 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving a sequence-to-sequence nlp model using a reinforcement learning policy algorithm
Dec 28, 2022
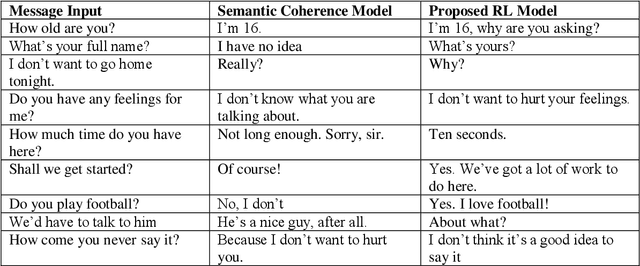


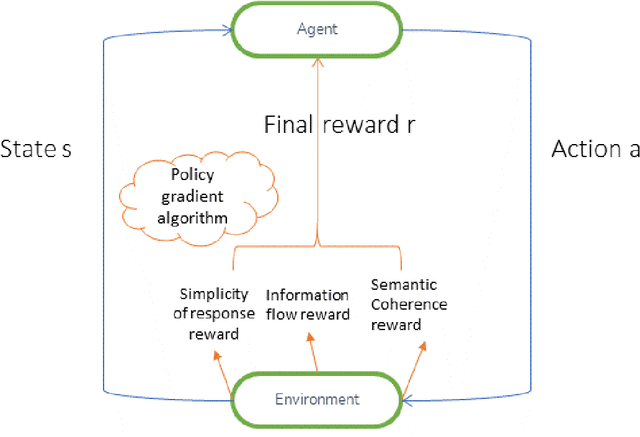
Nowadays, the current neural network models of dialogue generation(chatbots) show great promise for generating answers for chatty agents. But they are short-sighted in that they predict utterances one at a time while disregarding their impact on future outcomes. Modelling a dialogue's future direction is critical for generating coherent, interesting dialogues, a need that has led traditional NLP dialogue models that rely on reinforcement learning. In this article, we explain how to combine these objectives by using deep reinforcement learning to predict future rewards in chatbot dialogue. The model simulates conversations between two virtual agents, with policy gradient methods used to reward sequences that exhibit three useful conversational characteristics: the flow of informality, coherence, and simplicity of response (related to forward-looking function). We assess our model based on its diversity, length, and complexity with regard to humans. In dialogue simulation, evaluations demonstrated that the proposed model generates more interactive responses and encourages a more sustained successful conversation. This work commemorates a preliminary step toward developing a neural conversational model based on the long-term success of dialogues.
* Published in Proceedings of Artificial Intelligence, Soft Computing and Applications 12th International Conference on Artificial Intelligence, Soft Computing and Applications (AIAA 2022) December 22 ~ 24, 2022, Sydney, Australia Volume Editors : David C. Wyld, Dhinaharan Nagamalai (Eds) ISBN : 978-1-925953-83-1
Robustifying Markowitz
Dec 28, 2022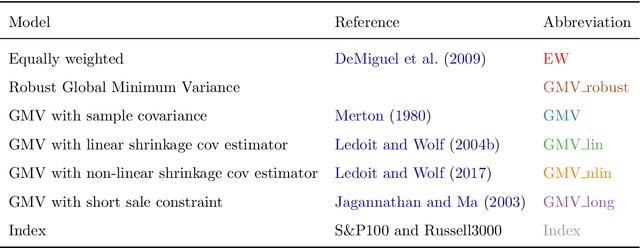
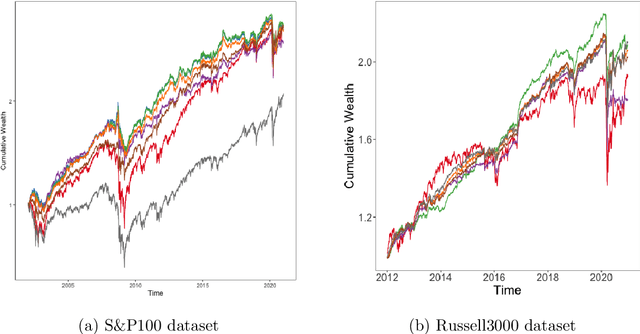
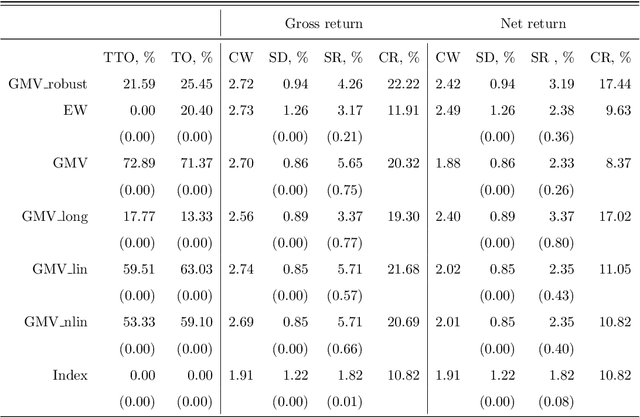
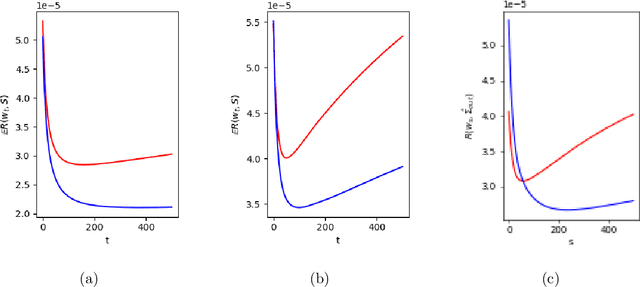
Markowitz mean-variance portfolios with sample mean and covariance as input parameters feature numerous issues in practice. They perform poorly out of sample due to estimation error, they experience extreme weights together with high sensitivity to change in input parameters. The heavy-tail characteristics of financial time series are in fact the cause for these erratic fluctuations of weights that consequently create substantial transaction costs. In robustifying the weights we present a toolbox for stabilizing costs and weights for global minimum Markowitz portfolios. Utilizing a projected gradient descent (PGD) technique, we avoid the estimation and inversion of the covariance operator as a whole and concentrate on robust estimation of the gradient descent increment. Using modern tools of robust statistics we construct a computationally efficient estimator with almost Gaussian properties based on median-of-means uniformly over weights. This robustified Markowitz approach is confirmed by empirical studies on equity markets. We demonstrate that robustified portfolios reach the lowest turnover compared to shrinkage-based and constrained portfolios while preserving or slightly improving out-of-sample performance.
Coordination of Drones at Scale: Decentralized Energy-aware Swarm Intelligence for Spatio-temporal Sensing
Dec 28, 2022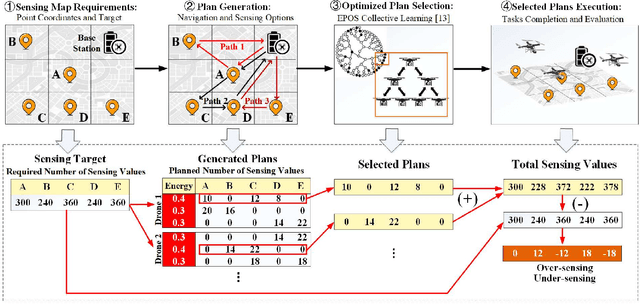
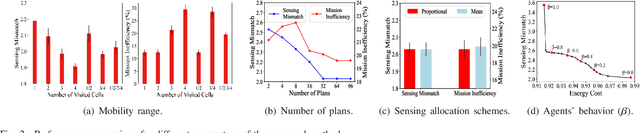
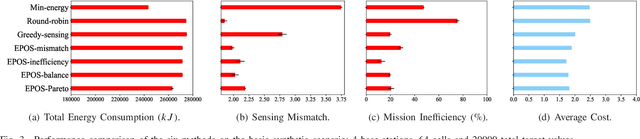
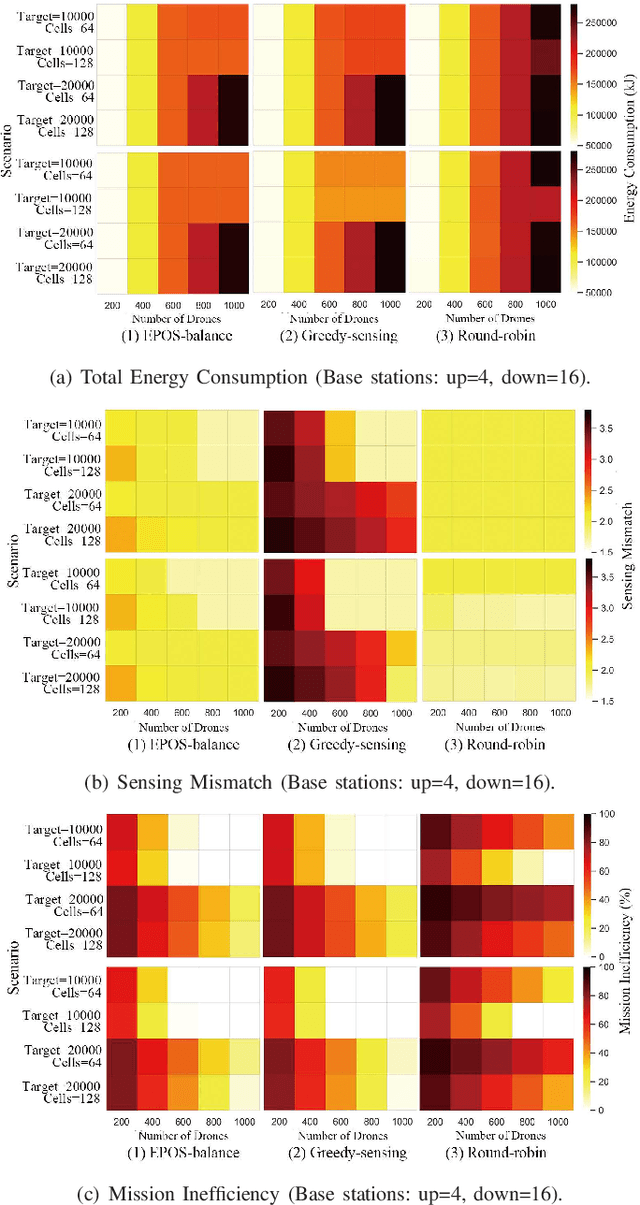
Smart City applications, such as traffic monitoring and disaster response, often use swarms of intelligent and cooperative drones to efficiently collect sensor data over different areas of interest and time spans. However, when the required sensing becomes spatio-temporally large and varying, a collective arrangement of sensing tasks to a large number of battery-restricted and distributed drones is challenging. To address this problem, we introduce a scalable and energy-aware model for planning and coordination of spatio-temporal sensing. The coordination model is built upon a decentralized multi-agent collective learning algorithm (EPOS) to ensure scalability, resilience, and flexibility that existing approaches lack of. Experimental results illustrate the outstanding performance of the proposed method compared to state-of-the-art methods. Analytical results contribute a deeper understanding of how coordinated mobility of drones influences sensing performance. This novel coordination solution is applied to traffic monitoring using real-world data to demonstrate a $46.45\%$ more accurate and $2.88\%$ more efficient detection of vehicles as the number of drones become a scarce resource.
Reconfigurable Holographic Surface: A New Paradigm to Implement Holographic Radio
Dec 28, 2022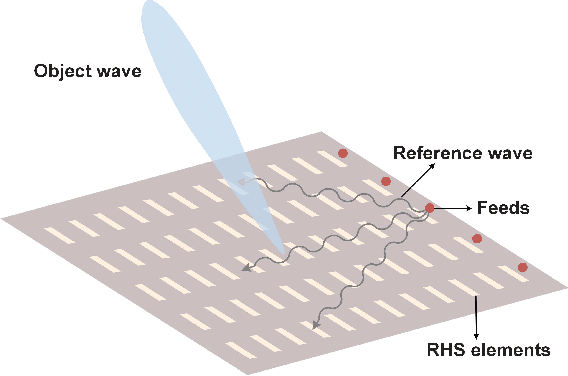
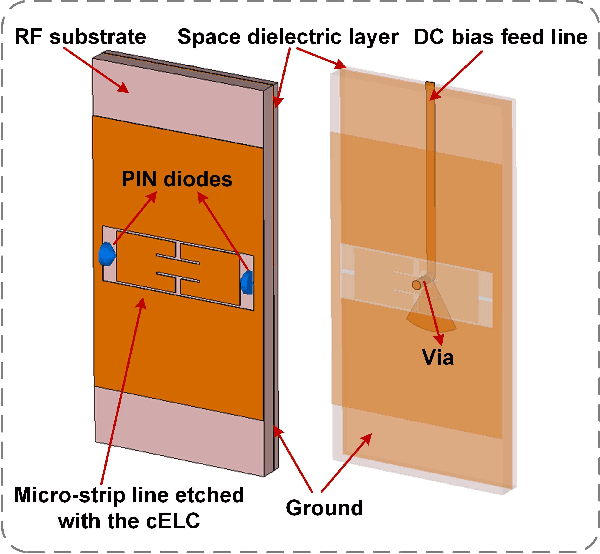
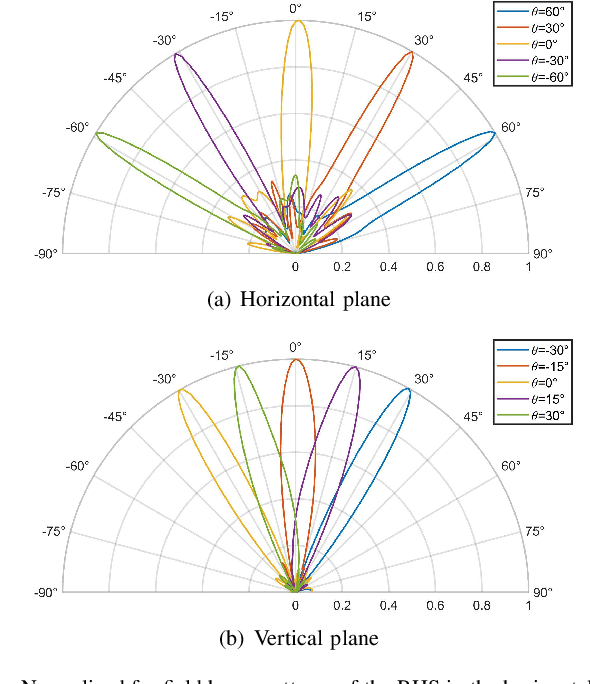
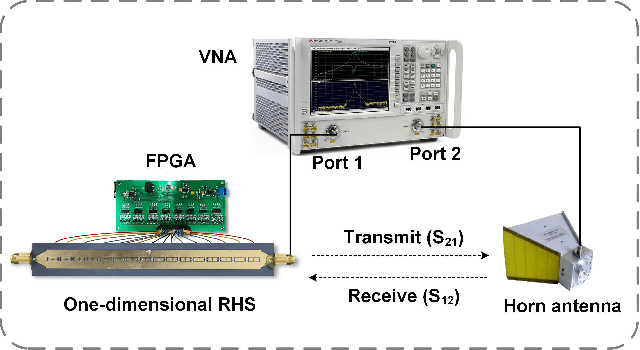
Ultra-massive multiple-input multiple-output (MIMO) is one of the key enablers in the forthcoming 6G networks to provide high-speed data services by exploiting spatial diversity. In this article, we consider a new paradigm termed holographic radio for ultra-massive MIMO, where numerous tiny and inexpensive antenna elements are integrated to realize high directive gain with low hardware cost. We propose a practical way to enable holographic radio by a novel metasurface-based antenna, i.e., reconfigurable holographic surface (RHS). Specifically, RHSs incorporating densely packed tunable metamaterial elements are capable of holographic beamforming. Based on the working principle and hardware design of RHSs, we conduct full-wave analyses of RHSs and build an RHS-aided point-to-point communication platform supporting real-time data transmission. Both simulated and experimental results show that the RHS has great potential to achieve high directive gain with a limited size, thereby substantiating the feasibility of RHS-enabled holographic radio. Moreover, future research directions for RHS-enabled holographic radio are also discussed.
Quantum-Inspired Tensor Neural Networks for Option Pricing
Dec 28, 2022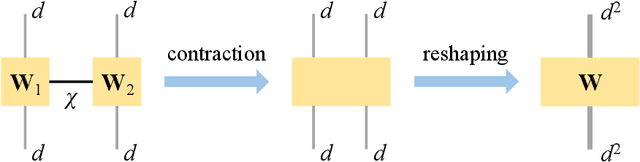
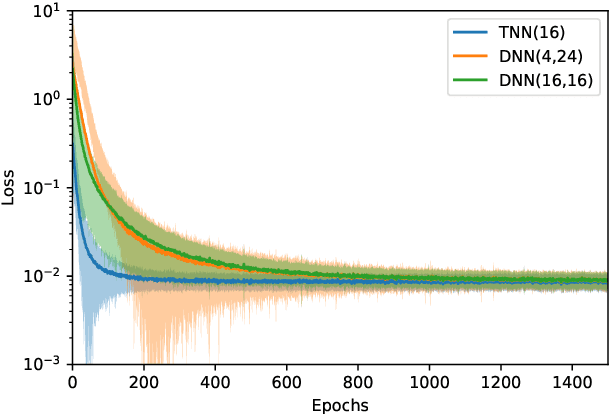
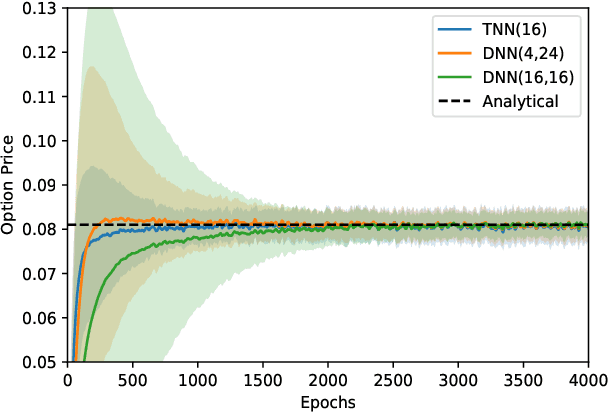
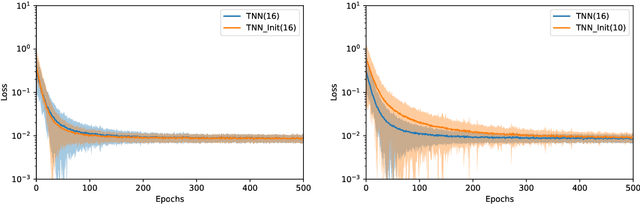
Recent advances in deep learning have enabled us to address the curse of dimensionality (COD) by solving problems in higher dimensions. A subset of such approaches of addressing the COD has led us to solving high-dimensional PDEs. This has resulted in opening doors to solving a variety of real-world problems ranging from mathematical finance to stochastic control for industrial applications. Although feasible, these deep learning methods are still constrained by training time and memory. Tackling these shortcomings, Tensor Neural Networks (TNN) demonstrate that they can provide significant parameter savings while attaining the same accuracy as compared to the classical Dense Neural Network (DNN). In addition, we also show how TNN can be trained faster than DNN for the same accuracy. Besides TNN, we also introduce Tensor Network Initializer (TNN Init), a weight initialization scheme that leads to faster convergence with smaller variance for an equivalent parameter count as compared to a DNN. We benchmark TNN and TNN Init by applying them to solve the parabolic PDE associated with the Heston model, which is widely used in financial pricing theory.
Parameterization of state duration in Hidden semi-Markov Models: an application in electrocardiography
Nov 17, 2022
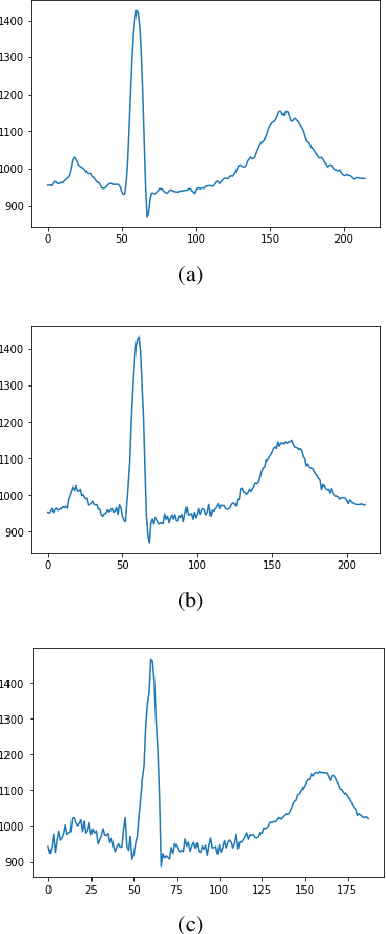
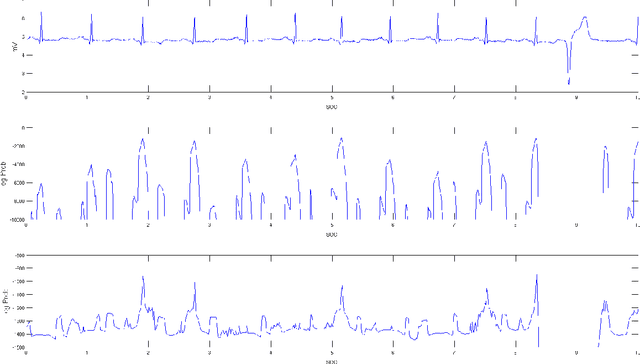
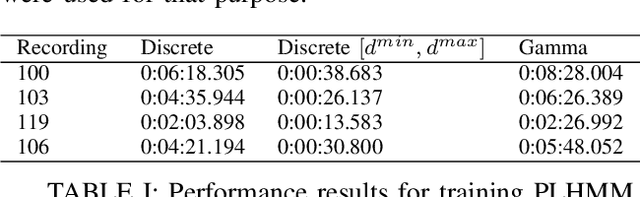
This work aims at providing a new model for time series classification based on learning from just one example. We assume that time series can be well characterized as a parametric random process, a sort of Hidden semi-Markov Model representing a sequence of regression models with variable duration. We introduce a parametric stochastic model for time series pattern recognition and provide a maximum-likelihood estimation of its parameters. Particularly, we are interested in examining two different representations for state duration: i) a discrete density distribution requiring an estimate for each possible duration; and ii) a parametric family of continuous density functions, here the Gamma distribution, with just two parameters to estimate. An application on heartbeat classification reveals the main strengths and weaknesses of each alternative.
Do Performance Aspirations Matter for Guiding Software Configuration Tuning?
Jan 09, 2023
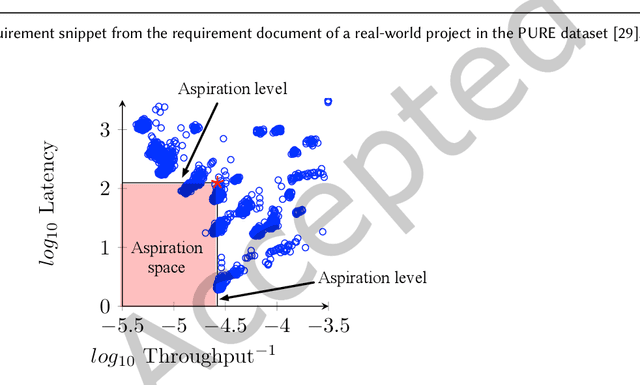

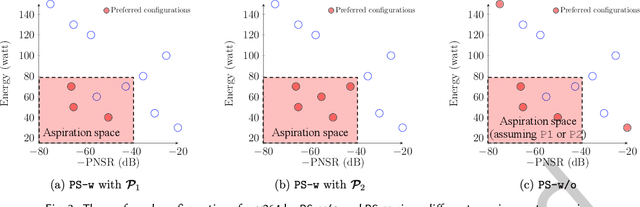
Configurable software systems can be tuned for better performance. Leveraging on some Pareto optimizers, recent work has shifted from tuning for a single, time-related performance objective to two intrinsically different objectives that assess distinct performance aspects of the system, each with varying aspirations. Before we design better optimizers, a crucial engineering decision to make therein is how to handle the performance requirements with clear aspirations in the tuning process. For this, the community takes two alternative optimization models: either quantifying and incorporating the aspirations into the search objectives that guide the tuning, or not considering the aspirations during the search but purely using them in the later decision-making process only. However, despite being a crucial decision that determines how an optimizer can be designed and tailored, there is a rather limited understanding of which optimization model should be chosen under what particular circumstance, and why. In this paper, we seek to close this gap. Firstly, we do that through a review of over 426 papers in the literature and 14 real-world requirements datasets. Drawing on these, we then conduct a comprehensive empirical study that covers 15 combinations of the state-of-the-art performance requirement patterns, four types of aspiration space, three Pareto optimizers, and eight real-world systems/environments, leading to 1,296 cases of investigation. We found that (1) the realism of aspirations is the key factor that determines whether they should be used to guide the tuning; (2) the given patterns and the position of the realistic aspirations in the objective landscape are less important for the choice, but they do matter to the extents of improvement; (3) the available tuning budget can also influence the choice for unrealistic aspirations but it is insignificant under realistic ones.
* This paper has been accepted by ACM Transactions on Software Engineering and Methodology (TOSEM)
A Search and Detection Autonomous Drone System: from Design to Implementation
Nov 29, 2022
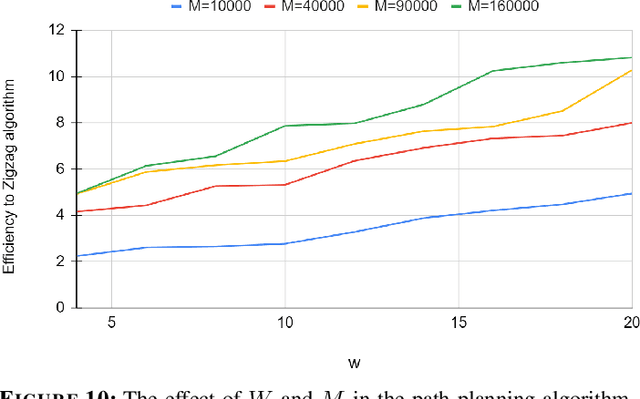
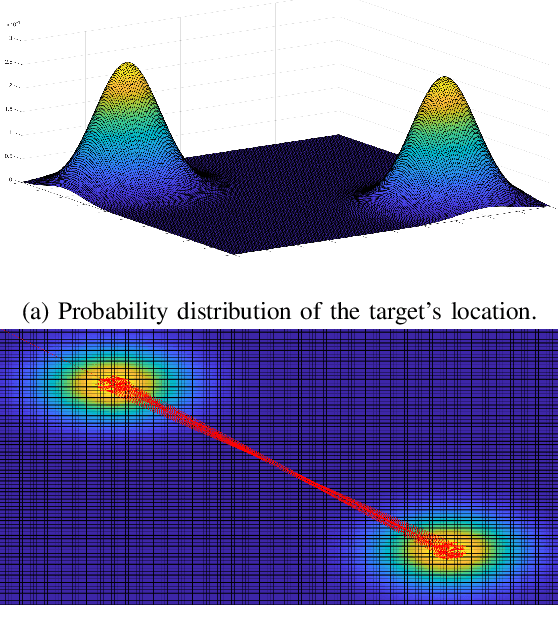

Utilizing autonomous drones or unmanned aerial vehicles (UAVs) has shown great advantages over preceding methods in support of urgent scenarios such as search and rescue (SAR) and wildfire detection. In these operations, search efficiency in terms of the amount of time spent to find the target is crucial since with the passing of time the survivability of the missing person decreases or wildfire management becomes more difficult with disastrous consequences. In this work, it is considered a scenario where a drone is intended to search and detect a missing person (e.g., a hiker or a mountaineer) or a potential fire spot in a given area. In order to obtain the shortest path to the target, a general framework is provided to model the problem of target detection when the target's location is probabilistically known. To this end, two algorithms are proposed: Path planning and target detection. The path planning algorithm is based on Bayesian inference and the target detection is accomplished by means of a residual neural network (ResNet) trained on the image dataset captured by the drone as well as existing pictures and datasets on the web. Through simulation and experiment, the proposed path planning algorithm is compared with two benchmark algorithms. It is shown that the proposed algorithm significantly decreases the average time of the mission.
Modeling Label Semantics Improves Activity Recognition
Jan 01, 2023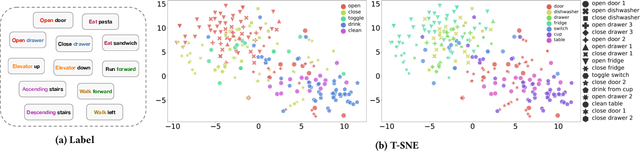

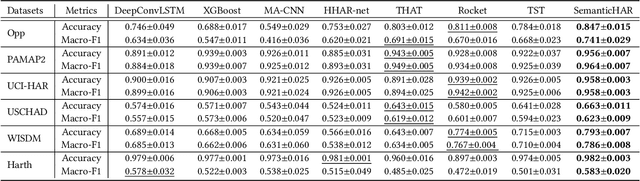
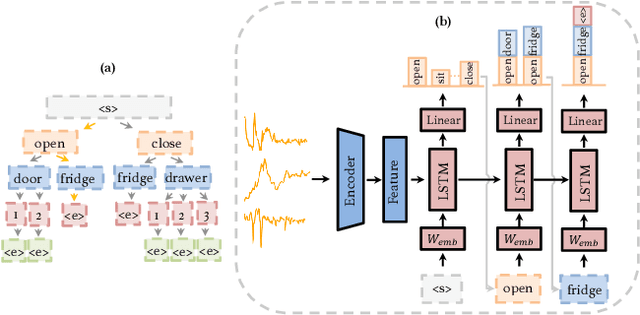
Human activity recognition (HAR) aims to classify sensory time series into different activities, with wide applications in activity tracking, healthcare, human computer interaction, etc. Existing HAR works improve recognition performance by designing more complicated feature extraction methods, but they neglect the label semantics by simply treating labels as integer IDs. We find that many activities in the current HAR datasets have shared label names, e.g., "open door" and "open fridge", "walk upstairs" and "walk downstairs". Through some exploratory analysis, we find that such shared structure in activity names also maps to similarity in the input features. To this end, we design a sequence-to-sequence framework to decode the label name semantics rather than classifying labels as integer IDs. Our proposed method decomposes learning activities into learning shared tokens ("open", "walk"), which is easier than learning the joint distribution ("open fridge", "walk upstairs") and helps transfer learning to activities with insufficient data samples. For datasets originally without shared tokens in label names, we also offer an automated method, using OpenAI's ChatGPT, to generate shared actions and objects. Extensive experiments on seven HAR benchmark datasets demonstrate the state-of-the-art performance of our method. We also show better performance in the long-tail activity distribution settings and few-shot settings.
A principled distributional approach to trajectory similarity measurement
Jan 01, 2023
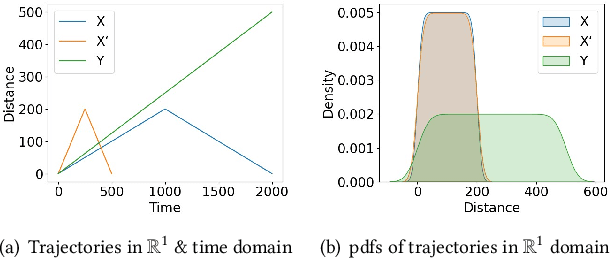


Existing measures and representations for trajectories have two longstanding fundamental shortcomings, i.e., they are computationally expensive and they can not guarantee the `uniqueness' property of a distance function: dist(X,Y) = 0 if and only if X=Y, where $X$ and $Y$ are two trajectories. This paper proposes a simple yet powerful way to represent trajectories and measure the similarity between two trajectories using a distributional kernel to address these shortcomings. It is a principled approach based on kernel mean embedding which has a strong theoretical underpinning. It has three distinctive features in comparison with existing approaches. (1) A distributional kernel is used for the very first time for trajectory representation and similarity measurement. (2) It does not rely on point-to-point distances which are used in most existing distances for trajectories. (3) It requires no learning, unlike existing learning and deep learning approaches. We show the generality of this new approach in three applications: (a) trajectory anomaly detection, (b) anomalous sub-trajectory detection, and (c) trajectory pattern mining. We identify that the distributional kernel has (i) a unique data-dependent property and the above uniqueness property which are the key factors that lead to its superior task-specific performance; and (ii) runtime orders of magnitude faster than existing distance measures.