 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time Series Prediction for Food sustainability
Sep 14, 2022
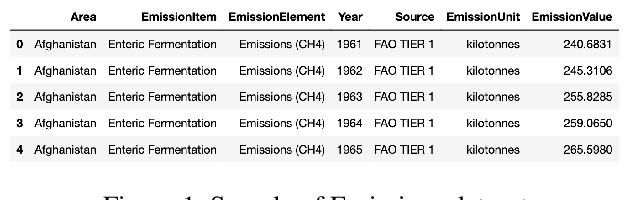


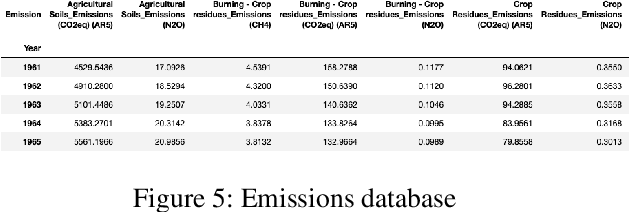
With exponential growth in the human population, it is vital to conserve natural resources without compromising on producing enough food to feed everyone. Doing so can improve people's livelihoods, health, and ecosystems for the present and future generations. Sustainable development, a paradigm of the United Nations, is rooted in food, crop, livestock, forest, population, and even the emission of gases. By understanding the overall usage of natural resources in different countries in the past, it is possible to forecast the demand in each country. The proposed solution consists of implementing a machine learning system using a statistical regression model that can predict the top k products that would endure a shortage in each country in a specific period in the future. The prediction performance in terms of absolute error and root mean square error show promising results due to its low errors. This solution could help organizations and manufacturers understand the productivity and sustainability needed to satisfy the global demand.
A Real-Time Fusion Framework for Long-term Visual Localization
Oct 18, 2022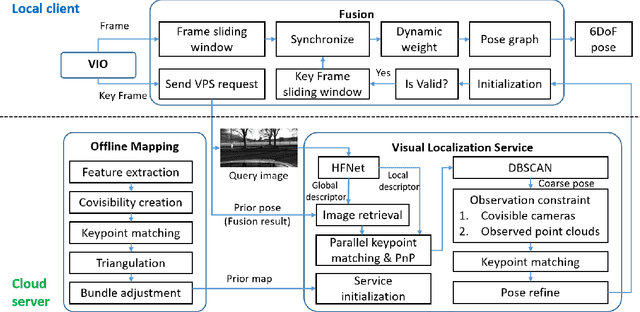
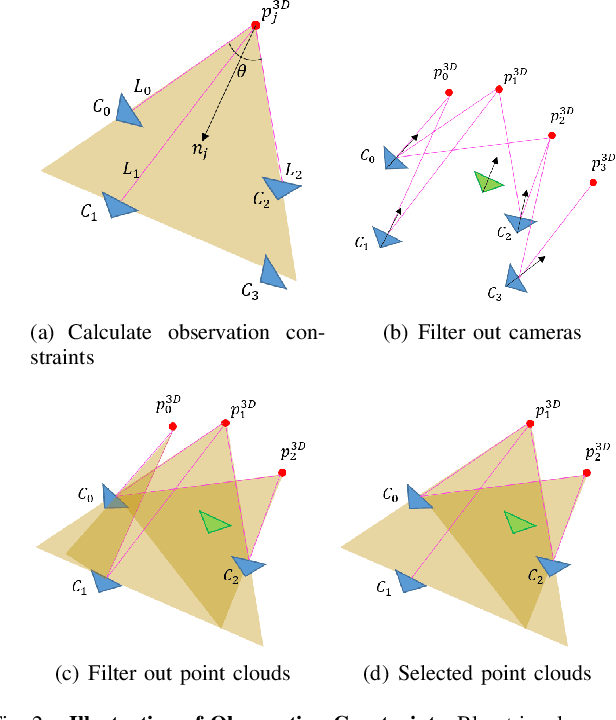
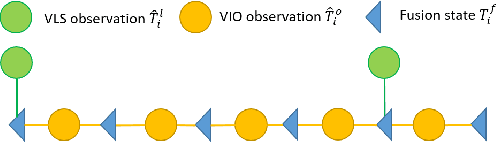
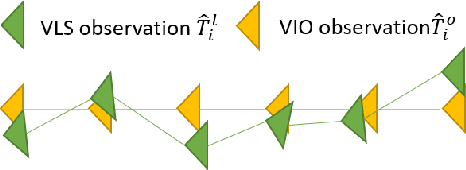
Visual localization is a fundamental task that regresses the 6 Degree Of Freedom (6DoF) poses with image features in order to serve the high precision localization requests in many robotics applications. Degenerate conditions like motion blur, illumination changes and environment variations place great challenges in this task. Fusion with additional information, such as sequential information and Inertial Measurement Unit (IMU) inputs, would greatly assist such problems. In this paper, we present an efficient client-server visual localization architecture that fuses global and local pose estimations to realize promising precision and efficiency. We include additional geometry hints in mapping and global pose regressing modules to improve the measurement quality. A loosely coupled fusion policy is adopted to leverage the computation complexity and accuracy. We conduct the evaluations on two typical open-source benchmarks, 4Seasons and OpenLORIS. Quantitative results prove that our framework has competitive performance with respect to other state-of-the-art visual localization solutions.
A Review and Evaluation of Elastic Distance Functions for Time Series Clustering
May 30, 2022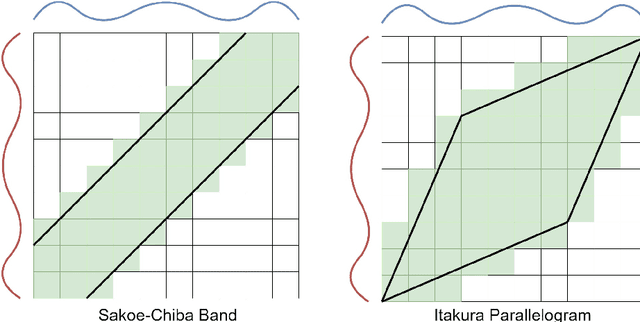
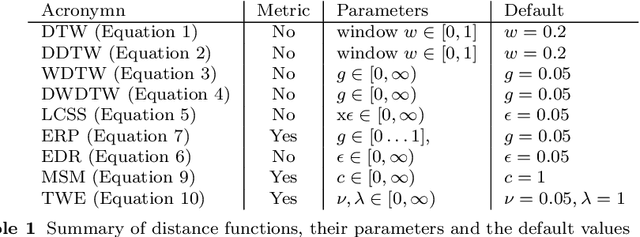
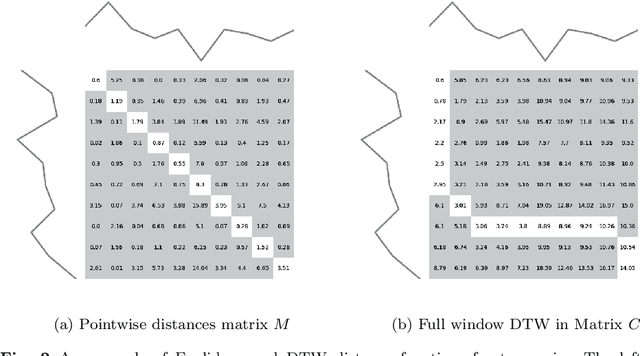
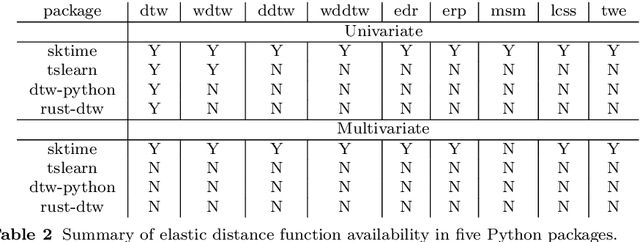
Time series clustering is the act of grouping time series data without recourse to a label. Algorithms that cluster time series can be classified into two groups: those that employ a time series specific distance measure; and those that derive features from time series. Both approaches usually rely on traditional clustering algorithms such as $k$-means. Our focus is on distance based time series that employ elastic distance measures, i.e. distances that perform some kind of realignment whilst measuring distance. We describe nine commonly used elastic distance measures and compare their performance with k-means and k-medoids clustering. Our findings are surprising. The most popular technique, dynamic time warping (DTW), performs worse than Euclidean distance with k-means, and even when tuned, is no better. Using k-medoids rather than k-means improved the clusterings for all nine distance measures. DTW is not significantly better than Euclidean distance with k-medoids. Generally, distance measures that employ editing in conjunction with warping perform better, and one distance measure, the move-split-merge (MSM) method, is the best performing measure of this study. We also compare to clustering with DTW using barycentre averaging (DBA). We find that DBA does improve DTW k-means, but that the standard DBA is still worse than using MSM. Our conclusion is to recommend MSM with k-medoids as the benchmark algorithm for clustering time series with elastic distance measures. We provide implementations, results and guidance on reproducing results on the associated GitHub repository.
Beyond Inverted Pendulums: Task-optimal Simple Models of Legged Locomotion
Jan 05, 2023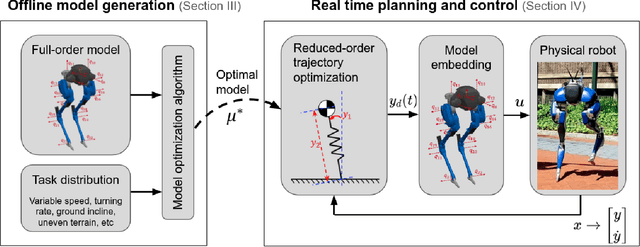
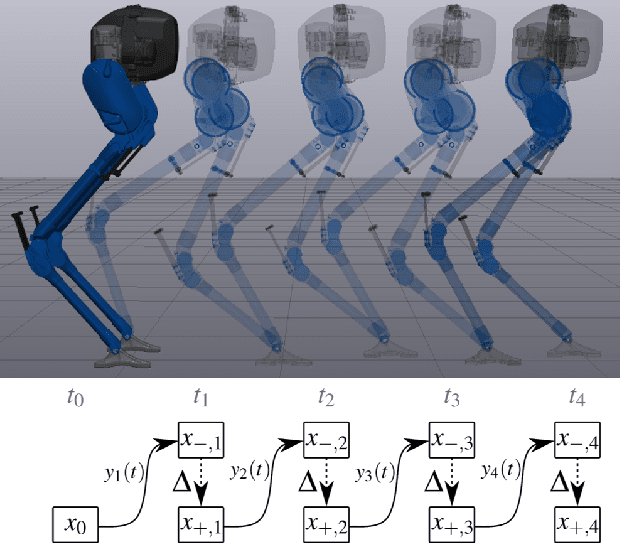
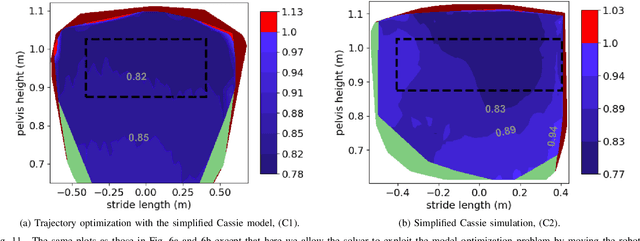

Reduced-order models (ROM) are popular in online motion planning due to their simplicity. A good ROM captures the bulk of the full model's dynamics while remaining low dimension. However, planning within the reduced-order space unavoidably constrains the full model, and hence we sacrifice the full potential of the robot. In the community of legged locomotion, this has lead to a search for better model extensions, but many of these extensions require human intuition, and there has not existed a principled way of evaluating the model performance and discovering new models. In this work, we propose a model optimization algorithm that automatically synthesizes reduced-order models, optimal with respect to any user-specified cost function. To demonstrate our work, we optimized models for a bipedal robot Cassie. We show in hardware experiment that the optimal ROM is simple enough for real time planning application and that the real robot achieves higher performance by using the optimal ROM.
HyperReel: High-Fidelity 6-DoF Video with Ray-Conditioned Sampling
Jan 05, 2023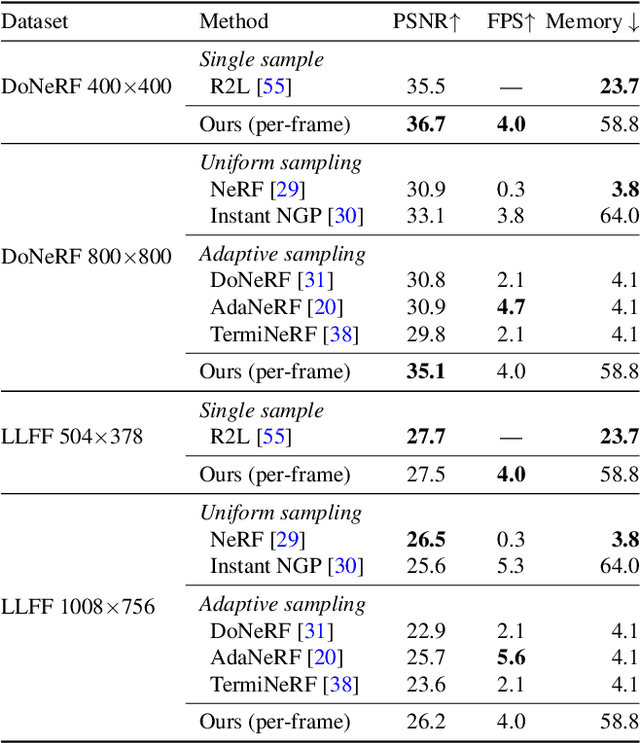
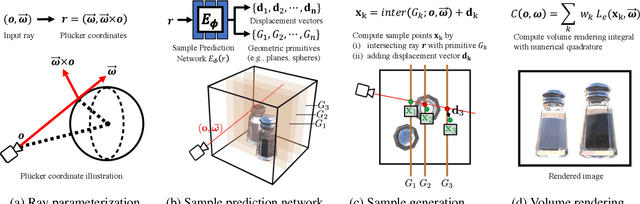
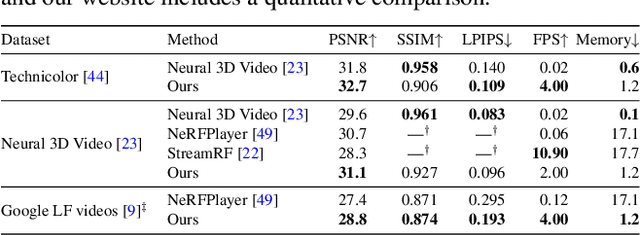
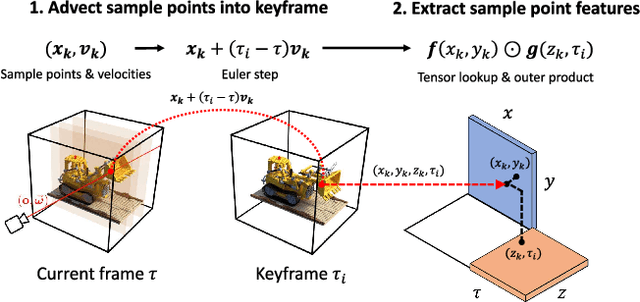
Volumetric scene representations enable photorealistic view synthesis for static scenes and form the basis of several existing 6-DoF video techniques. However, the volume rendering procedures that drive these representations necessitate careful trade-offs in terms of quality, rendering speed, and memory efficiency. In particular, existing methods fail to simultaneously achieve real-time performance, small memory footprint, and high-quality rendering for challenging real-world scenes. To address these issues, we present HyperReel -- a novel 6-DoF video representation. The two core components of HyperReel are: (1) a ray-conditioned sample prediction network that enables high-fidelity, high frame rate rendering at high resolutions and (2) a compact and memory efficient dynamic volume representation. Our 6-DoF video pipeline achieves the best performance compared to prior and contemporary approaches in terms of visual quality with small memory requirements, while also rendering at up to 18 frames-per-second at megapixel resolution without any custom CUDA code.
The necessity of depth for artificial neural networks to approximate certain classes of smooth and bounded functions without the curse of dimensionality
Jan 19, 2023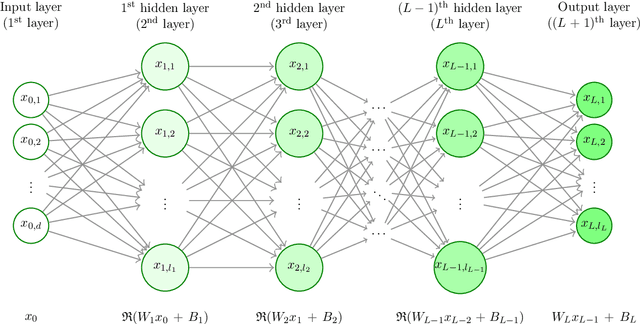
In this article we study high-dimensional approximation capacities of shallow and deep artificial neural networks (ANNs) with the rectified linear unit (ReLU) activation. In particular, it is a key contribution of this work to reveal that for all $a,b\in\mathbb{R}$ with $b-a\geq 7$ we have that the functions $[a,b]^d\ni x=(x_1,\dots,x_d)\mapsto\prod_{i=1}^d x_i\in\mathbb{R}$ for $d\in\mathbb{N}$ as well as the functions $[a,b]^d\ni x =(x_1,\dots, x_d)\mapsto\sin(\prod_{i=1}^d x_i) \in \mathbb{R} $ for $ d \in \mathbb{N} $ can neither be approximated without the curse of dimensionality by means of shallow ANNs nor insufficiently deep ANNs with ReLU activation but can be approximated without the curse of dimensionality by sufficiently deep ANNs with ReLU activation. We show that the product functions and the sine of the product functions are polynomially tractable approximation problems among the approximating class of deep ReLU ANNs with the number of hidden layers being allowed to grow in the dimension $ d \in \mathbb{N} $. We establish the above outlined statements not only for the product functions and the sine of the product functions but also for other classes of target functions, in particular, for classes of uniformly globally bounded $ C^{ \infty } $-functions with compact support on any $[a,b]^d$ with $a\in\mathbb{R}$, $b\in(a,\infty)$. Roughly speaking, in this work we lay open that simple approximation problems such as approximating the sine or cosine of products cannot be solved in standard implementation frameworks by shallow or insufficiently deep ANNs with ReLU activation in polynomial time, but can be approximated by sufficiently deep ReLU ANNs with the number of parameters growing at most polynomially.
Co-manipulation of soft-materials estimating deformation from depth images
Jan 13, 2023

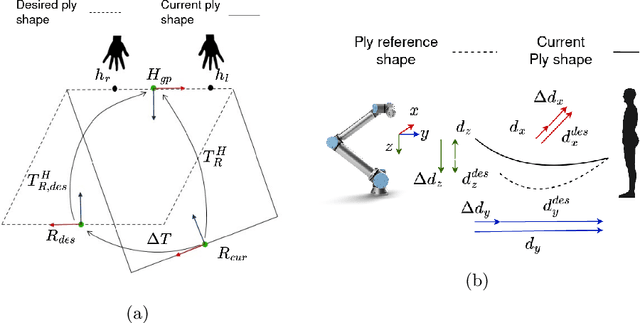
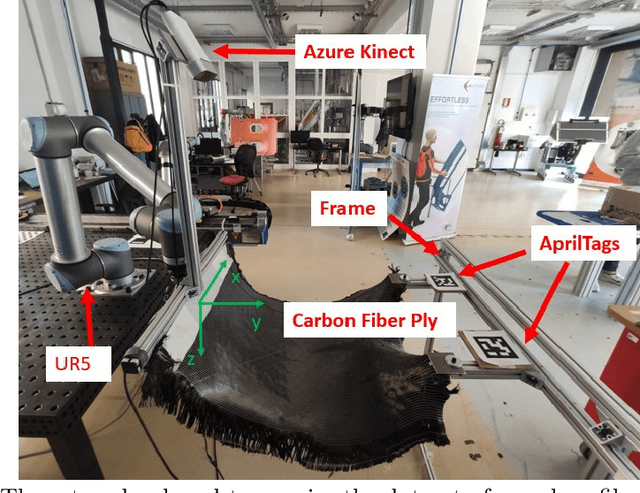
Human-robot co-manipulation of soft materials, such as fabrics, composites, and sheets of paper/cardboard, is a challenging operation that presents several relevant industrial applications. Estimating the deformation state of the co-manipulated material is one of the main challenges. Viable methods provide the indirect measure by calculating the human-robot relative distance. In this paper, we develop a data-driven model to estimate the deformation state of the material from a depth image through a Convolutional Neural Network (CNN). First, we define the deformation state of the material as the relative roto-translation from the current robot pose and a human grasping position. The model estimates the current deformation state through a Convolutional Neural Network, specifically a DenseNet-121 pretrained on ImageNet.The delta between the current and the desired deformation state is fed to the robot controller that outputs twist commands. The paper describes the developed approach to acquire, preprocess the dataset and train the model. The model is compared with the current state-of-the-art method based on a skeletal tracker from cameras. Results show that our approach achieves better performances and avoids the various drawbacks caused by using a skeletal tracker.Finally, we also studied the model performance according to different architectures and dataset dimensions to minimize the time required for dataset acquisition
Pylon: Semantic Table Union Search in Data Lakes
Jan 13, 2023
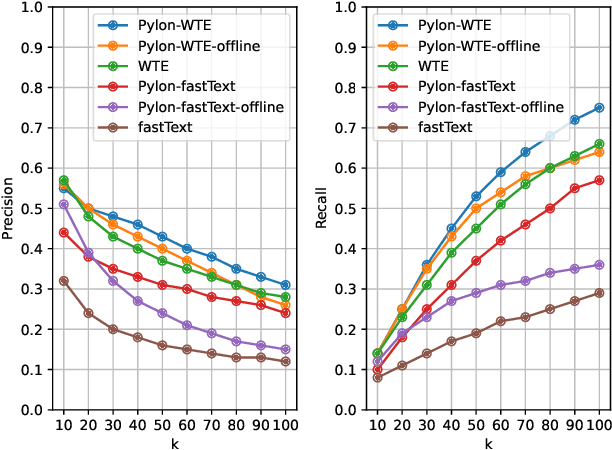
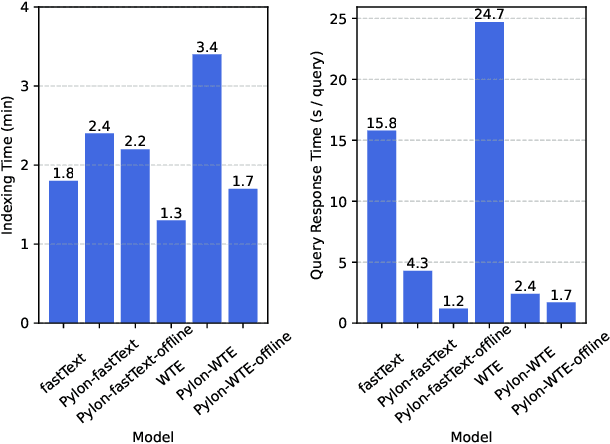
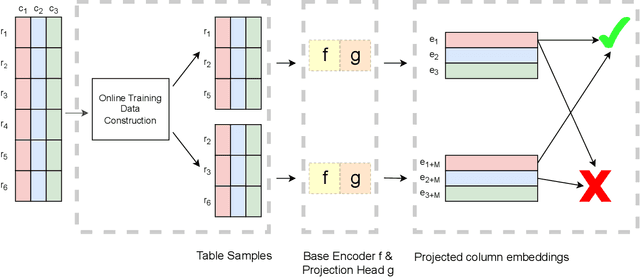
The large size and fast growth of data repositories, such as data lakes, has spurred the need for data discovery to help analysts find related data. The problem has become challenging as (i) a user typically does not know what datasets exist in an enormous data repository; and (ii) there is usually a lack of a unified data model to capture the interrelationships between heterogeneous datasets from disparate sources. In this work, we address one important class of discovery needs: finding union-able tables. The task is to find tables in a data lake that can be unioned with a given query table. The challenge is to recognize union-able columns even if they are represented differently. In this paper, we propose a data-driven learning approach: specifically, an unsupervised representation learning and embedding retrieval task. Our key idea is to exploit self-supervised contrastive learning to learn an embedding model that takes into account the indexing/search data structure and produces embeddings close by for columns with semantically similar values while pushing apart columns with semantically dissimilar values. We then find union-able tables based on similarities between their constituent columns in embedding space. On a real-world data lake, we demonstrate that our best-performing model achieves significant improvements in precision ($16\% \uparrow$), recall ($17\% \uparrow $), and query response time (7x faster) compared to the state-of-the-art.
Observational and Interventional Causal Learning for Regret-Minimizing Control
Dec 05, 2022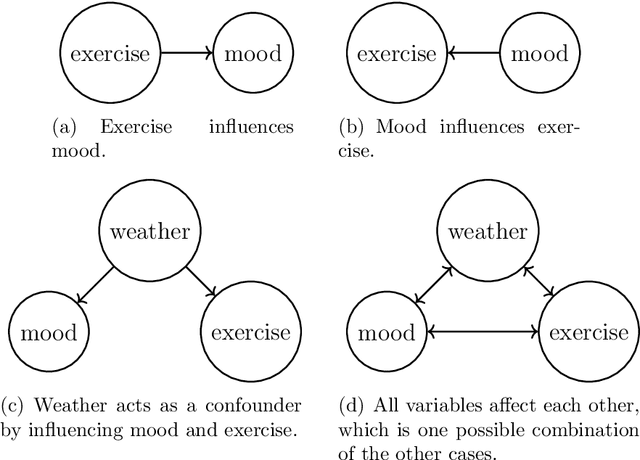


We explore how observational and interventional causal discovery methods can be combined. A state-of-the-art observational causal discovery algorithm for time series capable of handling latent confounders and contemporaneous effects, called LPCMCI, is extended to profit from casual constraints found through randomized control trials. Numerical results show that, given perfect interventional constraints, the reconstructed structural causal models (SCMs) of the extended LPCMCI allow 84.6% of the time for the optimal prediction of the target variable. The implementation of interventional and observational causal discovery is modular, allowing causal constraints from other sources. The second part of this thesis investigates the question of regret minimizing control by simultaneously learning a causal model and planning actions through the causal model. The idea is that an agent to optimize a measured variable first learns the system's mechanics through observational causal discovery. The agent then intervenes on the most promising variable with randomized values allowing for the exploitation and generation of new interventional data. The agent then uses the interventional data to enhance the causal model further, allowing improved actions the next time. The extended LPCMCI can be favorable compared to the original LPCMCI algorithm. The numerical results show that detecting and using interventional constraints leads to reconstructed SCMs that allow 60.9% of the time for the optimal prediction of the target variable in contrast to the baseline of 53.6% when using the original LPCMCI algorithm. Furthermore, the induced average regret decreases from 1.2 when using the original LPCMCI algorithm to 1.0 when using the extended LPCMCI algorithm with interventional discovery.
Timestomping Vulnerability of Age-Sensitive Gossip Networks
Dec 29, 2022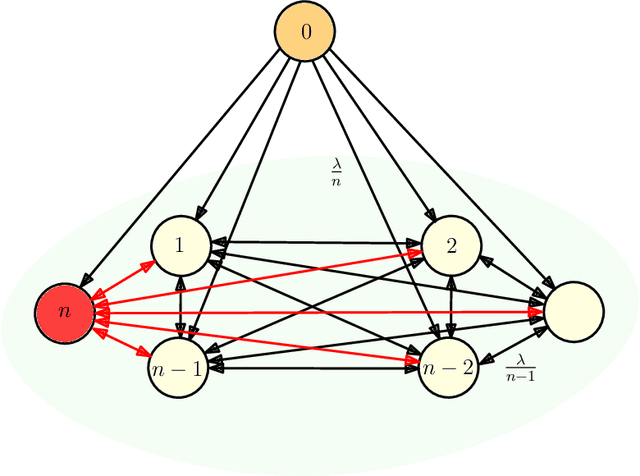
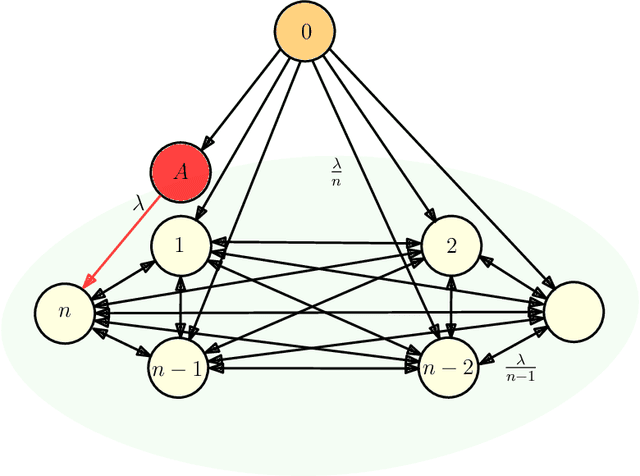
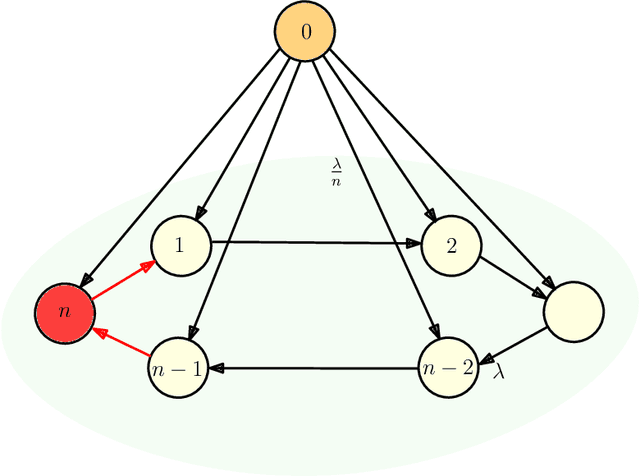
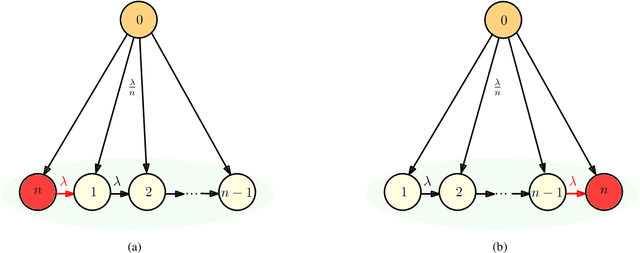
We consider gossip networks consisting of a source that maintains the current version of a file, $n$ nodes that use asynchronous gossip mechanisms to disseminate fresh information in the network, and an oblivious adversary who infects the packets at a target node through data timestamp manipulation, with the intent to replace circulation of fresh packets with outdated packets in the network. We demonstrate how network topology capacitates an adversary to influence age scaling in a network. We show that in a fully connected network, a single infected node increases the expected age from $O(\log n)$ to $O(n)$. Further, we show that the optimal behavior for an adversary is to reset the timestamps of all outgoing packets to the current time and of all incoming packets to an outdated time for the infected node; thereby preventing any fresh information to go into the infected node, and facilitating acceptance of stale information out of the infected node into other network nodes. Lastly for fully connected network, we show that if an infected node contacts only a single node instead of all nodes of the network, the system age can still be degraded to $O(n)$. These show that fully connected nature of a network can be both a benefit and a detriment for information freshness; full connectivity, while enabling fast dissemination of information, also enables fast dissipation of adversarial inputs. We then analyze the unidirectional ring network, the other end of the network connectivity spectrum, where we show that the adversarial effect on age scaling of a node is limited by its distance from the adversary, and the age scaling for a large fraction of the network continues to be $O(\sqrt{n})$, unchanged from the case with no adversary. We finally support our findings with simulations.