 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Future Mosquito Habitats Using Time Series Climate Forecasting and Deep Learning
Aug 01, 2022
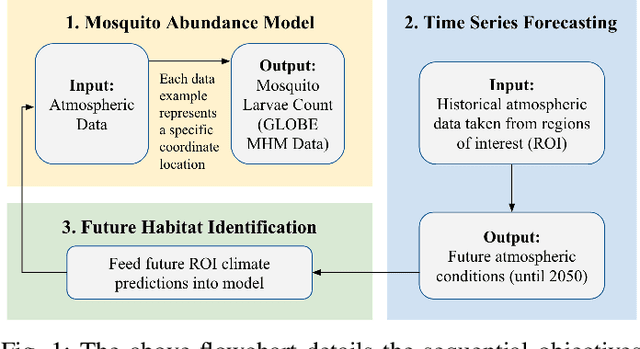
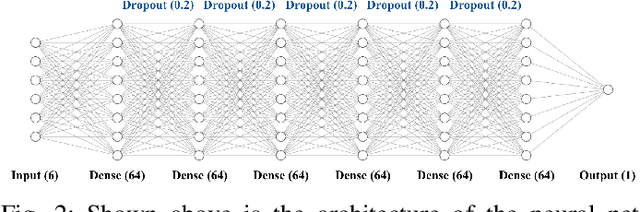
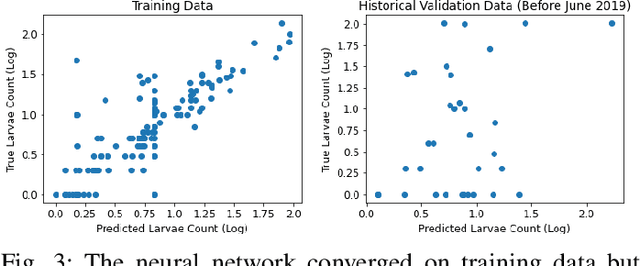
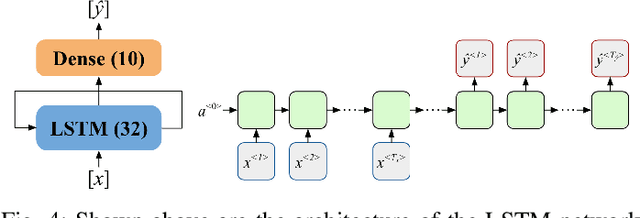
Mosquito habitat ranges are projected to expand due to climate change. This investigation aims to identify future mosquito habitats by analyzing preferred ecological conditions of mosquito larvae. After assembling a data set with atmospheric records and larvae observations, a neural network is trained to predict larvae counts from ecological inputs. Time series forecasting is conducted on these variables and climate projections are passed into the initial deep learning model to generate location-specific larvae abundance predictions. The results support the notion of regional ecosystem-driven changes in mosquito spread, with high-elevation regions in particular experiencing an increase in susceptibility to mosquito infestation.
Test-time image-to-image translation ensembling improves out-of-distribution generalization in histopathology
Jun 30, 2022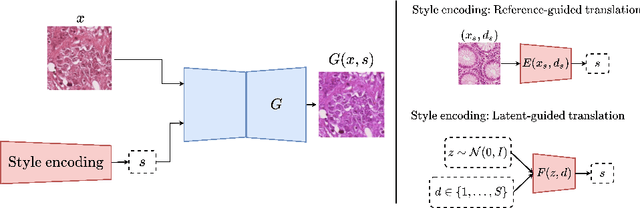
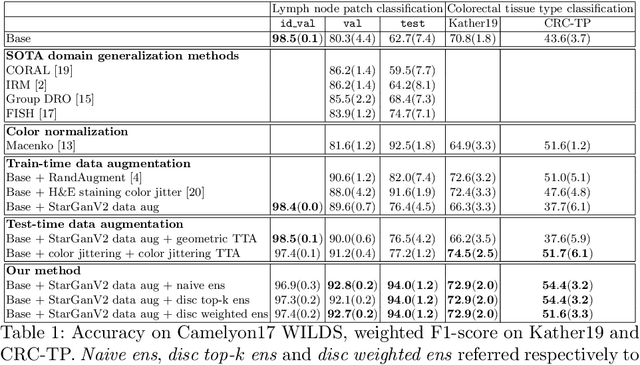
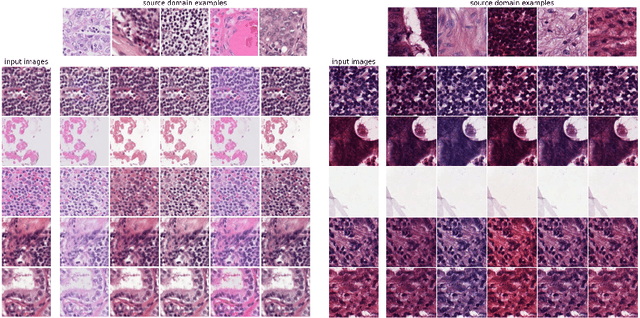
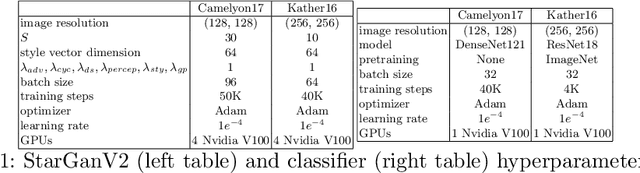
Histopathology whole slide images (WSIs) can reveal significant inter-hospital variability such as illumination, color or optical artifacts. These variations, caused by the use of different scanning protocols across medical centers (staining, scanner), can strongly harm algorithms generalization on unseen protocols. This motivates development of new methods to limit such drop of performances. In this paper, to enhance robustness on unseen target protocols, we propose a new test-time data augmentation based on multi domain image-to-image translation. It allows to project images from unseen protocol into each source domain before classifying them and ensembling the predictions. This test-time augmentation method results in a significant boost of performances for domain generalization. To demonstrate its effectiveness, our method has been evaluated on 2 different histopathology tasks where it outperforms conventional domain generalization, standard H&E specific color augmentation/normalization and standard test-time augmentation techniques. Our code is publicly available at https://gitlab.com/vitadx/articles/test-time-i2i-translation-ensembling.
MMMNA-Net for Overall Survival Time Prediction of Brain Tumor Patients
Jun 13, 2022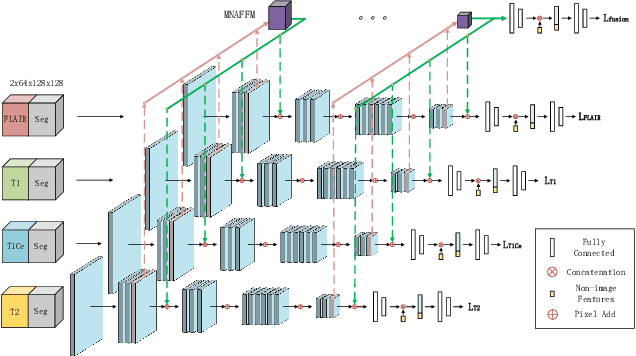
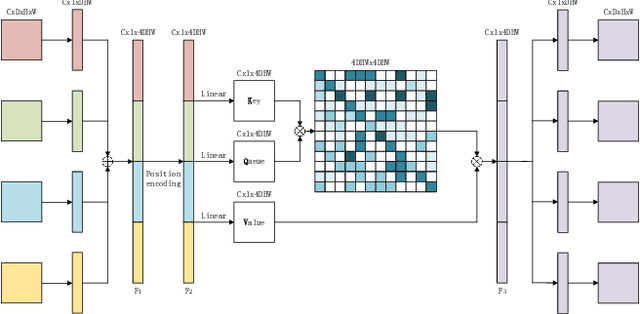
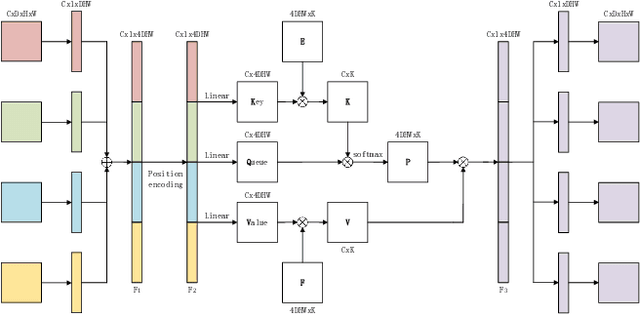
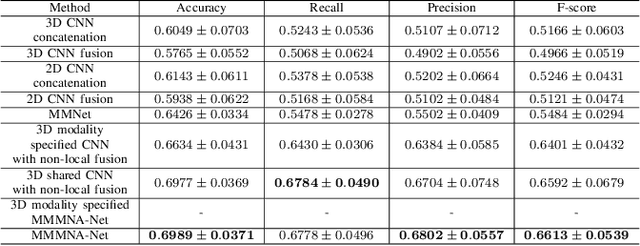
Overall survival (OS) time is one of the most important evaluation indices for gliomas situations. Multimodal Magnetic Resonance Imaging (MRI) scans play an important role in the study of glioma prognosis OS time. Several deep learning-based methods are proposed for the OS time prediction on multi-modal MRI problems. However, these methods usually fuse multi-modal information at the beginning or at the end of the deep learning networks and lack the fusion of features from different scales. In addition, the fusion at the end of networks always adapts global with global (eg. fully connected after concatenation of global average pooling output) or local with local (eg. bilinear pooling), which loses the information of local with global. In this paper, we propose a novel method for multi-modal OS time prediction of brain tumor patients, which contains an improved nonlocal features fusion module introduced on different scales. Our method obtains a relative 8.76% improvement over the current state-of-art method (0.6989 vs. 0.6426 on accuracy). Extensive testing demonstrates that our method could adapt to situations with missing modalities. The code is available at https://github.com/TangWen920812/mmmna-net.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Dec 28, 2022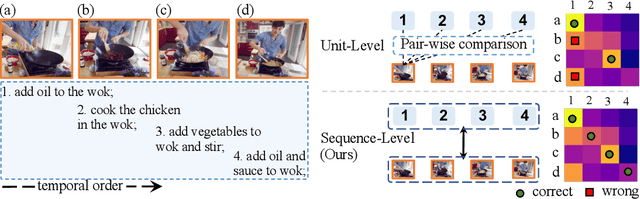
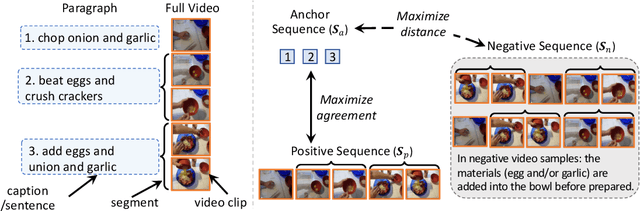
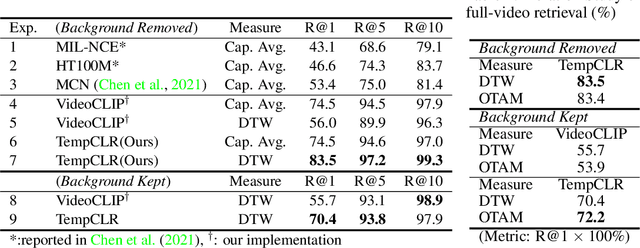
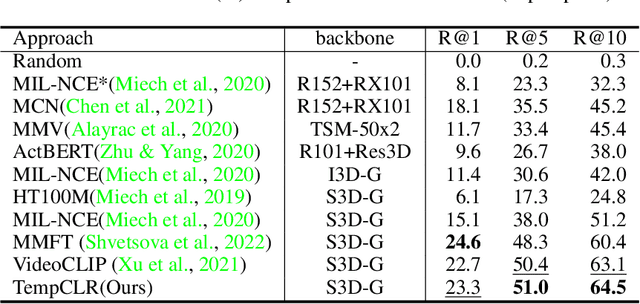
Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
Technology Report : Smartphone-Based Pedestrian Dead Reckoning Integrated with Data-Fusion-Adopted Visible Light Positioning
Jan 06, 2023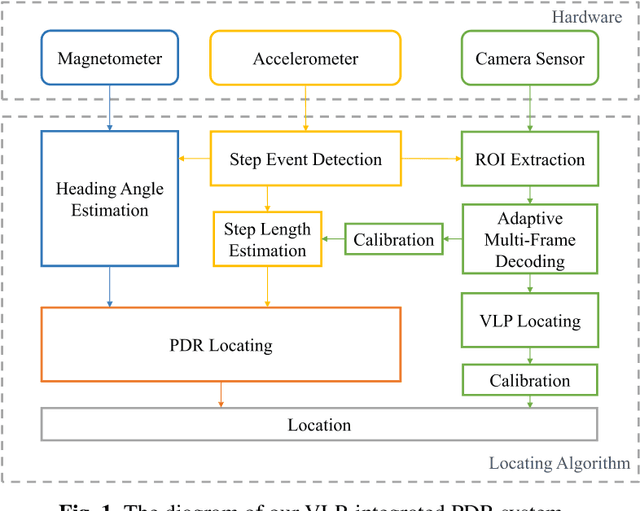
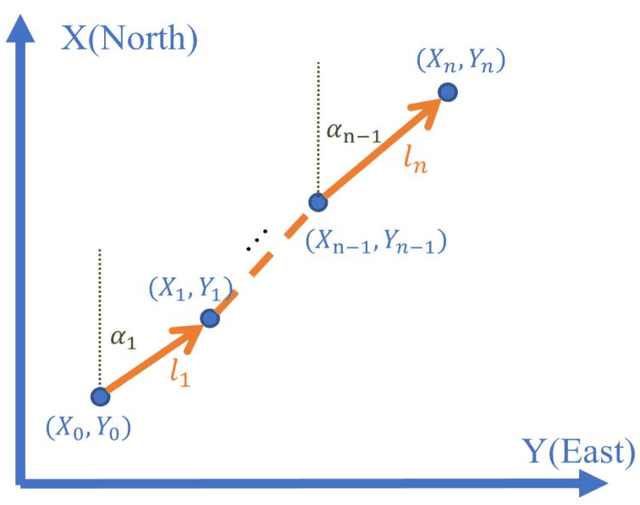
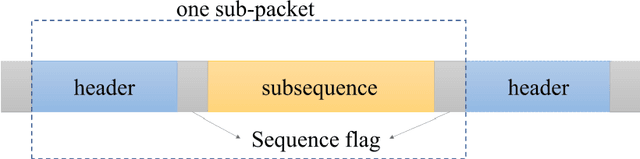
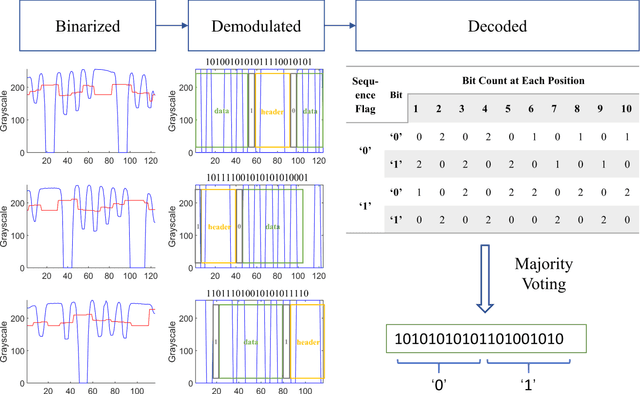
Pedestrian dead-reckoning (PDR) is a potential indoor localization technology that obtains location estimation with the inertial measurement unit (IMU). However, one of its most significant drawbacks is the accumulation of its measurement error. This paper proposes a visible light positioning (VLP)-integrated PDR system, which could achieve real-time and accurate indoor positioning using IMU and the camera sensor of our smartphone. A multi-frame fusion method is proposed in the encoding and decoding process of the system, reaching 98.5% decoding accuracy with a 20-bit-long ID at the height of 2.1 m, which allows the variation in the shutter speeds of cameras and heights of the LED. Meanwhile, absolute locations and step length could be calibrated with the help of a single light-emitting diode (LED), promising average accuracy within 0.5 meters in a 108-meter walk.
Text2Poster: Laying out Stylized Texts on Retrieved Images
Jan 06, 2023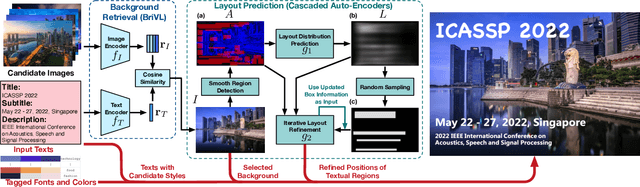


Poster generation is a significant task for a wide range of applications, which is often time-consuming and requires lots of manual editing and artistic experience. In this paper, we propose a novel data-driven framework, called \textit{Text2Poster}, to automatically generate visually-effective posters from textual information. Imitating the process of manual poster editing, our framework leverages a large-scale pretrained visual-textual model to retrieve background images from given texts, lays out the texts on the images iteratively by cascaded auto-encoders, and finally, stylizes the texts by a matching-based method. We learn the modules of the framework by weakly- and self-supervised learning strategies, mitigating the demand for labeled data. Both objective and subjective experiments demonstrate that our Text2Poster outperforms state-of-the-art methods, including academic research and commercial software, on the quality of generated posters.
Fully-Dynamic Decision Trees
Dec 01, 2022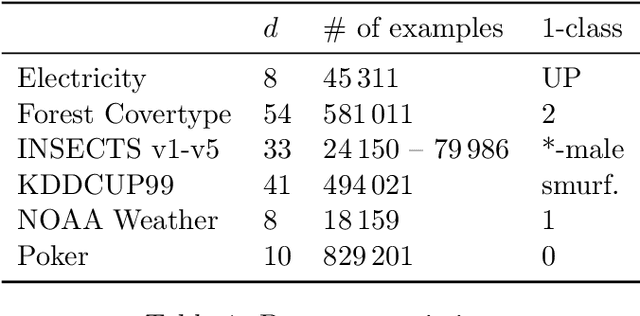
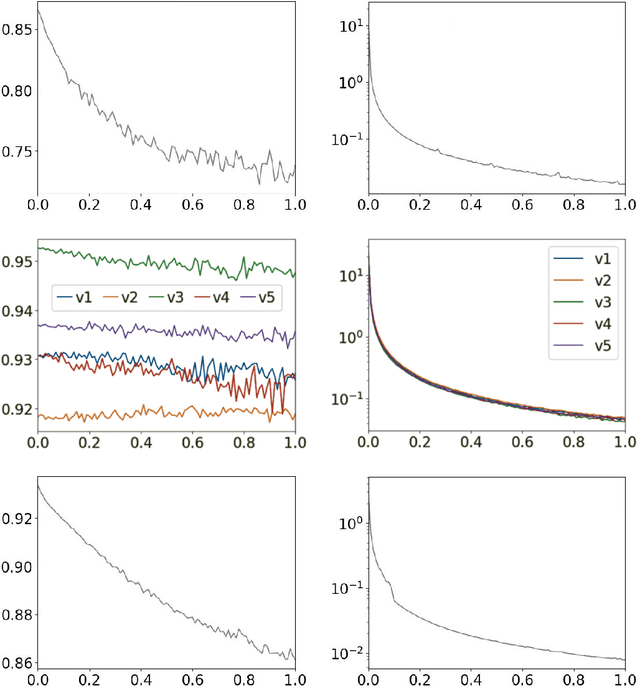
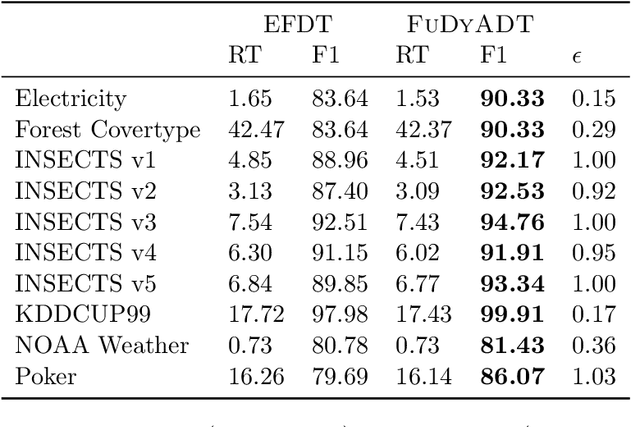
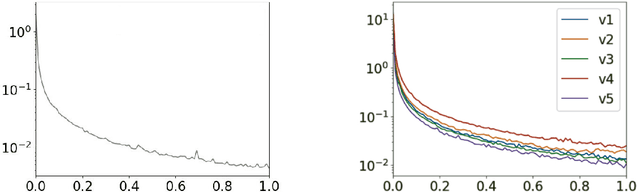
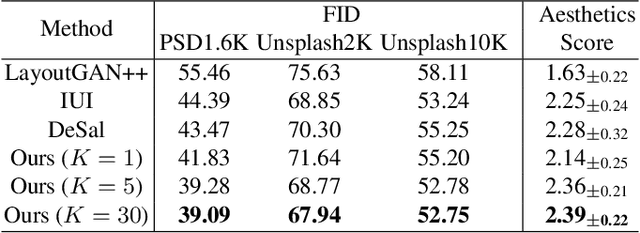
We develop the first fully dynamic algorithm that maintains a decision tree over an arbitrary sequence of insertions and deletions of labeled examples. Given $\epsilon > 0$ our algorithm guarantees that, at every point in time, every node of the decision tree uses a split with Gini gain within an additive $\epsilon$ of the optimum. For real-valued features the algorithm has an amortized running time per insertion/deletion of $O\big(\frac{d \log^3 n}{\epsilon^2}\big)$, which improves to $O\big(\frac{d \log^2 n}{\epsilon}\big)$ for binary or categorical features, while it uses space $O(n d)$, where $n$ is the maximum number of examples at any point in time and $d$ is the number of features. Our algorithm is nearly optimal, as we show that any algorithm with similar guarantees uses amortized running time $\Omega(d)$ and space $\tilde{\Omega} (n d)$. We complement our theoretical results with an extensive experimental evaluation on real-world data, showing the effectiveness of our algorithm.
SeqDiffuSeq: Text Diffusion with Encoder-Decoder Transformers
Dec 20, 2022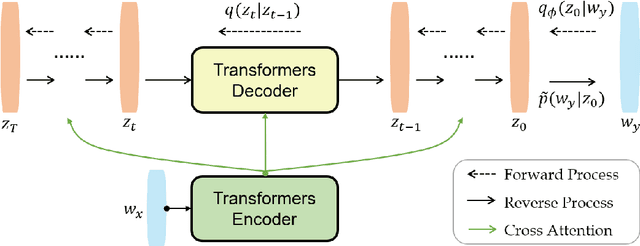
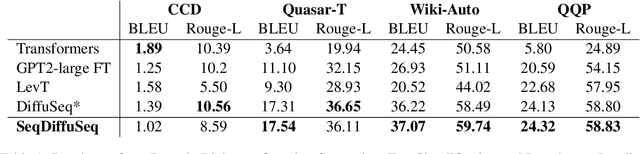

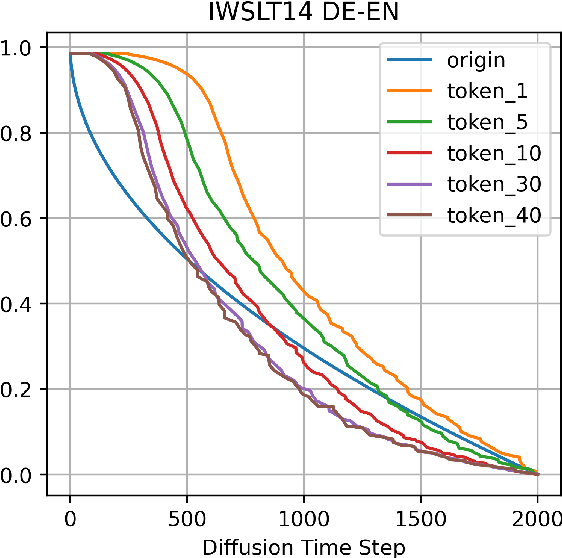
Diffusion model, a new generative modelling paradigm, has achieved great success in image, audio, and video generation. However, considering the discrete categorical nature of text, it is not trivial to extend continuous diffusion models to natural language, and text diffusion models are less studied. Sequence-to-sequence text generation is one of the essential natural language processing topics. In this work, we apply diffusion models to approach sequence-to-sequence text generation, and explore whether the superiority generation performance of diffusion model can transfer to natural language domain. We propose SeqDiffuSeq, a text diffusion model for sequence-to-sequence generation. SeqDiffuSeq uses an encoder-decoder Transformers architecture to model denoising function. In order to improve generation quality, SeqDiffuSeq combines the self-conditioning technique and a newly proposed adaptive noise schedule technique. The adaptive noise schedule has the difficulty of denoising evenly distributed across time steps, and considers exclusive noise schedules for tokens at different positional order. Experiment results illustrate the good performance on sequence-to-sequence generation in terms of text quality and inference time.
Concentration of the Langevin Algorithm's Stationary Distribution
Dec 24, 2022A canonical algorithm for log-concave sampling is the Langevin Algorithm, aka the Langevin Diffusion run with some discretization stepsize $\eta > 0$. This discretization leads the Langevin Algorithm to have a stationary distribution $\pi_{\eta}$ which differs from the stationary distribution $\pi$ of the Langevin Diffusion, and it is an important challenge to understand whether the well-known properties of $\pi$ extend to $\pi_{\eta}$. In particular, while concentration properties such as isoperimetry and rapidly decaying tails are classically known for $\pi$, the analogous properties for $\pi_{\eta}$ are open questions with direct algorithmic implications. This note provides a first step in this direction by establishing concentration results for $\pi_{\eta}$ that mirror classical results for $\pi$. Specifically, we show that for any nontrivial stepsize $\eta > 0$, $\pi_{\eta}$ is sub-exponential (respectively, sub-Gaussian) when the potential is convex (respectively, strongly convex). Moreover, the concentration bounds we show are essentially tight. Key to our analysis is the use of a rotation-invariant moment generating function (aka Bessel function) to study the stationary dynamics of the Langevin Algorithm. This technique may be of independent interest because it enables directly analyzing the discrete-time stationary distribution $\pi_{\eta}$ without going through the continuous-time stationary distribution $\pi$ as an intermediary.
An optimized fuzzy logic model for proactive maintenance
Dec 24, 2022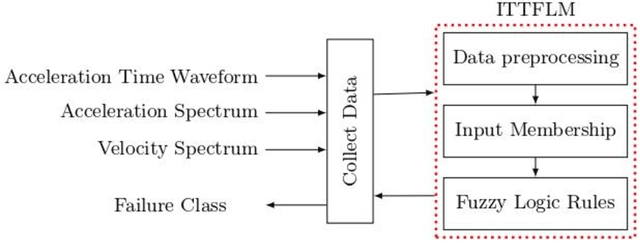
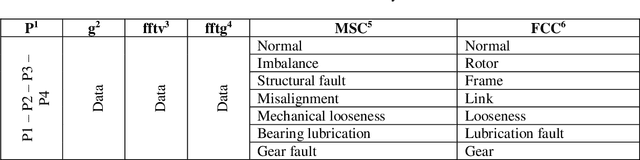
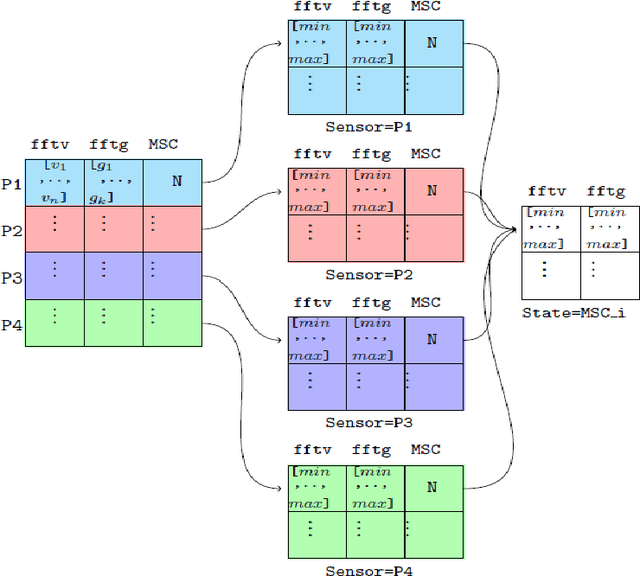

Fuzzy logic has been proposed in previous studies for machine diagnosis, to overcome different drawbacks of the traditional diagnostic approaches used. Among these approaches Failure Mode and Effect Critical Analysis method(FMECA) attempts to identify potential modes and treat failures before they occur based on subjective expert judgments. Although several versions of fuzzy logic are used to improve FMECA or to replace it, since it is an extremely cost-intensive approach in terms of failure modes because it evaluates each one of them separately, these propositions have not explicitly focused on the combinatorial complexity nor justified the choice of membership functions in Fuzzy logic modeling. Within this context, we develop an optimization-based approach referred to Integrated Truth Table and Fuzzy Logic Model (ITTFLM) that smartly generates fuzzy logic rules using Truth Tables. The ITTFLM was tested on fan data collected in real-time from a plant machine. In the experiment, three types of membership functions (Triangular, Trapezoidal, and Gaussian) were used. The ITTFLM can generate outputs in 5ms, the results demonstrate that this model based on the Trapezoidal membership functions identifies the failure states with high accuracy, and its capability of dealing with large numbers of rules and thus meets the real-time constraints that usually impact user experience.