 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Reconciling Usability and Usefulness of Explainable AI Methodologies
Jan 13, 2023
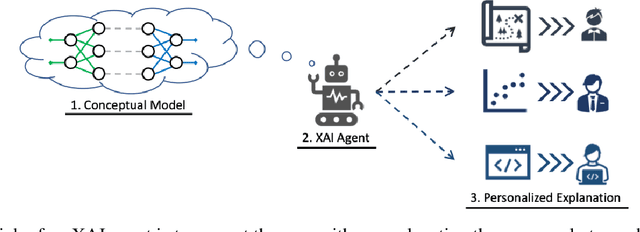
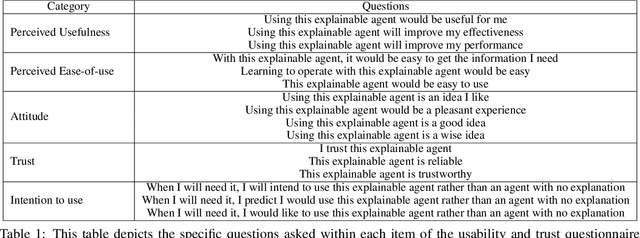

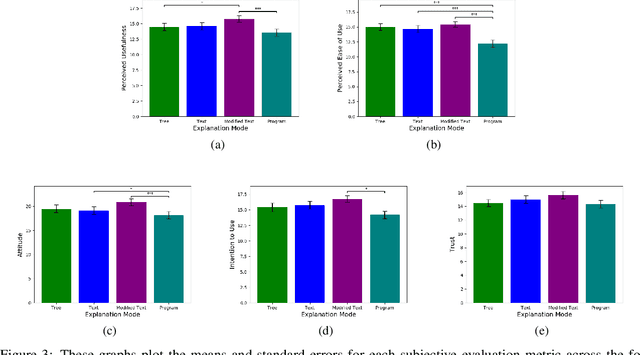
Interactive Artificial Intelligence (AI) agents are becoming increasingly prevalent in society. However, application of such systems without understanding them can be problematic. Black-box AI systems can lead to liability and accountability issues when they produce an incorrect decision. Explainable AI (XAI) seeks to bridge the knowledge gap, between developers and end-users, by offering insights into how an AI algorithm functions. Many modern algorithms focus on making the AI model "transparent", i.e. unveil the inherent functionality of the agent in a simpler format. However, these approaches do not cater to end-users of these systems, as users may not possess the requisite knowledge to understand these explanations in a reasonable amount of time. Therefore, to be able to develop suitable XAI methods, we need to understand the factors which influence subjective perception and objective usability. In this paper, we present a novel user-study which studies four differing XAI modalities commonly employed in prior work for explaining AI behavior, i.e. Decision Trees, Text, Programs. We study these XAI modalities in the context of explaining the actions of a self-driving car on a highway, as driving is an easily understandable real-world task and self-driving cars is a keen area of interest within the AI community. Our findings highlight internal consistency issues wherein participants perceived language explanations to be significantly more usable, however participants were better able to objectively understand the decision making process of the car through a decision tree explanation. Our work also provides further evidence of importance of integrating user-specific and situational criteria into the design of XAI systems. Our findings show that factors such as computer science experience, and watching the car succeed or fail can impact the perception and usefulness of the explanation.
Deep learning-based approaches for human motion decoding in smart walkers for rehabilitation
Jan 13, 2023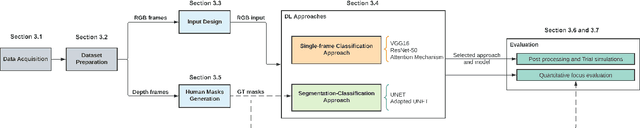

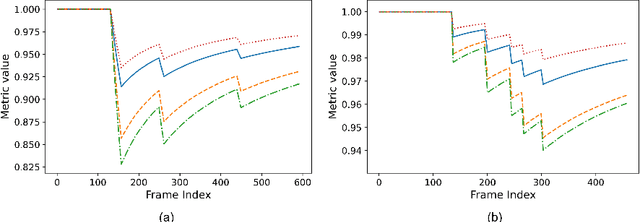
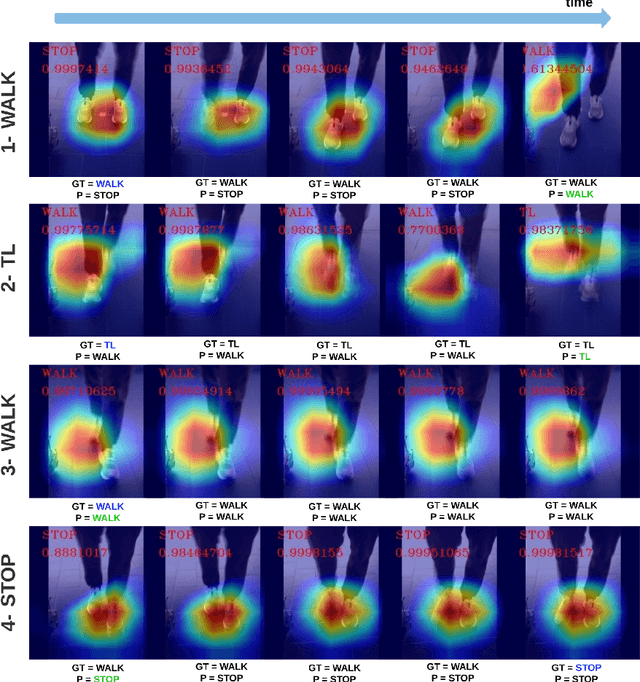
Gait disabilities are among the most frequent worldwide. Their treatment relies on rehabilitation therapies, in which smart walkers are being introduced to empower the user's recovery and autonomy, while reducing the clinicians effort. For that, these should be able to decode human motion and needs, as early as possible. Current walkers decode motion intention using information of wearable or embedded sensors, namely inertial units, force and hall sensors, and lasers, whose main limitations imply an expensive solution or hinder the perception of human movement. Smart walkers commonly lack a seamless human-robot interaction, which intuitively understands human motions. A contactless approach is proposed in this work, addressing human motion decoding as an early action recognition/detection problematic, using RGB-D cameras. We studied different deep learning-based algorithms, organised in three different approaches, to process lower body RGB-D video sequences, recorded from an embedded camera of a smart walker, and classify them into 4 classes (stop, walk, turn right/left). A custom dataset involving 15 healthy participants walking with the device was acquired and prepared, resulting in 28800 balanced RGB-D frames, to train and evaluate the deep networks. The best results were attained by a convolutional neural network with a channel attention mechanism, reaching accuracy values of 99.61% and above 93%, for offline early detection/recognition and trial simulations, respectively. Following the hypothesis that human lower body features encode prominent information, fostering a more robust prediction towards real-time applications, the algorithm focus was also evaluated using Dice metric, leading to values slightly higher than 30%. Promising results were attained for early action detection as a human motion decoding strategy, with enhancements in the focus of the proposed architectures.
Towards fully automated deep-learning-based brain tumor segmentation: is brain extraction still necessary?
Dec 14, 2022
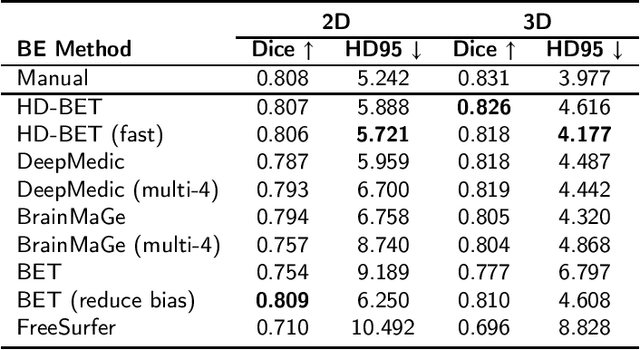
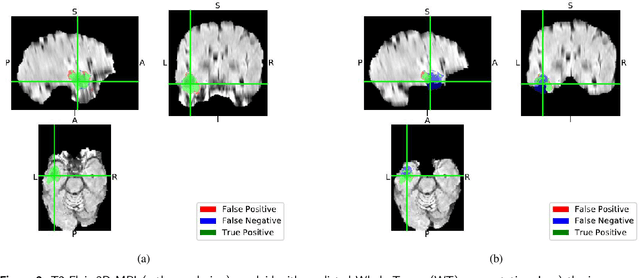
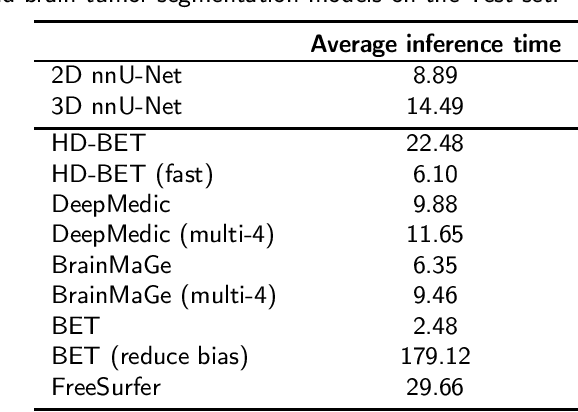
State-of-the-art brain tumor segmentation is based on deep learning models applied to multi-modal MRIs. Currently, these models are trained on images after a preprocessing stage that involves registration, interpolation, brain extraction (BE, also known as skull-stripping) and manual correction by an expert. However, for clinical practice, this last step is tedious and time-consuming and, therefore, not always feasible, resulting in skull-stripping faults that can negatively impact the tumor segmentation quality. Still, the extent of this impact has never been measured for any of the many different BE methods available. In this work, we propose an automatic brain tumor segmentation pipeline and evaluate its performance with multiple BE methods. Our experiments show that the choice of a BE method can compromise up to 15.7% of the tumor segmentation performance. Moreover, we propose training and testing tumor segmentation models on non-skull-stripped images, effectively discarding the BE step from the pipeline. Our results show that this approach leads to a competitive performance at a fraction of the time. We conclude that, in contrast to the current paradigm, training tumor segmentation models on non-skull-stripped images can be the best option when high performance in clinical practice is desired.
Revisiting Realistic Test-Time Training: Sequential Inference and Adaptation by Anchored Clustering
Jun 06, 2022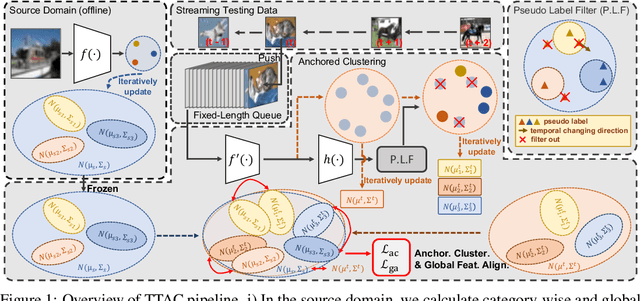
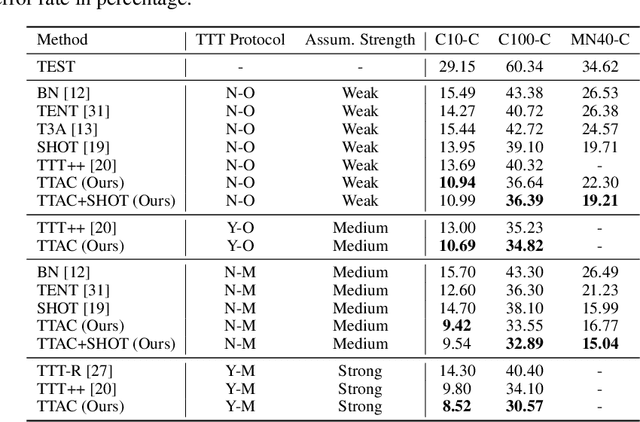
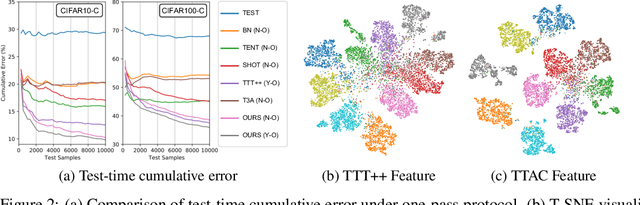
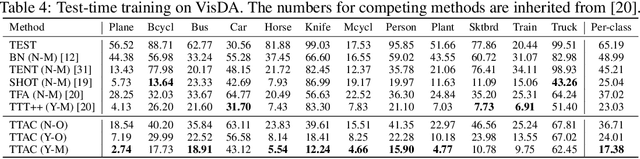
Deploying models on target domain data subject to distribution shift requires adaptation. Test-time training (TTT) emerges as a solution to this adaptation under a realistic scenario where access to full source domain data is not available and instant inference on target domain is required. Despite many efforts into TTT, there is a confusion over the experimental settings, thus leading to unfair comparisons. In this work, we first revisit TTT assumptions and categorize TTT protocols by two key factors. Among the multiple protocols, we adopt a realistic sequential test-time training (sTTT) protocol, under which we further develop a test-time anchored clustering (TTAC) approach to enable stronger test-time feature learning. TTAC discovers clusters in both source and target domain and match the target clusters to the source ones to improve generalization. Pseudo label filtering and iterative updating are developed to improve the effectiveness and efficiency of anchored clustering. We demonstrate that under all TTT protocols TTAC consistently outperforms the state-of-the-art methods on five TTT datasets. We hope this work will provide a fair benchmarking of TTT methods and future research should be compared within respective protocols. A demo code is available at https://github.com/Gorilla-Lab-SCUT/TTAC.
Sound Localization by Self-Supervised Time Delay Estimation
Apr 26, 2022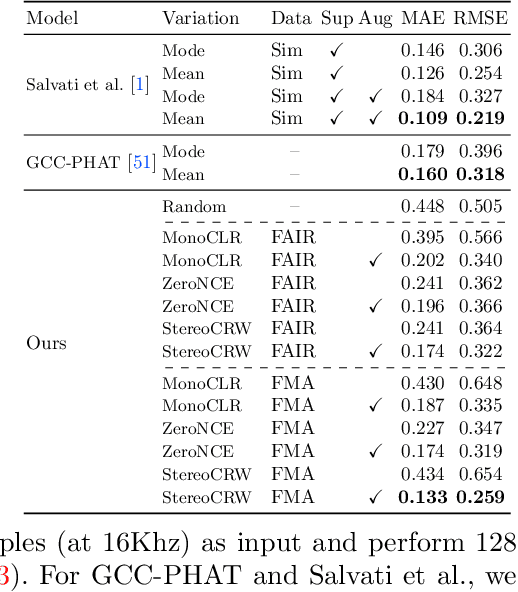
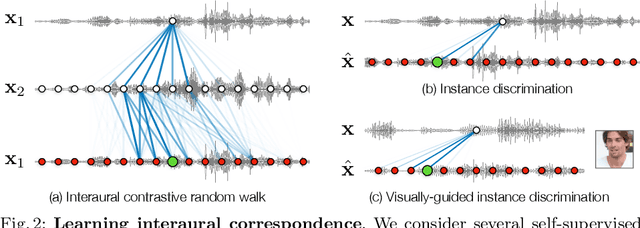
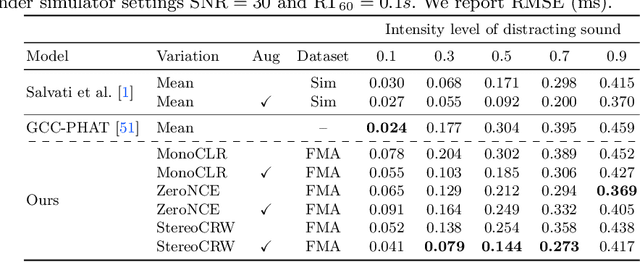

Sounds reach one microphone in a stereo pair sooner than the other, resulting in an interaural time delay that conveys their directions. Estimating a sound's time delay requires finding correspondences between the signals recorded by each microphone. We propose to learn these correspondences through self-supervision, drawing on recent techniques from visual tracking. We adapt the contrastive random walk of Jabri et al. to learn a cycle-consistent representation from unlabeled stereo sounds, resulting in a model that performs on par with supervised methods on "in the wild" internet recordings. We also propose a multimodal contrastive learning model that solves a visually-guided localization task: estimating the time delay for a particular person in a multi-speaker mixture, given a visual representation of their face. Project site: https://ificl.github.io/stereocrw/
Assessing Lower Limb Strength using Internet-of-Things Enabled Chair and Processing of Time-Series Data in Google GPU Tensorflow CoLab
Sep 08, 2022

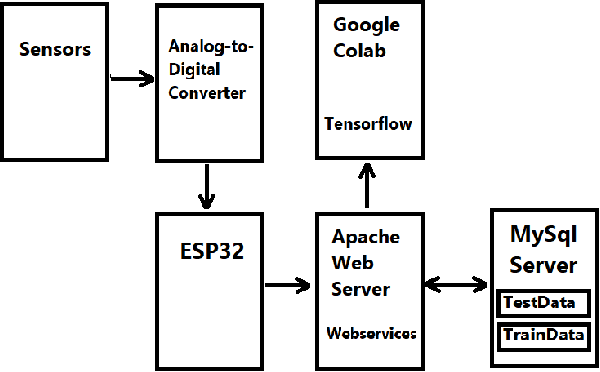

This project describes the application of the technologies of Machine Learning and Internet-of-Things to assess the lower limb strength of individuals undergoing rehabilitation or therapy. Specifically, it seeks to measure and assess the progress of individuals by sensors attached to chairs and processing the data through Google GPU Tensorflow CoLab. Pressure sensors are attached to various locations on a chair, including but not limited to the seating area, backrest, hand rests, and legs. Sensor data from the individual performing both sit-to-stand transition and stand-to-sit transition provides a time series dataset regarding the pressure distribution and vibratory motion on the chair. The dataset and timing information can then be fed into a machine learning model to estimate the relative strength and weakness during various phases of the movement.
A deep learning approach to using wearable seismocardiography (SCG) for diagnosing aortic valve stenosis and predicting aortic hemodynamics obtained by 4D flow MRI
Jan 05, 2023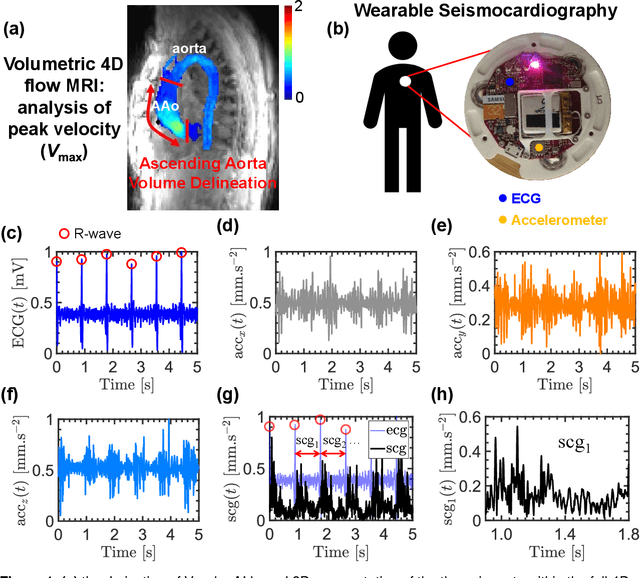
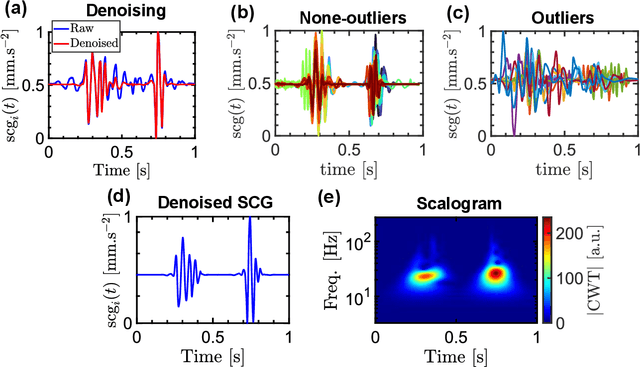
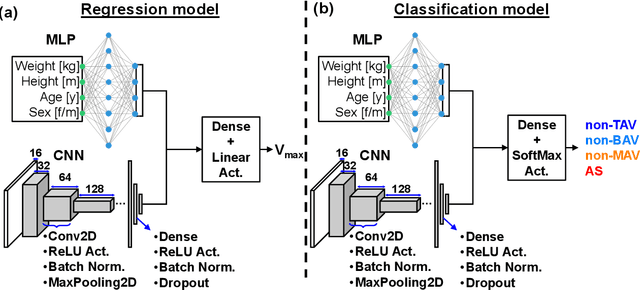
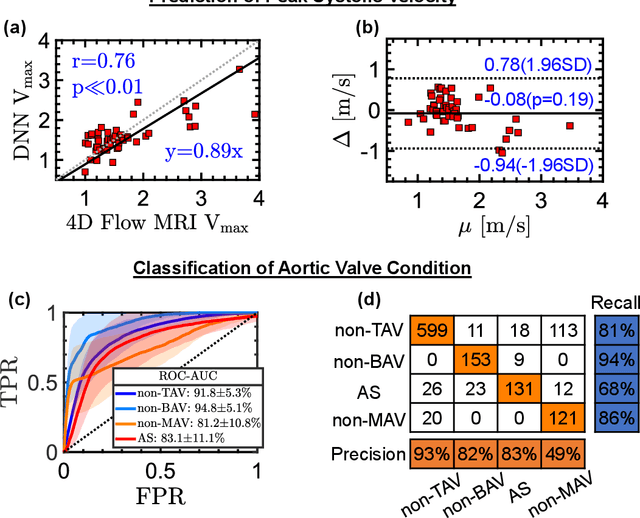
In this paper, we explored the use of deep learning for the prediction of aortic flow metrics obtained using 4D flow MRI using wearable seismocardiography (SCG) devices. 4D flow MRI provides a comprehensive assessment of cardiovascular hemodynamics, but it is costly and time-consuming. We hypothesized that deep learning could be used to identify pathological changes in blood flow, such as elevated peak systolic velocity Vmax in patients with heart valve diseases, from SCG signals. We also investigated the ability of this deep learning technique to differentiate between patients diagnosed with aortic valve stenosis (AS), non-AS patients with a bicuspid aortic valve (BAV), non-AS patients with a mechanical aortic valve (MAV), and healthy subjects with a normal tricuspid aortic valve (TAV). In a study of 77 subjects who underwent same-day 4D flow MRI and SCG, we found that the Vmax values obtained using deep learning and SCGs were in good agreement with those obtained by 4D flow MRI. Additionally, subjects with TAV, BAV, MAV, and AS could be classified with ROC-AUC values of 92%, 95%, 81%, and 83%, respectively. This suggests that SCG obtained using low-cost wearable electronics may be used as a supplement to 4D flow MRI exams or as a screening tool for aortic valve disease.
DADAO: Decoupled Accelerated Decentralized Asynchronous Optimization for Time-Varying Gossips
Jul 26, 2022
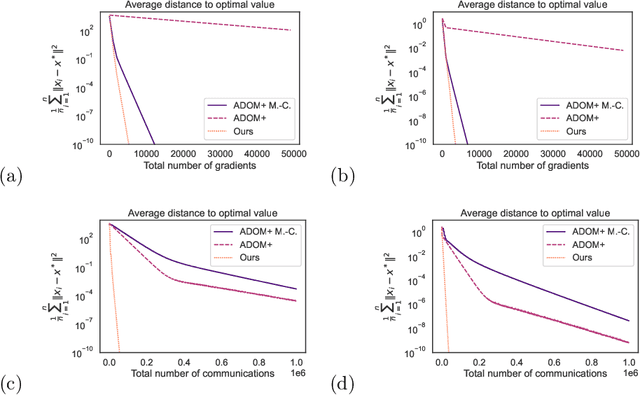

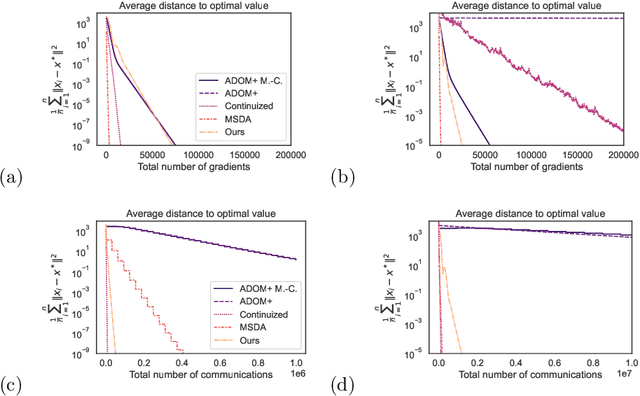
DADAO is a novel decentralized asynchronous stochastic algorithm to minimize a sum of $L$-smooth and $\mu$-strongly convex functions distributed over a time-varying connectivity network of size $n$. We model the local gradient updates and gossip communication procedures with separate independent Poisson Point Processes, decoupling the computation and communication steps in addition to making the whole approach completely asynchronous. Our method employs primal gradients and do not use a multi-consensus inner loop nor other ad-hoc mechanisms as Error Feedback, Gradient Tracking or a Proximal operator. By relating spatial quantities of our graphs $\chi^*_1,\chi_2^*$ to a necessary minimal communication rate between nodes of the network, we show that our algorithm requires $\mathcal{O}(n\sqrt{\frac{L}{\mu}}\log \epsilon)$ local gradients and only $\mathcal{O}(n\sqrt{\chi_1^*\chi_2^*}\sqrt{\frac{L}{\mu}}\log \epsilon)$ communications to reach a precision $\epsilon$. If SGD with uniform noise $\sigma^2$ is used, we reach a precision $\epsilon$ with same speed, up to a bias term in $\mathcal{O}(\frac{\sigma^2}{\sqrt{\mu L}})$. This improves upon the bounds obtained with current state-of-the-art approaches, our simulations validating the strength of our relatively unconstrained method. Our source-code is released on a public repository.
Multi-Variate Time Series Forecasting on Variable Subsets
Jun 25, 2022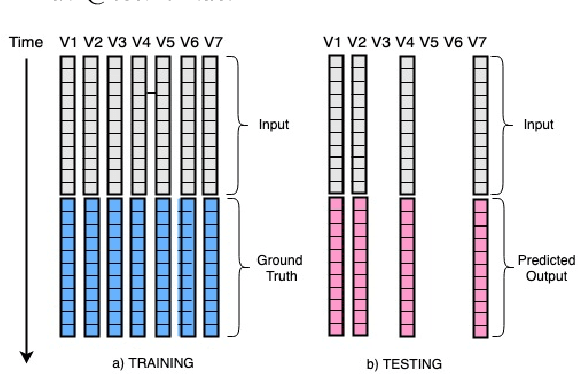
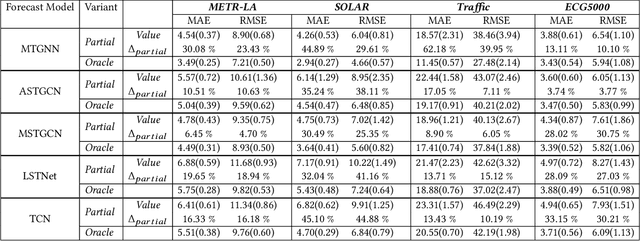
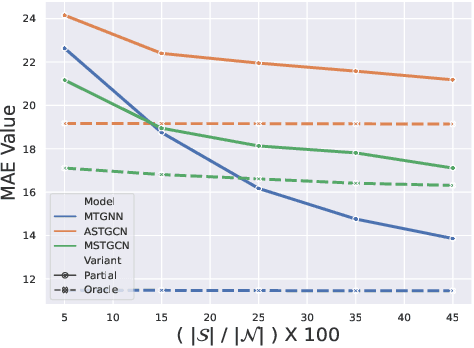

We formulate a new inference task in the domain of multivariate time series forecasting (MTSF), called Variable Subset Forecast (VSF), where only a small subset of the variables is available during inference. Variables are absent during inference because of long-term data loss (eg. sensor failures) or high -> low-resource domain shift between train / test. To the best of our knowledge, robustness of MTSF models in presence of such failures, has not been studied in the literature. Through extensive evaluation, we first show that the performance of state of the art methods degrade significantly in the VSF setting. We propose a non-parametric, wrapper technique that can be applied on top any existing forecast models. Through systematic experiments across 4 datasets and 5 forecast models, we show that our technique is able to recover close to 95\% performance of the models even when only 15\% of the original variables are present.
Look, Listen, and Attack: Backdoor Attacks Against Video Action Recognition
Jan 03, 2023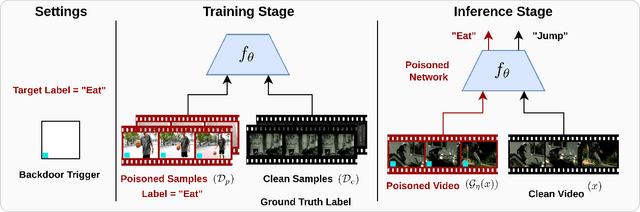
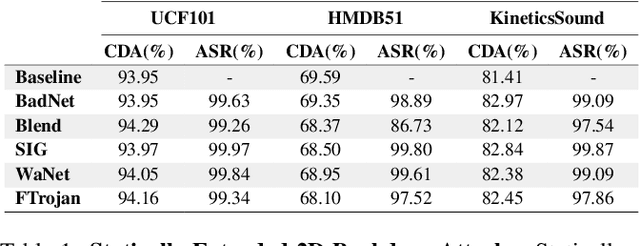

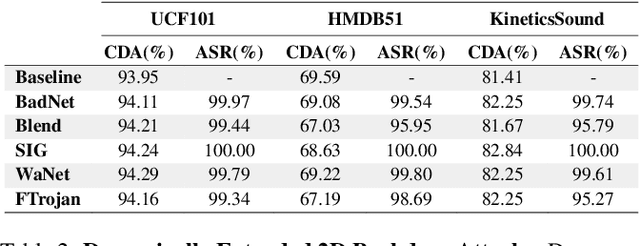
Deep neural networks (DNNs) are vulnerable to a class of attacks called "backdoor attacks", which create an association between a backdoor trigger and a target label the attacker is interested in exploiting. A backdoored DNN performs well on clean test images, yet persistently predicts an attacker-defined label for any sample in the presence of the backdoor trigger. Although backdoor attacks have been extensively studied in the image domain, there are very few works that explore such attacks in the video domain, and they tend to conclude that image backdoor attacks are less effective in the video domain. In this work, we revisit the traditional backdoor threat model and incorporate additional video-related aspects to that model. We show that poisoned-label image backdoor attacks could be extended temporally in two ways, statically and dynamically, leading to highly effective attacks in the video domain. In addition, we explore natural video backdoors to highlight the seriousness of this vulnerability in the video domain. And, for the first time, we study multi-modal (audiovisual) backdoor attacks against video action recognition models, where we show that attacking a single modality is enough for achieving a high attack success rate.