 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Real-time High-Definition Image Snow Removal: Efficient Pyramid Network with Asymmetrical Encoder-decoder Architecture
Jul 12, 2022
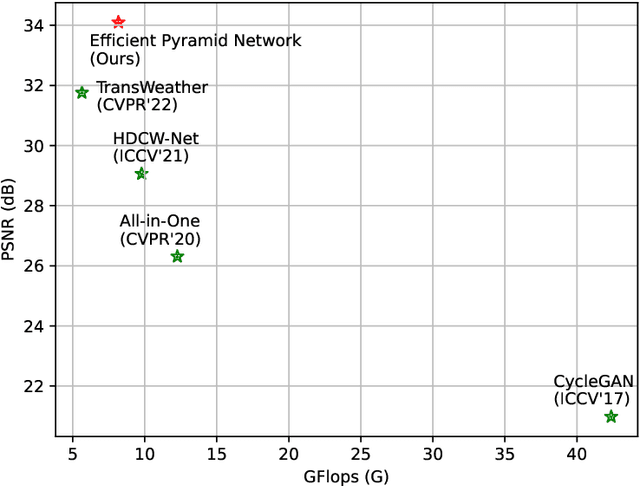
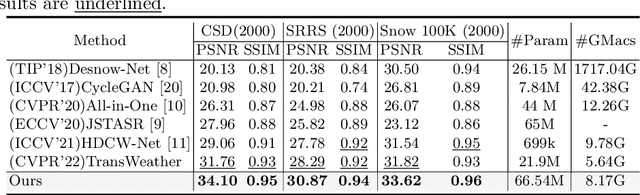
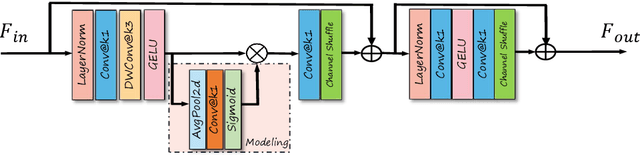

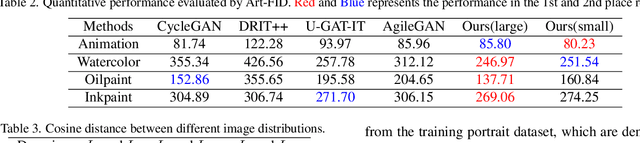
In winter scenes, the degradation of images taken under snow can be pretty complex, where the spatial distribution of snowy degradation is varied from image to image. Recent methods adopt deep neural networks to directly recover clean scenes from snowy images. However, due to the paradox caused by the variation of complex snowy degradation, achieving reliable High-Definition image desnowing performance in real time is a considerable challenge. We develop a novel Efficient Pyramid Network with asymmetrical encoder-decoder architecture for real-time HD image desnowing. The general idea of our proposed network is to utilize the multi-scale feature flow fully and implicitly mine clean cues from features. Compared with previous state-of-the-art desnowing methods, our approach achieves a better complexity-performance trade-off and effectively handles the processing difficulties of HD and Ultra-HD images. The extensive experiments on three large-scale image desnowing datasets demonstrate that our method surpasses all state-of-the-art approaches by a large margin both quantitatively and qualitatively, boosting the PSNR metric from 31.76 dB to 34.10 dB on the CSD test dataset and from 28.29 dB to 30.87 dB on the SRRS test dataset.
Continuous diffusion for categorical data
Dec 06, 2022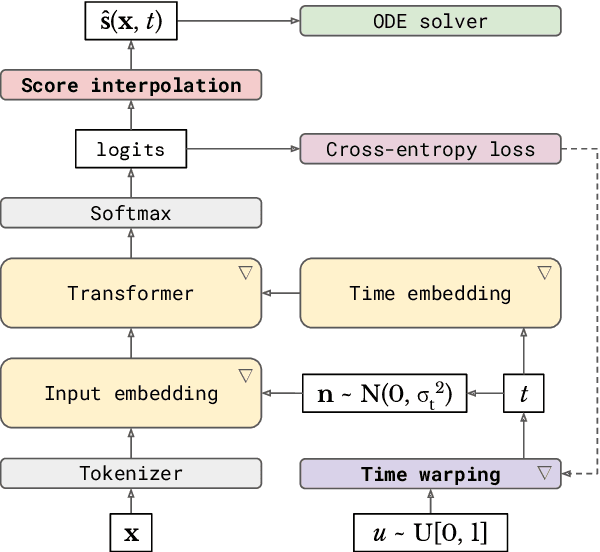
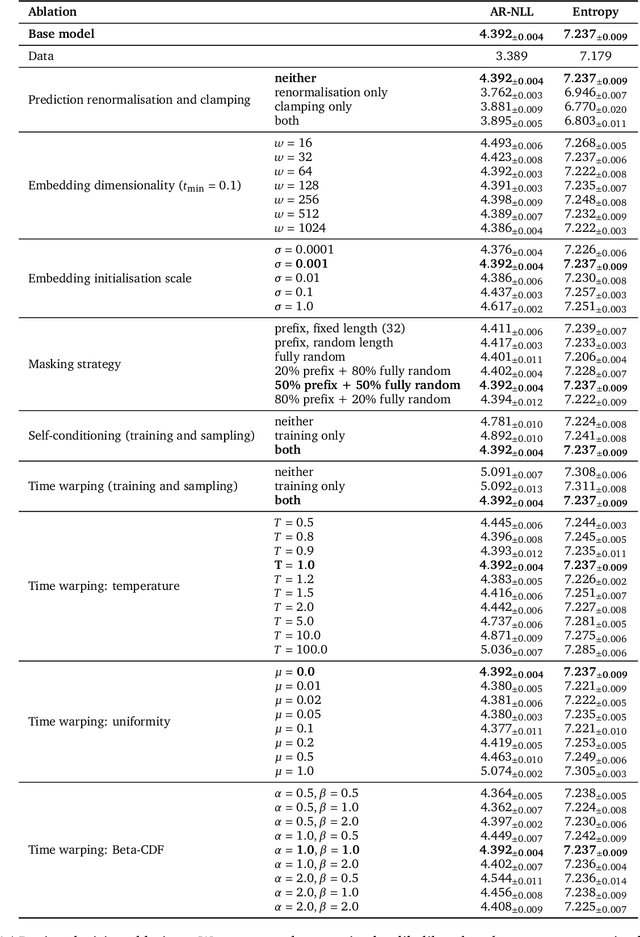
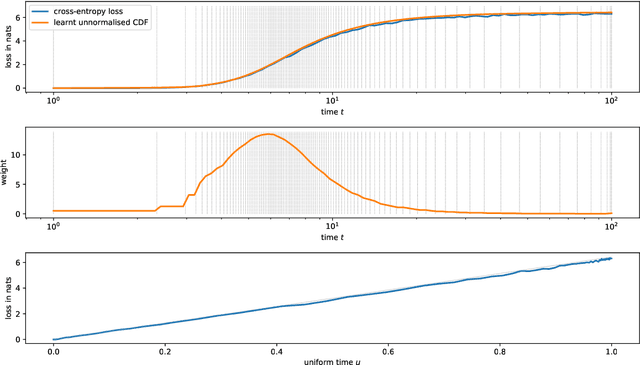
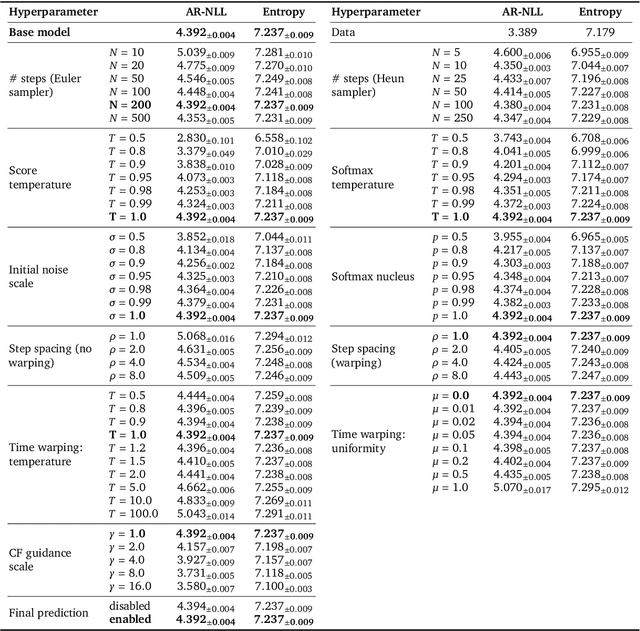
Diffusion models have quickly become the go-to paradigm for generative modelling of perceptual signals (such as images and sound) through iterative refinement. Their success hinges on the fact that the underlying physical phenomena are continuous. For inherently discrete and categorical data such as language, various diffusion-inspired alternatives have been proposed. However, the continuous nature of diffusion models conveys many benefits, and in this work we endeavour to preserve it. We propose CDCD, a framework for modelling categorical data with diffusion models that are continuous both in time and input space. We demonstrate its efficacy on several language modelling tasks.
Continuous-Time and Multi-Level Graph Representation Learning for Origin-Destination Demand Prediction
Jun 30, 2022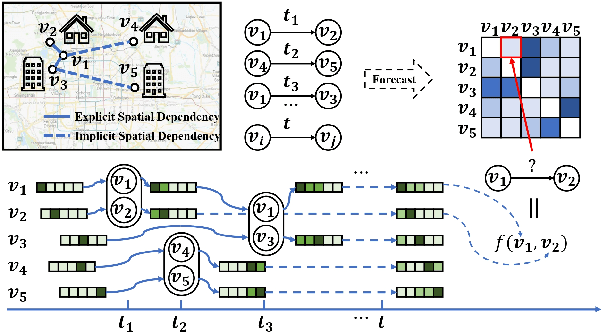
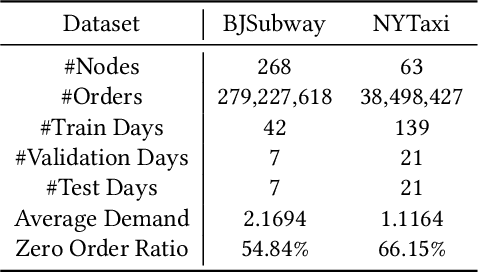
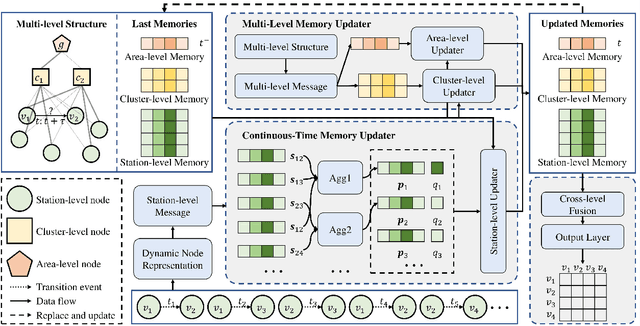
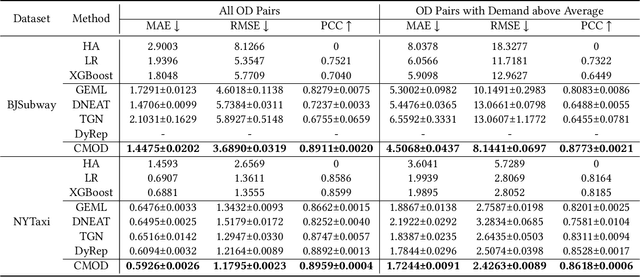
Traffic demand forecasting by deep neural networks has attracted widespread interest in both academia and industry society. Among them, the pairwise Origin-Destination (OD) demand prediction is a valuable but challenging problem due to several factors: (i) the large number of possible OD pairs, (ii) implicitness of spatial dependence, and (iii) complexity of traffic states. To address the above issues, this paper proposes a Continuous-time and Multi-level dynamic graph representation learning method for Origin-Destination demand prediction (CMOD). Firstly, a continuous-time dynamic graph representation learning framework is constructed, which maintains a dynamic state vector for each traffic node (metro stations or taxi zones). The state vectors keep historical transaction information and are continuously updated according to the most recently happened transactions. Secondly, a multi-level structure learning module is proposed to model the spatial dependency of station-level nodes. It can not only exploit relations between nodes adaptively from data, but also share messages and representations via cluster-level and area-level virtual nodes. Lastly, a cross-level fusion module is designed to integrate multi-level memories and generate comprehensive node representations for the final prediction. Extensive experiments are conducted on two real-world datasets from Beijing Subway and New York Taxi, and the results demonstrate the superiority of our model against the state-of-the-art approaches.
Time Shifts to Reduce the Size of Reservoir Computers
May 03, 2022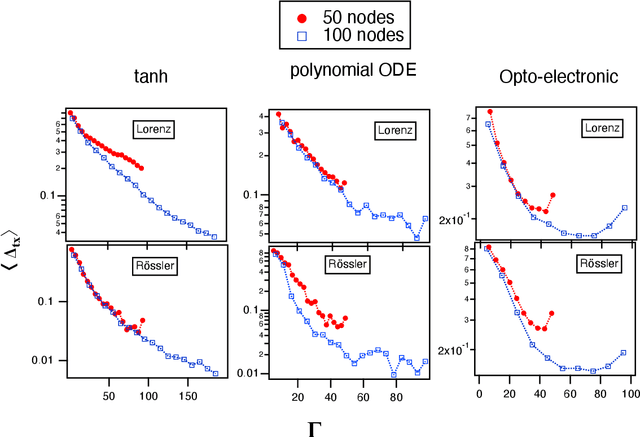
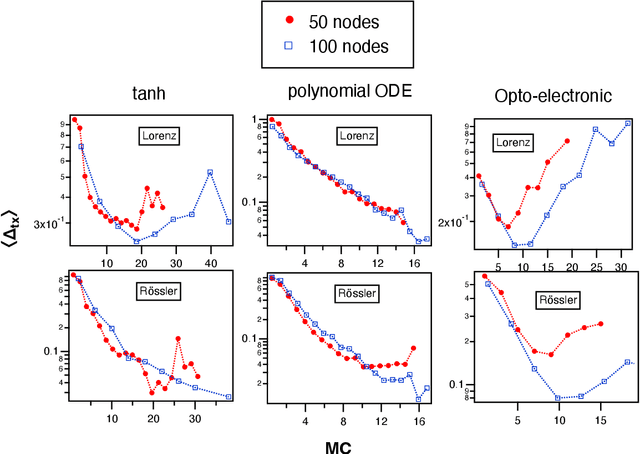
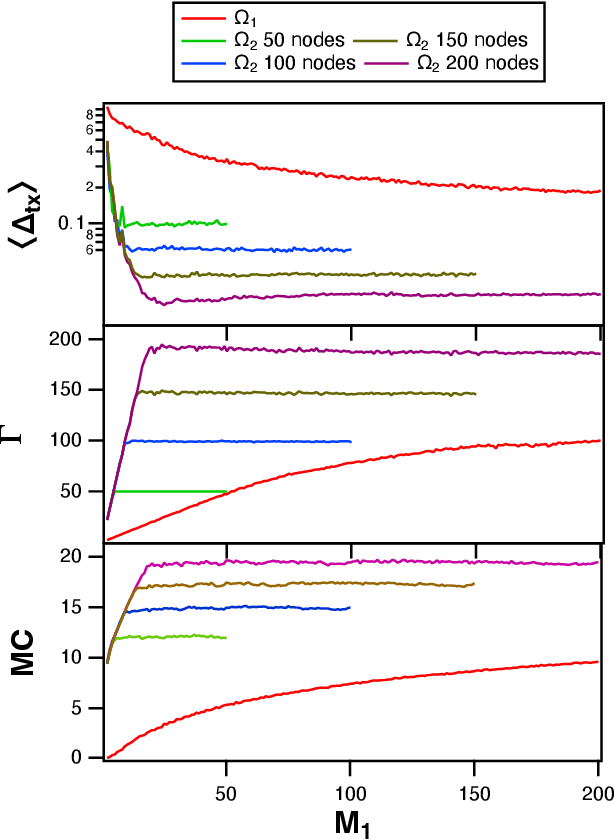
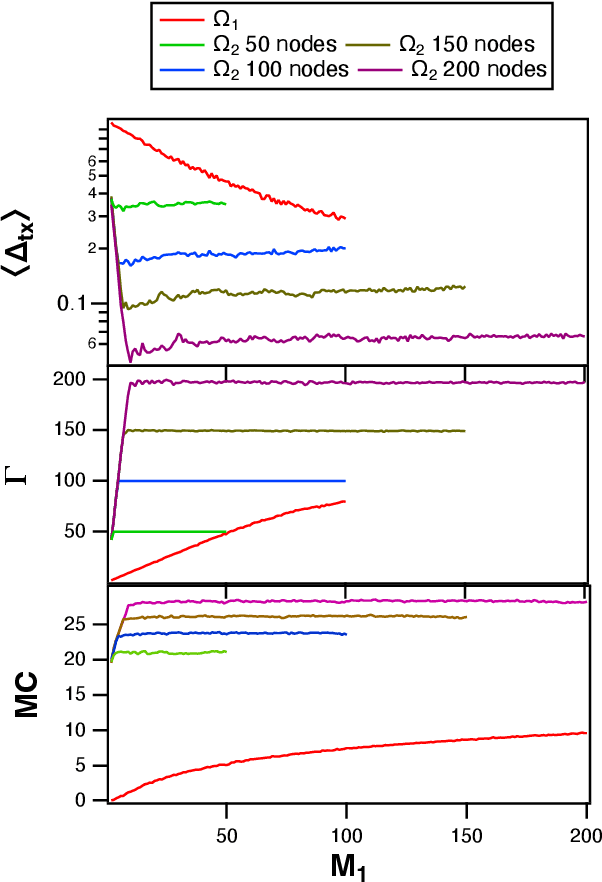
A reservoir computer is a type of dynamical system arranged to do computation. Typically, a reservoir computer is constructed by connecting a large number of nonlinear nodes in a network that includes recurrent connections. In order to achieve accurate results, the reservoir usually contains hundreds to thousands of nodes. This high dimensionality makes it difficult to analyze the reservoir computer using tools from dynamical systems theory. Additionally, the need to create and connect large numbers of nonlinear nodes makes it difficult to design and build analog reservoir computers that can be faster and consume less power than digital reservoir computers. We demonstrate here that a reservoir computer may be divided into two parts; a small set of nonlinear nodes (the reservoir), and a separate set of time-shifted reservoir output signals. The time-shifted output signals serve to increase the rank and memory of the reservoir computer, and the set of nonlinear nodes may create an embedding of the input dynamical system. We use this time-shifting technique to obtain excellent performance from an opto-electronic delay-based reservoir computer with only a small number of virtual nodes. Because only a few nonlinear nodes are required, construction of a reservoir computer becomes much easier, and delay-based reservoir computers can operate at much higher speeds.
Realtime Fewshot Portrait Stylization Based On Geometric Alignment
Nov 28, 2022
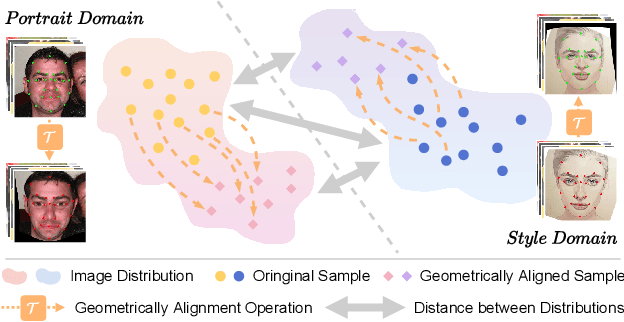
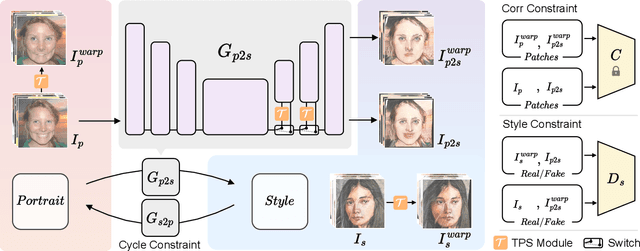
This paper presents a portrait stylization method designed for real-time mobile applications with limited style examples available. Previous learning based stylization methods suffer from the geometric and semantic gaps between portrait domain and style domain, which obstacles the style information to be correctly transferred to the portrait images, leading to poor stylization quality. Based on the geometric prior of human facial attributions, we propose to utilize geometric alignment to tackle this issue. Firstly, we apply Thin-Plate-Spline (TPS) on feature maps in the generator network and also directly to style images in pixel space, generating aligned portrait-style image pairs with identical landmarks, which closes the geometric gaps between two domains. Secondly, adversarial learning maps the textures and colors of portrait images to the style domain. Finally, geometric aware cycle consistency preserves the content and identity information unchanged, and deformation invariant constraint suppresses artifacts and distortions. Qualitative and quantitative comparison validate our method outperforms existing methods, and experiments proof our method could be trained with limited style examples (100 or less) in real-time (more than 40 FPS) on mobile devices. Ablation study demonstrates the effectiveness of each component in the framework.
Fast Non-Rigid Radiance Fields from Monocularized Data
Dec 02, 2022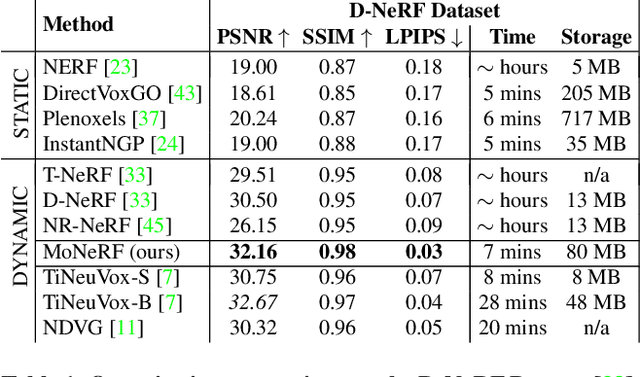
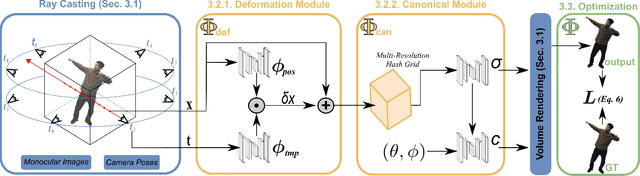
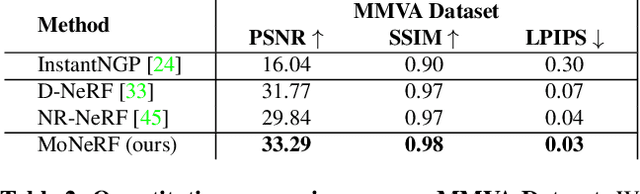

3D reconstruction and novel view synthesis of dynamic scenes from collections of single views recently gained increased attention. Existing work shows impressive results for synthetic setups and forward-facing real-world data, but is severely limited in the training speed and angular range for generating novel views. This paper addresses these limitations and proposes a new method for full 360{\deg} novel view synthesis of non-rigidly deforming scenes. At the core of our method are: 1) An efficient deformation module that decouples the processing of spatial and temporal information for acceleration at training and inference time; and 2) A static module representing the canonical scene as a fast hash-encoded neural radiance field. We evaluate the proposed approach on the established synthetic D-NeRF benchmark, that enables efficient reconstruction from a single monocular view per time-frame randomly sampled from a full hemisphere. We refer to this form of inputs as monocularized data. To prove its practicality for real-world scenarios, we recorded twelve challenging sequences with human actors by sampling single frames from a synchronized multi-view rig. In both cases, our method is trained significantly faster than previous methods (minutes instead of days) while achieving higher visual accuracy for generated novel views. Our source code and data is available at our project page https://graphics.tu-bs.de/publications/kappel2022fast.
GFPose: Learning 3D Human Pose Prior with Gradient Fields
Dec 16, 2022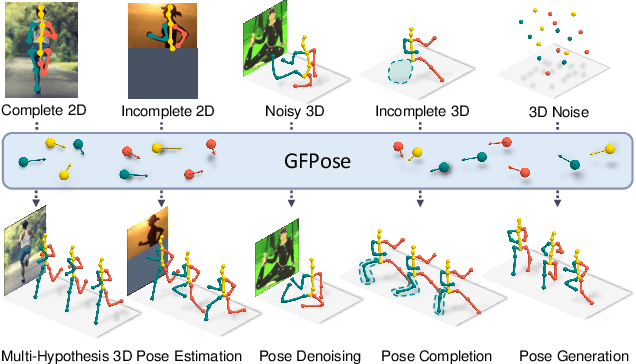
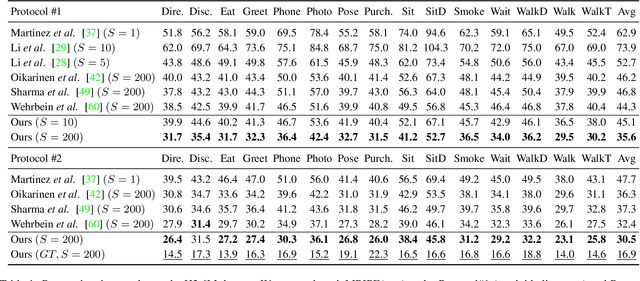

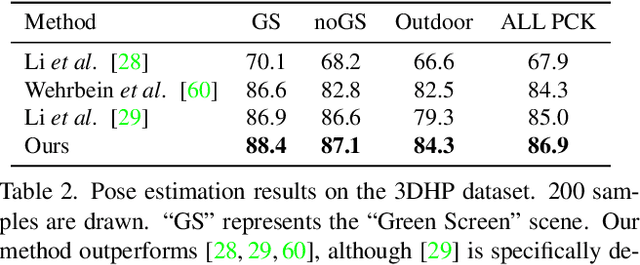
Learning 3D human pose prior is essential to human-centered AI. Here, we present GFPose, a versatile framework to model plausible 3D human poses for various applications. At the core of GFPose is a time-dependent score network, which estimates the gradient on each body joint and progressively denoises the perturbed 3D human pose to match a given task specification. During the denoising process, GFPose implicitly incorporates pose priors in gradients and unifies various discriminative and generative tasks in an elegant framework. Despite the simplicity, GFPose demonstrates great potential in several downstream tasks. Our experiments empirically show that 1) as a multi-hypothesis pose estimator, GFPose outperforms existing SOTAs by 20% on Human3.6M dataset. 2) as a single-hypothesis pose estimator, GFPose achieves comparable results to deterministic SOTAs, even with a vanilla backbone. 3) GFPose is able to produce diverse and realistic samples in pose denoising, completion and generation tasks. Project page https://sites.google.com/view/gfpose/
DopplerBAS: Binaural Audio Synthesis Addressing Doppler Effect
Dec 16, 2022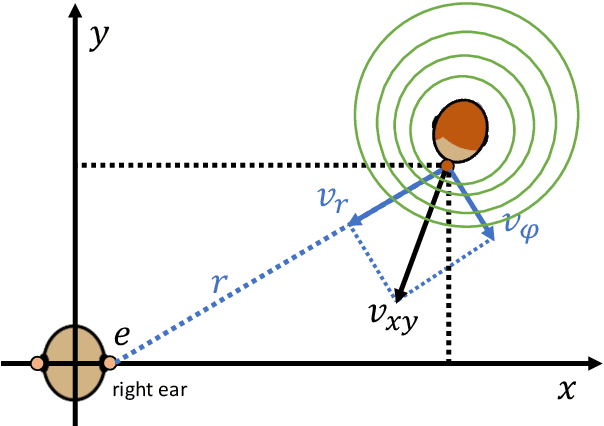
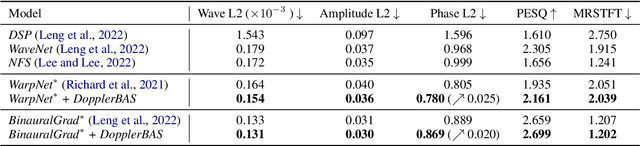
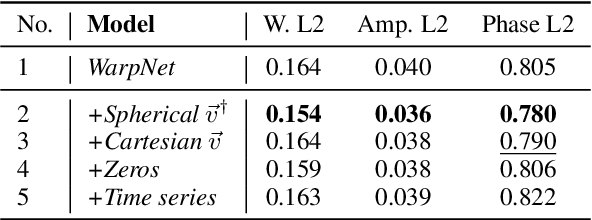
Recently, binaural audio synthesis (BAS) has emerged as a promising research field for its applications in augmented and virtual realities. Binaural audio helps us to orient ourselves and establish immersion by providing the brain with interaural time differences reflecting spatial information. However, existing methods are limited in terms of phase estimation, which is crucial for spatial hearing. In this paper, we propose the DopplerBAS method to explicitly address the Doppler effect of the moving sound source. Specifically, we calculate the radial relative velocity of the moving speaker in spherical coordinates, which further guides the synthesis of binaural audio. This simple method neither introduces any additional hyper-parameters nor modifies the loss functions, and is plug-and-play: it scales well to different types of backbones. DopplerBAS distinctly improves WarpNet and BinauralGrad in the phase error metric and reaches a new state-of-the-art: 0.780 (vs. the current state-of-the-art 0.807). Experiments and ablation studies demonstrate the effectiveness of our method.
Detection-aware multi-object tracking evaluation
Dec 16, 2022
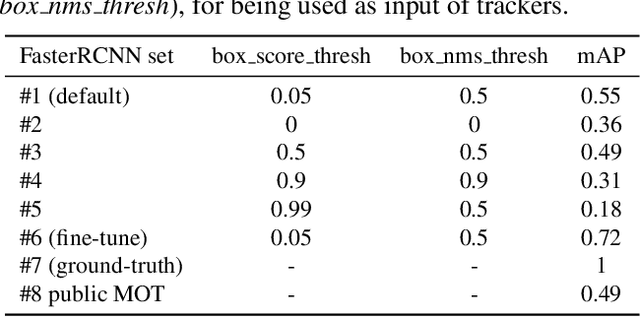
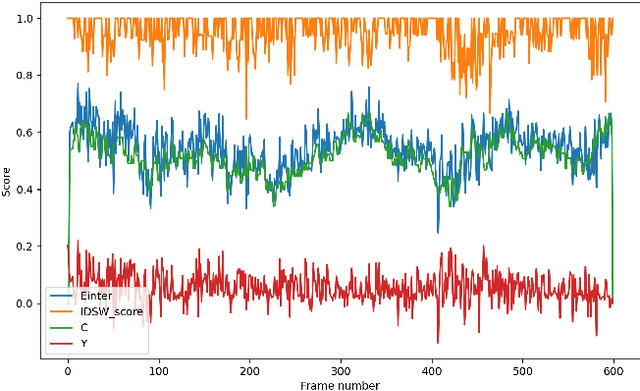
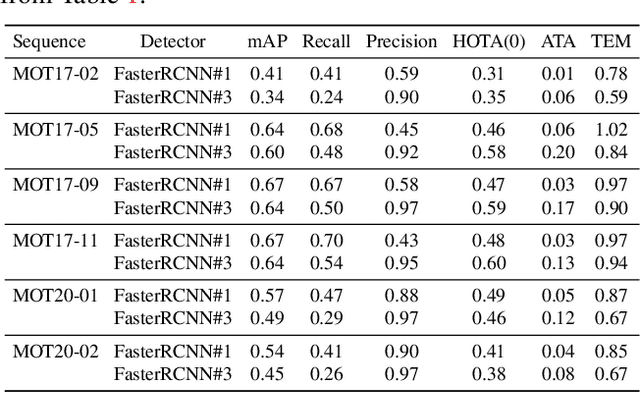
How would you fairly evaluate two multi-object tracking algorithms (i.e. trackers), each one employing a different object detector? Detectors keep improving, thus trackers can make less effort to estimate object states over time. Is it then fair to compare a new tracker employing a new detector with another tracker using an old detector? In this paper, we propose a novel performance measure, named Tracking Effort Measure (TEM), to evaluate trackers that use different detectors. TEM estimates the improvement that the tracker does with respect to its input data (i.e. detections) at frame level (intra-frame complexity) and sequence level (inter-frame complexity). We evaluate TEM over well-known datasets, four trackers and eight detection sets. Results show that, unlike conventional tracking evaluation measures, TEM can quantify the effort done by the tracker with a reduced correlation on the input detections. Its implementation is publicly available online at https://github.com/vpulab/MOT-evaluation.
One-shot domain adaptation in video-based assessment of surgical skills
Dec 16, 2022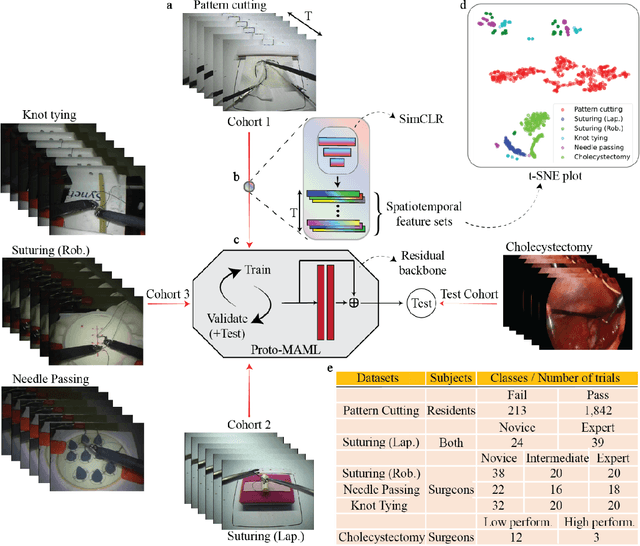

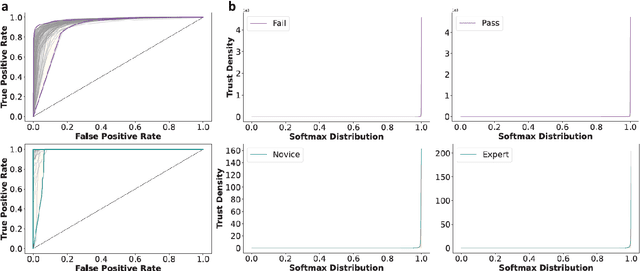
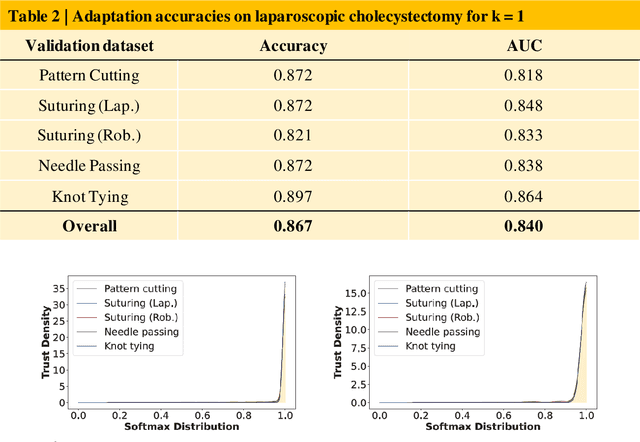
Deep Learning (DL) has achieved automatic and objective assessment of surgical skills. However, DL models are data-hungry and restricted to their training domain. This prevents them from transitioning to new tasks where data is limited. Hence, domain adaptation is crucial to implement DL in real life. Here, we propose a meta-learning model, A-VBANet, that can deliver domain-agnostic surgical skill classification via one-shot learning. We develop the A-VBANet on five laparoscopic and robotic surgical simulators. Additionally, we test it on operating room (OR) videos of laparoscopic cholecystectomy. Our model successfully adapts with accuracies up to 99.5% in one-shot and 99.9% in few-shot settings for simulated tasks and 89.7% for laparoscopic cholecystectomy. For the first time, we provide a domain-agnostic procedure for video-based assessment of surgical skills. A significant implication of this approach is that it allows the use of data from surgical simulators to assess performance in the operating room.