 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hand Guided High Resolution Feature Enhancement for Fine-Grained Atomic Action Segmentation within Complex Human Assemblies
Nov 24, 2022
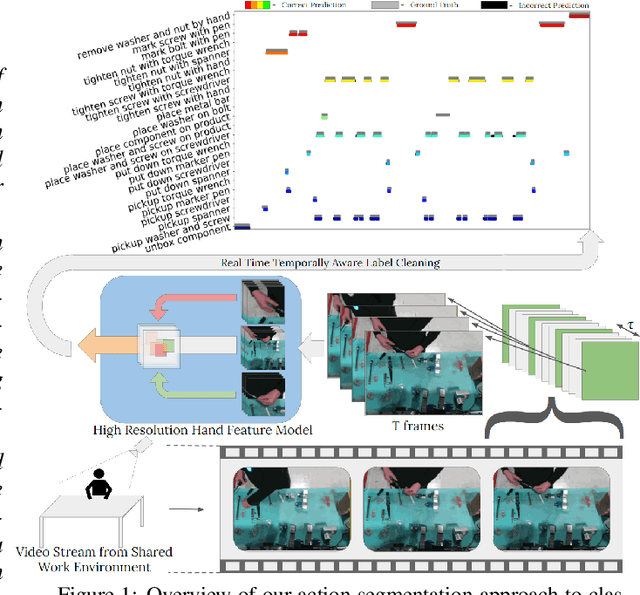
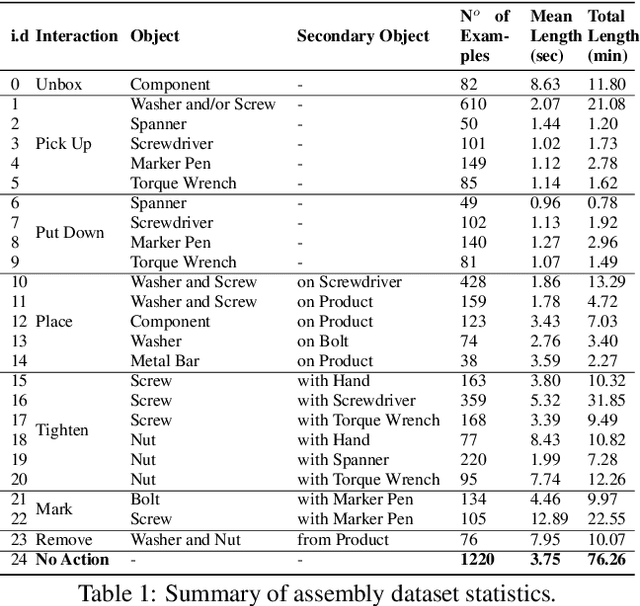
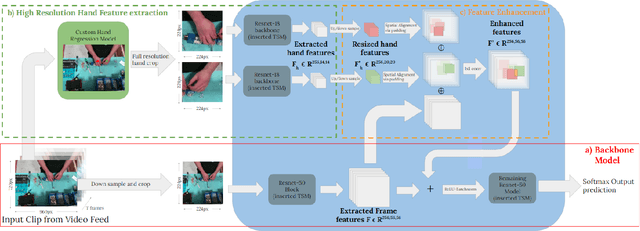
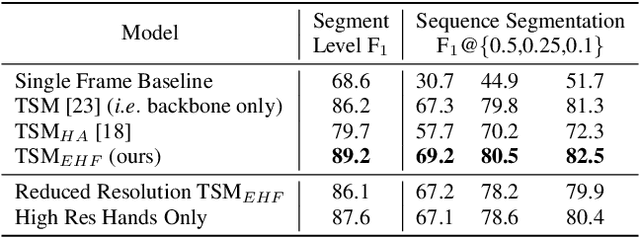
Due to the rapid temporal and fine-grained nature of complex human assembly atomic actions, traditional action segmentation approaches requiring the spatial (and often temporal) down sampling of video frames often loose vital fine-grained spatial and temporal information required for accurate classification within the manufacturing domain. In order to fully utilise higher resolution video data (often collected within the manufacturing domain) and facilitate real time accurate action segmentation - required for human robot collaboration - we present a novel hand location guided high resolution feature enhanced model. We also propose a simple yet effective method of deploying offline trained action recognition models for real time action segmentation on temporally short fine-grained actions, through the use of surround sampling while training and temporally aware label cleaning at inference. We evaluate our model on a novel action segmentation dataset containing 24 (+background) atomic actions from video data of a real world robotics assembly production line. Showing both high resolution hand features as well as traditional frame wide features improve fine-grained atomic action classification, and that though temporally aware label clearing our model is capable of surpassing similar encoder/decoder methods, while allowing for real time classification.
Geographic and Geopolitical Biases of Language Models
Dec 20, 2022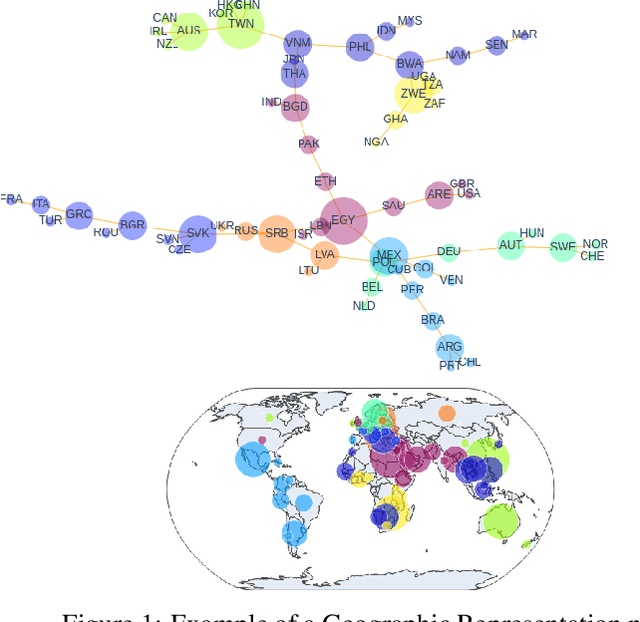
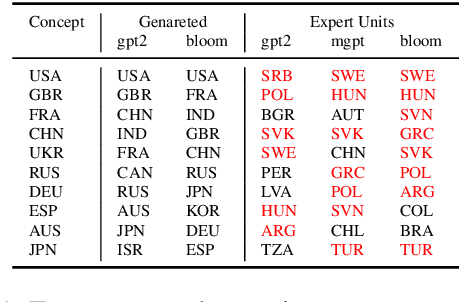
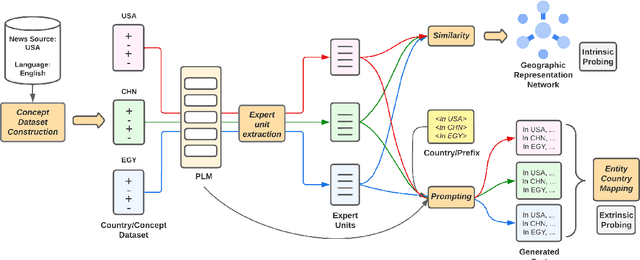
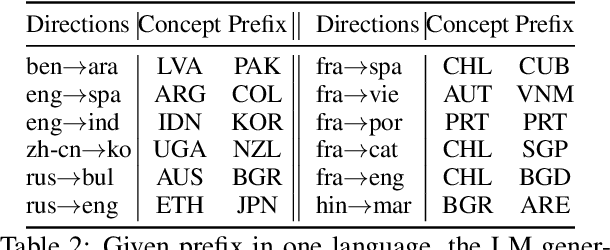
Pretrained language models (PLMs) often fail to fairly represent target users from certain world regions because of the under-representation of those regions in training datasets. With recent PLMs trained on enormous data sources, quantifying their potential biases is difficult, due to their black-box nature and the sheer scale of the data sources. In this work, we devise an approach to study the geographic bias (and knowledge) present in PLMs, proposing a Geographic-Representation Probing Framework adopting a self-conditioning method coupled with entity-country mappings. Our findings suggest PLMs' representations map surprisingly well to the physical world in terms of country-to-country associations, but this knowledge is unequally shared across languages. Last, we explain how large PLMs despite exhibiting notions of geographical proximity, over-amplify geopolitical favouritism at inference time.
Improving the quality of neural TTS using long-form content and multi-speaker multi-style modeling
Dec 20, 2022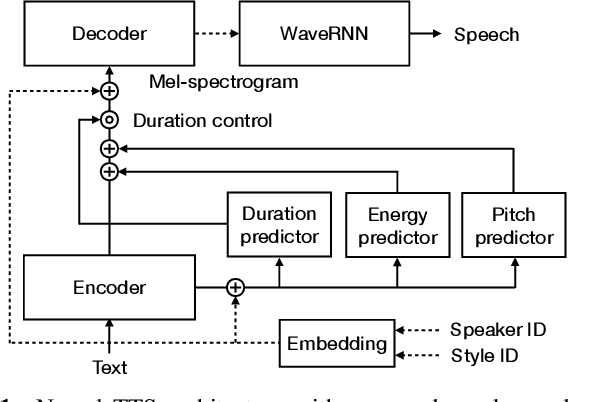
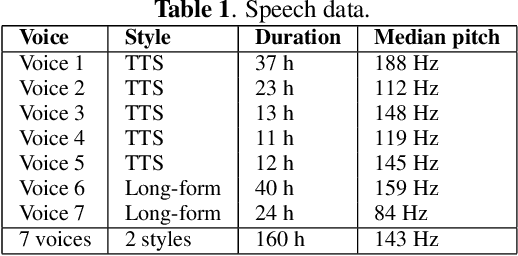
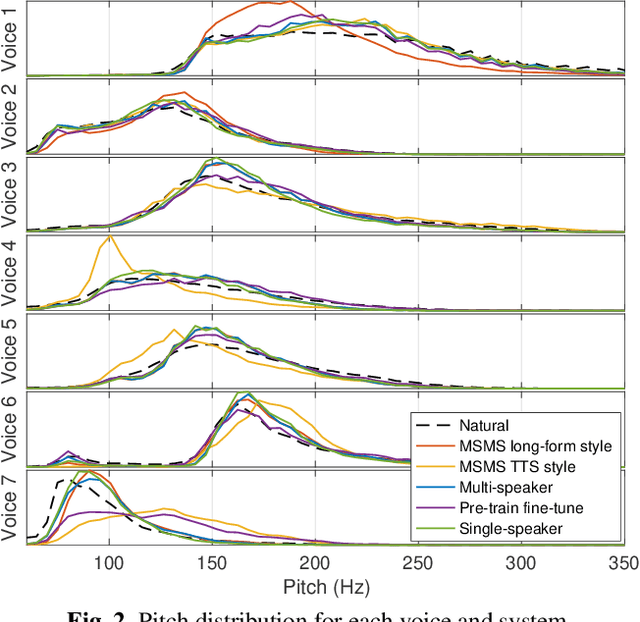
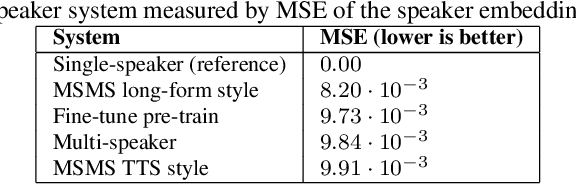
Neural text-to-speech (TTS) can provide quality close to natural speech if an adequate amount of high-quality speech material is available for training. However, acquiring speech data for TTS training is costly and time-consuming, especially if the goal is to generate different speaking styles. In this work, we show that we can transfer speaking style across speakers and improve the quality of synthetic speech by training a multi-speaker multi-style (MSMS) model with long-form recordings, in addition to regular TTS recordings. In particular, we show that 1) multi-speaker modeling improves the overall TTS quality, 2) the proposed MSMS approach outperforms pre-training and fine-tuning approach when utilizing additional multi-speaker data, and 3) long-form speaking style is highly rated regardless of the target text domain.
Scale-Invariant Specifications for Human-Swarm Systems
Dec 12, 2022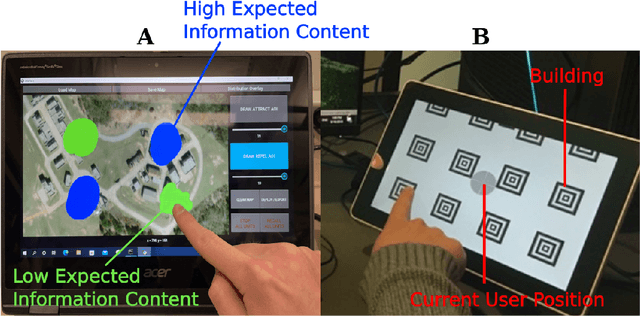
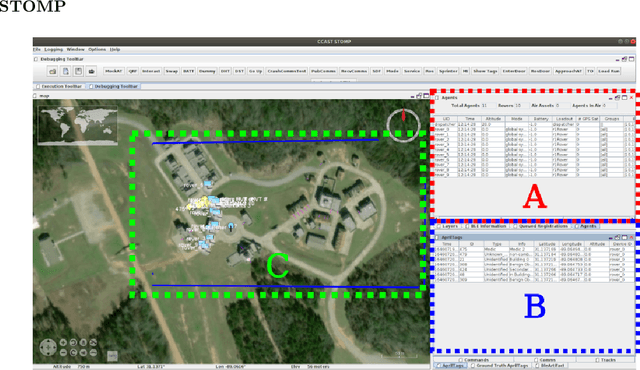
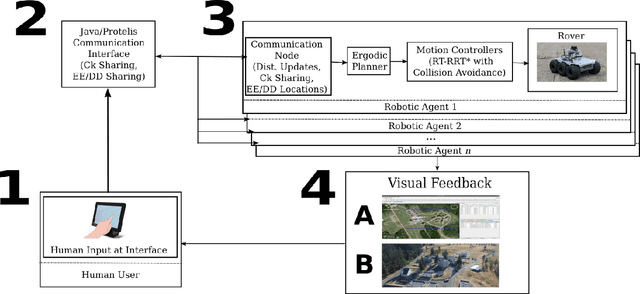
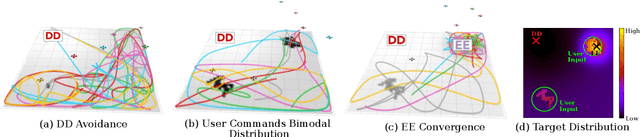
We present a method for controlling a swarm using its spectral decomposition -- that is, by describing the set of trajectories of a swarm in terms of a spatial distribution throughout the operational domain -- guaranteeing scale invariance with respect to the number of agents both for computation and for the operator tasked with controlling the swarm. We use ergodic control, decentralized across the network, for implementation. In the DARPA OFFSET program field setting, we test this interface design for the operator using the STOMP interface -- the same interface used by Raytheon BBN throughout the duration of the OFFSET program. In these tests, we demonstrate that our approach is scale-invariant -- the user specification does not depend on the number of agents; it is persistent -- the specification remains active until the user specifies a new command; and it is real-time -- the user can interact with and interrupt the swarm at any time. Moreover, we show that the spectral/ergodic specification of swarm behavior degrades gracefully as the number of agents goes down, enabling the operator to maintain the same approach as agents become disabled or are added to the network. We demonstrate the scale-invariance and dynamic response of our system in a field relevant simulator on a variety of tactical scenarios with up to 50 agents. We also demonstrate the dynamic response of our system in the field with a smaller team of agents. Lastly, we make the code for our system available.
Online Shielding for Reinforcement Learning
Dec 04, 2022Besides the recent impressive results on reinforcement learning (RL), safety is still one of the major research challenges in RL. RL is a machine-learning approach to determine near-optimal policies in Markov decision processes (MDPs). In this paper, we consider the setting where the safety-relevant fragment of the MDP together with a temporal logic safety specification is given and many safety violations can be avoided by planning ahead a short time into the future. We propose an approach for online safety shielding of RL agents. During runtime, the shield analyses the safety of each available action. For any action, the shield computes the maximal probability to not violate the safety specification within the next $k$ steps when executing this action. Based on this probability and a given threshold, the shield decides whether to block an action from the agent. Existing offline shielding approaches compute exhaustively the safety of all state-action combinations ahead of time, resulting in huge computation times and large memory consumption. The intuition behind online shielding is to compute at runtime the set of all states that could be reached in the near future. For each of these states, the safety of all available actions is analysed and used for shielding as soon as one of the considered states is reached. Our approach is well suited for high-level planning problems where the time between decisions can be used for safety computations and it is sustainable for the agent to wait until these computations are finished. For our evaluation, we selected a 2-player version of the classical computer game SNAKE. The game represents a high-level planning problem that requires fast decisions and the multiplayer setting induces a large state space, which is computationally expensive to analyse exhaustively.
Q-Ensemble for Offline RL: Don't Scale the Ensemble, Scale the Batch Size
Nov 20, 2022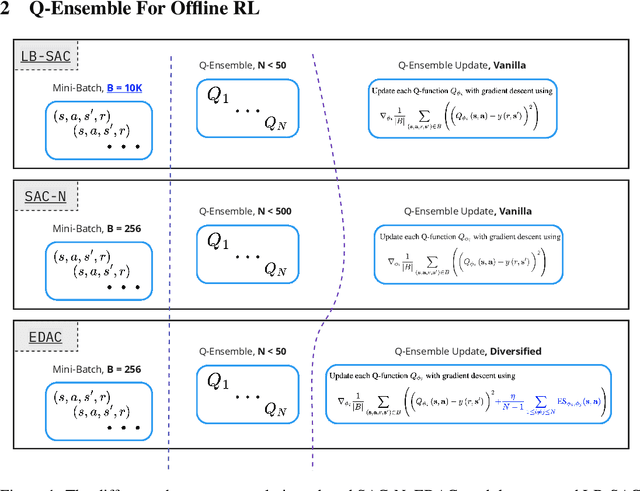
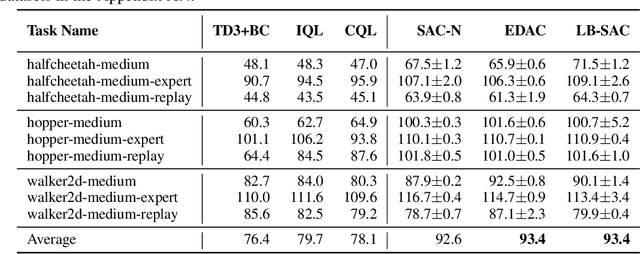
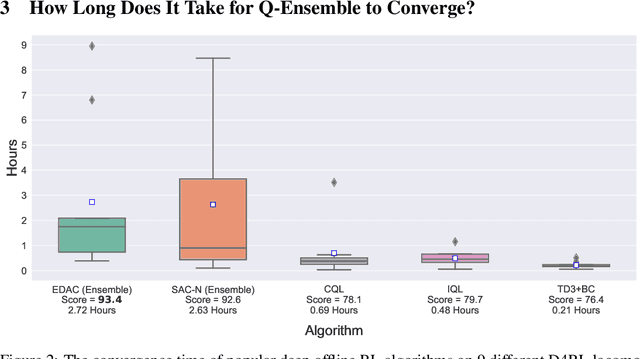
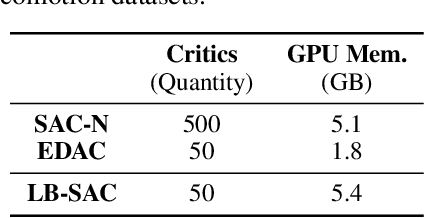
Training large neural networks is known to be time-consuming, with the learning duration taking days or even weeks. To address this problem, large-batch optimization was introduced. This approach demonstrated that scaling mini-batch sizes with appropriate learning rate adjustments can speed up the training process by orders of magnitude. While long training time was not typically a major issue for model-free deep offline RL algorithms, recently introduced Q-ensemble methods achieving state-of-the-art performance made this issue more relevant, notably extending the training duration. In this work, we demonstrate how this class of methods can benefit from large-batch optimization, which is commonly overlooked by the deep offline RL community. We show that scaling the mini-batch size and naively adjusting the learning rate allows for (1) a reduced size of the Q-ensemble, (2) stronger penalization of out-of-distribution actions, and (3) improved convergence time, effectively shortening training duration by 3-4x times on average.
Improved Kernel Alignment Regret Bound for Online Kernel Learning
Dec 26, 2022
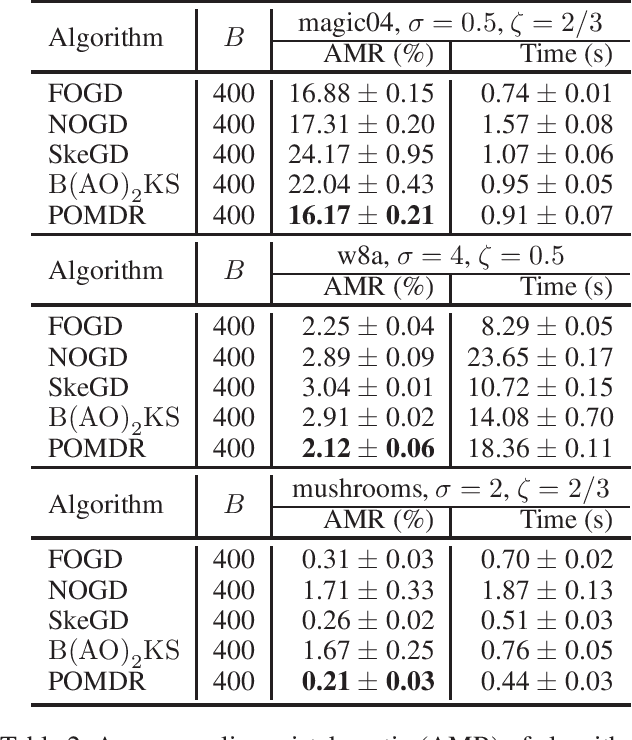
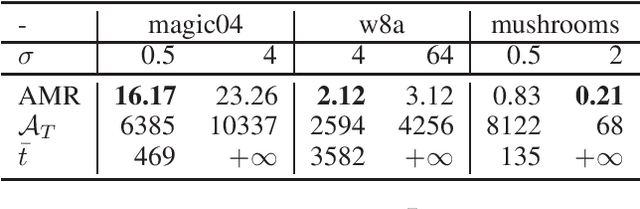
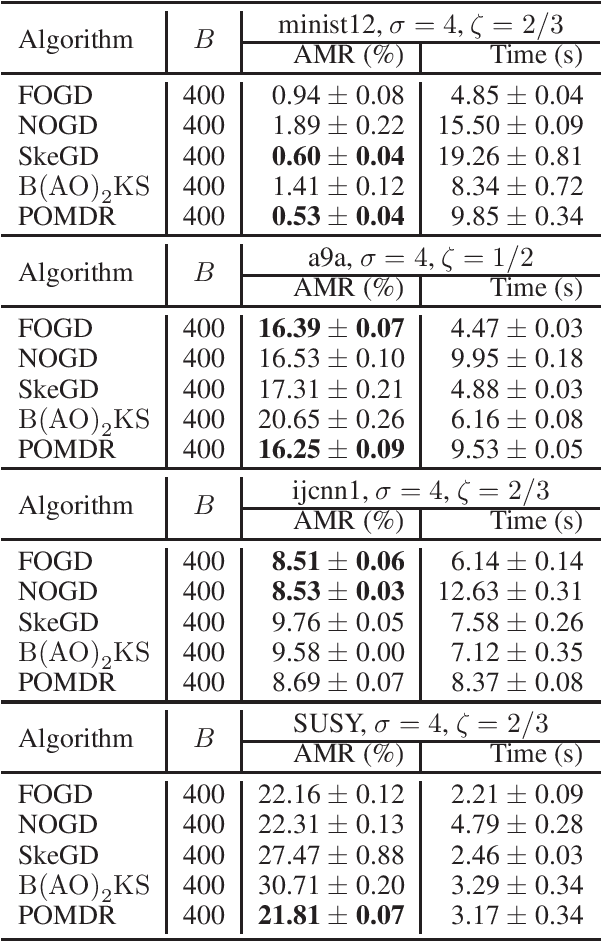
In this paper, we improve the kernel alignment regret bound for online kernel learning in the regime of the Hinge loss function. Previous algorithm achieves a regret of $O((\mathcal{A}_TT\ln{T})^{\frac{1}{4}})$ at a computational complexity (space and per-round time) of $O(\sqrt{\mathcal{A}_TT\ln{T}})$, where $\mathcal{A}_T$ is called \textit{kernel alignment}. We propose an algorithm whose regret bound and computational complexity are better than previous results. Our results depend on the decay rate of eigenvalues of the kernel matrix. If the eigenvalues of the kernel matrix decay exponentially, then our algorithm enjoys a regret of $O(\sqrt{\mathcal{A}_T})$ at a computational complexity of $O(\ln^2{T})$. Otherwise, our algorithm enjoys a regret of $O((\mathcal{A}_TT)^{\frac{1}{4}})$ at a computational complexity of $O(\sqrt{\mathcal{A}_TT})$. We extend our algorithm to batch learning and obtain a $O(\frac{1}{T}\sqrt{\mathbb{E}[\mathcal{A}_T]})$ excess risk bound which improves the previous $O(1/\sqrt{T})$ bound.
Physics Informed Neural Network for Dynamic Stress Prediction
Nov 28, 2022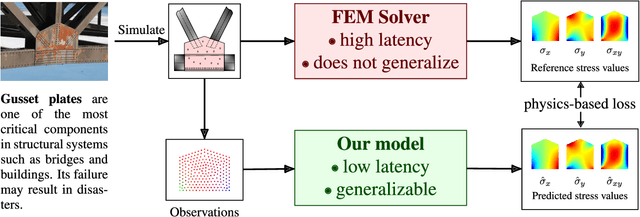

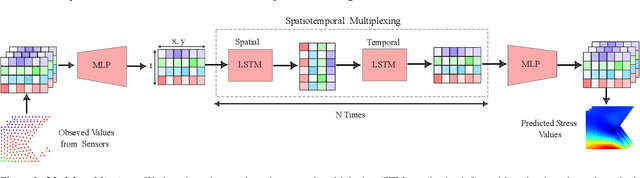

Structural failures are often caused by catastrophic events such as earthquakes and winds. As a result, it is crucial to predict dynamic stress distributions during highly disruptive events in real time. Currently available high-fidelity methods, such as Finite Element Models (FEMs), suffer from their inherent high complexity. Therefore, to reduce computational cost while maintaining accuracy, a Physics Informed Neural Network (PINN), PINN-Stress model, is proposed to predict the entire sequence of stress distribution based on Finite Element simulations using a partial differential equation (PDE) solver. Using automatic differentiation, we embed a PDE into a deep neural network's loss function to incorporate information from measurements and PDEs. The PINN-Stress model can predict the sequence of stress distribution in almost real-time and can generalize better than the model without PINN.
How would Stance Detection Techniques Evolve after the Launch of ChatGPT?
Dec 30, 2022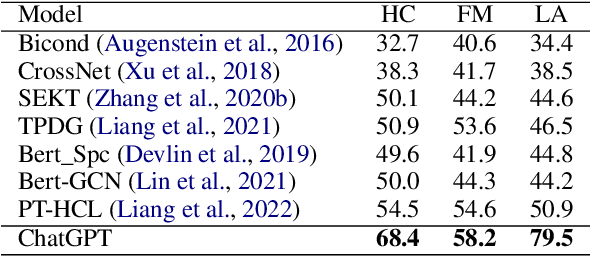
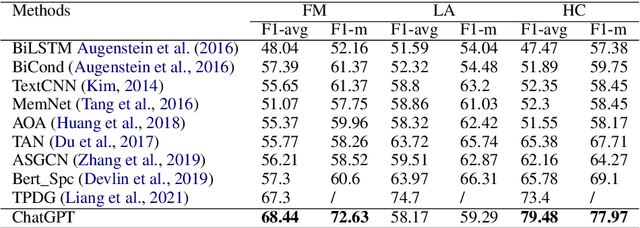
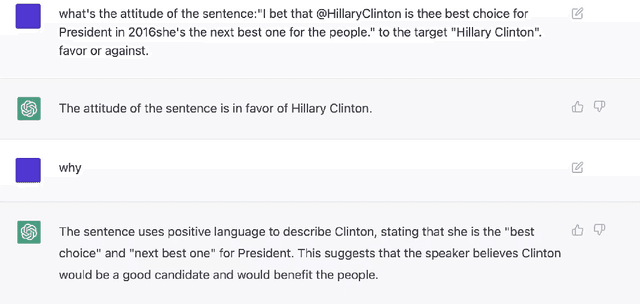
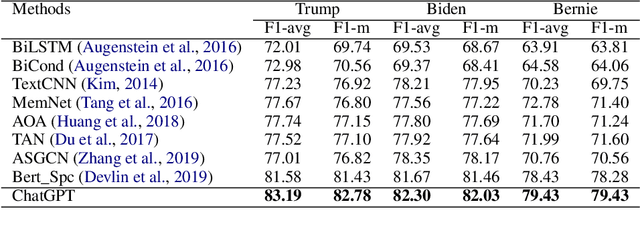
Stance detection refers to the task of extracting the standpoint (Favor, Against or Neither) towards a target in given texts. Such research gains increasing attention with the proliferation of social media contents. The conventional framework of handling stance detection is converting it into text classification tasks. Deep learning models have already replaced rule-based models and traditional machine learning models in solving such problems. Current deep neural networks are facing two main challenges which are insufficient labeled data and information in social media posts and the unexplainable nature of deep learning models. A new pre-trained language model chatGPT was launched on Nov 30, 2022. For the stance detection tasks, our experiments show that ChatGPT can achieve SOTA or similar performance for commonly used datasets including SemEval-2016 and P-Stance. At the same time, ChatGPT can provide explanation for its own prediction, which is beyond the capability of any existing model. The explanations for the cases it cannot provide classification results are especially useful. ChatGPT has the potential to be the best AI model for stance detection tasks in NLP, or at least change the research paradigm of this field. ChatGPT also opens up the possibility of building explanatory AI for stance detection.
HiTeA: Hierarchical Temporal-Aware Video-Language Pre-training
Dec 30, 2022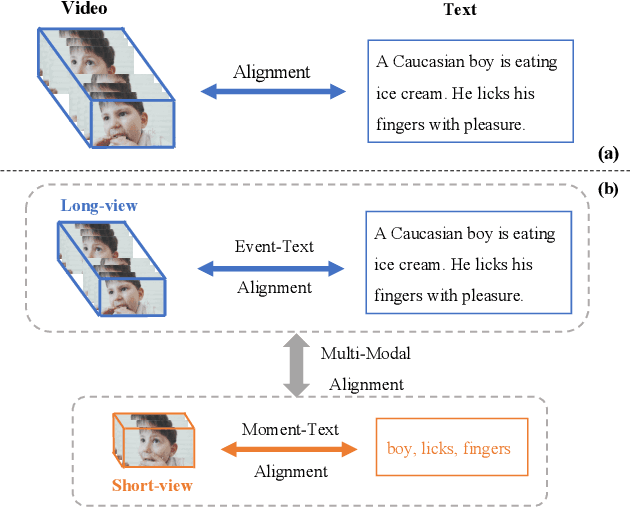
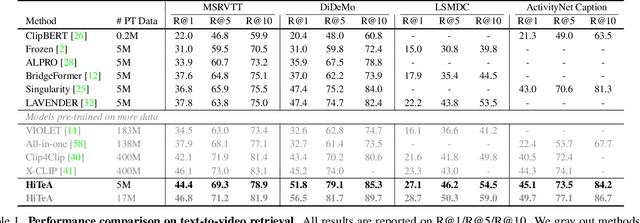
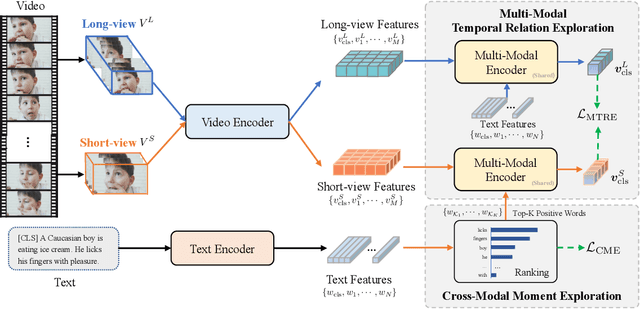
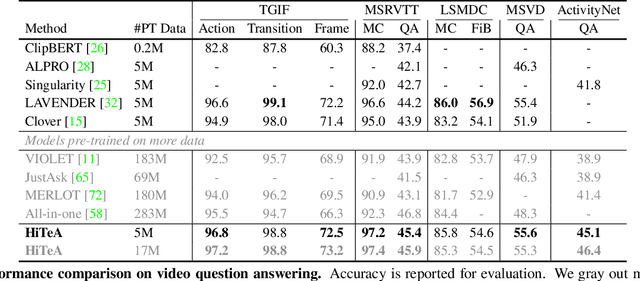
Video-language pre-training has advanced the performance of various downstream video-language tasks. However, most previous methods directly inherit or adapt typical image-language pre-training paradigms to video-language pre-training, thus not fully exploiting the unique characteristic of video, i.e., temporal. In this paper, we propose a Hierarchical Temporal-Aware video-language pre-training framework, HiTeA, with two novel pre-training tasks for modeling cross-modal alignment between moments and texts as well as the temporal relations of video-text pairs. Specifically, we propose a cross-modal moment exploration task to explore moments in videos, which results in detailed video moment representation. Besides, the inherent temporal relations are captured by aligning video-text pairs as a whole in different time resolutions with multi-modal temporal relation exploration task. Furthermore, we introduce the shuffling test to evaluate the temporal reliance of datasets and video-language pre-training models. We achieve state-of-the-art results on 15 well-established video-language understanding and generation tasks, especially on temporal-oriented datasets (e.g., SSv2-Template and SSv2-Label) with 8.6% and 11.1% improvement respectively. HiTeA also demonstrates strong generalization ability when directly transferred to downstream tasks in a zero-shot manner. Models and demo will be available on ModelScope.