 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Human-Robot Team Performance Compared to Full Robot Autonomy in 16 Real-World Search and Rescue Missions: Adaptation of the DARPA Subterranean Challenge
Dec 11, 2022

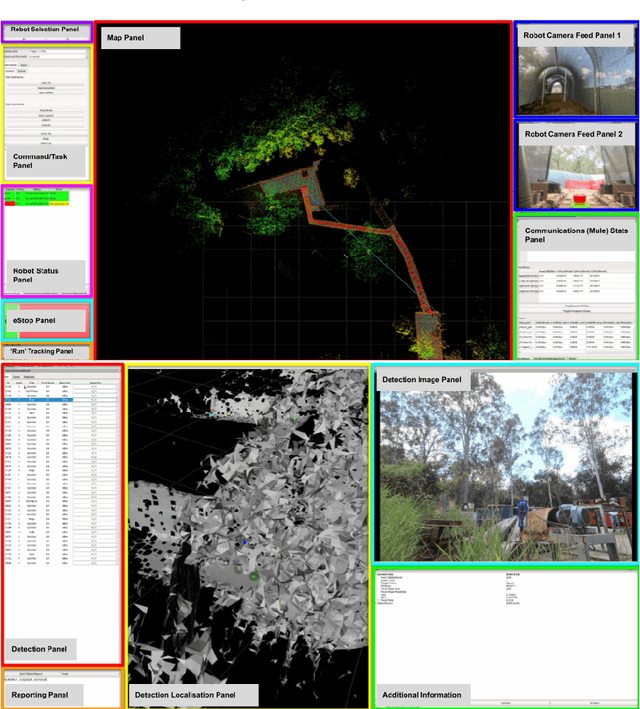


Human operators in human-robot teams are commonly perceived to be critical for mission success. To explore the direct and perceived impact of operator input on task success and team performance, 16 real-world missions (10 hrs) were conducted based on the DARPA Subterranean Challenge. These missions were to deploy a heterogeneous team of robots for a search task to locate and identify artifacts such as climbing rope, drills and mannequins representing human survivors. Two conditions were evaluated: human operators that could control the robot team with state-of-the-art autonomy (Human-Robot Team) compared to autonomous missions without human operator input (Robot-Autonomy). Human-Robot Teams were often in directed autonomy mode (70% of mission time), found more items, traversed more distance, covered more unique ground, and had a higher time between safety-related events. Human-Robot Teams were faster at finding the first artifact, but slower to respond to information from the robot team. In routine conditions, scores were comparable for artifacts, distance, and coverage. Reasons for intervention included creating waypoints to prioritise high-yield areas, and to navigate through error-prone spaces. After observing robot autonomy, operators reported increases in robot competency and trust, but that robot behaviour was not always transparent and understandable, even after high mission performance.
Decentralized Online Regularized Learning Over Random Time-Varying Graphs
Jun 07, 2022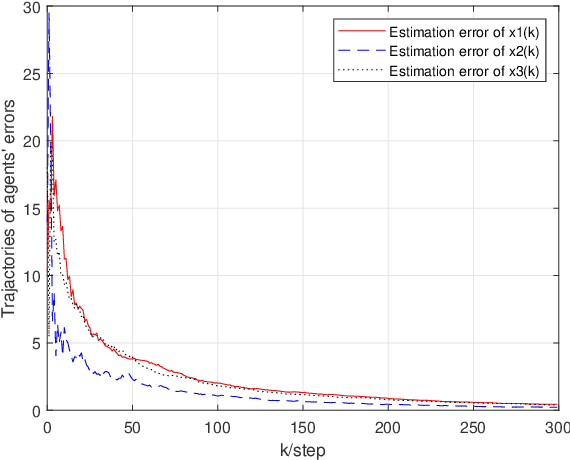
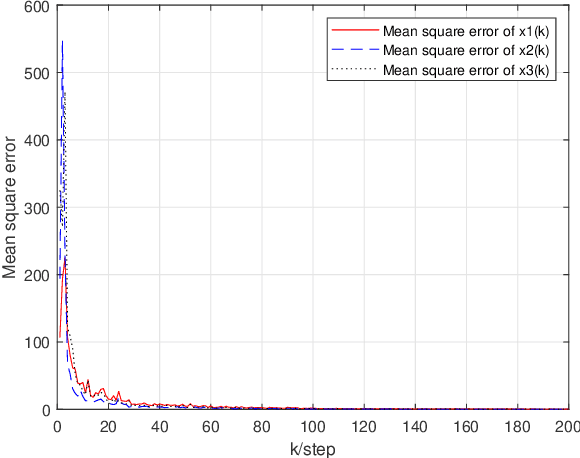
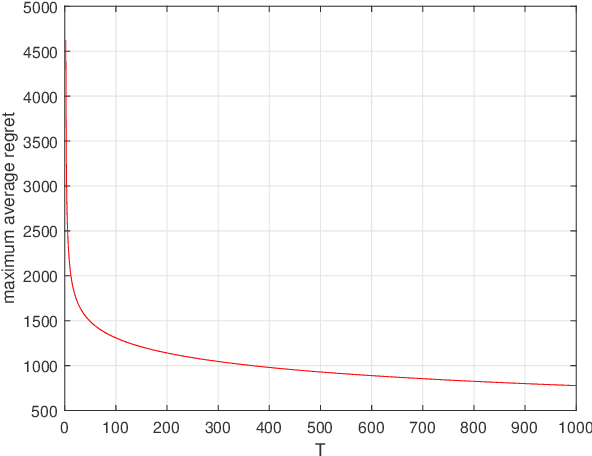
We study the decentralized online regularized linear regression algorithm over random time-varying graphs. At each time step, every node runs an online estimation algorithm consisting of an innovation term processing its own new measurement, a consensus term taking a weighted sum of estimations of its own and its neighbors with additive and multiplicative communication noises and a regularization term preventing over-fitting. It is not required that the regression matrices and graphs satisfy special statistical assumptions such as mutual independence, spatio-temporal independence or stationarity. We develop the nonnegative supermartingale inequality of the estimation error, and prove that the estimations of all nodes converge to the unknown true parameter vector almost surely if the algorithm gains, graphs and regression matrices jointly satisfy the sample path spatio-temporal persistence of excitation condition. Especially, this condition holds by choosing appropriate algorithm gains if the graphs are uniformly conditionally jointly connected and conditionally balanced, and the regression models of all nodes are uniformly conditionally spatio-temporally jointly observable, under which the algorithm converges in mean square and almost surely. In addition, we prove that the regret upper bound $\mathcal O(T^{1-\tau}\ln T)$, where $\tau\in (0.5,1)$ is a constant depending on the algorithm gains.
Automatically Prepare Training Data for YOLO Using Robotic In-Hand Observation and Synthesis
Jan 04, 2023

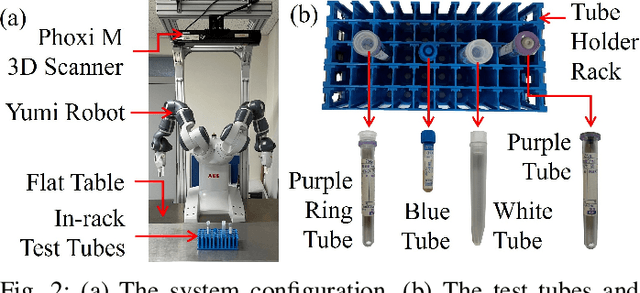
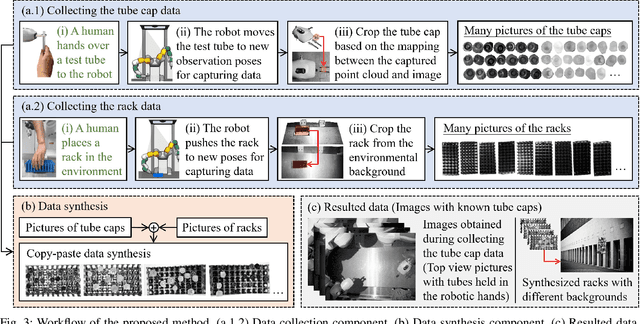
Deep learning methods have recently exhibited impressive performance in object detection. However, such methods needed much training data to achieve high recognition accuracy, which was time-consuming and required considerable manual work like labeling images. In this paper, we automatically prepare training data using robots. Considering the low efficiency and high energy consumption in robot motion, we proposed combining robotic in-hand observation and data synthesis to enlarge the limited data set collected by the robot. We first used a robot with a depth sensor to collect images of objects held in the robot's hands and segment the object pictures. Then, we used a copy-paste method to synthesize the segmented objects with rack backgrounds. The collected and synthetic images are combined to train a deep detection neural network. We conducted experiments to compare YOLOv5x detectors trained with images collected using the proposed method and several other methods. The results showed that combined observation and synthetic images led to comparable performance to manual data preparation. They provided a good guide on optimizing data configurations and parameter settings for training detectors. The proposed method required only a single process and was a low-cost way to produce the combined data. Interested readers may find the data sets and trained models from the following GitHub repository: github.com/wrslab/tubedet
GUAP: Graph Universal Attack Through Adversarial Patching
Jan 04, 2023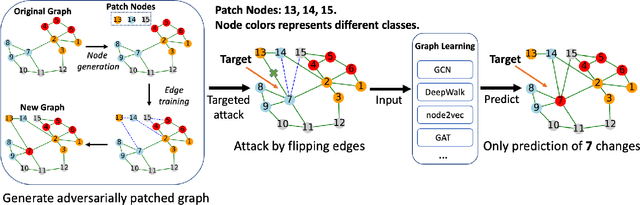
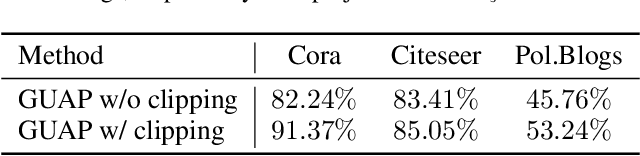
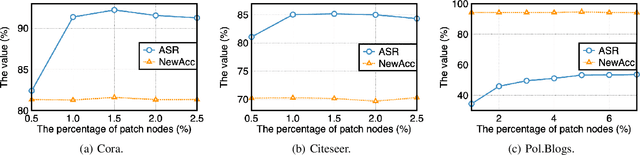
Graph neural networks (GNNs) are a class of effective deep learning models for node classification tasks; yet their predictive capability may be severely compromised under adversarially designed unnoticeable perturbations to the graph structure and/or node data. Most of the current work on graph adversarial attacks aims at lowering the overall prediction accuracy, but we argue that the resulting abnormal model performance may catch attention easily and invite quick counterattack. Moreover, attacks through modification of existing graph data may be hard to conduct if good security protocols are implemented. In this work, we consider an easier attack harder to be noticed, through adversarially patching the graph with new nodes and edges. The attack is universal: it targets a single node each time and flips its connection to the same set of patch nodes. The attack is unnoticeable: it does not modify the predictions of nodes other than the target. We develop an algorithm, named GUAP, that achieves high attack success rate but meanwhile preserves the prediction accuracy. GUAP is fast to train by employing a sampling strategy. We demonstrate that a 5% sampling in each epoch yields 20x speedup in training, with only a slight degradation in attack performance. Additionally, we show that the adversarial patch trained with the graph convolutional network transfers well to other GNNs, such as the graph attention network.
Gaussian Process Priors for Systems of Linear Partial Differential Equations with Constant Coefficients
Dec 29, 2022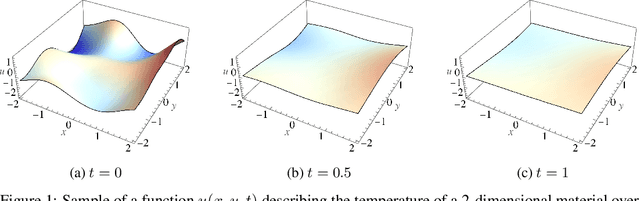
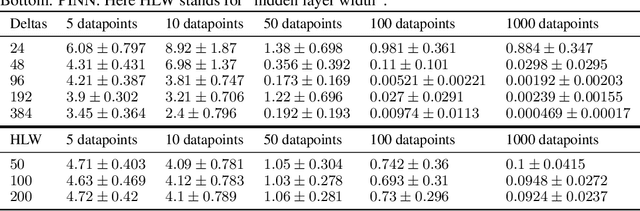
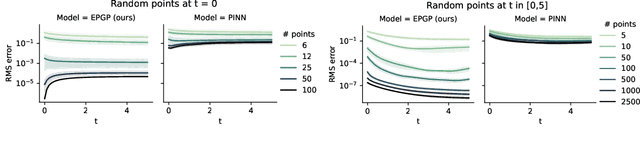
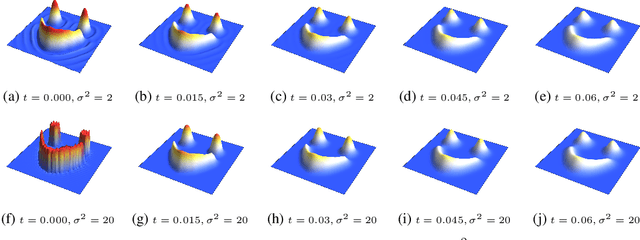
Partial differential equations (PDEs) are important tools to model physical systems, and including them into machine learning models is an important way of incorporating physical knowledge. Given any system of linear PDEs with constant coefficients, we propose a family of Gaussian process (GP) priors, which we call EPGP, such that all realizations are exact solutions of this system. We apply the Ehrenpreis-Palamodov fundamental principle, which works like a non-linear Fourier transform, to construct GP kernels mirroring standard spectral methods for GPs. Our approach can infer probable solutions of linear PDE systems from any data such as noisy measurements, or initial and boundary conditions. Constructing EPGP-priors is algorithmic, generally applicable, and comes with a sparse version (S-EPGP) that learns the relevant spectral frequencies and works better for big data sets. We demonstrate our approach on three families of systems of PDE, the heat equation, wave equation, and Maxwell's equations, where we improve upon the state of the art in computation time and precision, in some experiments by several orders of magnitude.
Unsupervised construction of representations for oil wells via Transformers
Dec 29, 2022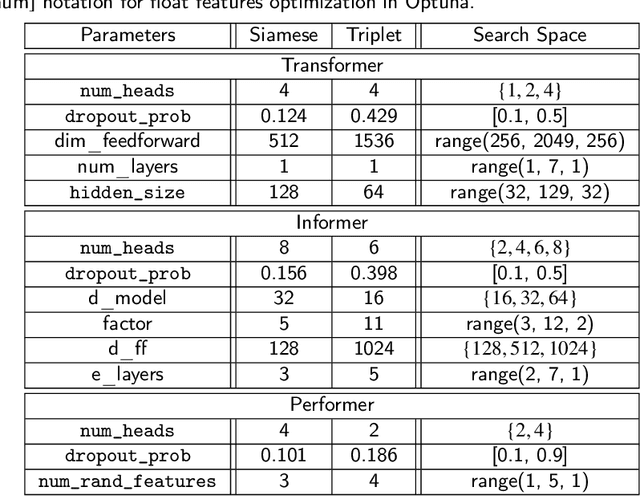
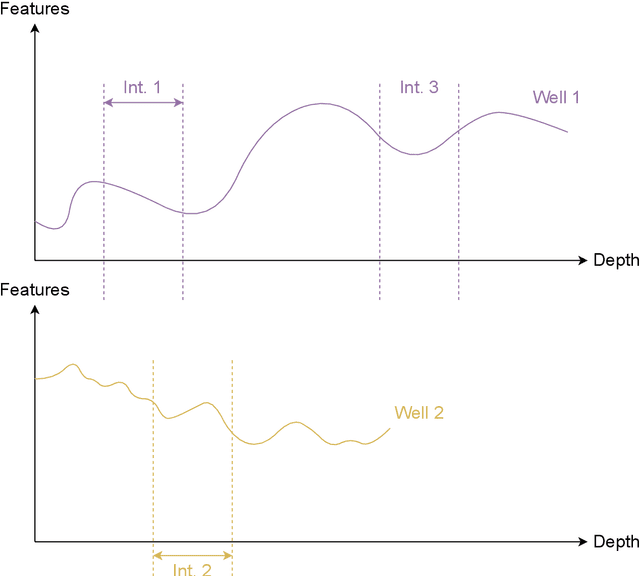
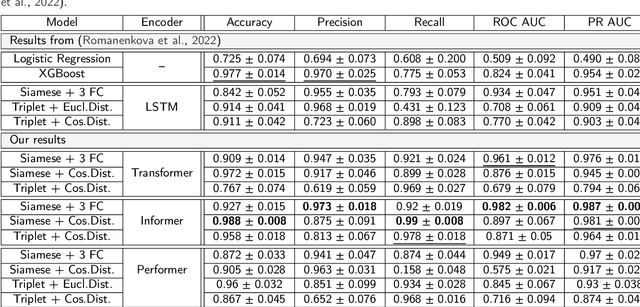
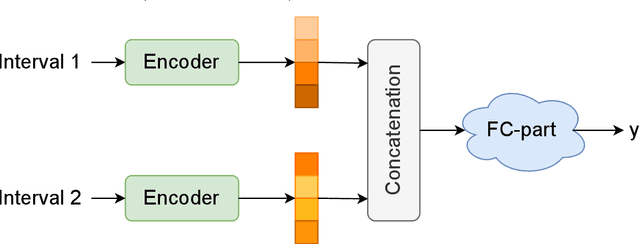
Determining and predicting reservoir formation properties for newly drilled wells represents a significant challenge. One of the variations of these properties evaluation is well-interval similarity. Many methodologies for similarity learning exist: from rule-based approaches to deep neural networks. Recently, articles adopted, e.g. recurrent neural networks to build a similarity model as we deal with sequential data. Such an approach suffers from short-term memory, as it pays more attention to the end of a sequence. Neural network with Transformer architecture instead cast their attention over all sequences to make a decision. To make them more efficient in terms of computational time, we introduce a limited attention mechanism similar to Informer and Performer architectures. We conduct experiments on open datasets with more than 20 wells making our experiments reliable and suitable for industrial usage. The best results were obtained with our adaptation of the Informer variant of Transformer with ROC AUC 0.982. It outperforms classical approaches with ROC AUC 0.824, Recurrent neural networks with ROC AUC 0.934 and straightforward usage of Transformers with ROC AUC 0.961.
Real Time Object Detection System with YOLO and CNN Models: A Review
Jul 23, 2022The field of artificial intelligence is built on object detection techniques. YOU ONLY LOOK ONCE (YOLO) algorithm and it's more evolved versions are briefly described in this research survey. This survey is all about YOLO and convolution neural networks (CNN)in the direction of real time object detection.YOLO does generalized object representation more effectively without precision losses than other object detection models.CNN architecture models have the ability to eliminate highlights and identify objects in any given image. When implemented appropriately, CNN models can address issues like deformity diagnosis, creating educational or instructive application, etc. This article reached atnumber of observations and perspective findings through the analysis.Also it provides support for the focused visual information and feature extraction in the financial and other industries, highlights the method of target detection and feature selection, and briefly describe the development process of YOLO algorithm.
Genetic-tunneling driven energy optimizer for magnetic system
Dec 31, 2022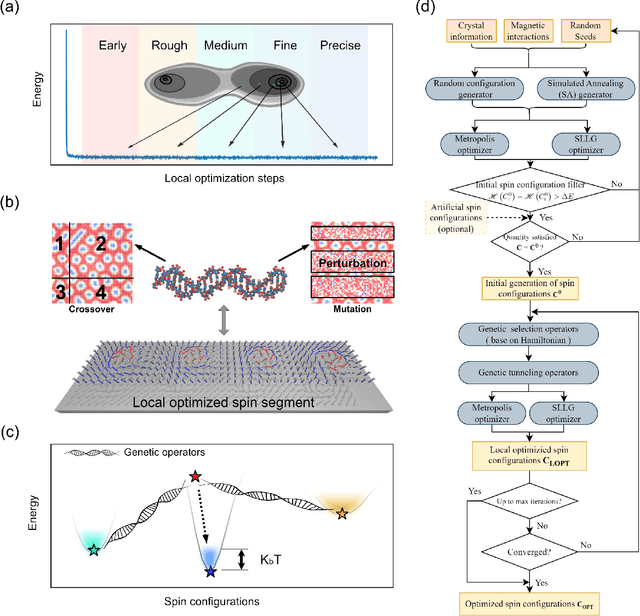
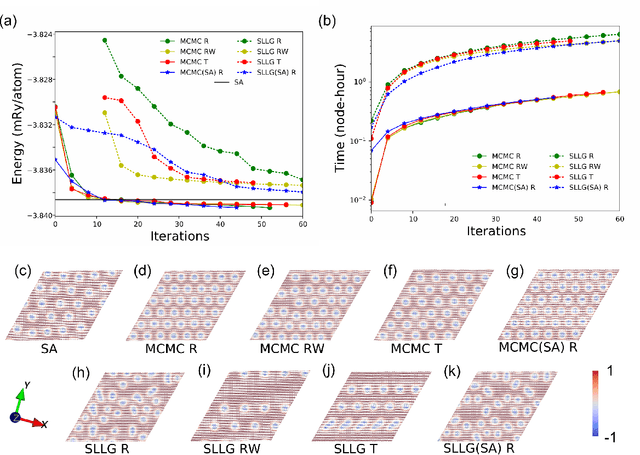
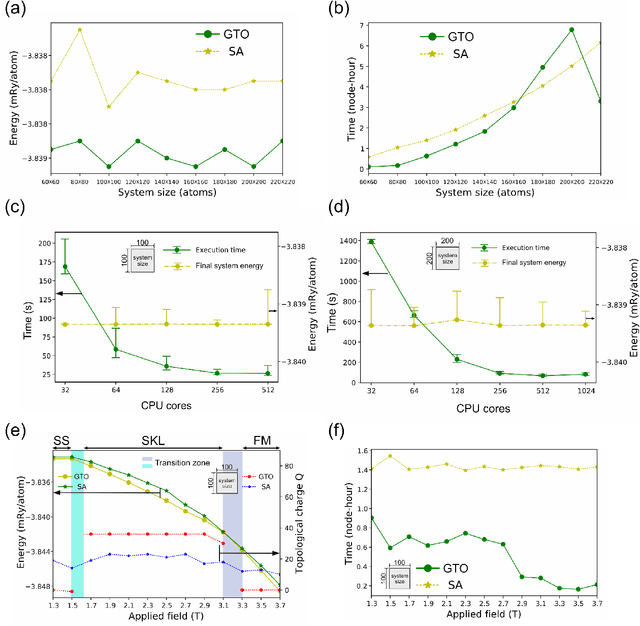
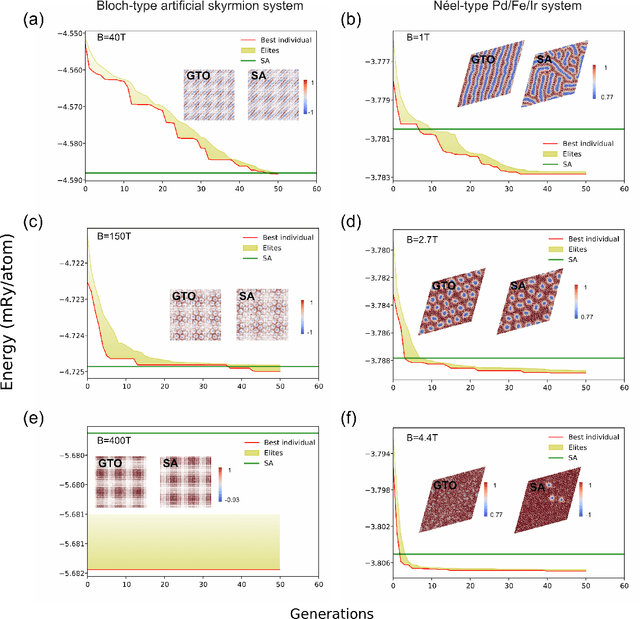
Novel topological spin textures, such as magnetic skyrmions, benefit from their inherent stability, acting as the ground state in several magnetic systems. In the current study of atomic monolayer magnetic materials, reasonable initial guesses are still needed to search for those magnetic patterns. This situation underlines the need to develop a more effective way to identify the ground states. To solve this problem, in this work, we propose a genetic-tunneling-driven variance-controlled optimization approach, which combines a local energy minimizer back-end and a metaheuristic global searching front-end. This algorithm is an effective optimization solution for searching for magnetic ground states at extremely low temperatures and is also robust for finding low-energy degenerated states at finite temperatures. We demonstrate here the success of this method in searching for magnetic ground states of 2D monolayer systems with both artificial and calculated interactions from density functional theory. It is also worth noting that the inherent concurrent property of this algorithm can significantly decrease the execution time. In conclusion, our proposed method builds a useful tool for low-dimensional magnetic system energy optimization.
AcceRL: Policy Acceleration Framework for Deep Reinforcement Learning
Nov 28, 2022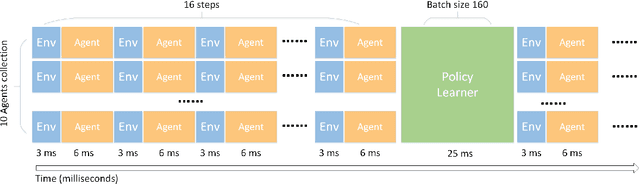

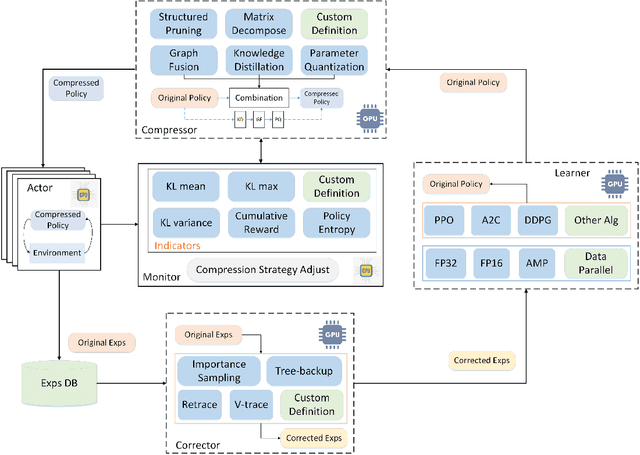
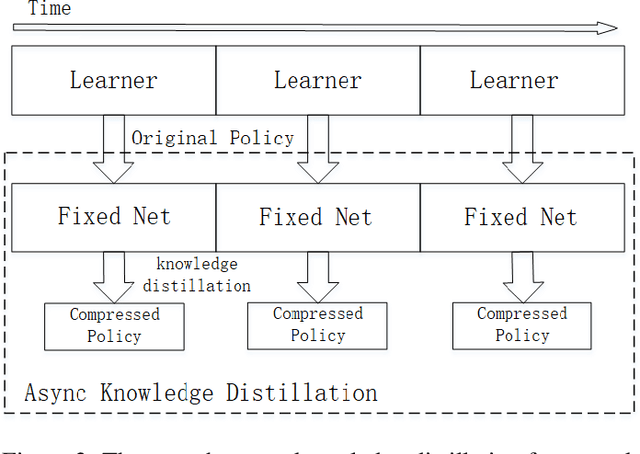
Deep reinforcement learning has achieved great success in various fields with its super decision-making ability. However, the policy learning process requires a large amount of training time, causing energy consumption. Inspired by the redundancy of neural networks, we propose a lightweight parallel training framework based on neural network compression, AcceRL, to accelerate the policy learning while ensuring policy quality. Specifically, AcceRL speeds up the experience collection by flexibly combining various neural network compression methods. Overall, the AcceRL consists of five components, namely Actor, Learner, Compressor, Corrector, and Monitor. The Actor uses the Compressor to compress the Learner's policy network to interact with the environment. And the generated experiences are transformed by the Corrector with Off-Policy methods, such as V-trace, Retrace and so on. Then the corrected experiences are feed to the Learner for policy learning. We believe this is the first general reinforcement learning framework that incorporates multiple neural network compression techniques. Extensive experiments conducted in gym show that the AcceRL reduces the time cost of the actor by about 2.0 X to 4.13 X compared to the traditional methods. Furthermore, the AcceRL reduces the whole training time by about 29.8% to 40.3% compared to the traditional methods while keeps the same policy quality.
A Projected Upper Bound for Mining High Utility Patterns from Interval-Based Event Sequences
Dec 21, 2022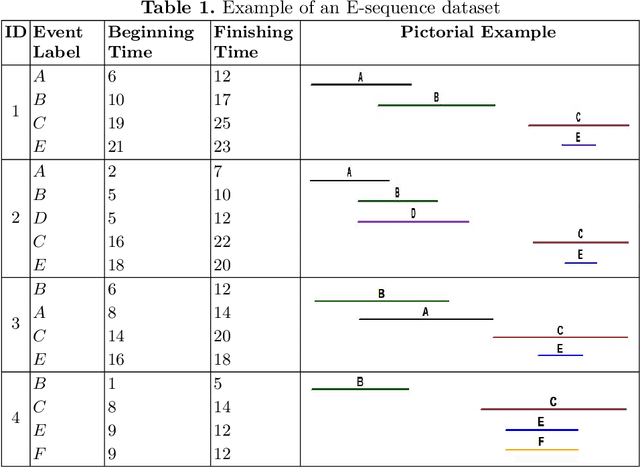
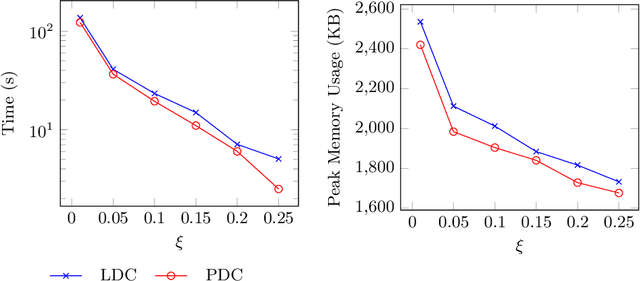

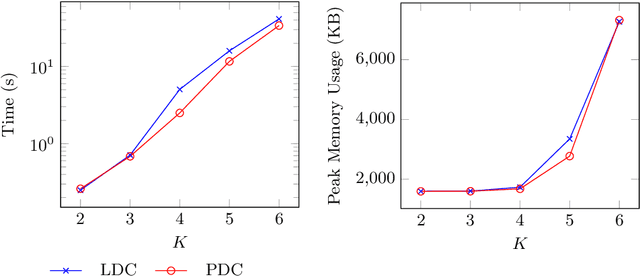
High utility pattern mining is an interesting yet challenging problem. The intrinsic computational cost of the problem will impose further challenges if efficiency in addition to the efficacy of a solution is sought. Recently, this problem was studied on interval-based event sequences with a constraint on the length and size of the patterns. However, the proposed solution lacks adequate efficiency. To address this issue, we propose a projected upper bound on the utility of the patterns discovered from sequences of interval-based events. To show its effectiveness, the upper bound is utilized by a pruning strategy employed by the HUIPMiner algorithm. Experimental results show that the new upper bound improves HUIPMiner performance in terms of both execution time and memory usage.