 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accelerating Innovation in 6G Research: Real-Time Capable SDR System Architecture for Rapid Prototyping
Feb 22, 2024
The next global mobile communication standard 6G strives to push the technological limits of radio frequency (RF) communication even further than its predecessors: Data rates beyond 100 Gbit/s, RF bandwidths above 1 GHz, and sub-millisecond latency necessitate very high performance development tools to enable the extent of innovation required for 6G's likely features. We propose a new SDR firmware and software architecture designed explicitly to meet these challenging requirements. It relies on Ethernet and commercial off-the-shelf network and server components to maximize flexibility and to reduce costs. We analyze state-of-the-art solutions (USRP X440 and other RFSoC-based systems), derive architectural design goals, explain resulting design decision in detail, and exemplify our architecture's implementation on the XCZU48DR RFSoC. Finally, we prove its performance via measurements and outline how the architecture surpasses the state-of-the-art with respect to sustained RF recording while maintaining high Ethernet bandwidth efficiency. Building a micro-Doppler radar example, we demonstrate its real-time and rapid application development capabilities.
Geometric Neural Network based on Phase Space for BCI decoding
Mar 08, 2024
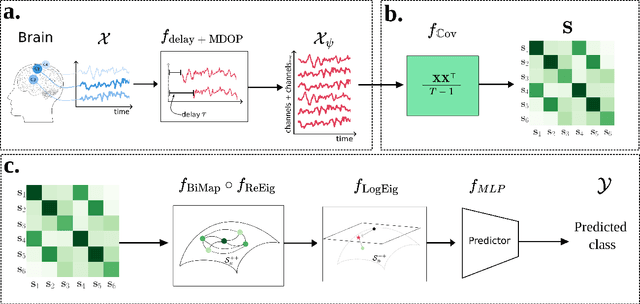
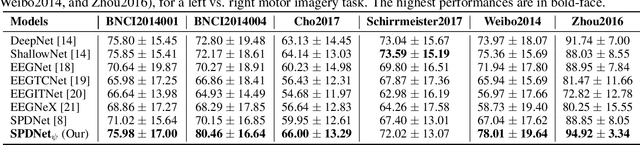
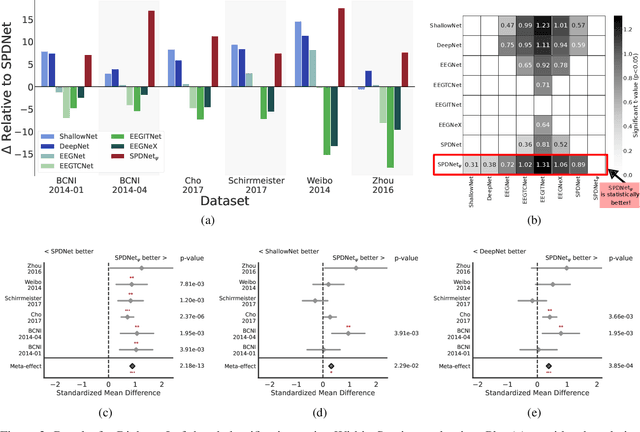
The integration of Deep Learning (DL) algorithms on brain signal analysis is still in its nascent stages compared to their success in fields like Computer Vision, especially in Brain-Computer Interface (BCI), where the brain activity is decoded to control external devices without requiring muscle control. Electroencephalography (EEG) is a widely adopted choice for designing BCI systems due to its non-invasive and cost-effective nature and excellent temporal resolution. Still, it comes at the expense of limited training data, poor signal-to-noise, and a large variability across and within-subject recordings. Finally, setting up a BCI system with many electrodes takes a long time, hindering the widespread adoption of reliable DL architectures in BCIs outside research laboratories. To improve adoption, we need to improve user comfort using, for instance, reliable algorithms that operate with few electrodes. \textbf{Approach:} Our research aims to develop a DL algorithm that delivers effective results with a limited number of electrodes. Taking advantage of the Augmented Covariance Method with SPDNet, we propose the SPDNet$_{\psi}$ architecture and analyze its performance and computational impact, as well as the interpretability of the results. The evaluation is conducted on 5-fold cross-validation, using only three electrodes positioned above the Motor Cortex. The methodology was tested on nearly 100 subjects from several open-source datasets using the Mother Of All BCI Benchmark (MOABB) framework. \textbf{Main results:} The results of our SPDNet$_{\psi}$ demonstrate that the augmented approach combined with the SPDNet significantly outperforms all the current state-of-the-art DL architecture in MI decoding. \textbf{Significance:} This new architecture is explainable, with a low number of trainable parameters and a reduced carbon footprint.
Decoupling Degradations with Recurrent Network for Video Restoration in Under-Display Camera
Mar 08, 2024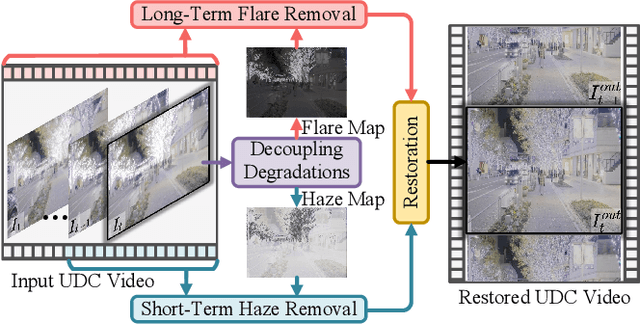
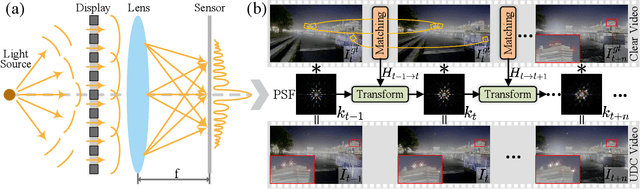

Under-display camera (UDC) systems are the foundation of full-screen display devices in which the lens mounts under the display. The pixel array of light-emitting diodes used for display diffracts and attenuates incident light, causing various degradations as the light intensity changes. Unlike general video restoration which recovers video by treating different degradation factors equally, video restoration for UDC systems is more challenging that concerns removing diverse degradation over time while preserving temporal consistency. In this paper, we introduce a novel video restoration network, called D$^2$RNet, specifically designed for UDC systems. It employs a set of Decoupling Attention Modules (DAM) that effectively separate the various video degradation factors. More specifically, a soft mask generation function is proposed to formulate each frame into flare and haze based on the diffraction arising from incident light of different intensities, followed by the proposed flare and haze removal components that leverage long- and short-term feature learning to handle the respective degradations. Such a design offers an targeted and effective solution to eliminating various types of degradation in UDC systems. We further extend our design into multi-scale to overcome the scale-changing of degradation that often occur in long-range videos. To demonstrate the superiority of D$^2$RNet, we propose a large-scale UDC video benchmark by gathering HDR videos and generating realistically degraded videos using the point spread function measured by a commercial UDC system. Extensive quantitative and qualitative evaluations demonstrate the superiority of D$^2$RNet compared to other state-of-the-art video restoration and UDC image restoration methods. Code is available at https://github.com/ChengxuLiu/DDRNet.git
Efficient Episodic Memory Utilization of Cooperative Multi-Agent Reinforcement Learning
Mar 07, 2024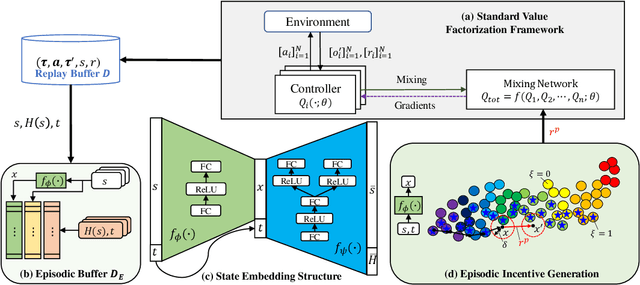

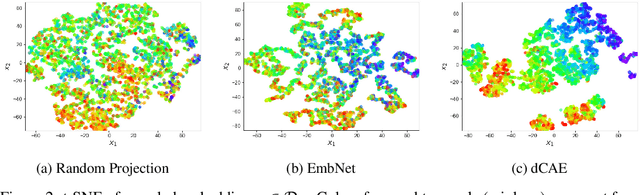
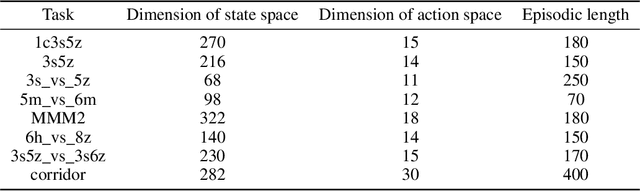
In cooperative multi-agent reinforcement learning (MARL), agents aim to achieve a common goal, such as defeating enemies or scoring a goal. Existing MARL algorithms are effective but still require significant learning time and often get trapped in local optima by complex tasks, subsequently failing to discover a goal-reaching policy. To address this, we introduce Efficient episodic Memory Utilization (EMU) for MARL, with two primary objectives: (a) accelerating reinforcement learning by leveraging semantically coherent memory from an episodic buffer and (b) selectively promoting desirable transitions to prevent local convergence. To achieve (a), EMU incorporates a trainable encoder/decoder structure alongside MARL, creating coherent memory embeddings that facilitate exploratory memory recall. To achieve (b), EMU introduces a novel reward structure called episodic incentive based on the desirability of states. This reward improves the TD target in Q-learning and acts as an additional incentive for desirable transitions. We provide theoretical support for the proposed incentive and demonstrate the effectiveness of EMU compared to conventional episodic control. The proposed method is evaluated in StarCraft II and Google Research Football, and empirical results indicate further performance improvement over state-of-the-art methods.
Impact of the Antenna on the Sub-Terahertz Indoor Channel Characteristics: An Experimental Approach
Mar 07, 2024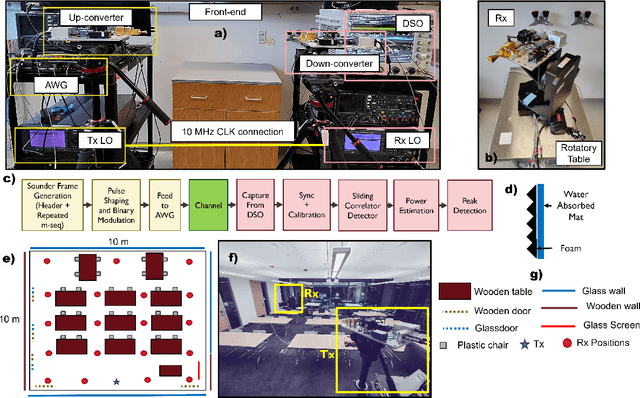
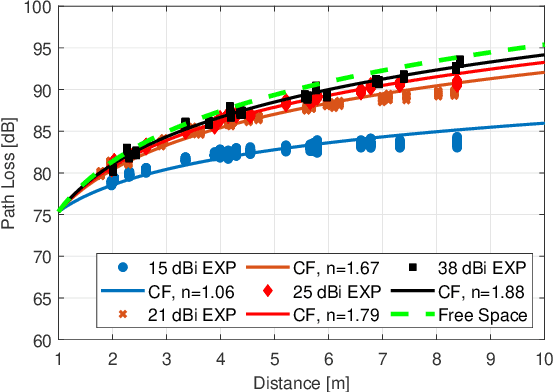
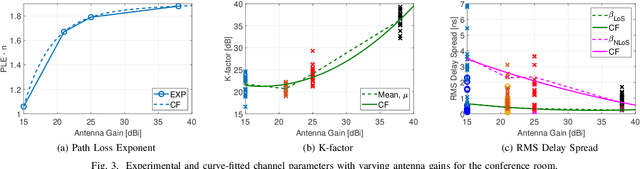
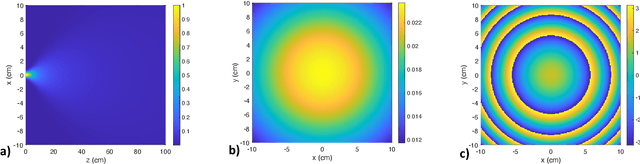
Terahertz-band (100 GHz-10 THz) communication is a promising radio technology envisioned to enable ultra-high data rate, reliable and low-latency wireless connectivity in next-generation wireless systems. However, the low transmission power of THz transmitters, the need for high gain directional antennas, and the complex interaction of THz radiation with common objects along the propagation path make crucial the understanding of the THz channel. In this paper, we conduct an extensive channel measurement campaign in an indoor setting (i.e., a conference room) through a channel sounder with 0.1 ns time resolution and 20 GHz bandwidth at 140 GHz. Particularly, the impact of different antenna directivities (and, thus, beam widths) on the channel characteristics is extensively studied. The experimentally obtained dataset is processed to develop the path loss model and, subsequently, derive key channel metrics such as the path loss exponent, delay spread, and K-factor. The results highlight the multi-faceted impact of the antenna gain on the channel and, by extension, the wireless system and, thus, show that an antenna-agnostic channel model cannot capture the propagation characteristics of the THz channel.
GRAWA: Gradient-based Weighted Averaging for Distributed Training of Deep Learning Models
Mar 07, 2024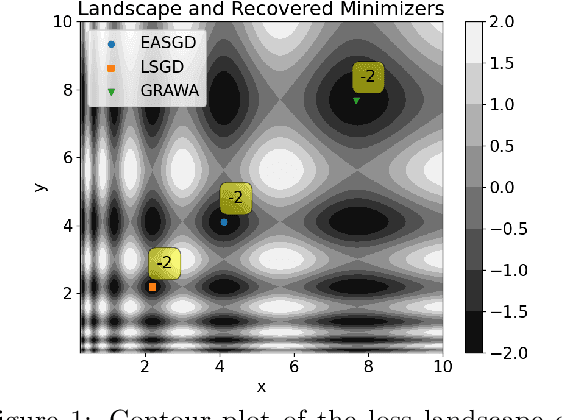
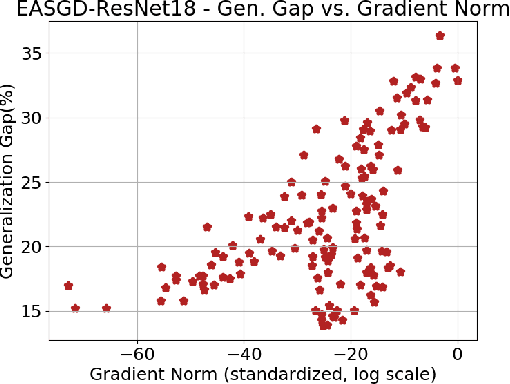
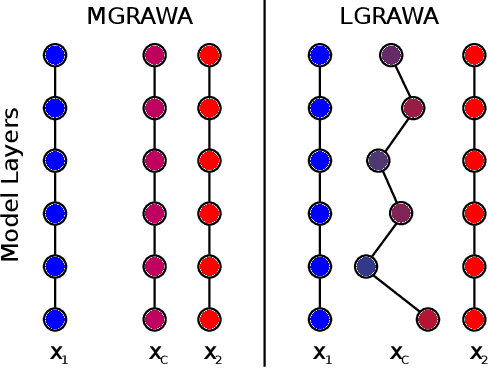

We study distributed training of deep learning models in time-constrained environments. We propose a new algorithm that periodically pulls workers towards the center variable computed as a weighted average of workers, where the weights are inversely proportional to the gradient norms of the workers such that recovering the flat regions in the optimization landscape is prioritized. We develop two asynchronous variants of the proposed algorithm that we call Model-level and Layer-level Gradient-based Weighted Averaging (resp. MGRAWA and LGRAWA), which differ in terms of the weighting scheme that is either done with respect to the entire model or is applied layer-wise. On the theoretical front, we prove the convergence guarantee for the proposed approach in both convex and non-convex settings. We then experimentally demonstrate that our algorithms outperform the competitor methods by achieving faster convergence and recovering better quality and flatter local optima. We also carry out an ablation study to analyze the scalability of the proposed algorithms in more crowded distributed training environments. Finally, we report that our approach requires less frequent communication and fewer distributed updates compared to the state-of-the-art baselines.
Matched-filter Precoded Rate Splitting Multiple Access: A Simple and Energy-efficient Design
Mar 07, 2024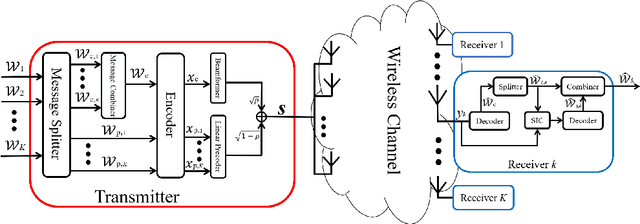
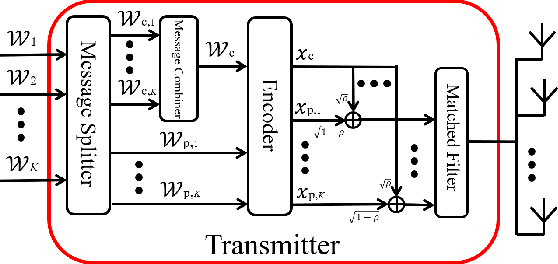
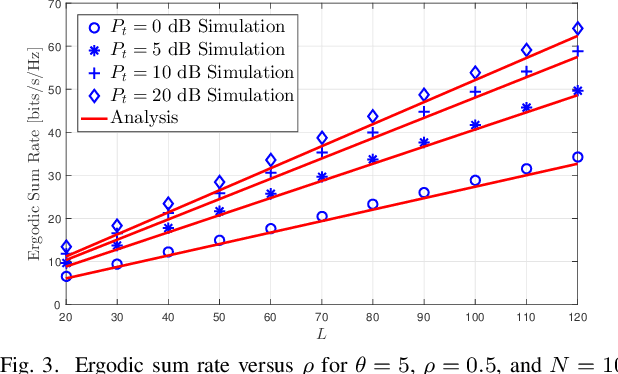
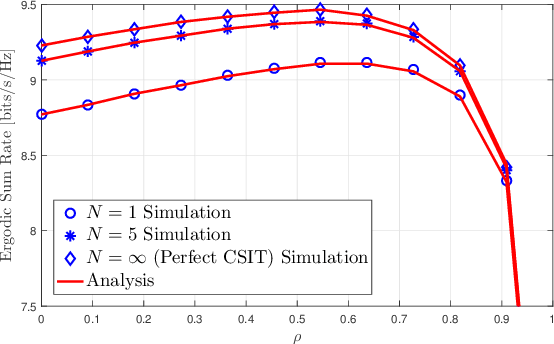
We introduce an energy-efficient downlink rate splitting multiple access (RSMA) scheme, employing a simple matched filter (MF) for precoding. We consider a transmitter equipped with multiple antennas, serving several single-antenna users at the same frequency-time resource, each with distinct message requests. Within the conventional 1-layer RSMA framework, requested messages undergo splitting into common and private streams, which are then precoded separately before transmission. In contrast, we propose a novel strategy where only an MF is employed to precode both the common and private streams in RSMA, promising significantly improved energy efficiency and reduced complexity. We demonstrate that this MF-precoded RSMA achieves the same delivery performance as conventional RSMA, where the common stream is beamformed using maximal ratio transmission (MRT) and the private streams are precoded by MF. Taking into account imperfect channel state information at the transmitter, we proceed to analyze the delivery performance of the MF-precoded RSMA. We derive the ergodic rates for decoding the common and private streams at a target user respectively in the massive MIMO regime. Finally, numerical simulations validate the accuracy of our analytical models, as well as demonstrate the advantages over conventional RSMA.
Scalable, Simulation-Guided Compliant Tactile Finger Design
Mar 07, 2024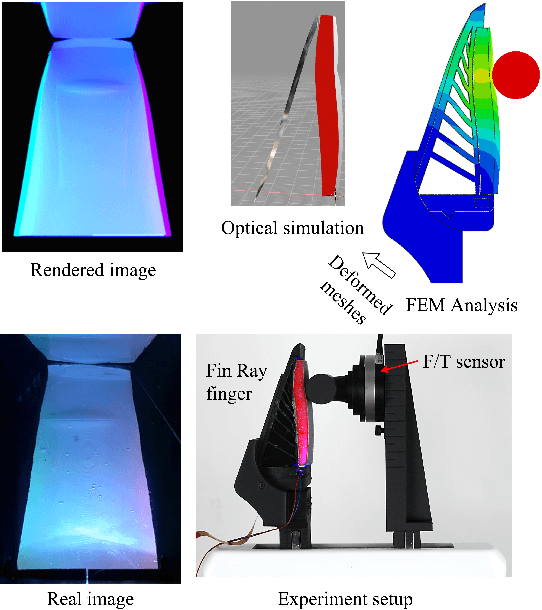
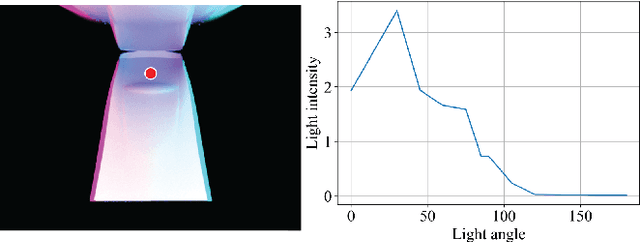


Compliant grippers enable robots to work with humans in unstructured environments. In general, these grippers can improve with tactile sensing to estimate the state of objects around them to precisely manipulate objects. However, co-designing compliant structures with high-resolution tactile sensing is a challenging task. We propose a simulation framework for the end-to-end forward design of GelSight Fin Ray sensors. Our simulation framework consists of mechanical simulation using the finite element method (FEM) and optical simulation including physically based rendering (PBR). To simulate the fluorescent paint used in these GelSight Fin Rays, we propose an efficient method that can be directly integrated in PBR. Using the simulation framework, we investigate design choices available in the compliant grippers, namely gel pad shapes, illumination conditions, Fin Ray gripper sizes, and Fin Ray stiffness. This infrastructure enables faster design and prototype time frames of new Fin Ray sensors that have various sensing areas, ranging from 48 mm $\times$ \18 mm to 70 mm $\times$ 35 mm. Given the parameters we choose, we can thus optimize different Fin Ray designs and show their utility in grasping day-to-day objects.
Almost Global Asymptotic Trajectory Tracking for Fully-Actuated Mechanical Systems on Homogeneous Riemannian Manifolds
Mar 07, 2024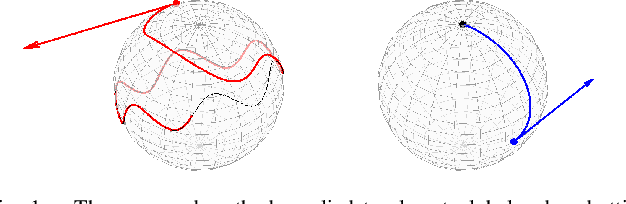

In this work, we address the design of tracking controllers that drive a mechanical system's state asymptotically towards a reference trajectory. Motivated by aerospace and robotics applications, we consider fully-actuated systems evolving on the broad class of homogeneous spaces (encompassing all vector spaces, Lie groups, and spheres of any dimension). In this setting, the transitive action of a Lie group on the configuration manifold enables an intrinsic description of the tracking error as an element of the state space, even in the absence of a group structure on the configuration manifold itself (e.g., for $\mathbb{S}^2$). Such an error state facilitates the design of a generalized control policy depending smoothly on state and time that drives this geometric tracking error to a designated origin from almost every initial condition, thereby guaranteeing almost global convergence to the reference trajectory. Moreover, the proposed controller simplifies naturally when specialized to a Lie group or the $n$-sphere. In summary, we propose a unified, intrinsic controller guaranteeing almost global asymptotic trajectory tracking for fully-actuated mechanical systems evolving on a broader class of manifolds. We apply the method to an axisymmetric satellite and an omnidirectional aerial robot.
Soft-constrained Schrodinger Bridge: a Stochastic Control Approach
Mar 04, 2024

Schr\"{o}dinger bridge can be viewed as a continuous-time stochastic control problem where the goal is to find an optimally controlled diffusion process with a pre-specified terminal distribution $\mu_T$. We propose to generalize this stochastic control problem by allowing the terminal distribution to differ from $\mu_T$ but penalizing the Kullback-Leibler divergence between the two distributions. We call this new control problem soft-constrained Schr\"{o}dinger bridge (SSB). The main contribution of this work is a theoretical derivation of the solution to SSB, which shows that the terminal distribution of the optimally controlled process is a geometric mixture of $\mu_T$ and some other distribution. This result is further extended to a time series setting. One application of SSB is the development of robust generative diffusion models. We propose a score matching-based algorithm for sampling from geometric mixtures and showcase its use via a numerical example for the MNIST data set.