 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Gradient flow in the gaussian covariate model: exact solution of learning curves and multiple descent structures
Dec 13, 2022

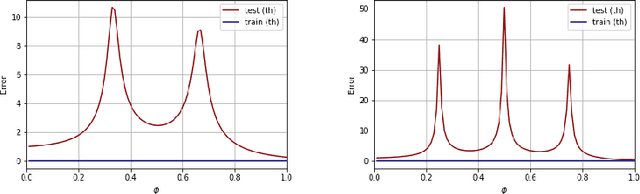
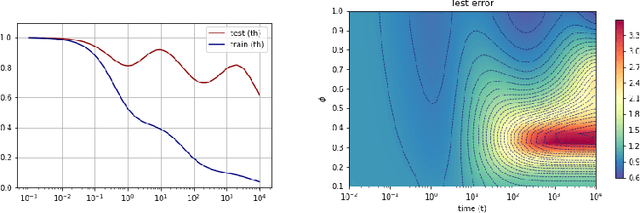
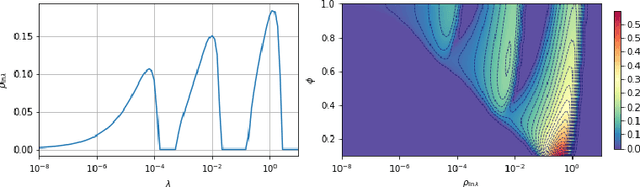
A recent line of work has shown remarkable behaviors of the generalization error curves in simple learning models. Even the least-squares regression has shown atypical features such as the model-wise double descent, and further works have observed triple or multiple descents. Another important characteristic are the epoch-wise descent structures which emerge during training. The observations of model-wise and epoch-wise descents have been analytically derived in limited theoretical settings (such as the random feature model) and are otherwise experimental. In this work, we provide a full and unified analysis of the whole time-evolution of the generalization curve, in the asymptotic large-dimensional regime and under gradient-flow, within a wider theoretical setting stemming from a gaussian covariate model. In particular, we cover most cases already disparately observed in the literature, and also provide examples of the existence of multiple descent structures as a function of a model parameter or time. Furthermore, we show that our theoretical predictions adequately match the learning curves obtained by gradient descent over realistic datasets. Technically we compute averages of rational expressions involving random matrices using recent developments in random matrix theory based on "linear pencils". Another contribution, which is also of independent interest in random matrix theory, is a new derivation of related fixed point equations (and an extension there-off) using Dyson brownian motions.
Post hoc Explanations may be Ineffective for Detecting Unknown Spurious Correlation
Dec 09, 2022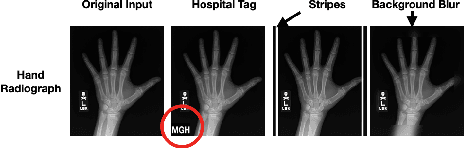
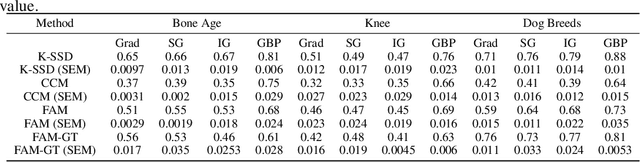
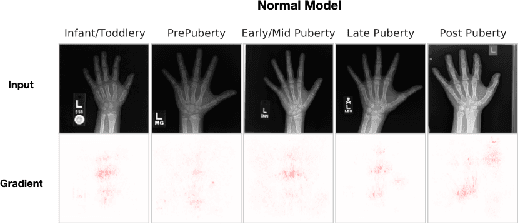
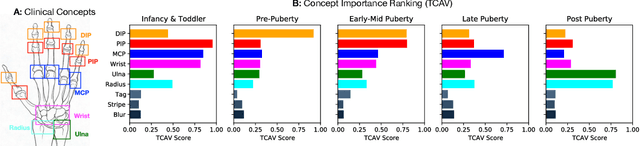
We investigate whether three types of post hoc model explanations--feature attribution, concept activation, and training point ranking--are effective for detecting a model's reliance on spurious signals in the training data. Specifically, we consider the scenario where the spurious signal to be detected is unknown, at test-time, to the user of the explanation method. We design an empirical methodology that uses semi-synthetic datasets along with pre-specified spurious artifacts to obtain models that verifiably rely on these spurious training signals. We then provide a suite of metrics that assess an explanation method's reliability for spurious signal detection under various conditions. We find that the post hoc explanation methods tested are ineffective when the spurious artifact is unknown at test-time especially for non-visible artifacts like a background blur. Further, we find that feature attribution methods are susceptible to erroneously indicating dependence on spurious signals even when the model being explained does not rely on spurious artifacts. This finding casts doubt on the utility of these approaches, in the hands of a practitioner, for detecting a model's reliance on spurious signals.
Matching DNN Compression and Cooperative Training with Resources and Data Availability
Dec 02, 2022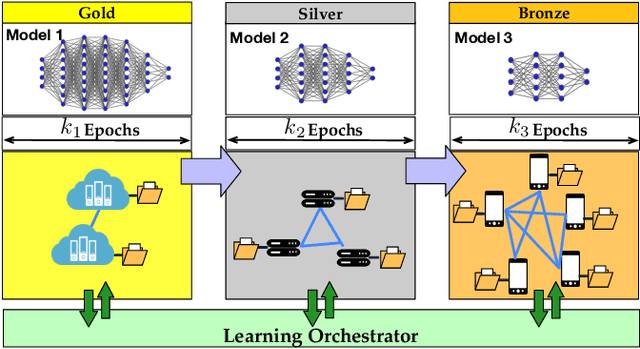
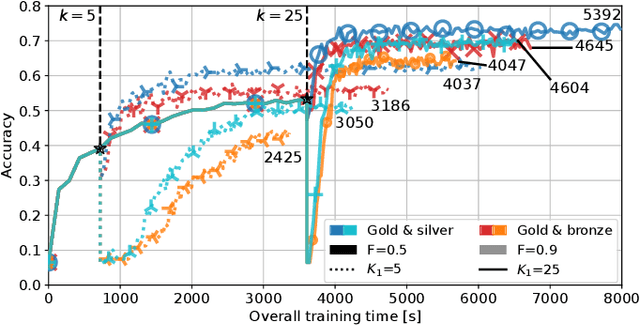
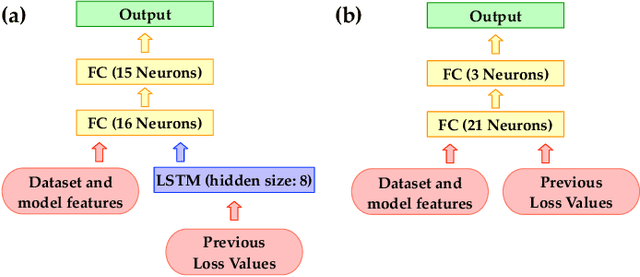
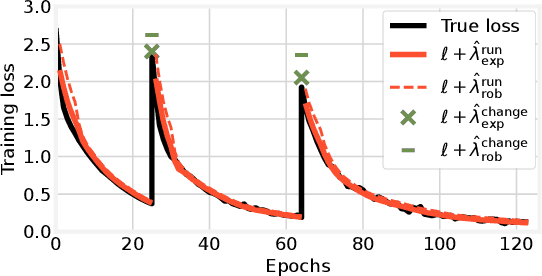
To make machine learning (ML) sustainable and apt to run on the diverse devices where relevant data is, it is essential to compress ML models as needed, while still meeting the required learning quality and time performance. However, how much and when an ML model should be compressed, and {\em where} its training should be executed, are hard decisions to make, as they depend on the model itself, the resources of the available nodes, and the data such nodes own. Existing studies focus on each of those aspects individually, however, they do not account for how such decisions can be made jointly and adapted to one another. In this work, we model the network system focusing on the training of DNNs, formalize the above multi-dimensional problem, and, given its NP-hardness, formulate an approximate dynamic programming problem that we solve through the PACT algorithmic framework. Importantly, PACT leverages a time-expanded graph representing the learning process, and a data-driven and theoretical approach for the prediction of the loss evolution to be expected as a consequence of training decisions. We prove that PACT's solutions can get as close to the optimum as desired, at the cost of an increased time complexity, and that, in any case, such complexity is polynomial. Numerical results also show that, even under the most disadvantageous settings, PACT outperforms state-of-the-art alternatives and closely matches the optimal energy cost.
Gaussian Process Priors for Systems of Linear Partial Differential Equations with Constant Coefficients
Dec 29, 2022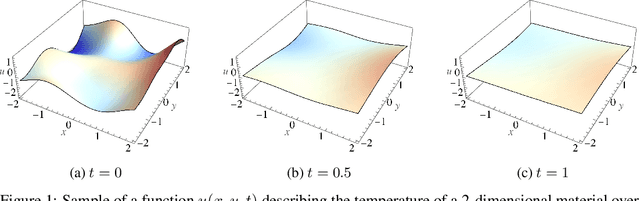
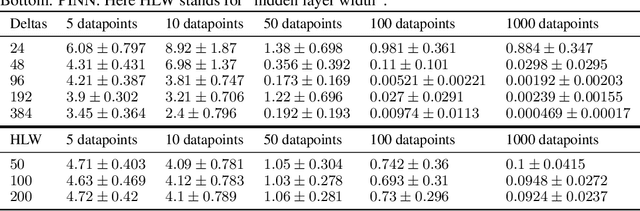
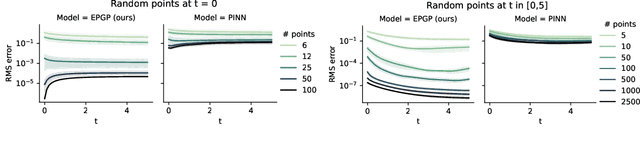
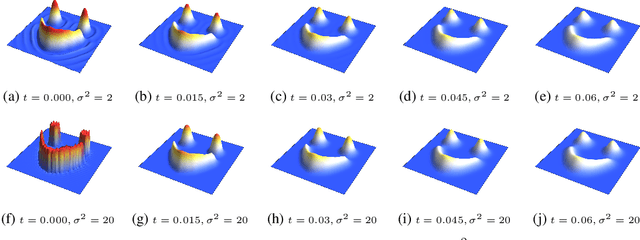
Partial differential equations (PDEs) are important tools to model physical systems, and including them into machine learning models is an important way of incorporating physical knowledge. Given any system of linear PDEs with constant coefficients, we propose a family of Gaussian process (GP) priors, which we call EPGP, such that all realizations are exact solutions of this system. We apply the Ehrenpreis-Palamodov fundamental principle, which works like a non-linear Fourier transform, to construct GP kernels mirroring standard spectral methods for GPs. Our approach can infer probable solutions of linear PDE systems from any data such as noisy measurements, or initial and boundary conditions. Constructing EPGP-priors is algorithmic, generally applicable, and comes with a sparse version (S-EPGP) that learns the relevant spectral frequencies and works better for big data sets. We demonstrate our approach on three families of systems of PDE, the heat equation, wave equation, and Maxwell's equations, where we improve upon the state of the art in computation time and precision, in some experiments by several orders of magnitude.
Unsupervised construction of representations for oil wells via Transformers
Dec 29, 2022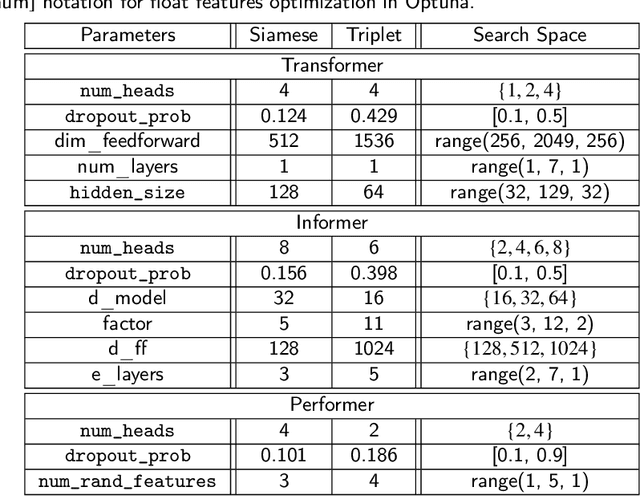
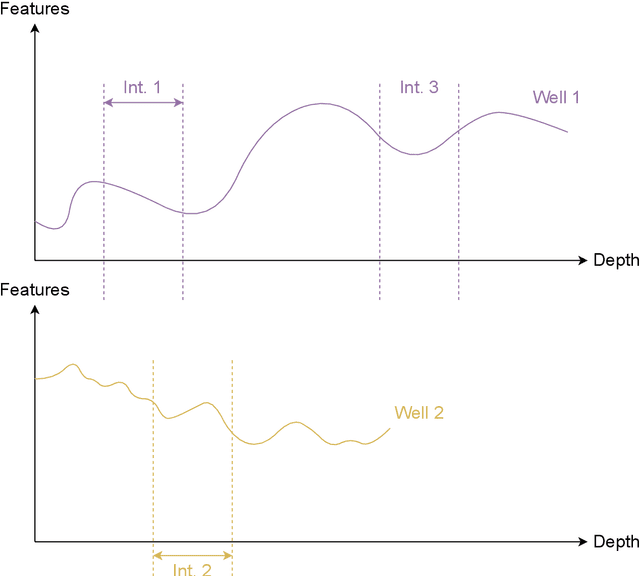
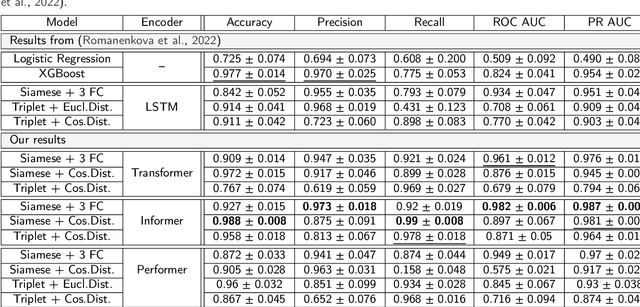
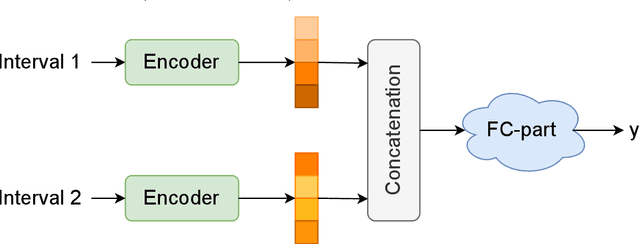
Determining and predicting reservoir formation properties for newly drilled wells represents a significant challenge. One of the variations of these properties evaluation is well-interval similarity. Many methodologies for similarity learning exist: from rule-based approaches to deep neural networks. Recently, articles adopted, e.g. recurrent neural networks to build a similarity model as we deal with sequential data. Such an approach suffers from short-term memory, as it pays more attention to the end of a sequence. Neural network with Transformer architecture instead cast their attention over all sequences to make a decision. To make them more efficient in terms of computational time, we introduce a limited attention mechanism similar to Informer and Performer architectures. We conduct experiments on open datasets with more than 20 wells making our experiments reliable and suitable for industrial usage. The best results were obtained with our adaptation of the Informer variant of Transformer with ROC AUC 0.982. It outperforms classical approaches with ROC AUC 0.824, Recurrent neural networks with ROC AUC 0.934 and straightforward usage of Transformers with ROC AUC 0.961.
Context-aware 6D Pose Estimation of Known Objects using RGB-D data
Dec 11, 2022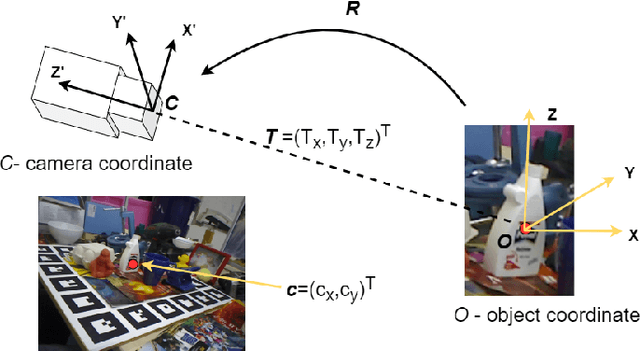
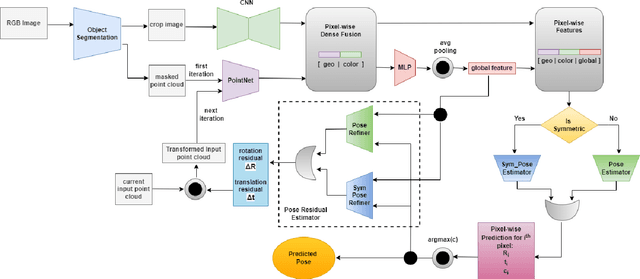

6D object pose estimation has been a research topic in the field of computer vision and robotics. Many modern world applications like robot grasping, manipulation, autonomous navigation etc, require the correct pose of objects present in a scene to perform their specific task. It becomes even harder when the objects are placed in a cluttered scene and the level of occlusion is high. Prior works have tried to overcome this problem but could not achieve accuracy that can be considered reliable in real-world applications. In this paper, we present an architecture that, unlike prior work, is context-aware. It utilizes the context information available to us about the objects. Our proposed architecture treats the objects separately according to their types i.e; symmetric and non-symmetric. A deeper estimator and refiner network pair is used for non-symmetric objects as compared to symmetric due to their intrinsic differences. Our experiments show an enhancement in the accuracy of about 3.2% over the LineMOD dataset, which is considered a benchmark for pose estimation in the occluded and cluttered scenes, against the prior state-of-the-art DenseFusion. Our results also show that the inference time we got is sufficient for real-time usage.
Human-Robot Team Performance Compared to Full Robot Autonomy in 16 Real-World Search and Rescue Missions: Adaptation of the DARPA Subterranean Challenge
Dec 11, 2022
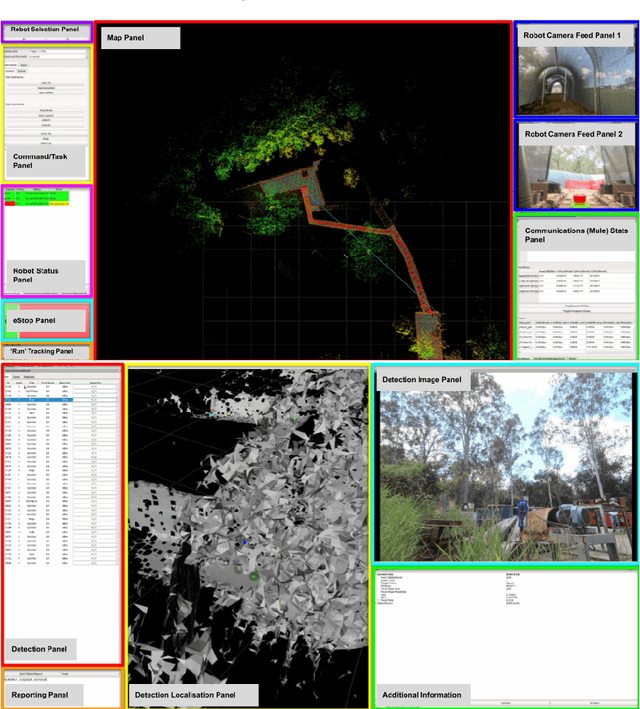


Human operators in human-robot teams are commonly perceived to be critical for mission success. To explore the direct and perceived impact of operator input on task success and team performance, 16 real-world missions (10 hrs) were conducted based on the DARPA Subterranean Challenge. These missions were to deploy a heterogeneous team of robots for a search task to locate and identify artifacts such as climbing rope, drills and mannequins representing human survivors. Two conditions were evaluated: human operators that could control the robot team with state-of-the-art autonomy (Human-Robot Team) compared to autonomous missions without human operator input (Robot-Autonomy). Human-Robot Teams were often in directed autonomy mode (70% of mission time), found more items, traversed more distance, covered more unique ground, and had a higher time between safety-related events. Human-Robot Teams were faster at finding the first artifact, but slower to respond to information from the robot team. In routine conditions, scores were comparable for artifacts, distance, and coverage. Reasons for intervention included creating waypoints to prioritise high-yield areas, and to navigate through error-prone spaces. After observing robot autonomy, operators reported increases in robot competency and trust, but that robot behaviour was not always transparent and understandable, even after high mission performance.
Genetic-tunneling driven energy optimizer for magnetic system
Dec 31, 2022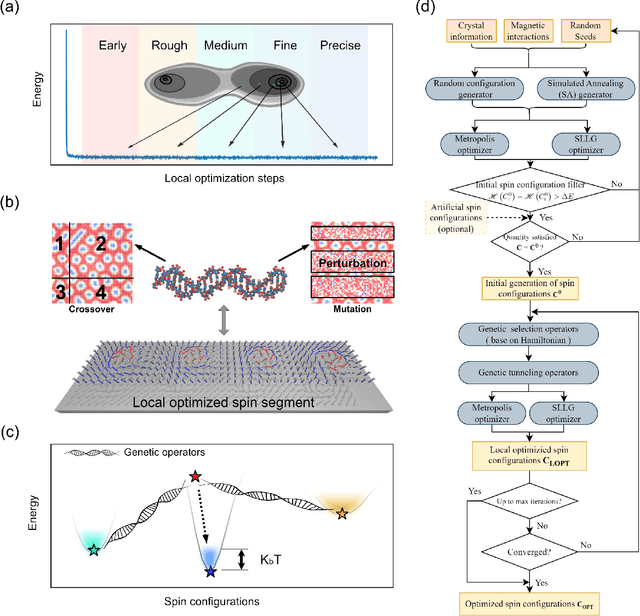
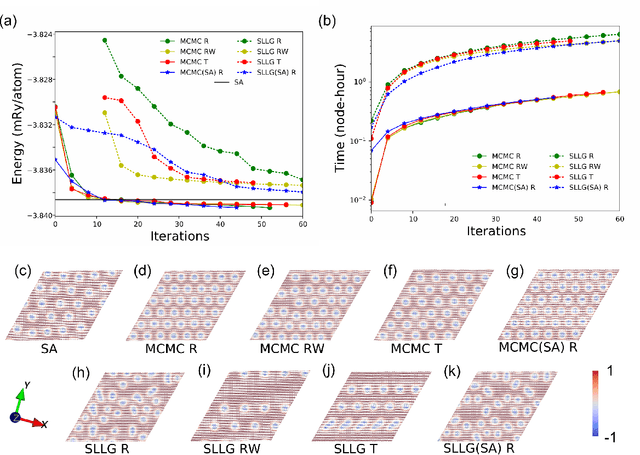
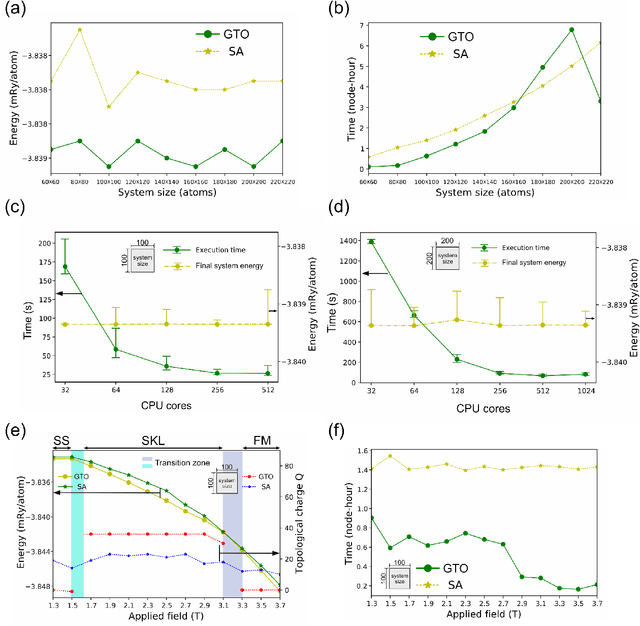
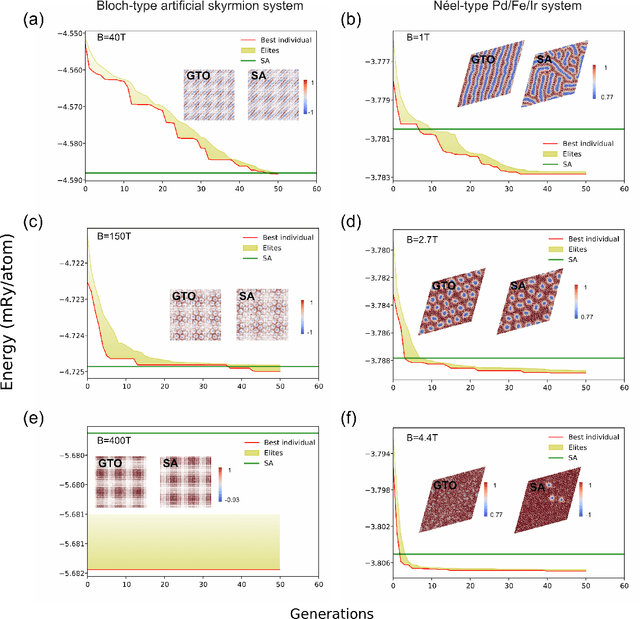
Novel topological spin textures, such as magnetic skyrmions, benefit from their inherent stability, acting as the ground state in several magnetic systems. In the current study of atomic monolayer magnetic materials, reasonable initial guesses are still needed to search for those magnetic patterns. This situation underlines the need to develop a more effective way to identify the ground states. To solve this problem, in this work, we propose a genetic-tunneling-driven variance-controlled optimization approach, which combines a local energy minimizer back-end and a metaheuristic global searching front-end. This algorithm is an effective optimization solution for searching for magnetic ground states at extremely low temperatures and is also robust for finding low-energy degenerated states at finite temperatures. We demonstrate here the success of this method in searching for magnetic ground states of 2D monolayer systems with both artificial and calculated interactions from density functional theory. It is also worth noting that the inherent concurrent property of this algorithm can significantly decrease the execution time. In conclusion, our proposed method builds a useful tool for low-dimensional magnetic system energy optimization.
Back to the Source: Diffusion-Driven Test-Time Adaptation
Jul 07, 2022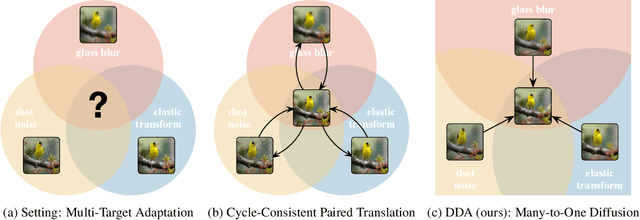

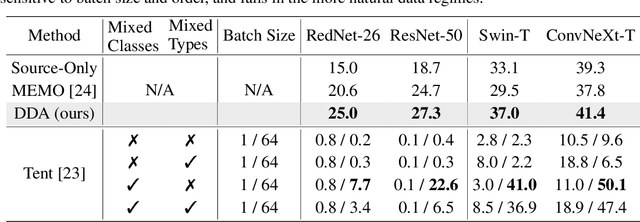
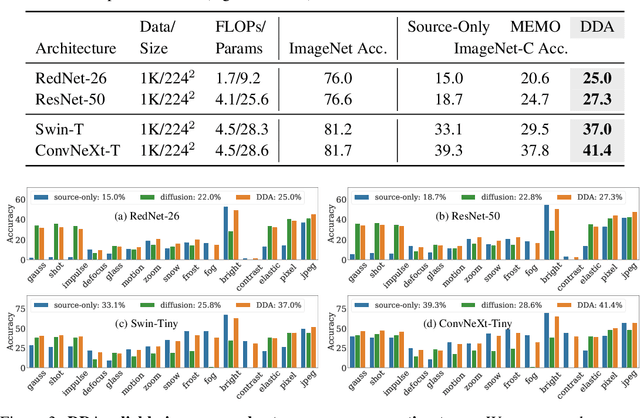
Test-time adaptation harnesses test inputs to improve the accuracy of a model trained on source data when tested on shifted target data. Existing methods update the source model by (re-)training on each target domain. While effective, re-training is sensitive to the amount and order of the data and the hyperparameters for optimization. We instead update the target data, by projecting all test inputs toward the source domain with a generative diffusion model. Our diffusion-driven adaptation method, DDA, shares its models for classification and generation across all domains. Both models are trained on the source domain, then fixed during testing. We augment diffusion with image guidance and self-ensembling to automatically decide how much to adapt. Input adaptation by DDA is more robust than prior model adaptation approaches across a variety of corruptions, architectures, and data regimes on the ImageNet-C benchmark. With its input-wise updates, DDA succeeds where model adaptation degrades on too little data in small batches, dependent data in non-uniform order, or mixed data with multiple corruptions.
A Projected Upper Bound for Mining High Utility Patterns from Interval-Based Event Sequences
Dec 21, 2022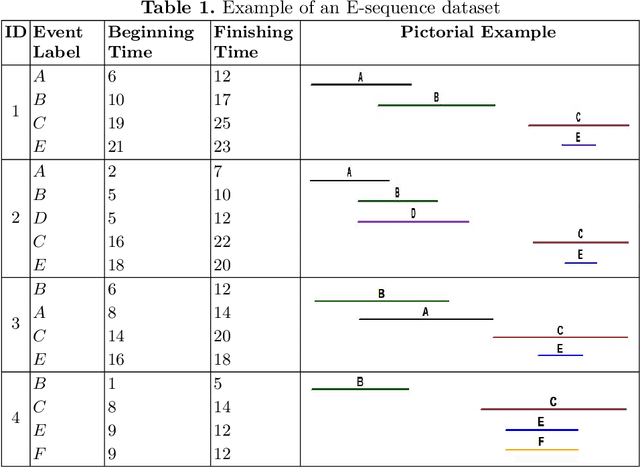
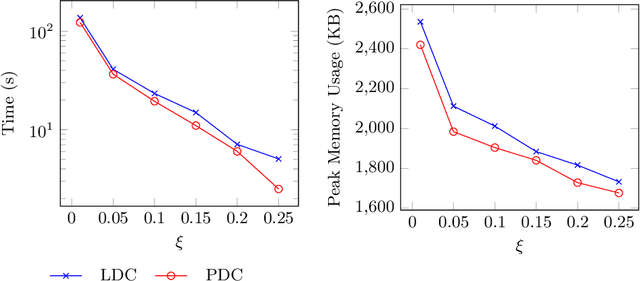

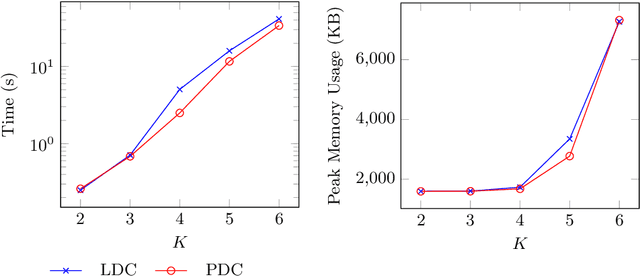
High utility pattern mining is an interesting yet challenging problem. The intrinsic computational cost of the problem will impose further challenges if efficiency in addition to the efficacy of a solution is sought. Recently, this problem was studied on interval-based event sequences with a constraint on the length and size of the patterns. However, the proposed solution lacks adequate efficiency. To address this issue, we propose a projected upper bound on the utility of the patterns discovered from sequences of interval-based events. To show its effectiveness, the upper bound is utilized by a pruning strategy employed by the HUIPMiner algorithm. Experimental results show that the new upper bound improves HUIPMiner performance in terms of both execution time and memory usage.