 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Convolution-enhanced Evolving Attention Networks
Dec 16, 2022
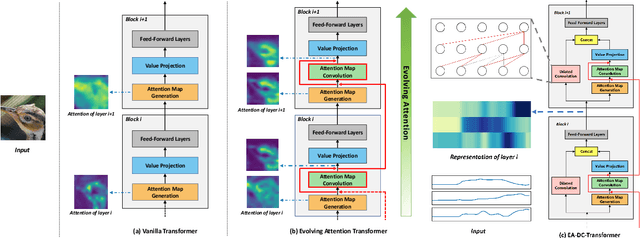

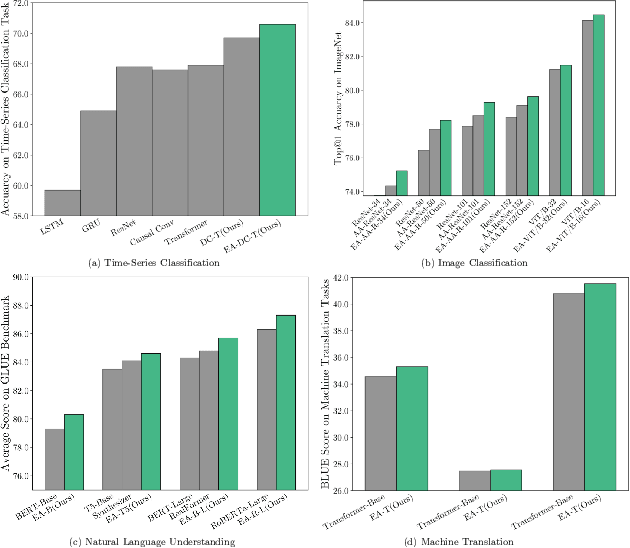
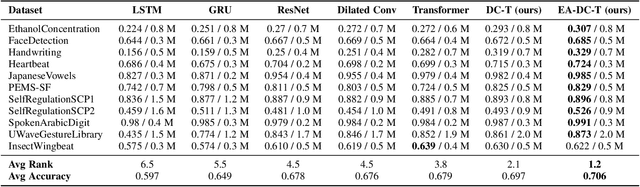
Attention-based neural networks, such as Transformers, have become ubiquitous in numerous applications, including computer vision, natural language processing, and time-series analysis. In all kinds of attention networks, the attention maps are crucial as they encode semantic dependencies between input tokens. However, most existing attention networks perform modeling or reasoning based on representations, wherein the attention maps of different layers are learned separately without explicit interactions. In this paper, we propose a novel and generic evolving attention mechanism, which directly models the evolution of inter-token relationships through a chain of residual convolutional modules. The major motivations are twofold. On the one hand, the attention maps in different layers share transferable knowledge, thus adding a residual connection can facilitate the information flow of inter-token relationships across layers. On the other hand, there is naturally an evolutionary trend among attention maps at different abstraction levels, so it is beneficial to exploit a dedicated convolution-based module to capture this process. Equipped with the proposed mechanism, the convolution-enhanced evolving attention networks achieve superior performance in various applications, including time-series representation, natural language understanding, machine translation, and image classification. Especially on time-series representation tasks, Evolving Attention-enhanced Dilated Convolutional (EA-DC-) Transformer outperforms state-of-the-art models significantly, achieving an average of 17% improvement compared to the best SOTA. To the best of our knowledge, this is the first work that explicitly models the layer-wise evolution of attention maps. Our implementation is available at https://github.com/pkuyym/EvolvingAttention
Bag of States: A Non-sequential Approach to Video-based Engagement Measurement
Jan 17, 2023
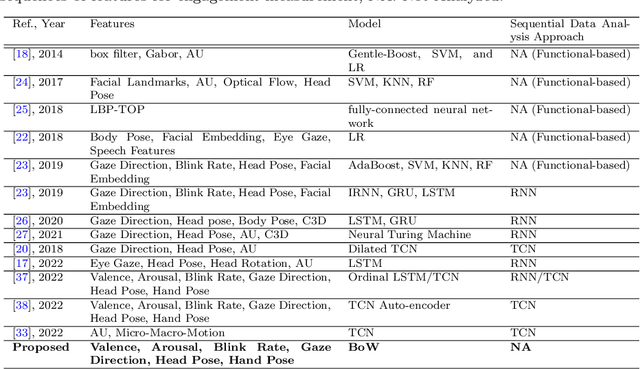
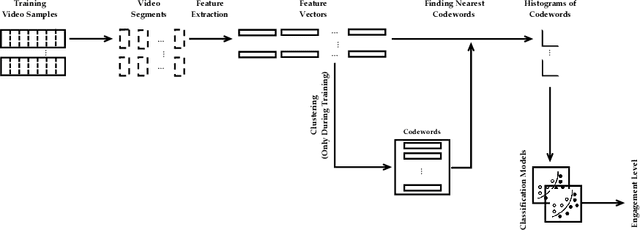
Automatic measurement of student engagement provides helpful information for instructors to meet learning program objectives and individualize program delivery. Students' behavioral and emotional states need to be analyzed at fine-grained time scales in order to measure their level of engagement. Many existing approaches have developed sequential and spatiotemporal models, such as recurrent neural networks, temporal convolutional networks, and three-dimensional convolutional neural networks, for measuring student engagement from videos. These models are trained to incorporate the order of behavioral and emotional states of students into video analysis and output their level of engagement. In this paper, backed by educational psychology, we question the necessity of modeling the order of behavioral and emotional states of students in measuring their engagement. We develop bag-of-words-based models in which only the occurrence of behavioral and emotional states of students is modeled and analyzed and not the order in which they occur. Behavioral and affective features are extracted from videos and analyzed by the proposed models to determine the level of engagement in an ordinal-output classification setting. Compared to the existing sequential and spatiotemporal approaches for engagement measurement, the proposed non-sequential approach improves the state-of-the-art results. According to experimental results, our method significantly improved engagement level classification accuracy on the IIITB Online SE dataset by 26% compared to sequential models and achieved engagement level classification accuracy as high as 66.58% on the DAiSEE student engagement dataset.
A reinforcement learning path planning approach for range-only underwater target localization with autonomous vehicles
Jan 17, 2023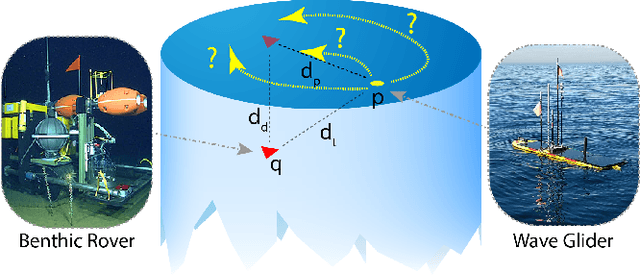
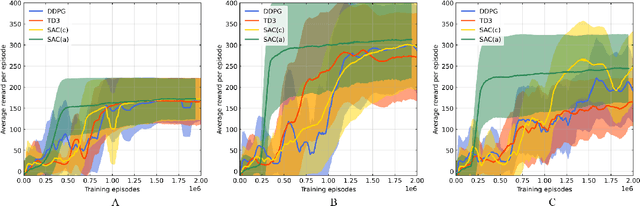
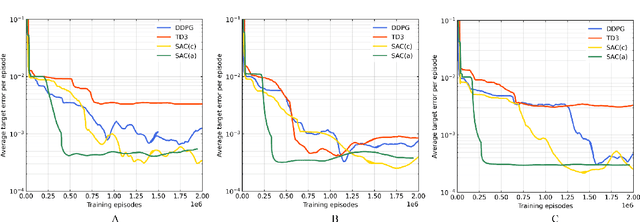
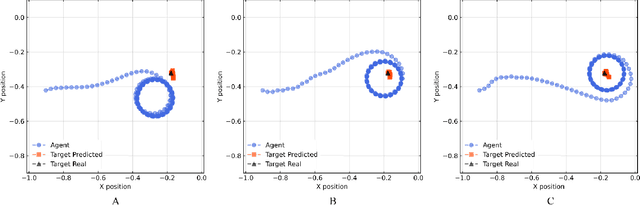
Underwater target localization using range-only and single-beacon (ROSB) techniques with autonomous vehicles has been used recently to improve the limitations of more complex methods, such as long baseline and ultra-short baseline systems. Nonetheless, in ROSB target localization methods, the trajectory of the tracking vehicle near the localized target plays an important role in obtaining the best accuracy of the predicted target position. Here, we investigate a Reinforcement Learning (RL) approach to find the optimal path that an autonomous vehicle should follow in order to increase and optimize the overall accuracy of the predicted target localization, while reducing time and power consumption. To accomplish this objective, different experimental tests have been designed using state-of-the-art deep RL algorithms. Our study also compares the results obtained with the analytical Fisher information matrix approach used in previous studies. The results revealed that the policy learned by the RL agent outperforms trajectories based on these analytical solutions, e.g. the median predicted error at the beginning of the target's localisation is 17% less. These findings suggest that using deep RL for localizing acoustic targets could be successfully applied to in-water applications that include tracking of acoustically tagged marine animals by autonomous underwater vehicles. This is envisioned as a first necessary step to validate the use of RL to tackle such problems, which could be used later on in a more complex scenarios
* Accepted at CASE2022. Code at this Github repository https://github.com/imasmitja/RLforUTracking
AlphaPose: Whole-Body Regional Multi-Person Pose Estimation and Tracking in Real-Time
Nov 07, 2022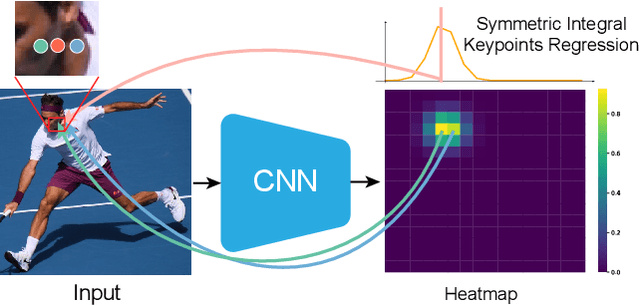
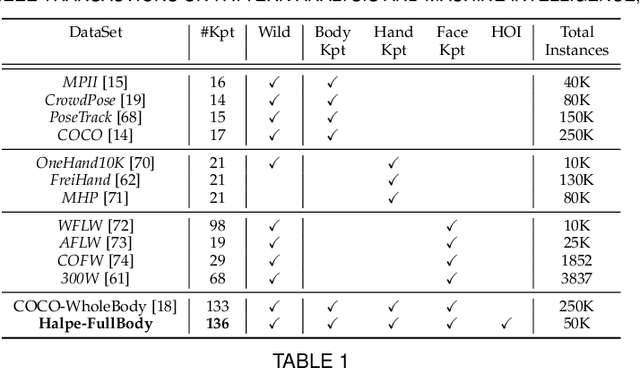
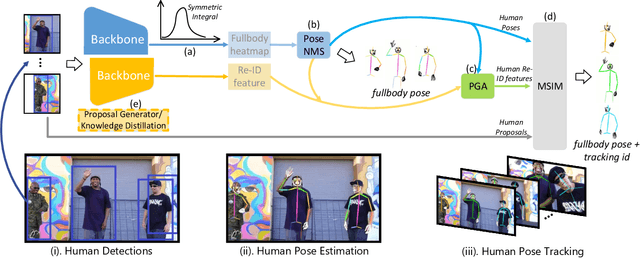
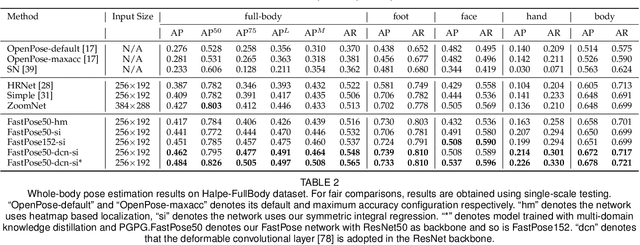
Accurate whole-body multi-person pose estimation and tracking is an important yet challenging topic in computer vision. To capture the subtle actions of humans for complex behavior analysis, whole-body pose estimation including the face, body, hand and foot is essential over conventional body-only pose estimation. In this paper, we present AlphaPose, a system that can perform accurate whole-body pose estimation and tracking jointly while running in realtime. To this end, we propose several new techniques: Symmetric Integral Keypoint Regression (SIKR) for fast and fine localization, Parametric Pose Non-Maximum-Suppression (P-NMS) for eliminating redundant human detections and Pose Aware Identity Embedding for jointly pose estimation and tracking. During training, we resort to Part-Guided Proposal Generator (PGPG) and multi-domain knowledge distillation to further improve the accuracy. Our method is able to localize whole-body keypoints accurately and tracks humans simultaneously given inaccurate bounding boxes and redundant detections. We show a significant improvement over current state-of-the-art methods in both speed and accuracy on COCO-wholebody, COCO, PoseTrack, and our proposed Halpe-FullBody pose estimation dataset. Our model, source codes and dataset are made publicly available at https://github.com/MVIG-SJTU/AlphaPose.
Taming Lagrangian Chaos with Multi-Objective Reinforcement Learning
Dec 19, 2022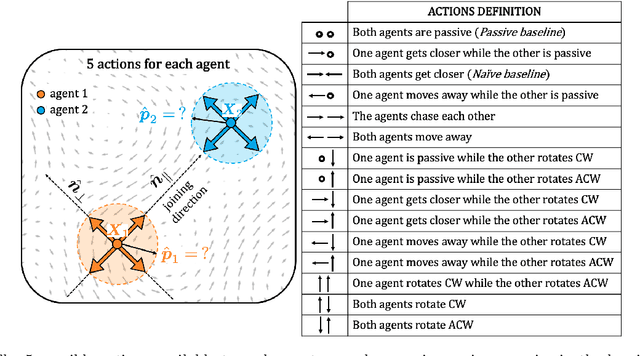

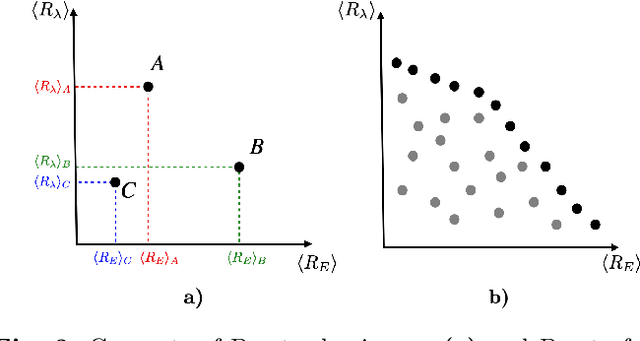
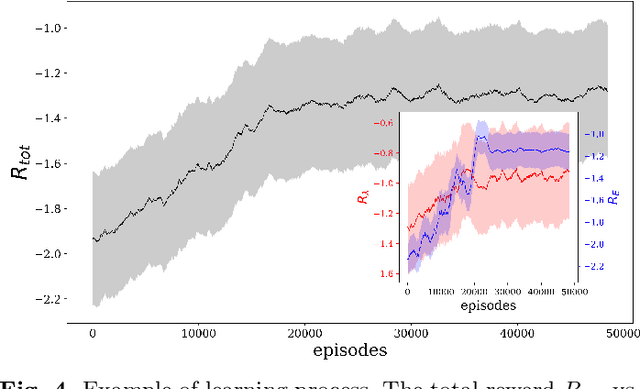
We consider the problem of two active particles in 2D complex flows with the multi-objective goals of minimizing both the dispersion rate and the energy consumption of the pair. We approach the problem by means of Multi Objective Reinforcement Learning (MORL), combining scalarization techniques together with a Q-learning algorithm, for Lagrangian drifters that have variable swimming velocity. We show that MORL is able to find a set of trade-off solutions forming an optimal Pareto frontier. As a benchmark, we show that a set of heuristic strategies are dominated by the MORL solutions. We consider the situation in which the agents cannot update their control variables continuously, but only after a discrete (decision) time, $\tau$. We show that there is a range of decision times, in between the Lyapunov time and the continuous updating limit, where Reinforcement Learning finds strategies that significantly improve over heuristics. In particular, we discuss how large decision times require enhanced knowledge of the flow, whereas for smaller $\tau$ all a priori heuristic strategies become Pareto optimal.
Safe Drone Flight with Time-Varying Backup Controllers
Jul 11, 2022
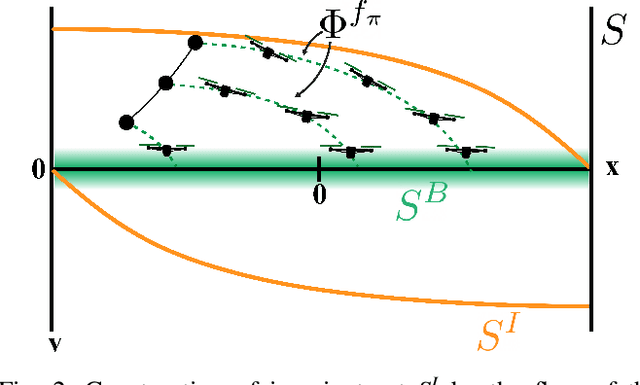
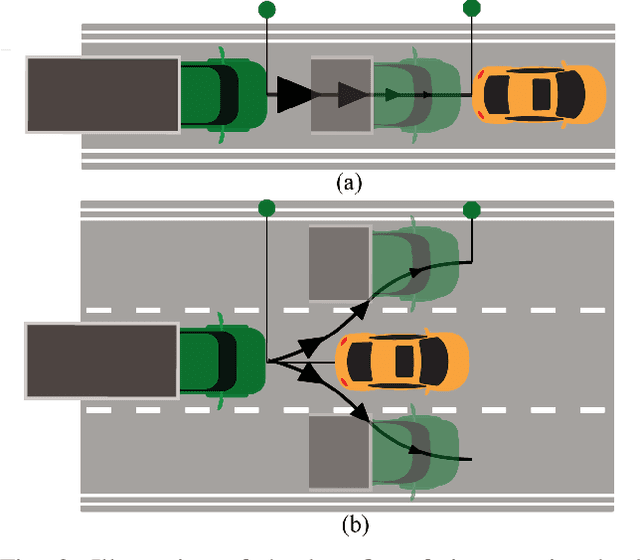
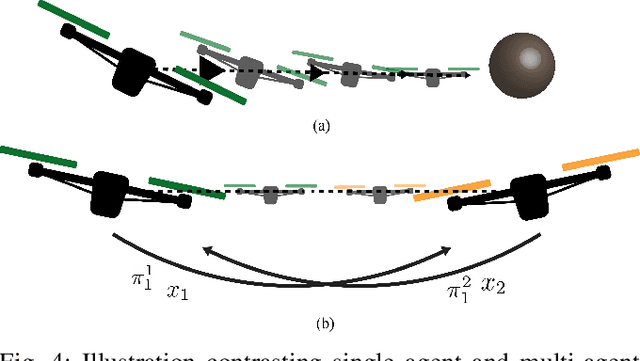
The weight, space, and power limitations of small aerial vehicles often prevent the application of modern control techniques without significant model simplifications. Moreover, high-speed agile behavior, such as that exhibited in drone racing, make these simplified models too unreliable for safety-critical control. In this work, we introduce the concept of time-varying backup controllers (TBCs): user-specified maneuvers combined with backup controllers that generate reference trajectories which guarantee the safety of nonlinear systems. TBCs reduce conservatism when compared to traditional backup controllers and can be directly applied to multi-agent coordination to guarantee safety. Theoretically, we provide conditions under which TBCs strictly reduce conservatism, describe how to switch between several TBC's and show how to embed TBCs in a multi-agent setting. Experimentally, we verify that TBCs safely increase operational freedom when filtering a pilot's actions and demonstrate robustness and computational efficiency when applied to decentralized safety filtering of two quadrotors.
A recurrent CNN for online object detection on raw radar frames
Dec 21, 2022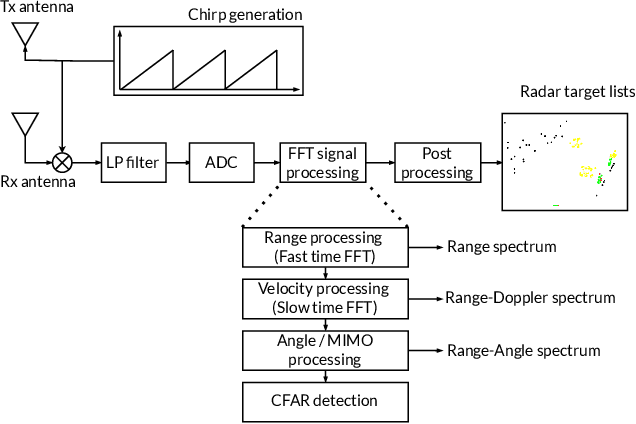
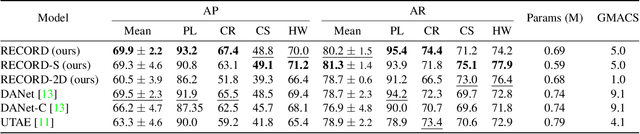


Automotive radar sensors provide valuable information for advanced driving assistance systems (ADAS). Radars can reliably estimate the distance to an object and the relative velocity, regardless of weather and light conditions. However, radar sensors suffer from low resolution and huge intra-class variations in the shape of objects. Exploiting the time information (e.g., multiple frames) has been shown to help to capture better the dynamics of objects and, therefore, the variation in the shape of objects. Most temporal radar object detectors use 3D convolutions to learn spatial and temporal information. However, these methods are often non-causal and unsuitable for real-time applications. This work presents RECORD, a new recurrent CNN architecture for online radar object detection. We propose an end-to-end trainable architecture mixing convolutions and ConvLSTMs to learn spatio-temporal dependencies between successive frames. Our model is causal and requires only the past information encoded in the memory of the ConvLSTMs to detect objects. Our experiments show such a method's relevance for detecting objects in different radar representations (range-Doppler, range-angle) and outperform state-of-the-art models on the ROD2021 and CARRADA datasets while being less computationally expensive. The code will be available soon.
CarFi: Rider Localization Using Wi-Fi CSI
Dec 21, 2022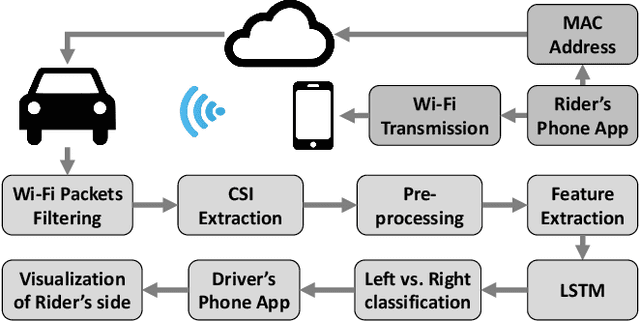

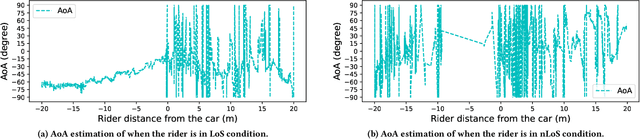
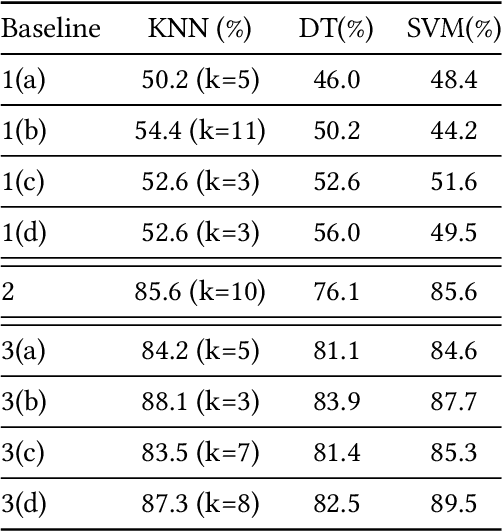
With the rise of hailing services, people are increasingly relying on shared mobility (e.g., Uber, Lyft) drivers to pick up for transportation. However, such drivers and riders have difficulties finding each other in urban areas as GPS signals get blocked by skyscrapers, in crowded environments (e.g., in stadiums, airports, and bars), at night, and in bad weather. It wastes their time, creates a bad user experience, and causes more CO2 emissions due to idle driving. In this work, we explore the potential of Wi-Fi to help drivers to determine the street side of the riders. Our proposed system is called CarFi that uses Wi-Fi CSI from two antennas placed inside a moving vehicle and a data-driven technique to determine the street side of the rider. By collecting real-world data in realistic and challenging settings by blocking the signal with other people and other parked cars, we see that CarFi is 95.44% accurate in rider-side determination in both line of sight (LoS) and non-line of sight (nLoS) conditions, and can be run on an embedded GPU in real-time.
Regional Precipitation Nowcasting Based on CycleGAN Extension
Dec 09, 2022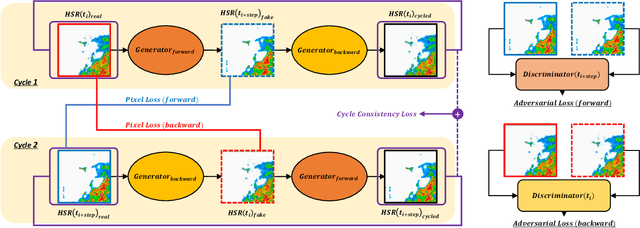

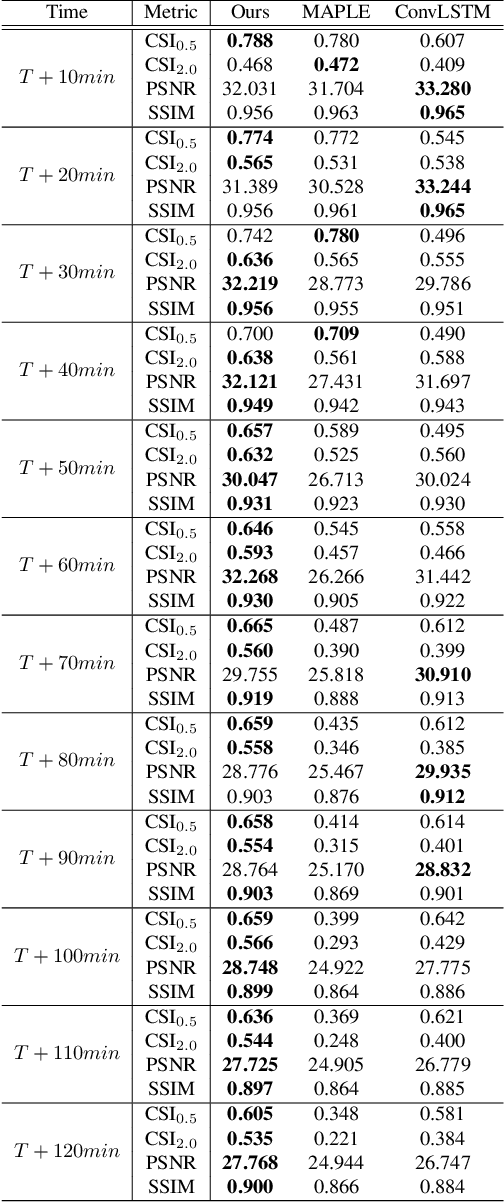
Unusually, intensive heavy rain hit the central region of Korea on August 8, 2022. Many low-lying areas were submerged, so traffic and life were severely paralyzed. It was the critical damage caused by torrential rain for just a few hours. This event reminded us of the need for a more reliable regional precipitation nowcasting method. In this paper, we bring cycle-consistent adversarial networks (CycleGAN) into the time-series domain and extend it to propose a reliable model for regional precipitation nowcasting. The proposed model generates composite hybrid surface rainfall (HSR) data after 10 minutes from the present time. Also, the proposed model provides a reliable prediction of up to 2 hours with a gradual extension of the training time steps. Unlike the existing complex nowcasting methods, the proposed model does not use recurrent neural networks (RNNs) and secures temporal causality via sequential training in the cycle. Our precipitation nowcasting method outperforms convolutional long short-term memory (ConvLSTM) based on RNNs. Additionally, we demonstrate the superiority of our approach by qualitative and quantitative comparisons against MAPLE, the McGill algorithm for precipitation nowcasting by lagrangian extrapolation, one of the real quantitative precipitation forecast (QPF) models.
Image-Based Fire Detection in Industrial Environments with YOLOv4
Dec 09, 2022
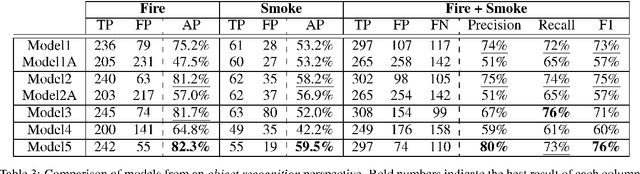

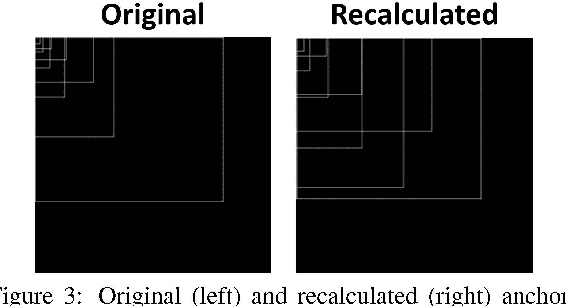
Fires have destructive power when they break out and affect their surroundings on a devastatingly large scale. The best way to minimize their damage is to detect the fire as quickly as possible before it has a chance to grow. Accordingly, this work looks into the potential of AI to detect and recognize fires and reduce detection time using object detection on an image stream. Object detection has made giant leaps in speed and accuracy over the last six years, making real-time detection feasible. To our end, we collected and labeled appropriate data from several public sources, which have been used to train and evaluate several models based on the popular YOLOv4 object detector. Our focus, driven by a collaborating industrial partner, is to implement our system in an industrial warehouse setting, which is characterized by high ceilings. A drawback of traditional smoke detectors in this setup is that the smoke has to rise to a sufficient height. The AI models brought forward in this research managed to outperform these detectors by a significant amount of time, providing precious anticipation that could help to minimize the effects of fires further.