 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
KRLS: Improving End-to-End Response Generation in Task Oriented Dialog with Reinforced Keywords Learning
Dec 20, 2022
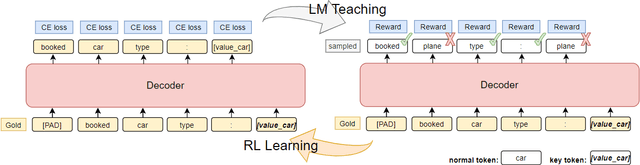
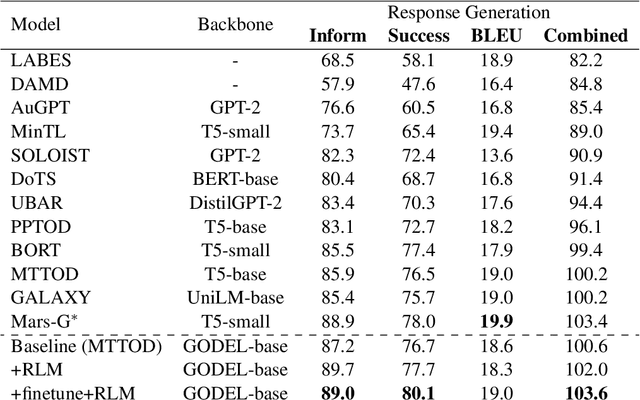
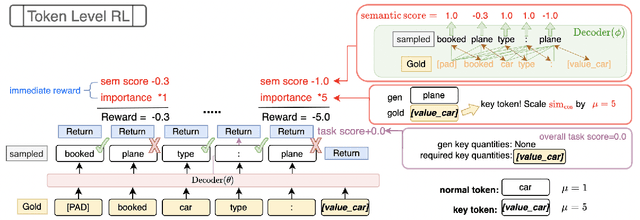

In task-oriented dialogs, an informative and successful system response needs to include key information such as the phone number of a hotel. Therefore, we hypothesize that a model can achieve better overall performance by focusing on correctly generating key quantities. In this paper, we propose a new training algorithm, Keywords Reinforcement Learning with Next-word Sampling (KRLS), that utilizes Reinforcement Learning but avoids the time-consuming auto-regressive generation, and a fine-grained per-token reward function to help the model learn keywords generation more robustly. Empirical results show that the KRLS algorithm can achieve state-of-the-art performance on the inform, success, and combined score on the MultiWoZ benchmark dataset.
GaitVibe+: Enhancing Structural Vibration-based Footstep Localization Using Temporary Cameras for In-home Gait Analysis
Dec 07, 2022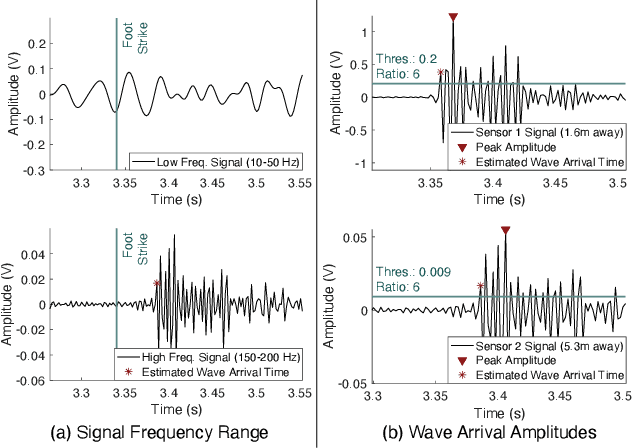
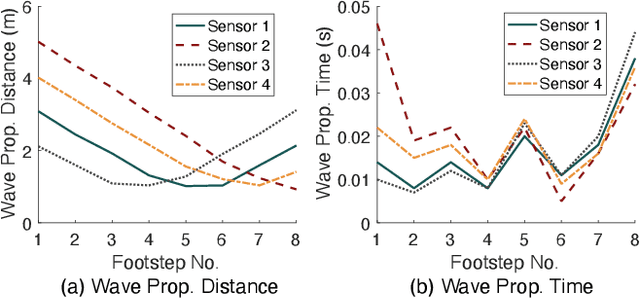
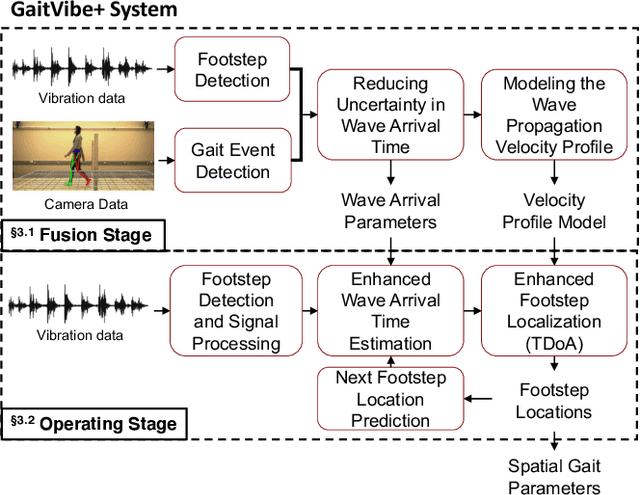
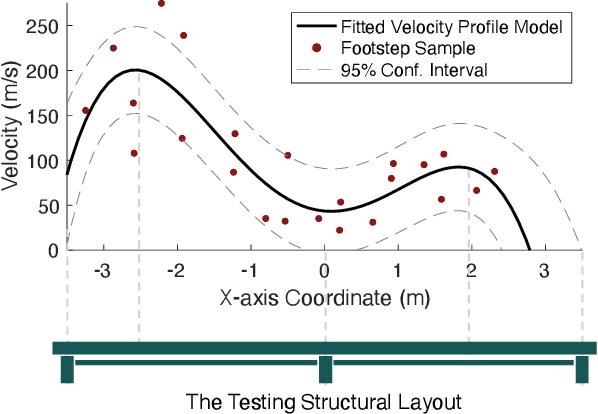
In-home gait analysis is important for providing early diagnosis and adaptive treatments for individuals with gait disorders. Existing systems include wearables and pressure mats, but they have limited scalability. Recent studies have developed vision-based systems to enable scalable, accurate in-home gait analysis, but it faces privacy concerns due to the exposure of people's appearances. Our prior work developed footstep-induced structural vibration sensing for gait monitoring, which is device-free, wide-ranged, and perceived as more privacy-friendly. Although it has succeeded in temporal gait event extraction, it shows limited performance for spatial gait parameter estimation due to imprecise footstep localization. In particular, the localization error mainly comes from the estimation error of the wave arrival time at the vibration sensors and its error propagation to wave velocity estimations. Therefore, we present GaitVibe+, a vibration-based footstep localization method fused with temporarily installed cameras for in-home gait analysis. Our method has two stages: fusion and operating. In the fusion stage, both cameras and vibration sensors are installed to record only a few trials of the subject's footstep data, through which we characterize the uncertainty in wave arrival time and model the wave velocity profiles for the given structure. In the operating stage, we remove the camera to preserve privacy at home. The footstep localization is conducted by estimating the time difference of arrival (TDoA) over multiple vibration sensors, whose accuracy is improved through the reduced uncertainty and velocity modeling during the fusion stage. We evaluate GaitVibe+ through a real-world experiment with 50 walking trials. With only 3 trials of multi-modal fusion, our approach has an average localization error of 0.22 meters, which reduces the spatial gait parameter error from 111% to 27%.
Genetic-tunneling driven energy optimizer for magnetic system
Dec 31, 2022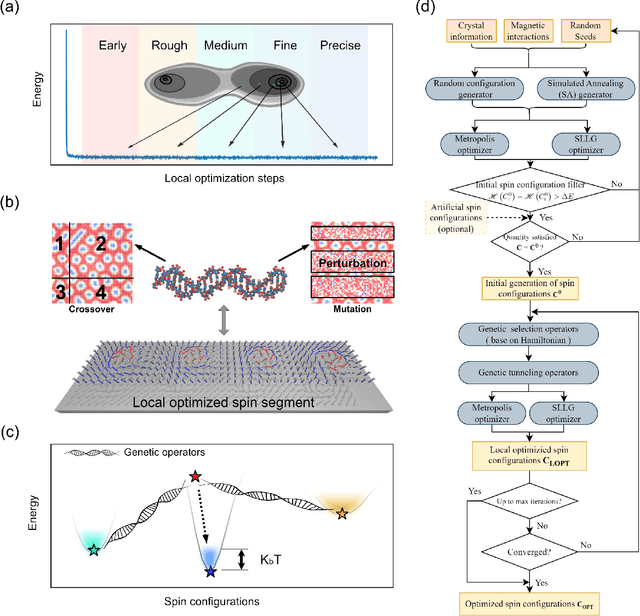
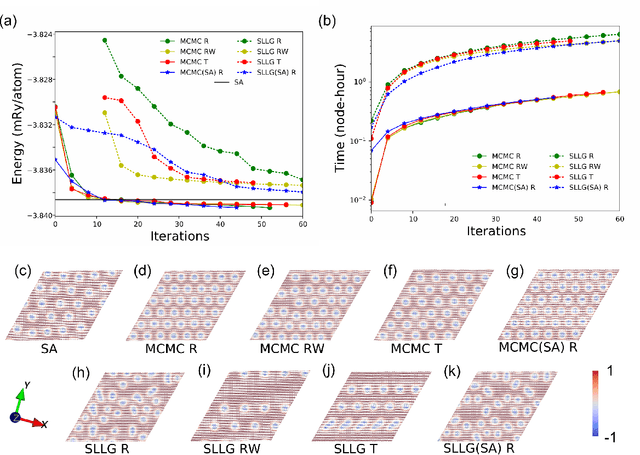
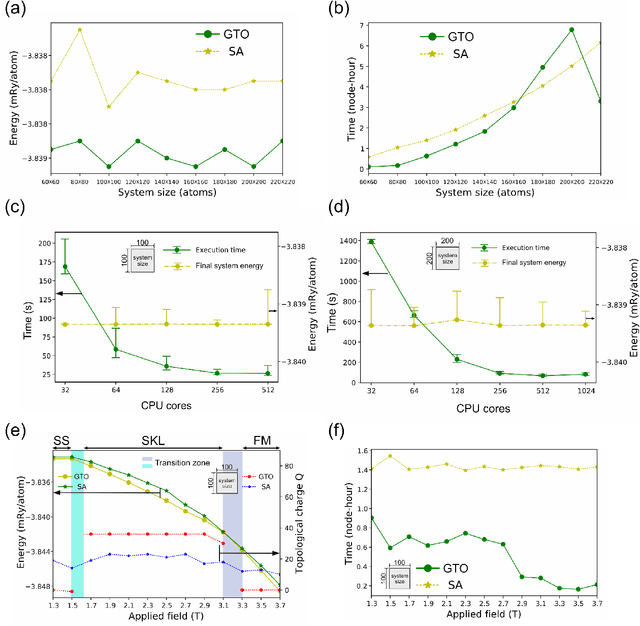
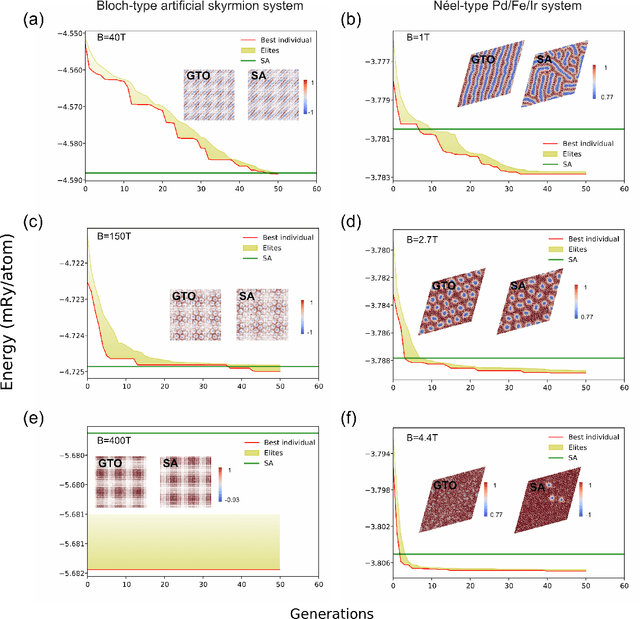
Novel topological spin textures, such as magnetic skyrmions, benefit from their inherent stability, acting as the ground state in several magnetic systems. In the current study of atomic monolayer magnetic materials, reasonable initial guesses are still needed to search for those magnetic patterns. This situation underlines the need to develop a more effective way to identify the ground states. To solve this problem, in this work, we propose a genetic-tunneling-driven variance-controlled optimization approach, which combines a local energy minimizer back-end and a metaheuristic global searching front-end. This algorithm is an effective optimization solution for searching for magnetic ground states at extremely low temperatures and is also robust for finding low-energy degenerated states at finite temperatures. We demonstrate here the success of this method in searching for magnetic ground states of 2D monolayer systems with both artificial and calculated interactions from density functional theory. It is also worth noting that the inherent concurrent property of this algorithm can significantly decrease the execution time. In conclusion, our proposed method builds a useful tool for low-dimensional magnetic system energy optimization.
Gradient flow in the gaussian covariate model: exact solution of learning curves and multiple descent structures
Dec 13, 2022
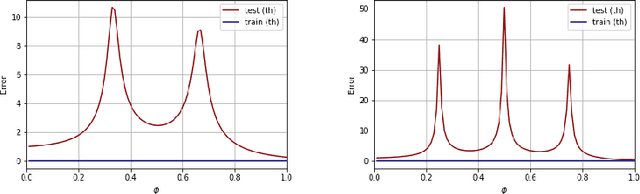
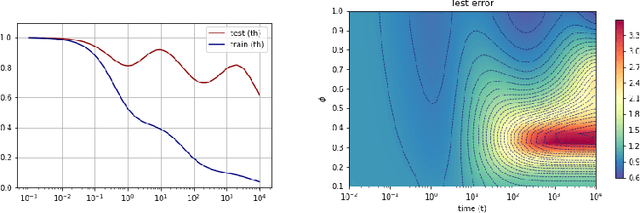
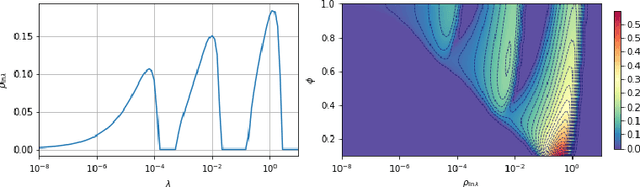
A recent line of work has shown remarkable behaviors of the generalization error curves in simple learning models. Even the least-squares regression has shown atypical features such as the model-wise double descent, and further works have observed triple or multiple descents. Another important characteristic are the epoch-wise descent structures which emerge during training. The observations of model-wise and epoch-wise descents have been analytically derived in limited theoretical settings (such as the random feature model) and are otherwise experimental. In this work, we provide a full and unified analysis of the whole time-evolution of the generalization curve, in the asymptotic large-dimensional regime and under gradient-flow, within a wider theoretical setting stemming from a gaussian covariate model. In particular, we cover most cases already disparately observed in the literature, and also provide examples of the existence of multiple descent structures as a function of a model parameter or time. Furthermore, we show that our theoretical predictions adequately match the learning curves obtained by gradient descent over realistic datasets. Technically we compute averages of rational expressions involving random matrices using recent developments in random matrix theory based on "linear pencils". Another contribution, which is also of independent interest in random matrix theory, is a new derivation of related fixed point equations (and an extension there-off) using Dyson brownian motions.
Cross-network transferable neural models for WLAN interference estimation
Nov 25, 2022
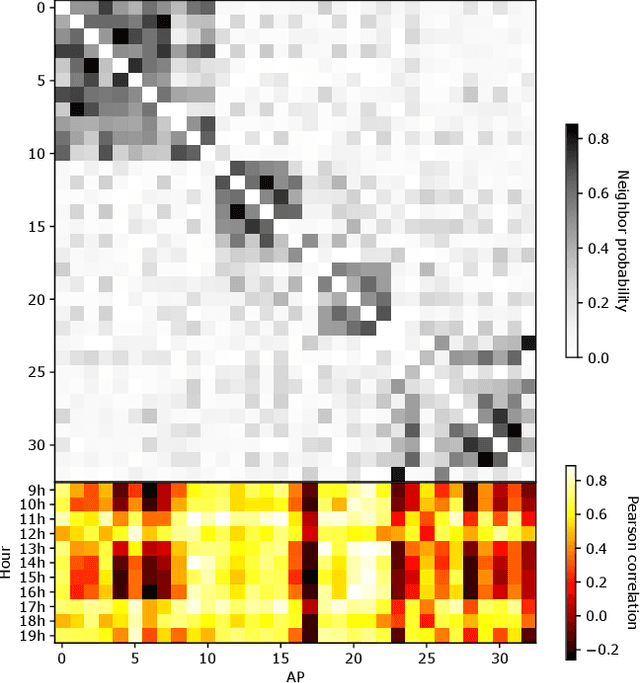
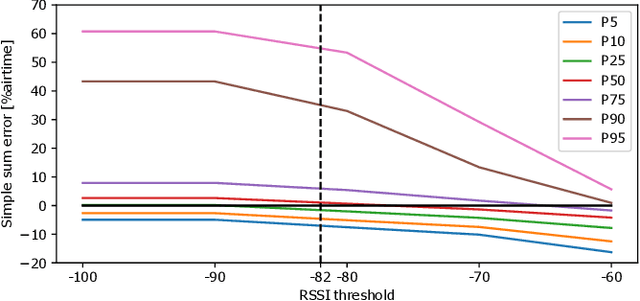
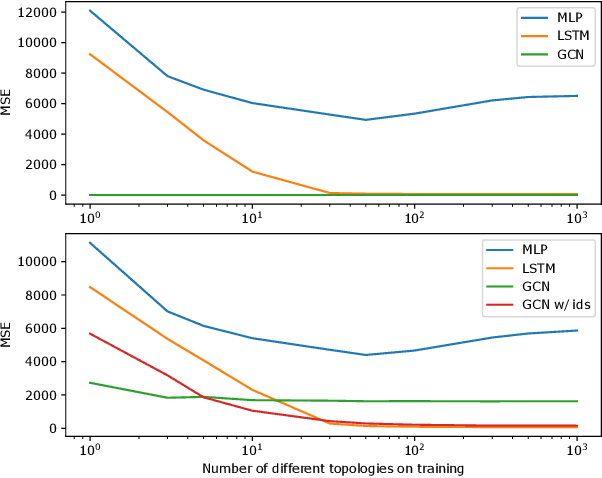
Airtime interference is a key performance indicator for WLANs, measuring, for a given time period, the percentage of time during which a node is forced to wait for other transmissions before to transmitting or receiving. Being able to accurately estimate interference resulting from a given state change (e.g., channel, bandwidth, power) would allow a better control of WLAN resources, assessing the impact of a given configuration before actually implementing it. In this paper, we adopt a principled approach to interference estimation in WLANs. We first use real data to characterize the factors that impact it, and derive a set of relevant synthetic workloads for a controlled comparison of various deep learning architectures in terms of accuracy, generalization and robustness to outlier data. We find, unsurprisingly, that Graph Convolutional Networks (GCNs) yield the best performance overall, leveraging the graph structure inherent to campus WLANs. We notice that, unlike e.g. LSTMs, they struggle to learn the behavior of specific nodes, unless given the node indexes in addition. We finally verify GCN model generalization capabilities, by applying trained models on operational deployments unseen at training time.
Post hoc Explanations may be Ineffective for Detecting Unknown Spurious Correlation
Dec 09, 2022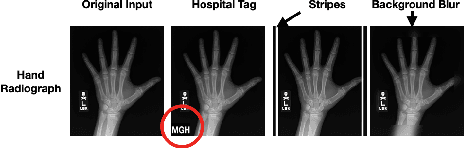
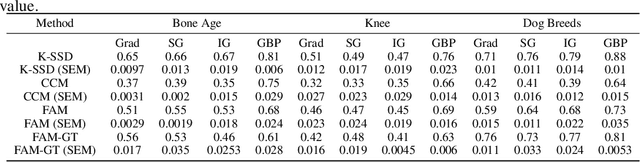
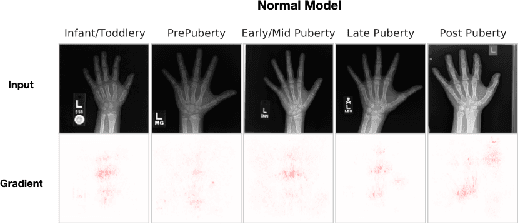
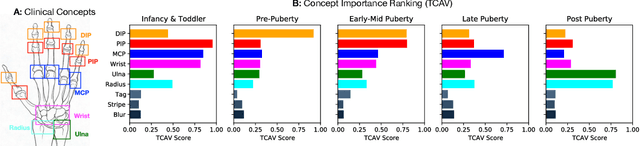
We investigate whether three types of post hoc model explanations--feature attribution, concept activation, and training point ranking--are effective for detecting a model's reliance on spurious signals in the training data. Specifically, we consider the scenario where the spurious signal to be detected is unknown, at test-time, to the user of the explanation method. We design an empirical methodology that uses semi-synthetic datasets along with pre-specified spurious artifacts to obtain models that verifiably rely on these spurious training signals. We then provide a suite of metrics that assess an explanation method's reliability for spurious signal detection under various conditions. We find that the post hoc explanation methods tested are ineffective when the spurious artifact is unknown at test-time especially for non-visible artifacts like a background blur. Further, we find that feature attribution methods are susceptible to erroneously indicating dependence on spurious signals even when the model being explained does not rely on spurious artifacts. This finding casts doubt on the utility of these approaches, in the hands of a practitioner, for detecting a model's reliance on spurious signals.
Context-aware 6D Pose Estimation of Known Objects using RGB-D data
Dec 11, 2022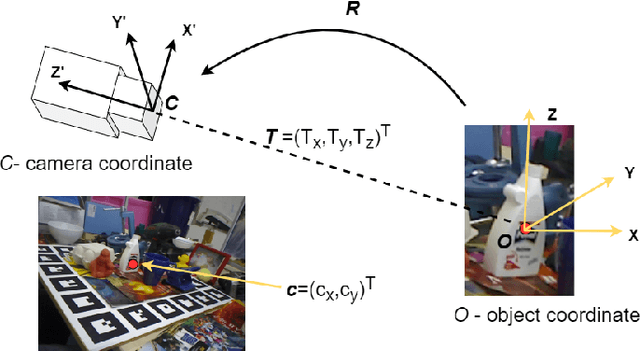
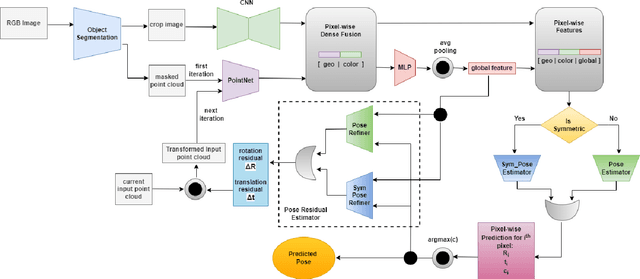

6D object pose estimation has been a research topic in the field of computer vision and robotics. Many modern world applications like robot grasping, manipulation, autonomous navigation etc, require the correct pose of objects present in a scene to perform their specific task. It becomes even harder when the objects are placed in a cluttered scene and the level of occlusion is high. Prior works have tried to overcome this problem but could not achieve accuracy that can be considered reliable in real-world applications. In this paper, we present an architecture that, unlike prior work, is context-aware. It utilizes the context information available to us about the objects. Our proposed architecture treats the objects separately according to their types i.e; symmetric and non-symmetric. A deeper estimator and refiner network pair is used for non-symmetric objects as compared to symmetric due to their intrinsic differences. Our experiments show an enhancement in the accuracy of about 3.2% over the LineMOD dataset, which is considered a benchmark for pose estimation in the occluded and cluttered scenes, against the prior state-of-the-art DenseFusion. Our results also show that the inference time we got is sufficient for real-time usage.
Human-Robot Team Performance Compared to Full Robot Autonomy in 16 Real-World Search and Rescue Missions: Adaptation of the DARPA Subterranean Challenge
Dec 11, 2022
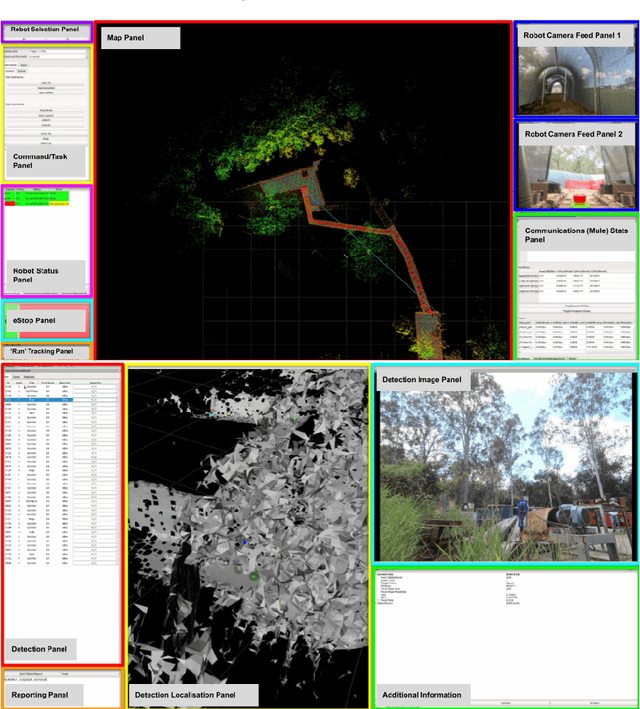


Human operators in human-robot teams are commonly perceived to be critical for mission success. To explore the direct and perceived impact of operator input on task success and team performance, 16 real-world missions (10 hrs) were conducted based on the DARPA Subterranean Challenge. These missions were to deploy a heterogeneous team of robots for a search task to locate and identify artifacts such as climbing rope, drills and mannequins representing human survivors. Two conditions were evaluated: human operators that could control the robot team with state-of-the-art autonomy (Human-Robot Team) compared to autonomous missions without human operator input (Robot-Autonomy). Human-Robot Teams were often in directed autonomy mode (70% of mission time), found more items, traversed more distance, covered more unique ground, and had a higher time between safety-related events. Human-Robot Teams were faster at finding the first artifact, but slower to respond to information from the robot team. In routine conditions, scores were comparable for artifacts, distance, and coverage. Reasons for intervention included creating waypoints to prioritise high-yield areas, and to navigate through error-prone spaces. After observing robot autonomy, operators reported increases in robot competency and trust, but that robot behaviour was not always transparent and understandable, even after high mission performance.
Matching DNN Compression and Cooperative Training with Resources and Data Availability
Dec 02, 2022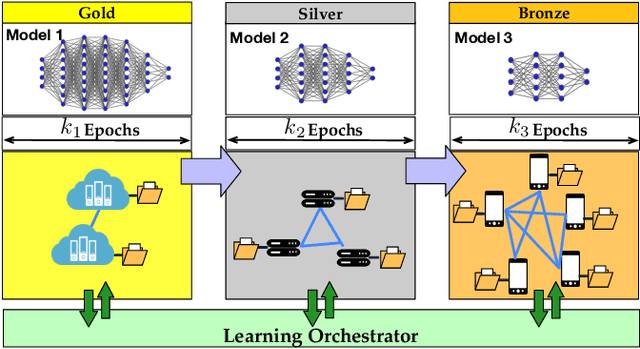
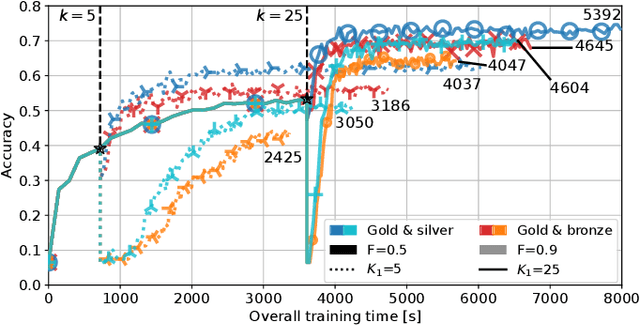
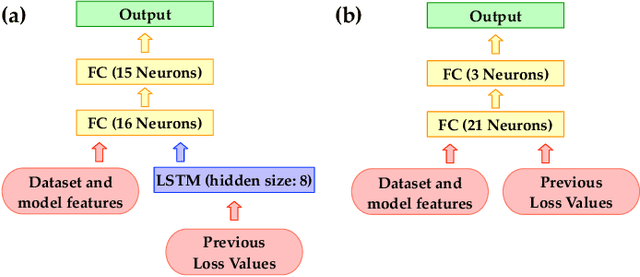
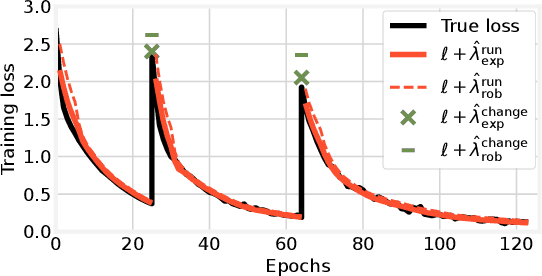
To make machine learning (ML) sustainable and apt to run on the diverse devices where relevant data is, it is essential to compress ML models as needed, while still meeting the required learning quality and time performance. However, how much and when an ML model should be compressed, and {\em where} its training should be executed, are hard decisions to make, as they depend on the model itself, the resources of the available nodes, and the data such nodes own. Existing studies focus on each of those aspects individually, however, they do not account for how such decisions can be made jointly and adapted to one another. In this work, we model the network system focusing on the training of DNNs, formalize the above multi-dimensional problem, and, given its NP-hardness, formulate an approximate dynamic programming problem that we solve through the PACT algorithmic framework. Importantly, PACT leverages a time-expanded graph representing the learning process, and a data-driven and theoretical approach for the prediction of the loss evolution to be expected as a consequence of training decisions. We prove that PACT's solutions can get as close to the optimum as desired, at the cost of an increased time complexity, and that, in any case, such complexity is polynomial. Numerical results also show that, even under the most disadvantageous settings, PACT outperforms state-of-the-art alternatives and closely matches the optimal energy cost.
Sound Localization by Self-Supervised Time Delay Estimation
Apr 26, 2022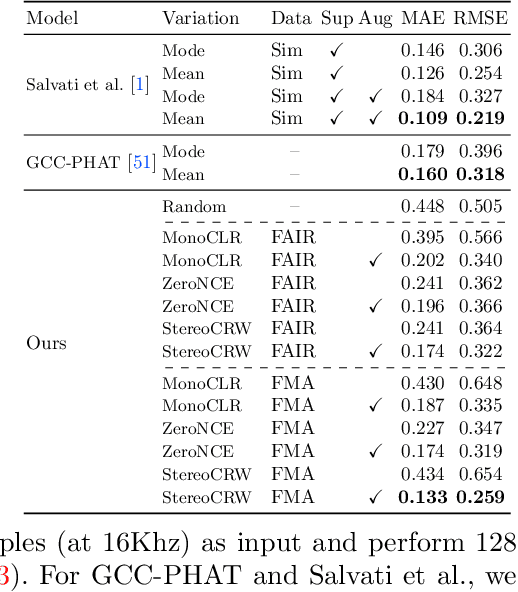
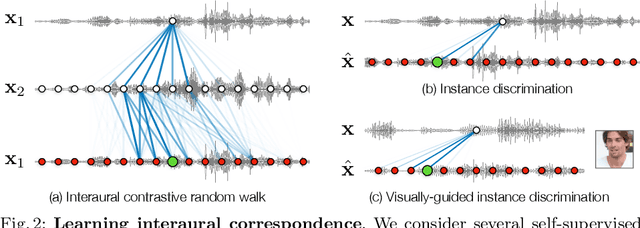
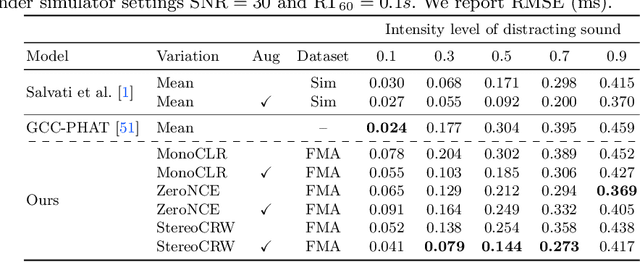

Sounds reach one microphone in a stereo pair sooner than the other, resulting in an interaural time delay that conveys their directions. Estimating a sound's time delay requires finding correspondences between the signals recorded by each microphone. We propose to learn these correspondences through self-supervision, drawing on recent techniques from visual tracking. We adapt the contrastive random walk of Jabri et al. to learn a cycle-consistent representation from unlabeled stereo sounds, resulting in a model that performs on par with supervised methods on "in the wild" internet recordings. We also propose a multimodal contrastive learning model that solves a visually-guided localization task: estimating the time delay for a particular person in a multi-speaker mixture, given a visual representation of their face. Project site: https://ificl.github.io/stereocrw/