 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An AI-Powered VVPAT Counter for Elections in India
Dec 09, 2022

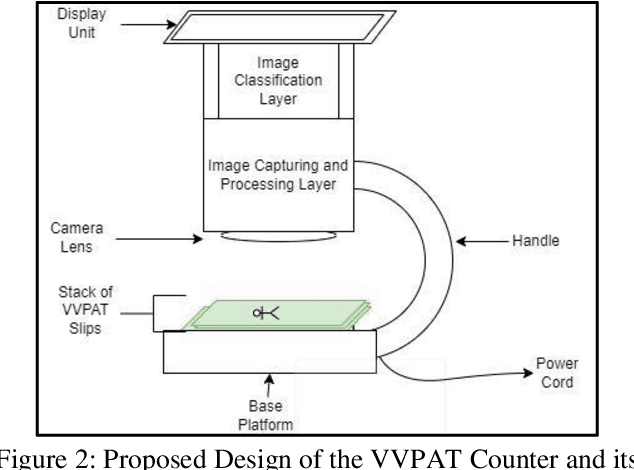

The Election Commission of India has introduced Voter Verified Paper Audit Trail since 2019. This mechanism has increased voter confidence at the time of casting the votes. However, physical verification of the VVPATs against the party level counts from the EVMs is done only in 5 (randomly selected) machines per constituency. The time required to conduct physical verification becomes a bottleneck in scaling this activity for 100% of machines in all constituencies. We proposed an automated counter powered by image processing and machine learning algorithms to speed up the process and address this issue.
Explainable Quantum Machine Learning
Jan 22, 2023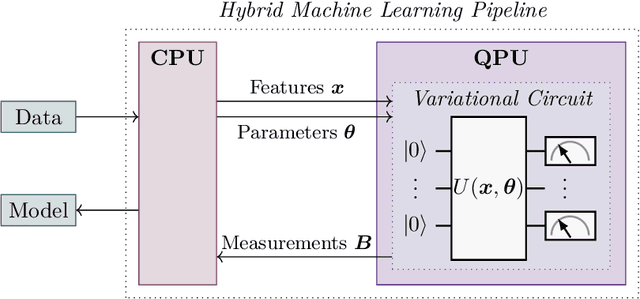
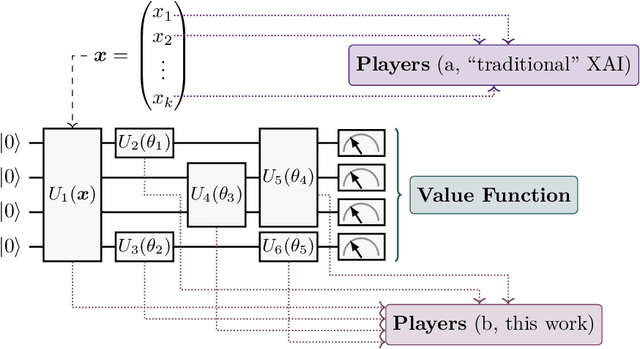
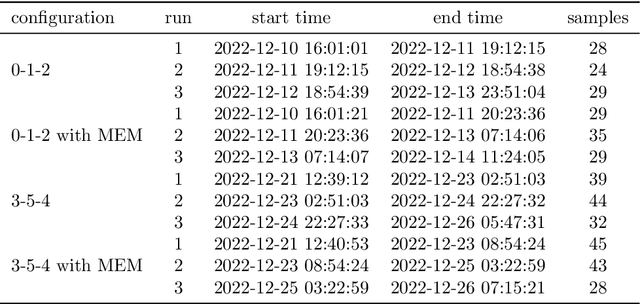
Methods of artificial intelligence (AI) and especially machine learning (ML) have been growing ever more complex, and at the same time have more and more impact on people's lives. This leads to explainable AI (XAI) manifesting itself as an important research field that helps humans to better comprehend ML systems. In parallel, quantum machine learning (QML) is emerging with the ongoing improvement of quantum computing hardware combined with its increasing availability via cloud services. QML enables quantum-enhanced ML in which quantum mechanics is exploited to facilitate ML tasks, typically in form of quantum-classical hybrid algorithms that combine quantum and classical resources. Quantum gates constitute the building blocks of gate-based quantum hardware and form circuits that can be used for quantum computations. For QML applications, quantum circuits are typically parameterized and their parameters are optimized classically such that a suitably defined objective function is minimized. Inspired by XAI, we raise the question of explainability of such circuits by quantifying the importance of (groups of) gates for specific goals. To this end, we transfer and adapt the well-established concept of Shapley values to the quantum realm. The resulting attributions can be interpreted as explanations for why a specific circuit works well for a given task, improving the understanding of how to construct parameterized (or variational) quantum circuits, and fostering their human interpretability in general. An experimental evaluation on simulators and two superconducting quantum hardware devices demonstrates the benefits of the proposed framework for classification, generative modeling, transpilation, and optimization. Furthermore, our results shed some light on the role of specific gates in popular QML approaches.
GAN-Based Content Generation of Maps for Strategy Games
Jan 07, 2023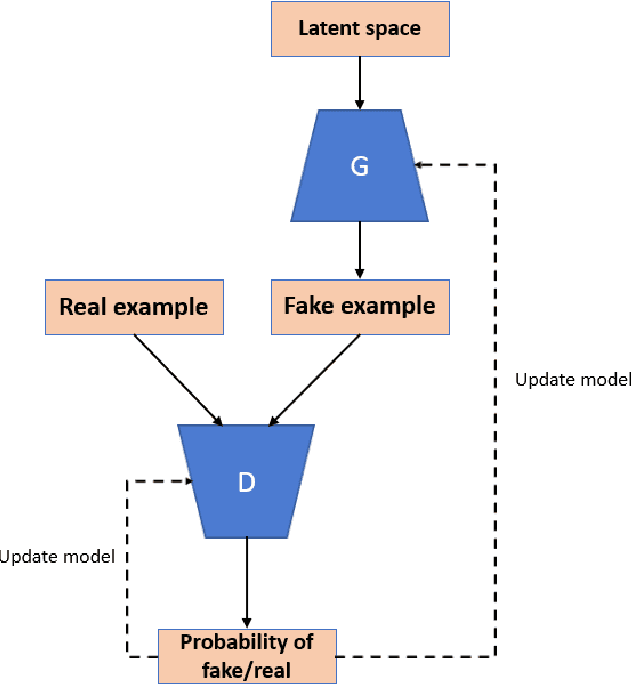

Maps are a very important component of strategy games, and a time-consuming task if done by hand. Maps generated by traditional PCG techniques such as Perlin noise or tile-based PCG techniques look unnatural and unappealing, thus not providing the best user experience for the players. However it is possible to have a generator that can create realistic and natural images of maps, given that it is trained how to do so. We propose a model for the generation of maps based on Generative Adversarial Networks (GAN). In our implementation we tested out different variants of GAN-based networks on a dataset of heightmaps. We conducted extensive empirical evaluation to determine the advantages and properties of each approach. The results obtained are promising, showing that it is indeed possible to generate realistic looking maps using this type of approach.
* Published in the Proceedings of GAME ON 2022
Building a Parallel Corpus and Training Translation Models Between Luganda and English
Jan 07, 2023



Neural machine translation (NMT) has achieved great successes with large datasets, so NMT is more premised on high-resource languages. This continuously underpins the low resource languages such as Luganda due to the lack of high-quality parallel corpora, so even 'Google translate' does not serve Luganda at the time of this writing. In this paper, we build a parallel corpus with 41,070 pairwise sentences for Luganda and English which is based on three different open-sourced corpora. Then, we train NMT models with hyper-parameter search on the dataset. Experiments gave us a BLEU score of 21.28 from Luganda to English and 17.47 from English to Luganda. Some translation examples show high quality of the translation. We believe that our model is the first Luganda-English NMT model. The bilingual dataset we built will be available to the public.
Job recommendations: benchmarking of collaborative filtering methods for classifieds
Jan 19, 2023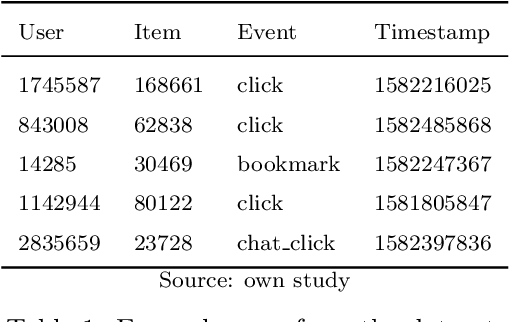
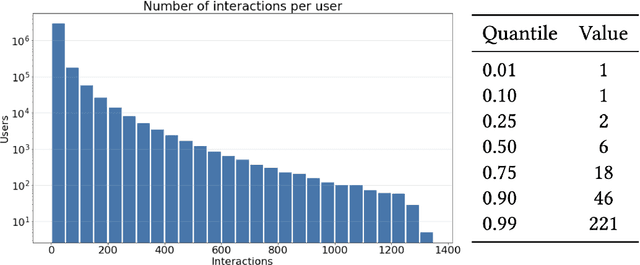
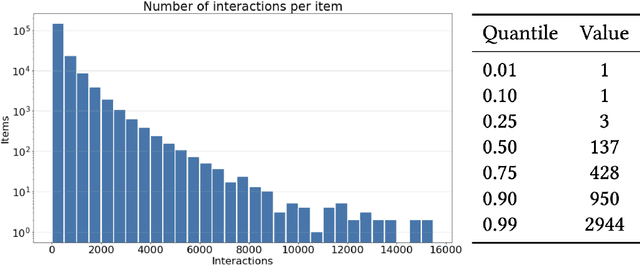
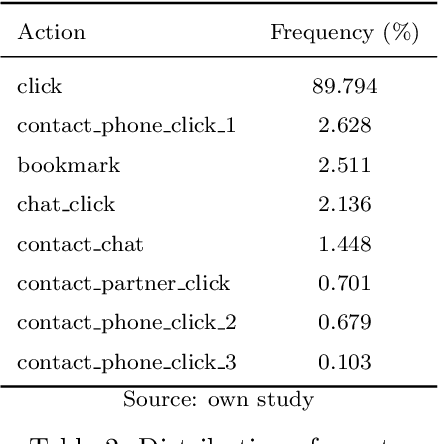
Classifieds provide many challenges for recommendation methods, due to the limited information regarding users and items. In this paper, we explore recommendation methods for classifieds using the example of OLX Jobs. The goal of the paper is to benchmark different recommendation methods for jobs classifieds in order to improve advertisements' conversion rate and user satisfaction. In our research, we implemented methods that are scalable and represent different approaches to recommendation, namely ALS, LightFM, Prod2Vec, RP3beta, and SLIM. We performed a laboratory comparison of methods with regard to accuracy, diversity, and scalability (memory and time consumption during training and in prediction). Online A/B tests were also carried out by sending millions of messages with recommendations to evaluate models in a real-world setting. In addition, we have published the dataset that we created for the needs of our research. To the best of our knowledge, this is the first dataset of this kind. The dataset contains 65,502,201 events performed on OLX Jobs by 3,295,942 users, who interacted with (displayed, replied to, or bookmarked) 185,395 job ads in two weeks of 2020. We demonstrate that RP3beta, SLIM, and ALS perform significantly better than Prod2Vec and LightFM when tested in a laboratory setting. Online A/B tests also demonstrated that sending messages with recommendations generated by the ALS and RP3beta models increases the number of users contacting advertisers. Additionally, RP3beta had a 20% greater impact on this metric than ALS.
Fast Inference in Denoising Diffusion Models via MMD Finetuning
Jan 19, 2023



Denoising Diffusion Models (DDMs) have become a popular tool for generating high-quality samples from complex data distributions. These models are able to capture sophisticated patterns and structures in the data, and can generate samples that are highly diverse and representative of the underlying distribution. However, one of the main limitations of diffusion models is the complexity of sample generation, since a large number of inference timesteps is required to faithfully capture the data distribution. In this paper, we present MMD-DDM, a novel method for fast sampling of diffusion models. Our approach is based on the idea of using the Maximum Mean Discrepancy (MMD) to finetune the learned distribution with a given budget of timesteps. This allows the finetuned model to significantly improve the speed-quality trade-off, by substantially increasing fidelity in inference regimes with few steps or, equivalently, by reducing the required number of steps to reach a target fidelity, thus paving the way for a more practical adoption of diffusion models in a wide range of applications. We evaluate our approach on unconditional image generation with extensive experiments across the CIFAR-10, CelebA, ImageNet and LSUN-Church datasets. Our findings show that the proposed method is able to produce high-quality samples in a fraction of the time required by widely-used diffusion models, and outperforms state-of-the-art techniques for accelerated sampling. Code is available at: https://github.com/diegovalsesia/MMD-DDM.
SoftEnNet: Symbiotic Monocular Depth Estimation and Lumen Segmentation for Colonoscopy Endorobots
Jan 19, 2023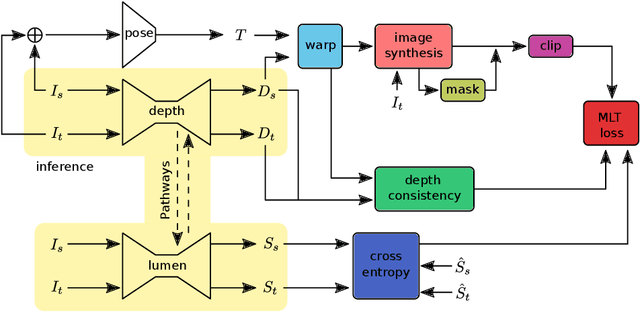
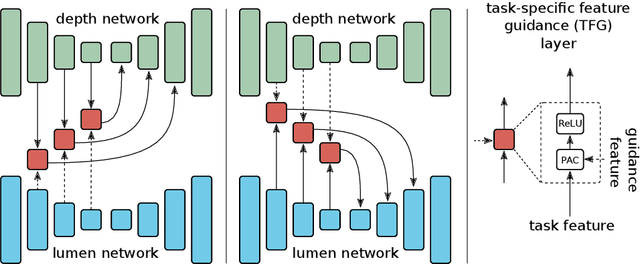
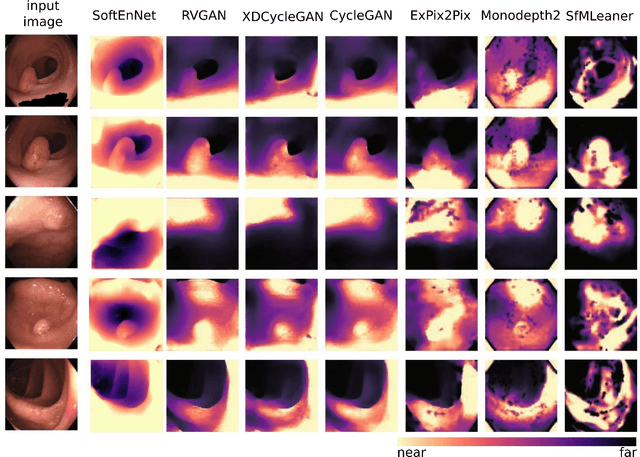
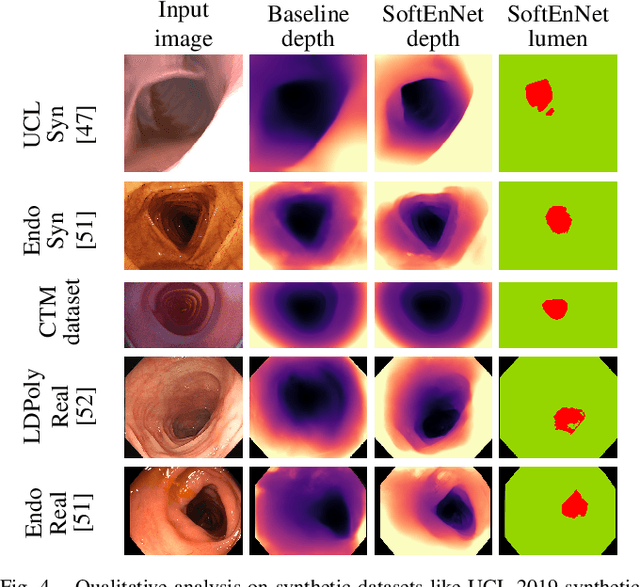
Colorectal cancer is the third most common cause of cancer death worldwide. Optical colonoscopy is the gold standard for detecting colorectal cancer; however, about 25 percent of polyps are missed during the procedure. A vision-based autonomous endorobot can improve colonoscopy procedures significantly through systematic, complete screening of the colonic mucosa. The reliable robot navigation needed requires a three-dimensional understanding of the environment and lumen tracking to support autonomous tasks. We propose a novel multi-task model that simultaneously predicts dense depth and lumen segmentation with an ensemble of deep networks. The depth estimation sub-network is trained in a self-supervised fashion guided by view synthesis; the lumen segmentation sub-network is supervised. The two sub-networks are interconnected with pathways that enable information exchange and thereby mutual learning. As the lumen is in the image's deepest visual space, lumen segmentation helps with the depth estimation at the farthest location. In turn, the estimated depth guides the lumen segmentation network as the lumen location defines the farthest scene location. Unlike other environments, view synthesis often fails in the colon because of the deformable wall, textureless surface, specularities, and wide field of view image distortions, all challenges that our pipeline addresses. We conducted qualitative analysis on a synthetic dataset and quantitative analysis on a colon training model and real colonoscopy videos. The experiments show that our model predicts accurate scale-invariant depth maps and lumen segmentation from colonoscopy images in near real-time.
Evaluation of the potential of Near Infrared Hyperspectral Imaging for monitoring the invasive brown marmorated stink bug
Jan 19, 2023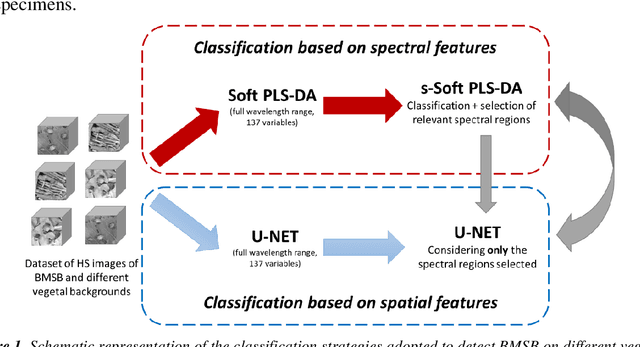
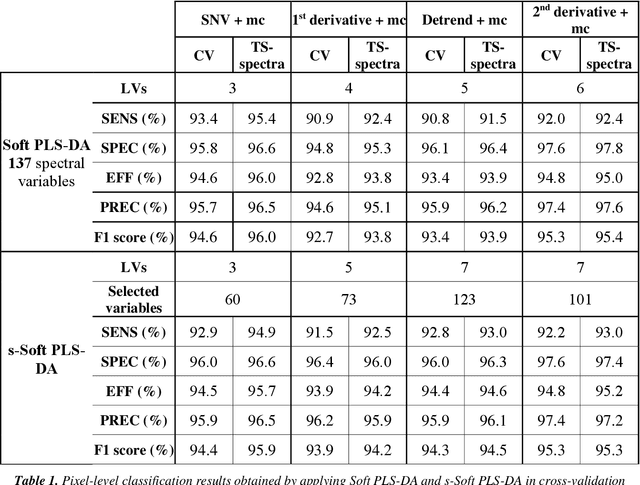
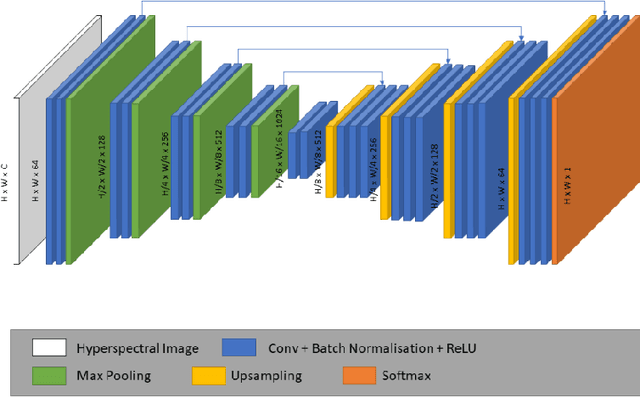
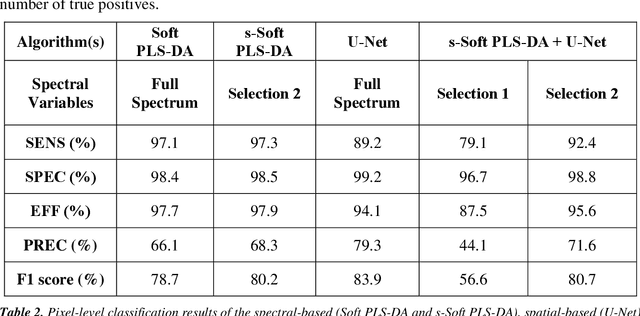
The brown marmorated stink bug (BMSB), Halyomorpha halys, is an invasive insect pest of global importance that damages several crops, compromising agri-food production. Field monitoring procedures are fundamental to perform risk assessment operations, in order to promptly face crop infestations and avoid economical losses. To improve pest management, spectral cameras mounted on Unmanned Aerial Vehicles (UAVs) and other Internet of Things (IoT) devices, such as smart traps or unmanned ground vehicles, could be used as an innovative technology allowing fast, efficient and real-time monitoring of insect infestations. The present study consists in a preliminary evaluation at the laboratory level of Near Infrared Hyperspectral Imaging (NIR-HSI) as a possible technology to detect BMSB specimens on different vegetal backgrounds, overcoming the problem of BMSB mimicry. Hyperspectral images of BMSB were acquired in the 980-1660 nm range, considering different vegetal backgrounds selected to mimic a real field application scene. Classification models were obtained following two different chemometric approaches. The first approach was focused on modelling spectral information and selecting relevant spectral regions for discrimination by means of sparse-based variable selection coupled with Soft Partial Least Squares Discriminant Analysis (s-Soft PLS-DA) classification algorithm. The second approach was based on modelling spatial and spectral features contained in the hyperspectral images using Convolutional Neural Networks (CNN). Finally, to further improve BMSB detection ability, the two strategies were merged, considering only the spectral regions selected by s-Soft PLS-DA for CNN modelling.
* Accepted manuscript
R$^3$LIVE++: A Robust, Real-time, Radiance reconstruction package with a tightly-coupled LiDAR-Inertial-Visual state Estimator
Sep 08, 2022

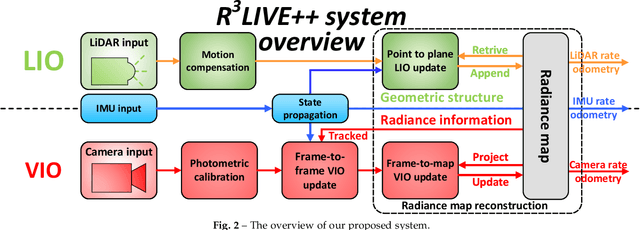
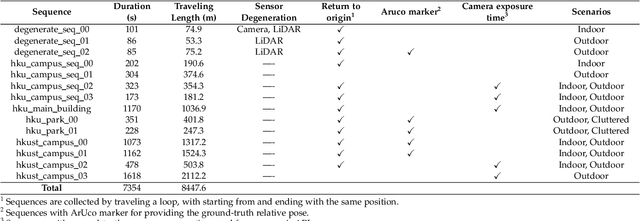
Simultaneous localization and mapping (SLAM) are crucial for autonomous robots (e.g., self-driving cars, autonomous drones), 3D mapping systems, and AR/VR applications. This work proposed a novel LiDAR-inertial-visual fusion framework termed R$^3$LIVE++ to achieve robust and accurate state estimation while simultaneously reconstructing the radiance map on the fly. R$^3$LIVE++ consists of a LiDAR-inertial odometry (LIO) and a visual-inertial odometry (VIO), both running in real-time. The LIO subsystem utilizes the measurements from a LiDAR for reconstructing the geometric structure (i.e., the positions of 3D points), while the VIO subsystem simultaneously recovers the radiance information of the geometric structure from the input images. R$^3$LIVE++ is developed based on R$^3$LIVE and further improves the accuracy in localization and mapping by accounting for the camera photometric calibration (e.g., non-linear response function and lens vignetting) and the online estimation of camera exposure time. We conduct more extensive experiments on both public and our private datasets to compare our proposed system against other state-of-the-art SLAM systems. Quantitative and qualitative results show that our proposed system has significant improvements over others in both accuracy and robustness. In addition, to demonstrate the extendability of our work, {we developed several applications based on our reconstructed radiance maps, such as high dynamic range (HDR) imaging, virtual environment exploration, and 3D video gaming.} Lastly, to share our findings and make contributions to the community, we make our codes, hardware design, and dataset publicly available on our Github: github.com/hku-mars/r3live
Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer
Apr 07, 2022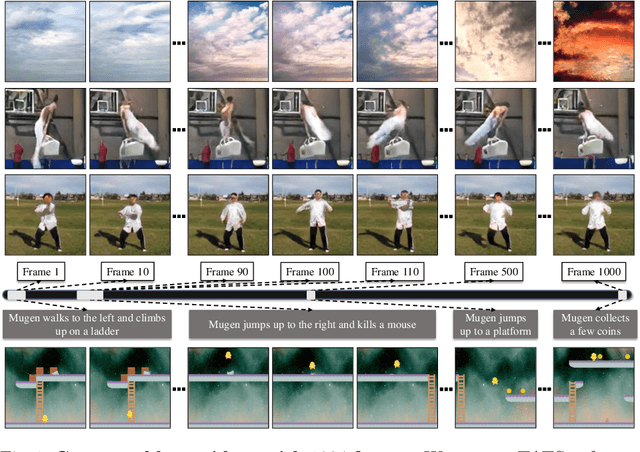
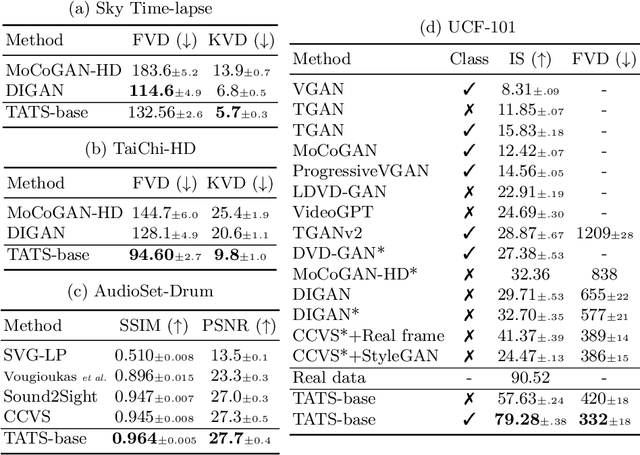

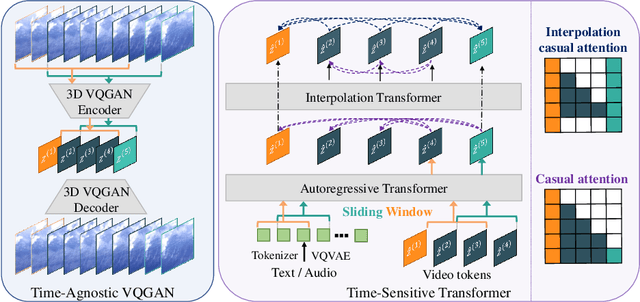
Videos are created to express emotion, exchange information, and share experiences. Video synthesis has intrigued researchers for a long time. Despite the rapid progress driven by advances in visual synthesis, most existing studies focus on improving the frames' quality and the transitions between them, while little progress has been made in generating longer videos. In this paper, we present a method that builds on 3D-VQGAN and transformers to generate videos with thousands of frames. Our evaluation shows that our model trained on 16-frame video clips from standard benchmarks such as UCF-101, Sky Time-lapse, and Taichi-HD datasets can generate diverse, coherent, and high-quality long videos. We also showcase conditional extensions of our approach for generating meaningful long videos by incorporating temporal information with text and audio. Videos and code can be found at https://songweige.github.io/projects/tats/index.html.