 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stars: Tera-Scale Graph Building for Clustering and Graph Learning
Dec 05, 2022

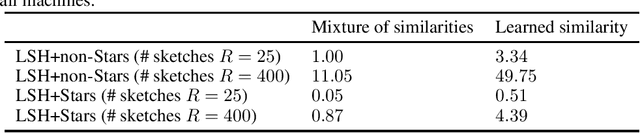
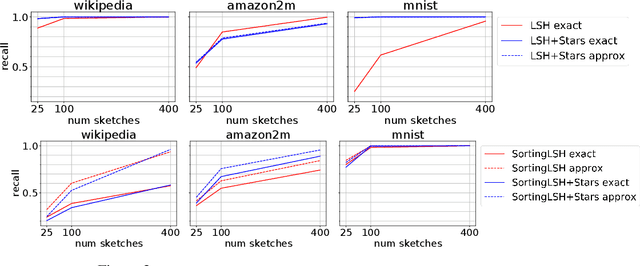

A fundamental procedure in the analysis of massive datasets is the construction of similarity graphs. Such graphs play a key role for many downstream tasks, including clustering, classification, graph learning, and nearest neighbor search. For these tasks, it is critical to build graphs which are sparse yet still representative of the underlying data. The benefits of sparsity are twofold: firstly, constructing dense graphs is infeasible in practice for large datasets, and secondly, the runtime of downstream tasks is directly influenced by the sparsity of the similarity graph. In this work, we present $\textit{Stars}$: a highly scalable method for building extremely sparse graphs via two-hop spanners, which are graphs where similar points are connected by a path of length at most two. Stars can construct two-hop spanners with significantly fewer similarity comparisons, which are a major bottleneck for learning based models where comparisons are expensive to evaluate. Theoretically, we demonstrate that Stars builds a graph in nearly-linear time, where approximate nearest neighbors are contained within two-hop neighborhoods. In practice, we have deployed Stars for multiple data sets allowing for graph building at the $\textit{Tera-Scale}$, i.e., for graphs with tens of trillions of edges. We evaluate the performance of Stars for clustering and graph learning, and demonstrate 10~1000-fold improvements in pairwise similarity comparisons compared to different baselines, and 2~10-fold improvement in running time without quality loss.
Unsupervised Representation Learning from Pre-trained Diffusion Probabilistic Models
Jan 01, 2023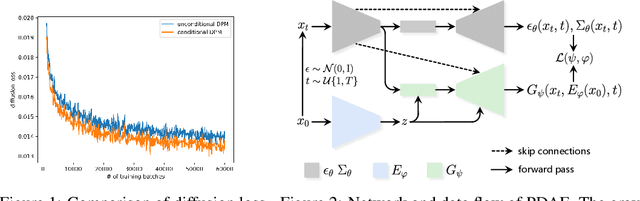
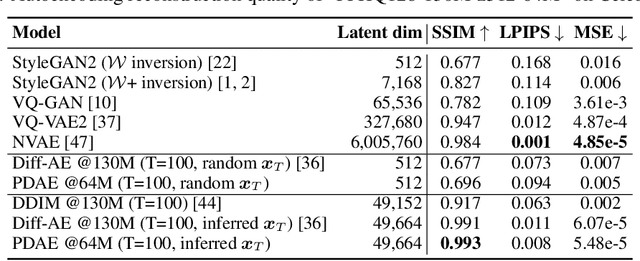


Diffusion Probabilistic Models (DPMs) have shown a powerful capacity of generating high-quality image samples. Recently, diffusion autoencoders (Diff-AE) have been proposed to explore DPMs for representation learning via autoencoding. Their key idea is to jointly train an encoder for discovering meaningful representations from images and a conditional DPM as the decoder for reconstructing images. Considering that training DPMs from scratch will take a long time and there have existed numerous pre-trained DPMs, we propose \textbf{P}re-trained \textbf{D}PM \textbf{A}uto\textbf{E}ncoding (\textbf{PDAE}), a general method to adapt existing pre-trained DPMs to the decoders for image reconstruction, with better training efficiency and performance than Diff-AE. Specifically, we find that the reason that pre-trained DPMs fail to reconstruct an image from its latent variables is due to the information loss of forward process, which causes a gap between their predicted posterior mean and the true one. From this perspective, the classifier-guided sampling method can be explained as computing an extra mean shift to fill the gap, reconstructing the lost class information in samples. These imply that the gap corresponds to the lost information of the image, and we can reconstruct the image by filling the gap. Drawing inspiration from this, we employ a trainable model to predict a mean shift according to encoded representation and train it to fill as much gap as possible, in this way, the encoder is forced to learn as much information as possible from images to help the filling. By reusing a part of network of pre-trained DPMs and redesigning the weighting scheme of diffusion loss, PDAE can learn meaningful representations from images efficiently. Extensive experiments demonstrate the effectiveness, efficiency and flexibility of PDAE.
Continuous-Time and Multi-Level Graph Representation Learning for Origin-Destination Demand Prediction
Jun 30, 2022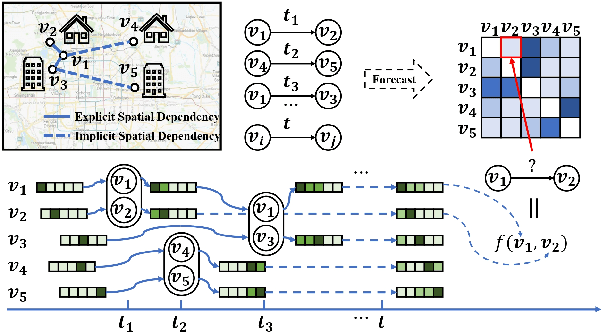
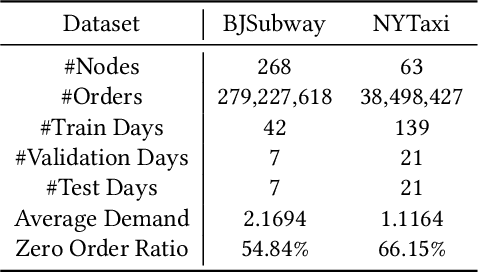
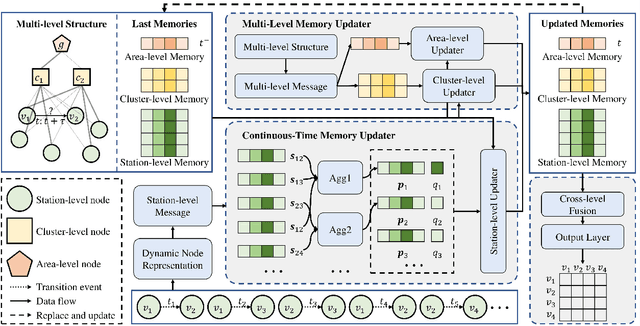
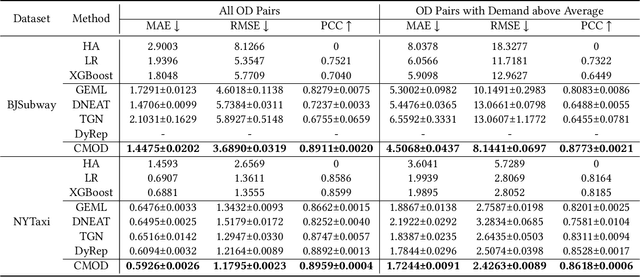
Traffic demand forecasting by deep neural networks has attracted widespread interest in both academia and industry society. Among them, the pairwise Origin-Destination (OD) demand prediction is a valuable but challenging problem due to several factors: (i) the large number of possible OD pairs, (ii) implicitness of spatial dependence, and (iii) complexity of traffic states. To address the above issues, this paper proposes a Continuous-time and Multi-level dynamic graph representation learning method for Origin-Destination demand prediction (CMOD). Firstly, a continuous-time dynamic graph representation learning framework is constructed, which maintains a dynamic state vector for each traffic node (metro stations or taxi zones). The state vectors keep historical transaction information and are continuously updated according to the most recently happened transactions. Secondly, a multi-level structure learning module is proposed to model the spatial dependency of station-level nodes. It can not only exploit relations between nodes adaptively from data, but also share messages and representations via cluster-level and area-level virtual nodes. Lastly, a cross-level fusion module is designed to integrate multi-level memories and generate comprehensive node representations for the final prediction. Extensive experiments are conducted on two real-world datasets from Beijing Subway and New York Taxi, and the results demonstrate the superiority of our model against the state-of-the-art approaches.
Annotated History of Modern AI and Deep Learning
Dec 29, 2022Machine learning is the science of credit assignment: finding patterns in observations that predict the consequences of actions and help to improve future performance. Credit assignment is also required for human understanding of how the world works, not only for individuals navigating daily life, but also for academic professionals like historians who interpret the present in light of past events. Here I focus on the history of modern artificial intelligence (AI) which is dominated by artificial neural networks (NNs) and deep learning, both conceptually closer to the old field of cybernetics than to what's been called AI since 1956 (e.g., expert systems and logic programming). A modern history of AI will emphasize breakthroughs outside of the focus of traditional AI text books, in particular, mathematical foundations of today's NNs such as the chain rule (1676), the first NNs (linear regression, circa 1800), and the first working deep learners (1965-). From the perspective of 2022, I provide a timeline of the -- in hindsight -- most important relevant events in the history of NNs, deep learning, AI, computer science, and mathematics in general, crediting those who laid foundations of the field. The text contains numerous hyperlinks to relevant overview sites from my AI Blog. It supplements my previous deep learning survey (2015) which provides hundreds of additional references. Finally, to round it off, I'll put things in a broader historic context spanning the time since the Big Bang until when the universe will be many times older than it is now.
Towards Real-time High-Definition Image Snow Removal: Efficient Pyramid Network with Asymmetrical Encoder-decoder Architecture
Jul 12, 2022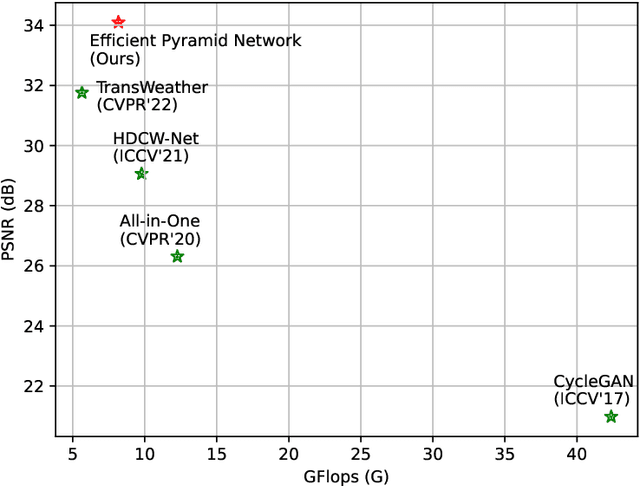
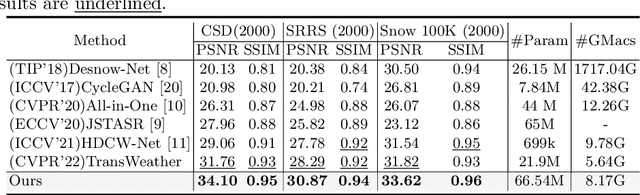
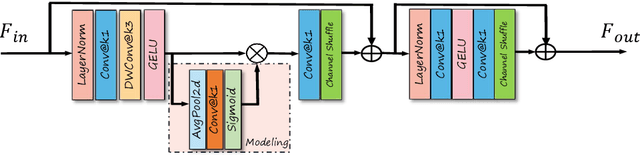

In winter scenes, the degradation of images taken under snow can be pretty complex, where the spatial distribution of snowy degradation is varied from image to image. Recent methods adopt deep neural networks to directly recover clean scenes from snowy images. However, due to the paradox caused by the variation of complex snowy degradation, achieving reliable High-Definition image desnowing performance in real time is a considerable challenge. We develop a novel Efficient Pyramid Network with asymmetrical encoder-decoder architecture for real-time HD image desnowing. The general idea of our proposed network is to utilize the multi-scale feature flow fully and implicitly mine clean cues from features. Compared with previous state-of-the-art desnowing methods, our approach achieves a better complexity-performance trade-off and effectively handles the processing difficulties of HD and Ultra-HD images. The extensive experiments on three large-scale image desnowing datasets demonstrate that our method surpasses all state-of-the-art approaches by a large margin both quantitatively and qualitatively, boosting the PSNR metric from 31.76 dB to 34.10 dB on the CSD test dataset and from 28.29 dB to 30.87 dB on the SRRS test dataset.
Intelligent Reflecting Surface Assisted Secret Key Generation Under Spatially Correlated Channels in Quasi-Static Environments
Dec 03, 2022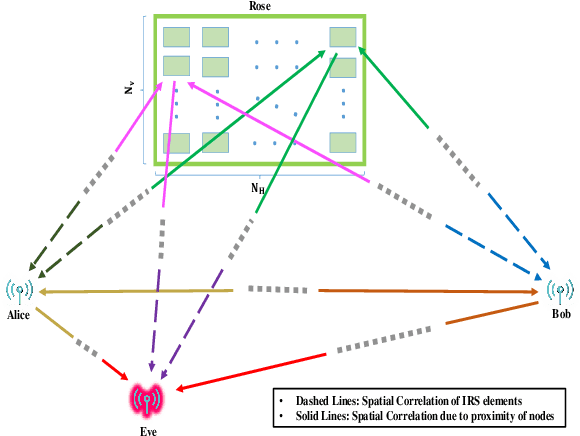
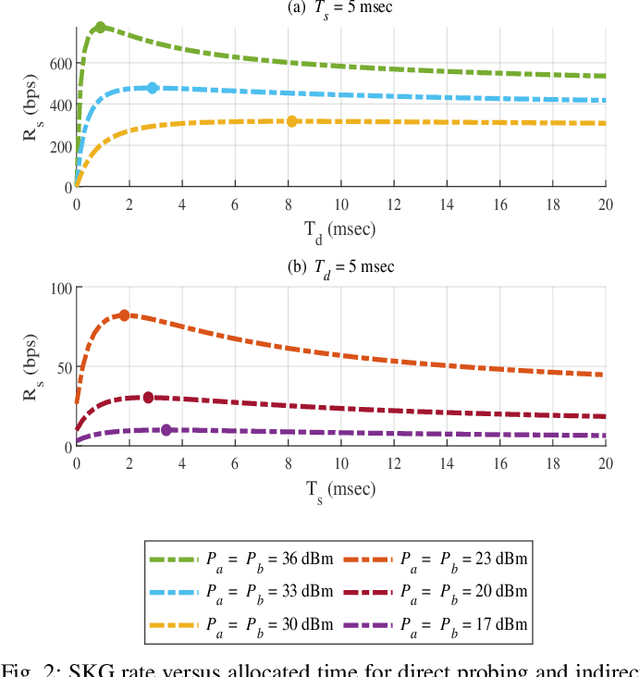
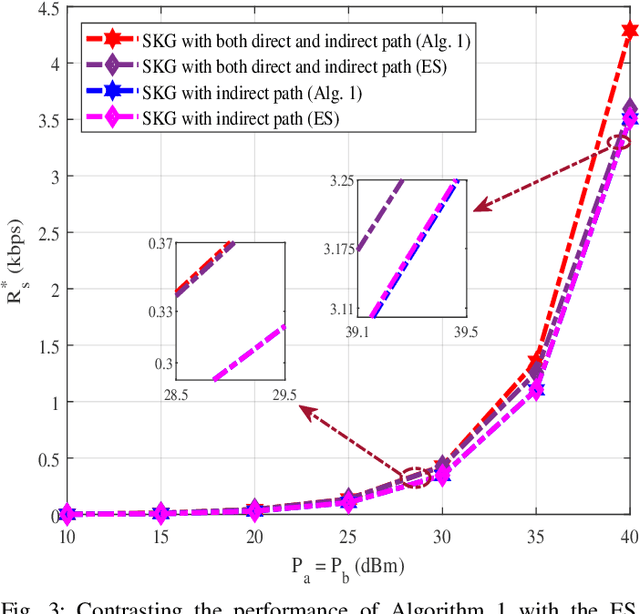
Physical layer key generation (PLKG) can significantly enhance the security of classic encryption schemes by enabling them to change their secret keys significantly faster and more efficient. However, due to the reliance of PLKG techniques on channel medium, reaching a high secret key rate is challenging in static environments. Recently, exploiting intelligent reflecting surface (IRS) as a means to induce randomness in static wireless channels has received significant research interest. However, the impact of spatial correlation between the IRS elements is rarely studied. To be specific, for the first time, in this contribution, we take into account a spatially correlated IRS which intends to enhance the secret key generation (SKG) rate in a static medium. Closed form analytical expressions for SKG rate are derived for the two cases of random phase shift and equal random phase shift for all the IRS elements. We also analyze the temporal correlation between the channel samples to ensure the randomness of the generated secret key sequence. We further formulate an optimization problem in which we determine the optimal portion of time within a coherence interval dedicated for the direct and indirect channel estimation. We show the accuracy and the fast convergence of our proposed sequential convex programming (SCP) based algorithm and discuss the various parameters affecting spatially correlated IRS assisted PLKG.
Near Sample-Optimal Reduction-based Policy Learning for Average Reward MDP
Dec 01, 2022
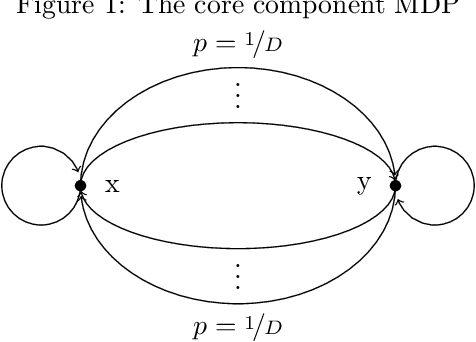
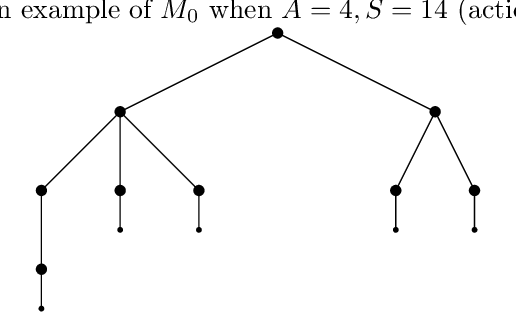
This work considers the sample complexity of obtaining an $\varepsilon$-optimal policy in an average reward Markov Decision Process (AMDP), given access to a generative model (simulator). When the ground-truth MDP is weakly communicating, we prove an upper bound of $\widetilde O(H \varepsilon^{-3} \ln \frac{1}{\delta})$ samples per state-action pair, where $H := sp(h^*)$ is the span of bias of any optimal policy, $\varepsilon$ is the accuracy and $\delta$ is the failure probability. This bound improves the best-known mixing-time-based approaches in [Jin & Sidford 2021], which assume the mixing-time of every deterministic policy is bounded. The core of our analysis is a proper reduction bound from AMDP problems to discounted MDP (DMDP) problems, which may be of independent interests since it allows the application of DMDP algorithms for AMDP in other settings. We complement our upper bound by proving a minimax lower bound of $\Omega(|\mathcal S| |\mathcal A| H \varepsilon^{-2} \ln \frac{1}{\delta})$ total samples, showing that a linear dependent on $H$ is necessary and that our upper bound matches the lower bound in all parameters of $(|\mathcal S|, |\mathcal A|, H, \ln \frac{1}{\delta})$ up to some logarithmic factors.
A Large-Scale Annotated Multivariate Time Series Aviation Maintenance Dataset from the NGAFID
Oct 13, 2022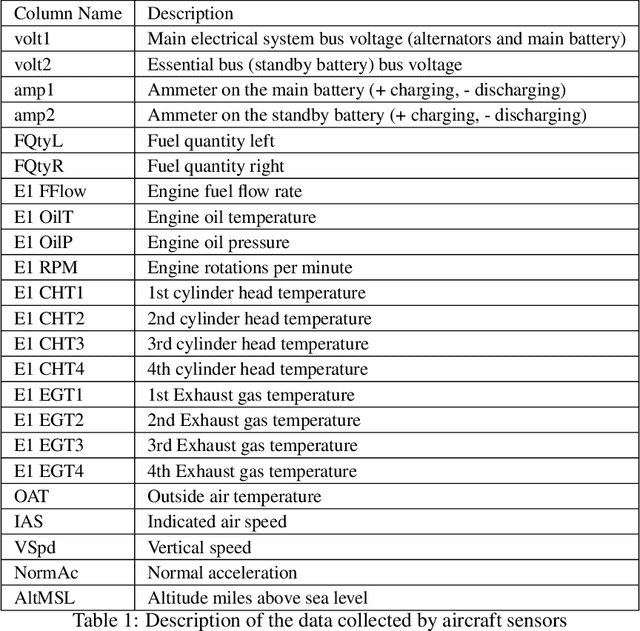
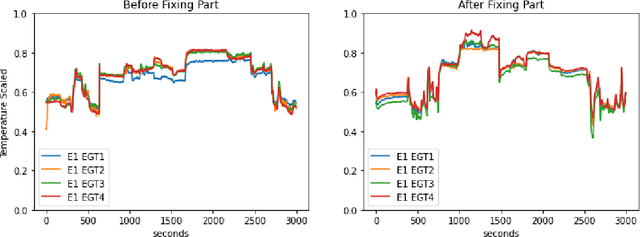
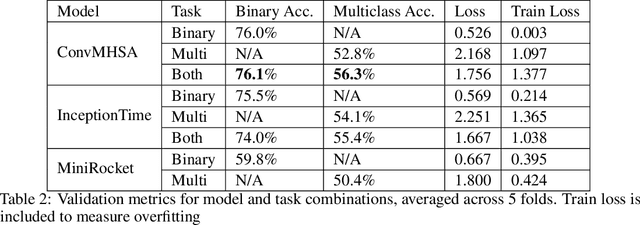
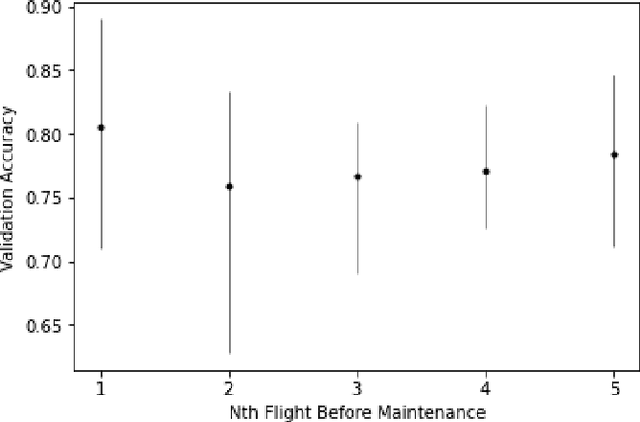
This paper presents the largest publicly available, non-simulated, fleet-wide aircraft flight recording and maintenance log data for use in predicting part failure and maintenance need. We present 31,177 hours of flight data across 28,935 flights, which occur relative to 2,111 unplanned maintenance events clustered into 36 types of maintenance issues. Flights are annotated as before or after maintenance, with some flights occurring on the day of maintenance. Collecting data to evaluate predictive maintenance systems is challenging because it is difficult, dangerous, and unethical to generate data from compromised aircraft. To overcome this, we use the National General Aviation Flight Information Database (NGAFID), which contains flights recorded during regular operation of aircraft, and maintenance logs to construct a part failure dataset. We use a novel framing of Remaining Useful Life (RUL) prediction and consider the probability that the RUL of a part is greater than 2 days. Unlike previous datasets generated with simulations or in laboratory settings, the NGAFID Aviation Maintenance Dataset contains real flight records and maintenance logs from different seasons, weather conditions, pilots, and flight patterns. Additionally, we provide Python code to easily download the dataset and a Colab environment to reproduce our benchmarks on three different models. Our dataset presents a difficult challenge for machine learning researchers and a valuable opportunity to test and develop prognostic health management methods
DeepMB: Deep neural network for real-time model-based optoacoustic image reconstruction with adjustable speed of sound
Jun 29, 2022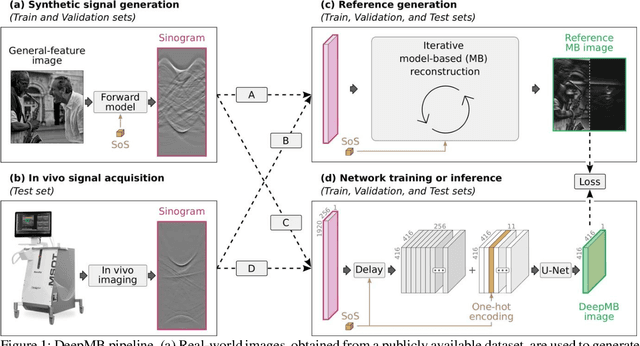
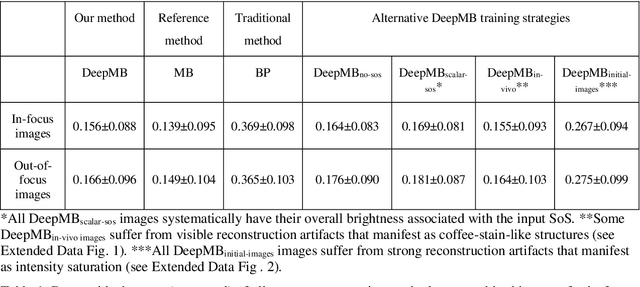

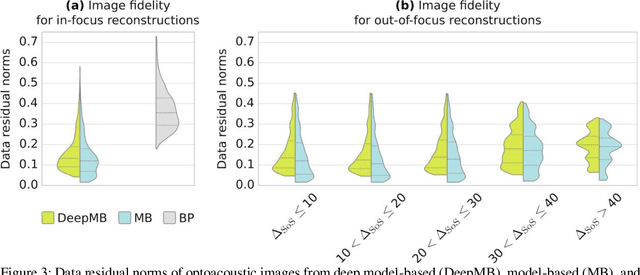
Multispectral optoacoustic tomography (MSOT) is a high-resolution functional imaging modality that can non-invasively access a broad range of pathophysiological phenomena by quantifying the contrast of endogenous chromophores in tissue. Real-time imaging is imperative to translate MSOT into clinical imaging, visualize dynamic pathophysiological changes associated with disease progression, and enable in situ diagnoses. Model-based reconstruction affords state-of-the-art optoacoustic images; however, the advanced image quality provided by model-based reconstruction remains inaccessible during real-time imaging because the algorithm is iterative and computationally demanding. Deep-learning may afford faster reconstructions for real-time optoacoustic imaging, but existing approaches only support oversimplified imaging settings and fail to generalize to in vivo data. In this work, we introduce a novel deep-learning framework, termed DeepMB, to learn the model-based reconstruction operator and infer optoacoustic images with state-of-the-art quality in less than 10 ms per image. DeepMB accurately generalizes to in vivo data after training on synthesized sinograms that are derived from real-world images. The framework affords in-focus images for a broad range of anatomical locations because it supports dynamic adjustment of the reconstruction speed of sound during imaging. Furthermore, DeepMB is compatible with the data rates and image sizes of modern multispectral optoacoustic tomography scanners. We evaluate DeepMB on a diverse dataset of in vivo images and demonstrate that the framework reconstructs images 3000 times faster than the iterative model-based reference method while affording near-identical image qualities. Accurate and real-time image reconstructions with DeepMB can enable full access to the high-resolution and multispectral contrast of handheld optoacoustic tomography.
Two-Step Online Trajectory Planning of a Quadcopter in Indoor Environments with Obstacles
Nov 14, 2022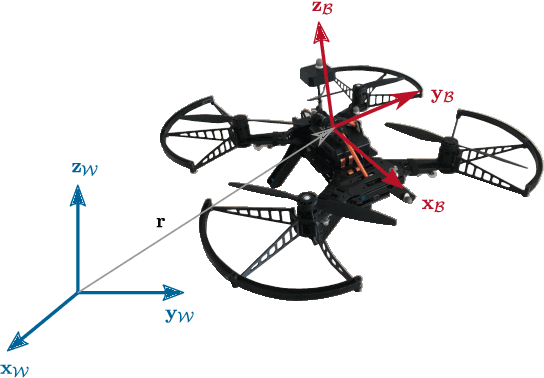
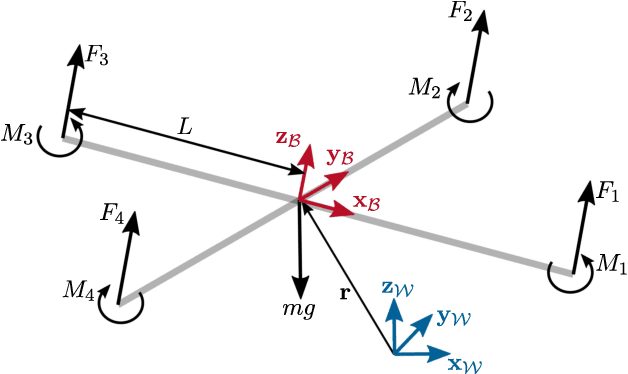
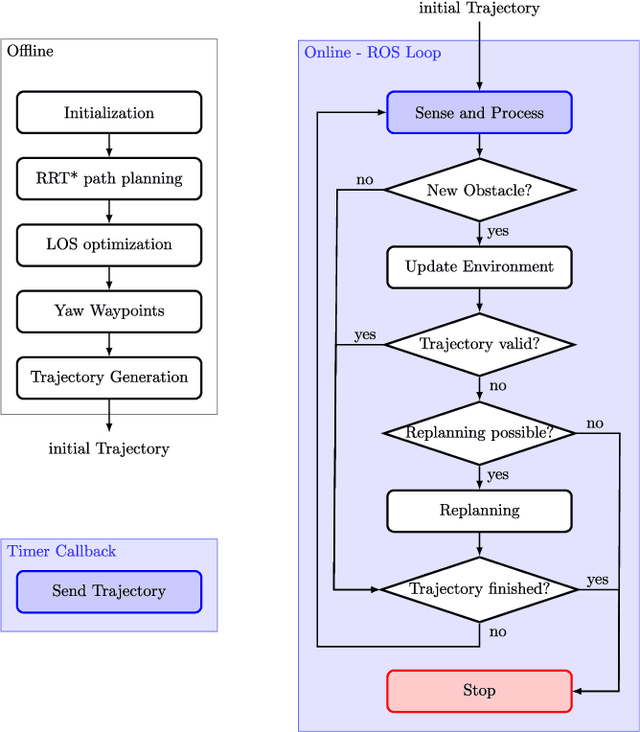
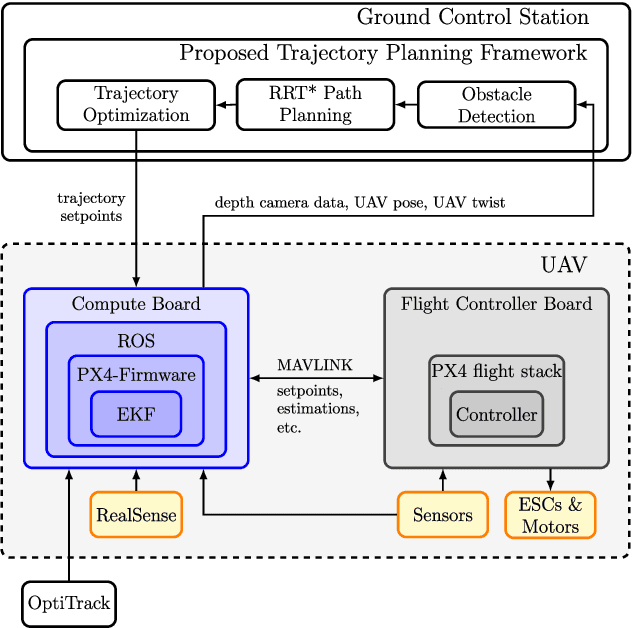
This paper presents a two-step algorithm for online trajectory planning in indoor environments with unknown obstacles. In the first step, sampling-based path planning techniques such as the optimal Rapidly exploring Random Tree (RRT*) algorithm and the Line-of-Sight (LOS) algorithm are employed to generate a collision-free path consisting of multiple waypoints. Then, in the second step, constrained quadratic programming is utilized to compute a smooth trajectory that passes through all computed waypoints. The main contribution of this work is the development of a flexible trajectory planning framework that can detect changes in the environment, such as new obstacles, and compute alternative trajectories in real time. The proposed algorithm actively considers all changes in the environment and performs the replanning process only on waypoints that are occupied by new obstacles. This helps to reduce the computation time and realize the proposed approach in real time. The feasibility of the proposed algorithm is evaluated using the Intel Aero Ready-to-Fly (RTF) quadcopter in simulation and in a real-world experiment.