 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VO$Q$L: Towards Optimal Regret in Model-free RL with Nonlinear Function Approximation
Dec 12, 2022



We study time-inhomogeneous episodic reinforcement learning (RL) under general function approximation and sparse rewards. We design a new algorithm, Variance-weighted Optimistic $Q$-Learning (VO$Q$L), based on $Q$-learning and bound its regret assuming completeness and bounded Eluder dimension for the regression function class. As a special case, VO$Q$L achieves $\tilde{O}(d\sqrt{HT}+d^6H^{5})$ regret over $T$ episodes for a horizon $H$ MDP under ($d$-dimensional) linear function approximation, which is asymptotically optimal. Our algorithm incorporates weighted regression-based upper and lower bounds on the optimal value function to obtain this improved regret. The algorithm is computationally efficient given a regression oracle over the function class, making this the first computationally tractable and statistically optimal approach for linear MDPs.
SLAM for Visually Impaired People: A Survey
Dec 09, 2022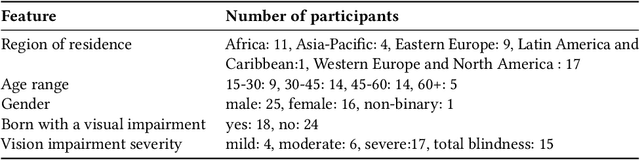
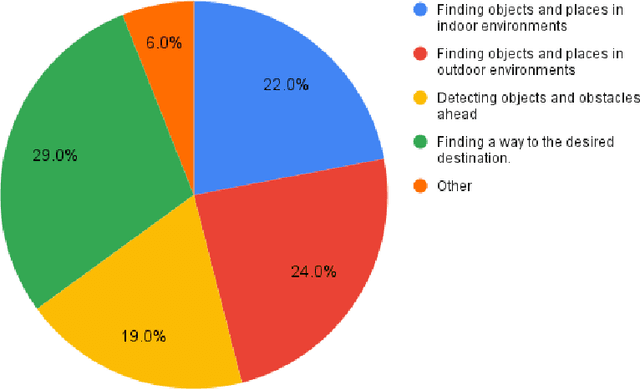
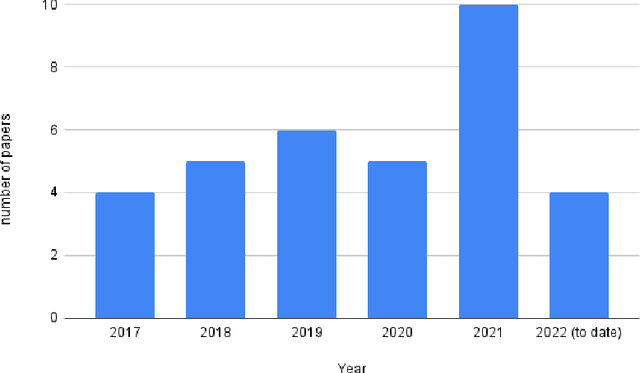
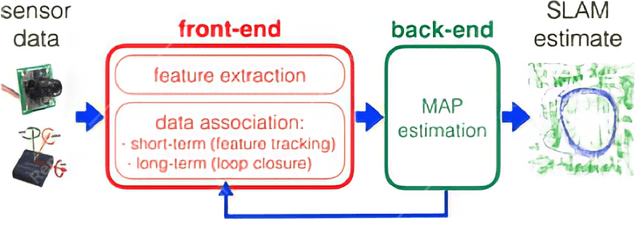
In recent decades, several assistive technologies for visually impaired and blind (VIB) people have been developed to improve their ability to navigate independently and safely. At the same time, simultaneous localization and mapping (SLAM) techniques have become sufficiently robust and efficient to be adopted in the development of assistive technologies. In this paper, we first report the results of an anonymous survey conducted with VIB people to understand their experience and needs; we focus on digital assistive technologies that help them with indoor and outdoor navigation. Then, we present a literature review of assistive technologies based on SLAM. We discuss proposed approaches and indicate their pros and cons. We conclude by presenting future opportunities and challenges in this domain.
Towards Real-time High-Definition Image Snow Removal: Efficient Pyramid Network with Asymmetrical Encoder-decoder Architecture
Jul 12, 2022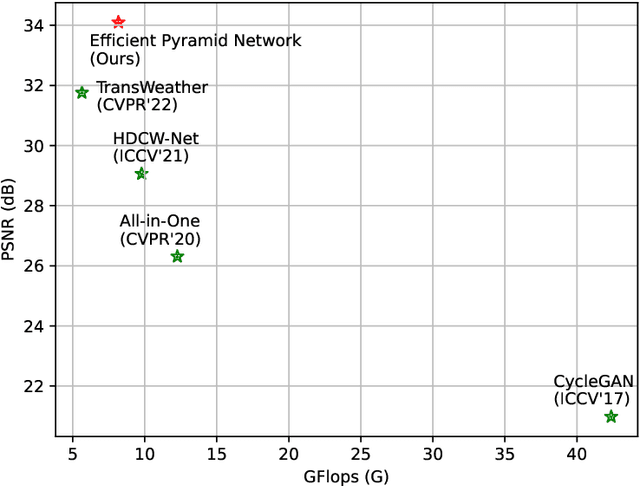
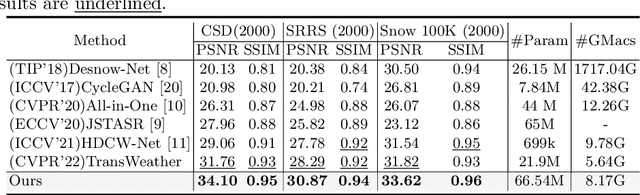
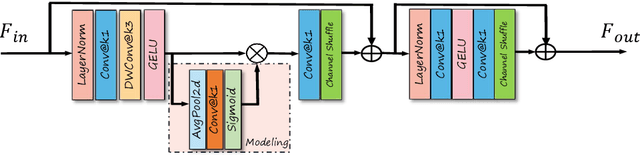

In winter scenes, the degradation of images taken under snow can be pretty complex, where the spatial distribution of snowy degradation is varied from image to image. Recent methods adopt deep neural networks to directly recover clean scenes from snowy images. However, due to the paradox caused by the variation of complex snowy degradation, achieving reliable High-Definition image desnowing performance in real time is a considerable challenge. We develop a novel Efficient Pyramid Network with asymmetrical encoder-decoder architecture for real-time HD image desnowing. The general idea of our proposed network is to utilize the multi-scale feature flow fully and implicitly mine clean cues from features. Compared with previous state-of-the-art desnowing methods, our approach achieves a better complexity-performance trade-off and effectively handles the processing difficulties of HD and Ultra-HD images. The extensive experiments on three large-scale image desnowing datasets demonstrate that our method surpasses all state-of-the-art approaches by a large margin both quantitatively and qualitatively, boosting the PSNR metric from 31.76 dB to 34.10 dB on the CSD test dataset and from 28.29 dB to 30.87 dB on the SRRS test dataset.
Continuous-Time and Multi-Level Graph Representation Learning for Origin-Destination Demand Prediction
Jun 30, 2022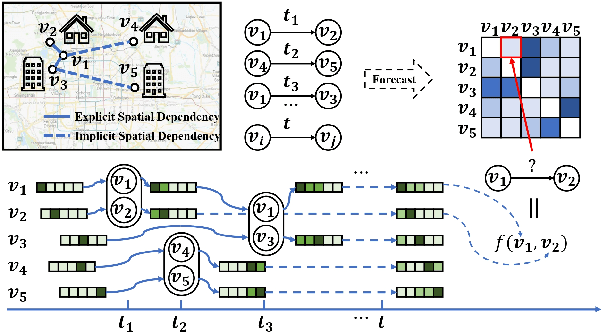
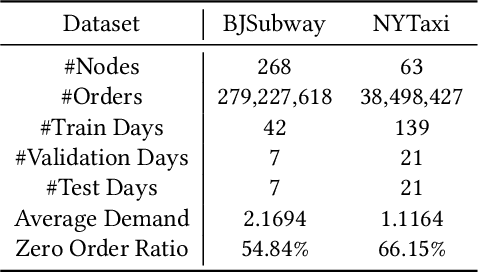
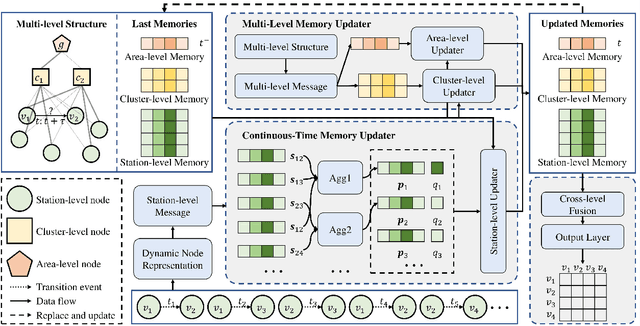
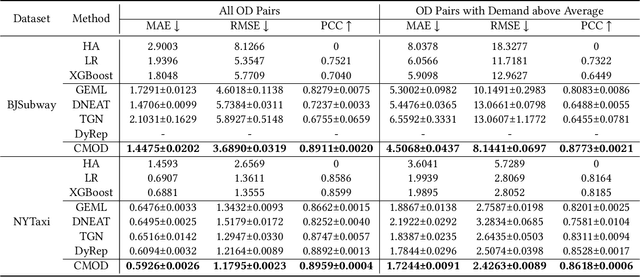
Traffic demand forecasting by deep neural networks has attracted widespread interest in both academia and industry society. Among them, the pairwise Origin-Destination (OD) demand prediction is a valuable but challenging problem due to several factors: (i) the large number of possible OD pairs, (ii) implicitness of spatial dependence, and (iii) complexity of traffic states. To address the above issues, this paper proposes a Continuous-time and Multi-level dynamic graph representation learning method for Origin-Destination demand prediction (CMOD). Firstly, a continuous-time dynamic graph representation learning framework is constructed, which maintains a dynamic state vector for each traffic node (metro stations or taxi zones). The state vectors keep historical transaction information and are continuously updated according to the most recently happened transactions. Secondly, a multi-level structure learning module is proposed to model the spatial dependency of station-level nodes. It can not only exploit relations between nodes adaptively from data, but also share messages and representations via cluster-level and area-level virtual nodes. Lastly, a cross-level fusion module is designed to integrate multi-level memories and generate comprehensive node representations for the final prediction. Extensive experiments are conducted on two real-world datasets from Beijing Subway and New York Taxi, and the results demonstrate the superiority of our model against the state-of-the-art approaches.
Trajectory Smoothing Using GNSS/PDR Integration Via Factor Graph Optimization in Urban Canyons
Dec 29, 2022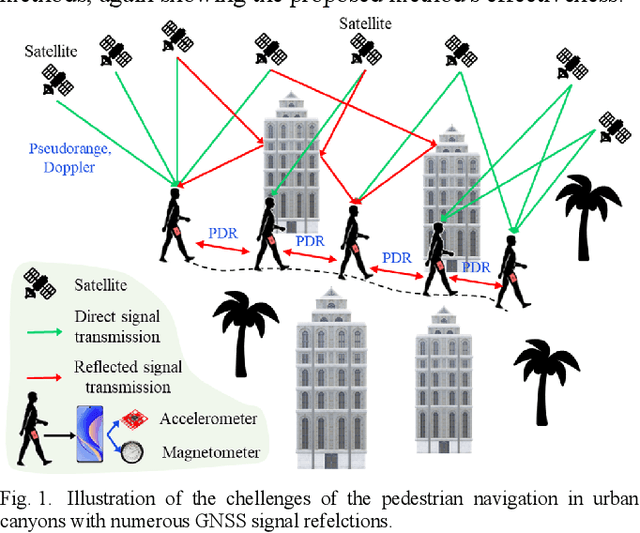

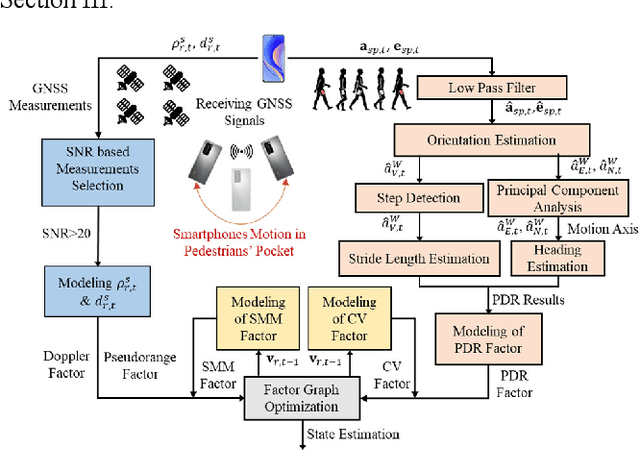
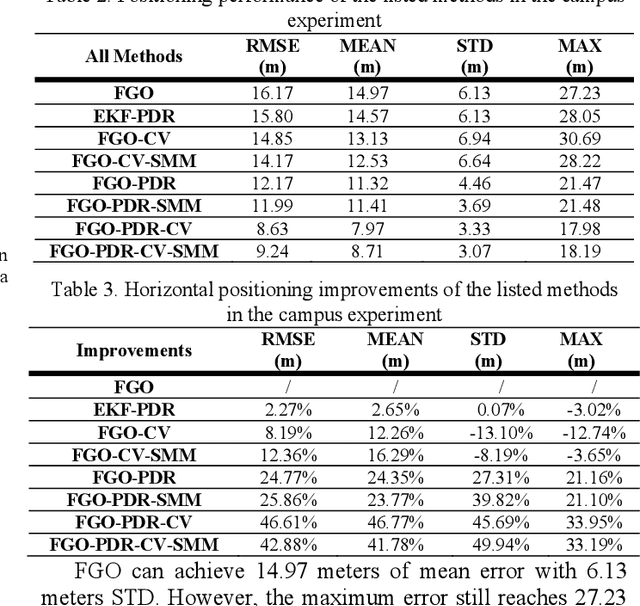
Accurate and smooth global navigation satellite system (GNSS) positioning for pedestrians in urban canyons is still a challenge due to the multipath effects and the non-light-of-sight (NLOS) receptions caused by the reflections from surrounding buildings. The recently developed factor graph optimization (FGO) based GNSS positioning method opened a new window for improving urban GNSS positioning by effectively exploiting the measurement redundancy from the historical information to resist the outlier measurements. Unfortunately, the FGO-based GNSS standalone positioning is still challenged in highly urbanized areas. As an extension of the previous FGO-based GNSS positioning method, this paper exploits the potential of the pedestrian dead reckoning (PDR) model in FGO to improve the GNSS standalone positioning performance in urban canyons. Specifically, the relative motion of the pedestrian is estimated based on the raw acceleration measurements from the onboard smartphone inertial measurement unit (IMU) via the PDR algorithm. Then the raw GNSS pseudorange, Doppler measurements, and relative motion from PDR are integrated using the FGO. Given the context of pedestrian navigation with a small acceleration most of the time, a novel soft motion model is proposed to smooth the states involved in the factor graph model. The effectiveness of the proposed method is verified step-by-step through two datasets collected in dense urban canyons of Hong Kong using smartphone-level GNSS receivers. The comparison between the conventional extended Kalman filter, several existing methods, and FGO-based integration is presented. The results reveal that the existing FGO-based GNSS standalone positioning is highly complementary to the PDR's relative motion estimation. Both improved positioning accuracy and trajectory smoothness are obtained with the help of the proposed method.
Data Dimension Reduction makes ML Algorithms efficient
Nov 17, 2022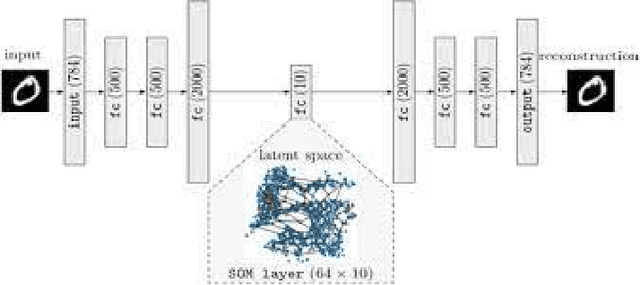
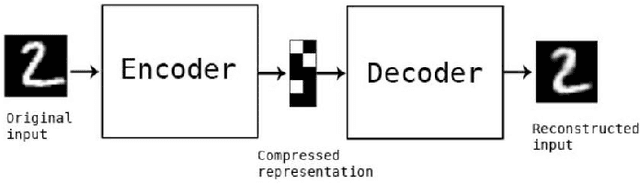
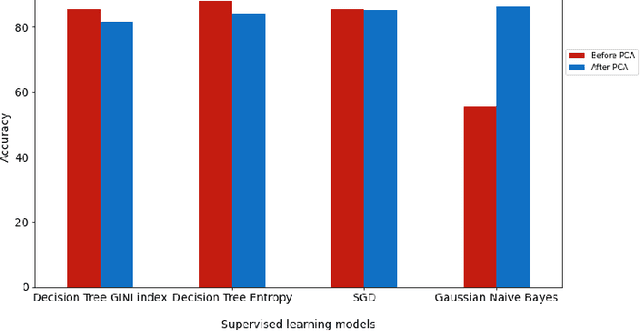
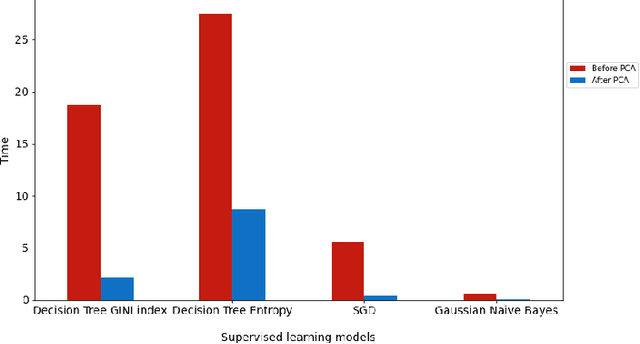
Data dimension reduction (DDR) is all about mapping data from high dimensions to low dimensions, various techniques of DDR are being used for image dimension reduction like Random Projections, Principal Component Analysis (PCA), the Variance approach, LSA-Transform, the Combined and Direct approaches, and the New Random Approach. Auto-encoders (AE) are used to learn end-to-end mapping. In this paper, we demonstrate that pre-processing not only speeds up the algorithms but also improves accuracy in both supervised and unsupervised learning. In pre-processing of DDR, first PCA based DDR is used for supervised learning, then we explore AE based DDR for unsupervised learning. In PCA based DDR, we first compare supervised learning algorithms accuracy and time before and after applying PCA. Similarly, in AE based DDR, we compare unsupervised learning algorithm accuracy and time before and after AE representation learning. Supervised learning algorithms including support-vector machines (SVM), Decision Tree with GINI index, Decision Tree with entropy and Stochastic Gradient Descent classifier (SGDC) and unsupervised learning algorithm including K-means clustering, are used for classification purpose. We used two datasets MNIST and FashionMNIST Our experiment shows that there is massive improvement in accuracy and time reduction after pre-processing in both supervised and unsupervised learning.
Time Shifts to Reduce the Size of Reservoir Computers
May 03, 2022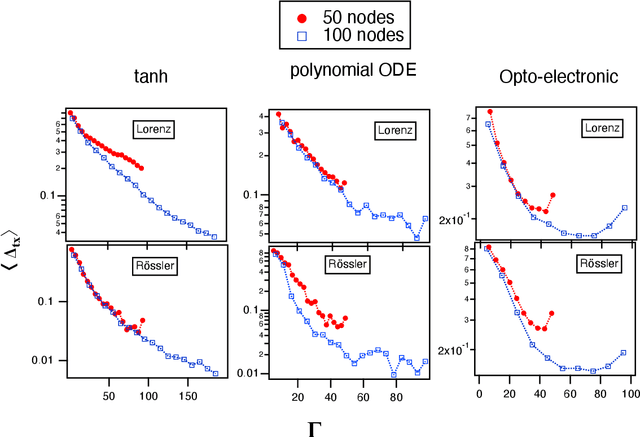
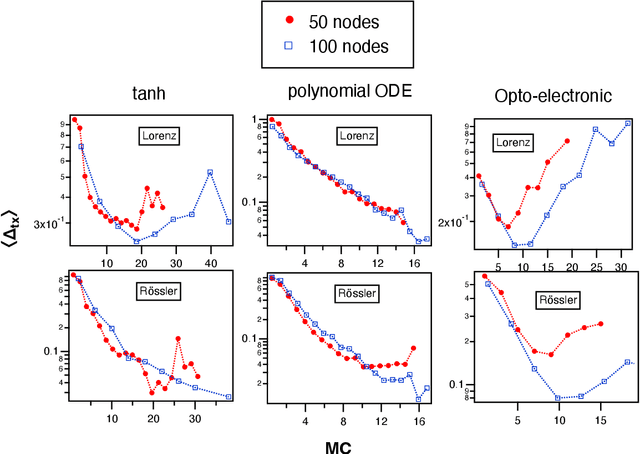
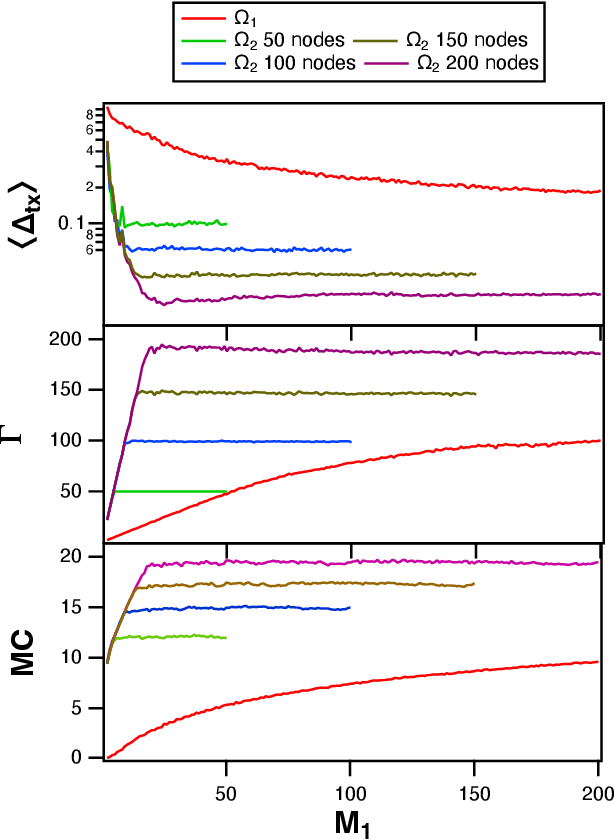
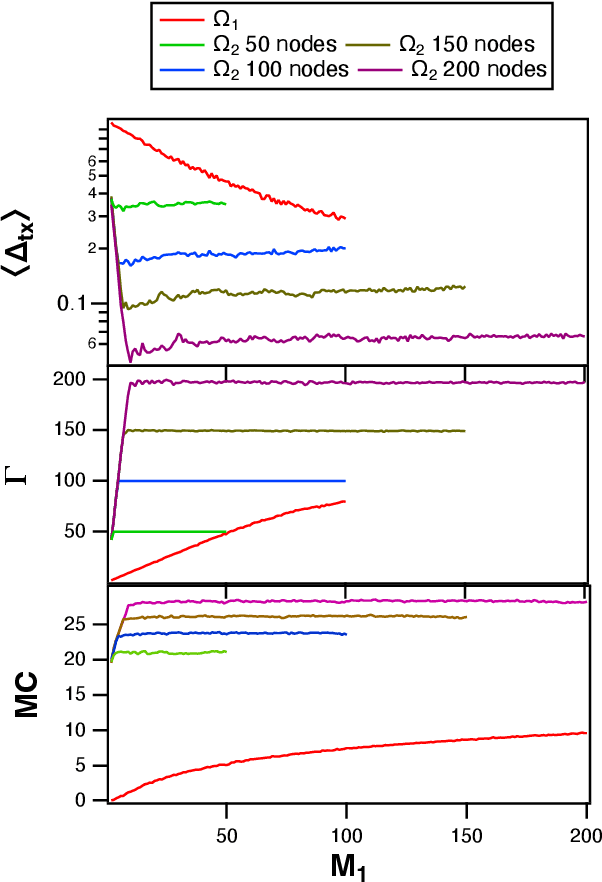
A reservoir computer is a type of dynamical system arranged to do computation. Typically, a reservoir computer is constructed by connecting a large number of nonlinear nodes in a network that includes recurrent connections. In order to achieve accurate results, the reservoir usually contains hundreds to thousands of nodes. This high dimensionality makes it difficult to analyze the reservoir computer using tools from dynamical systems theory. Additionally, the need to create and connect large numbers of nonlinear nodes makes it difficult to design and build analog reservoir computers that can be faster and consume less power than digital reservoir computers. We demonstrate here that a reservoir computer may be divided into two parts; a small set of nonlinear nodes (the reservoir), and a separate set of time-shifted reservoir output signals. The time-shifted output signals serve to increase the rank and memory of the reservoir computer, and the set of nonlinear nodes may create an embedding of the input dynamical system. We use this time-shifting technique to obtain excellent performance from an opto-electronic delay-based reservoir computer with only a small number of virtual nodes. Because only a few nonlinear nodes are required, construction of a reservoir computer becomes much easier, and delay-based reservoir computers can operate at much higher speeds.
Beyond Digital "Echo Chambers": The Role of Viewpoint Diversity in Political Discussion
Dec 18, 2022

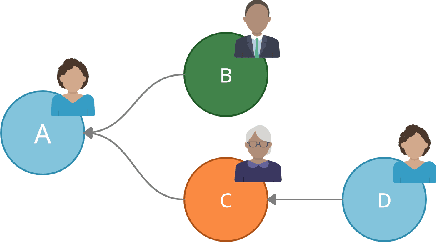
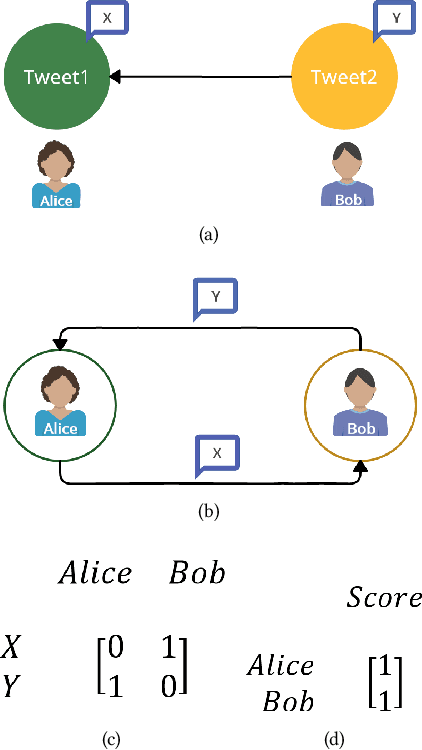
Increasingly taking place in online spaces, modern political conversations are typically perceived to be unproductively affirming -- siloed in so called ``echo chambers'' of exclusively like-minded discussants. Yet, to date we lack sufficient means to measure viewpoint diversity in conversations. To this end, in this paper, we operationalize two viewpoint metrics proposed for recommender systems and adapt them to the context of social media conversations. This is the first study to apply these two metrics (Representation and Fragmentation) to real world data and to consider the implications for online conversations specifically. We apply these measures to two topics -- daylight savings time (DST), which serves as a control, and the more politically polarized topic of immigration. We find that the diversity scores for both Fragmentation and Representation are lower for immigration than for DST. Further, we find that while pro-immigrant views receive consistent pushback on the platform, anti-immigrant views largely operate within echo chambers. We observe less severe yet similar patterns for DST. Taken together, Representation and Fragmentation paint a meaningful and important new picture of viewpoint diversity.
Empirical Analysis of AI-based Energy Management in Electric Vehicles: A Case Study on Reinforcement Learning
Dec 18, 2022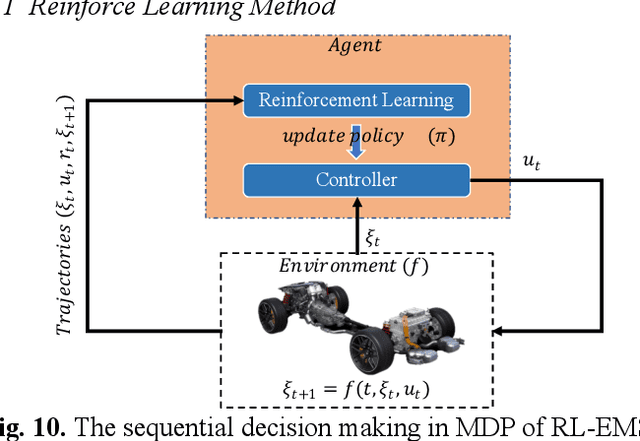
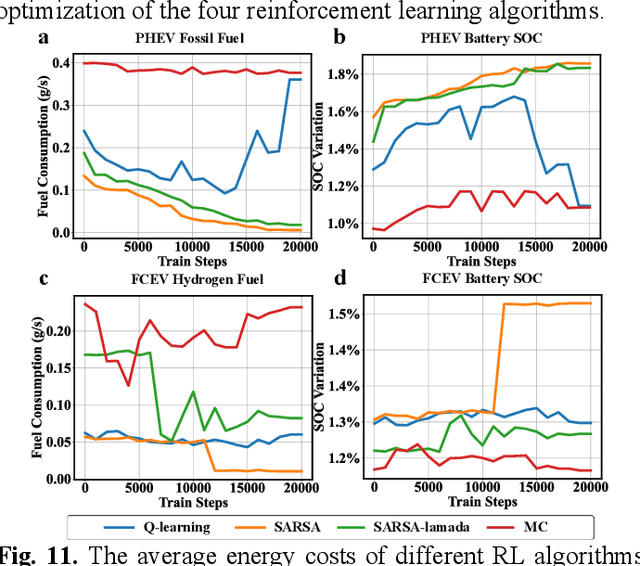
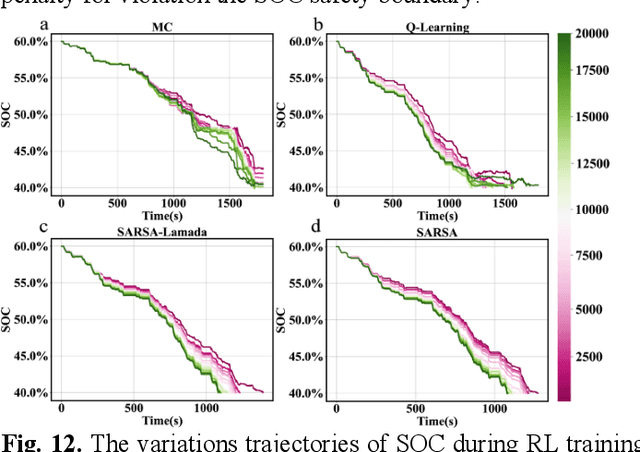
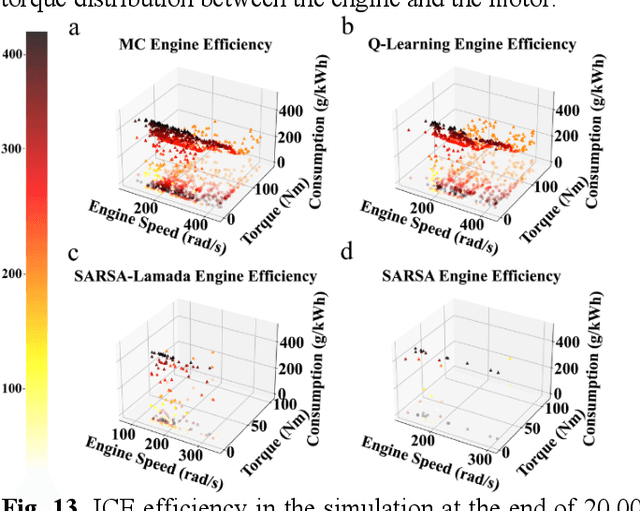
Reinforcement learning-based (RL-based) energy management strategy (EMS) is considered a promising solution for the energy management of electric vehicles with multiple power sources. It has been shown to outperform conventional methods in energy management problems regarding energy-saving and real-time performance. However, previous studies have not systematically examined the essential elements of RL-based EMS. This paper presents an empirical analysis of RL-based EMS in a Plug-in Hybrid Electric Vehicle (PHEV) and Fuel Cell Electric Vehicle (FCEV). The empirical analysis is developed in four aspects: algorithm, perception and decision granularity, hyperparameters, and reward function. The results show that the Off-policy algorithm effectively develops a more fuel-efficient solution within the complete driving cycle compared with other algorithms. Improving the perception and decision granularity does not produce a more desirable energy-saving solution but better balances battery power and fuel consumption. The equivalent energy optimization objective based on the instantaneous state of charge (SOC) variation is parameter sensitive and can help RL-EMSs to achieve more efficient energy-cost strategies.
Contextually Enhanced ES-dRNN with Dynamic Attention for Short-Term Load Forecasting
Dec 18, 2022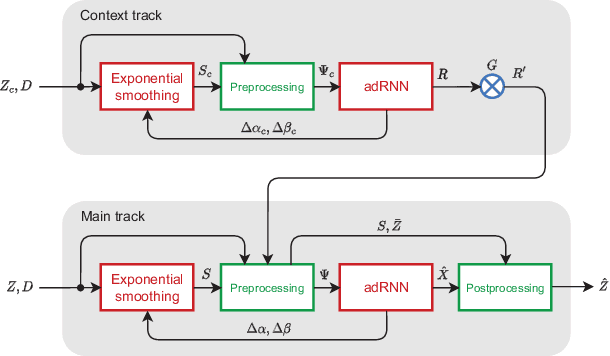
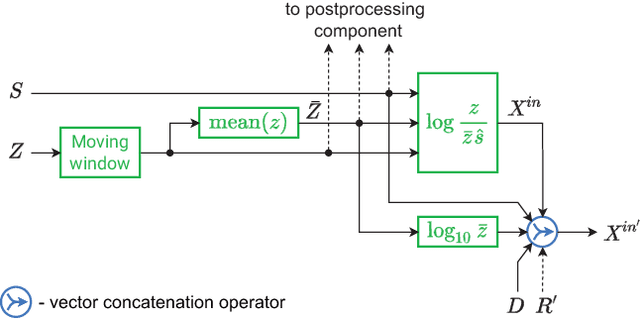
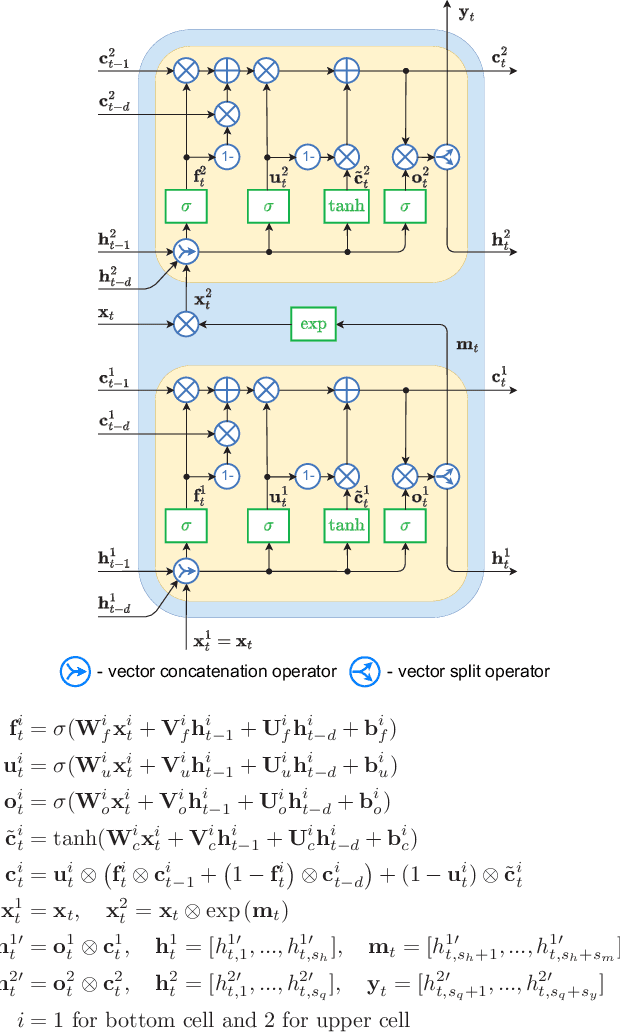
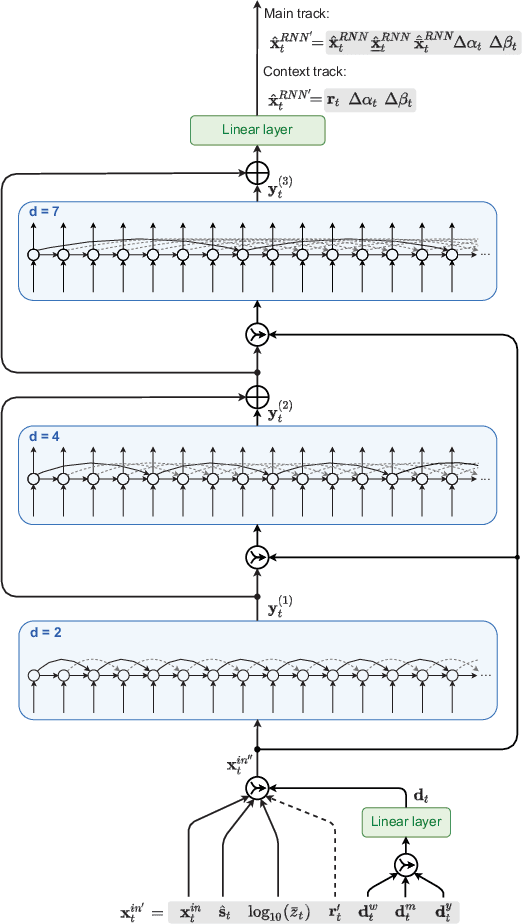
In this paper, we propose a new short-term load forecasting (STLF) model based on contextually enhanced hybrid and hierarchical architecture combining exponential smoothing (ES) and a recurrent neural network (RNN). The model is composed of two simultaneously trained tracks: the context track and the main track. The context track introduces additional information to the main track. It is extracted from representative series and dynamically modulated to adjust to the individual series forecasted by the main track. The RNN architecture consists of multiple recurrent layers stacked with hierarchical dilations and equipped with recently proposed attentive dilated recurrent cells. These cells enable the model to capture short-term, long-term and seasonal dependencies across time series as well as to weight dynamically the input information. The model produces both point forecasts and predictive intervals. The experimental part of the work performed on 35 forecasting problems shows that the proposed model outperforms in terms of accuracy its predecessor as well as standard statistical models and state-of-the-art machine learning models.