 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Spatio-Temporal Aware Traffic Time Series Forecasting--Full Version
Apr 05, 2022
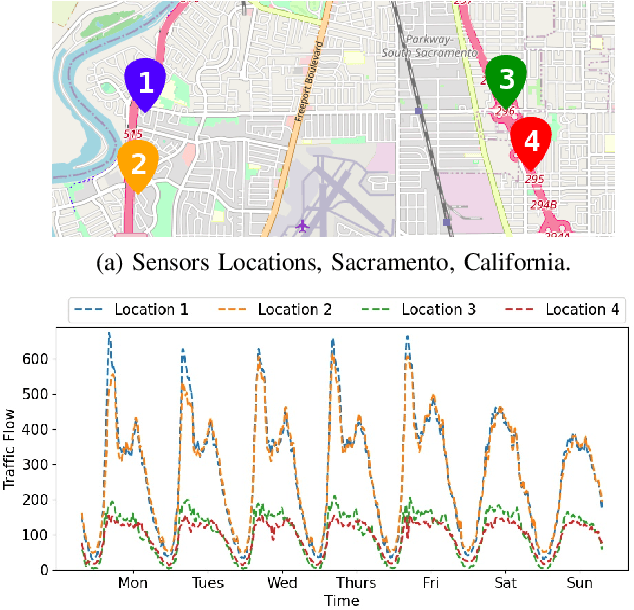
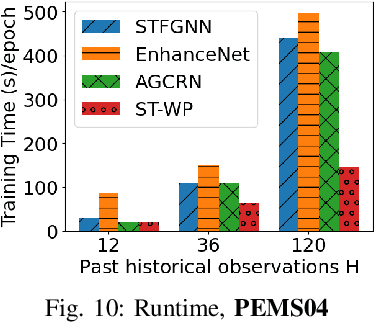
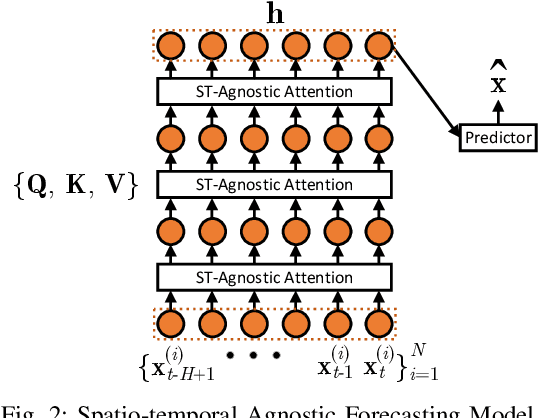
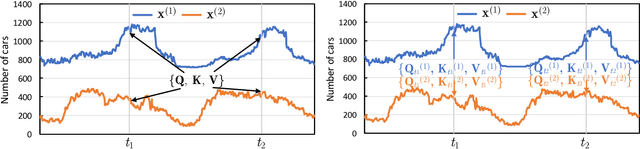
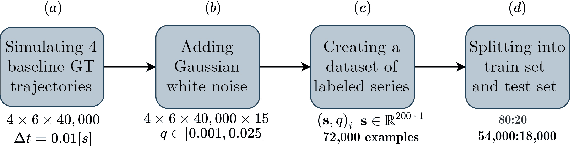
Traffic time series forecasting is challenging due to complex spatio-temporal dynamics time series from different locations often have distinct patterns; and for the same time series, patterns may vary across time, where, for example, there exist certain periods across a day showing stronger temporal correlations. Although recent forecasting models, in particular deep learning based models, show promising results, they suffer from being spatio-temporal agnostic. Such spatio-temporal agnostic models employ a shared parameter space irrespective of the time series locations and the time periods and they assume that the temporal patterns are similar across locations and do not evolve across time, which may not always hold, thus leading to sub-optimal results. In this work, we propose a framework that aims at turning spatio-temporal agnostic models to spatio-temporal aware models. To do so, we encode time series from different locations into stochastic variables, from which we generate location-specific and time-varying model parameters to better capture the spatio-temporal dynamics. We show how to integrate the framework with canonical attentions to enable spatio-temporal aware attentions. Next, to compensate for the additional overhead introduced by the spatio-temporal aware model parameter generation process, we propose a novel window attention scheme, which helps reduce the complexity from quadratic to linear, making spatio-temporal aware attentions also have competitive efficiency. We show strong empirical evidence on four traffic time series datasets, where the proposed spatio-temporal aware attentions outperform state-of-the-art methods in term of accuracy and efficiency. This is an extended version of "Towards Spatio-Temporal Aware Traffic Time Series Forecasting", to appear in ICDE 2022 [1], including additional experimental results.
GENIE: Large Scale Pre-training for Text Generation with Diffusion Model
Dec 22, 2022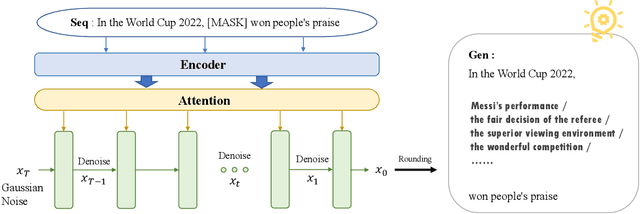
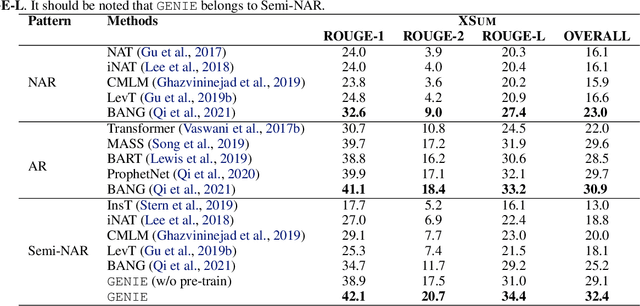

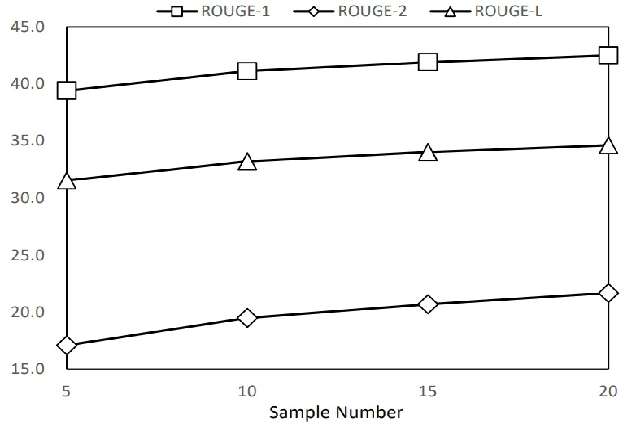
In this paper, we propose a large-scale language pre-training for text GENeration using dIffusion modEl, which is named GENIE. GENIE is a pre-training sequence-to-sequence text generation model which combines Transformer and diffusion. The diffusion model accepts the latent information from the encoder, which is used to guide the denoising of the current time step. After multiple such denoise iterations, the diffusion model can restore the Gaussian noise to the diverse output text which is controlled by the input text. Moreover, such architecture design also allows us to adopt large scale pre-training on the GENIE. We propose a novel pre-training method named continuous paragraph denoise based on the characteristics of the diffusion model. Extensive experiments on the XSum, CNN/DailyMail, and Gigaword benchmarks shows that GENIE can achieves comparable performance with various strong baselines, especially after pre-training, the generation quality of GENIE is greatly improved. We have also conduct a lot of experiments on the generation diversity and parameter impact of GENIE. The code for GENIE will be made publicly available.
SupeRGB-D: Zero-shot Instance Segmentation in Cluttered Indoor Environments
Dec 22, 2022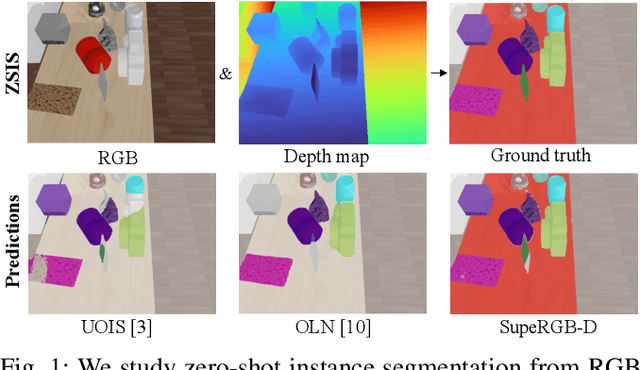
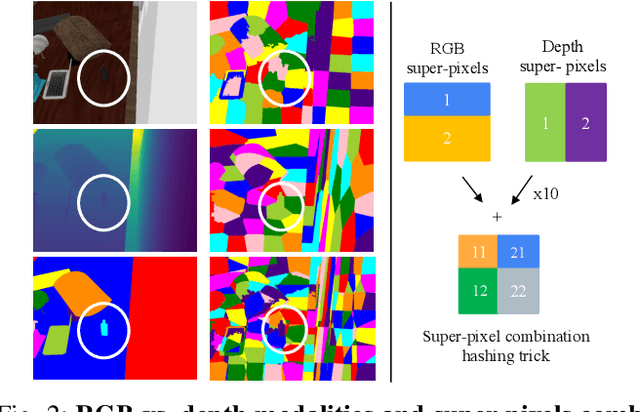
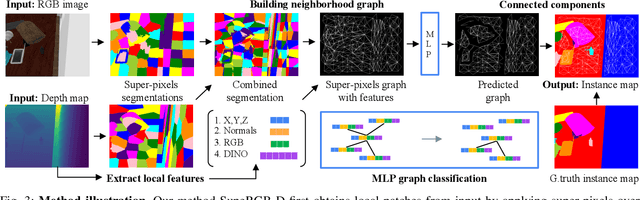

Object instance segmentation is a key challenge for indoor robots navigating cluttered environments with many small objects. Limitations in 3D sensing capabilities often make it difficult to detect every possible object. While deep learning approaches may be effective for this problem, manually annotating 3D data for supervised learning is time-consuming. In this work, we explore zero-shot instance segmentation (ZSIS) from RGB-D data to identify unseen objects in a semantic category-agnostic manner. We introduce a zero-shot split for Tabletop Objects Dataset (TOD-Z) to enable this study and present a method that uses annotated objects to learn the ``objectness'' of pixels and generalize to unseen object categories in cluttered indoor environments. Our method, SupeRGB-D, groups pixels into small patches based on geometric cues and learns to merge the patches in a deep agglomerative clustering fashion. SupeRGB-D outperforms existing baselines on unseen objects while achieving similar performance on seen objects. Additionally, it is extremely lightweight (0.4 MB memory requirement) and suitable for mobile and robotic applications. The dataset split and code will be made publicly available upon acceptance.
Runtime Performance of Evolutionary Algorithms for the Chance-constrained Makespan Scheduling Problem
Dec 22, 2022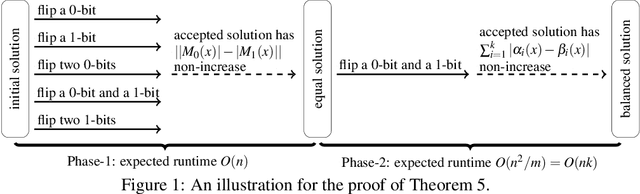

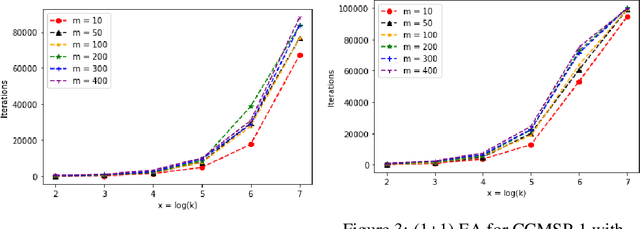
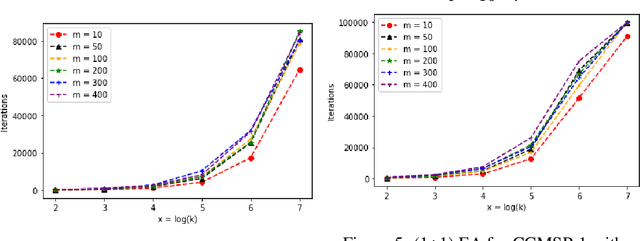
The Makespan Scheduling problem is an extensively studied NP-hard problem, and its simplest version looks for an allocation approach for a set of jobs with deterministic processing times to two identical machines such that the makespan is minimized. However, in real life scenarios, the actual processing time of each job may be stochastic around the expected value with a variance, under the influence of external factors, and the actual processing times of these jobs may be correlated with covariances. Thus within this paper, we propose a chance-constrained version of the Makespan Scheduling problem and investigate the theoretical performance of the classical Randomized Local Search and (1+1) EA for it. More specifically, we first study two variants of the Chance-constrained Makespan Scheduling problem and their computational complexities, then separately analyze the expected runtime of the two algorithms to obtain an optimal solution or almost optimal solution to the instances of the two variants. In addition, we investigate the experimental performance of the two algorithms for the two variants.
ProNet: Adaptive Process Noise Estimation for INS/DVL Fusion
Dec 17, 2022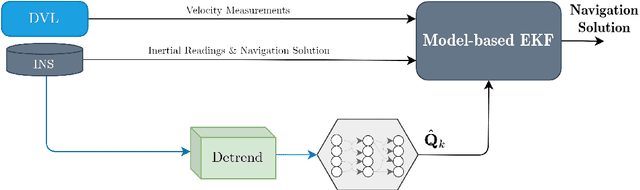
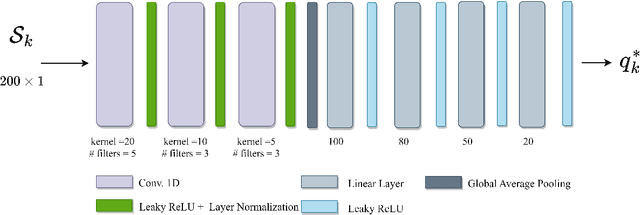
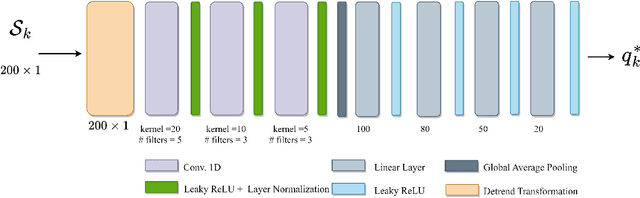
Inertial and Doppler velocity log sensors are commonly used to provide the navigation solution for autonomous underwater vehicles (AUV). To this end, a nonlinear filter is adopted for the fusion task. The filter's process noise covariance matrix is critical for filter accuracy and robustness. While this matrix varies over time during the AUV mission, the filter assumes a constant matrix. Several models and learning approaches in the literature suggest tuning the process noise covariance during operation. In this work, we propose ProNet, a hybrid, adaptive process, noise estimation approach for a velocity-aided navigation filter. ProNet requires only the inertial sensor reading to regress the process noise covariance. Once learned, it is fed into the model-based navigation filter, resulting in a hybrid filter. Simulation results show the benefits of our approach compared to other models and learning adaptive approaches.
DT-SV: A Transformer-based Time-domain Approach for Speaker Verification
May 26, 2022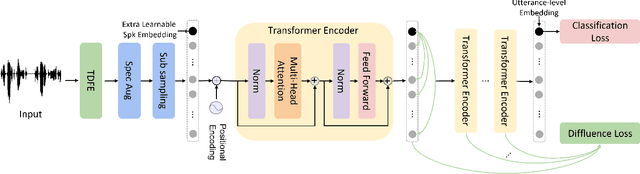
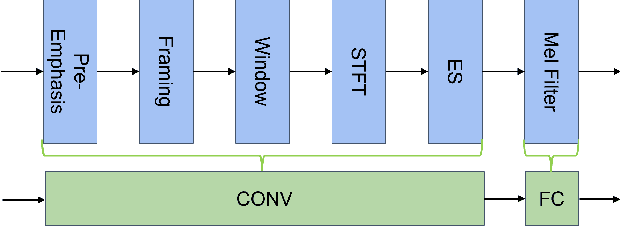
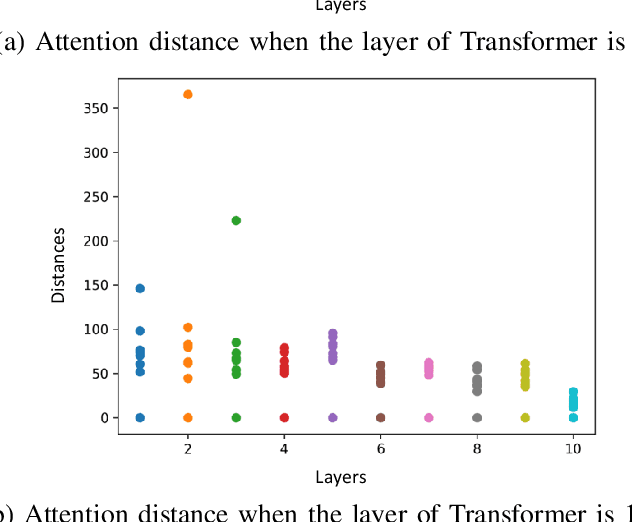
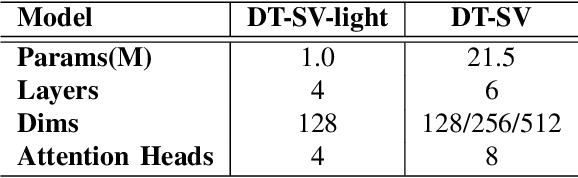
Speaker verification (SV) aims to determine whether the speaker's identity of a test utterance is the same as the reference speech. In the past few years, extracting speaker embeddings using deep neural networks for SV systems has gone mainstream. Recently, different attention mechanisms and Transformer networks have been explored widely in SV fields. However, utilizing the original Transformer in SV directly may have frame-level information waste on output features, which could lead to restrictions on capacity and discrimination of speaker embeddings. Therefore, we propose an approach to derive utterance-level speaker embeddings via a Transformer architecture that uses a novel loss function named diffluence loss to integrate the feature information of different Transformer layers. Therein, the diffluence loss aims to aggregate frame-level features into an utterance-level representation, and it could be integrated into the Transformer expediently. Besides, we also introduce a learnable mel-fbank energy feature extractor named time-domain feature extractor that computes the mel-fbank features more precisely and efficiently than the standard mel-fbank extractor. Combining Diffluence loss and Time-domain feature extractor, we propose a novel Transformer-based time-domain SV model (DT-SV) with faster training speed and higher accuracy. Experiments indicate that our proposed model can achieve better performance in comparison with other models.
Performance Analysis of YOLO-based Architectures for Vehicle Detection from Traffic Images in Bangladesh
Dec 24, 2022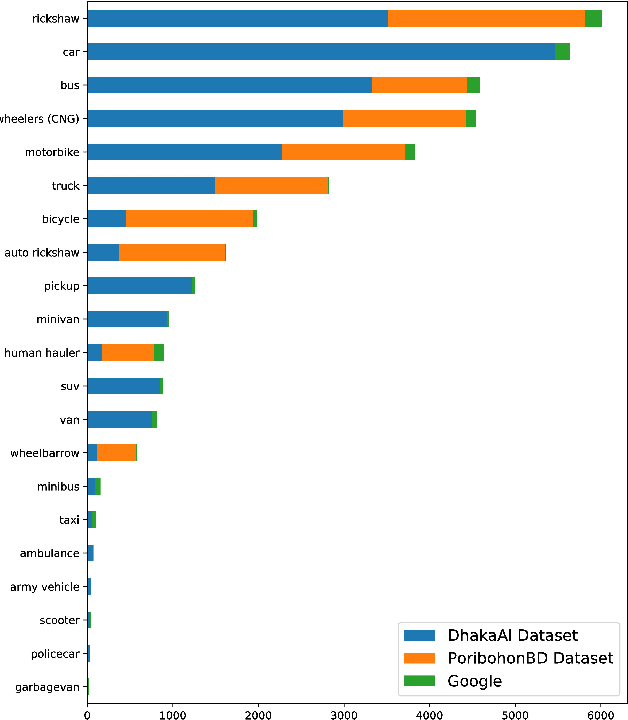

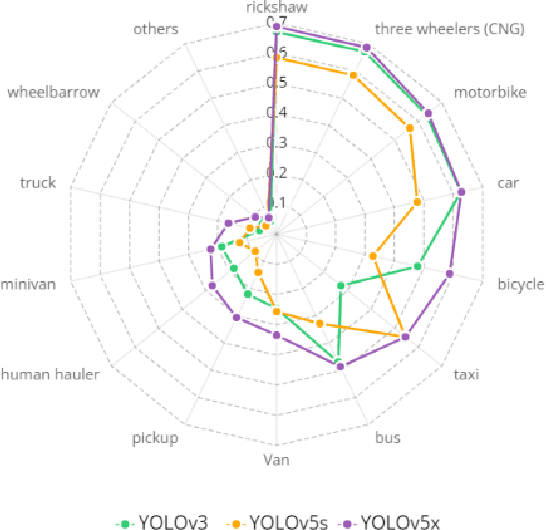

The task of locating and classifying different types of vehicles has become a vital element in numerous applications of automation and intelligent systems ranging from traffic surveillance to vehicle identification and many more. In recent times, Deep Learning models have been dominating the field of vehicle detection. Yet, Bangladeshi vehicle detection has remained a relatively unexplored area. One of the main goals of vehicle detection is its real-time application, where `You Only Look Once' (YOLO) models have proven to be the most effective architecture. In this work, intending to find the best-suited YOLO architecture for fast and accurate vehicle detection from traffic images in Bangladesh, we have conducted a performance analysis of different variants of the YOLO-based architectures such as YOLOV3, YOLOV5s, and YOLOV5x. The models were trained on a dataset containing 7390 images belonging to 21 types of vehicles comprising samples from the DhakaAI dataset, the Poribohon-BD dataset, and our self-collected images. After thorough quantitative and qualitative analysis, we found the YOLOV5x variant to be the best-suited model, performing better than YOLOv3 and YOLOv5s models respectively by 7 & 4 percent in mAP, and 12 & 8.5 percent in terms of Accuracy.
A Large-scale Friend Suggestion Architecture
Dec 24, 2022
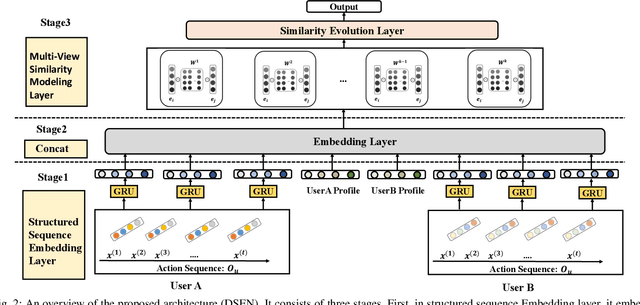
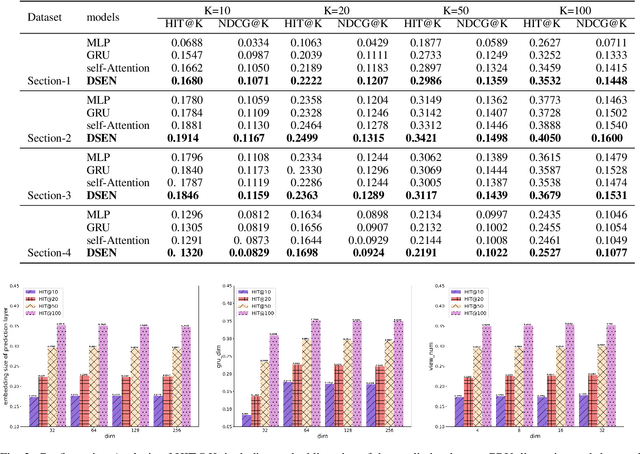
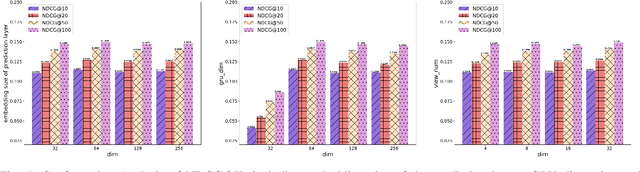
Online social as an extension of traditional life plays an important role in our daily lives. Users often seek out new friends that have significant similarities such as interests and habits, motivating us to exploit such online information to suggest friends to users. In this work, we focus on friend suggestion in online game platforms because in-game social quality significantly correlates with player engagement, determining game experience. Unlike a typical recommendation system that depends on item-user interactions, in our setting, user-user interactions do not depend on each other. Meanwhile, user preferences change rapidly due to fast changing game environment. There has been little work on designing friend suggestion when facing these difficulties, and for the first time we aim to tackle this in large scale online games. Motivated by the fast changing online game environment, we formulate this problem as friend ranking by modeling the evolution of similarity among users, exploiting the long-term and short-term feature of users in games. Our experiments on large-scale game datasets with several million users demonstrate that our proposed model achieves superior performance over other competing baselines.
Reconstructing Kernel-based Machine Learning Force Fields with Super-linear Convergence
Dec 24, 2022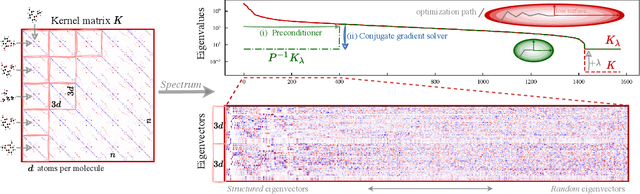
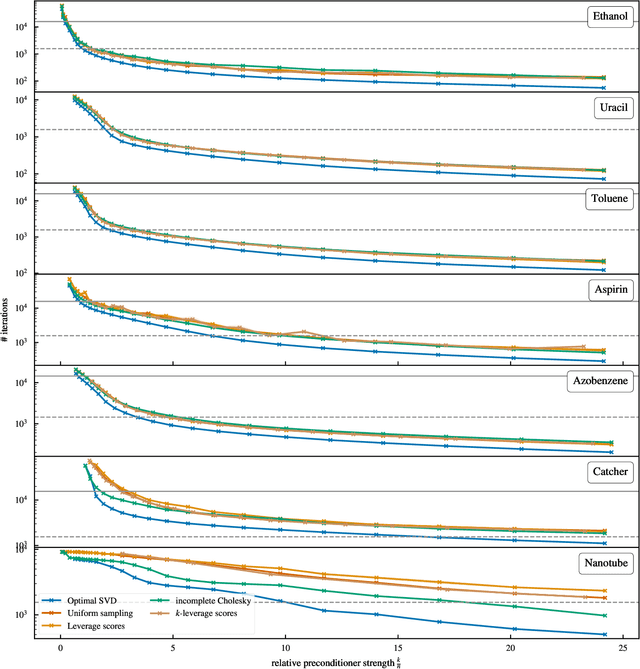
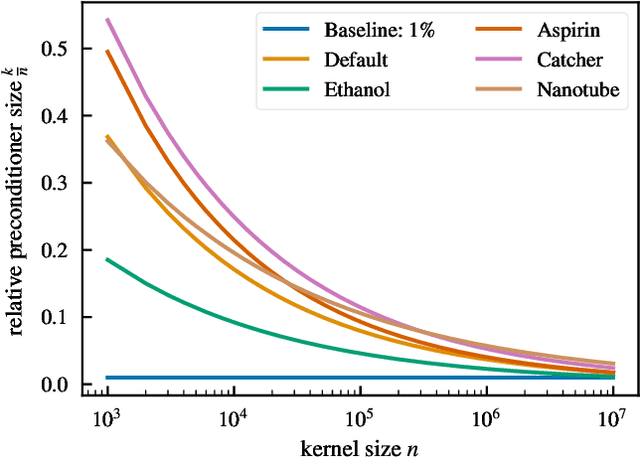
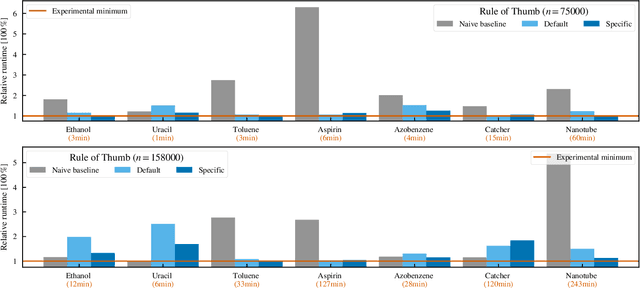
Kernel machines have sustained continuous progress in the field of quantum chemistry. In particular, they have proven to be successful in the low-data regime of force field reconstruction. This is because many physical invariances and symmetries can be incorporated into the kernel function to compensate for much larger datasets. So far, the scalability of this approach has however been hindered by its cubical runtime in the number of training points. While it is known, that iterative Krylov subspace solvers can overcome these burdens, they crucially rely on effective preconditioners, which are elusive in practice. Practical preconditioners need to be computationally efficient and numerically robust at the same time. Here, we consider the broad class of Nystr\"om-type methods to construct preconditioners based on successively more sophisticated low-rank approximations of the original kernel matrix, each of which provides a different set of computational trade-offs. All considered methods estimate the relevant subspace spanned by the kernel matrix columns using different strategies to identify a representative set of inducing points. Our comprehensive study covers the full spectrum of approaches, starting from naive random sampling to leverage score estimates and incomplete Cholesky factorizations, up to exact SVD decompositions.
Kidney and Kidney Tumour Segmentation in CT Images
Dec 26, 2022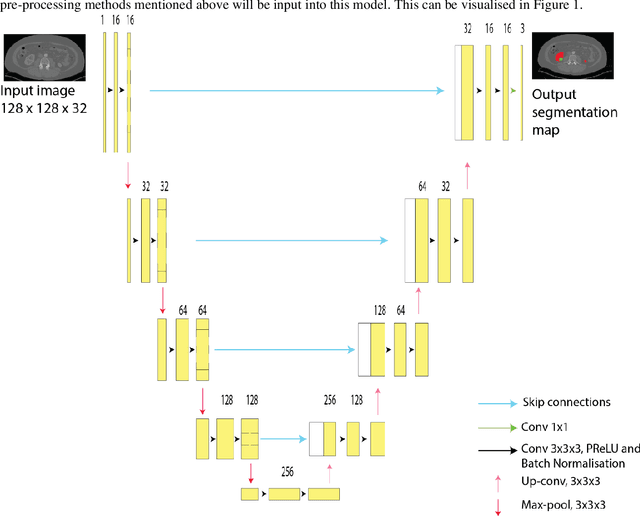
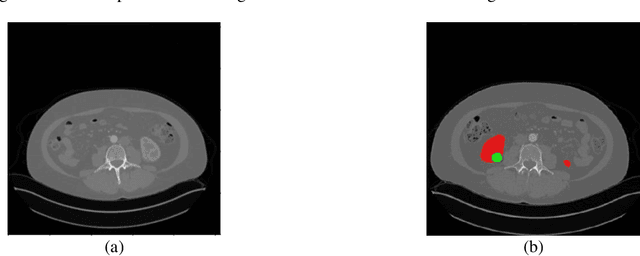

Automatic segmentation of kidney and kidney tumour in Computed Tomography (CT) images is essential, as it uses less time as compared to the current gold standard of manual segmentation. However, many hospitals are still reliant on manual study and segmentation of CT images by medical practitioners because of its higher accuracy. Thus, this study focuses on the development of an approach for automatic kidney and kidney tumour segmentation in contrast-enhanced CT images. A method based on Convolutional Neural Network (CNN) was proposed, where a 3D U-Net segmentation model was developed and trained to delineate the kidney and kidney tumour from CT scans. Each CT image was pre-processed before inputting to the CNN, and the effect of down-sampled and patch-wise input images on the model performance was analysed. The proposed method was evaluated on the publicly available 2021 Kidney and Kidney Tumour Segmentation Challenge (KiTS21) dataset. The method with the best performing model recorded an average training Dice score of 0.6129, with the kidney and kidney tumour Dice scores of 0.7923 and 0.4344, respectively. For testing, the model obtained a kidney Dice score of 0.8034, and a kidney tumour Dice score of 0.4713, with an average Dice score of 0.6374.