. Specifically, instead of adaptively re-encoding source keys and values at each time step, we disentangle their representations and only re-encode keys periodically, at some interval. Our new architecture leads to better generalization performance across existing tasks and datasets, and a new machine translation benchmark which we create by detecting naturally occurring compositional patterns in relation to a training set. We show this methodology better emulates real-world requirements than artificial challenges.
Robust Recurrent Neural Network to Identify Ship Motion in Open Water with Performance Guarantees -- Technical Report
Dec 12, 2022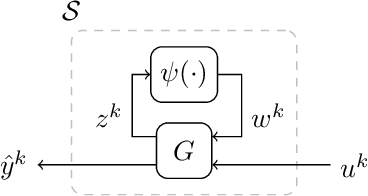
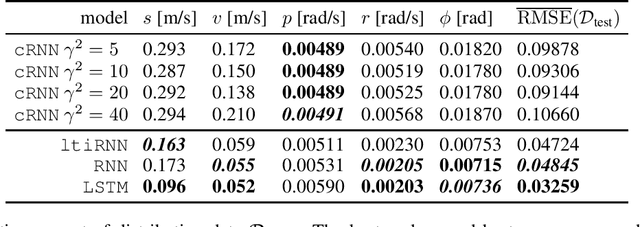
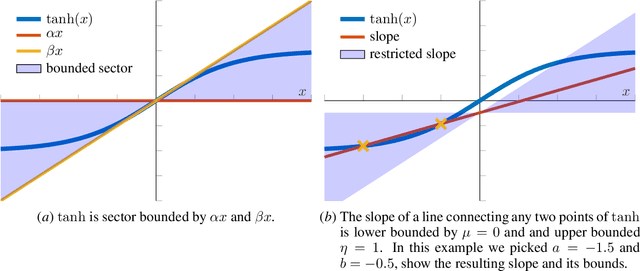
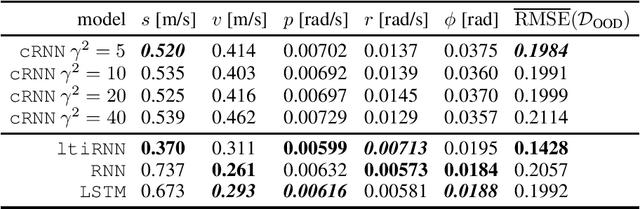
Recurrent neural networks are capable of learning the dynamics of an unknown nonlinear system purely from input-output measurements. However, the resulting models do not provide any stability guarantees on the input-output mapping. In this work, we represent a recurrent neural network as a linear time-invariant system with nonlinear disturbances. By introducing constraints on the parameters, we can guarantee finite gain stability and incremental finite gain stability. We apply this identification method to learn the motion of a four-degrees-of-freedom ship that is moving in open water and compare it against other purely learning-based approaches with unconstrained parameters. Our analysis shows that the constrained recurrent neural network has a lower prediction accuracy on the test set, but it achieves comparable results on an out-of-distribution set and respects stability conditions.
Joint Embedding of 2D and 3D Networks for Medical Image Anomaly Detection
Dec 23, 2022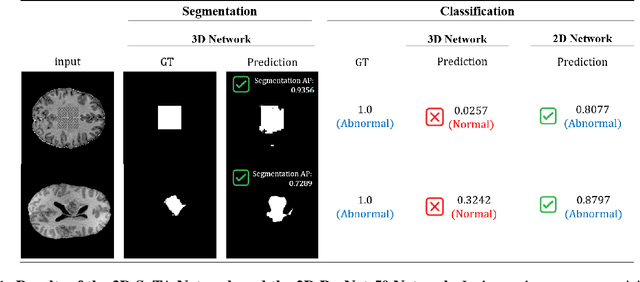
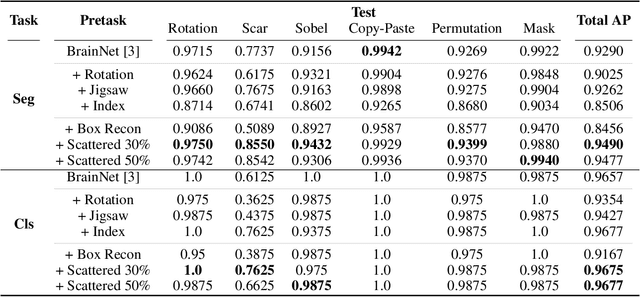
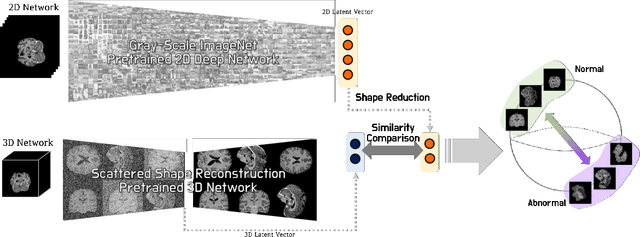
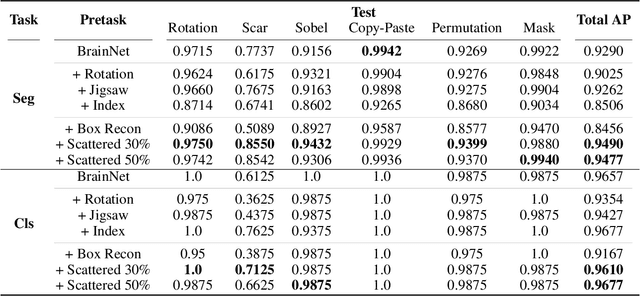
Obtaining ground truth data in medical imaging has difficulties due to the fact that it requires a lot of annotating time from the experts in the field. Also, when trained with supervised learning, it detects only the cases included in the labels. In real practice, we want to also open to other possibilities than the named cases while examining the medical images. As a solution, the need for anomaly detection that can detect and localize abnormalities by learning the normal characteristics using only normal images is emerging. With medical image data, we can design either 2D or 3D networks of self-supervised learning for anomaly detection task. Although 3D networks, which learns 3D structures of the human body, show good performance in 3D medical image anomaly detection, they cannot be stacked in deeper layers due to memory problems. While 2D networks have advantage in feature detection, they lack 3D context information. In this paper, we develop a method for combining the strength of the 3D network and the strength of the 2D network through joint embedding. We also propose the pretask of self-supervised learning to make it possible for the networks to learn efficiently. Through the experiments, we show that the proposed method achieves better performance in both classification and segmentation tasks compared to the SoTA method.
Self-supervised and Weakly Supervised Contrastive Learning for Frame-wise Action Representations
Dec 23, 2022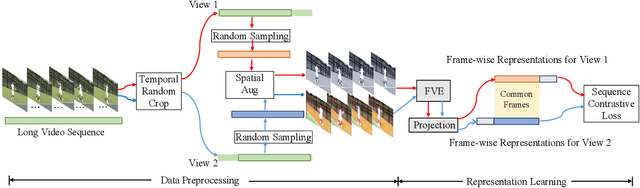
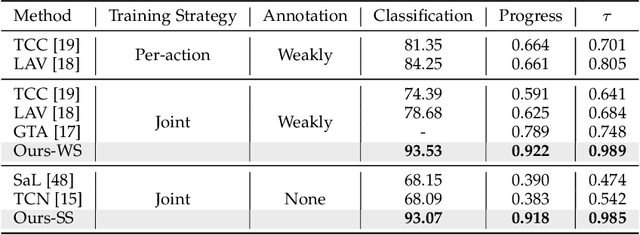
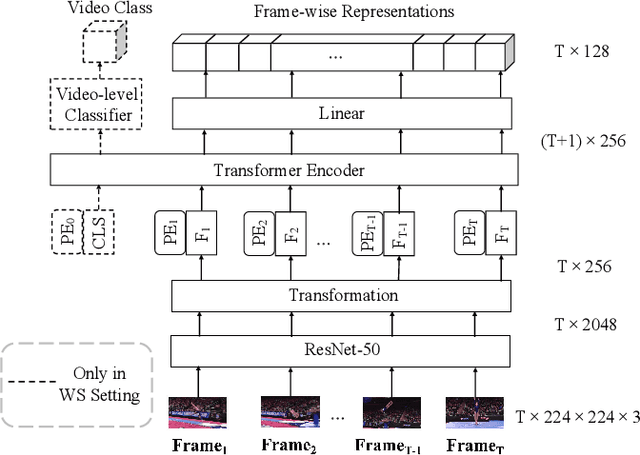
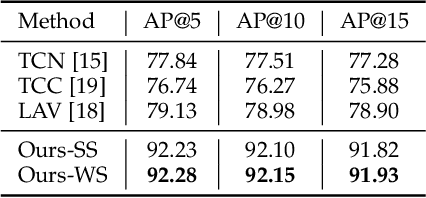
Previous work on action representation learning focused on global representations for short video clips. In contrast, many practical applications, such as video alignment, strongly demand learning the intensive representation of long videos. In this paper, we introduce a new framework of contrastive action representation learning (CARL) to learn frame-wise action representation in a self-supervised or weakly-supervised manner, especially for long videos. Specifically, we introduce a simple but effective video encoder that considers both spatial and temporal context by combining convolution and transformer. Inspired by the recent massive progress in self-supervised learning, we propose a new sequence contrast loss (SCL) applied to two related views obtained by expanding a series of spatio-temporal data in two versions. One is the self-supervised version that optimizes embedding space by minimizing KL-divergence between sequence similarity of two augmented views and prior Gaussian distribution of timestamp distance. The other is the weakly-supervised version that builds more sample pairs among videos using video-level labels by dynamic time wrapping (DTW). Experiments on FineGym, PennAction, and Pouring datasets show that our method outperforms previous state-of-the-art by a large margin for downstream fine-grained action classification and even faster inference. Surprisingly, although without training on paired videos like in previous works, our self-supervised version also shows outstanding performance in video alignment and fine-grained frame retrieval tasks.
PoissonMat: Remodeling Matrix Factorization using Poisson Distribution and Solving the Cold Start Problem without Input Data
Dec 06, 2022Matrix Factorization is one of the most successful recommender system techniques over the past decade. However, the classic probabilistic theory framework for matrix factorization is modeled using normal distributions. To find better probabilistic models, algorithms such as RankMat, ZeroMat and DotMat have been invented in recent years. In this paper, we model the user rating behavior in recommender system as a Poisson process, and design an algorithm that relies on no input data to solve the recommendation problem and the cold start issue at the same time. We prove the superiority of our algorithm in comparison with matrix factorization, random placement, Zipf placement, ZeroMat, DotMat, etc.
Abnormal Signal Recognition with Time-Frequency Spectrogram: A Deep Learning Approach
May 30, 2022
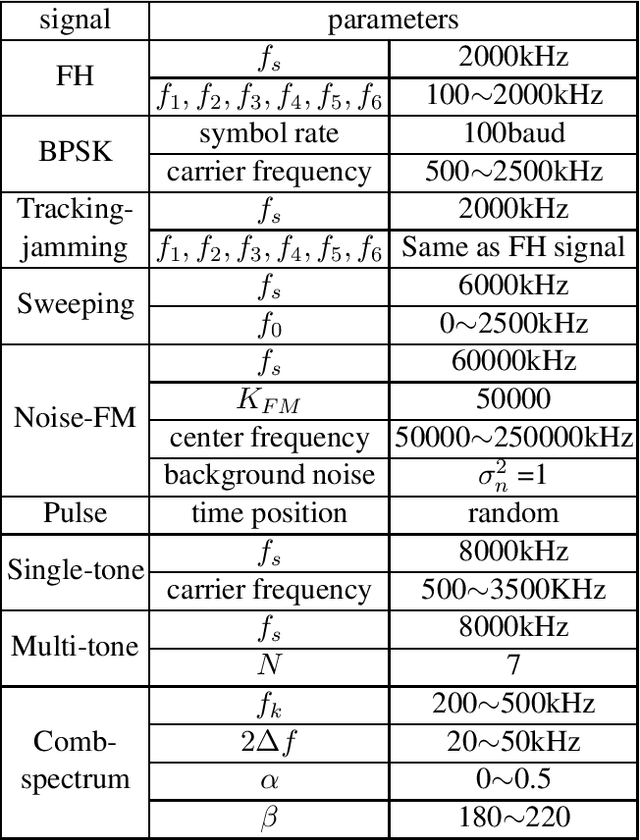


With the increasingly complex and changeable electromagnetic environment, wireless communication systems are facing jamming and abnormal signal injection, which significantly affects the normal operation of a communication system. In particular, the abnormal signals may emulate the normal signals, which makes it very challenging for abnormal signal recognition. In this paper, we propose a new abnormal signal recognition scheme, which combines time-frequency analysis with deep learning to effectively identify synthetic abnormal communication signals. Firstly, we emulate synthetic abnormal communication signals including seven jamming patterns. Then, we model an abnormal communication signals recognition system based on the communication protocol between the transmitter and the receiver. To improve the performance, we convert the original signal into the time-frequency spectrogram to develop an image classification algorithm. Simulation results demonstrate that the proposed method can effectively recognize the abnormal signals under various parameter configurations, even under low signal-to-noise ratio (SNR) and low jamming-to-signal ratio (JSR) conditions.
Learning to Control under Time-Varying Environment
Jun 06, 2022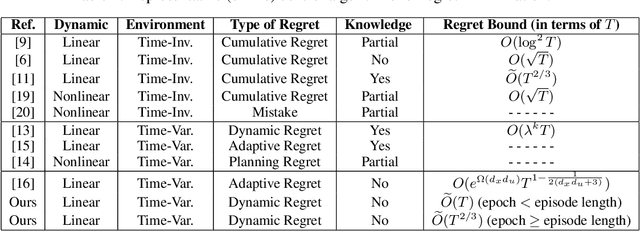
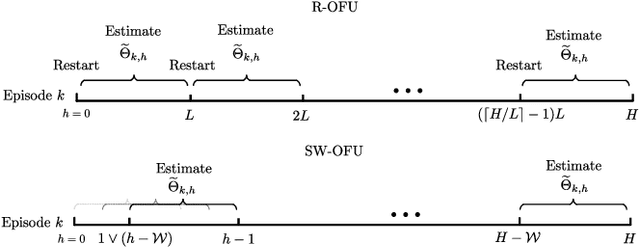
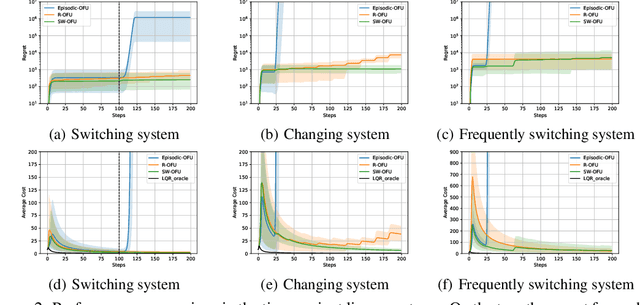
This paper investigates the problem of regret minimization in linear time-varying (LTV) dynamical systems. Due to the simultaneous presence of uncertainty and non-stationarity, designing online control algorithms for unknown LTV systems remains a challenging task. At a cost of NP-hard offline planning, prior works have introduced online convex optimization algorithms, although they suffer from nonparametric rate of regret. In this paper, we propose the first computationally tractable online algorithm with regret guarantees that avoids offline planning over the state linear feedback policies. Our algorithm is based on the optimism in the face of uncertainty (OFU) principle in which we optimistically select the best model in a high confidence region. Our algorithm is then more explorative when compared to previous approaches. To overcome non-stationarity, we propose either a restarting strategy (R-OFU) or a sliding window (SW-OFU) strategy. With proper configuration, our algorithm is attains sublinear regret $O(T^{2/3})$. These algorithms utilize data from the current phase for tracking variations on the system dynamics. We corroborate our theoretical findings with numerical experiments, which highlight the effectiveness of our methods. To the best of our knowledge, our study establishes the first model-based online algorithm with regret guarantees under LTV dynamical systems.
Panoptic Lifting for 3D Scene Understanding with Neural Fields
Dec 19, 2022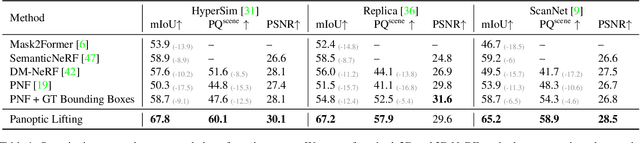
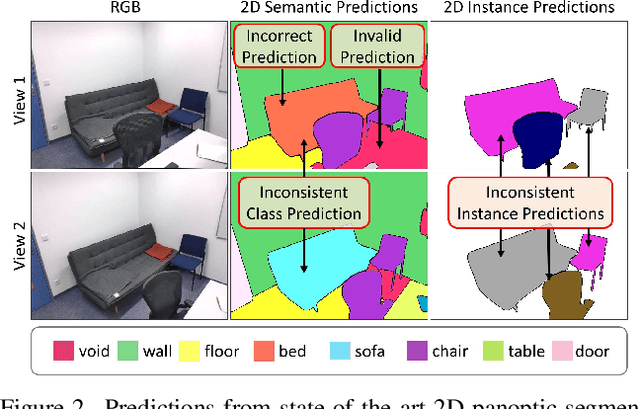
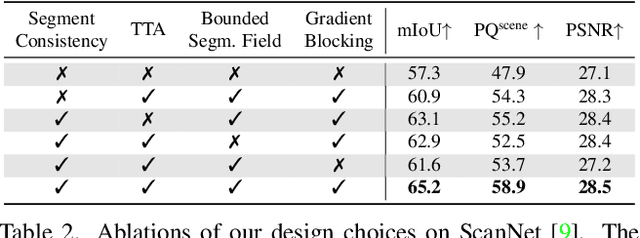
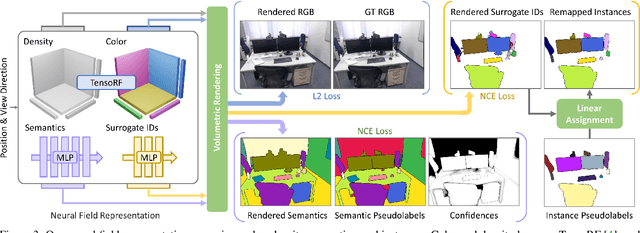
We propose Panoptic Lifting, a novel approach for learning panoptic 3D volumetric representations from images of in-the-wild scenes. Once trained, our model can render color images together with 3D-consistent panoptic segmentation from novel viewpoints. Unlike existing approaches which use 3D input directly or indirectly, our method requires only machine-generated 2D panoptic segmentation masks inferred from a pre-trained network. Our core contribution is a panoptic lifting scheme based on a neural field representation that generates a unified and multi-view consistent, 3D panoptic representation of the scene. To account for inconsistencies of 2D instance identifiers across views, we solve a linear assignment with a cost based on the model's current predictions and the machine-generated segmentation masks, thus enabling us to lift 2D instances to 3D in a consistent way. We further propose and ablate contributions that make our method more robust to noisy, machine-generated labels, including test-time augmentations for confidence estimates, segment consistency loss, bounded segmentation fields, and gradient stopping. Experimental results validate our approach on the challenging Hypersim, Replica, and ScanNet datasets, improving by 8.4, 13.8, and 10.6% in scene-level PQ over state of the art.
Don't Generate, Discriminate: A Proposal for Grounding Language Models to Real-World Environments
Dec 19, 2022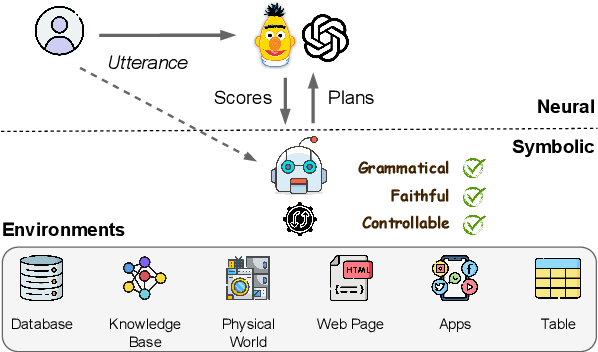
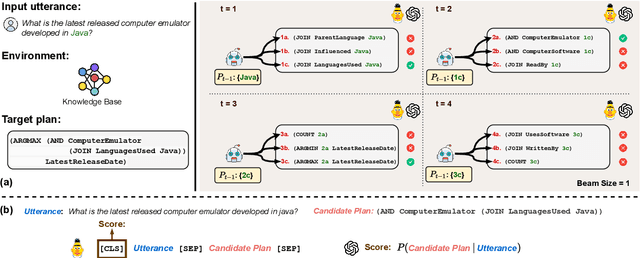

A key missing ability of current language models (LMs) is grounding to real-world environments. Most existing work for grounded language understanding uses LMs to directly generate plans that can be executed in the environment to achieve the desired effects. It casts the burden of ensuring grammaticality, faithfulness, and controllability all on the LMs. We propose Pangu, a generic framework for grounded language understanding that capitalizes on the discriminative ability of LMs instead of their generative ability. Pangu consists of a symbolic agent and a neural LM working in a concerted fashion: the agent explores the environment to incrementally construct valid candidate plans, and the LM evaluates the plausibility of the candidate plans to guide the search process. A case study on the challenging problem of knowledge base question answering (KBQA), which features a massive environment, demonstrates the remarkable effectiveness and flexibility of Pangu: A BERT-base LM is sufficient for achieving a new state of the art on standard KBQA datasets, and larger LMs further improve the performance by a large margin. Pangu also enables, for the first time, effective few-shot in-context learning for KBQA with large LMs such as Codex.