 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Emergent communication enhances foraging behaviour in evolved swarms controlled by Spiking Neural Networks
Dec 16, 2022

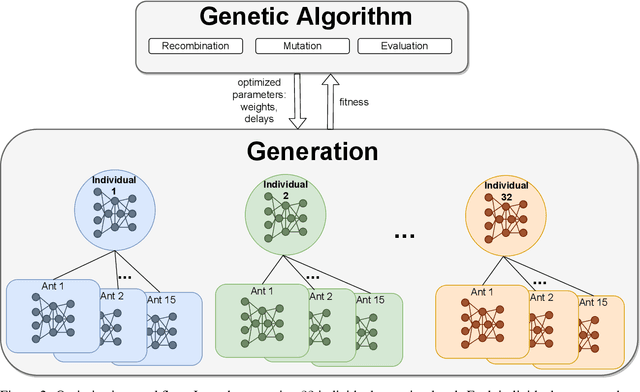
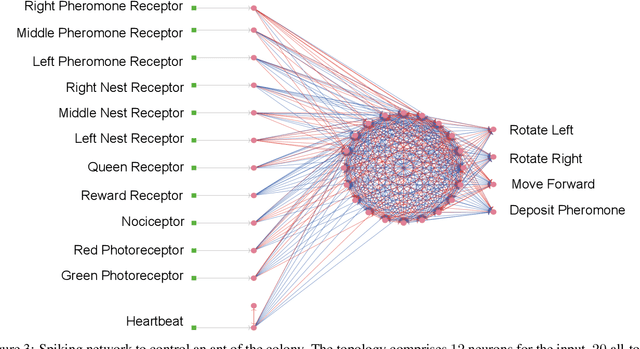
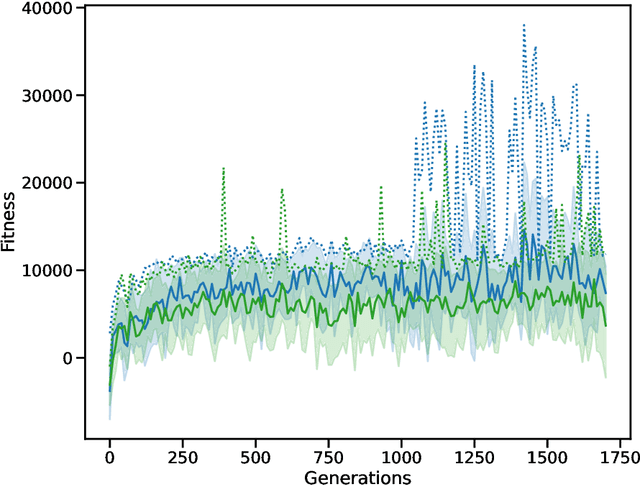
Social insects such as ants communicate via pheromones which allows them to coordinate their activity and solve complex tasks as a swarm, e.g. foraging for food. This behaviour was shaped through evolutionary processes. In computational models, self-coordination in swarms has been implemented using probabilistic or action rules to shape the decision of each agent and the collective behaviour. However, manual tuned decision rules may limit the behaviour of the swarm. In this work we investigate the emergence of self-coordination and communication in evolved swarms without defining any rule. We evolve a swarm of agents representing an ant colony. We use a genetic algorithm to optimize a spiking neural network (SNN) which serves as an artificial brain to control the behaviour of each agent. The goal of the colony is to find optimal ways to forage for food in the shortest amount of time. In the evolutionary phase, the ants are able to learn to collaborate by depositing pheromone near food piles and near the nest to guide its cohorts. The pheromone usage is not encoded into the network; instead, this behaviour is established through the optimization procedure. We observe that pheromone-based communication enables the ants to perform better in comparison to colonies where communication did not emerge. We assess the foraging performance by comparing the SNN based model to a rule based system. Our results show that the SNN based model can complete the foraging task more efficiently in a shorter time. Our approach illustrates that even in the absence of pre-defined rules, self coordination via pheromone emerges as a result of the network optimization. This work serves as a proof of concept for the possibility of creating complex applications utilizing SNNs as underlying architectures for multi-agent interactions where communication and self-coordination is desired.
Neural Enhanced Belief Propagation for Multiobject Tracking
Dec 16, 2022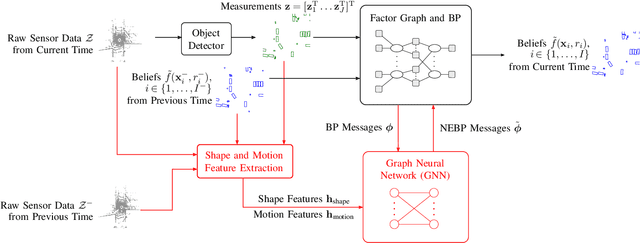
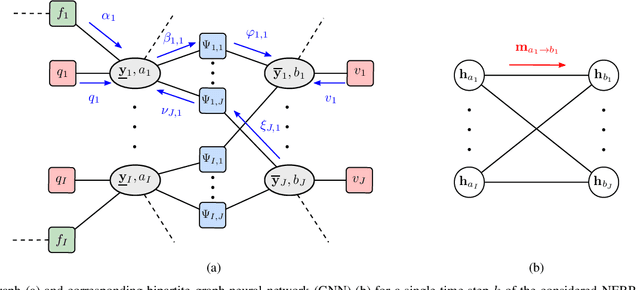
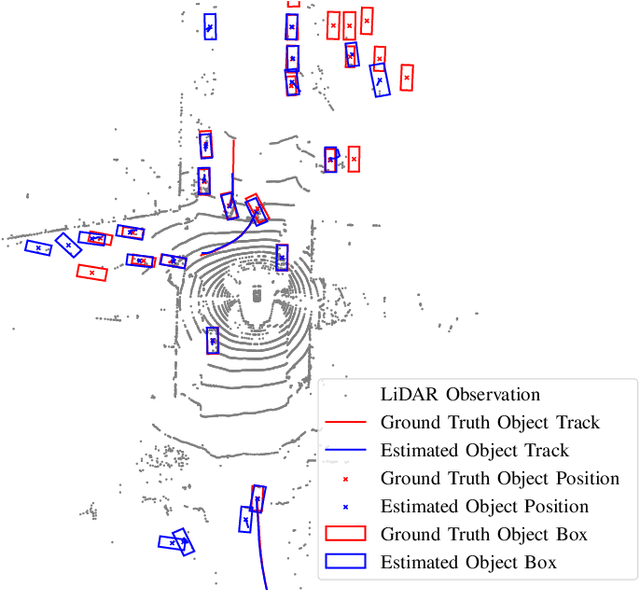

Algorithmic solutions for multi-object tracking (MOT) are a key enabler for applications in autonomous navigation and applied ocean sciences. State-of-the-art MOT methods fully rely on a statistical model and typically use preprocessed sensor data as measurements. In particular, measurements are produced by a detector that extracts potential object locations from the raw sensor data collected for a discrete time step. This preparatory processing step reduces data flow and computational complexity but may result in a loss of information. State-of-the-art Bayesian MOT methods that are based on belief propagation (BP) systematically exploit graph structures of the statistical model to reduce computational complexity and improve scalability. However, as a fully model-based approach, BP can only provide suboptimal estimates when there is a mismatch between the statistical model and the true data-generating process. Existing BP-based MOT methods can further only make use of preprocessed measurements. In this paper, we introduce a variant of BP that combines model-based with data-driven MOT. The proposed neural enhanced belief propagation (NEBP) method complements the statistical model of BP by information learned from raw sensor data. This approach conjectures that the learned information can reduce model mismatch and thus improve data association and false alarm rejection. Our NEBP method improves tracking performance compared to model-based methods. At the same time, it inherits the advantages of BP-based MOT, i.e., it scales only quadratically in the number of objects, and it can thus generate and maintain a large number of object tracks. We evaluate the performance of our NEBP approach for MOT on the nuScenes autonomous driving dataset and demonstrate that it has state-of-the-art performance.
Annotation by Clicks: A Point-Supervised Contrastive Variance Method for Medical Semantic Segmentation
Dec 23, 2022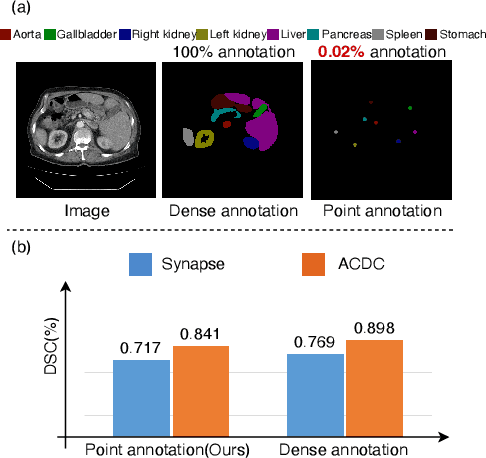

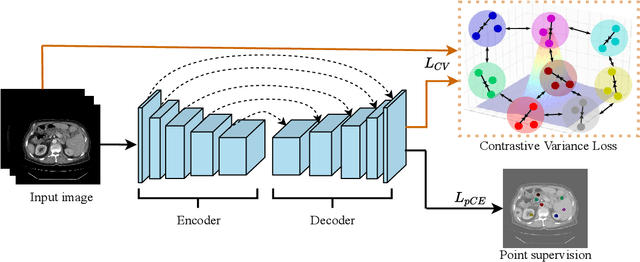
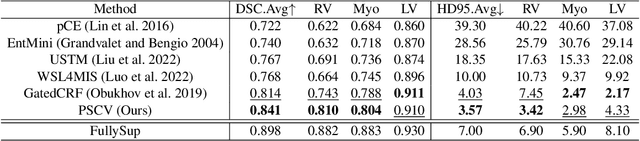
Medical image segmentation methods typically rely on numerous dense annotated images for model training, which are notoriously expensive and time-consuming to collect. To alleviate this burden, weakly supervised techniques have been exploited to train segmentation models with less expensive annotations. In this paper, we propose a novel point-supervised contrastive variance method (PSCV) for medical image semantic segmentation, which only requires one pixel-point from each organ category to be annotated. The proposed method trains the base segmentation network by using a novel contrastive variance (CV) loss to exploit the unlabeled pixels and a partial cross-entropy loss on the labeled pixels. The CV loss function is designed to exploit the statistical spatial distribution properties of organs in medical images and their variance distribution map representations to enforce discriminative predictions over the unlabeled pixels. Experimental results on two standard medical image datasets demonstrate that the proposed method outperforms the state-of-the-art weakly supervised methods on point-supervised medical image semantic segmentation tasks.
RIS-Assisted Receive Quadrature Spatial Modulation with Low-Complexity Greedy Detection
Jan 02, 2023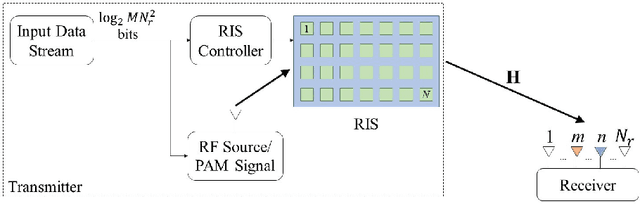
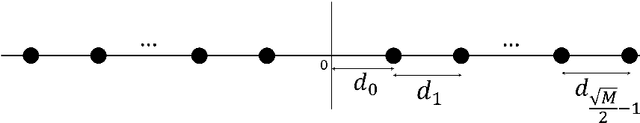
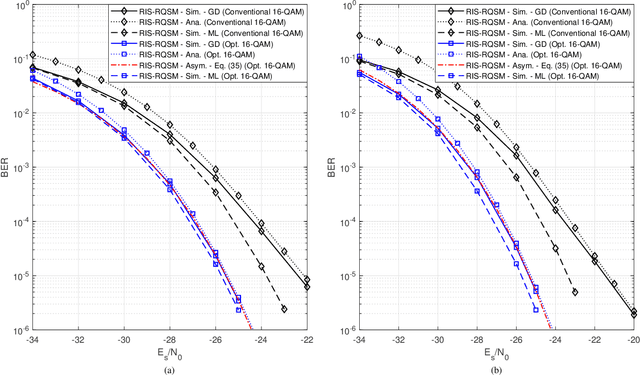
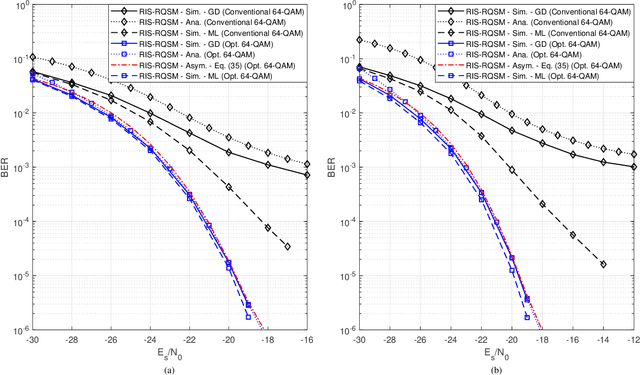
In this paper, we propose a novel reconfigurable intelligent surface (RIS)-assisted wireless communication scheme which uses the concept of spatial modulation, namely RIS-assisted receive quadrature spatial modulation (RIS-RQSM). In the proposed RIS-RQSM system, the information bits are conveyed via both the indices of the two selected receive antennas and the conventional in-phase/quadrature (IQ) modulation. We propose a novel methodology to adjust the phase shifts of the RIS elements in order to maximize the signal-to-noise ratio (SNR) and at the same time to construct two separate PAM symbols at the selected receive antennas, as the in-phase and quadrature components of the desired IQ symbol. An energy-based greedy detector (GD) is implemented at the receiver to efficiently detect the received signal with minimal channel state information (CSI) via the use of an appropriately designed one-tap pre-equalizer. We also derive a closed-form upper bound on the average bit error probability (ABEP) of the proposed RIS-RQSM system. Then, we formulate an optimization problem to minimize the ABEP in order to improve the performance of the system, which allows the GD to act as a near-optimal receiver. Extensive numerical results are provided to demonstrate the error rate performance of the system and to compare with that of a prominent benchmark scheme. The results verify the remarkable superiority of the proposed RIS-RQSM system over the benchmark scheme.
Superimposed Channel Estimation in OTFS Modulation Using Compressive Sensing
Dec 19, 2022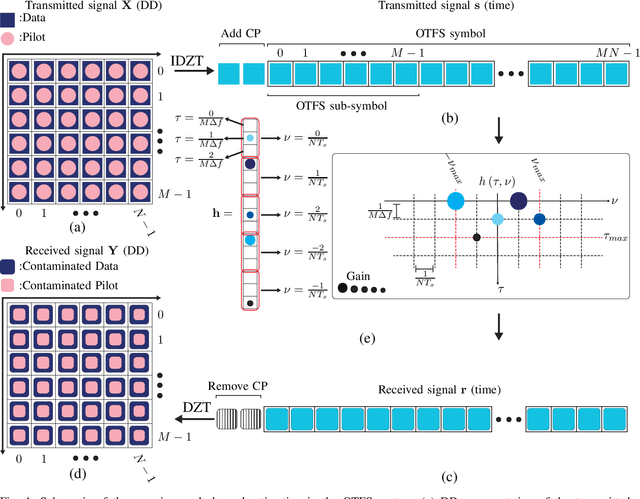
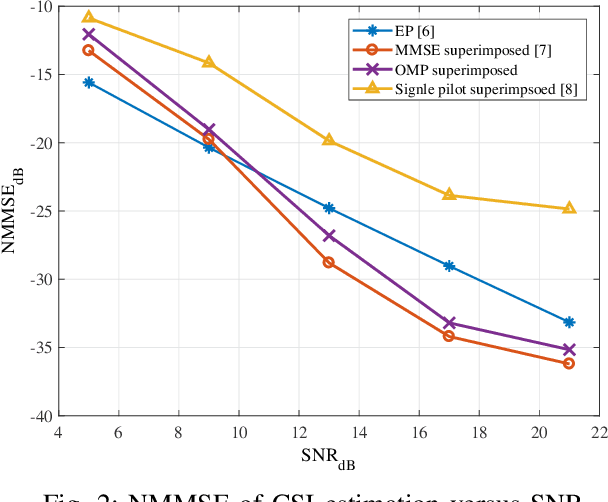
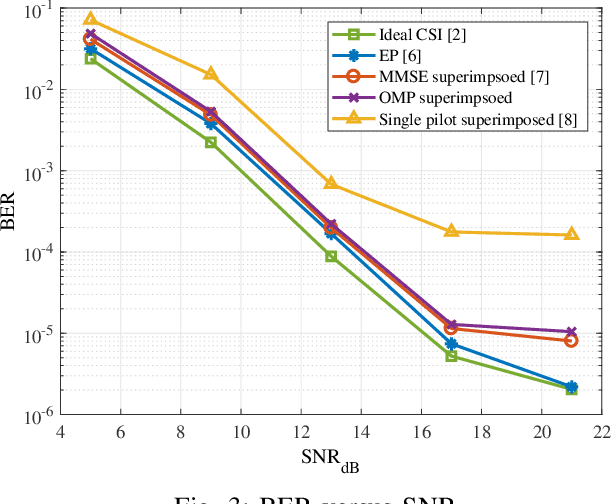
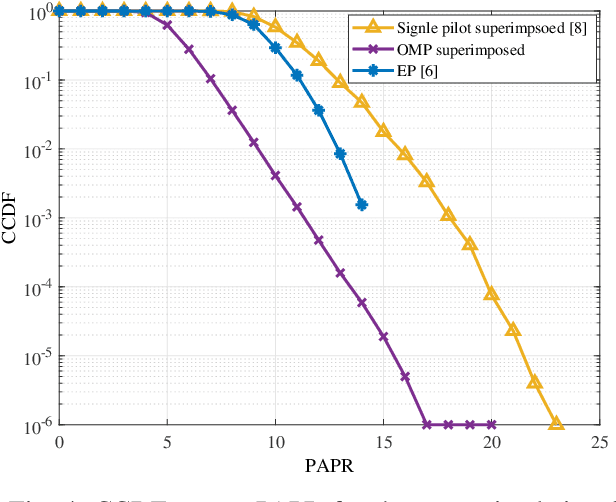
Orthogonal time frequency space (OTFS) technique is a two-dimensional modulation method that multiplexes information symbols in the delay-Doppler (DD) domain. OTFS combats high Doppler shift existing in high speed wireless communication. However, conventional channel estimation in OTFS suffers from high pilot overhead because guard symbols occupy a significant part of the DD domain grids. In this paper, a superimposed channel estimation is proposed which can completely estimate channel parameters without considering pilot overhead and performance degradation. As the channel state information (CSI) in the DD domain is sparse, a sparse recovery algorithm orthogonal matching pursuit (OMP) is used. Besides, our proposed method does not suffer from high peak to average power ratio (PAPR). To detect information symbols, a message passing (MP) detector, which exploits the sparsity of DD channel representation, is employed.
Hardware Acceleration of Lane Detection Algorithm: A GPU Versus FPGA Comparison
Dec 19, 2022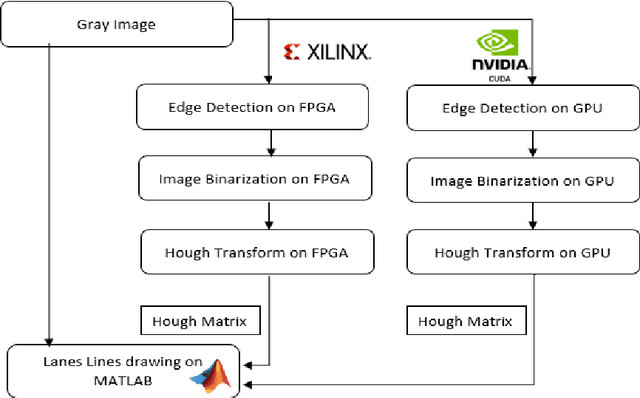


A Complete Computer vision system can be divided into two main categories: detection and classification. The Lane detection algorithm is a part of the computer vision detection category and has been applied in autonomous driving and smart vehicle systems. The lane detection system is responsible for lane marking in a complex road environment. At the same time, lane detection plays a crucial role in the warning system for a car when departs the lane. The implemented lane detection algorithm is mainly divided into two steps: edge detection and line detection. In this paper, we will compare the state-of-the-art implementation performance obtained with both FPGA and GPU to evaluate the trade-off for latency, power consumption, and utilization. Our comparison emphasises the advantages and disadvantages of the two systems.
Plant species richness prediction from DESIS hyperspectral data: A comparison study on feature extraction procedures and regression models
Jan 05, 2023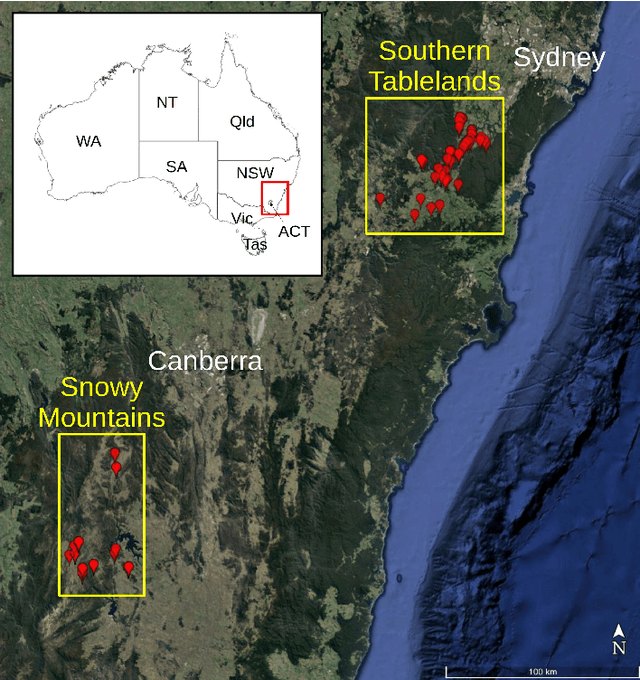
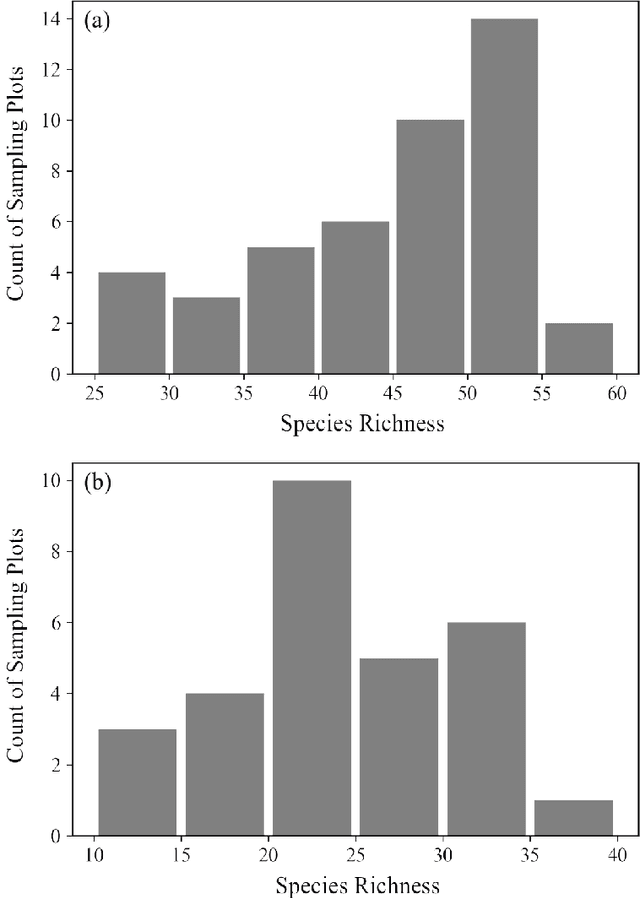
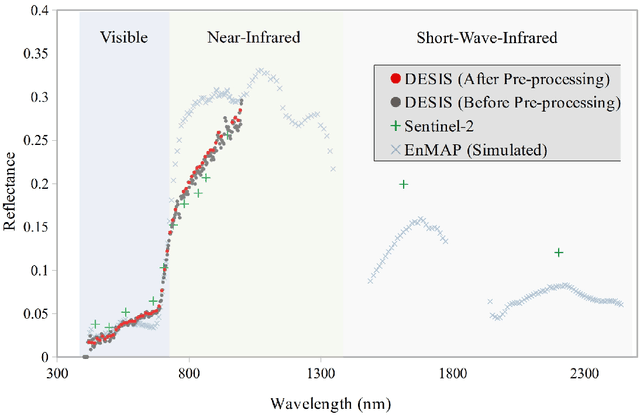
The diversity of terrestrial vascular plants plays a key role in maintaining the stability and productivity of ecosystems. Monitoring species compositional diversity across large spatial scales is challenging and time consuming. The advanced spectral and spatial specification of the recently launched DESIS (the DLR Earth Sensing Imaging Spectrometer) instrument provides a unique opportunity to test the potential for monitoring plant species diversity with spaceborne hyperspectral data. This study provides a quantitative assessment on the ability of DESIS hyperspectral data for predicting plant species richness in two different habitat types in southeast Australia. Spectral features were first extracted from the DESIS spectra, then regressed against on-ground estimates of plant species richness, with a two-fold cross validation scheme to assess the predictive performance. We tested and compared the effectiveness of Principal Component Analysis (PCA), Canonical Correlation Analysis (CCA), and Partial Least Squares analysis (PLS) for feature extraction, and Kernel Ridge Regression (KRR), Gaussian Process Regression (GPR), Random Forest Regression (RFR) for species richness prediction. The best prediction results were r=0.76 and RMSE=5.89 for the Southern Tablelands region, and r=0.68 and RMSE=5.95 for the Snowy Mountains region. Relative importance analysis for the DESIS spectral bands showed that the red-edge, red, and blue spectral regions were more important for predicting plant species richness than the green bands and the near-infrared bands beyond red-edge. We also found that the DESIS hyperspectral data performed better than Sentinel-2 multispectral data in the prediction of plant species richness. Our results provide a quantitative reference for future studies exploring the potential of spaceborne hyperspectral data for plant biodiversity mapping.
Benchmarking Edge Computing Devices for Grape Bunches and Trunks Detection using Accelerated Object Detection Single Shot MultiBox Deep Learning Models
Nov 21, 2022
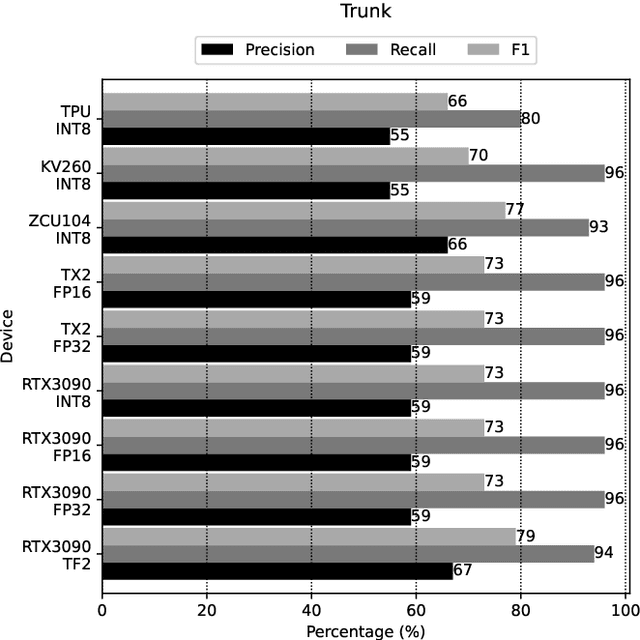

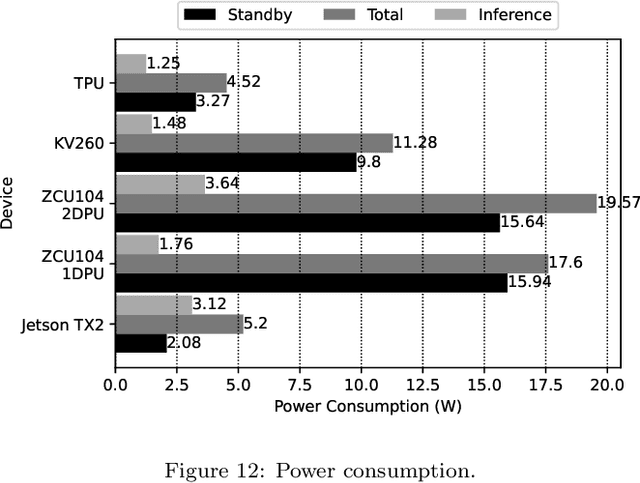
Purpose: Visual perception enables robots to perceive the environment. Visual data is processed using computer vision algorithms that are usually time-expensive and require powerful devices to process the visual data in real-time, which is unfeasible for open-field robots with limited energy. This work benchmarks the performance of different heterogeneous platforms for object detection in real-time. This research benchmarks three architectures: embedded GPU -- Graphical Processing Units (such as NVIDIA Jetson Nano 2 GB and 4 GB, and NVIDIA Jetson TX2), TPU -- Tensor Processing Unit (such as Coral Dev Board TPU), and DPU -- Deep Learning Processor Unit (such as in AMD-Xilinx ZCU104 Development Board, and AMD-Xilinx Kria KV260 Starter Kit). Method: The authors used the RetinaNet ResNet-50 fine-tuned using the natural VineSet dataset. After the trained model was converted and compiled for target-specific hardware formats to improve the execution efficiency. Conclusions and Results: The platforms were assessed in terms of performance of the evaluation metrics and efficiency (time of inference). Graphical Processing Units (GPUs) were the slowest devices, running at 3 FPS to 5 FPS, and Field Programmable Gate Arrays (FPGAs) were the fastest devices, running at 14 FPS to 25 FPS. The efficiency of the Tensor Processing Unit (TPU) is irrelevant and similar to NVIDIA Jetson TX2. TPU and GPU are the most power-efficient, consuming about 5W. The performance differences, in the evaluation metrics, across devices are irrelevant and have an F1 of about 70 % and mean Average Precision (mAP) of about 60 %.
Policy Transfer via Enhanced Action Space
Dec 07, 2022
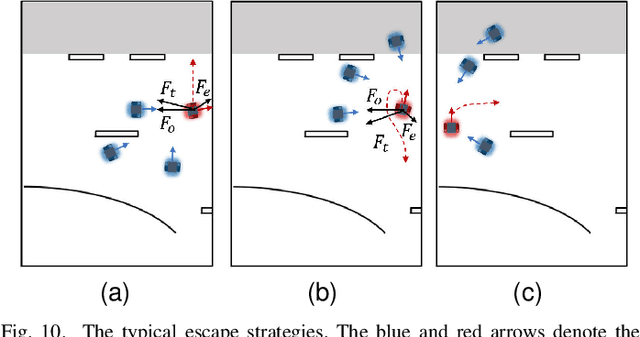
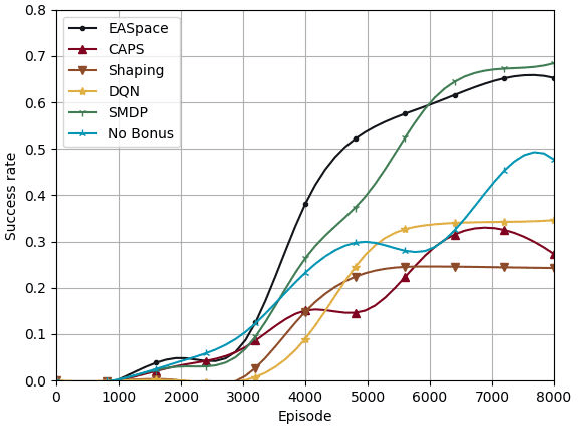
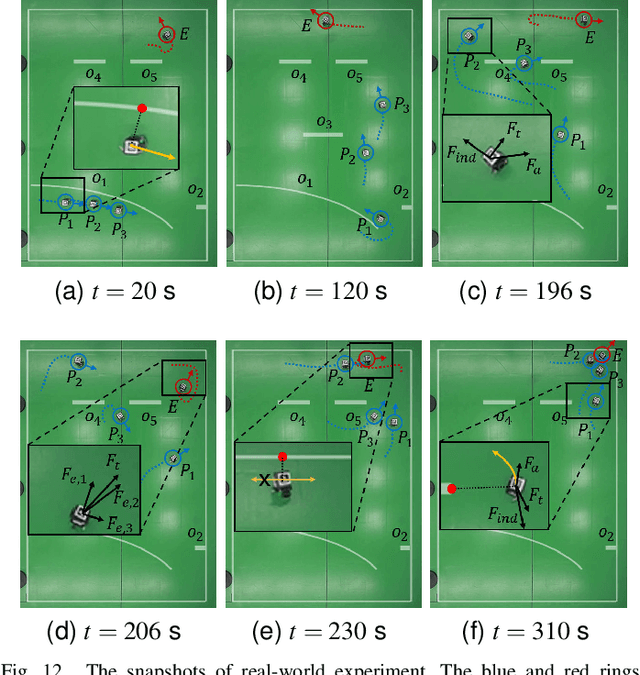
Though transfer learning is promising to increase the learning efficiency, the existing methods are still subject to the challenges from long-horizon tasks, especially when expert policies are sub-optimal and partially useful. Hence, a novel algorithm named EASpace (Enhanced Action Space) is proposed in this paper to transfer the knowledge of multiple sub-optimal expert policies. EASpace formulates each expert policy into multiple macro actions with different execution time period, then integrates all macro actions into the primitive action space directly. Through this formulation, the proposed EASpace could learn when to execute which expert policy and how long it lasts. An intra-macro-action learning rule is proposed by adjusting the temporal difference target of macro actions to improve the data efficiency and alleviate the non-stationarity issue in multi-agent settings. Furthermore, an additional reward proportional to the execution time of macro actions is introduced to encourage the environment exploration via macro actions, which is significant to learn a long-horizon task. Theoretical analysis is presented to show the convergence of the proposed algorithm. The efficiency of the proposed algorithm is illustrated by a grid-based game and a multi-agent pursuit problem. The proposed algorithm is also implemented to real physical systems to justify its effectiveness.
DeepSpeed Data Efficiency: Improving Deep Learning Model Quality and Training Efficiency via Efficient Data Sampling and Routing
Dec 07, 2022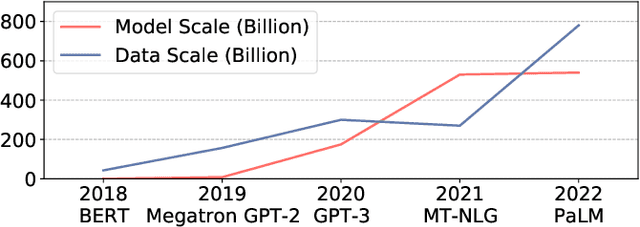
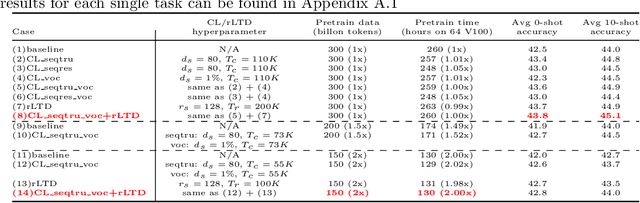
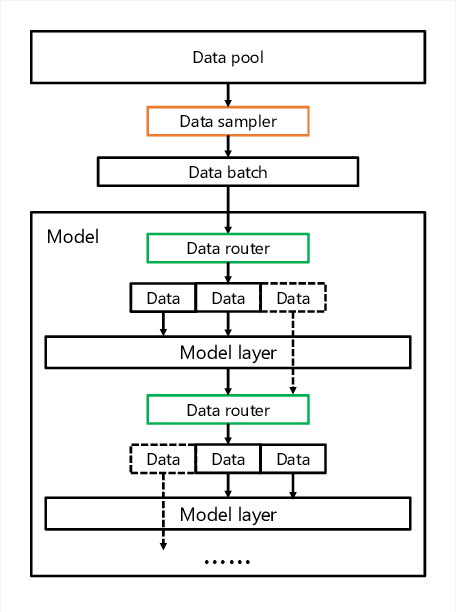

Recent advances on deep learning models come at the price of formidable training cost. The increasing model size is one of the root cause, but another less-emphasized fact is that data scale is actually increasing at a similar speed as model scale, and the training cost is proportional to both of them. Compared to the rapidly evolving model architecture, how to efficiently use the training data (especially for the expensive foundation model pertaining) is both less explored and difficult to realize due to the lack of a convenient framework that focus on data efficiency capabilities. To this end, we present DeepSpeed Data Efficiency library, a framework that makes better use of data, increases training efficiency, and improves model quality. Specifically, it provides efficient data sampling via curriculum learning, and efficient data routing via random layerwise token dropping. DeepSpeed Data Efficiency takes extensibility, flexibility and composability into consideration, so that users can easily utilize the framework to compose multiple techniques and apply customized strategies. By applying our solution to GPT-3 1.3B and BERT-Large language model pretraining, we can achieve similar model quality with up to 2x less data and 2x less time, or achieve better model quality under similar amount of data and time.