 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BlazePose GHUM Holistic: Real-time 3D Human Landmarks and Pose Estimation
Jun 23, 2022
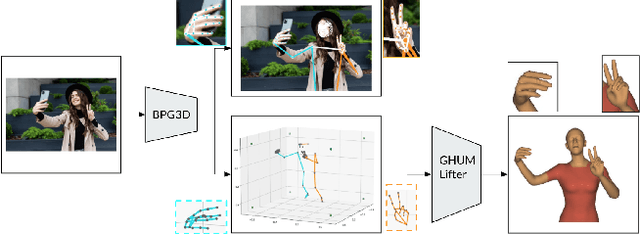
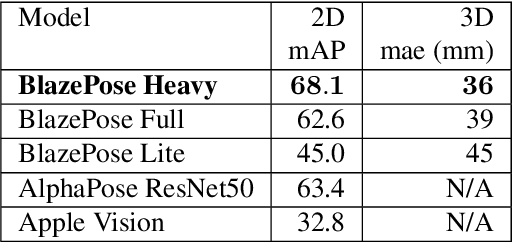
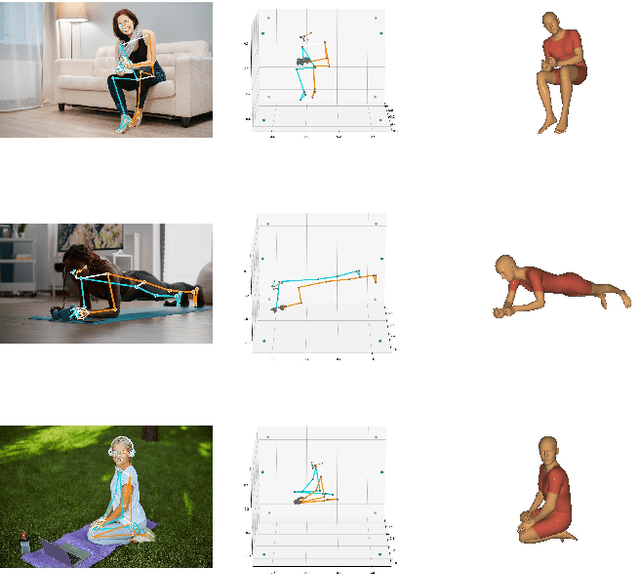
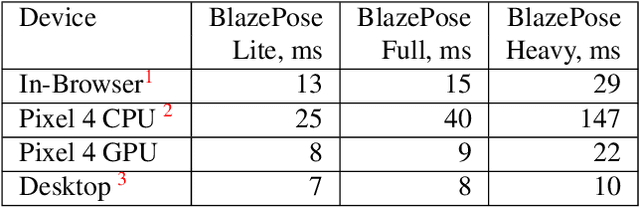
We present BlazePose GHUM Holistic, a lightweight neural network pipeline for 3D human body landmarks and pose estimation, specifically tailored to real-time on-device inference. BlazePose GHUM Holistic enables motion capture from a single RGB image including avatar control, fitness tracking and AR/VR effects. Our main contributions include i) a novel method for 3D ground truth data acquisition, ii) updated 3D body tracking with additional hand landmarks and iii) full body pose estimation from a monocular image.
NeuroView-RNN: It's About Time
Feb 23, 2022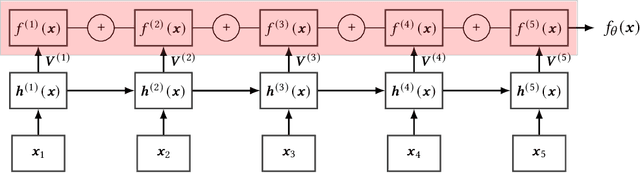
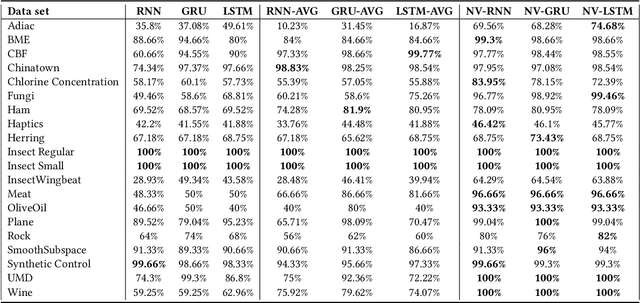


Recurrent Neural Networks (RNNs) are important tools for processing sequential data such as time-series or video. Interpretability is defined as the ability to be understood by a person and is different from explainability, which is the ability to be explained in a mathematical formulation. A key interpretability issue with RNNs is that it is not clear how each hidden state per time step contributes to the decision-making process in a quantitative manner. We propose NeuroView-RNN as a family of new RNN architectures that explains how all the time steps are used for the decision-making process. Each member of the family is derived from a standard RNN architecture by concatenation of the hidden steps into a global linear classifier. The global linear classifier has all the hidden states as the input, so the weights of the classifier have a linear mapping to the hidden states. Hence, from the weights, NeuroView-RNN can quantify how important each time step is to a particular decision. As a bonus, NeuroView-RNN also offers higher accuracy in many cases compared to the RNNs and their variants. We showcase the benefits of NeuroView-RNN by evaluating on a multitude of diverse time-series datasets.
A walk through of time series analysis on quantum computers
May 02, 2022
Because of the rotational components on quantum circuits, some quantum neural networks based on variational circuits can be considered equivalent to the classical Fourier networks. In addition, they can be used to predict Fourier coefficients of continuous functions. Time series data indicates a state of a variable in time. Since some time series data can be also considered as continuous functions, we can expect quantum machine learning models to do do many data analysis tasks successfully on time series data. Therefore, it is important to investigate new quantum logics for temporal data processing and analyze intrinsic relationships of data on quantum computers. In this paper, we go through the quantum analogues of classical data preprocessing and forecasting with ARIMA models by using simple quantum operators requiring a few number of quantum gates. Then we discuss future directions and some of the tools/algorithms that can be used for temporal data analysis on quantum computers.
Bayesian Semiparametric Model for Sequential Treatment Decisions with Informative Timing
Nov 29, 2022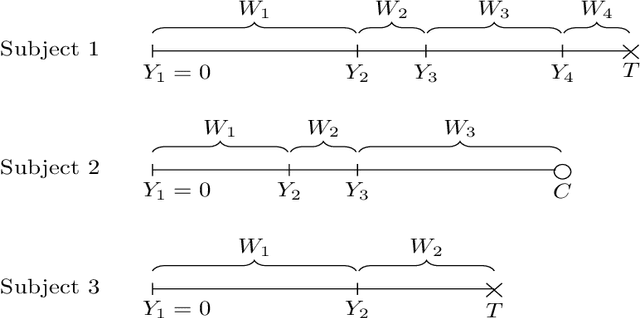
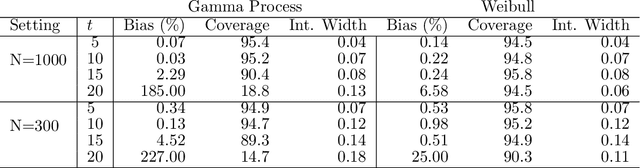
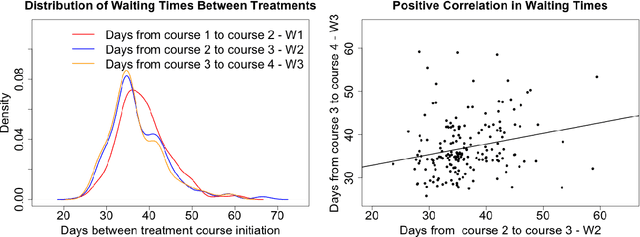
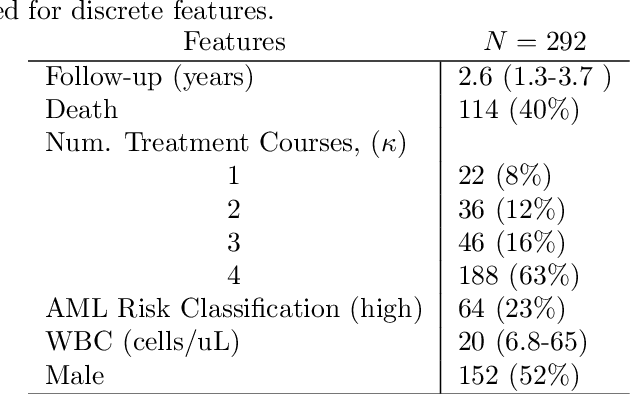
We develop a Bayesian semi-parametric model for the estimating the impact of dynamic treatment rules on survival among patients diagnosed with pediatric acute myeloid leukemia (AML). The data consist of a subset of patients enrolled in the phase III AAML1031 clinical trial in which patients move through a sequence of four treatment courses. At each course, they undergo treatment that may or may not include anthracyclines (ACT). While ACT is known to be effective at treating AML, it is also cardiotoxic and can lead to early death for some patients. Our task is to estimate the potential survival probability under hypothetical dynamic ACT treatment strategies, but there are several impediments. First, since ACT was not randomized in the trial, its effect on survival is confounded over time. Second, subjects initiate the next course depending on when they recover from the previous course, making timing potentially informative of subsequent treatment and survival. Third, patients may die or drop out before ever completing the full treatment sequence. We develop a generative Bayesian semi-parametric model based on Gamma Process priors to address these complexities. At each treatment course, the model captures subjects' transition to subsequent treatment or death in continuous time under a given rule. A g-computation procedure is used to compute a posterior over potential survival probability that is adjusted for time-varying confounding. Using this approach, we conduct posterior inference for the efficacy of hypothetical treatment rules that dynamically modify ACT based on evolving cardiac function.
Few-Shot Forecasting of Time-Series with Heterogeneous Channels
Apr 07, 2022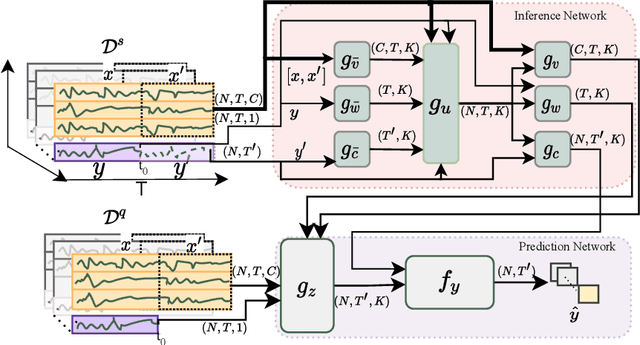
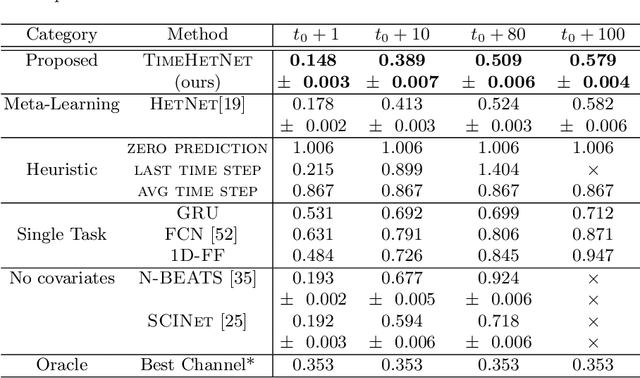
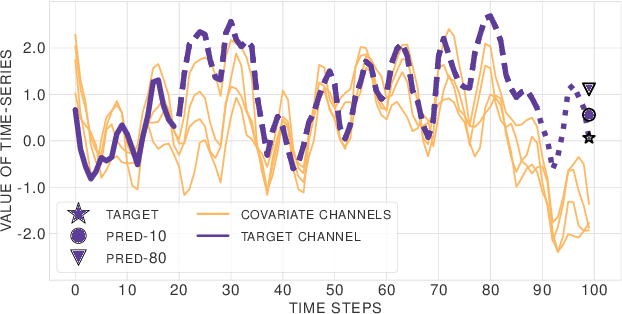

Learning complex time series forecasting models usually requires a large amount of data, as each model is trained from scratch for each task/data set. Leveraging learning experience with similar datasets is a well-established technique for classification problems called few-shot classification. However, existing approaches cannot be applied to time-series forecasting because i) multivariate time-series datasets have different channels and ii) forecasting is principally different from classification. In this paper we formalize the problem of few-shot forecasting of time-series with heterogeneous channels for the first time. Extending recent work on heterogeneous attributes in vector data, we develop a model composed of permutation-invariant deep set-blocks which incorporate a temporal embedding. We assemble the first meta-dataset of 40 multivariate time-series datasets and show through experiments that our model provides a good generalization, outperforming baselines carried over from simpler scenarios that either fail to learn across tasks or miss temporal information.
Koopman operator for time-dependent reliability analysis
Mar 14, 2022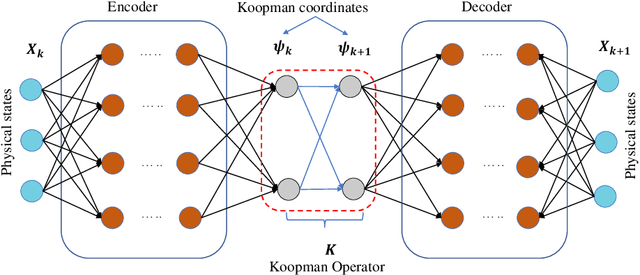

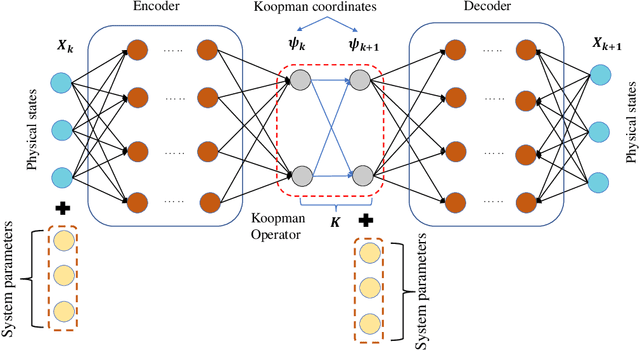

Time-dependent structural reliability analysis of nonlinear dynamical systems is non-trivial; subsequently, scope of most of the structural reliability analysis methods is limited to time-independent reliability analysis only. In this work, we propose a Koopman operator based approach for time-dependent reliability analysis of nonlinear dynamical systems. Since the Koopman representations can transform any nonlinear dynamical system into a linear dynamical system, the time evolution of dynamical systems can be obtained by Koopman operators seamlessly regardless of the nonlinear or chaotic behavior. Despite the fact that the Koopman theory has been in vogue a long time back, identifying intrinsic coordinates is a challenging task; to address this, we propose an end-to-end deep learning architecture that learns the Koopman observables and then use it for time marching the dynamical response. Unlike purely data-driven approaches, the proposed approach is robust even in the presence of uncertainties; this renders the proposed approach suitable for time-dependent reliability analysis. We propose two architectures; one suitable for time-dependent reliability analysis when the system is subjected to random initial condition and the other suitable when the underlying system have uncertainties in system parameters. The proposed approach is robust and generalizes to unseen environment (out-of-distribution prediction). Efficacy of the proposed approached is illustrated using three numerical examples. Results obtained indicate supremacy of the proposed approach as compared to purely data-driven auto-regressive neural network and long-short term memory network.
Inflected Forms Are Redundant in Question Generation Models
Jan 01, 2023

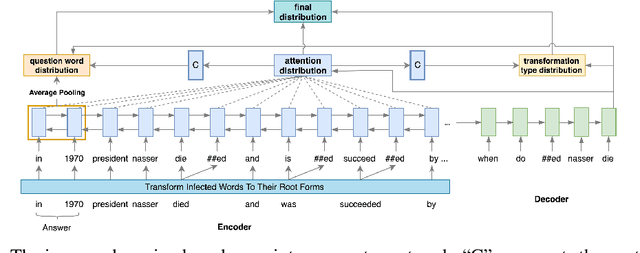
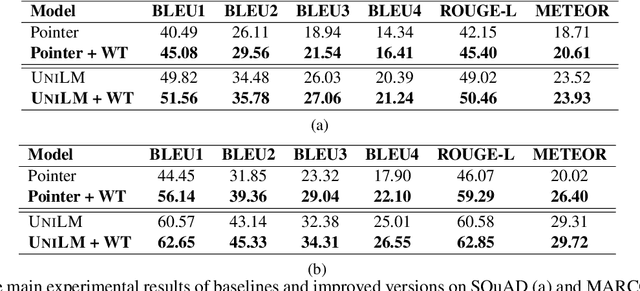
Neural models with an encoder-decoder framework provide a feasible solution to Question Generation (QG). However, after analyzing the model vocabulary we find that current models (both RNN-based and pre-training based) have more than 23\% inflected forms. As a result, the encoder will generate separate embeddings for the inflected forms, leading to a waste of training data and parameters. Even worse, in decoding these models are vulnerable to irrelevant noise and they suffer from high computational costs. In this paper, we propose an approach to enhance the performance of QG by fusing word transformation. Firstly, we identify the inflected forms of words from the input of encoder, and replace them with the root words, letting the encoder pay more attention to the repetitive root words. Secondly, we propose to adapt QG as a combination of the following actions in the encode-decoder framework: generating a question word, copying a word from the source sequence or generating a word transformation type. Such extension can greatly decrease the size of predicted words in the decoder as well as noise. We apply our approach to a typical RNN-based model and \textsc{UniLM} to get the improved versions. We conduct extensive experiments on SQuAD and MS MARCO datasets. The experimental results show that the improved versions can significantly outperform the corresponding baselines in terms of BLEU, ROUGE-L and METEOR as well as time cost.
MTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jan 01, 2023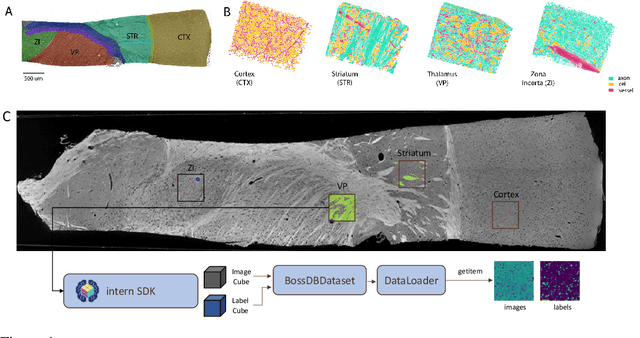
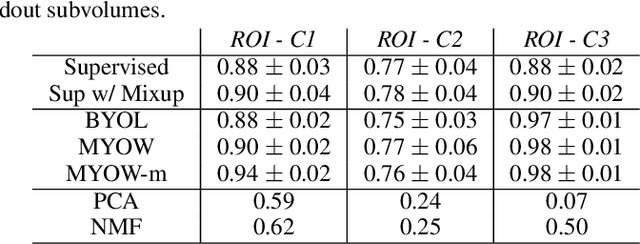

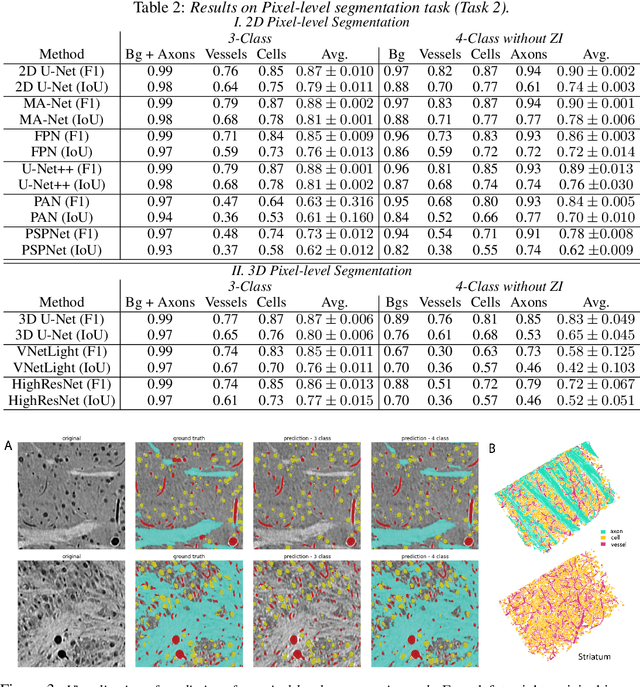
There are multiple scales of abstraction from which we can describe the same image, depending on whether we are focusing on fine-grained details or a more global attribute of the image. In brain mapping, learning to automatically parse images to build representations of both small-scale features (e.g., the presence of cells or blood vessels) and global properties of an image (e.g., which brain region the image comes from) is a crucial and open challenge. However, most existing datasets and benchmarks for neuroanatomy consider only a single downstream task at a time. To bridge this gap, we introduce a new dataset, annotations, and multiple downstream tasks that provide diverse ways to readout information about brain structure and architecture from the same image. Our multi-task neuroimaging benchmark (MTNeuro) is built on volumetric, micrometer-resolution X-ray microtomography images spanning a large thalamocortical section of mouse brain, encompassing multiple cortical and subcortical regions. We generated a number of different prediction challenges and evaluated several supervised and self-supervised models for brain-region prediction and pixel-level semantic segmentation of microstructures. Our experiments not only highlight the rich heterogeneity of this dataset, but also provide insights into how self-supervised approaches can be used to learn representations that capture multiple attributes of a single image and perform well on a variety of downstream tasks. Datasets, code, and pre-trained baseline models are provided at: https://mtneuro.github.io/ .
DeepJoin: Joinable Table Discovery with Pre-trained Language Models
Dec 15, 2022

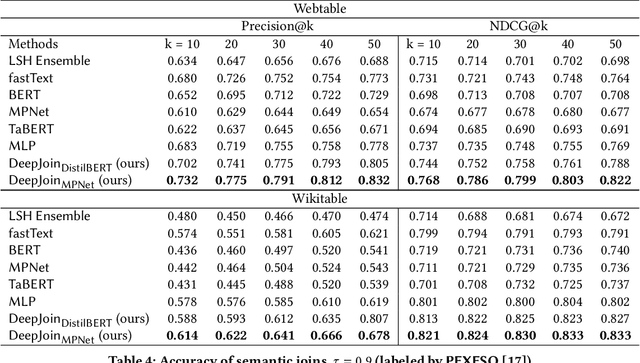
Due to the usefulness in data enrichment for data analysis tasks, joinable table discovery has become an important operation in data lake management. Existing approaches target equi-joins, the most common way of combining tables for creating a unified view, or semantic joins, which tolerate misspellings and different formats to deliver more join results. They are either exact solutions whose running time is linear in the sizes of query column and target table repository or approximate solutions lacking precision. In this paper, we propose Deepjoin, a deep learning model for accurate and efficient joinable table discovery. Our solution is an embedding-based retrieval, which employs a pre-trained language model (PLM) and is designed as one framework serving both equi- and semantic joins. We propose a set of contextualization options to transform column contents to a text sequence. The PLM reads the sequence and is fine-tuned to embed columns to vectors such that columns are expected to be joinable if they are close to each other in the vector space. Since the output of the PLM is fixed in length, the subsequent search procedure becomes independent of the column size. With a state-of-the-art approximate nearest neighbor search algorithm, the search time is logarithmic in the repository size. To train the model, we devise the techniques for preparing training data as well as data augmentation. The experiments on real datasets demonstrate that by training on a small subset of a corpus, Deepjoin generalizes to large datasets and its precision consistently outperforms other approximate solutions'. Deepjoin is even more accurate than an exact solution to semantic joins when evaluated with labels from experts. Moreover, when equipped with a GPU, Deepjoin is up to two orders of magnitude faster than existing solutions.
NLP Based Anomaly Detection for Categorical Time Series
Apr 22, 2022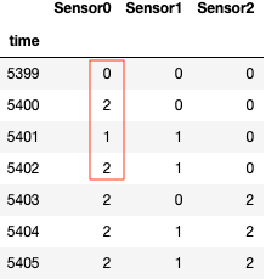
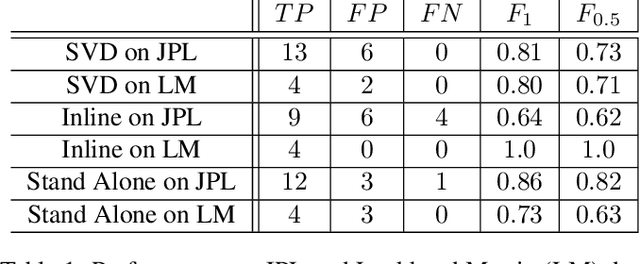

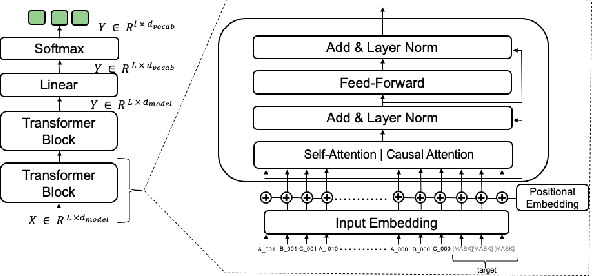
Identifying anomalies in large multi-dimensional time series is a crucial and difficult task across multiple domains. Few methods exist in the literature that address this task when some of the variables are categorical in nature. We formalize an analogy between categorical time series and classical Natural Language Processing and demonstrate the strength of this analogy for anomaly detection and root cause investigation by implementing and testing three different machine learning anomaly detection and root cause investigation models based upon it.