 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Mathematics of multi-agent learning systems at the interface of game theory and artificial intelligence
Mar 09, 2024
Evolutionary Game Theory (EGT) and Artificial Intelligence (AI) are two fields that, at first glance, might seem distinct, but they have notable connections and intersections. The former focuses on the evolution of behaviors (or strategies) in a population, where individuals interact with others and update their strategies based on imitation (or social learning). The more successful a strategy is, the more prevalent it becomes over time. The latter, meanwhile, is centered on machine learning algorithms and (deep) neural networks. It is often from a single-agent perspective but increasingly involves multi-agent environments, in which intelligent agents adjust their strategies based on feedback and experience, somewhat akin to the evolutionary process yet distinct in their self-learning capacities. In light of the key components necessary to address real-world problems, including (i) learning and adaptation, (ii) cooperation and competition, (iii) robustness and stability, and altogether (iv) population dynamics of individual agents whose strategies evolve, the cross-fertilization of ideas between both fields will contribute to the advancement of mathematics of multi-agent learning systems, in particular, to the nascent domain of ``collective cooperative intelligence'' bridging evolutionary dynamics and multi-agent reinforcement learning.
Provable Policy Gradient Methods for Average-Reward Markov Potential Games
Mar 09, 2024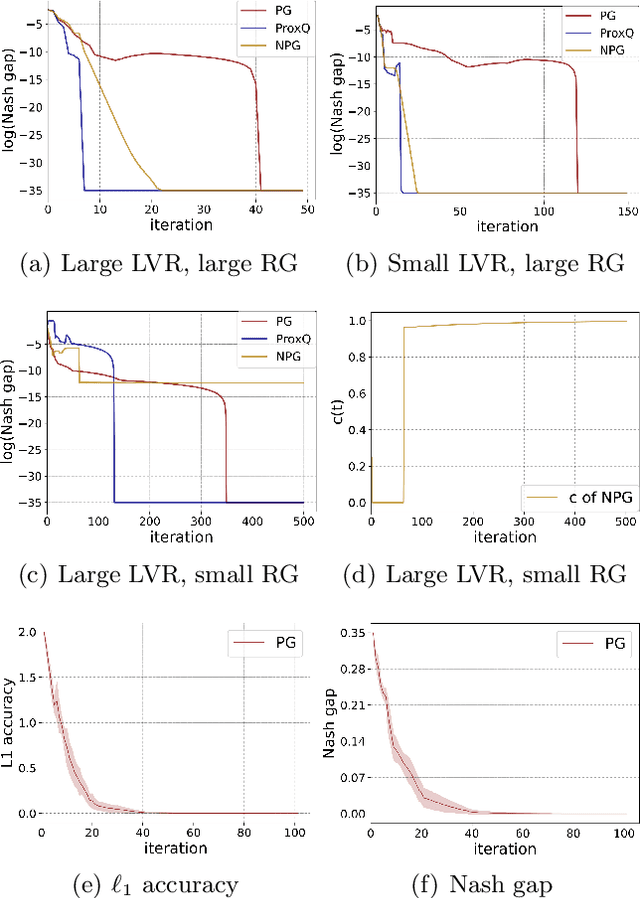
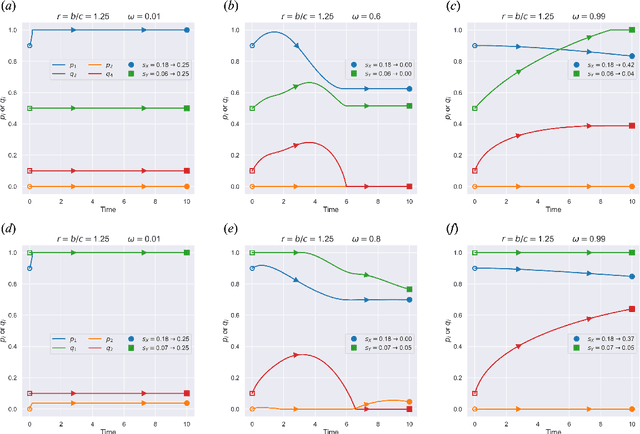
We study Markov potential games under the infinite horizon average reward criterion. Most previous studies have been for discounted rewards. We prove that both algorithms based on independent policy gradient and independent natural policy gradient converge globally to a Nash equilibrium for the average reward criterion. To set the stage for gradient-based methods, we first establish that the average reward is a smooth function of policies and provide sensitivity bounds for the differential value functions, under certain conditions on ergodicity and the second largest eigenvalue of the underlying Markov decision process (MDP). We prove that three algorithms, policy gradient, proximal-Q, and natural policy gradient (NPG), converge to an $\epsilon$-Nash equilibrium with time complexity $O(\frac{1}{\epsilon^2})$, given a gradient/differential Q function oracle. When policy gradients have to be estimated, we propose an algorithm with $\tilde{O}(\frac{1}{\min_{s,a}\pi(a|s)\delta})$ sample complexity to achieve $\delta$ approximation error w.r.t~the $\ell_2$ norm. Equipped with the estimator, we derive the first sample complexity analysis for a policy gradient ascent algorithm, featuring a sample complexity of $\tilde{O}(1/\epsilon^5)$. Simulation studies are presented.
Only the Curve Shape Matters: Training Foundation Models for Zero-Shot Multivariate Time Series Forecasting through Next Curve Shape Prediction
Feb 19, 2024We present General Time Transformer (GTT), an encoder-only style foundation model for zero-shot multivariate time series forecasting. GTT is pretrained on a large dataset of 200M high-quality time series samples spanning diverse domains. In our proposed framework, the task of multivariate time series forecasting is formulated as a channel-wise next curve shape prediction problem, where each time series sample is represented as a sequence of non-overlapping curve shapes with a unified numerical magnitude. GTT is trained to predict the next curve shape based on a window of past curve shapes in a channel-wise manner. Experimental results demonstrate that GTT exhibits superior zero-shot multivariate forecasting capabilities on unseen time series datasets, even surpassing state-of-the-art supervised baselines. Additionally, we investigate the impact of varying GTT model parameters and training dataset scales, observing that the scaling law also holds in the context of zero-shot multivariate time series forecasting.
MMSR: Symbolic Regression is a Multimodal Task
Mar 10, 2024Mathematical formulas are the crystallization of human wisdom in exploring the laws of nature for thousands of years. Describing the complex laws of nature with a concise mathematical formula is a constant pursuit of scientists and a great challenge for artificial intelligence. This field is called symbolic regression. Symbolic regression was originally formulated as a combinatorial optimization problem, and GP and reinforcement learning algorithms were used to solve it. However, GP is sensitive to hyperparameters, and these two types of algorithms are inefficient. To solve this problem, researchers treat the mapping from data to expressions as a translation problem. And the corresponding large-scale pre-trained model is introduced. However, the data and expression skeletons do not have very clear word correspondences as the two languages do. Instead, they are more like two modalities (e.g., image and text). Therefore, in this paper, we proposed MMSR. The SR problem is solved as a pure multimodal problem, and contrastive learning is also introduced in the training process for modal alignment to facilitate later modal feature fusion. It is worth noting that in order to better promote the modal feature fusion, we adopt the strategy of training contrastive learning loss and other losses at the same time, which only needs one-step training, instead of training contrastive learning loss first and then training other losses. Because our experiments prove training together can make the feature extraction module and feature fusion module running-in better. Experimental results show that compared with multiple large-scale pre-training baselines, MMSR achieves the most advanced results on multiple mainstream datasets including SRBench.
Uncovering the Deep Filter Bubble: Narrow Exposure in Short-Video Recommendation
Mar 07, 2024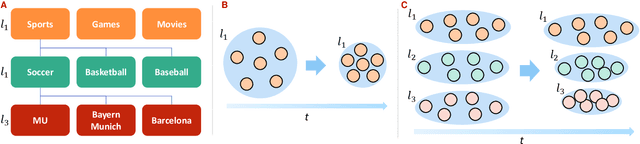
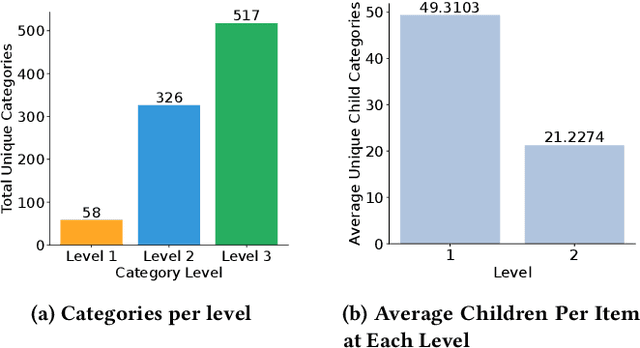
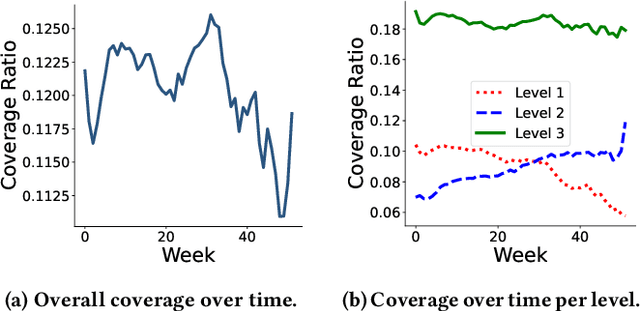
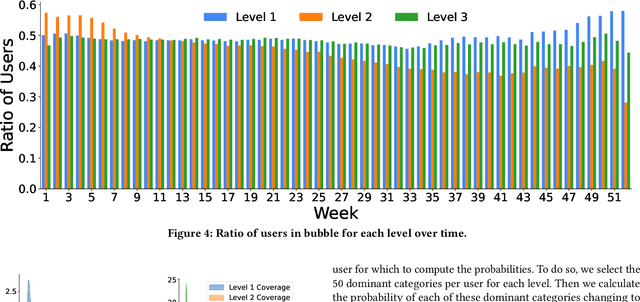
Filter bubbles have been studied extensively within the context of online content platforms due to their potential to cause undesirable outcomes such as user dissatisfaction or polarization. With the rise of short-video platforms, the filter bubble has been given extra attention because these platforms rely on an unprecedented use of the recommender system to provide relevant content. In our work, we investigate the deep filter bubble, which refers to the user being exposed to narrow content within their broad interests. We accomplish this using one-year interaction data from a top short-video platform in China, which includes hierarchical data with three levels of categories for each video. We formalize our definition of a "deep" filter bubble within this context, and then explore various correlations within the data: first understanding the evolution of the deep filter bubble over time, and later revealing some of the factors that give rise to this phenomenon, such as specific categories, user demographics, and feedback type. We observe that while the overall proportion of users in a filter bubble remains largely constant over time, the depth composition of their filter bubble changes. In addition, we find that some demographic groups that have a higher likelihood of seeing narrower content and implicit feedback signals can lead to less bubble formation. Finally, we propose some ways in which recommender systems can be designed to reduce the risk of a user getting caught in a bubble.
Inference via Interpolation: Contrastive Representations Provably Enable Planning and Inference
Mar 06, 2024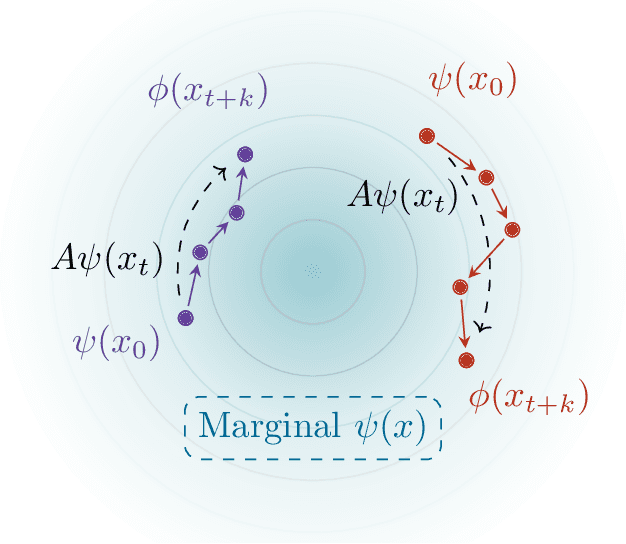
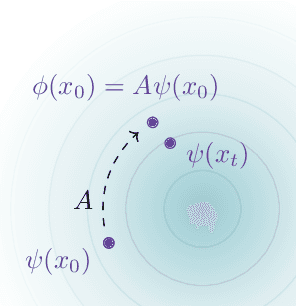

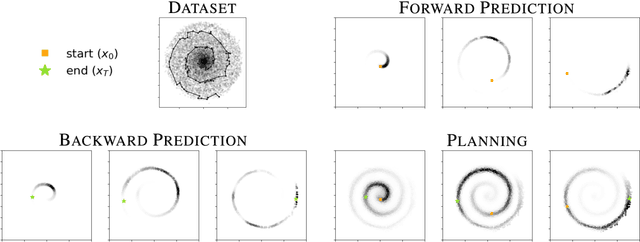
Given time series data, how can we answer questions like "what will happen in the future?" and "how did we get here?" These sorts of probabilistic inference questions are challenging when observations are high-dimensional. In this paper, we show how these questions can have compact, closed form solutions in terms of learned representations. The key idea is to apply a variant of contrastive learning to time series data. Prior work already shows that the representations learned by contrastive learning encode a probability ratio. By extending prior work to show that the marginal distribution over representations is Gaussian, we can then prove that joint distribution of representations is also Gaussian. Taken together, these results show that representations learned via temporal contrastive learning follow a Gauss-Markov chain, a graphical model where inference (e.g., prediction, planning) over representations corresponds to inverting a low-dimensional matrix. In one special case, inferring intermediate representations will be equivalent to interpolating between the learned representations. We validate our theory using numerical simulations on tasks up to 46-dimensions.
Binaural Speech Enhancement Using Deep Complex Convolutional Transformer Networks
Mar 08, 2024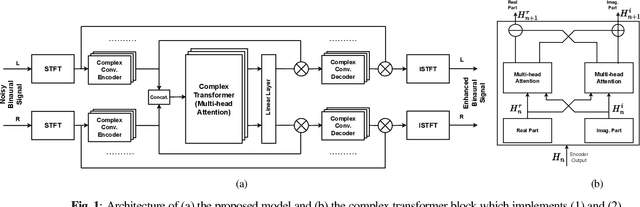
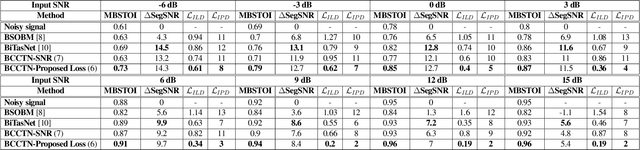
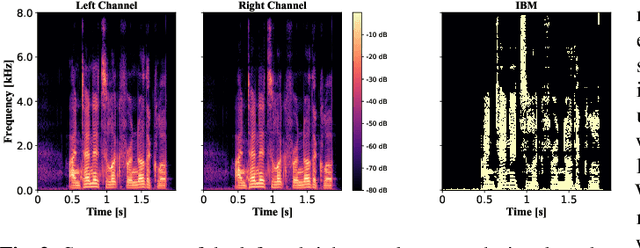
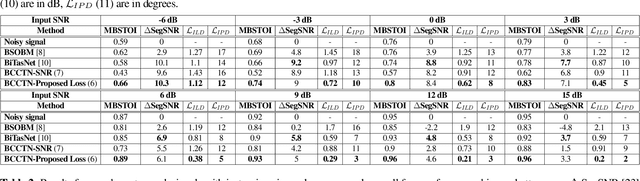
Studies have shown that in noisy acoustic environments, providing binaural signals to the user of an assistive listening device may improve speech intelligibility and spatial awareness. This paper presents a binaural speech enhancement method using a complex convolutional neural network with an encoder-decoder architecture and a complex multi-head attention transformer. The model is trained to estimate individual complex ratio masks in the time-frequency domain for the left and right-ear channels of binaural hearing devices. The model is trained using a novel loss function that incorporates the preservation of spatial information along with speech intelligibility improvement and noise reduction. Simulation results for acoustic scenarios with a single target speaker and isotropic noise of various types show that the proposed method improves the estimated binaural speech intelligibility and preserves the binaural cues better in comparison with several baseline algorithms.
DualBEV: CNN is All You Need in View Transformation
Mar 08, 2024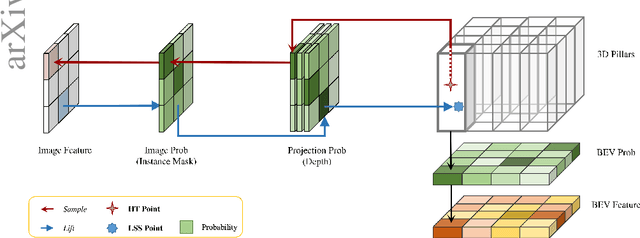


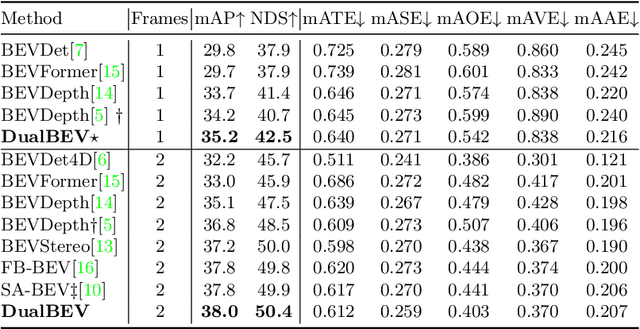
Camera-based Bird's-Eye-View (BEV) perception often struggles between adopting 3D-to-2D or 2D-to-3D view transformation (VT). The 3D-to-2D VT typically employs resource intensive Transformer to establish robust correspondences between 3D and 2D feature, while the 2D-to-3D VT utilizes the Lift-Splat-Shoot (LSS) pipeline for real-time application, potentially missing distant information. To address these limitations, we propose DualBEV, a unified framework that utilizes a shared CNN-based feature transformation incorporating three probabilistic measurements for both strategies. By considering dual-view correspondences in one-stage, DualBEV effectively bridges the gap between these strategies, harnessing their individual strengths. Our method achieves state-of-the-art performance without Transformer, delivering comparable efficiency to the LSS approach, with 55.2% mAP and 63.4% NDS on the nuScenes test set. Code will be released at https://github.com/PeidongLi/DualBEV.
RFWave: Multi-band Rectified Flow for Audio Waveform Reconstruction
Mar 08, 2024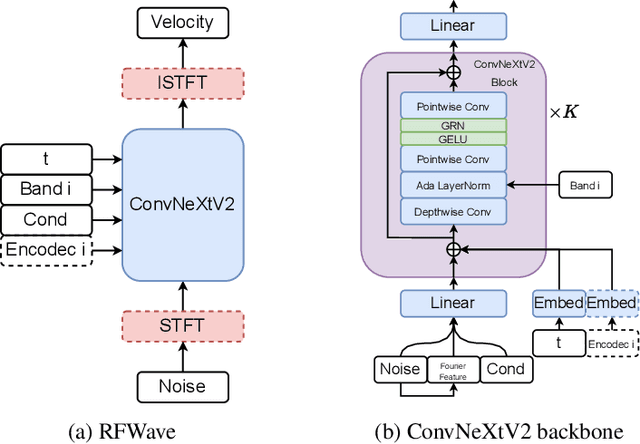
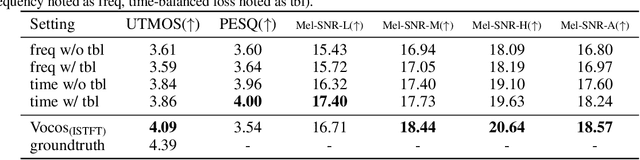
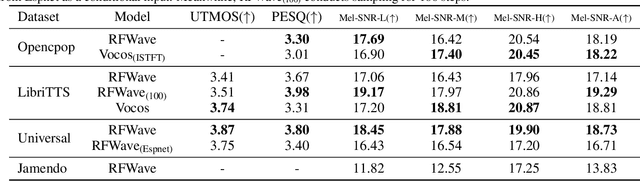

Recent advancements in generative modeling have led to significant progress in audio waveform reconstruction from diverse representations. Although diffusion models have been used for reconstructing audio waveforms, they tend to exhibit latency issues because they operate at the level of individual sample points and require a relatively large number of sampling steps. In this study, we introduce RFWave, a novel multi-band Rectified Flow approach that reconstructs high-fidelity audio waveforms from Mel-spectrograms. RFWave is distinctive for generating complex spectrograms and operating at the frame level, processing all subbands concurrently to enhance efficiency. Thanks to Rectified Flow, which aims for a flat transport trajectory, RFWave requires only 10 sampling steps. Empirical evaluations demonstrate that RFWave achieves exceptional reconstruction quality and superior computational efficiency, capable of generating audio at a speed 90 times faster than real-time.
DOCTOR: Dynamic On-Chip Remediation Against Temporally-Drifting Thermal Variations Toward Self-Corrected Photonic Tensor Accelerators
Mar 05, 2024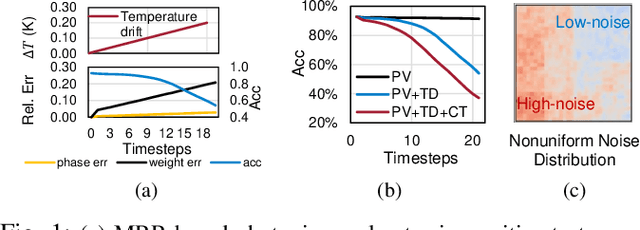
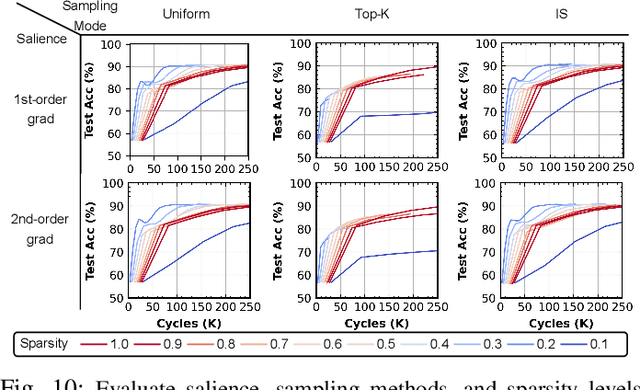
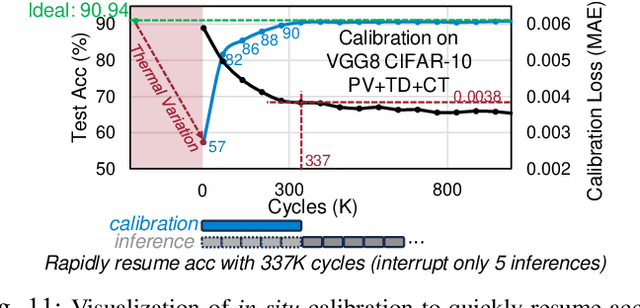
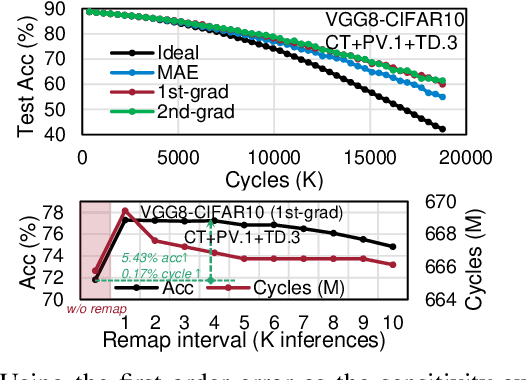
Photonic computing has emerged as a promising solution for accelerating computation-intensive artificial intelligence (AI) workloads, offering unparalleled speed and energy efficiency, especially in resource-limited, latency-sensitive edge computing environments. However, the deployment of analog photonic tensor accelerators encounters reliability challenges due to hardware noises and environmental variations. While off-chip noise-aware training and on-chip training have been proposed to enhance the variation tolerance of optical neural accelerators with moderate, static noises, we observe a notable performance degradation over time due to temporally drifting variations, which requires a real-time, in-situ calibration mechanism. To tackle this challenging reliability issues, for the first time, we propose a lightweight dynamic on-chip remediation framework, dubbed DOCTOR, providing adaptive, in-situ accuracy recovery against temporally drifting noises. The DOCTOR framework intelligently monitors the chip status using adaptive probing and performs fast in-situ training-free calibration to restore accuracy when necessary. Recognizing nonuniform spatial variation distributions across devices and tensor cores, we also propose a variation-aware architectural remapping strategy to avoid executing critical tasks on noisy devices. Extensive experiments show that our proposed framework can guarantee sustained performance under drifting variations with 34% higher accuracy and 2-3 orders-of-magnitude lower overhead compared to state-of-the-art on-chip training methods.