 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pearl Causal Hierarchy on Image Data: Intricacies & Challenges
Dec 23, 2022
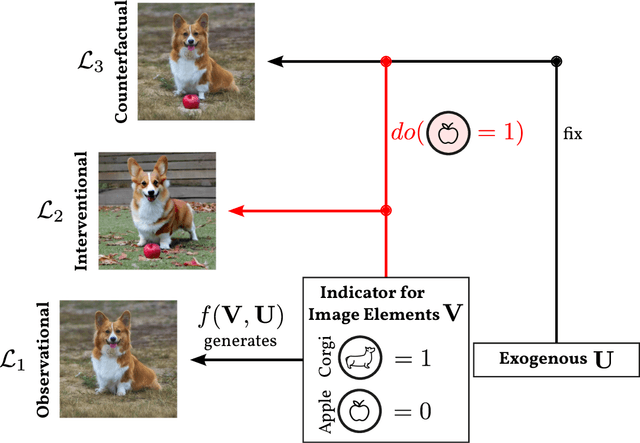

Many researchers have voiced their support towards Pearl's counterfactual theory of causation as a stepping stone for AI/ML research's ultimate goal of intelligent systems. As in any other growing subfield, patience seems to be a virtue since significant progress on integrating notions from both fields takes time, yet, major challenges such as the lack of ground truth benchmarks or a unified perspective on classical problems such as computer vision seem to hinder the momentum of the research movement. This present work exemplifies how the Pearl Causal Hierarchy (PCH) can be understood on image data by providing insights on several intricacies but also challenges that naturally arise when applying key concepts from Pearlian causality to the study of image data.
Alternating Projections Method for Joint Precoding and Peak-to-Average-Power Ratio Reduction
Dec 23, 2022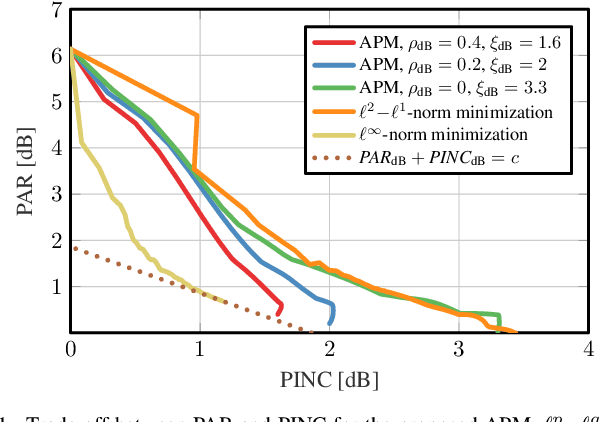
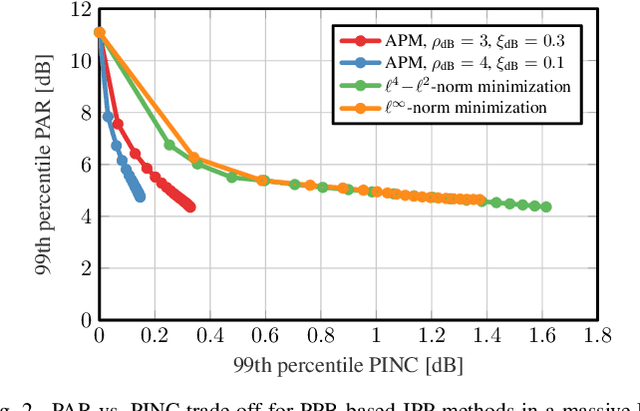
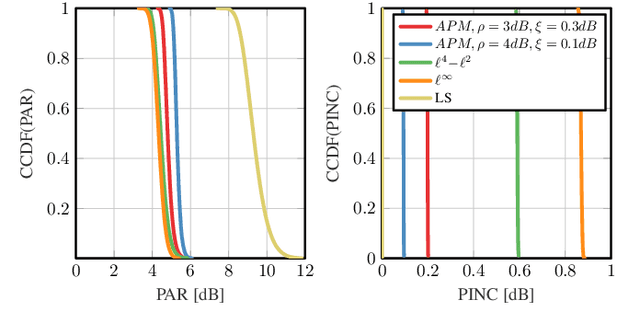
Orthogonal frequency-division multiplexing (OFDM) time-domain signals exhibit high peak-to-average (power) ratio (PAR), which requires linear radio-frequency chains to avoid an increase in error-vector magnitude (EVM) and out-of-band (OOB) emissions. In this paper, we propose a novel joint PAR reduction and precoding algorithm that relaxes these linearity requirements in massive multiuser (MU) multiple-input multiple-output (MIMO) wireless systems. Concretely, we develop a novel alternating projections method, which limits the PAR and transmit power increase while simultaneously suppressing MU interference. We provide a theoretical foundation of our algorithm and provide simulation results for a massive MU-MIMO-OFDM scenario. Our results demonstrate significant PAR reduction while limiting the transmit power, without causing EVM or OOB emissions.
Faster VoxelPose: Real-time 3D Human Pose Estimation by Orthographic Projection
Jul 22, 2022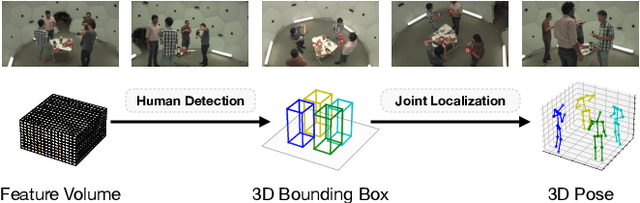

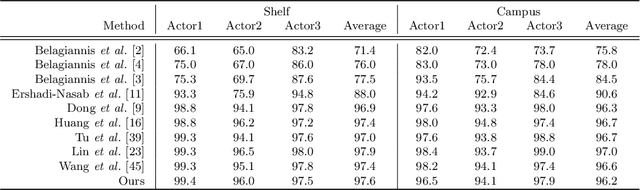
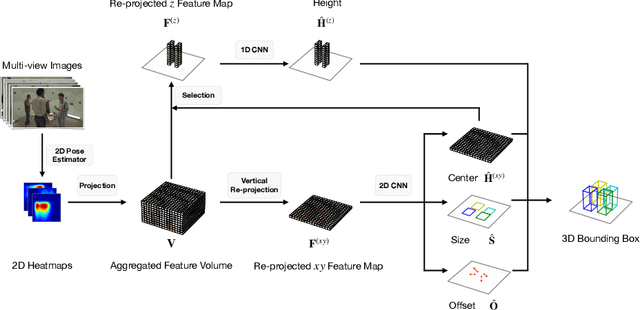
While the voxel-based methods have achieved promising results for multi-person 3D pose estimation from multi-cameras, they suffer from heavy computation burdens, especially for large scenes. We present Faster VoxelPose to address the challenge by re-projecting the feature volume to the three two-dimensional coordinate planes and estimating X, Y, Z coordinates from them separately. To that end, we first localize each person by a 3D bounding box by estimating a 2D box and its height based on the volume features projected to the xy-plane and z-axis, respectively. Then for each person, we estimate partial joint coordinates from the three coordinate planes separately which are then fused to obtain the final 3D pose. The method is free from costly 3D-CNNs and improves the speed of VoxelPose by ten times and meanwhile achieves competitive accuracy as the state-of-the-art methods, proving its potential in real-time applications.
Walk These Ways: Tuning Robot Control for Generalization with Multiplicity of Behavior
Dec 06, 2022
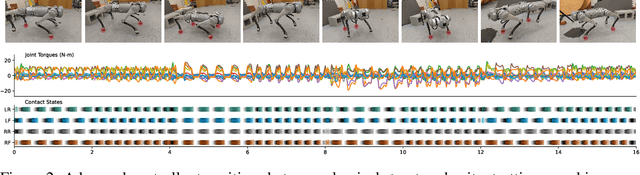
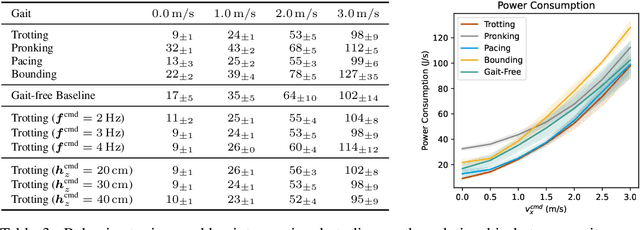
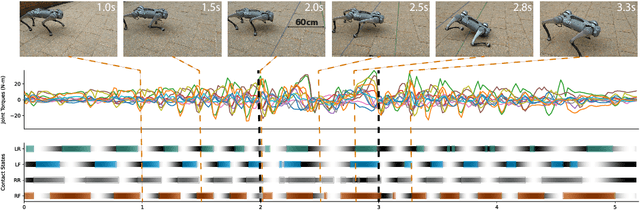
Learned locomotion policies can rapidly adapt to diverse environments similar to those experienced during training but lack a mechanism for fast tuning when they fail in an out-of-distribution test environment. This necessitates a slow and iterative cycle of reward and environment redesign to achieve good performance on a new task. As an alternative, we propose learning a single policy that encodes a structured family of locomotion strategies that solve training tasks in different ways, resulting in Multiplicity of Behavior (MoB). Different strategies generalize differently and can be chosen in real-time for new tasks or environments, bypassing the need for time-consuming retraining. We release a fast, robust open-source MoB locomotion controller, Walk These Ways, that can execute diverse gaits with variable footswing, posture, and speed, unlocking diverse downstream tasks: crouching, hopping, high-speed running, stair traversal, bracing against shoves, rhythmic dance, and more. Video and code release: https://gmargo11.github.io/walk-these-ways/
Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
Dec 06, 2022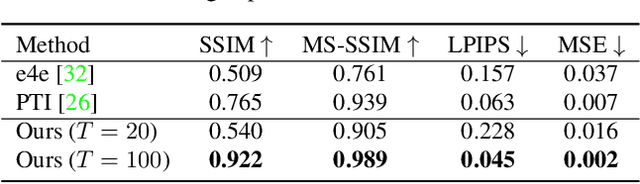
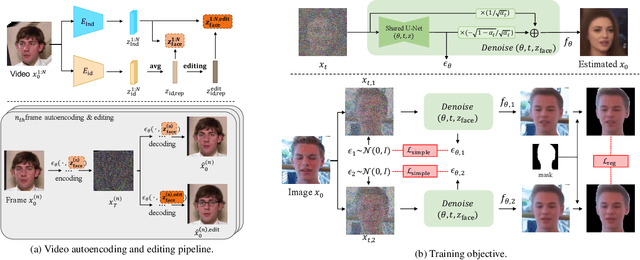
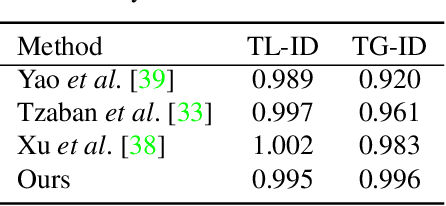
Inspired by the impressive performance of recent face image editing methods, several studies have been naturally proposed to extend these methods to the face video editing task. One of the main challenges here is temporal consistency among edited frames, which is still unresolved. To this end, we propose a novel face video editing framework based on diffusion autoencoders that can successfully extract the decomposed features - for the first time as a face video editing model - of identity and motion from a given video. This modeling allows us to edit the video by simply manipulating the temporally invariant feature to the desired direction for the consistency. Another unique strength of our model is that, since our model is based on diffusion models, it can satisfy both reconstruction and edit capabilities at the same time, and is robust to corner cases in wild face videos (e.g. occluded faces) unlike the existing GAN-based methods.
ReFace: Real-time Adversarial Attacks on Face Recognition Systems
Jun 09, 2022
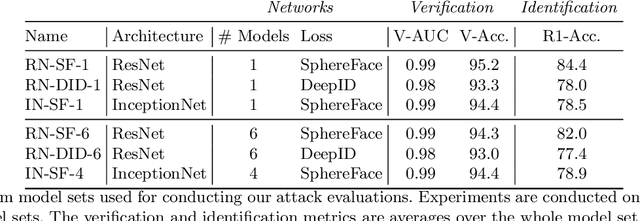
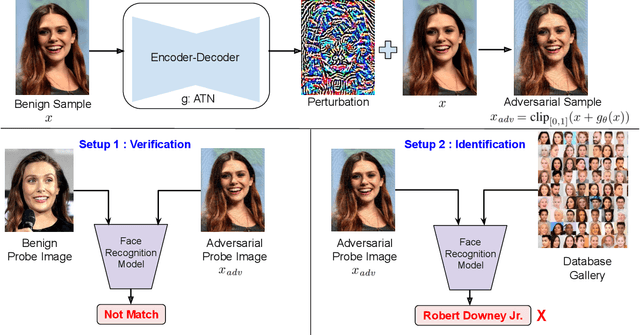
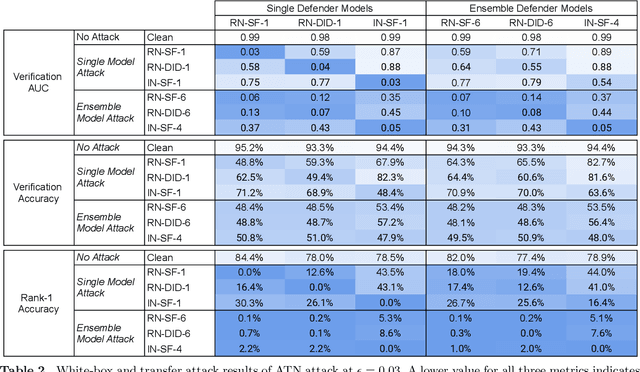
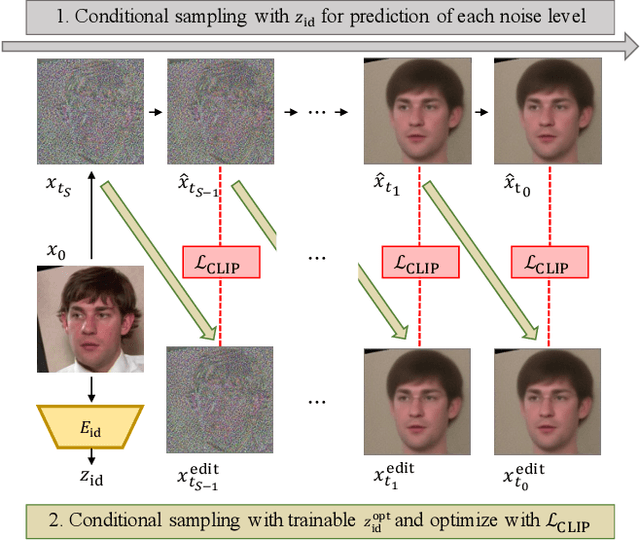
Deep neural network based face recognition models have been shown to be vulnerable to adversarial examples. However, many of the past attacks require the adversary to solve an input-dependent optimization problem using gradient descent which makes the attack impractical in real-time. These adversarial examples are also tightly coupled to the attacked model and are not as successful in transferring to different models. In this work, we propose ReFace, a real-time, highly-transferable attack on face recognition models based on Adversarial Transformation Networks (ATNs). ATNs model adversarial example generation as a feed-forward neural network. We find that the white-box attack success rate of a pure U-Net ATN falls substantially short of gradient-based attacks like PGD on large face recognition datasets. We therefore propose a new architecture for ATNs that closes this gap while maintaining a 10000x speedup over PGD. Furthermore, we find that at a given perturbation magnitude, our ATN adversarial perturbations are more effective in transferring to new face recognition models than PGD. ReFace attacks can successfully deceive commercial face recognition services in a transfer attack setting and reduce face identification accuracy from 82% to 16.4% for AWS SearchFaces API and Azure face verification accuracy from 91% to 50.1%.
Regional Precipitation Nowcasting Based on CycleGAN Extension
Nov 28, 2022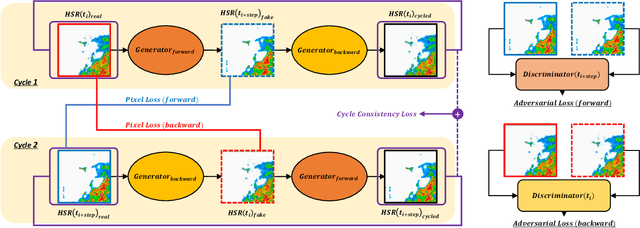

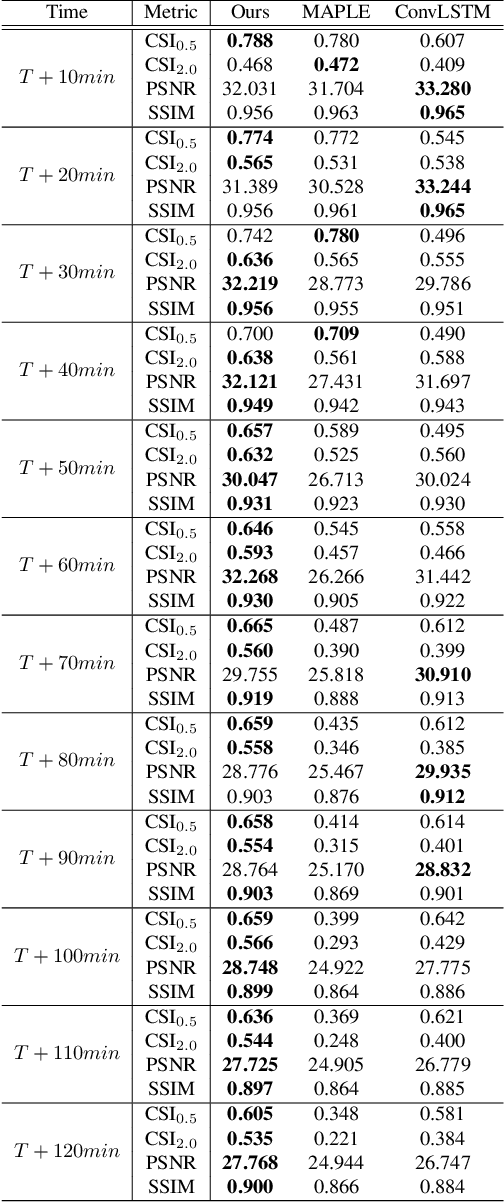
Unusually, intensive heavy rain hit the central region of Korea on August 8, 2022. Many low-lying areas were submerged, so traffic and life were severely paralyzed. It was the critical damage caused by torrential rain for just a few hours. This event reminded us of the need for a more reliable regional precipitation nowcasting method. In this paper, we bring cycle-consistent adversarial networks (CycleGAN) into the time-series domain and extend it to propose a reliable model for regional precipitation nowcasting. The proposed model generates composite hybrid surface rainfall (HSR) data after 10 minutes from the present time. Also, the proposed model provides a reliable prediction of up to 2 hours with a gradual extension of the training time steps. Unlike the existing complex nowcasting methods, the proposed model does not use recurrent neural networks (RNNs) and secures temporal causality via sequential training in the cycle. Our precipitation nowcasting method outperforms convolutional long short-term memory (ConvLSTM) based on RNNs. Additionally, we demonstrate the superiority of our approach by qualitative and quantitative comparisons against MAPLE, the McGill algorithm for precipitation nowcasting by lagrangian extrapolation, one of the real quantitative precipitation forecast (QPF) models.
Advanced Data Augmentation Approaches: A Comprehensive Survey and Future directions
Jan 07, 2023
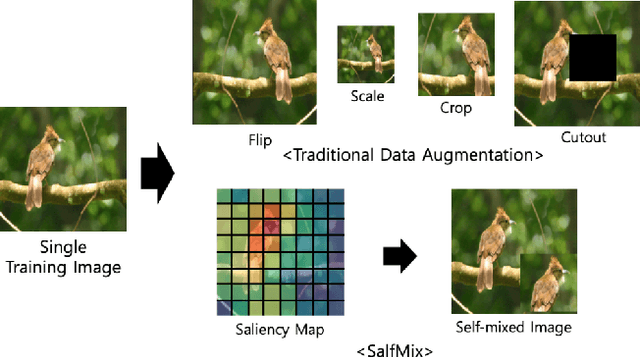


Deep learning (DL) algorithms have shown significant performance in various computer vision tasks. However, having limited labelled data lead to a network overfitting problem, where network performance is bad on unseen data as compared to training data. Consequently, it limits performance improvement. To cope with this problem, various techniques have been proposed such as dropout, normalization and advanced data augmentation. Among these, data augmentation, which aims to enlarge the dataset size by including sample diversity, has been a hot topic in recent times. In this article, we focus on advanced data augmentation techniques. we provide a background of data augmentation, a novel and comprehensive taxonomy of reviewed data augmentation techniques, and the strengths and weaknesses (wherever possible) of each technique. We also provide comprehensive results of the data augmentation effect on three popular computer vision tasks, such as image classification, object detection and semantic segmentation. For results reproducibility, we compiled available codes of all data augmentation techniques. Finally, we discuss the challenges and difficulties, and possible future direction for the research community. We believe, this survey provides several benefits i) readers will understand the data augmentation working mechanism to fix overfitting problems ii) results will save the searching time of the researcher for comparison purposes. iii) Codes of the mentioned data augmentation techniques are available at https://github.com/kmr2017/Advanced-Data-augmentation-codes iv) Future work will spark interest in research community.
Speed up the inference of diffusion models via shortcut MCMC sampling
Dec 18, 2022
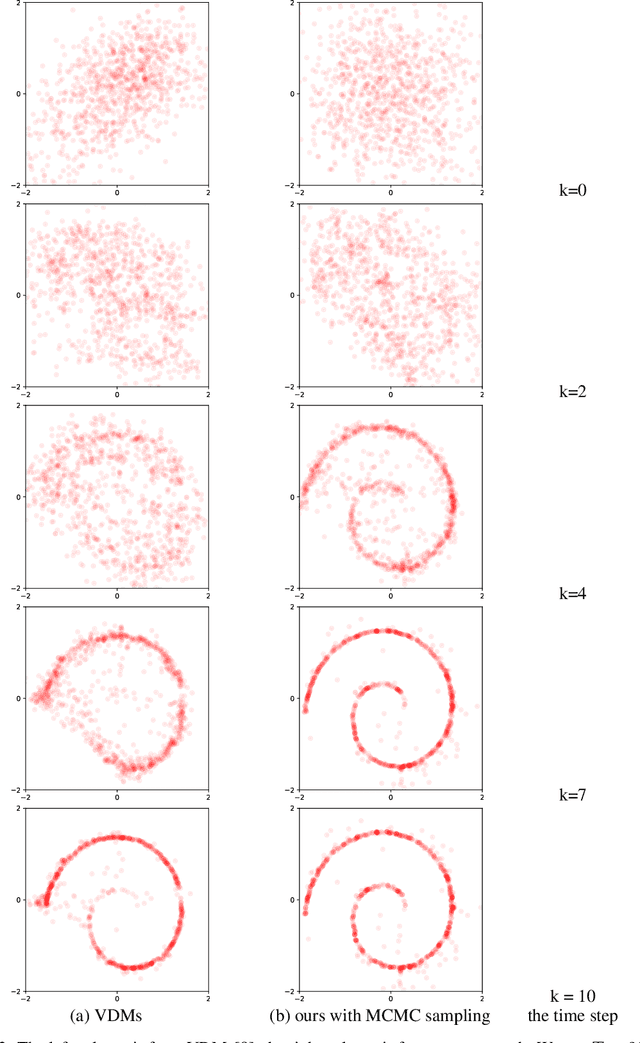
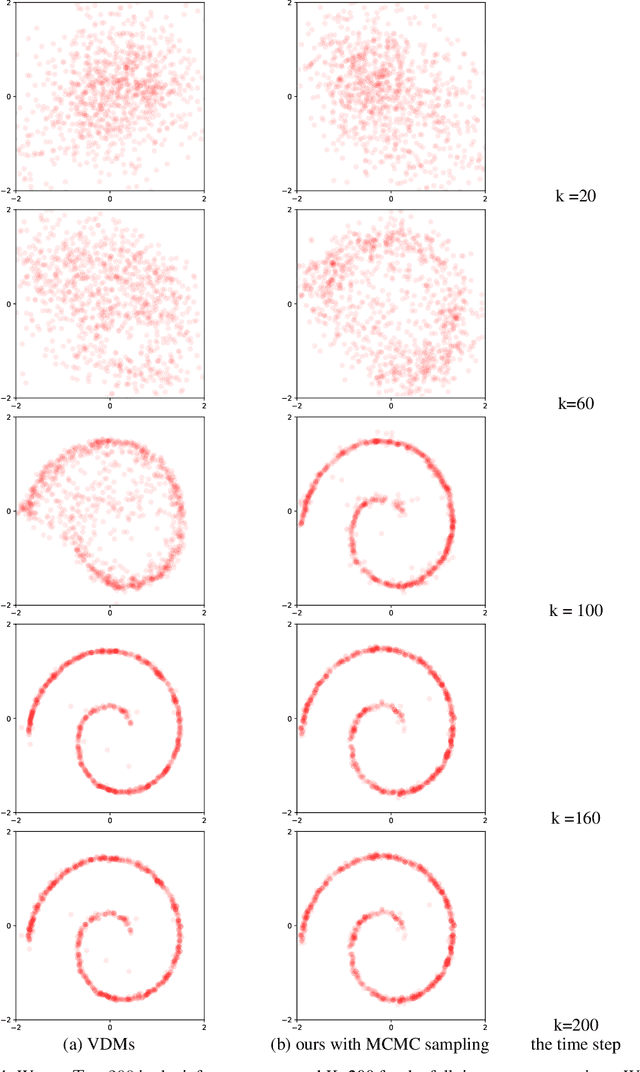
Diffusion probabilistic models have generated high quality image synthesis recently. However, one pain point is the notorious inference to gradually obtain clear images with thousands of steps, which is time consuming compared to other generative models. In this paper, we present a shortcut MCMC sampling algorithm, which balances training and inference, while keeping the generated data's quality. In particular, we add the global fidelity constraint with shortcut MCMC sampling to combat the local fitting from diffusion models. We do some initial experiments and show very promising results. Our implementation is available at https://github.com//vividitytech/diffusion-mcmc.git.
SATViz: Real-Time Visualization of Clausal Proofs
Sep 13, 2022
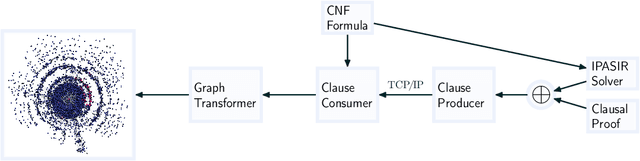
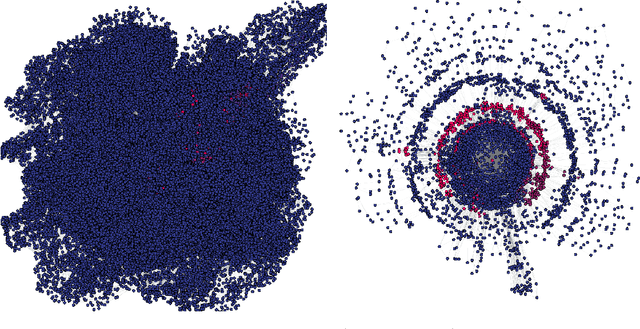
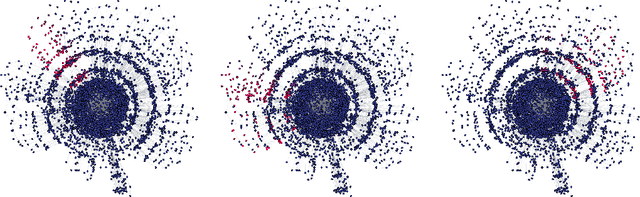
Visual layouts of graphs representing SAT instances can highlight the community structure of SAT instances. The community structure of SAT instances has been associated with both instance hardness and known clause quality heuristics. Our tool SATViz visualizes CNF formulas using the variable interaction graph and a force-directed layout algorithm. With SATViz, clause proofs can be animated to continuously highlight variables that occur in a moving window of recently learned clauses. If needed, SATViz can also create new layouts of the variable interaction graph with the adjusted edge weights. In this paper, we describe the structure and feature set of SATViz. We also present some interesting visualizations created with SATViz.