 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
What is Cognitive Computing? An Architecture and State of The Art
Jan 02, 2023
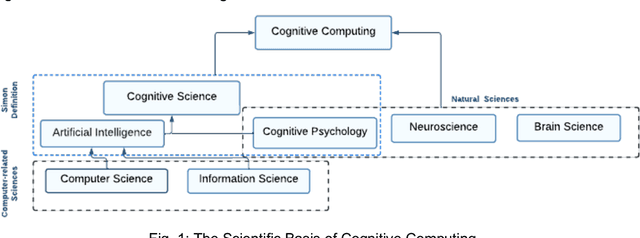
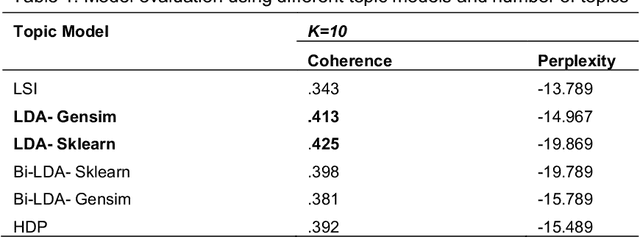
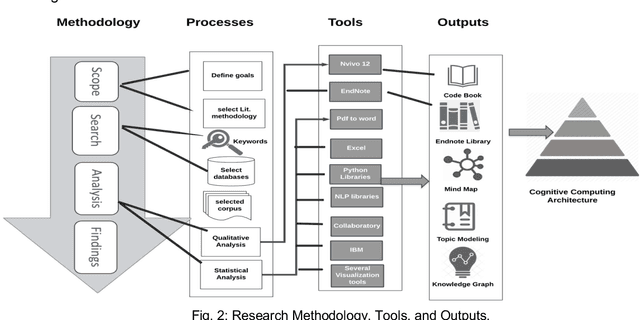
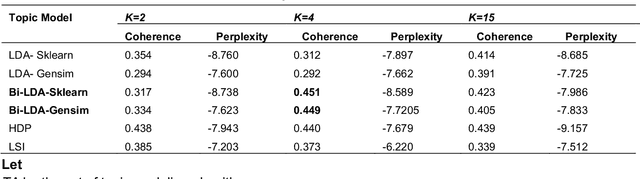
Cognitive Computing (COC) aims to build highly cognitive machines with low computational resources that respond in real-time. However, scholarly literature shows varying research areas and various interpretations of COC. This calls for a cohesive architecture that delineates the nature of COC. We argue that if Herbert Simon considered the design science is the science of artificial, cognitive systems are the products of cognitive science or 'the newest science of the artificial'. Therefore, building a conceptual basis for COC is an essential step into prospective cognitive computing-based systems. This paper proposes an architecture of COC through analyzing the literature on COC using a myriad of statistical analysis methods. Then, we compare the statistical analysis results with previous qualitative analysis results to confirm our findings. The study also comprehensively surveys the recent research on COC to identify the state of the art and connect the advances in varied research disciplines in COC. The study found that there are three underlaying computing paradigms, Von-Neuman, Neuromorphic Engineering and Quantum Computing, that comprehensively complement the structure of cognitive computation. The research discuss possible applications and open research directions under the COC umbrella.
Functional Optimization Reinforcement Learning for Real-Time Bidding
Jul 03, 2022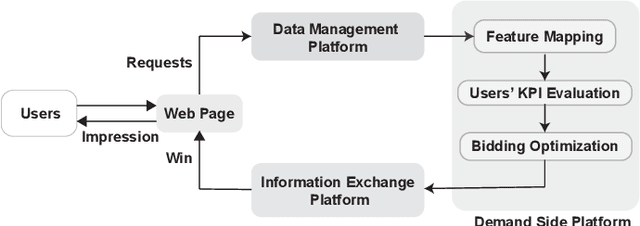
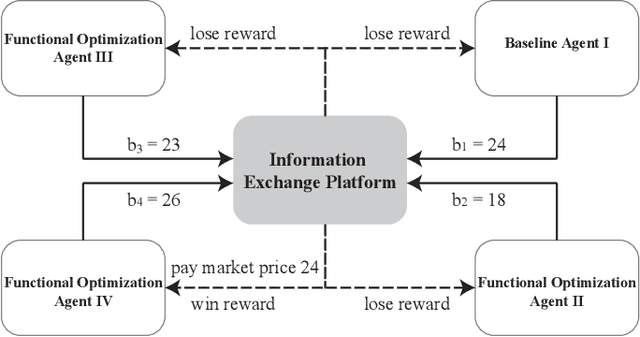
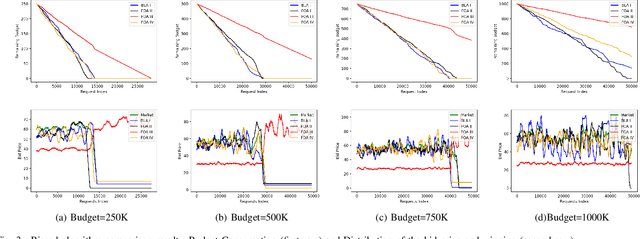
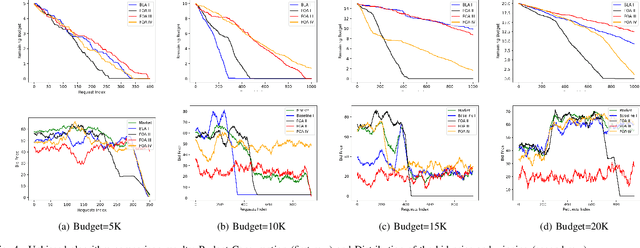
Real-time bidding is the new paradigm of programmatic advertising. An advertiser wants to make the intelligent choice of utilizing a \textbf{Demand-Side Platform} to improve the performance of their ad campaigns. Existing approaches are struggling to provide a satisfactory solution for bidding optimization due to stochastic bidding behavior. In this paper, we proposed a multi-agent reinforcement learning architecture for RTB with functional optimization. We designed four agents bidding environment: three Lagrange-multiplier based functional optimization agents and one baseline agent (without any attribute of functional optimization) First, numerous attributes have been assigned to each agent, including biased or unbiased win probability, Lagrange multiplier, and click-through rate. In order to evaluate the proposed RTB strategy's performance, we demonstrate the results on ten sequential simulated auction campaigns. The results show that agents with functional actions and rewards had the most significant average winning rate and winning surplus, given biased and unbiased winning information respectively. The experimental evaluations show that our approach significantly improve the campaign's efficacy and profitability.
User-Conditioned Neural Control Policies for Mobile Robotics
Dec 15, 2022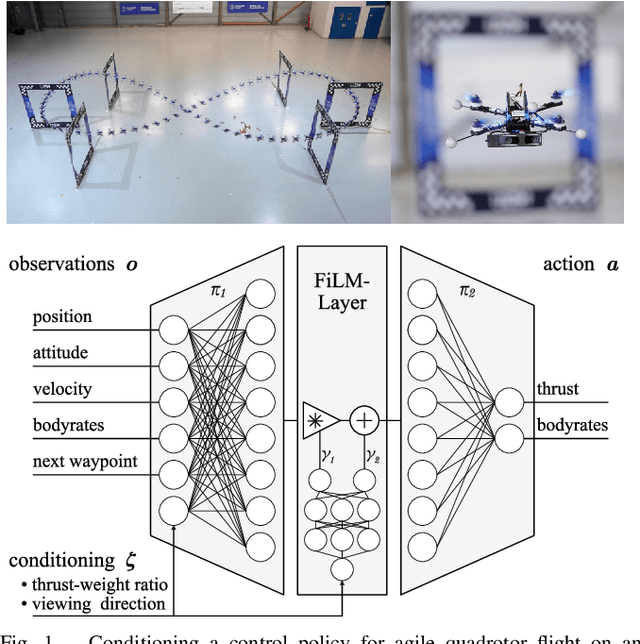



Recently, learning-based controllers have been shown to push mobile robotic systems to their limits and provide the robustness needed for many real-world applications. However, only classical optimization-based control frameworks offer the inherent flexibility to be dynamically adjusted during execution by, for example, setting target speeds or actuator limits. We present a framework to overcome this shortcoming of neural controllers by conditioning them on an auxiliary input. This advance is enabled by including a feature-wise linear modulation layer (FiLM). We use model-free reinforcement-learning to train quadrotor control policies for the task of navigating through a sequence of waypoints in minimum time. By conditioning the policy on the maximum available thrust or the viewing direction relative to the next waypoint, a user can regulate the aggressiveness of the quadrotor's flight during deployment. We demonstrate in simulation and in real-world experiments that a single control policy can achieve close to time-optimal flight performance across the entire performance envelope of the robot, reaching up to 60 km/h and 4.5g in acceleration. The ability to guide a learned controller during task execution has implications beyond agile quadrotor flight, as conditioning the control policy on human intent helps safely bringing learning based systems out of the well-defined laboratory environment into the wild.
Random Feature Models for Learning Interacting Dynamical Systems
Dec 11, 2022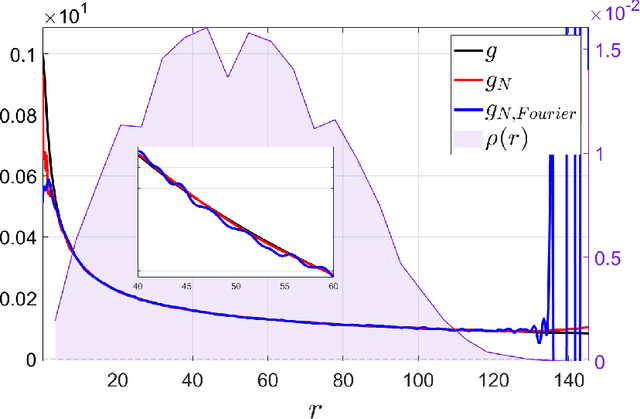

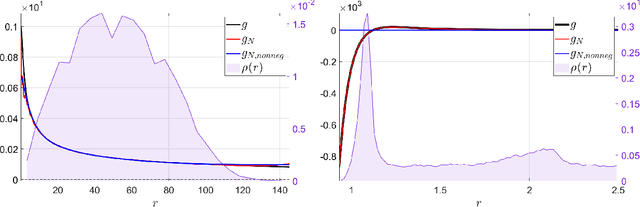

Particle dynamics and multi-agent systems provide accurate dynamical models for studying and forecasting the behavior of complex interacting systems. They often take the form of a high-dimensional system of differential equations parameterized by an interaction kernel that models the underlying attractive or repulsive forces between agents. We consider the problem of constructing a data-based approximation of the interacting forces directly from noisy observations of the paths of the agents in time. The learned interaction kernels are then used to predict the agents behavior over a longer time interval. The approximation developed in this work uses a randomized feature algorithm and a sparse randomized feature approach. Sparsity-promoting regression provides a mechanism for pruning the randomly generated features which was observed to be beneficial when one has limited data, in particular, leading to less overfitting than other approaches. In addition, imposing sparsity reduces the kernel evaluation cost which significantly lowers the simulation cost for forecasting the multi-agent systems. Our method is applied to various examples, including first-order systems with homogeneous and heterogeneous interactions, second order homogeneous systems, and a new sheep swarming system.
Scalable and Sample Efficient Distributed Policy Gradient Algorithms in Multi-Agent Networked Systems
Dec 13, 2022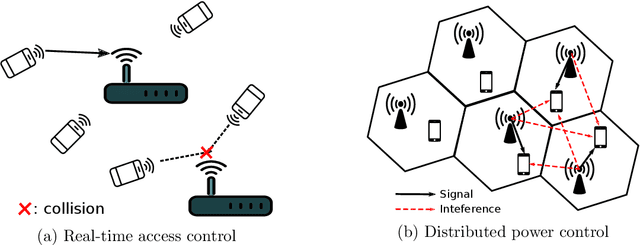
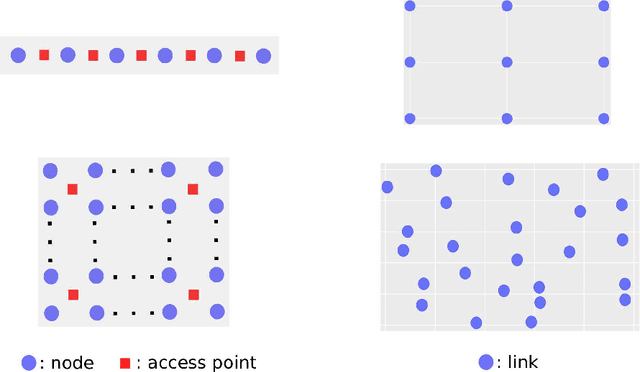
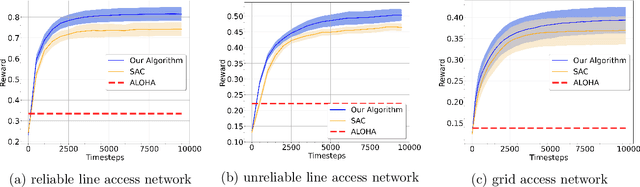
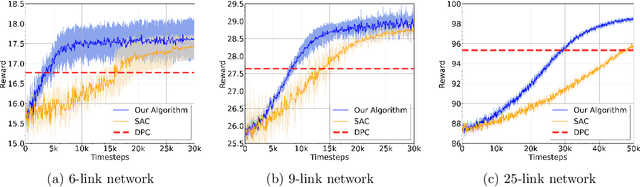
This paper studies a class of multi-agent reinforcement learning (MARL) problems where the reward that an agent receives depends on the states of other agents, but the next state only depends on the agent's own current state and action. We name it REC-MARL standing for REward-Coupled Multi-Agent Reinforcement Learning. REC-MARL has a range of important applications such as real-time access control and distributed power control in wireless networks. This paper presents a distributed and optimal policy gradient algorithm for REC-MARL. The proposed algorithm is distributed in two aspects: (i) the learned policy is a distributed policy that maps a local state of an agent to its local action and (ii) the learning/training is distributed, during which each agent updates its policy based on its own and neighbors' information. The learned policy is provably optimal among all local policies and its regret bounds depend on the dimension of local states and actions. This distinguishes our result from most existing results on MARL, which often obtain stationary-point policies. The experimental results of our algorithm for the real-time access control and power control in wireless networks show that our policy significantly outperforms the state-of-the-art algorithms and well-known benchmarks.
Decentralized Online Regularized Learning Over Random Time-Varying Graphs
Jun 14, 2022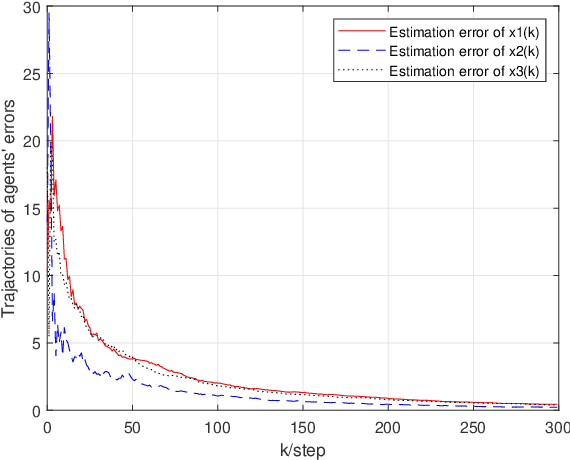
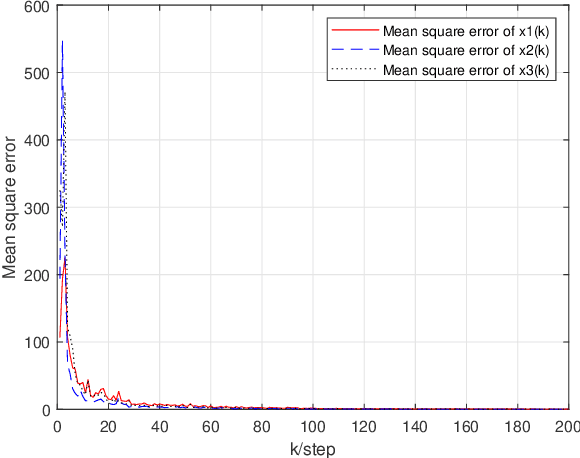
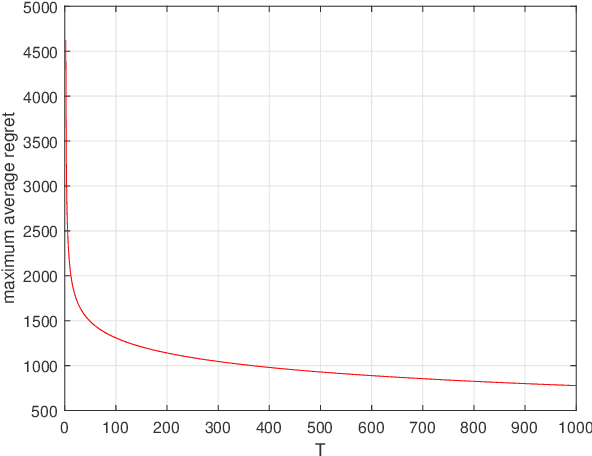
We study the decentralized online regularized linear regression algorithm over random time-varying graphs. At each time step, every node runs an online estimation algorithm consisting of an innovation term processing its own new measurement, a consensus term taking a weighted sum of estimations of its own and its neighbors with additive and multiplicative communication noises and a regularization term preventing over-fitting. It is not required that the regression matrices and graphs satisfy special statistical assumptions such as mutual independence, spatio-temporal independence or stationarity. We develop the nonnegative supermartingale inequality of the estimation error, and prove that the estimations of all nodes converge to the unknown true parameter vector almost surely if the algorithm gains, graphs and regression matrices jointly satisfy the sample path spatio-temporal persistence of excitation condition. Especially, this condition holds by choosing appropriate algorithm gains if the graphs are uniformly conditionally jointly connected and conditionally balanced, and the regression models of all nodes are uniformly conditionally spatio-temporally jointly observable, under which the algorithm converges in mean square and almost surely. In addition, we prove that the regret upper bound $\mathcal O(T^{1-\tau}\ln T)$, where $\tau\in (0.5,1)$ is a constant depending on the algorithm gains.
Generative Anomaly Detection for Time Series Datasets
Jun 28, 2022
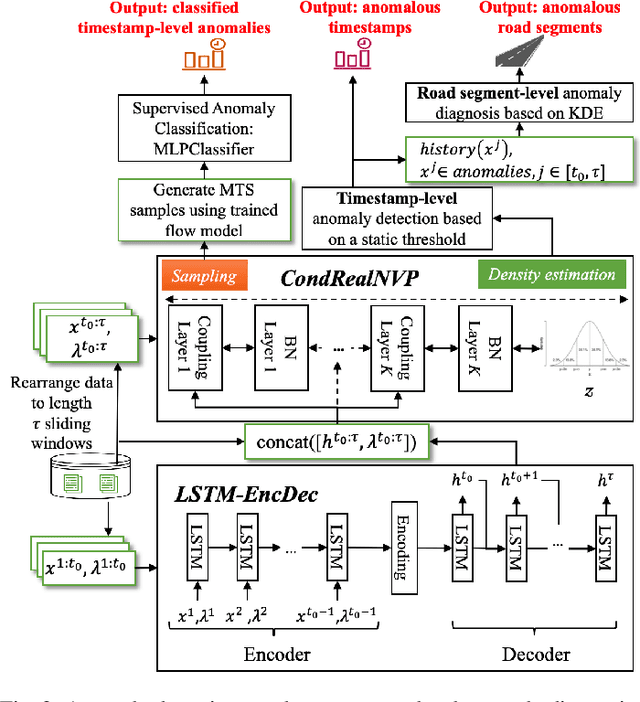

Traffic congestion anomaly detection is of paramount importance in intelligent traffic systems. The goals of transportation agencies are two-fold: to monitor the general traffic conditions in the area of interest and to locate road segments under abnormal congestion states. Modeling congestion patterns can achieve these goals for citywide roadways, which amounts to learning the distribution of multivariate time series (MTS). However, existing works are either not scalable or unable to capture the spatial-temporal information in MTS simultaneously. To this end, we propose a principled and comprehensive framework consisting of a data-driven generative approach that can perform tractable density estimation for detecting traffic anomalies. Our approach first clusters segments in the feature space and then uses conditional normalizing flow to identify anomalous temporal snapshots at the cluster level in an unsupervised setting. Then, we identify anomalies at the segment level by using a kernel density estimator on the anomalous cluster. Extensive experiments on synthetic datasets show that our approach significantly outperforms several state-of-the-art congestion anomaly detection and diagnosis methods in terms of Recall and F1-Score. We also use the generative model to sample labeled data, which can train classifiers in a supervised setting, alleviating the lack of labeled data for anomaly detection in sparse settings.
Look Beyond Bias with Entropic Adversarial Data Augmentation
Jan 10, 2023
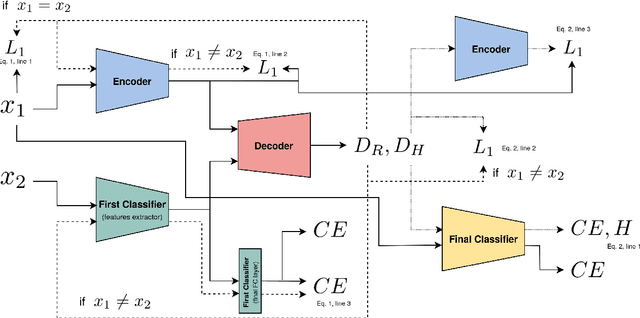

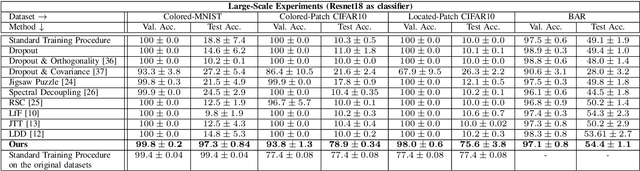
Deep neural networks do not discriminate between spurious and causal patterns, and will only learn the most predictive ones while ignoring the others. This shortcut learning behaviour is detrimental to a network's ability to generalize to an unknown test-time distribution in which the spurious correlations do not hold anymore. Debiasing methods were developed to make networks robust to such spurious biases but require to know in advance if a dataset is biased and make heavy use of minority counterexamples that do not display the majority bias of their class. In this paper, we argue that such samples should not be necessarily needed because the ''hidden'' causal information is often also contained in biased images. To study this idea, we propose 3 publicly released synthetic classification benchmarks, exhibiting predictive classification shortcuts, each of a different and challenging nature, without any minority samples acting as counterexamples. First, we investigate the effectiveness of several state-of-the-art strategies on our benchmarks and show that they do not yield satisfying results on them. Then, we propose an architecture able to succeed on our benchmarks, despite their unusual properties, using an entropic adversarial data augmentation training scheme. An encoder-decoder architecture is tasked to produce images that are not recognized by a classifier, by maximizing the conditional entropy of its outputs, and keep as much as possible of the initial content. A precise control of the information destroyed, via a disentangling process, enables us to remove the shortcut and leave everything else intact. Furthermore, results competitive with the state-of-the-art on the BAR dataset ensure the applicability of our method in real-life situations.
Language Models sounds the Death Knell of Knowledge Graphs
Jan 10, 2023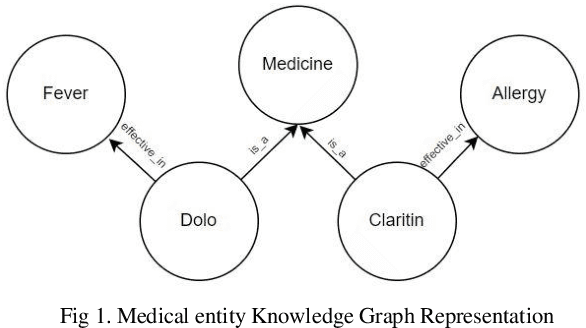
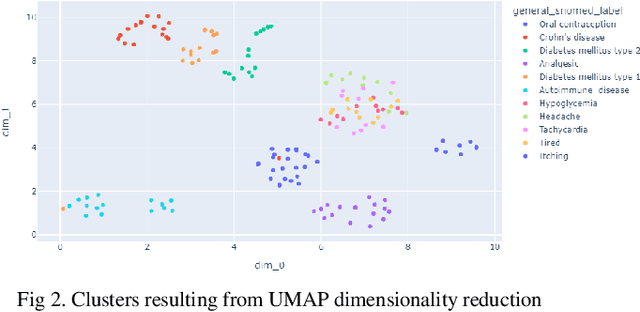
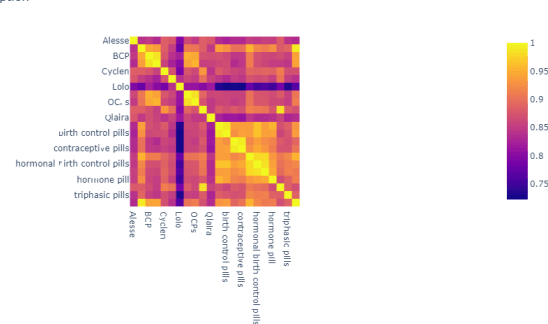
Healthcare domain generates a lot of unstructured and semi-structured text. Natural Language processing (NLP) has been used extensively to process this data. Deep Learning based NLP especially Large Language Models (LLMs) such as BERT have found broad acceptance and are used extensively for many applications. A Language Model is a probability distribution over a word sequence. Self-supervised Learning on a large corpus of data automatically generates deep learning-based language models. BioBERT and Med-BERT are language models pre-trained for the healthcare domain. Healthcare uses typical NLP tasks such as question answering, information extraction, named entity recognition, and search to simplify and improve processes. However, to ensure robust application of the results, NLP practitioners need to normalize and standardize them. One of the main ways of achieving normalization and standardization is the use of Knowledge Graphs. A Knowledge Graph captures concepts and their relationships for a specific domain, but their creation is time-consuming and requires manual intervention from domain experts, which can prove expensive. SNOMED CT (Systematized Nomenclature of Medicine -- Clinical Terms), Unified Medical Language System (UMLS), and Gene Ontology (GO) are popular ontologies from the healthcare domain. SNOMED CT and UMLS capture concepts such as disease, symptoms and diagnosis and GO is the world's largest source of information on the functions of genes. Healthcare has been dealing with an explosion in information about different types of drugs, diseases, and procedures. This paper argues that using Knowledge Graphs is not the best solution for solving problems in this domain. We present experiments using LLMs for the healthcare domain to demonstrate that language models provide the same functionality as knowledge graphs, thereby making knowledge graphs redundant.
Advanced Data Augmentation Approaches: A Comprehensive Survey and Future directions
Jan 07, 2023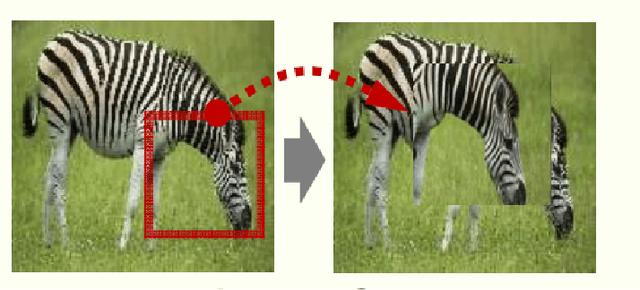
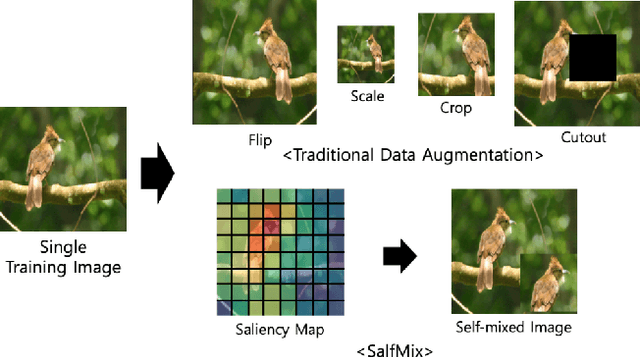


Deep learning (DL) algorithms have shown significant performance in various computer vision tasks. However, having limited labelled data lead to a network overfitting problem, where network performance is bad on unseen data as compared to training data. Consequently, it limits performance improvement. To cope with this problem, various techniques have been proposed such as dropout, normalization and advanced data augmentation. Among these, data augmentation, which aims to enlarge the dataset size by including sample diversity, has been a hot topic in recent times. In this article, we focus on advanced data augmentation techniques. we provide a background of data augmentation, a novel and comprehensive taxonomy of reviewed data augmentation techniques, and the strengths and weaknesses (wherever possible) of each technique. We also provide comprehensive results of the data augmentation effect on three popular computer vision tasks, such as image classification, object detection and semantic segmentation. For results reproducibility, we compiled available codes of all data augmentation techniques. Finally, we discuss the challenges and difficulties, and possible future direction for the research community. We believe, this survey provides several benefits i) readers will understand the data augmentation working mechanism to fix overfitting problems ii) results will save the searching time of the researcher for comparison purposes. iii) Codes of the mentioned data augmentation techniques are available at https://github.com/kmr2017/Advanced-Data-augmentation-codes iv) Future work will spark interest in research community.