 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
POIBERT: A Transformer-based Model for the Tour Recommendation Problem
Dec 16, 2022
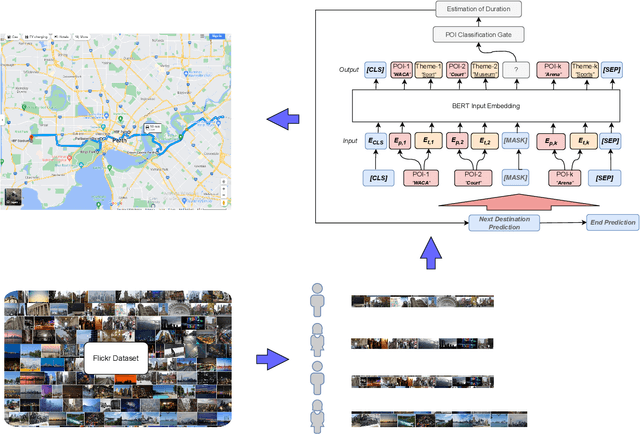
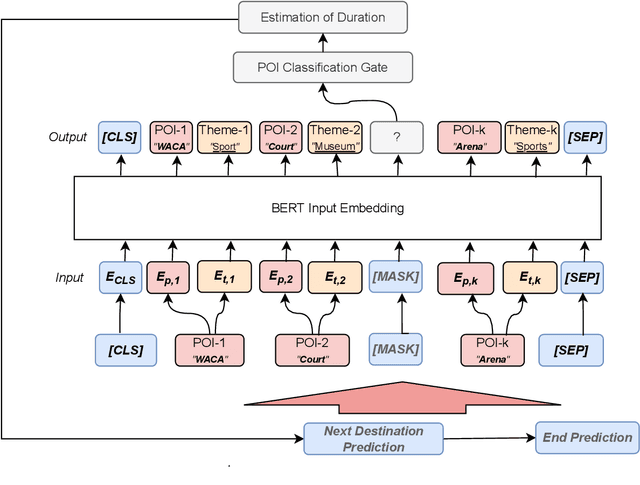
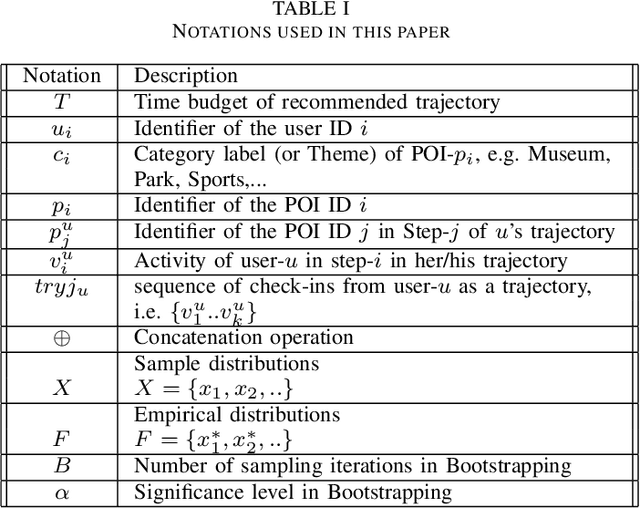
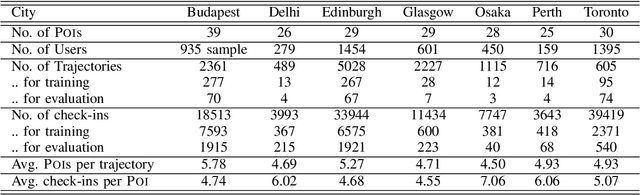
Tour itinerary planning and recommendation are challenging problems for tourists visiting unfamiliar cities. Many tour recommendation algorithms only consider factors such as the location and popularity of Points of Interest (POIs) but their solutions may not align well with the user's own preferences and other location constraints. Additionally, these solutions do not take into consideration of the users' preference based on their past POIs selection. In this paper, we propose POIBERT, an algorithm for recommending personalized itineraries using the BERT language model on POIs. POIBERT builds upon the highly successful BERT language model with the novel adaptation of a language model to our itinerary recommendation task, alongside an iterative approach to generate consecutive POIs. Our recommendation algorithm is able to generate a sequence of POIs that optimizes time and users' preference in POI categories based on past trajectories from similar tourists. Our tour recommendation algorithm is modeled by adapting the itinerary recommendation problem to the sentence completion problem in natural language processing (NLP). We also innovate an iterative algorithm to generate travel itineraries that satisfies the time constraints which is most likely from past trajectories. Using a Flickr dataset of seven cities, experimental results show that our algorithm out-performs many sequence prediction algorithms based on measures in recall, precision and F1-scores.
ENGNN: A General Edge-Update Empowered GNN Architecture for Radio Resource Management in Wireless Networks
Dec 14, 2022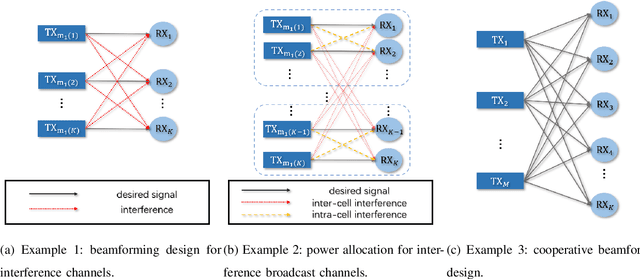
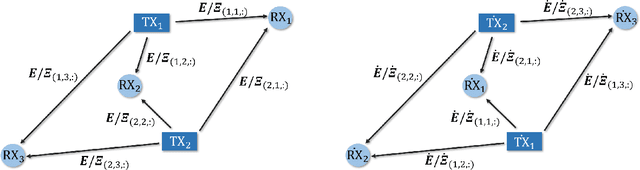
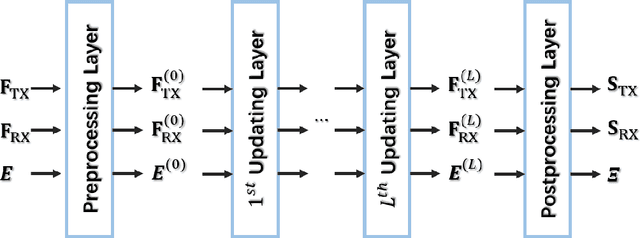
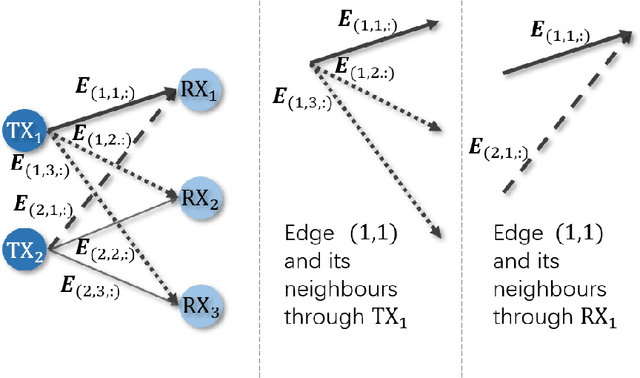
In order to achieve high data rate and ubiquitous connectivity in future wireless networks, a key task is to efficiently manage the radio resource by judicious beamforming and power allocation. Unfortunately, the iterative nature of the commonly applied optimization-based algorithms cannot meet the low latency requirements due to the high computational complexity. For real-time implementations, deep learning-based approaches, especially the graph neural networks (GNNs), have been demonstrated with good scalability and generalization performance due to the permutation equivariance (PE) property. However, the current architectures are only equipped with the node-update mechanism, which prohibits the applications to a more general setup, where the unknown variables are also defined on the graph edges. To fill this gap, we propose an edge-update mechanism, which enables GNNs to handle both node and edge variables and prove its PE property with respect to both transmitters and receivers. Simulation results on typical radio resource management problems demonstrate that the proposed method achieves higher sum rate but with much shorter computation time than state-of-the-art methods and generalizes well on different numbers of base stations and users, different noise variances, interference levels, and transmit power budgets.
Test-time image-to-image translation ensembling improves out-of-distribution generalization in histopathology
Jun 20, 2022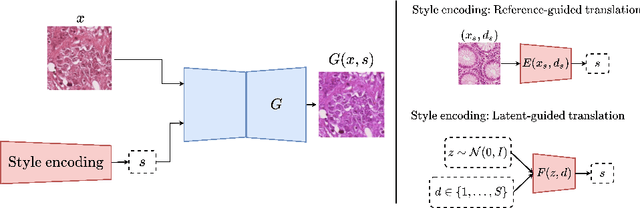
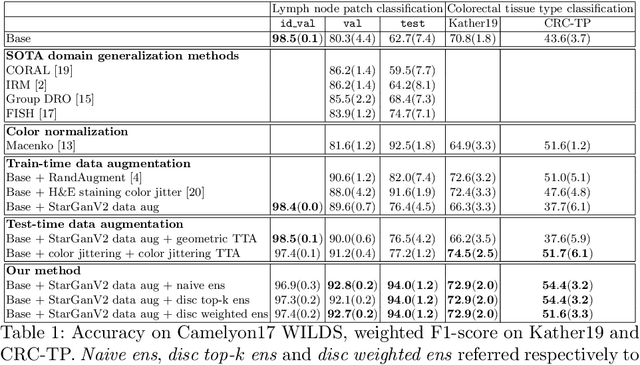
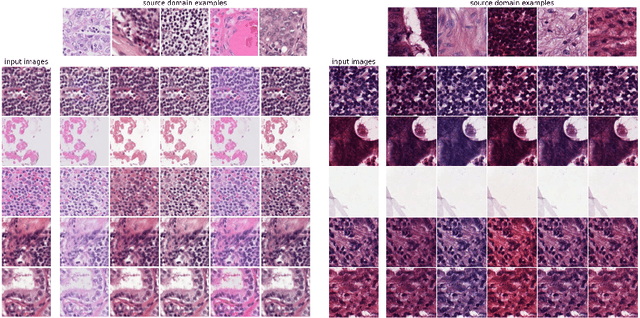
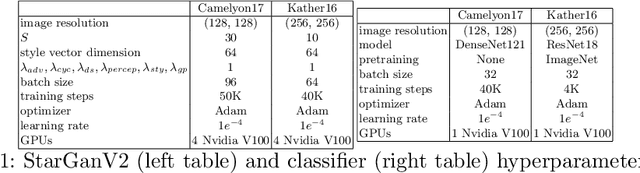
Histopathology whole slide images (WSIs) can reveal significant inter-hospital variability such as illumination, color or optical artifacts. These variations, caused by the use of different scanning protocols across medical centers (staining, scanner), can strongly harm algorithms generalization on unseen protocols. This motivates development of new methods to limit such drop of performances. In this paper, to enhance robustness on unseen target protocols, we propose a new test-time data augmentation based on multi domain image-to-image translation. It allows to project images from unseen protocol into each source domain before classifying them and ensembling the predictions. This test-time augmentation method results in a significant boost of performances for domain generalization. To demonstrate its effectiveness, our method has been evaluated on 2 different histopathology tasks where it outperforms conventional domain generalization, standard H&E specific color augmentation/normalization and standard test-time augmentation techniques. Our code is publicly available at https://gitlab.com/vitadx/articles/test-time-i2i-translation-ensembling.
A minor extension of the logistic equation for growth of word counts on online media: Parametric description of diversity of growth phenomena in society
Nov 30, 2022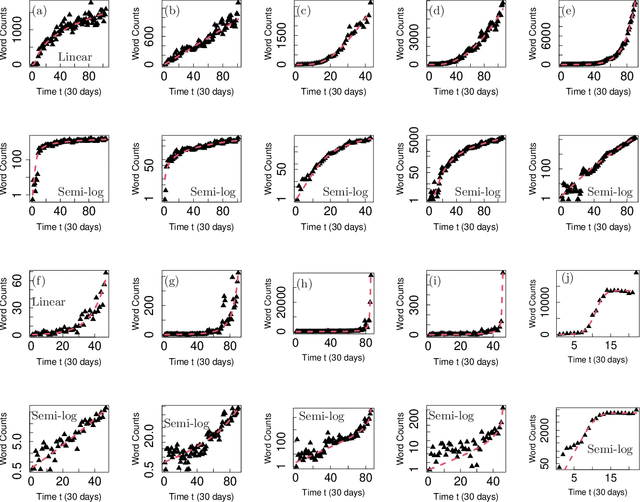

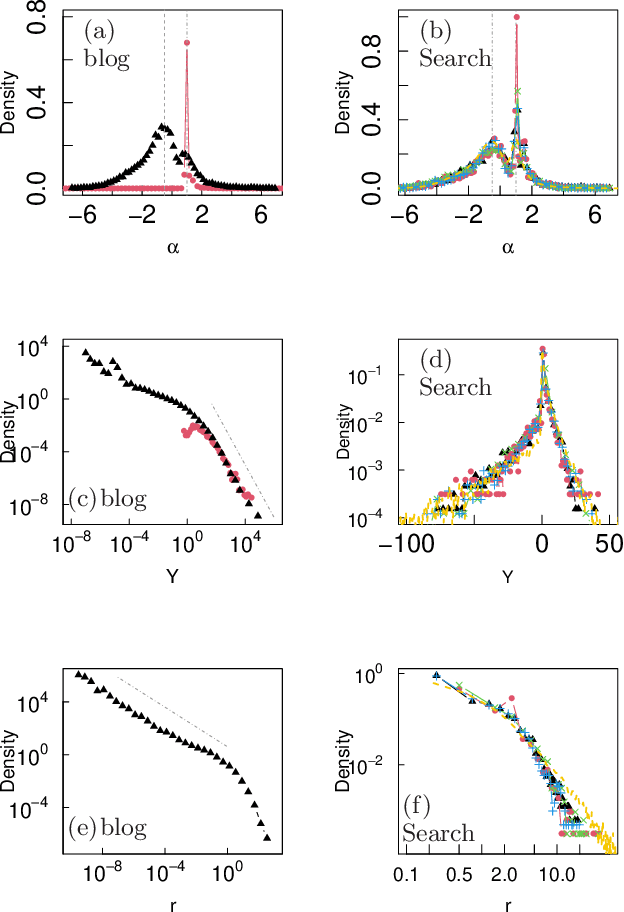
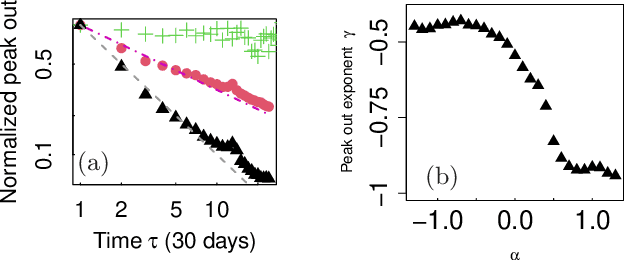
To understand the growing phenomena of new vocabulary on nationwide online social media, we analyzed monthly word count time series extracted from approximately 1 billion Japanese blog articles from 2007 to 2019. In particular, we first introduced the extended logistic equation by adding one parameter to the original equation and showed that the model can consistently reproduce various patterns of actual growth curves, such as the logistic function, linear growth, and finite-time divergence. Second, by analyzing the model parameters, we found that the typical growth pattern is not only a logistic function, which often appears in various complex systems, but also a nontrivial growth curve that starts with an exponential function and asymptotically approaches a power function without a steady state. Furthermore, we observed a connection between the functional form of growth and the peak-out. Finally, we showed that the proposed model and statistical properties are also valid for Google Trends data (English, French, Spanish, and Japanese), which is a time series of the nationwide popularity of search queries.
Lie Group Forced Variational Integrator Networks for Learning and Control of Robot Systems
Nov 30, 2022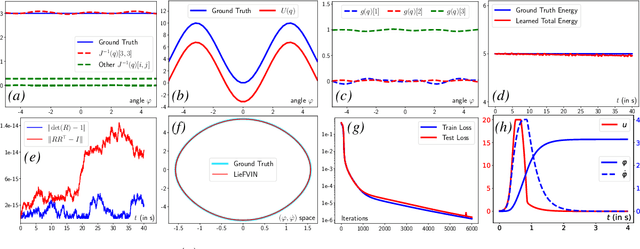
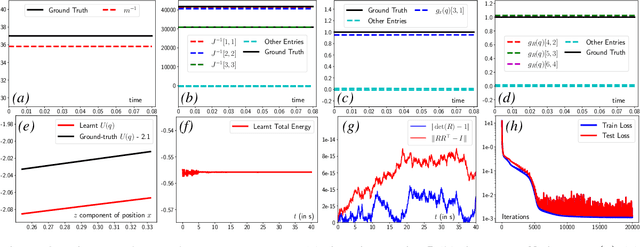
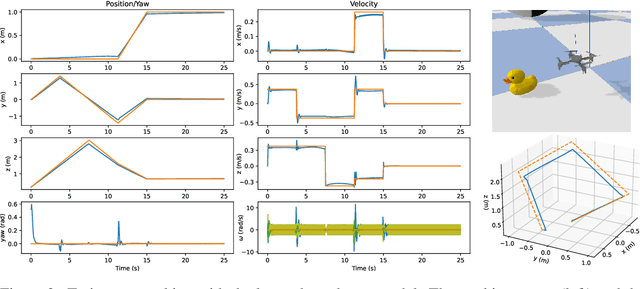
Incorporating prior knowledge of physics laws and structural properties of dynamical systems into the design of deep learning architectures has proven to be a powerful technique for improving their computational efficiency and generalization capacity. Learning accurate models of robot dynamics is critical for safe and stable control. Autonomous mobile robots, including wheeled, aerial, and underwater vehicles, can be modeled as controlled Lagrangian or Hamiltonian rigid-body systems evolving on matrix Lie groups. In this paper, we introduce a new structure-preserving deep learning architecture, the Lie group Forced Variational Integrator Network (LieFVIN), capable of learning controlled Lagrangian or Hamiltonian dynamics on Lie groups, either from position-velocity or position-only data. By design, LieFVINs preserve both the Lie group structure on which the dynamics evolve and the symplectic structure underlying the Hamiltonian or Lagrangian systems of interest. The proposed architecture learns surrogate discrete-time flow maps allowing accurate and fast prediction without numerical-integrator, neural-ODE, or adjoint techniques, which are needed for vector fields. Furthermore, the learnt discrete-time dynamics can be utilized with computationally scalable discrete-time (optimal) control strategies.
E2E Segmentation in a Two-Pass Cascaded Encoder ASR Model
Nov 28, 2022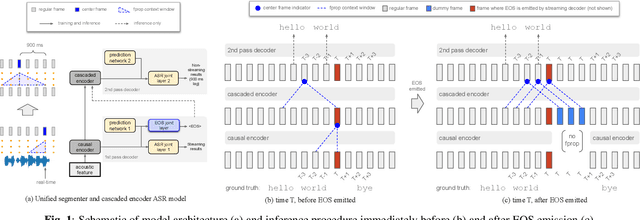
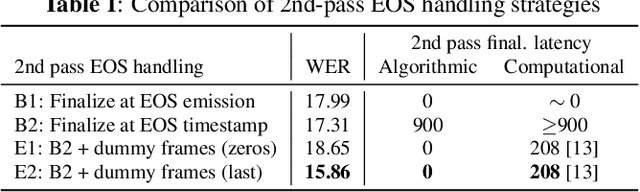
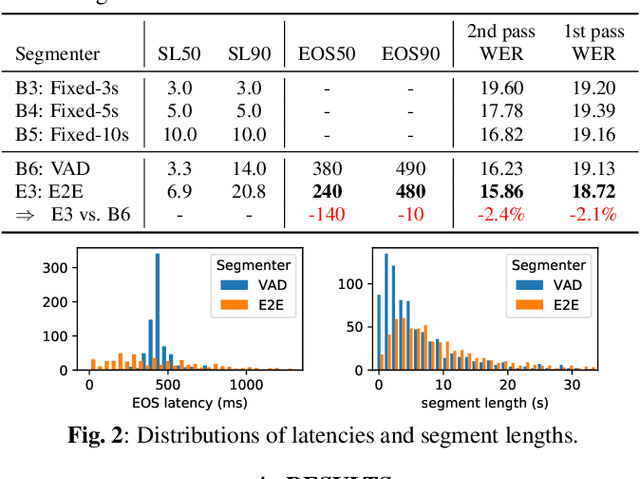
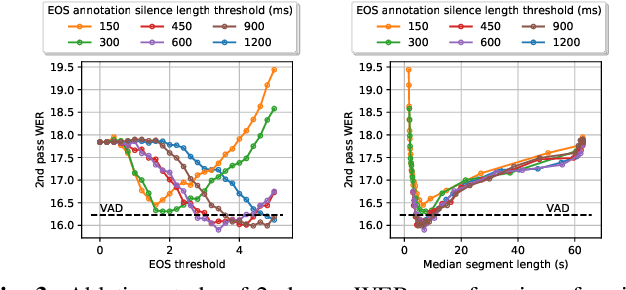
We explore unifying a neural segmenter with two-pass cascaded encoder ASR into a single model. A key challenge is allowing the segmenter (which runs in real-time, synchronously with the decoder) to finalize the 2nd pass (which runs 900 ms behind real-time) without introducing user-perceived latency or deletion errors during inference. We propose a design where the neural segmenter is integrated with the causal 1st pass decoder to emit a end-of-segment (EOS) signal in real-time. The EOS signal is then used to finalize the non-causal 2nd pass. We experiment with different ways to finalize the 2nd pass, and find that a novel dummy frame injection strategy allows for simultaneous high quality 2nd pass results and low finalization latency. On a real-world long-form captioning task (YouTube), we achieve 2.4% relative WER and 140 ms EOS latency gains over a baseline VAD-based segmenter with the same cascaded encoder.
Markov Chain Monte Carlo for Continuous-Time Switching Dynamical Systems
May 18, 2022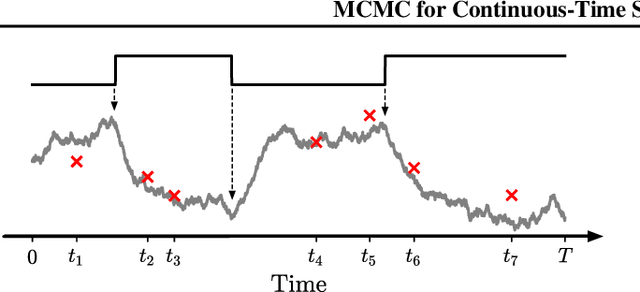
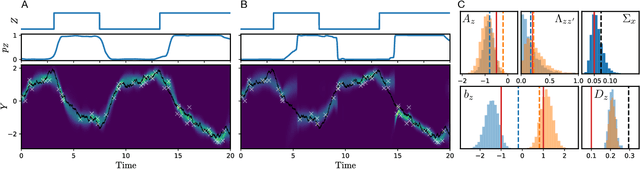
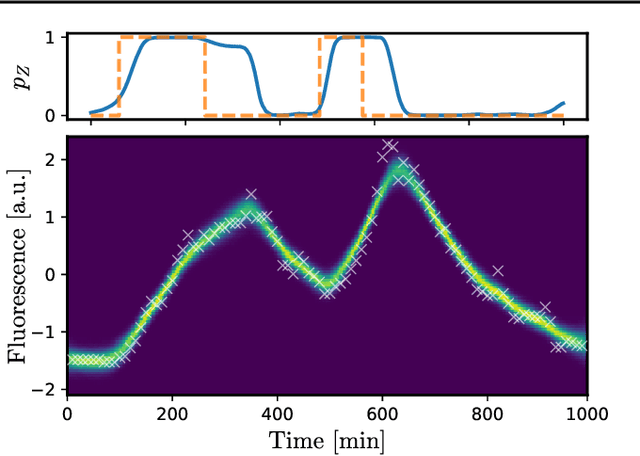
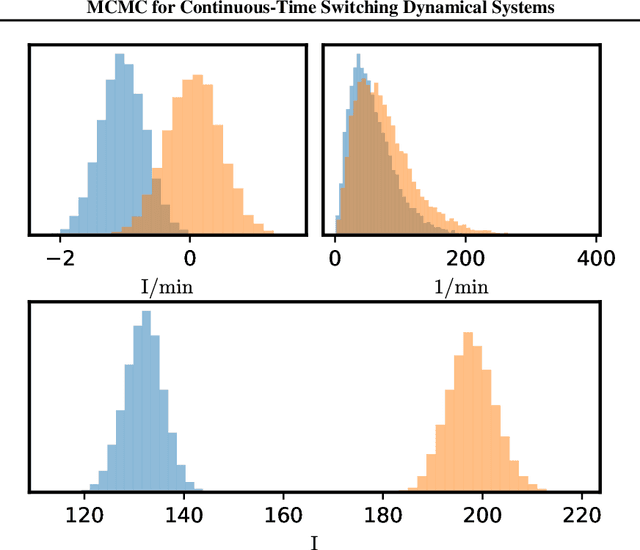
Switching dynamical systems are an expressive model class for the analysis of time-series data. As in many fields within the natural and engineering sciences, the systems under study typically evolve continuously in time, it is natural to consider continuous-time model formulations consisting of switching stochastic differential equations governed by an underlying Markov jump process. Inference in these types of models is however notoriously difficult, and tractable computational schemes are rare. In this work, we propose a novel inference algorithm utilizing a Markov Chain Monte Carlo approach. The presented Gibbs sampler allows to efficiently obtain samples from the exact continuous-time posterior processes. Our framework naturally enables Bayesian parameter estimation, and we also include an estimate for the diffusion covariance, which is oftentimes assumed fixed in stochastic differential equation models. We evaluate our framework under the modeling assumption and compare it against an existing variational inference approach.
Augmented Lagrangian Methods for Time-varying Constrained Online Convex Optimization
May 19, 2022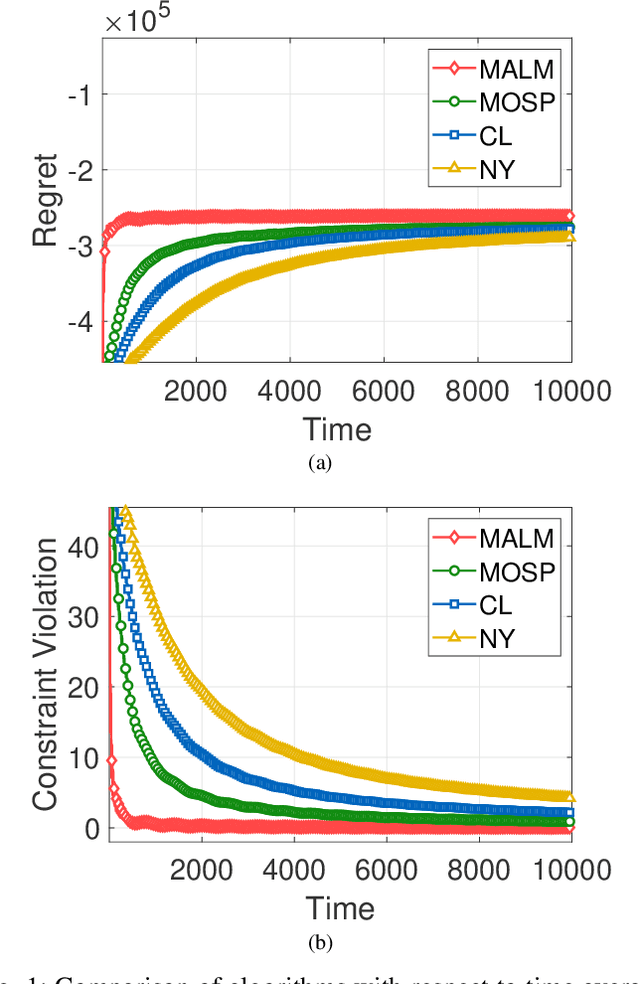
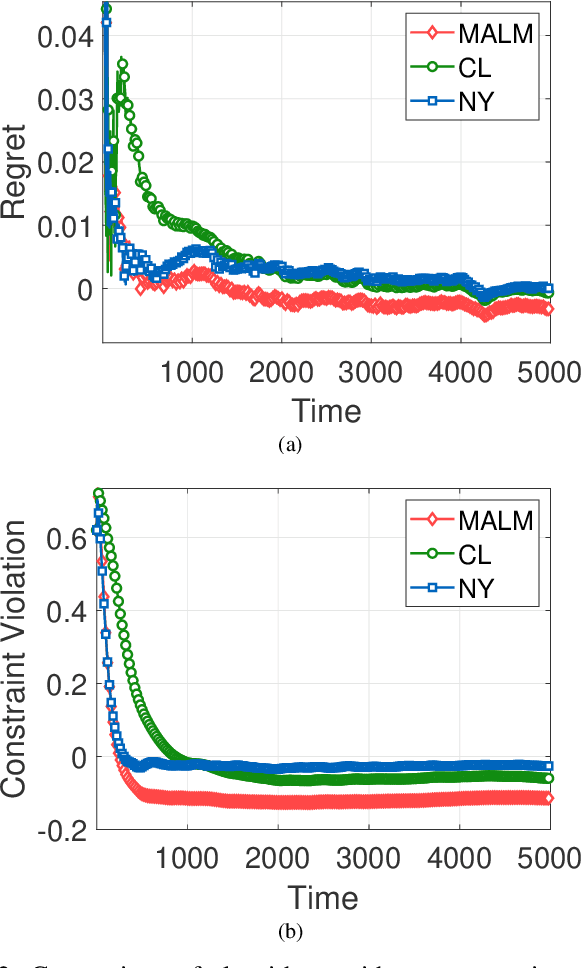
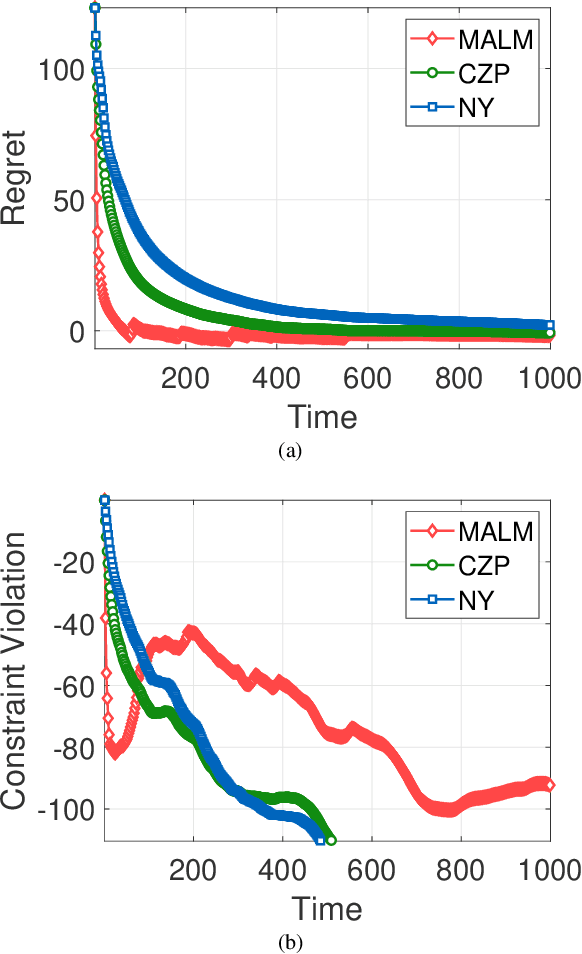
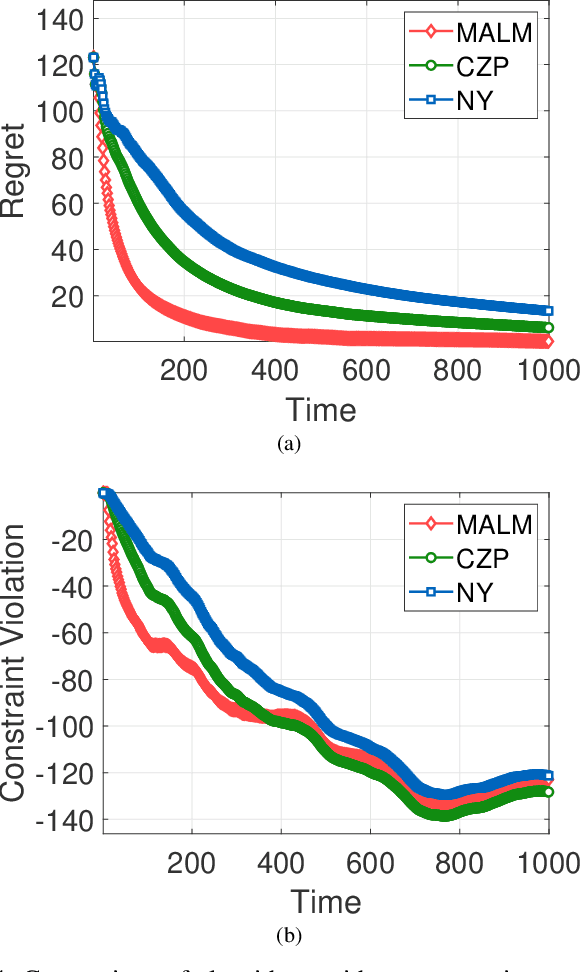
In this paper, we consider online convex optimization (OCO) with time-varying loss and constraint functions. Specifically, the decision maker chooses sequential decisions based only on past information, meantime the loss and constraint functions are revealed over time. We first develop a class of model-based augmented Lagrangian methods (MALM) for time-varying functional constrained OCO (without feedback delay). Under standard assumptions, we establish sublinear regret and sublinear constraint violation of MALM. Furthermore, we extend MALM to deal with time-varying functional constrained OCO with delayed feedback, in which the feedback information of loss and constraint functions is revealed to decision maker with delays. Without additional assumptions, we also establish sublinear regret and sublinear constraint violation for the delayed version of MALM. Finally, numerical results for several examples of constrained OCO including online network resource allocation, online logistic regression and online quadratically constrained quadratical program are presented to demonstrate the efficiency of the proposed algorithms.
FOF: Learning Fourier Occupancy Field for Monocular Real-time Human Reconstruction
Jun 05, 2022

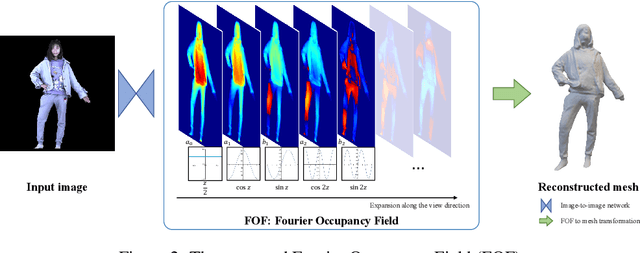

The advent of deep learning has led to significant progress in monocular human reconstruction. However, existing representations, such as parametric models, voxel grids, meshes and implicit neural representations, have difficulties achieving high-quality results and real-time speed at the same time. In this paper, we propose Fourier Occupancy Field (FOF), a novel powerful, efficient and flexible 3D representation, for monocular real-time and accurate human reconstruction. The FOF represents a 3D object with a 2D field orthogonal to the view direction where at each 2D position the occupancy field of the object along the view direction is compactly represented with the first few terms of Fourier series, which retains the topology and neighborhood relation in the 2D domain. A FOF can be stored as a multi-channel image, which is compatible with 2D convolutional neural networks and can bridge the gap between 3D geometries and 2D images. The FOF is very flexible and extensible, e.g., parametric models can be easily integrated into a FOF as a prior to generate more robust results. Based on FOF, we design the first 30+FPS high-fidelity real-time monocular human reconstruction framework. We demonstrate the potential of FOF on both public dataset and real captured data. The code will be released for research purposes.
A Verification Framework for Component-Based Modeling and Simulation Putting the pieces together
Jan 08, 2023
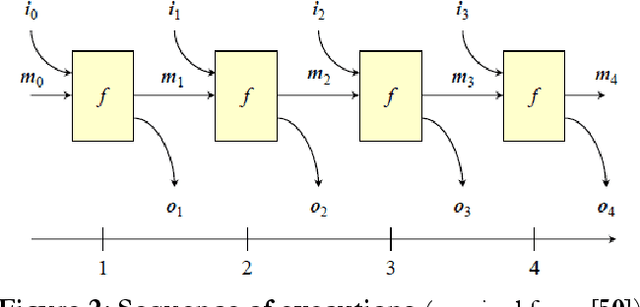
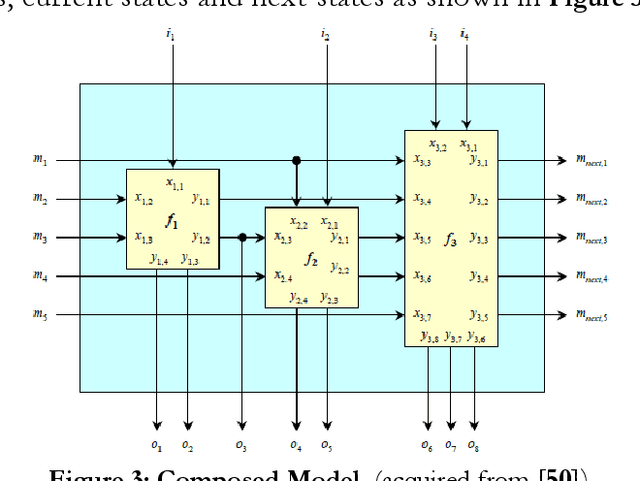
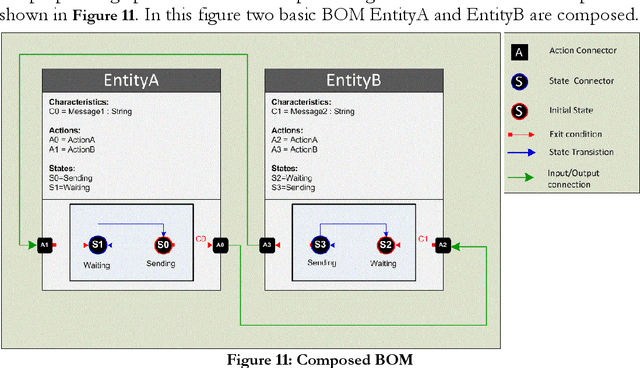
In this thesis a comprehensive verification framework is proposed to contend with some important issues in composability verification and a verification process is suggested to verify composability of different kinds of systems models, such as reactive, real-time and probabilistic systems. With an assumption that all these systems are concurrent in nature in which different composed components interact with each other simultaneously, the requirements for the extensive techniques for the structural and behavioral analysis becomes increasingly challenging. The proposed verification framework provides methods, techniques and tool support for verifying composability at its different levels. These levels are defined as foundations of consistent model composability. Each level is discussed in detail and an approach is presented to verify composability at that level. In particular we focus on the Dynamic-Semantic Composability level due to its significance in the overall composability correctness and also due to the level of difficulty it poses in the process. In order to verify composability at this level we investigate the application of three different approaches namely (i) Petri Nets based Algebraic Analysis (ii) Colored Petri Nets (CPN) based State-space Analysis and (iii) Communicating Sequential Processes based Model Checking. All three approaches attack the problem of verifying dynamic-semantic composability in different ways however they all share the same aim i.e., to confirm the correctness of a composed model with respect to its requirement specifications.