 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Learning of Deep Time Series Anomaly Detection Models with Contaminated Training Data
Aug 03, 2022
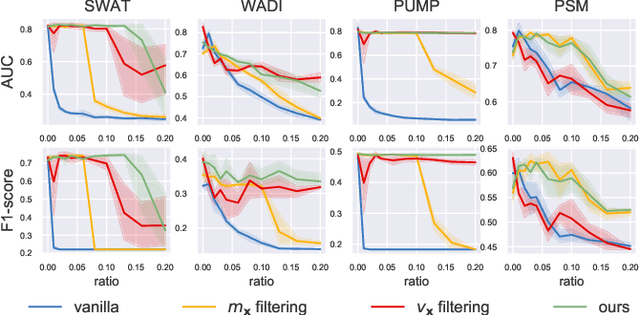
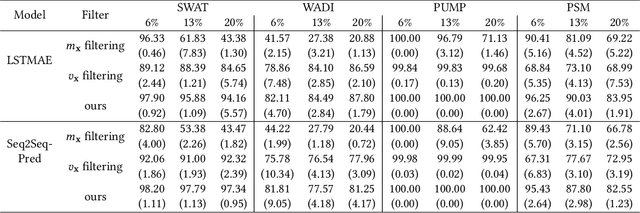
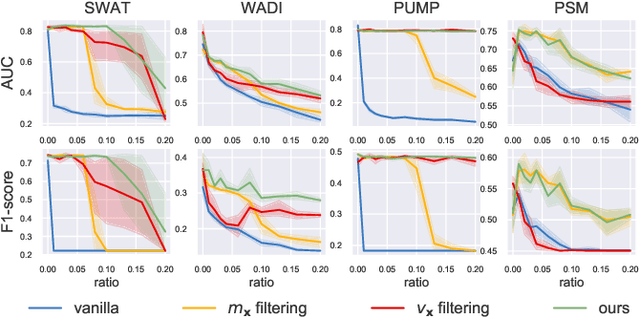
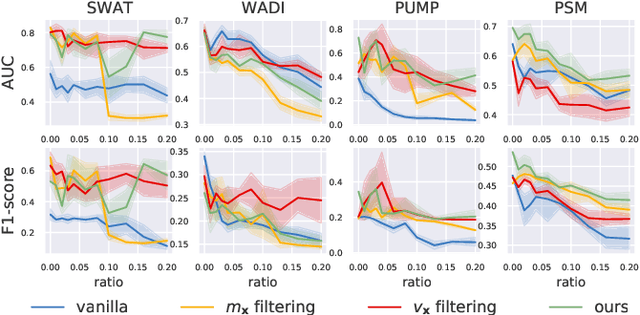
Time series anomaly detection (TSAD) is an important data mining task with numerous applications in the IoT era. In recent years, a large number of deep neural network-based methods have been proposed, demonstrating significantly better performance than conventional methods on addressing challenging TSAD problems in a variety of areas. Nevertheless, these deep TSAD methods typically rely on a clean training dataset that is not polluted by anomalies to learn the "normal profile" of the underlying dynamics. This requirement is nontrivial since a clean dataset can hardly be provided in practice. Moreover, without the awareness of their robustness, blindly applying deep TSAD methods with potentially contaminated training data can possibly incur significant performance degradation in the detection phase. In this work, to tackle this important challenge, we firstly investigate the robustness of commonly used deep TSAD methods with contaminated training data which provides a guideline for applying these methods when the provided training data are not guaranteed to be anomaly-free. Furthermore, we propose a model-agnostic method which can effectively improve the robustness of learning mainstream deep TSAD models with potentially contaminated data. Experiment results show that our method can consistently prevent or mitigate performance degradation of mainstream deep TSAD models on widely used benchmark datasets.
Enabling More Users to Benefit from Near-Field Communications: From Linear to Circular Array
Dec 30, 2022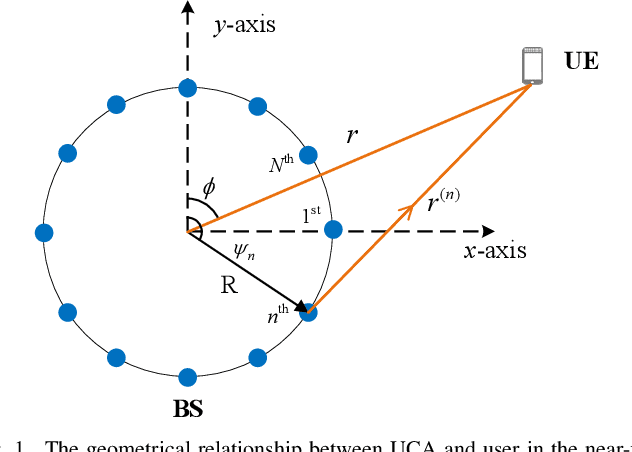
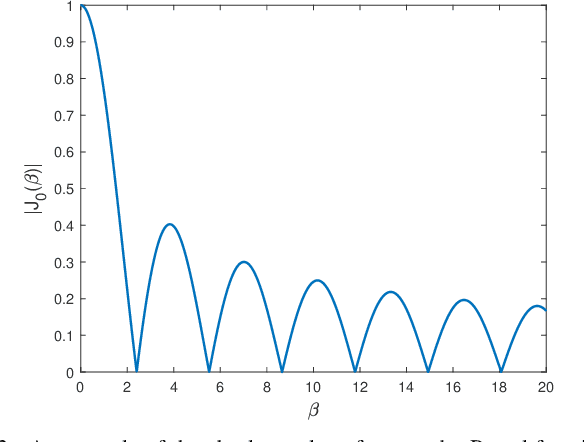
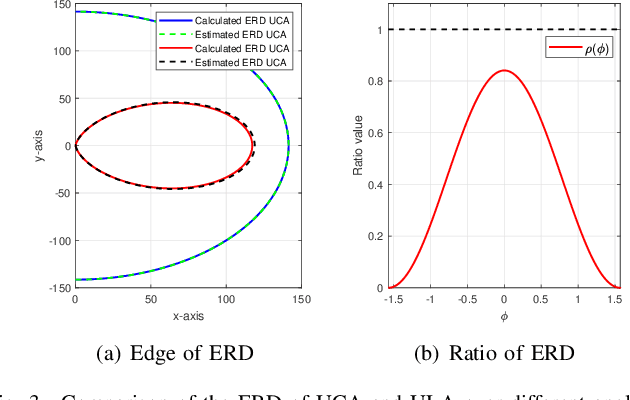
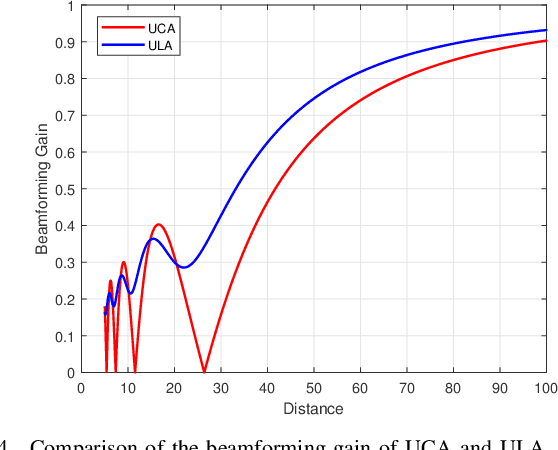
Massive multiple-input multiple-output (MIMO) for 5G is evolving into the extremely large-scale antenna array (ELAA) to increase the spectrum efficiency by orders of magnitude for 6G communications. ELAA introduces spherical-wave-based near-field communications, where channel capacity can be significantly improved for single-user and multi-user scenarios. Unfortunately, for the widely studied uniform linear array (ULA), the near-field regions at large incidence angles will be reduced. Thus, many users randomly distributed in a cell may fail to benefit from near-field communications. In this paper, we leverage the rotational symmetry of uniform circular array (UCA) to provide uniform and enlarged near-field region for all users in a cell, enabling more users to benefit from near-field communications. Specifically, by exploiting the geometrical relationship between UCA and user with the spherical-wave model, the near-field beamforming technique for UCA is developed for the first time. Based on the analysis of near-field beamforming, we reveal that UCA is able to provide a larger near-field region than ULA in terms of the effective Rayleigh distance. Moreover, based on the UCA beamforming property, a concentric-ring codebook is designed to realize efficient beamforming in the near-field region of UCA. In addition, we find out that UCA could generate orthogonal near-field beams along the same direction, which has the potential for further improvement of multi-user capacity compared with ULA. Simulation results are provided to verify the feasibility of UCA to enable more users to benefit from near-field communications by broadening the near-field region.
Time Series Anomaly Detection via Reinforcement Learning-Based Model Selection
May 23, 2022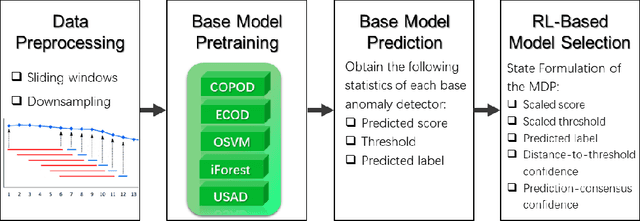
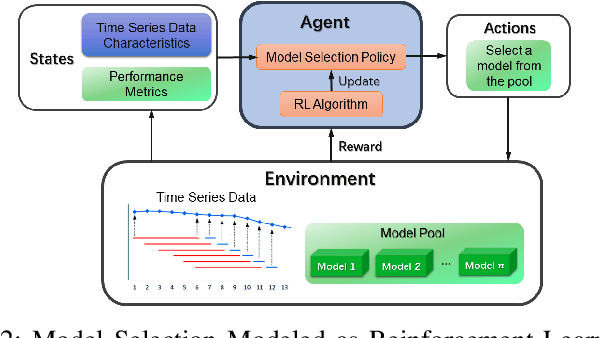
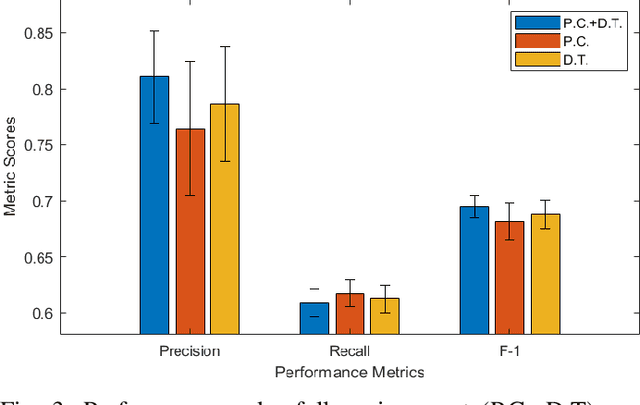
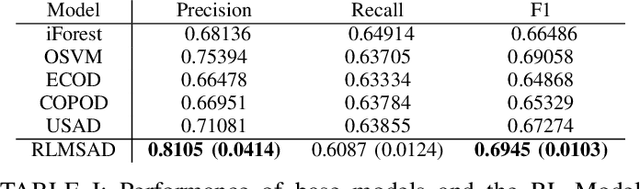
Time series anomaly detection is of critical importance for the reliable and efficient operation of real-world systems. Many anomaly detection models have been developed throughout the years based on various assumptions regarding anomaly characteristics. However, due to the complex nature of real-world data, different anomalies within a time series usually have diverse profiles supporting different anomaly assumptions, making it difficult to find a single anomaly detector that can consistently beat all other models. In this work, to harness the benefits of different base models, we assume that a pool of anomaly detection models is accessible and propose to utilize reinforcement learning to dynamically select a candidate model from these base models. Experiments on real-world data have been implemented. It is demonstrated that the proposed strategy can outperforms all baseline models in terms of overall performance.
Improving Question Answering Performance through Manual Annotation: Costs, Benefits and Strategies
Dec 17, 2022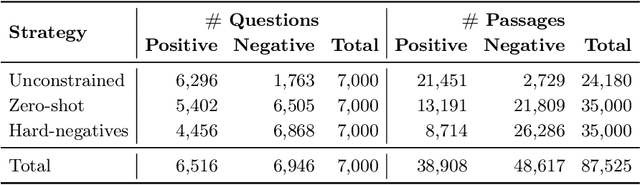
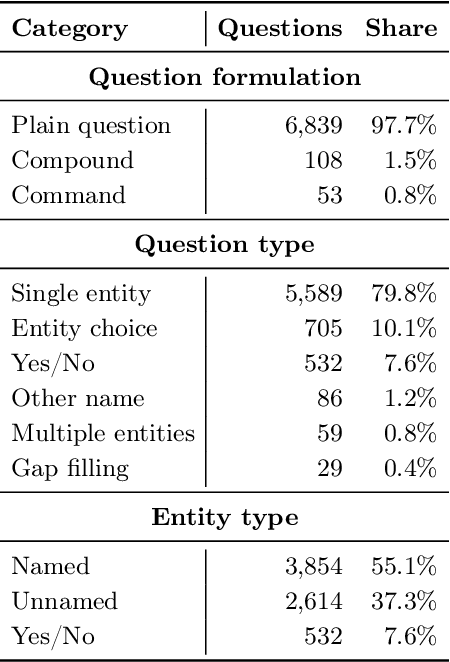
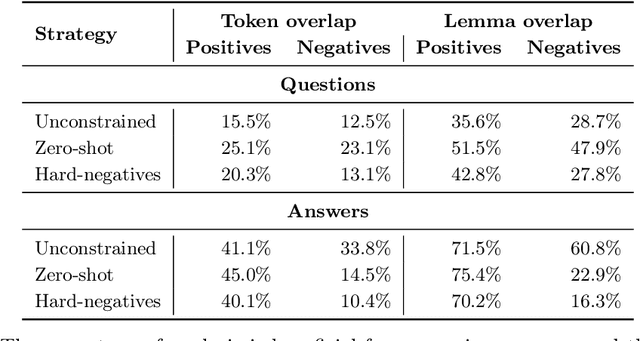
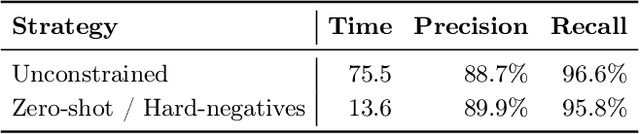
Recently proposed systems for open-domain question answering (OpenQA) require large amounts of training data to achieve state-of-the-art performance. However, data annotation is known to be time-consuming and therefore expensive to acquire. As a result, the appropriate datasets are available only for a handful of languages (mainly English and Chinese). In this work, we introduce and publicly release PolQA, the first Polish dataset for OpenQA. It consists of 7,000 questions, 87,525 manually labeled evidence passages, and a corpus of over 7,097,322 candidate passages. Each question is classified according to its formulation, type, as well as entity type of the answer. This resource allows us to evaluate the impact of different annotation choices on the performance of the QA system and propose an efficient annotation strategy that increases the passage retrieval performance by 10.55 p.p. while reducing the annotation cost by 82%.
Reservoir Computing Using Complex Systems
Dec 17, 2022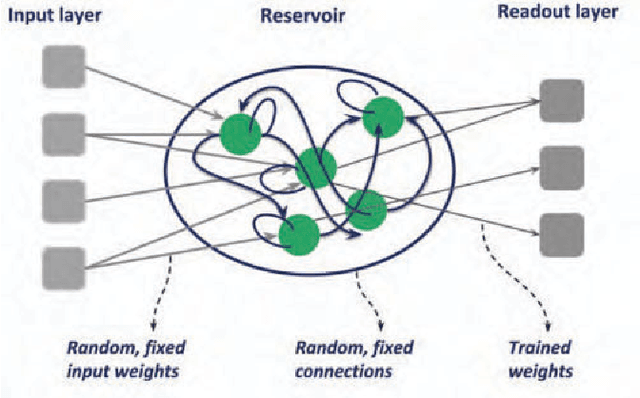
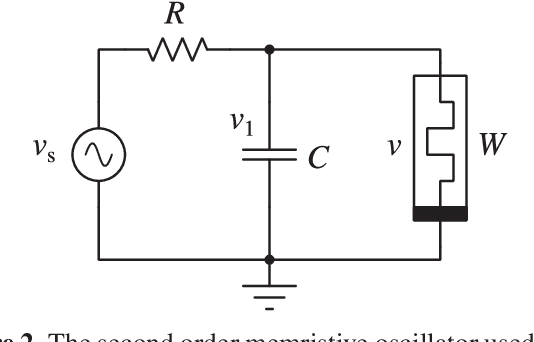
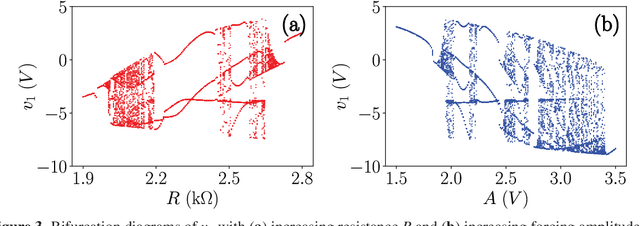
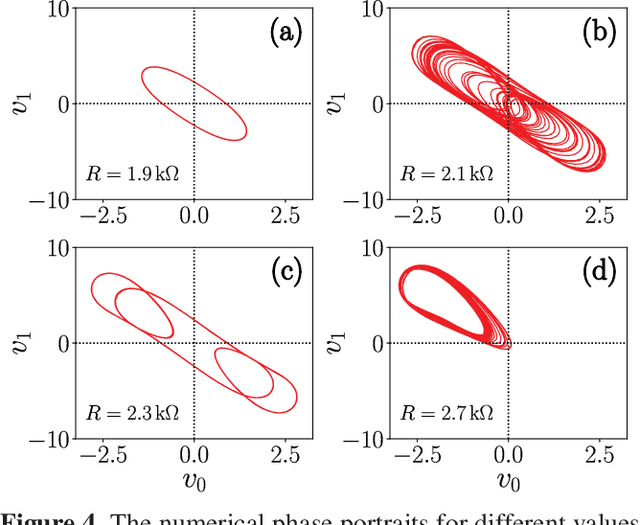
Reservoir Computing is an emerging machine learning framework which is a versatile option for utilising physical systems for computation. In this paper, we demonstrate how a single node reservoir, made of a simple electronic circuit, can be employed for computation and explore the available options to improve the computational capability of the physical reservoirs. We build a reservoir computing system using a memristive chaotic oscillator as the reservoir. We choose two of the available hyperparameters to find the optimal working regime for the reservoir, resulting in two reservoir versions. We compare the performance of both the reservoirs in a set of three non-temporal tasks: approximating two non-chaotic polynomials and a chaotic trajectory of the Lorenz time series. We also demonstrate how the dynamics of the physical system plays a direct role in the reservoir's hyperparameters and hence in the reservoir's prediction ability.
* 7 pages, 7 figures
Real-time Controllable Motion Transition for Characters
May 05, 2022

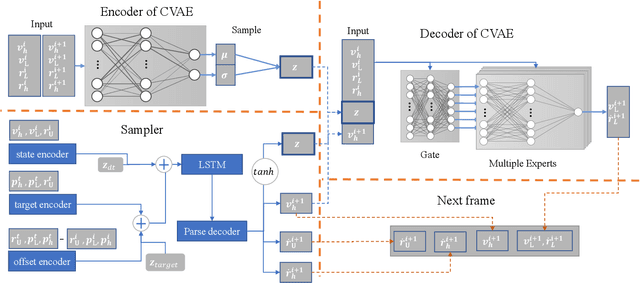
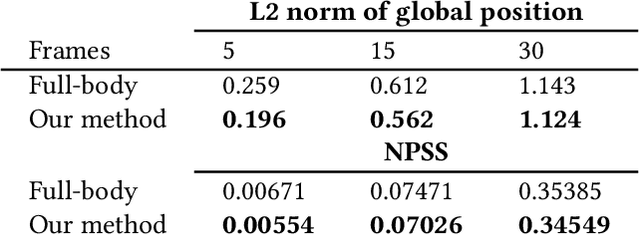
Real-time in-between motion generation is universally required in games and highly desirable in existing animation pipelines. Its core challenge lies in the need to satisfy three critical conditions simultaneously: quality, controllability and speed, which renders any methods that need offline computation (or post-processing) or cannot incorporate (often unpredictable) user control undesirable. To this end, we propose a new real-time transition method to address the aforementioned challenges. Our approach consists of two key components: motion manifold and conditional transitioning. The former learns the important low-level motion features and their dynamics; while the latter synthesizes transitions conditioned on a target frame and the desired transition duration. We first learn a motion manifold that explicitly models the intrinsic transition stochasticity in human motions via a multi-modal mapping mechanism. Then, during generation, we design a transition model which is essentially a sampling strategy to sample from the learned manifold, based on the target frame and the aimed transition duration. We validate our method on different datasets in tasks where no post-processing or offline computation is allowed. Through exhaustive evaluation and comparison, we show that our method is able to generate high-quality motions measured under multiple metrics. Our method is also robust under various target frames (with extreme cases).
A Light Touch Approach to Teaching Transformers Multi-view Geometry
Nov 28, 2022
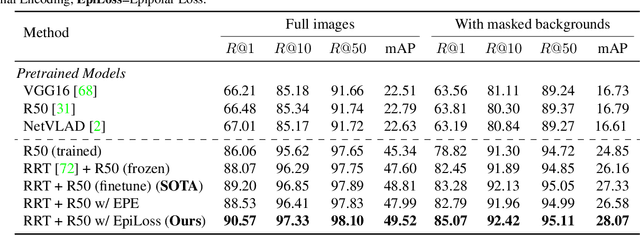
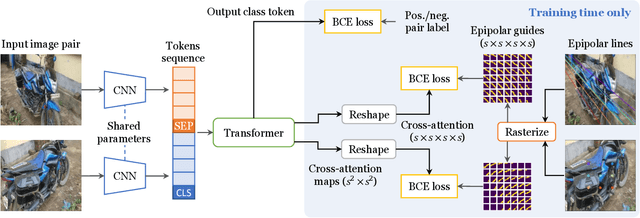
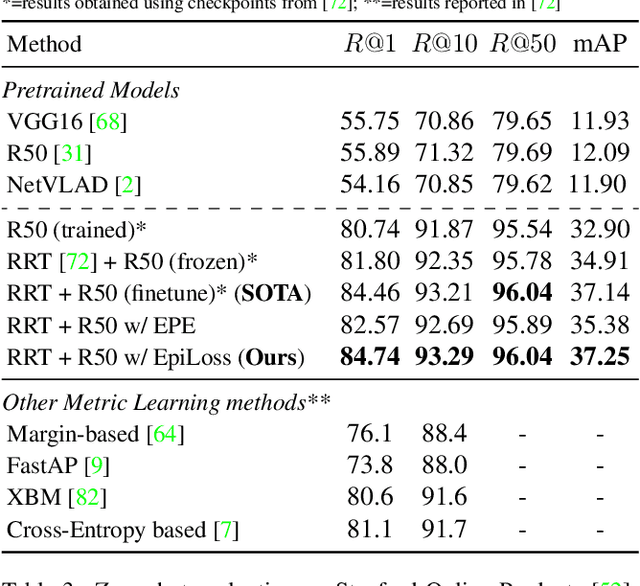
Transformers are powerful visual learners, in large part due to their conspicuous lack of manually-specified priors. This flexibility can be problematic in tasks that involve multiple-view geometry, due to the near-infinite possible variations in 3D shapes and viewpoints (requiring flexibility), and the precise nature of projective geometry (obeying rigid laws). To resolve this conundrum, we propose a "light touch" approach, guiding visual Transformers to learn multiple-view geometry but allowing them to break free when needed. We achieve this by using epipolar lines to guide the Transformer's cross-attention maps, penalizing attention values outside the epipolar lines and encouraging higher attention along these lines since they contain geometrically plausible matches. Unlike previous methods, our proposal does not require any camera pose information at test-time. We focus on pose-invariant object instance retrieval, where standard Transformer networks struggle, due to the large differences in viewpoint between query and retrieved images. Experimentally, our method outperforms state-of-the-art approaches at object retrieval, without needing pose information at test-time.
FastCycle: A Message Sharing Framework for Modular Automated Driving Systems
Nov 28, 2022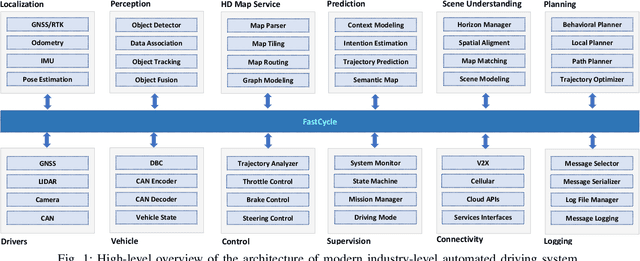
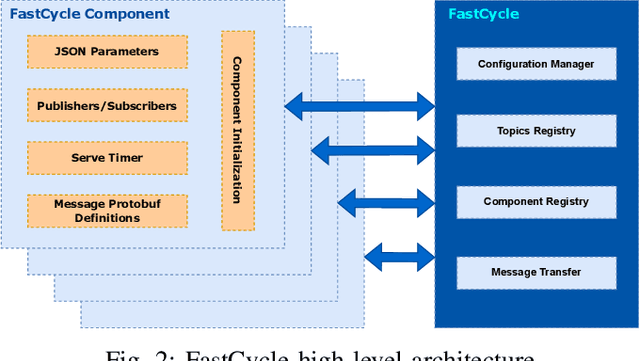
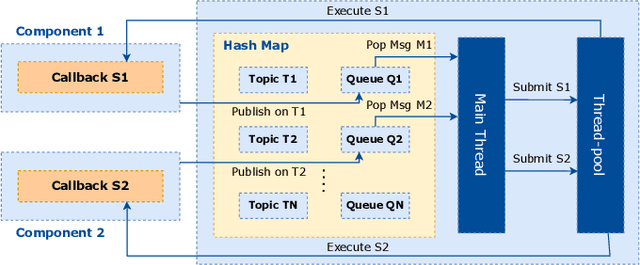
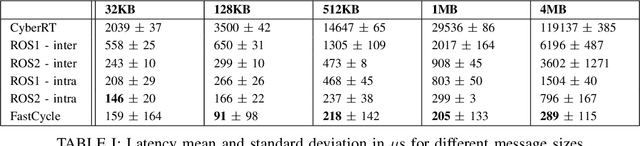
Automated Driving Systems (ADS) have rapidly evolved in recent years and their architecture becomes sophisticated. Ensuring robustness, reliability and safety of performance is particularly important. The main challenge in building an ADS is the ability to meet certain stringent performance requirements in terms of both making safe operational decisions and finishing processing in real-time. Middlewares play a crucial role to handle these requirements in ADS. The way middlewares share data between the different system components has a direct impact on the overall performance, particularly the latency overhead. To this end, this paper presents FastCycle as a lightweight multi-threaded zero-copy messaging broker to meet the requirements of a high fidelity ADS in terms of modularity, real-time performance and security. We discuss the architecture and the main features of the proposed framework. Evaluation of the proposed framework based on standard metrics in comparison with popular middlewares used in robotics and automated driving shows the improved performance of our framework. The implementation of FastCycle and the associated comparisons with other frameworks are open sourced.
Automated Detection of Dolphin Whistles with Convolutional Networks and Transfer Learning
Nov 28, 2022
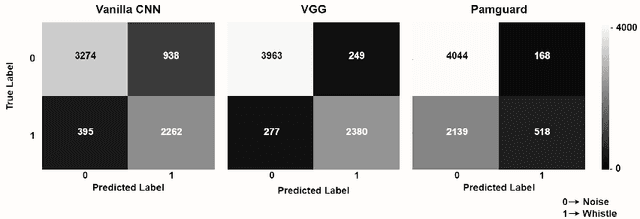
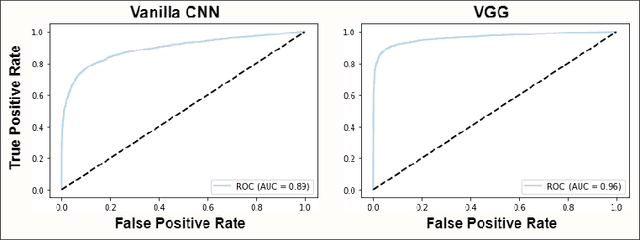
Effective conservation of maritime environments and wildlife management of endangered species require the implementation of efficient, accurate and scalable solutions for environmental monitoring. Ecoacoustics offers the advantages of non-invasive, long-duration sampling of environmental sounds and has the potential to become the reference tool for biodiversity surveying. However, the analysis and interpretation of acoustic data is a time-consuming process that often requires a great amount of human supervision. This issue might be tackled by exploiting modern techniques for automatic audio signal analysis, which have recently achieved impressive performance thanks to the advances in deep learning research. In this paper we show that convolutional neural networks can indeed significantly outperform traditional automatic methods in a challenging detection task: identification of dolphin whistles from underwater audio recordings. The proposed system can detect signals even in the presence of ambient noise, at the same time consistently reducing the likelihood of producing false positives and false negatives. Our results further support the adoption of artificial intelligence technology to improve the automatic monitoring of marine ecosystems.
A Visual Active Search Framework for Geospatial Exploration
Nov 28, 2022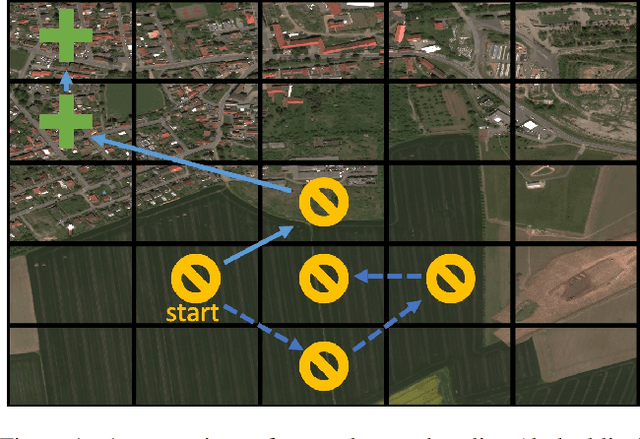
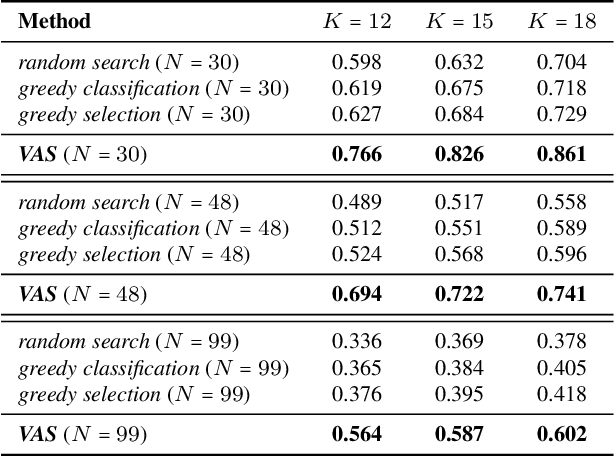
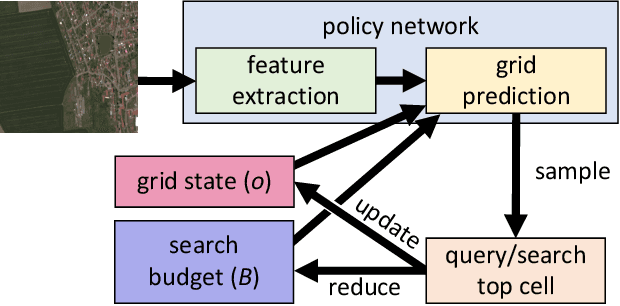
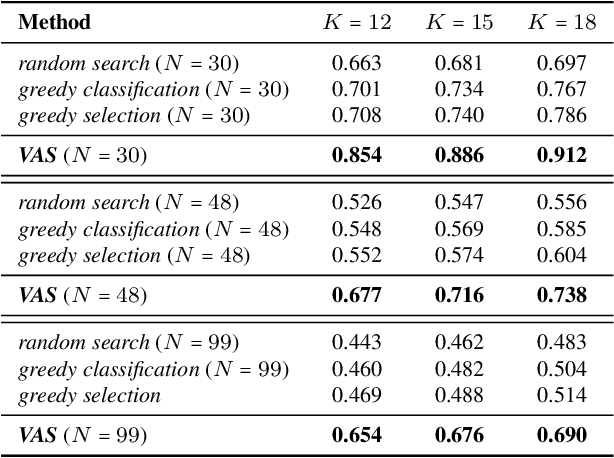
Many problems can be viewed as forms of geospatial search aided by aerial imagery, with examples ranging from detecting poaching activity to human trafficking. We model this class of problems in a visual active search (VAS) framework, which takes as input an image of a broad area, and aims to identify as many examples of a target object as possible. It does this through a limited sequence of queries, each of which verifies whether an example is present in a given region. We propose a reinforcement learning approach for VAS that leverages a collection of fully annotated search tasks as training data to learn a search policy, and combines features of the input image with a natural representation of active search state. Additionally, we propose domain adaptation techniques to improve the policy at decision time when training data is not fully reflective of the test-time distribution of VAS tasks. Through extensive experiments on several satellite imagery datasets, we show that the proposed approach significantly outperforms several strong baselines. Code and data will be made public.