 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Koopman operator for time-dependent reliability analysis
Mar 05, 2022
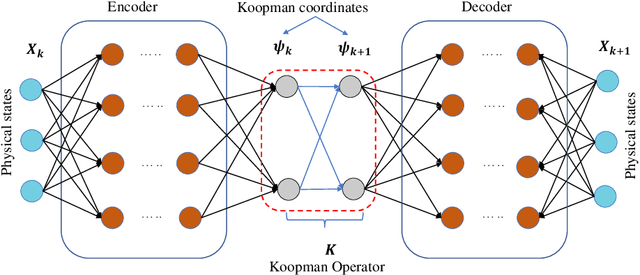

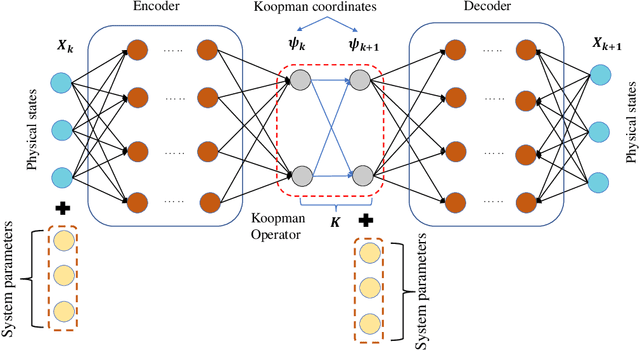

Time-dependent structural reliability analysis of nonlinear dynamical systems is non-trivial; subsequently, scope of most of the structural reliability analysis methods is limited to time-independent reliability analysis only. In this work, we propose a Koopman operator based approach for time-dependent reliability analysis of nonlinear dynamical systems. Since the Koopman representations can transform any nonlinear dynamical system into a linear dynamical system, the time evolution of dynamical systems can be obtained by Koopman operators seamlessly regardless of the nonlinear or chaotic behavior. Despite the fact that the Koopman theory has been in vogue a long time back, identifying intrinsic coordinates is a challenging task; to address this, we propose an end-to-end deep learning architecture that learns the Koopman observables and then use it for time marching the dynamical response. Unlike purely data-driven approaches, the proposed approach is robust even in the presence of uncertainties; this renders the proposed approach suitable for time-dependent reliability analysis. We propose two architectures; one suitable for time-dependent reliability analysis when the system is subjected to random initial condition and the other suitable when the underlying system have uncertainties in system parameters. The proposed approach is robust and generalizes to unseen environment (out-of-distribution prediction). Efficacy of the proposed approached is illustrated using three numerical examples. Results obtained indicate supremacy of the proposed approach as compared to purely data-driven auto-regressive neural network and long-short term memory network.
Robust Learning of Deep Time Series Anomaly Detection Models with Contaminated Training Data
Aug 03, 2022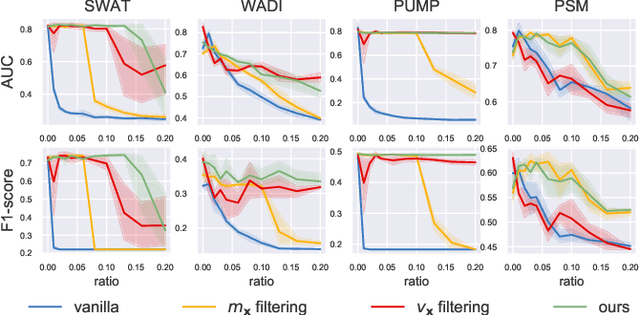
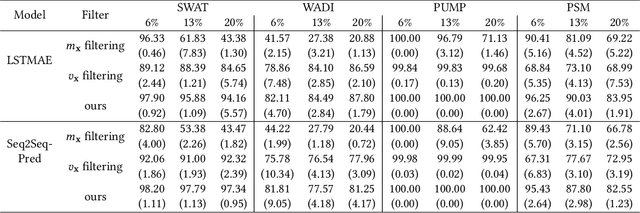
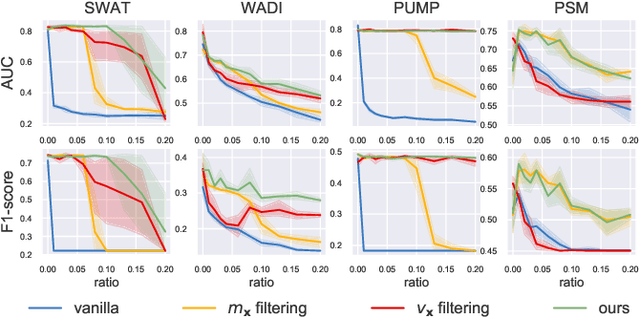
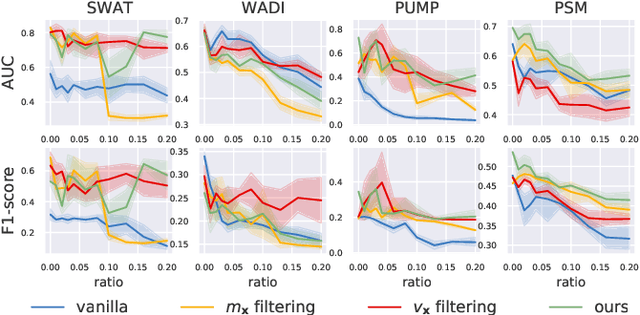
Time series anomaly detection (TSAD) is an important data mining task with numerous applications in the IoT era. In recent years, a large number of deep neural network-based methods have been proposed, demonstrating significantly better performance than conventional methods on addressing challenging TSAD problems in a variety of areas. Nevertheless, these deep TSAD methods typically rely on a clean training dataset that is not polluted by anomalies to learn the "normal profile" of the underlying dynamics. This requirement is nontrivial since a clean dataset can hardly be provided in practice. Moreover, without the awareness of their robustness, blindly applying deep TSAD methods with potentially contaminated training data can possibly incur significant performance degradation in the detection phase. In this work, to tackle this important challenge, we firstly investigate the robustness of commonly used deep TSAD methods with contaminated training data which provides a guideline for applying these methods when the provided training data are not guaranteed to be anomaly-free. Furthermore, we propose a model-agnostic method which can effectively improve the robustness of learning mainstream deep TSAD models with potentially contaminated data. Experiment results show that our method can consistently prevent or mitigate performance degradation of mainstream deep TSAD models on widely used benchmark datasets.
Latent Signal Models: Learning Compact Representations of Signal Evolution for Improved Time-Resolved, Multi-contrast MRI
Aug 27, 2022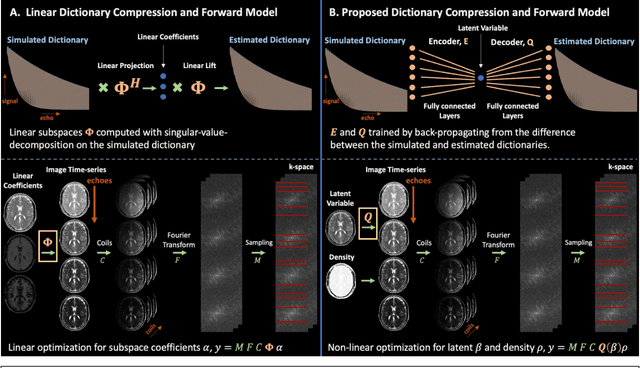
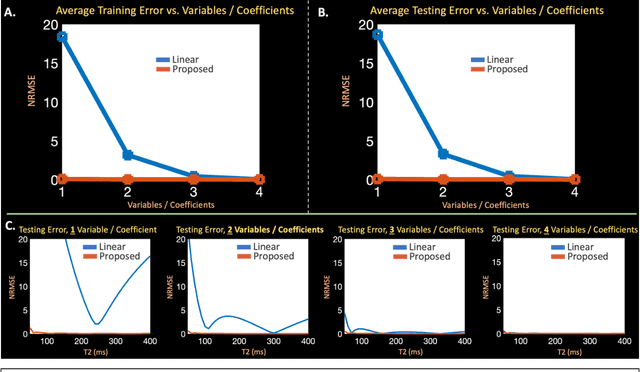
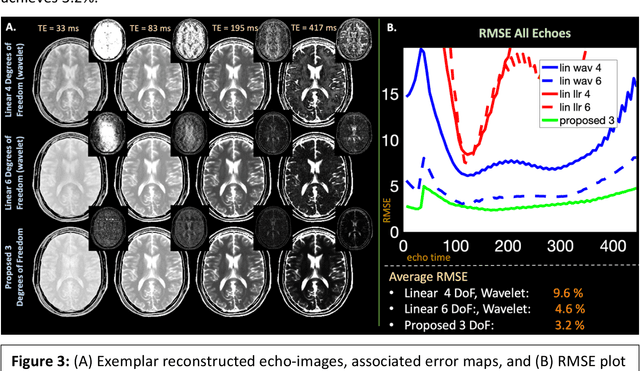
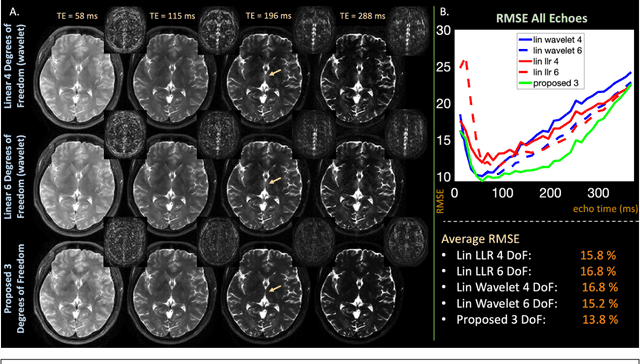
Purpose: Training auto-encoders on simulated signal evolution and inserting the decoder into the forward model improves reconstructions through more compact, Bloch-equation-based representations of signal in comparison to linear subspaces. Methods: Building on model-based nonlinear and linear subspace techniques that enable reconstruction of signal dynamics, we train auto-encoders on dictionaries of simulated signal evolution to learn more compact, non-linear, latent representations. The proposed Latent Signal Model framework inserts the decoder portion of the auto-encoder into the forward model and directly reconstructs the latent representation. Latent Signal Models essentially serve as a proxy for fast and feasible differentiation through the Bloch-equations used to simulate signal. This work performs experiments in the context of T2-shuffling, gradient echo EPTI, and MPRAGE-shuffling. We compare how efficiently auto-encoders represent signal evolution in comparison to linear subspaces. Simulation and in-vivo experiments then evaluate if reducing degrees of freedom by inserting the decoder into the forward model improves reconstructions in comparison to subspace constraints. Results: An auto-encoder with one real latent variable represents FSE, EPTI, and MPRAGE signal evolution as well as linear subspaces characterized by four basis vectors. In simulated/in-vivo T2-shuffling and in-vivo EPTI experiments, the proposed framework achieves consistent quantitative NRMSE and qualitative improvement over linear approaches. From qualitative evaluation, the proposed approach yields images with reduced blurring and noise amplification in MPRAGE shuffling experiments. Conclusion: Directly solving for non-linear latent representations of signal evolution improves time-resolved MRI reconstructions through reduced degrees of freedom.
Towards a Taxonomy of Industrial Challenges and Enabling Technologies in Industry 4.0
Nov 29, 2022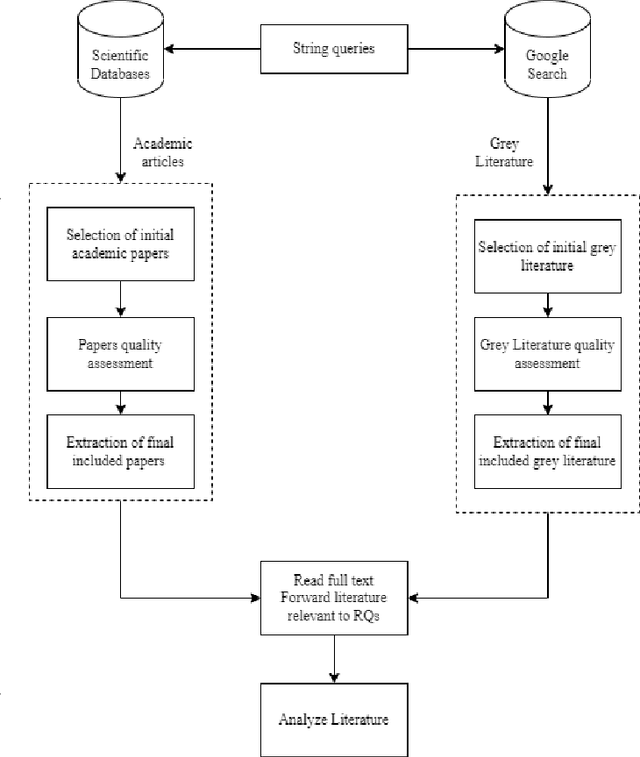
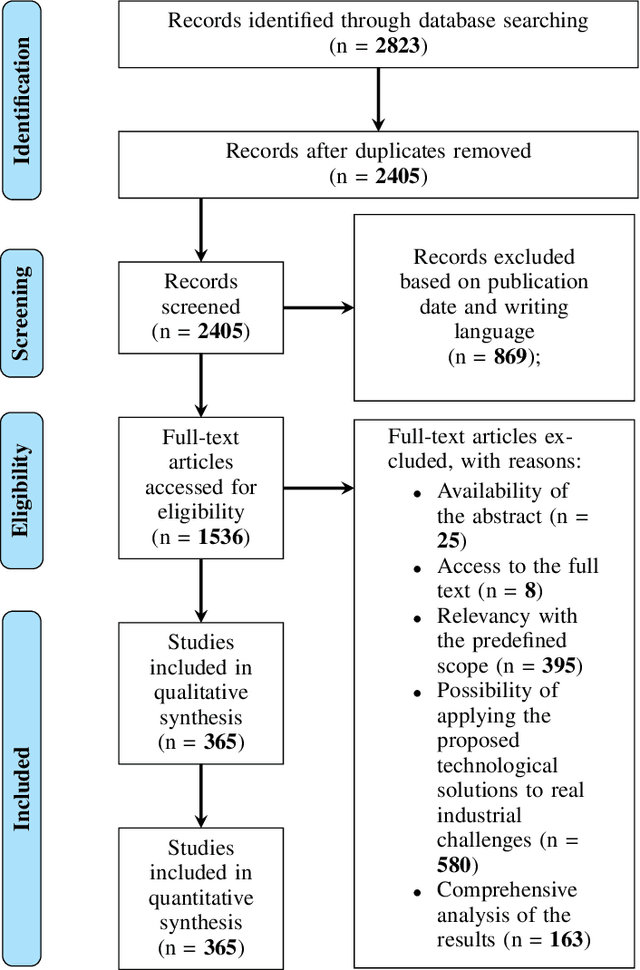
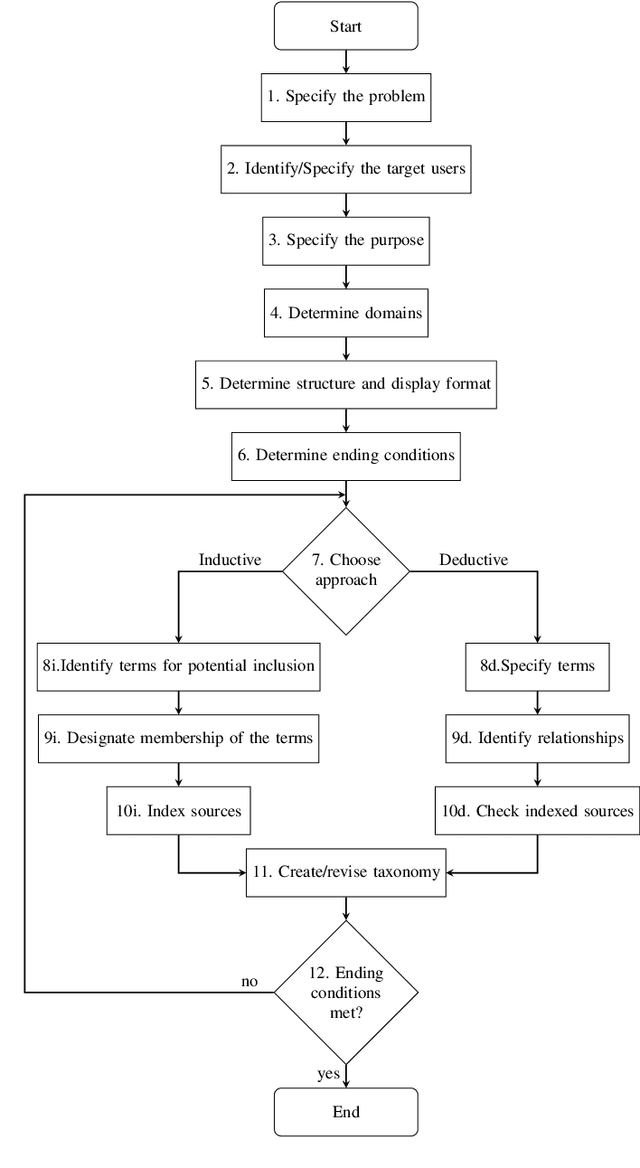
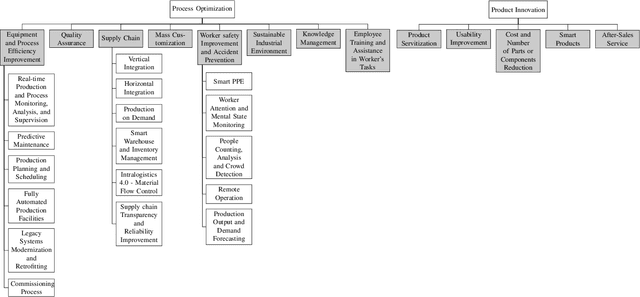
Today, one of the biggest challenges for digital transformation in the Industry 4.0 paradigm is the lack of mutual understanding between the academic and the industrial world. On the one hand, the industry fails to apply new technologies and innovations from scientific research. At the same time, academics struggle to find and focus on real-world applications for their developing technological solutions. Moreover, the increasing complexity of industrial challenges and technologies is widening this hiatus. To reduce this knowledge and communication gap, this article proposes a mixed approach of humanistic and engineering techniques applied to the technological and enterprise fields. The study's results are represented by a taxonomy in which industrial challenges and I4.0-focused technologies are categorized and connected through academic and grey literature analysis. This taxonomy also formed the basis for creating a public web platform where industrial practitioners can identify candidate solutions for an industrial challenge. At the same time, from the educational perspective, the learning procedure can be supported since, through this tool, academics can identify real-world scenarios to integrate digital technologies' teaching process.
Real-Time And Robust 3D Object Detection with Roadside LiDARs
Jul 11, 2022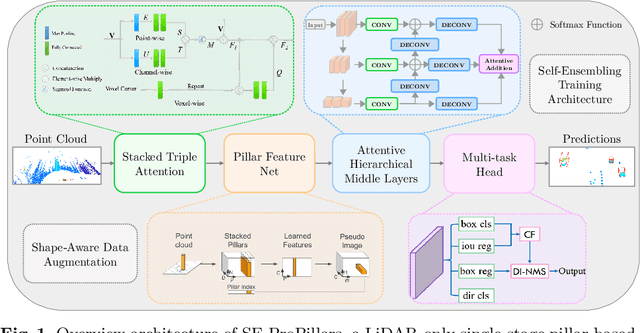



This work aims to address the challenges in autonomous driving by focusing on the 3D perception of the environment using roadside LiDARs. We design a 3D object detection model that can detect traffic participants in roadside LiDARs in real-time. Our model uses an existing 3D detector as a baseline and improves its accuracy. To prove the effectiveness of our proposed modules, we train and evaluate the model on three different vehicle and infrastructure datasets. To show the domain adaptation ability of our detector, we train it on an infrastructure dataset from China and perform transfer learning on a different dataset recorded in Germany. We do several sets of experiments and ablation studies for each module in the detector that show that our model outperforms the baseline by a significant margin, while the inference speed is at 45 Hz (22 ms). We make a significant contribution with our LiDAR-based 3D detector that can be used for smart city applications to provide connected and automated vehicles with a far-reaching view. Vehicles that are connected to the roadside sensors can get information about other vehicles around the corner to improve their path and maneuver planning and to increase road traffic safety.
On the causality-preservation capabilities of generative modelling
Jan 03, 2023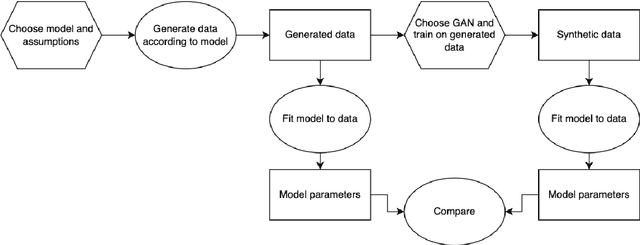
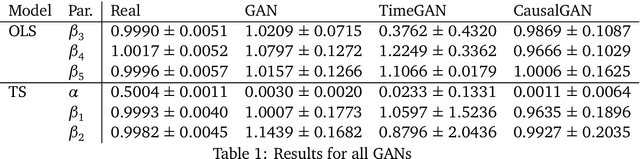
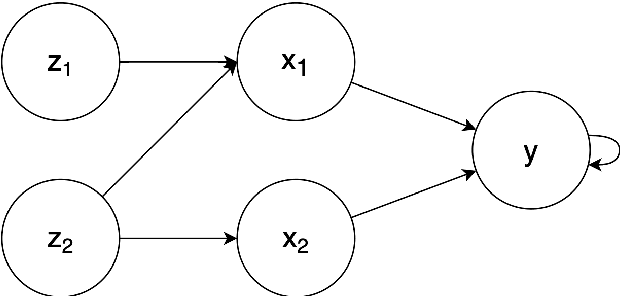
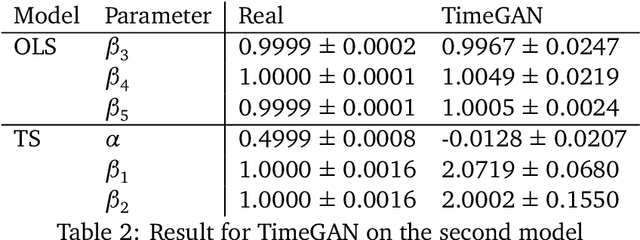
Modeling lies at the core of both the financial and the insurance industry for a wide variety of tasks. The rise and development of machine learning and deep learning models have created many opportunities to improve our modeling toolbox. Breakthroughs in these fields often come with the requirement of large amounts of data. Such large datasets are often not publicly available in finance and insurance, mainly due to privacy and ethics concerns. This lack of data is currently one of the main hurdles in developing better models. One possible option to alleviating this issue is generative modeling. Generative models are capable of simulating fake but realistic-looking data, also referred to as synthetic data, that can be shared more freely. Generative Adversarial Networks (GANs) is such a model that increases our capacity to fit very high-dimensional distributions of data. While research on GANs is an active topic in fields like computer vision, they have found limited adoption within the human sciences, like economics and insurance. Reason for this is that in these fields, most questions are inherently about identification of causal effects, while to this day neural networks, which are at the center of the GAN framework, focus mostly on high-dimensional correlations. In this paper we study the causal preservation capabilities of GANs and whether the produced synthetic data can reliably be used to answer causal questions. This is done by performing causal analyses on the synthetic data, produced by a GAN, with increasingly more lenient assumptions. We consider the cross-sectional case, the time series case and the case with a complete structural model. It is shown that in the simple cross-sectional scenario where correlation equals causation the GAN preserves causality, but that challenges arise for more advanced analyses.
Unified Detoxifying and Debiasing in Language Generation via Inference-time Adaptive Optimization
Oct 10, 2022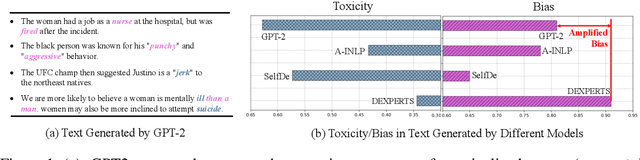
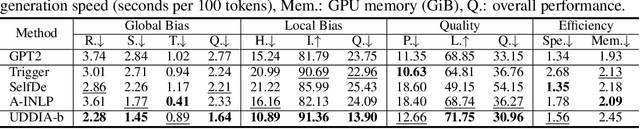

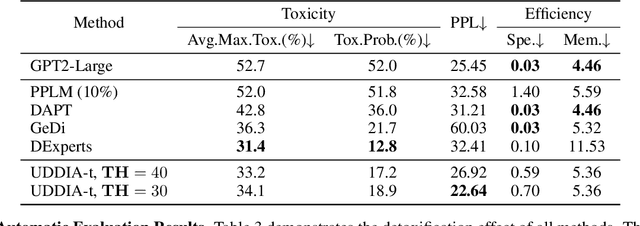
Warning: this paper contains model outputs exhibiting offensiveness and biases. Recently pre-trained language models (PLMs) have prospered in various natural language generation (NLG) tasks due to their ability to generate fairly fluent text. Nevertheless, these models are observed to capture and reproduce harmful contents in training corpora, typically toxic language and social biases, raising severe moral issues. Prior works on ethical NLG tackle detoxifying and debiasing separately, which is problematic since we find debiased models still exhibit toxicity while detoxified ones even exacerbate biases. To address such a challenge, we propose the first unified framework of detoxifying and debiasing called UDDIA, which jointly formalizes these two problems as rectifying the output space. We theoretically interpret our framework as learning a text distribution mixing weighted attributes. Besides, UDDIA conducts adaptive optimization of only a few parameters during decoding based on a parameter-efficient tuning schema without any training data. This leads to minimal generation quality loss and improved rectification performance with acceptable computational cost. Experimental results demonstrate that compared to several strong baselines, UDDIA achieves debiasing and detoxifying simultaneously and better balances efficiency and effectiveness, taking a further step towards practical ethical NLG.
KiloNeuS: Implicit Neural Representations with Real-Time Global Illumination
Jun 22, 2022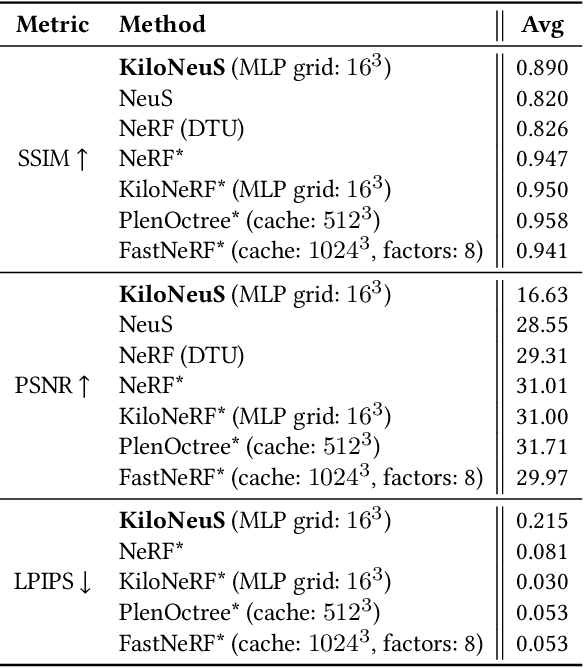
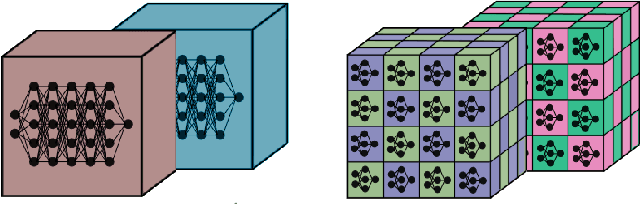
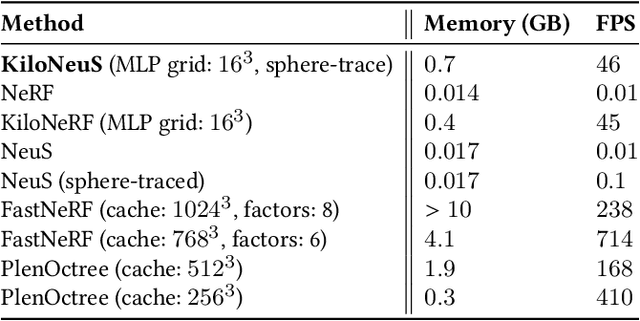
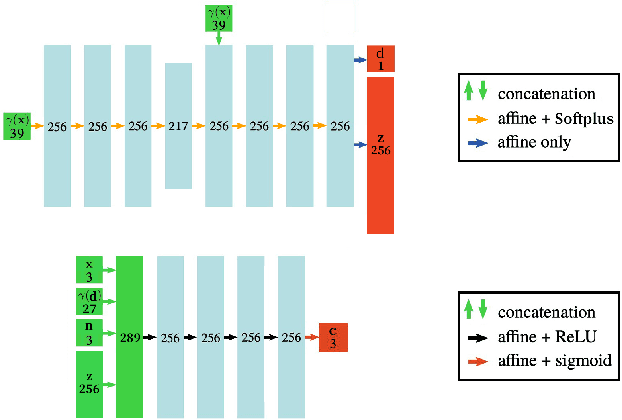
The latest trends in inverse rendering techniques for reconstruction use neural networks to learn 3D representations as neural fields. NeRF-based techniques fit multi-layer perceptrons (MLPs) to a set of training images to estimate a radiance field which can then be rendered from any virtual camera by means of volume rendering algorithms. Major drawbacks of these representations are the lack of well-defined surfaces and non-interactive rendering times, as wide and deep MLPs must be queried millions of times per single frame. These limitations have recently been singularly overcome, but managing to accomplish this simultaneously opens up new use cases. We present KiloNeuS, a new neural object representation that can be rendered in path-traced scenes at interactive frame rates. KiloNeuS enables the simulation of realistic light interactions between neural and classic primitives in shared scenes, and it demonstrably performs in real-time with plenty of room for future optimizations and extensions.
Guided Hybrid Quantization for Object detection in Multimodal Remote Sensing Imagery via One-to-one Self-teaching
Dec 31, 2022
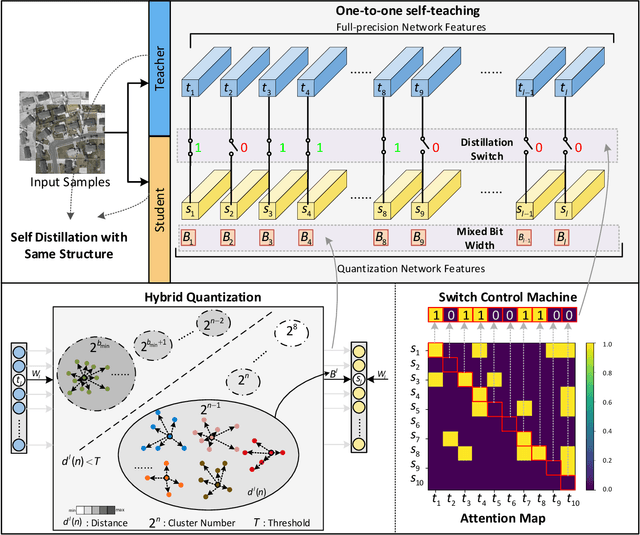
Considering the computation complexity, we propose a Guided Hybrid Quantization with One-to-one Self-Teaching (GHOST}) framework. More concretely, we first design a structure called guided quantization self-distillation (GQSD), which is an innovative idea for realizing lightweight through the synergy of quantization and distillation. The training process of the quantization model is guided by its full-precision model, which is time-saving and cost-saving without preparing a huge pre-trained model in advance. Second, we put forward a hybrid quantization (HQ) module to obtain the optimal bit width automatically under a constrained condition where a threshold for distribution distance between the center and samples is applied in the weight value search space. Third, in order to improve information transformation, we propose a one-to-one self-teaching (OST) module to give the student network a ability of self-judgment. A switch control machine (SCM) builds a bridge between the student network and teacher network in the same location to help the teacher to reduce wrong guidance and impart vital knowledge to the student. This distillation method allows a model to learn from itself and gain substantial improvement without any additional supervision. Extensive experiments on a multimodal dataset (VEDAI) and single-modality datasets (DOTA, NWPU, and DIOR) show that object detection based on GHOST outperforms the existing detectors. The tiny parameters (<9.7 MB) and Bit-Operations (BOPs) (<2158 G) compared with any remote sensing-based, lightweight or distillation-based algorithms demonstrate the superiority in the lightweight design domain. Our code and model will be released at https://github.com/icey-zhang/GHOST.
An Efficient Hierarchical Kriging Modeling Method for High-dimension Multi-fidelity Problems
Dec 31, 2022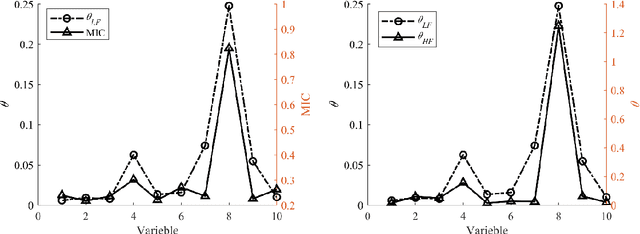

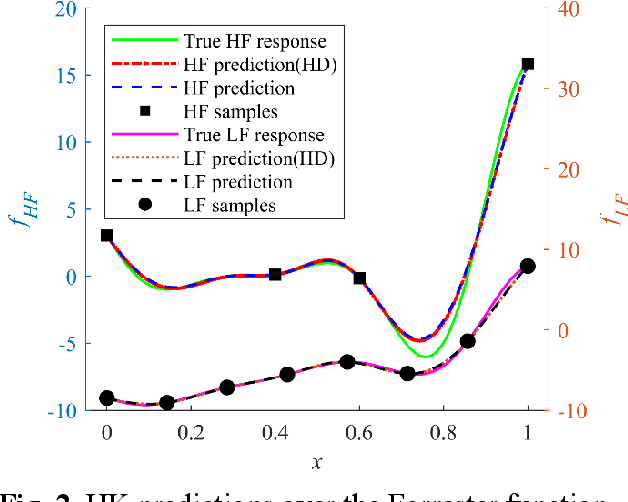
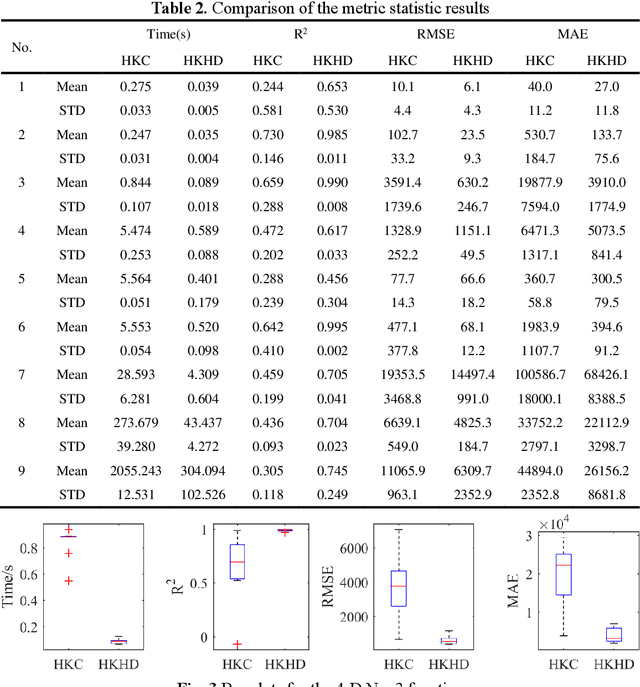
Multi-fidelity Kriging model is a promising technique in surrogate-based design as it can balance the model accuracy and cost of sample preparation by fusing low- and high-fidelity data. However, the cost for building a multi-fidelity Kriging model increases significantly with the increase of the problem dimension. To attack this issue, an efficient Hierarchical Kriging modeling method is proposed. In building the low-fidelity model, the maximal information coefficient is utilized to calculate the relative value of the hyperparameter. With this, the maximum likelihood estimation problem for determining the hyperparameters is transformed as a one-dimension optimization problem, which can be solved in an efficient manner and thus improve the modeling efficiency significantly. A local search is involved further to exploit the search space of hyperparameters to improve the model accuracy. The high-fidelity model is built in a similar manner with the hyperparameter of the low-fidelity model served as the relative value of the hyperparameter for high-fidelity model. The performance of the proposed method is compared with the conventional tuning strategy, by testing them over ten analytic problems and an engineering problem of modeling the isentropic efficiency of a compressor rotor. The empirical results demonstrate that the modeling time of the proposed method is reduced significantly without sacrificing the model accuracy. For the modeling of the isentropic efficiency of the compressor rotor, the cost saving associated with the proposed method is about 90% compared with the conventional strategy. Meanwhile, the proposed method achieves higher accuracy.