 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reconfigurable Holographic Surface: A New Paradigm to Implement Holographic Radio
Dec 28, 2022
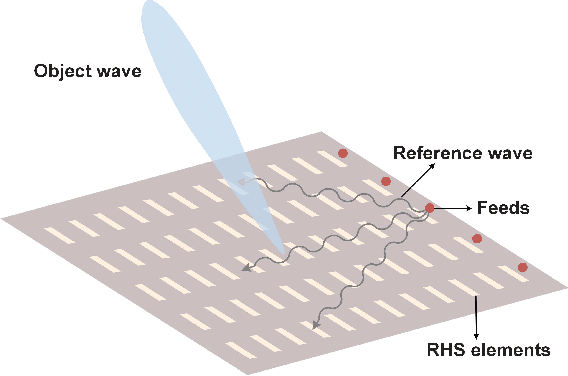
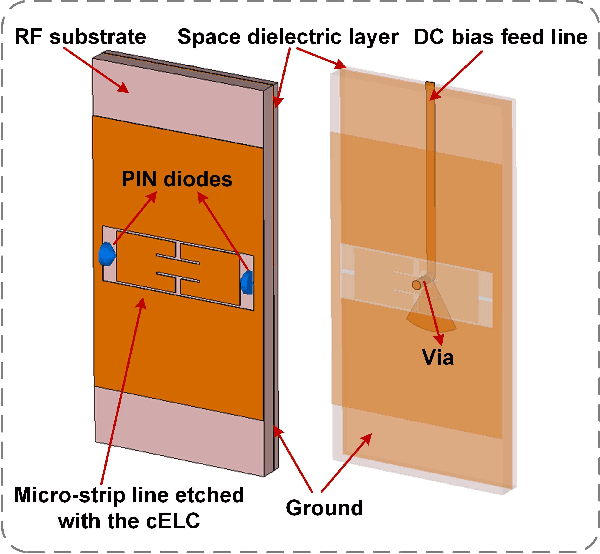
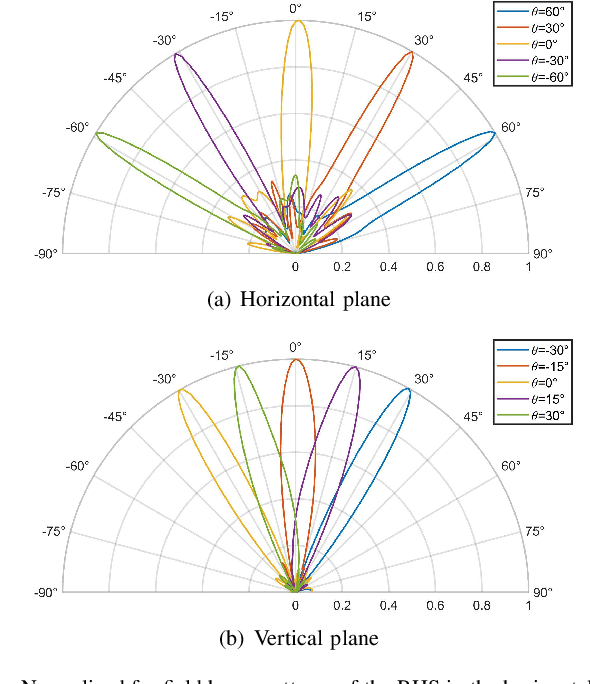
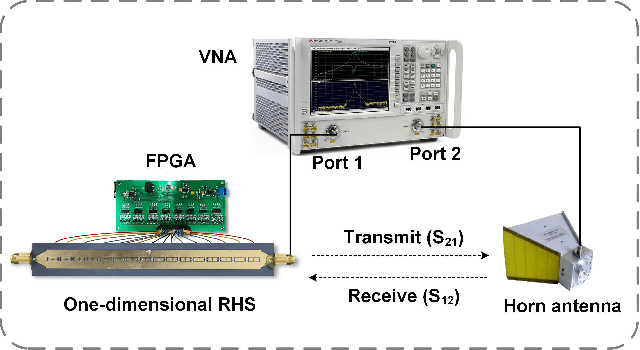
Ultra-massive multiple-input multiple-output (MIMO) is one of the key enablers in the forthcoming 6G networks to provide high-speed data services by exploiting spatial diversity. In this article, we consider a new paradigm termed holographic radio for ultra-massive MIMO, where numerous tiny and inexpensive antenna elements are integrated to realize high directive gain with low hardware cost. We propose a practical way to enable holographic radio by a novel metasurface-based antenna, i.e., reconfigurable holographic surface (RHS). Specifically, RHSs incorporating densely packed tunable metamaterial elements are capable of holographic beamforming. Based on the working principle and hardware design of RHSs, we conduct full-wave analyses of RHSs and build an RHS-aided point-to-point communication platform supporting real-time data transmission. Both simulated and experimental results show that the RHS has great potential to achieve high directive gain with a limited size, thereby substantiating the feasibility of RHS-enabled holographic radio. Moreover, future research directions for RHS-enabled holographic radio are also discussed.
Quantum-Inspired Tensor Neural Networks for Option Pricing
Dec 28, 2022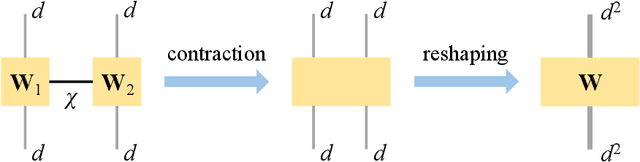
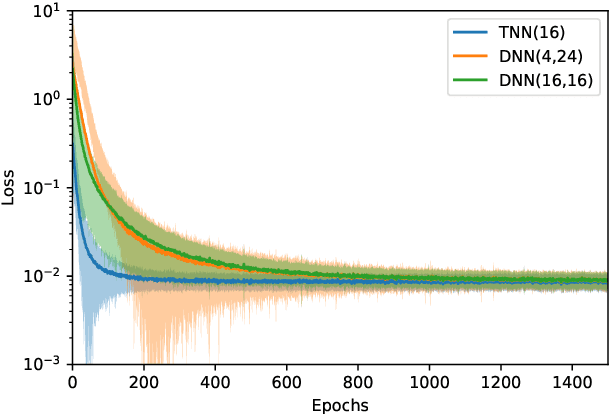
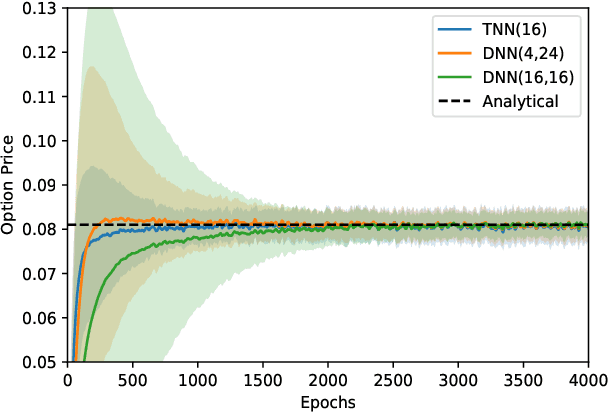
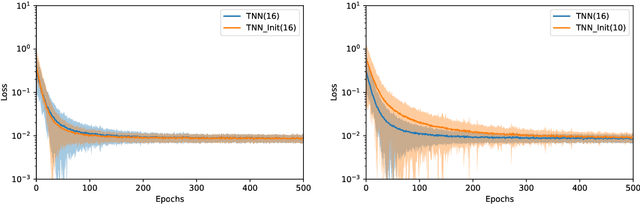
Recent advances in deep learning have enabled us to address the curse of dimensionality (COD) by solving problems in higher dimensions. A subset of such approaches of addressing the COD has led us to solving high-dimensional PDEs. This has resulted in opening doors to solving a variety of real-world problems ranging from mathematical finance to stochastic control for industrial applications. Although feasible, these deep learning methods are still constrained by training time and memory. Tackling these shortcomings, Tensor Neural Networks (TNN) demonstrate that they can provide significant parameter savings while attaining the same accuracy as compared to the classical Dense Neural Network (DNN). In addition, we also show how TNN can be trained faster than DNN for the same accuracy. Besides TNN, we also introduce Tensor Network Initializer (TNN Init), a weight initialization scheme that leads to faster convergence with smaller variance for an equivalent parameter count as compared to a DNN. We benchmark TNN and TNN Init by applying them to solve the parabolic PDE associated with the Heston model, which is widely used in financial pricing theory.
Automated Segmentation of Computed Tomography Images with Submanifold Sparse Convolutional Networks
Dec 06, 2022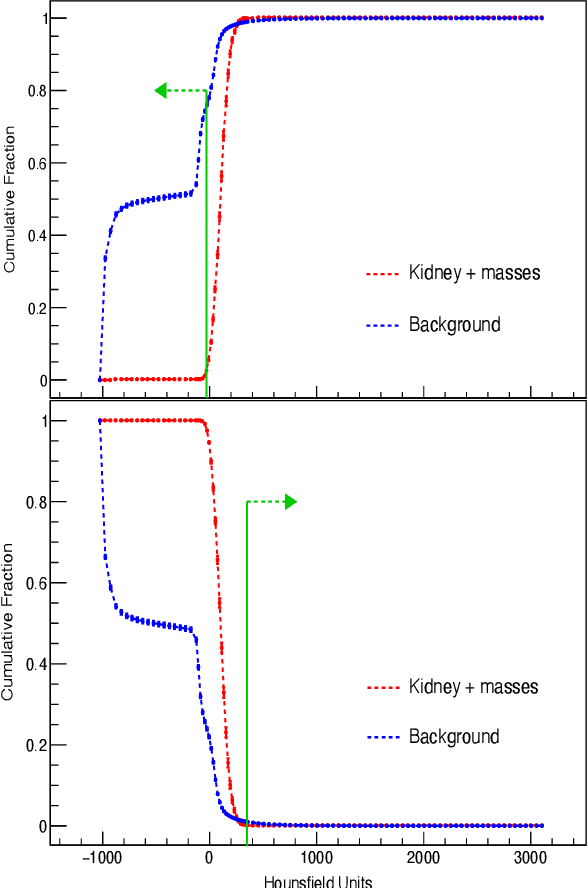
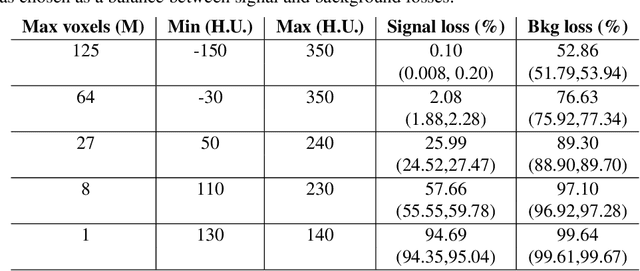
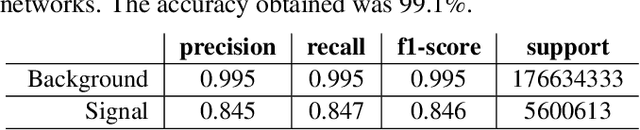
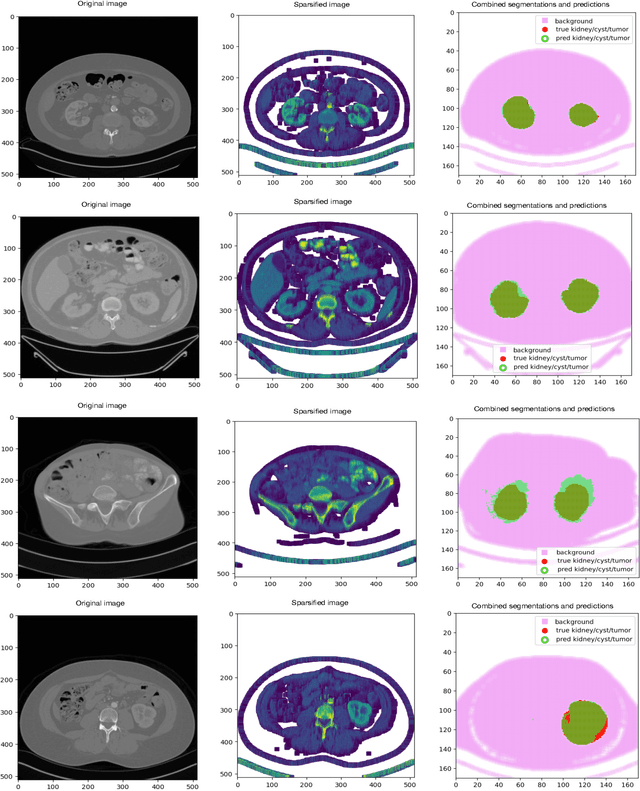
Quantitative cancer image analysis relies on the accurate delineation of tumours, a very specialised and time-consuming task. For this reason, methods for automated segmentation of tumours in medical imaging have been extensively developed in recent years, being Computed Tomography one of the most popular imaging modalities explored. However, the large amount of 3D voxels in a typical scan is prohibitive for the entire volume to be analysed at once in conventional hardware. To overcome this issue, the processes of downsampling and/or resampling are generally implemented when using traditional convolutional neural networks in medical imaging. In this paper, we propose a new methodology that introduces a process of sparsification of the input images and submanifold sparse convolutional networks as an alternative to downsampling. As a proof of concept, we applied this new methodology to Computed Tomography images of renal cancer patients, obtaining performances of segmentations of kidneys and tumours competitive with previous methods (~84.6% Dice similarity coefficient), while achieving a significant improvement in computation time (2-3 min per training epoch).
Safe Imitation Learning of Nonlinear Model Predictive Control for Flexible Robots
Dec 06, 2022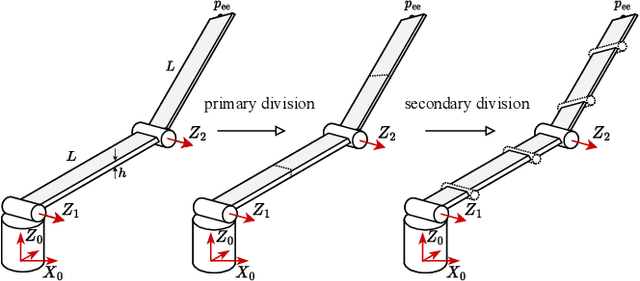
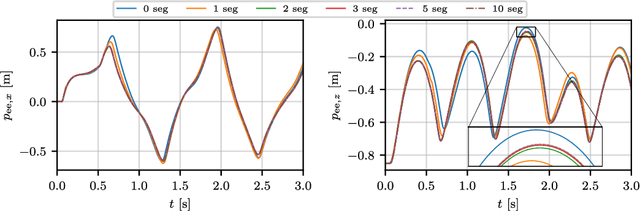
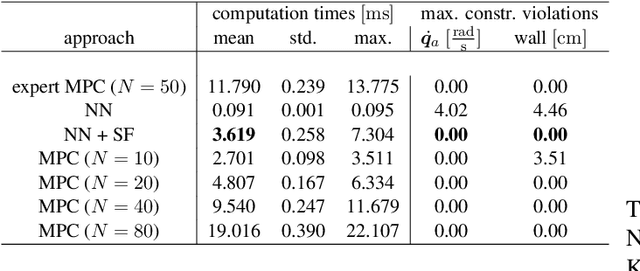
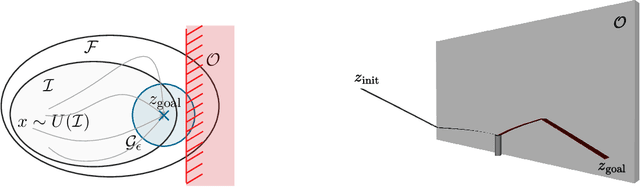
Flexible robots may overcome the industry's major problems: safe human-robot collaboration and increased load-to-mass ratio. However, oscillations and high dimensional state space complicate the control of flexible robots. This work investigates nonlinear model predictive control (NMPC) of flexible robots -- for simultaneous planning and control -- modeled via the rigid finite element method. Although NMPC performs well in simulation, computational complexity prevents its deployment in practice. We show that imitation learning of NMPC with neural networks as function approximator can massively improve the computation time of the controller at the cost of slight performance loss and, more critically, loss of safety guarantees. We leverage a safety filter formulated as a simpler NMPC to recover safety guarantees. Experiments on a simulated three degrees of freedom flexible robot manipulator demonstrate that the average computational time of the proposed safe approximate NMPC controller is 3.6 ms while of the original NMPC is 11.8 ms. Fast and safe approximate NMPC might facilitate the industry's adoption of flexible robots and new solutions for similar problems, e.g., deformable object manipulation and soft robot control.
CNN-based Timing Synchronization for OFDM Systems Assisted by Initial Path Acquisition in Frequency Selective Fading Channel
Dec 06, 2022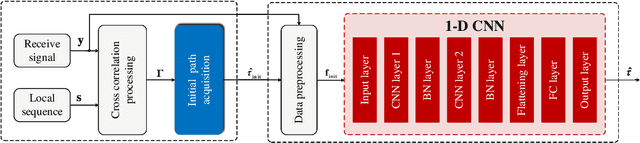
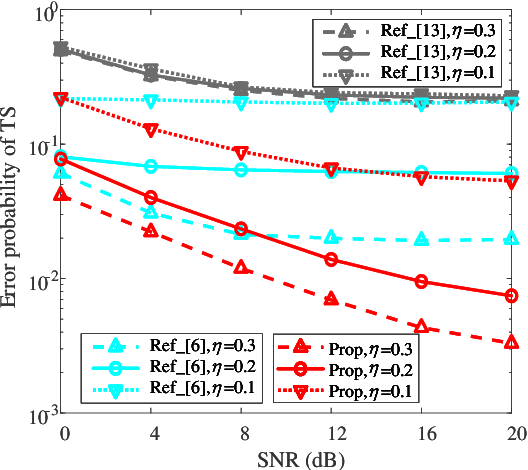
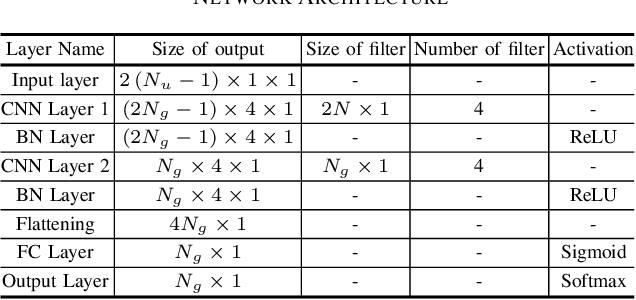
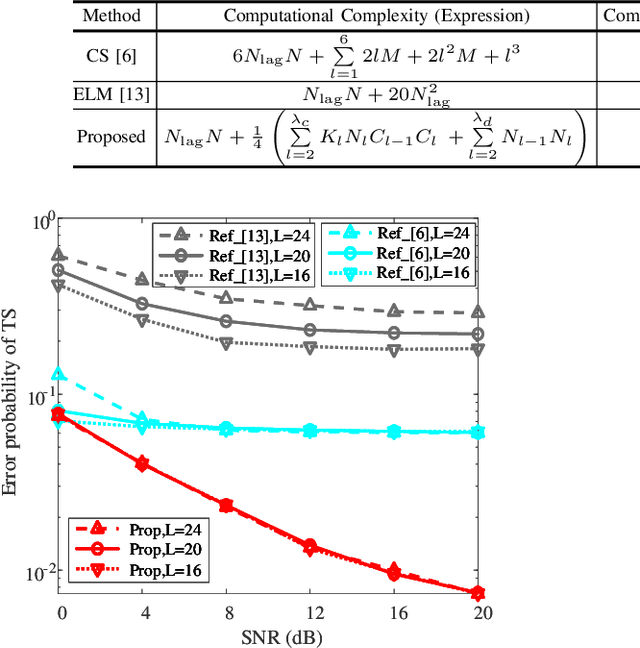
Multi-path fading seriously affects the accuracy of timing synchronization (TS) in orthogonal frequency division multiplexing (OFDM) systems. To tackle this issue, we propose a convolutional neural network (CNN)-based TS scheme assisted by initial path acquisition in this paper. Specifically, the classic cross-correlation method is first employed to estimate a coarse timing offset and capture an initial path, which shrinks the TS search region. Then, a one-dimensional (1-D) CNN is developed to optimize the TS of OFDM systems. Due to the narrowed search region of TS, the CNN-based TS effectively locates the accurate TS point and inspires us to construct a lightweight network in terms of computational complexity and online running time. Compared with the compressed sensing-based TS method and extreme learning machine-based TS method, simulation results show that the proposed method can effectively improve the TS performance with the reduced computational complexity and online running time. Besides, the proposed TS method presents robustness against the variant parameters of multi-path fading channels.
Object State Change Classification in Egocentric Videos using the Divided Space-Time Attention Mechanism
Jul 24, 2022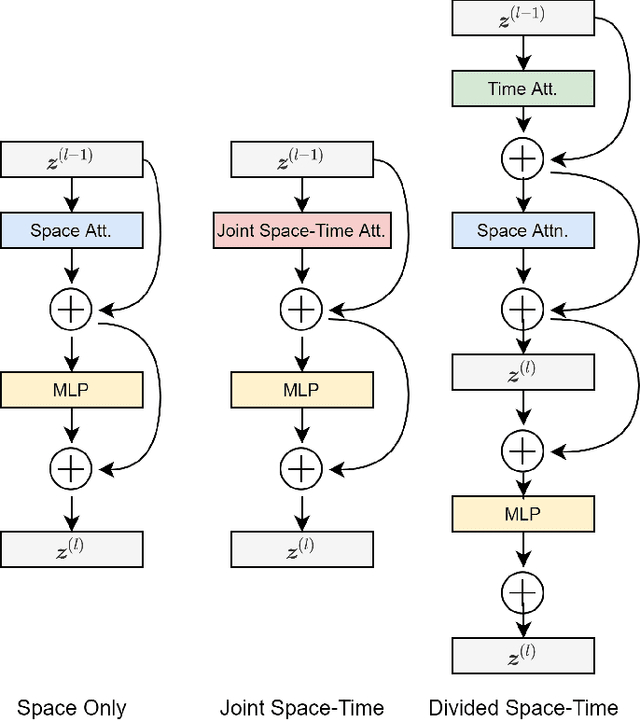
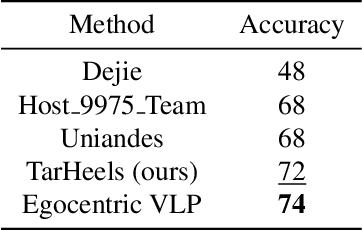
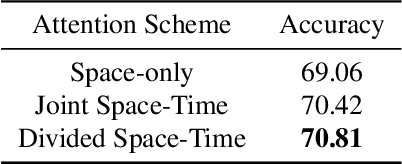

This report describes our submission called "TarHeels" for the Ego4D: Object State Change Classification Challenge. We use a transformer-based video recognition model and leverage the Divided Space-Time Attention mechanism for classifying object state change in egocentric videos. Our submission achieves the second-best performance in the challenge. Furthermore, we perform an ablation study to show that identifying object state change in egocentric videos requires temporal modeling ability. Lastly, we present several positive and negative examples to visualize our model's predictions. The code is publicly available at: https://github.com/md-mohaiminul/ObjectStateChange
Modeling Label Semantics Improves Activity Recognition
Jan 01, 2023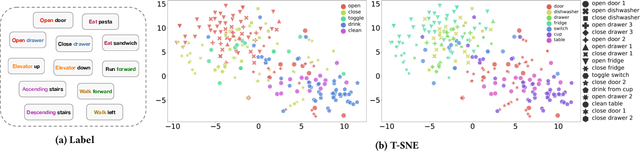

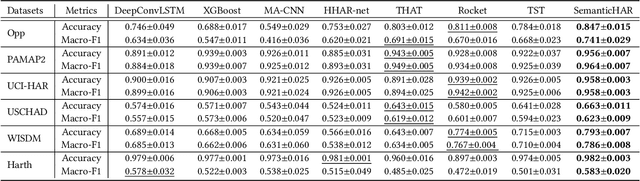
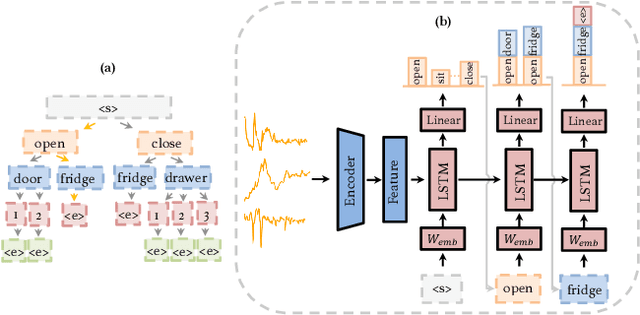
Human activity recognition (HAR) aims to classify sensory time series into different activities, with wide applications in activity tracking, healthcare, human computer interaction, etc. Existing HAR works improve recognition performance by designing more complicated feature extraction methods, but they neglect the label semantics by simply treating labels as integer IDs. We find that many activities in the current HAR datasets have shared label names, e.g., "open door" and "open fridge", "walk upstairs" and "walk downstairs". Through some exploratory analysis, we find that such shared structure in activity names also maps to similarity in the input features. To this end, we design a sequence-to-sequence framework to decode the label name semantics rather than classifying labels as integer IDs. Our proposed method decomposes learning activities into learning shared tokens ("open", "walk"), which is easier than learning the joint distribution ("open fridge", "walk upstairs") and helps transfer learning to activities with insufficient data samples. For datasets originally without shared tokens in label names, we also offer an automated method, using OpenAI's ChatGPT, to generate shared actions and objects. Extensive experiments on seven HAR benchmark datasets demonstrate the state-of-the-art performance of our method. We also show better performance in the long-tail activity distribution settings and few-shot settings.
A principled distributional approach to trajectory similarity measurement
Jan 01, 2023
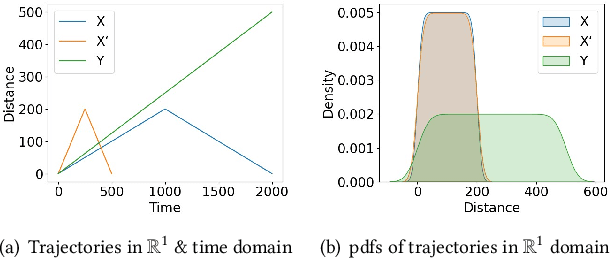


Existing measures and representations for trajectories have two longstanding fundamental shortcomings, i.e., they are computationally expensive and they can not guarantee the `uniqueness' property of a distance function: dist(X,Y) = 0 if and only if X=Y, where $X$ and $Y$ are two trajectories. This paper proposes a simple yet powerful way to represent trajectories and measure the similarity between two trajectories using a distributional kernel to address these shortcomings. It is a principled approach based on kernel mean embedding which has a strong theoretical underpinning. It has three distinctive features in comparison with existing approaches. (1) A distributional kernel is used for the very first time for trajectory representation and similarity measurement. (2) It does not rely on point-to-point distances which are used in most existing distances for trajectories. (3) It requires no learning, unlike existing learning and deep learning approaches. We show the generality of this new approach in three applications: (a) trajectory anomaly detection, (b) anomalous sub-trajectory detection, and (c) trajectory pattern mining. We identify that the distributional kernel has (i) a unique data-dependent property and the above uniqueness property which are the key factors that lead to its superior task-specific performance; and (ii) runtime orders of magnitude faster than existing distance measures.
Selective classification using a robust meta-learning approach
Dec 12, 2022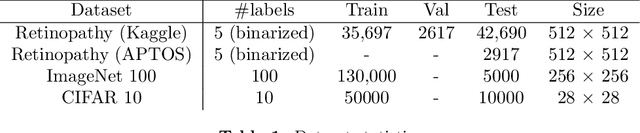
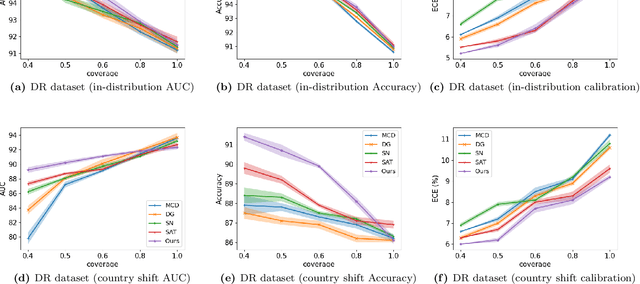
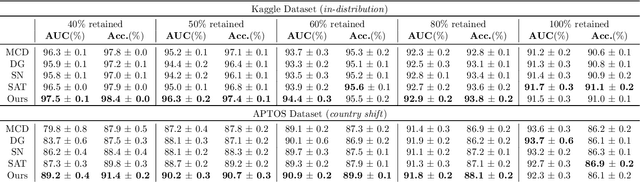
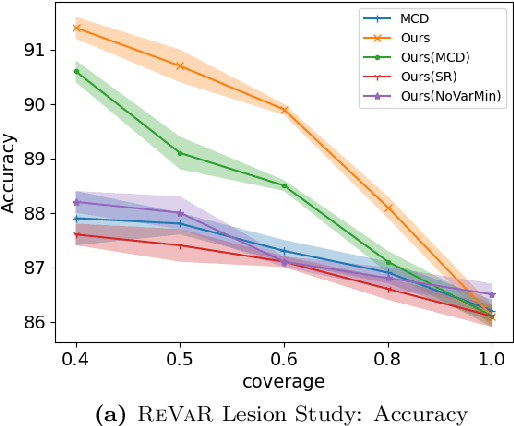
Selective classification involves identifying the subset of test samples that a model can classify with high accuracy, and is important for applications such as automated medical diagnosis. We argue that this capability of identifying uncertain samples is valuable for training classifiers as well, with the aim of building more accurate classifiers. We unify these dual roles by training a single auxiliary meta-network to output an importance weight as a function of the instance. This measure is used at train time to reweight training data, and at test-time to rank test instances for selective classification. A second, key component of our proposal is the meta-objective of minimizing dropout variance (the variance of classifier output when subjected to random weight dropout) for training the metanetwork. We train the classifier together with its metanetwork using a nested objective of minimizing classifier loss on training data and meta-loss on a separate meta-training dataset. We outperform current state-of-the-art on selective classification by substantial margins--for instance, upto 1.9% AUC and 2% accuracy on a real-world diabetic retinopathy dataset. Finally, our meta-learning framework extends naturally to unsupervised domain adaptation, given our unsupervised variance minimization meta-objective. We show cumulative absolute gains of 3.4% / 3.3% accuracy and AUC over the other baselines in domain shift settings on the Retinopathy dataset using unsupervised domain adaptation.
Wasserstein multivariate auto-regressive models for modeling distributional time series and its application in graph learning
Jul 12, 2022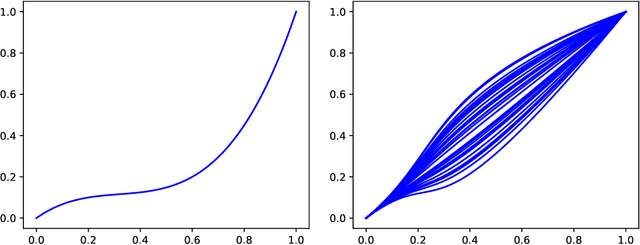
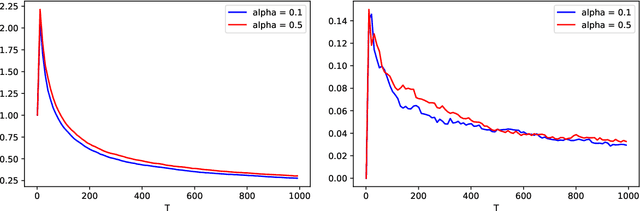
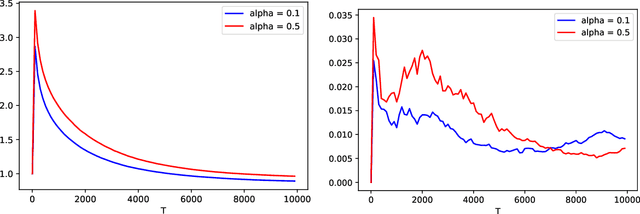
We propose a new auto-regressive model for the statistical analysis of multivariate distributional time series. The data of interest consist of a collection of multiple series of probability measures supported over a bounded interval of the real line, and that are indexed by distinct time instants. The probability measures are modelled as random objects in the Wasserstein space. We establish the auto-regressive model in the tangent space at the Lebesgue measure by first centering all the raw measures so that their Fr\'echet means turn to be the Lebesgue measure. Using the theory of iterated random function systems, results on the existence, uniqueness and stationarity of the solution of such a model are provided. We also propose a consistent estimator for the model coefficient. In addition to the analysis of simulated data, the proposed model is illustrated with two real data sets made of observations from age distribution in different countries and bike sharing network in Paris. Finally, due to the positive and boundedness constraints that we impose on the model coefficients, the proposed estimator that is learned under these constraints, naturally has a sparse structure. The sparsity allows furthermore the application of the proposed model in learning a graph of temporal dependency from the multivariate distributional time series.