 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Better Fit: Accommodate Variations in Clothing Types for Virtual Try-on
Mar 13, 2024
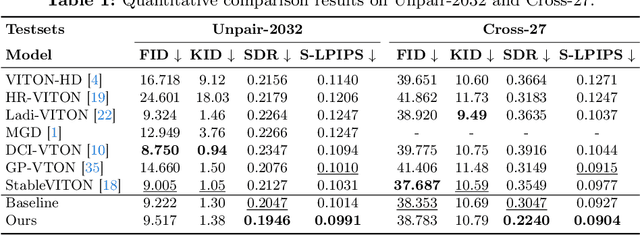
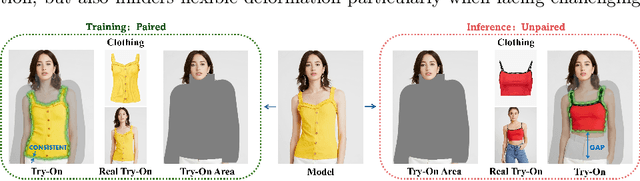
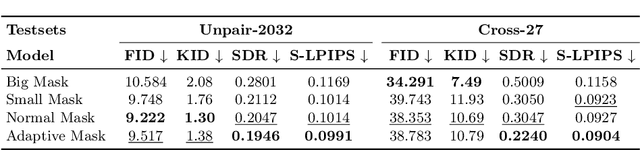
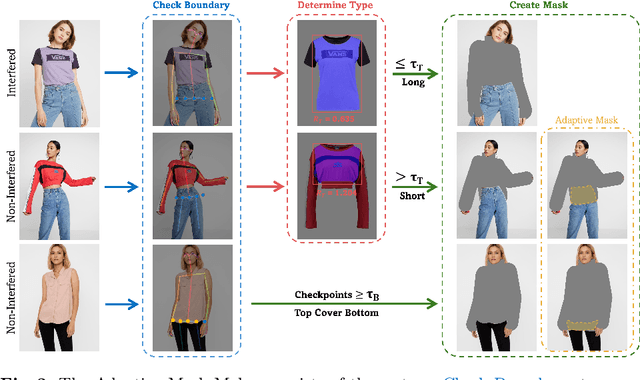
Image-based virtual try-on aims to transfer target in-shop clothing to a dressed model image, the objectives of which are totally taking off original clothing while preserving the contents outside of the try-on area, naturally wearing target clothing and correctly inpainting the gap between target clothing and original clothing. Tremendous efforts have been made to facilitate this popular research area, but cannot keep the type of target clothing with the try-on area affected by original clothing. In this paper, we focus on the unpaired virtual try-on situation where target clothing and original clothing on the model are different, i.e., the practical scenario. To break the correlation between the try-on area and the original clothing and make the model learn the correct information to inpaint, we propose an adaptive mask training paradigm that dynamically adjusts training masks. It not only improves the alignment and fit of clothing but also significantly enhances the fidelity of virtual try-on experience. Furthermore, we for the first time propose two metrics for unpaired try-on evaluation, the Semantic-Densepose-Ratio (SDR) and Skeleton-LPIPS (S-LPIPS), to evaluate the correctness of clothing type and the accuracy of clothing texture. For unpaired try-on validation, we construct a comprehensive cross-try-on benchmark (Cross-27) with distinctive clothing items and model physiques, covering a broad try-on scenarios. Experiments demonstrate the effectiveness of the proposed methods, contributing to the advancement of virtual try-on technology and offering new insights and tools for future research in the field. The code, model and benchmark will be publicly released.
iRoCo: Intuitive Robot Control From Anywhere Using a Smartwatch
Mar 11, 2024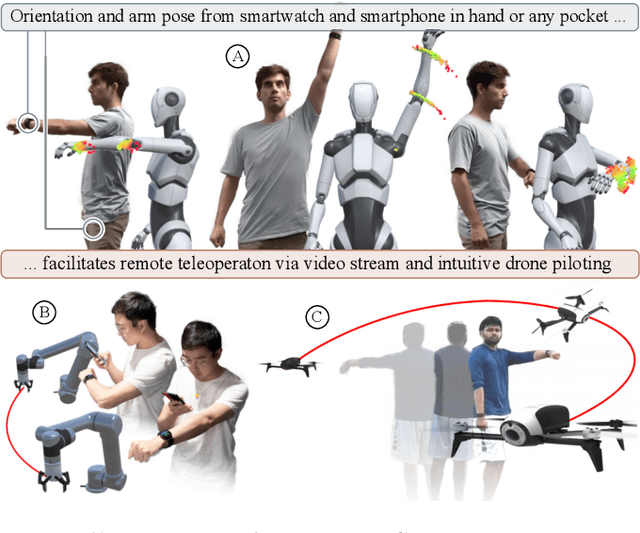
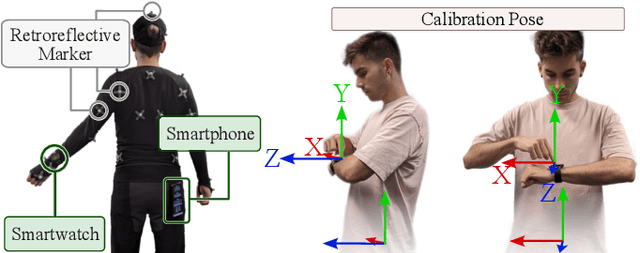
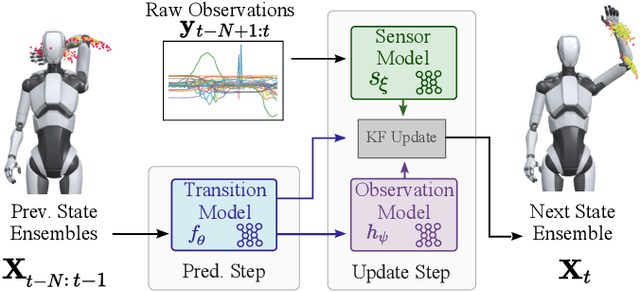
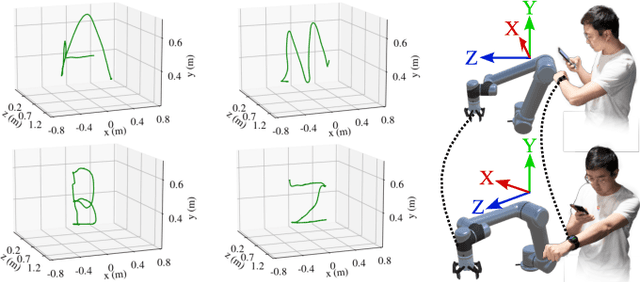
This paper introduces iRoCo (intuitive Robot Control) - a framework for ubiquitous human-robot collaboration using a single smartwatch and smartphone. By integrating probabilistic differentiable filters, iRoCo optimizes a combination of precise robot control and unrestricted user movement from ubiquitous devices. We demonstrate and evaluate the effectiveness of iRoCo in practical teleoperation and drone piloting applications. Comparative analysis shows no significant difference between task performance with iRoCo and gold-standard control systems in teleoperation tasks. Additionally, iRoCo users complete drone piloting tasks 32\% faster than with a traditional remote control and report less frustration in a subjective load index questionnaire. Our findings strongly suggest that iRoCo is a promising new approach for intuitive robot control through smartwatches and smartphones from anywhere, at any time. The code is available at www.github.com/wearable-motion-capture
Task-Oriented GNNs Training on Large Knowledge Graphs for Accurate and Efficient Modeling
Mar 09, 2024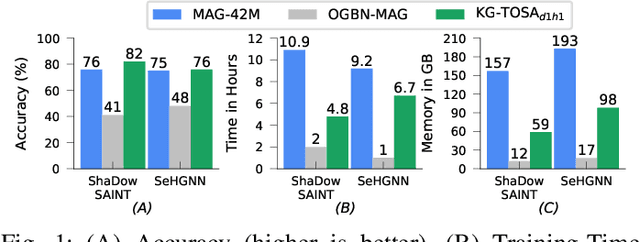
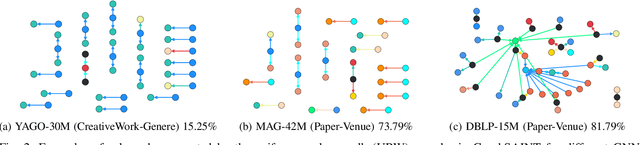
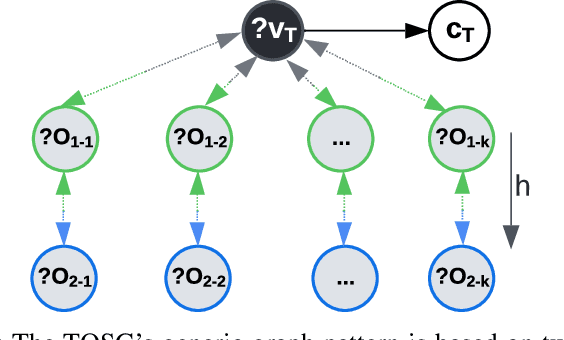
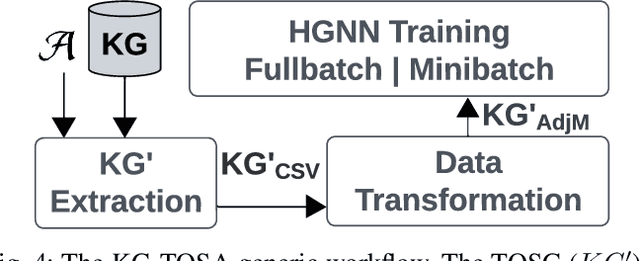
A Knowledge Graph (KG) is a heterogeneous graph encompassing a diverse range of node and edge types. Heterogeneous Graph Neural Networks (HGNNs) are popular for training machine learning tasks like node classification and link prediction on KGs. However, HGNN methods exhibit excessive complexity influenced by the KG's size, density, and the number of node and edge types. AI practitioners handcraft a subgraph of a KG G relevant to a specific task. We refer to this subgraph as a task-oriented subgraph (TOSG), which contains a subset of task-related node and edge types in G. Training the task using TOSG instead of G alleviates the excessive computation required for a large KG. Crafting the TOSG demands a deep understanding of the KG's structure and the task's objectives. Hence, it is challenging and time-consuming. This paper proposes KG-TOSA, an approach to automate the TOSG extraction for task-oriented HGNN training on a large KG. In KG-TOSA, we define a generic graph pattern that captures the KG's local and global structure relevant to a specific task. We explore different techniques to extract subgraphs matching our graph pattern: namely (i) two techniques sampling around targeted nodes using biased random walk or influence scores, and (ii) a SPARQL-based extraction method leveraging RDF engines' built-in indices. Hence, it achieves negligible preprocessing overhead compared to the sampling techniques. We develop a benchmark of real KGs of large sizes and various tasks for node classification and link prediction. Our experiments show that KG-TOSA helps state-of-the-art HGNN methods reduce training time and memory usage by up to 70% while improving the model performance, e.g., accuracy and inference time.
Understanding Missingness in Time-series Electronic Health Records for Individualized Representation
Feb 24, 2024With the widespread of machine learning models for healthcare applications, there is increased interest in building applications for personalized medicine. Despite the plethora of proposed research for personalized medicine, very few focus on representing missingness and learning from the missingness patterns in time-series Electronic Health Records (EHR) data. The lack of focus on missingness representation in an individualized way limits the full utilization of machine learning applications towards true personalization. In this brief communication, we highlight new insights into patterns of missingness with real-world examples and implications of missingness in EHRs. The insights in this work aim to bridge the gap between theoretical assumptions and practical observations in real-world EHRs. We hope this work will open new doors for exploring directions for better representation in predictive modelling for true personalization.
Enhancing Mean-Reverting Time Series Prediction with Gaussian Processes: Functional and Augmented Data Structures in Financial Forecasting
Feb 23, 2024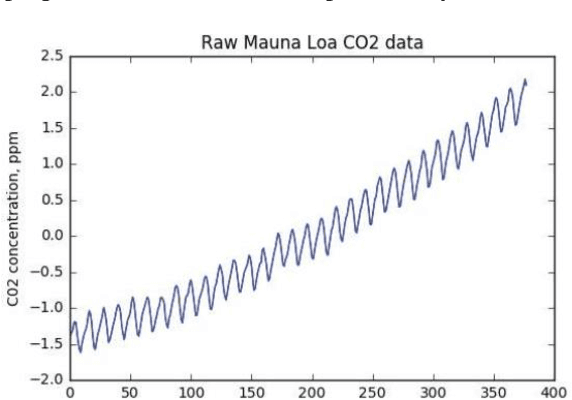
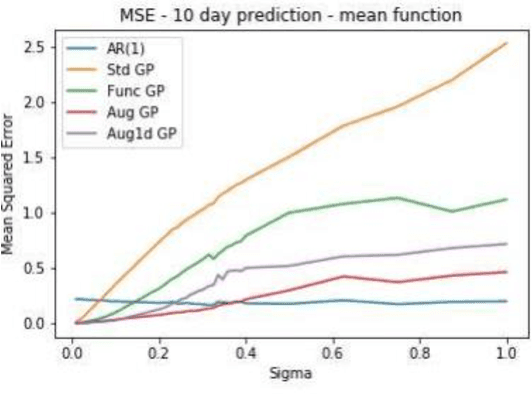
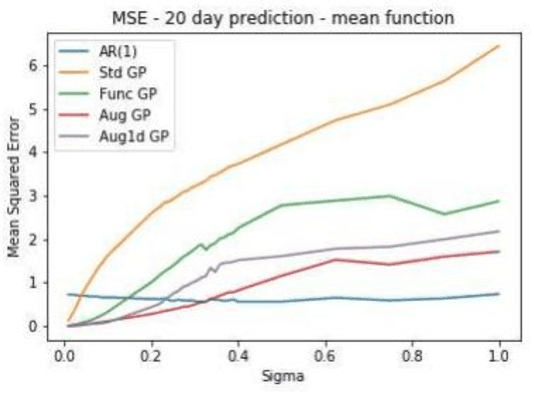
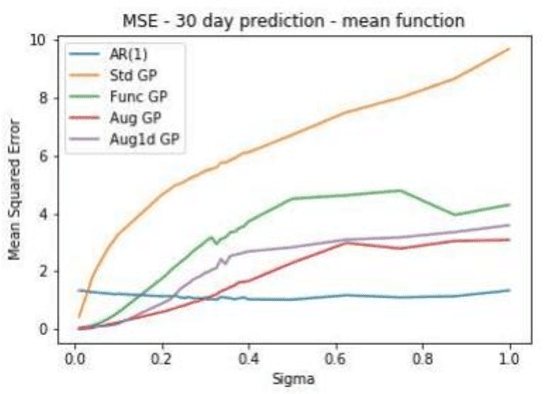
In this paper, we explore the application of Gaussian Processes (GPs) for predicting mean-reverting time series with an underlying structure, using relatively unexplored functional and augmented data structures. While many conventional forecasting methods concentrate on the short-term dynamics of time series data, GPs offer the potential to forecast not just the average prediction but the entire probability distribution over a future trajectory. This is particularly beneficial in financial contexts, where accurate predictions alone may not suffice if incorrect volatility assessments lead to capital losses. Moreover, in trade selection, GPs allow for the forecasting of multiple Sharpe ratios adjusted for transaction costs, aiding in decision-making. The functional data representation utilized in this study enables longer-term predictions by leveraging information from previous years, even as the forecast moves away from the current year's training data. Additionally, the augmented representation enriches the training set by incorporating multiple targets for future points in time, facilitating long-term predictions. Our implementation closely aligns with the methodology outlined in, which assessed effectiveness on commodity futures. However, our testing methodology differs. Instead of real data, we employ simulated data with similar characteristics. We construct a testing environment to evaluate both data representations and models under conditions of increasing noise, fat tails, and inappropriate kernels-conditions commonly encountered in practice. By simulating data, we can compare our forecast distribution over time against a full simulation of the actual distribution of our test set, thereby reducing the inherent uncertainty in testing time series models on real data. We enable feature prediction through augmentation and employ sub-sampling to ensure the feasibility of GPs.
Learned 3D volumetric recovery of clouds and its uncertainty for climate analysis
Mar 09, 2024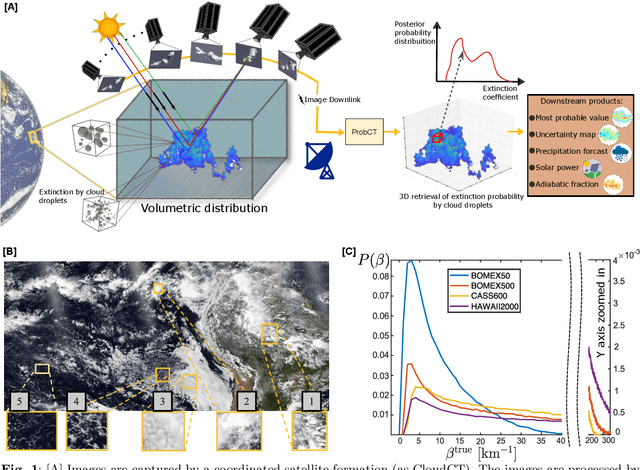
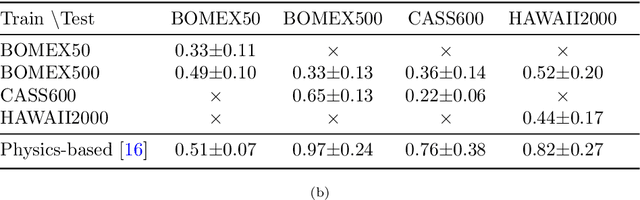
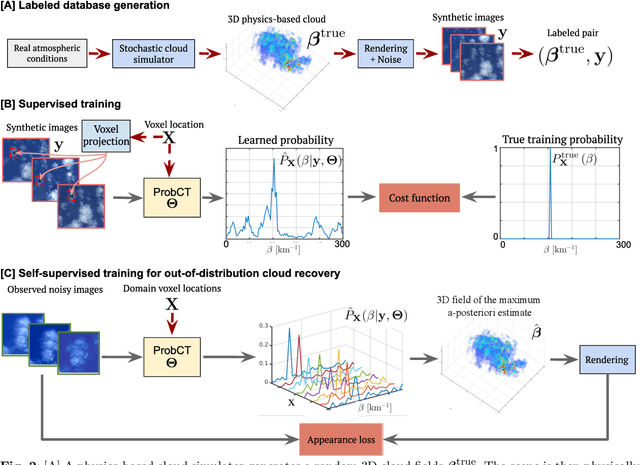
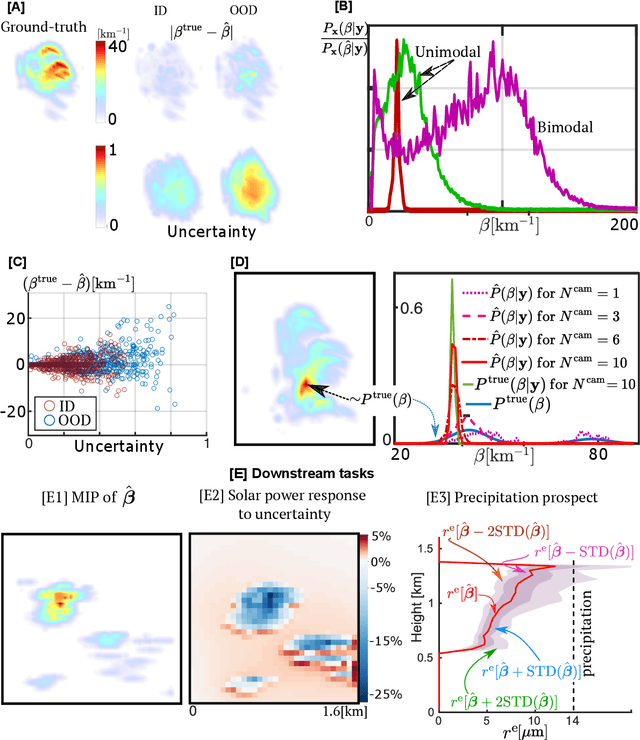
Significant uncertainty in climate prediction and cloud physics is tied to observational gaps relating to shallow scattered clouds. Addressing these challenges requires remote sensing of their three-dimensional (3D) heterogeneous volumetric scattering content. This calls for passive scattering computed tomography (CT). We design a learning-based model (ProbCT) to achieve CT of such clouds, based on noisy multi-view spaceborne images. ProbCT infers - for the first time - the posterior probability distribution of the heterogeneous extinction coefficient, per 3D location. This yields arbitrary valuable statistics, e.g., the 3D field of the most probable extinction and its uncertainty. ProbCT uses a neural-field representation, making essentially real-time inference. ProbCT undergoes supervised training by a new labeled multi-class database of physics-based volumetric fields of clouds and their corresponding images. To improve out-of-distribution inference, we incorporate self-supervised learning through differential rendering. We demonstrate the approach in simulations and on real-world data, and indicate the relevance of 3D recovery and uncertainty to precipitation and renewable energy.
A Fourier Transform Framework for Domain Adaptation
Mar 12, 2024
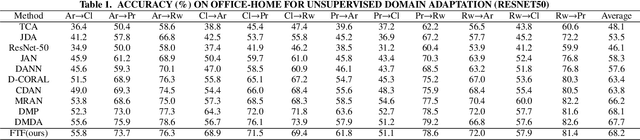
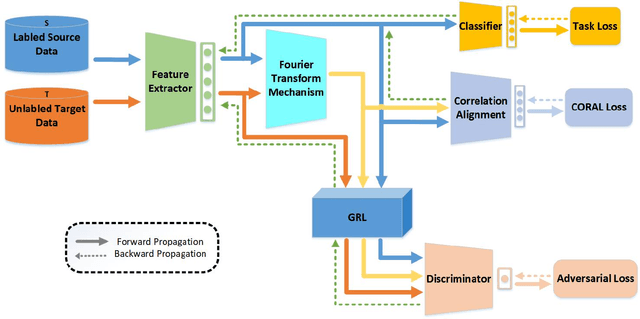

By using unsupervised domain adaptation (UDA), knowledge can be transferred from a label-rich source domain to a target domain that contains relevant information but lacks labels. Many existing UDA algorithms suffer from directly using raw images as input, resulting in models that overly focus on redundant information and exhibit poor generalization capability. To address this issue, we attempt to improve the performance of unsupervised domain adaptation by employing the Fourier method (FTF).Specifically, FTF is inspired by the amplitude of Fourier spectra, which primarily preserves low-level statistical information. In FTF, we effectively incorporate low-level information from the target domain into the source domain by fusing the amplitudes of both domains in the Fourier domain. Additionally, we observe that extracting features from batches of images can eliminate redundant information while retaining class-specific features relevant to the task. Building upon this observation, we apply the Fourier Transform at the data stream level for the first time. To further align multiple sources of data, we introduce the concept of correlation alignment. To evaluate the effectiveness of our FTF method, we conducted evaluations on four benchmark datasets for domain adaptation, including Office-31, Office-Home, ImageCLEF-DA, and Office-Caltech. Our results demonstrate superior performance.
Scalable Spatiotemporal Prediction with Bayesian Neural Fields
Mar 12, 2024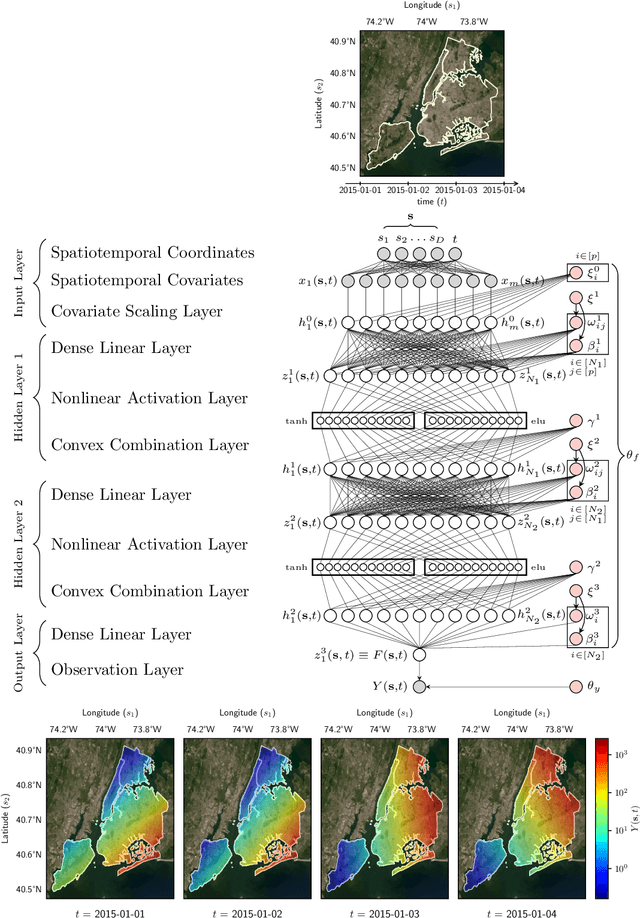
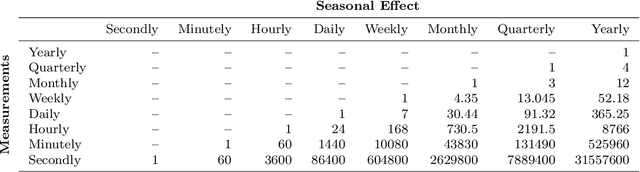
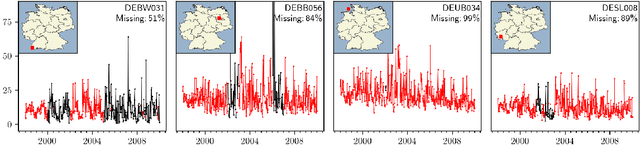
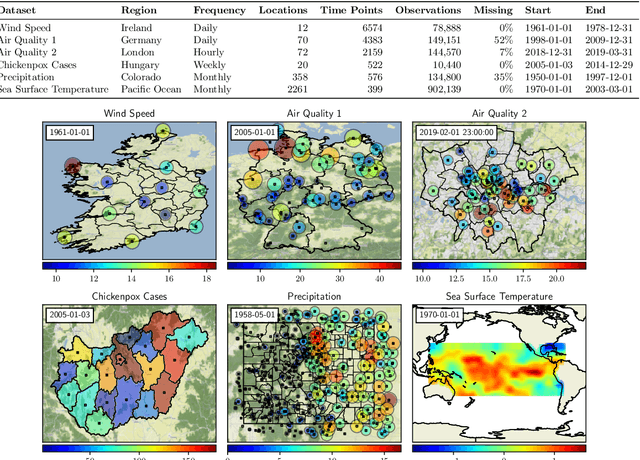
Spatiotemporal datasets, which consist of spatially-referenced time series, are ubiquitous in many scientific and business-intelligence applications, such as air pollution monitoring, disease tracking, and cloud-demand forecasting. As modern datasets continue to increase in size and complexity, there is a growing need for new statistical methods that are flexible enough to capture complex spatiotemporal dynamics and scalable enough to handle large prediction problems. This work presents the Bayesian Neural Field (BayesNF), a domain-general statistical model for inferring rich probability distributions over a spatiotemporal domain, which can be used for data-analysis tasks including forecasting, interpolation, and variography. BayesNF integrates a novel deep neural network architecture for high-capacity function estimation with hierarchical Bayesian inference for robust uncertainty quantification. By defining the prior through a sequence of smooth differentiable transforms, posterior inference is conducted on large-scale data using variationally learned surrogates trained via stochastic gradient descent. We evaluate BayesNF against prominent statistical and machine-learning baselines, showing considerable improvements on diverse prediction problems from climate and public health datasets that contain tens to hundreds of thousands of measurements. The paper is accompanied with an open-source software package (https://github.com/google/bayesnf) that is easy-to-use and compatible with modern GPU and TPU accelerators on the JAX machine learning platform.
Application of Distributed Arithmetic to Adaptive Filtering Algorithms: Trends, Challenges and Future
Mar 12, 2024
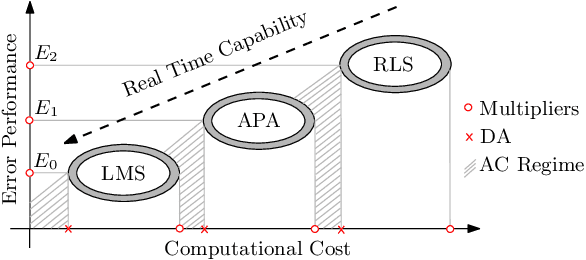
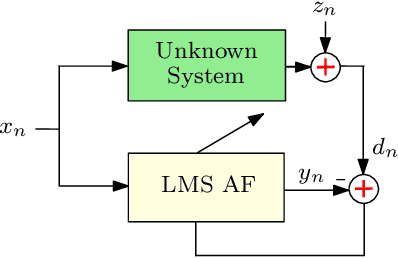
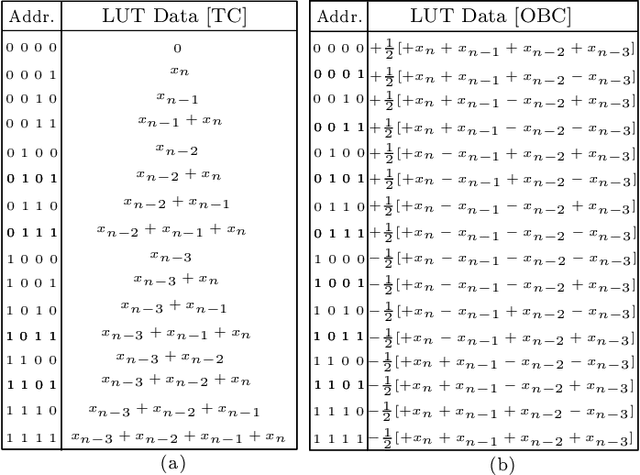
The utilization of distributed arithmetic (DA) in AF algorithms has gained significant attention in recent years due to its potential to enhance computational efficiency and reduce resource requirements. This paper presents an exploration of the application of DA to adaptive filtering (AF) algorithms, analyzing trends, discussing challenges, and outlining future prospects. It begins by providing an overview of both DA and AF algorithms, highlighting their individual merits and established applications. Subsequently, the integration of DA into AF algorithms is explored, showcasing its ability to optimize multiply-accumulate operations and mitigate the computational burden associated with AF algorithms. Throughout the paper, the critical trends observed in the field are discussed, including advancements in DA-based hardware architectures. Moreover, the challenges encountered in implementing DA-based AF is also discussed. The continued evolution of DA techniques to cater to the demands of modern AF applications, including real-time processing, resource-constrained environments, and high-dimensional data streams is anticipated. In conclusion, this paper consolidates the current state of applying DA to AF algorithms, offering insights into prevailing trends, discussing challenges, and presenting future research and development in the field. The fusion of these two domains holds promise for achieving improved computational efficiency, reduced hardware complexity, and enhanced performance in various signal processing applications.
Decoupled Data Consistency with Diffusion Purification for Image Restoration
Mar 12, 2024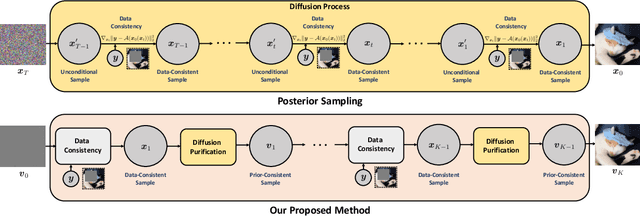
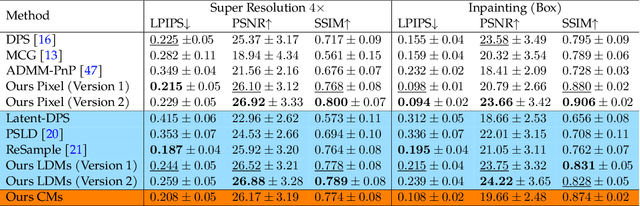
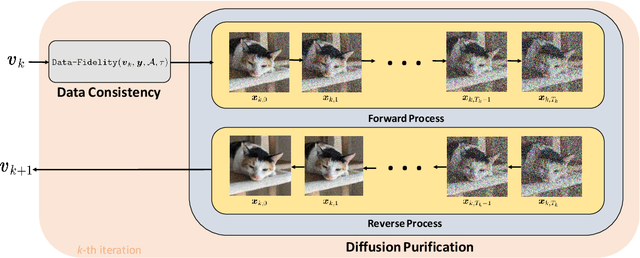
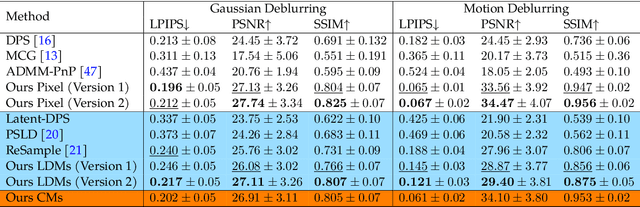
Diffusion models have recently gained traction as a powerful class of deep generative priors, excelling in a wide range of image restoration tasks due to their exceptional ability to model data distributions. To solve image restoration problems, many existing techniques achieve data consistency by incorporating additional likelihood gradient steps into the reverse sampling process of diffusion models. However, the additional gradient steps pose a challenge for real-world practical applications as they incur a large computational overhead, thereby increasing inference time. They also present additional difficulties when using accelerated diffusion model samplers, as the number of data consistency steps is limited by the number of reverse sampling steps. In this work, we propose a novel diffusion-based image restoration solver that addresses these issues by decoupling the reverse process from the data consistency steps. Our method involves alternating between a reconstruction phase to maintain data consistency and a refinement phase that enforces the prior via diffusion purification. Our approach demonstrates versatility, making it highly adaptable for efficient problem-solving in latent space. Additionally, it reduces the necessity for numerous sampling steps through the integration of consistency models. The efficacy of our approach is validated through comprehensive experiments across various image restoration tasks, including image denoising, deblurring, inpainting, and super-resolution.