 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast conformational clustering of extensive molecular dynamics simulation data
Jan 11, 2023
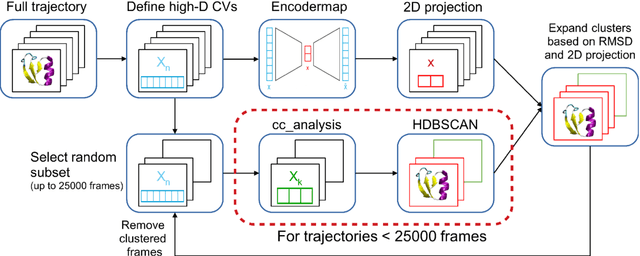
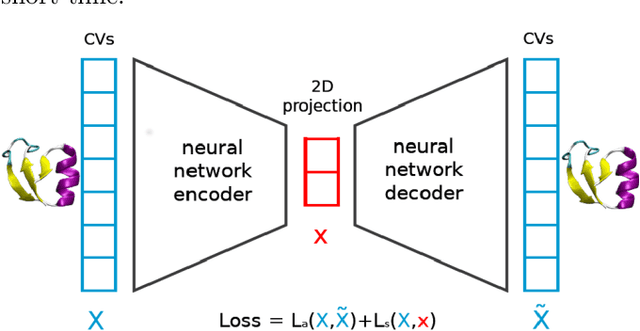
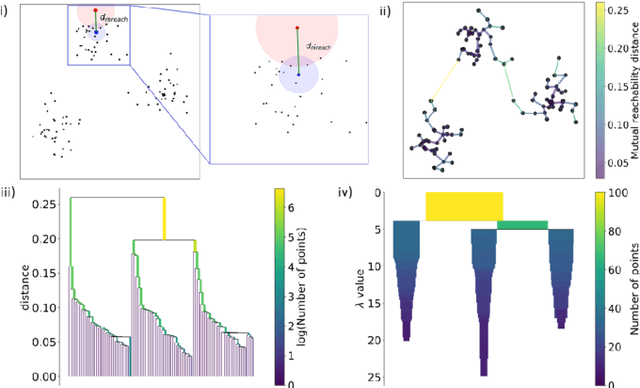
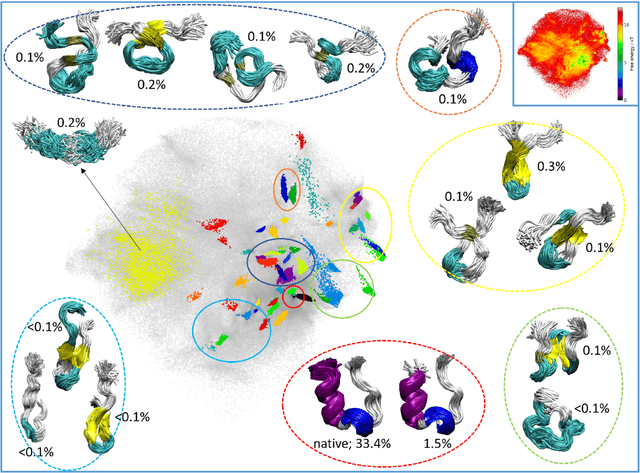
We present an unsupervised data processing workflow that is specifically designed to obtain a fast conformational clustering of long molecular dynamics simulation trajectories. In this approach we combine two dimensionality reduction algorithms (cc\_analysis and encodermap) with a density-based spatial clustering algorithm (HDBSCAN). The proposed scheme benefits from the strengths of the three algorithms while avoiding most of the drawbacks of the individual methods. Here the cc\_analysis algorithm is for the first time applied to molecular simulation data. Encodermap complements cc\_analysis by providing an efficient way to process and assign large amounts of data to clusters. The main goal of the procedure is to maximize the number of assigned frames of a given trajectory, while keeping a clear conformational identity of the clusters that are found. In practice we achieve this by using an iterative clustering approach and a tunable root-mean-square-deviation-based criterion in the final cluster assignment. This allows to find clusters of different densities as well as different degrees of structural identity. With the help of four test systems we illustrate the capability and performance of this clustering workflow: wild-type and thermostable mutant of the Trp-cage protein (TC5b and TC10b), NTL9 and Protein B. Each of these systems poses individual challenges to the scheme, which in total give a nice overview of the advantages, as well as potential difficulties that can arise when using the proposed method.
On the Finite-Time Performance of the Knowledge Gradient Algorithm
Jun 17, 2022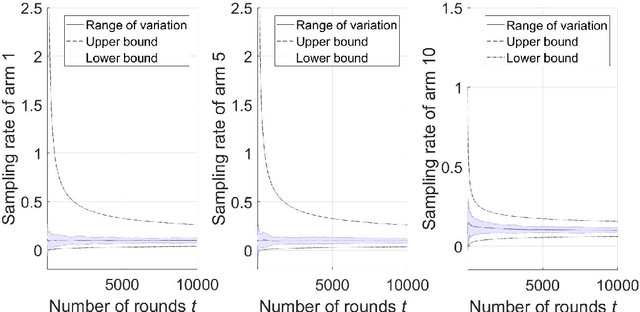
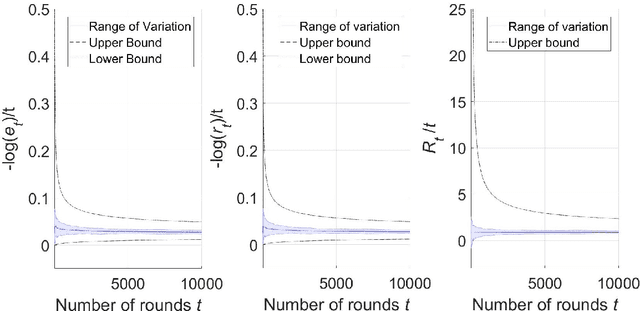
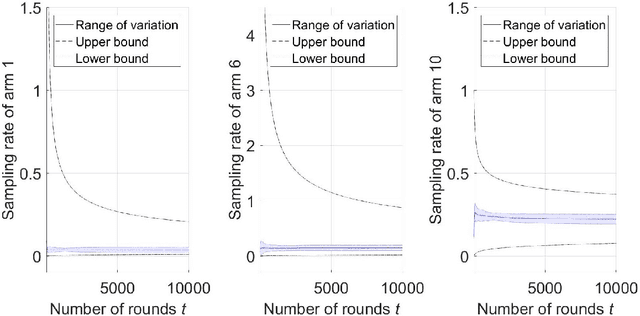
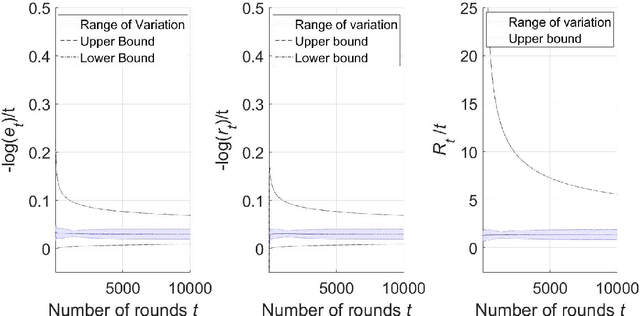
The knowledge gradient (KG) algorithm is a popular and effective algorithm for the best arm identification (BAI) problem. Due to the complex calculation of KG, theoretical analysis of this algorithm is difficult, and existing results are mostly about the asymptotic performance of it, e.g., consistency, asymptotic sample allocation, etc. In this research, we present new theoretical results about the finite-time performance of the KG algorithm. Under independent and normally distributed rewards, we derive lower bounds and upper bounds for the probability of error and simple regret of the algorithm. With these bounds, existing asymptotic results become simple corollaries. We also show the performance of the algorithm for the multi-armed bandit (MAB) problem. These developments not only extend the existing analysis of the KG algorithm, but can also be used to analyze other improvement-based algorithms. Last, we use numerical experiments to further demonstrate the finite-time behavior of the KG algorithm.
Test Time Transform Prediction for Open Set Histopathological Image Recognition
Jun 20, 2022
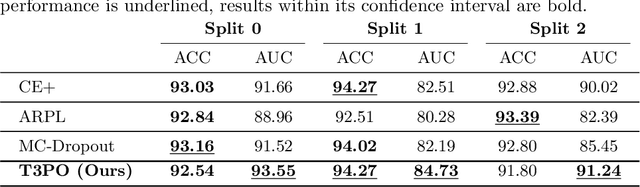
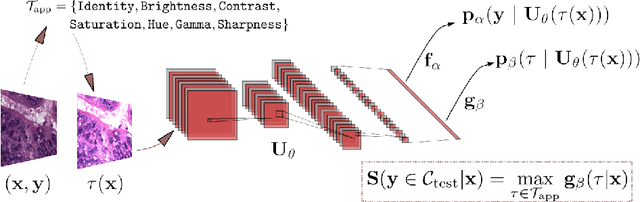
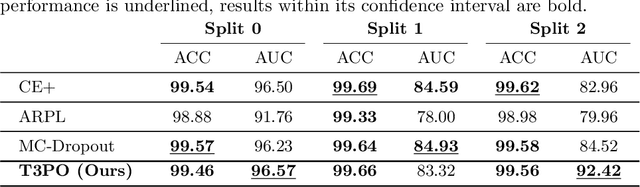
Tissue typology annotation in Whole Slide histological images is a complex and tedious, yet necessary task for the development of computational pathology models. We propose to address this problem by applying Open Set Recognition techniques to the task of jointly classifying tissue that belongs to a set of annotated classes, e.g. clinically relevant tissue categories, while rejecting in test time Open Set samples, i.e. images that belong to categories not present in the training set. To this end, we introduce a new approach for Open Set histopathological image recognition based on training a model to accurately identify image categories and simultaneously predict which data augmentation transform has been applied. In test time, we measure model confidence in predicting this transform, which we expect to be lower for images in the Open Set. We carry out comprehensive experiments in the context of colorectal cancer assessment from histological images, which provide evidence on the strengths of our approach to automatically identify samples from unknown categories. Code is released at https://github.com/agaldran/t3po .
CAFA: Class-Aware Feature Alignment for Test-Time Adaptation
Jun 01, 2022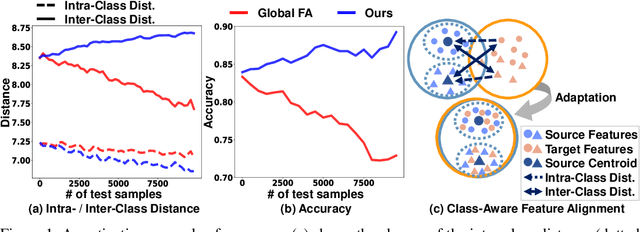
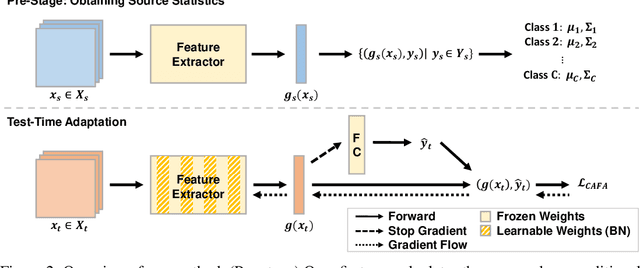
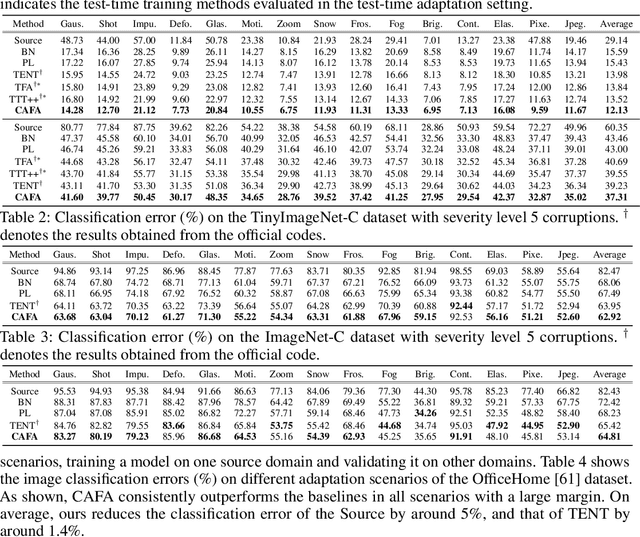
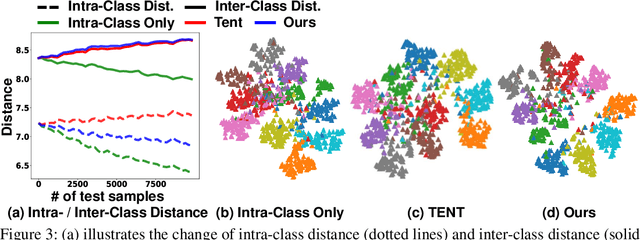
Despite recent advancements in deep learning, deep networks still suffer from performance degradation when they face new and different data from their training distributions. Addressing such a problem, test-time adaptation (TTA) aims to adapt a model to unlabeled test data on test time while making predictions simultaneously. TTA applies to pretrained networks without modifying their training procedures, which enables to utilize the already well-formed source distribution for adaptation. One possible approach is to align the representation space of test samples to the source distribution (\textit{i.e.,} feature alignment). However, performing feature alignments in TTA is especially challenging in that the access to labeled source data is restricted during adaptation. That is, a model does not have a chance to learn test data in a class-discriminative manner, which was feasible in other adaptation tasks (\textit{e.g.,} unsupervised domain adaptation) via supervised loss on the source data. Based on such an observation, this paper proposes \emph{a simple yet effective} feature alignment loss, termed as Class-Aware Feature Alignment (CAFA), which 1) encourages a model to learn target representations in a class-discriminative manner and 2) effectively mitigates the distribution shifts in test time, simultaneously. Our method does not require any hyper-parameters or additional losses, which are required in the previous approaches. We conduct extensive experiments and show our proposed method consistently outperforms existing baselines.
Quantum Representations of Sound: from mechanical waves to quantum circuits
Jan 01, 2023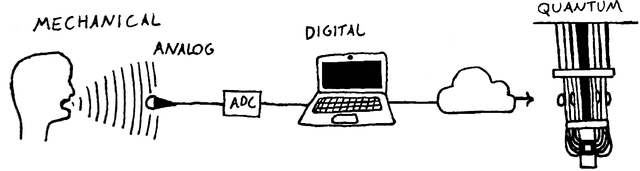
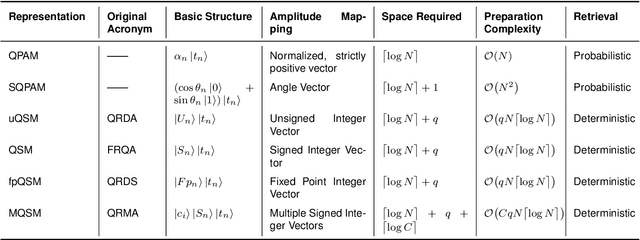
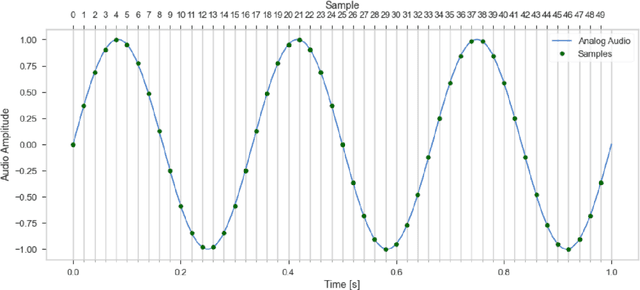
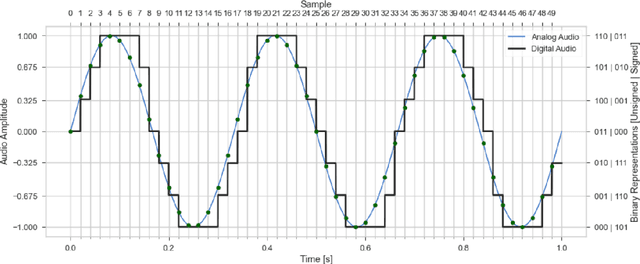
By the time of writing, quantum audio still is a very young area of study, even within the quantum signal processing community. This chapter introduces the state of the art in quantum audio and discusses methods for the quantum representation of audio signals. Currently, no quantum representation strategy claims to be the best one for audio applications. Each one presents advantages and disadvantages. It can be argued that future quantum audio representation schemes will make use of multiple strategies aimed at specific applications. NOTE: This is an unedited abridged version of the pre-submission draft of a chapter, with the same title, published in the book Quantum Computer Music: Foundations, Methods and Advanced Concepts, by E. R. Miranda (pp. 223 - 274). Please refer to the version in this book for application examples and a discussion on sound synthesis methods based on quantum audio representation and their potential for developing new types of musical instruments. https://link.springer.com/book/10.1007/978-3-031-13909-3
Modeling Continuous Time Sequences with Intermittent Observations using Marked Temporal Point Processes
Jun 23, 2022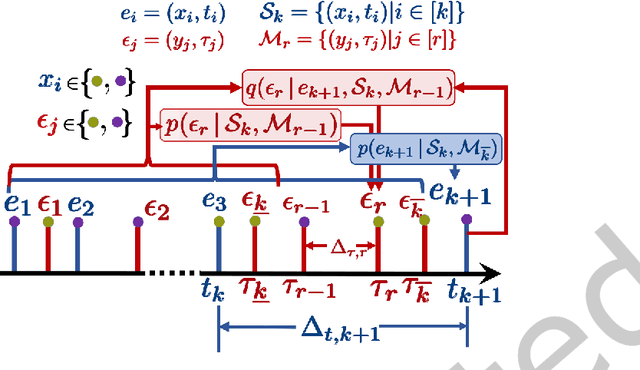

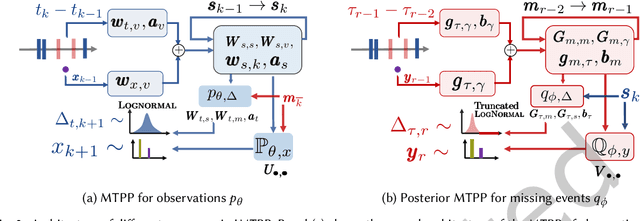
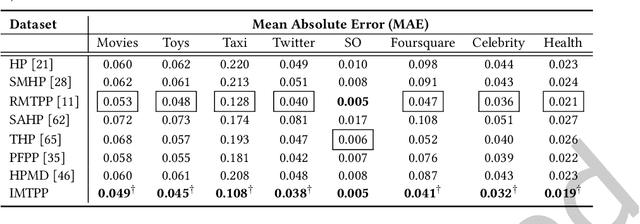
A large fraction of data generated via human activities such as online purchases, health records, spatial mobility etc. can be represented as a sequence of events over a continuous-time. Learning deep learning models over these continuous-time event sequences is a non-trivial task as it involves modeling the ever-increasing event timestamps, inter-event time gaps, event types, and the influences between different events within and across different sequences. In recent years neural enhancements to marked temporal point processes (MTPP) have emerged as a powerful framework to model the underlying generative mechanism of asynchronous events localized in continuous time. However, most existing models and inference methods in the MTPP framework consider only the complete observation scenario i.e. the event sequence being modeled is completely observed with no missing events -- an ideal setting that is rarely applicable in real-world applications. A recent line of work which considers missing events while training MTPP utilizes supervised learning techniques that require additional knowledge of missing or observed label for each event in a sequence, which further restricts its practicability as in several scenarios the details of missing events is not known apriori. In this work, we provide a novel unsupervised model and inference method for learning MTPP in presence of event sequences with missing events. Specifically, we first model the generative processes of observed events and missing events using two MTPP, where the missing events are represented as latent random variables. Then, we devise an unsupervised training method that jointly learns both the MTPP by means of variational inference. Such a formulation can effectively impute the missing data among the observed events and can identify the optimal position of missing events in a sequence.
L-SeqSleepNet: Whole-cycle Long Sequence Modelling for Automatic Sleep Staging
Jan 09, 2023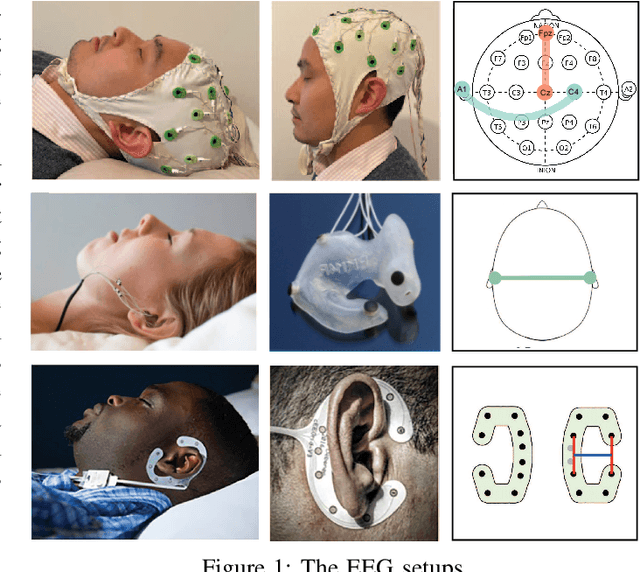
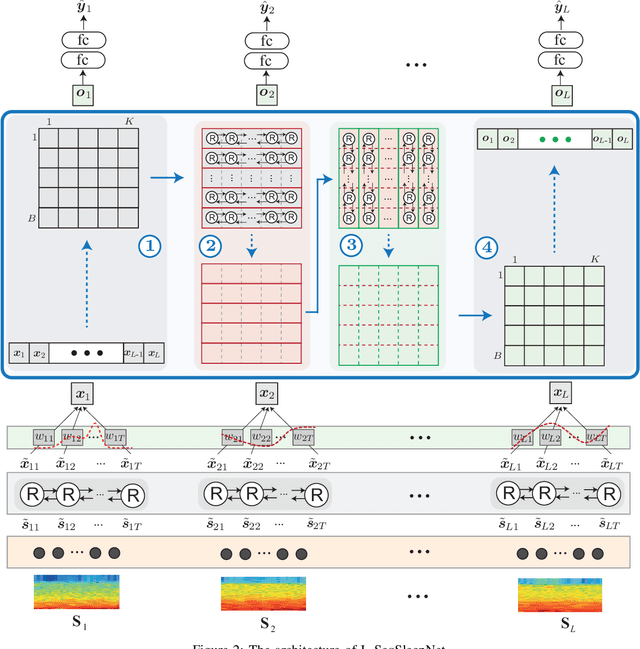
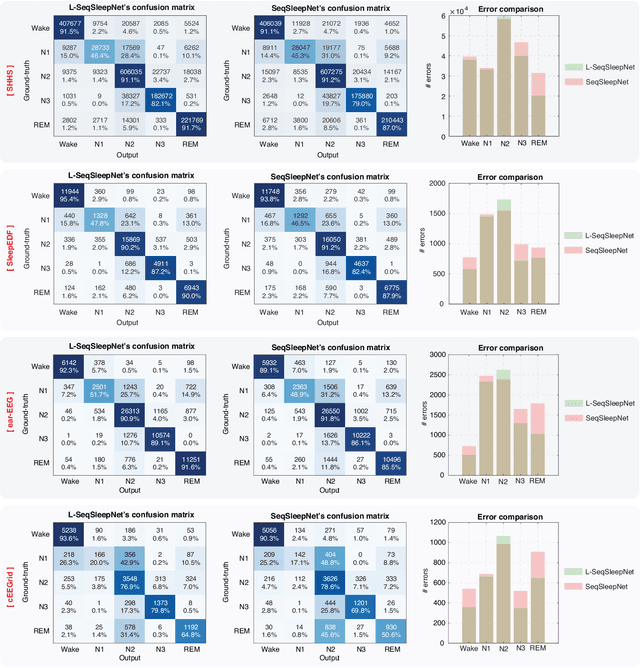
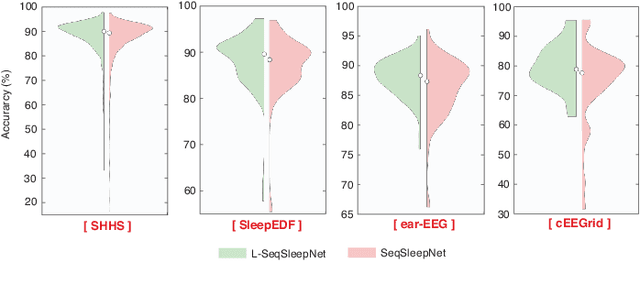
Human sleep is cyclical with a period of approximately 90 minutes, implying long temporal dependency in the sleep data. Yet, exploring this long-term dependency when developing sleep staging models has remained untouched. In this work, we show that while encoding the logic of a whole sleep cycle is crucial to improve sleep staging performance, the sequential modelling approach in existing state-of-the-art deep learning models are inefficient for that purpose. We then introduce a method for efficient long sequence modelling and propose a new deep learning model, L-SeqSleepNet, incorporating this method to take into account whole-cycle sleep information for sleep staging. Evaluating L-SeqSleepNet on a set of four distinct databases of various sizes, we demonstrate state-of-the-art performance obtained by the model over three different EEG setups, including scalp EEG in conventional Polysomnography (PSG), in-ear EEG, and around-the-ear EEG (cEEGrid), even with a single-EEG channel input. Our analyses also show that L-SeqSleepNet is able to remedy the effect of N2 sleep (the major class in terms of classification) to bring down errors in other sleep stages and that the network largely reduces exceptionally high errors seen in many subjects. Finally, the computation time only grows at a sub-linear rate when the sequence length increases.
Training one model to detect heart and lung sound events from single point auscultations
Jan 15, 2023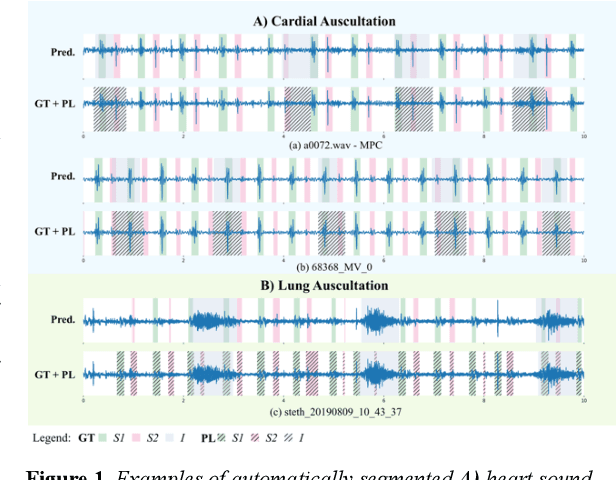
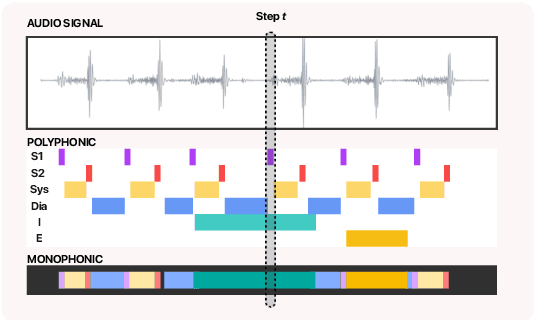
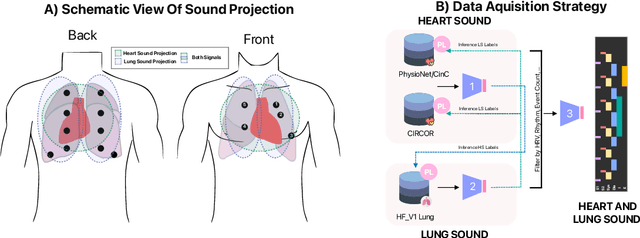
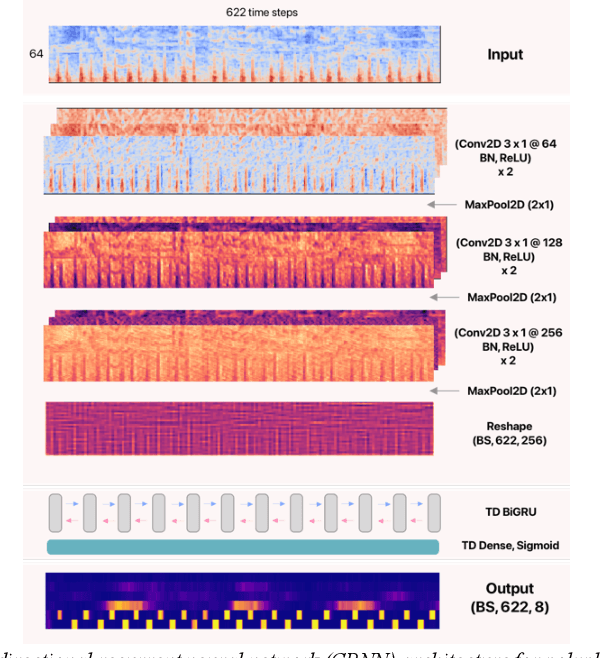
Objective: This work proposes a semi-supervised training approach for detecting lung and heart sounds simultaneously with only one trained model and in invariance to the auscultation point. Methods: We use open-access data from the 2016 Physionet/CinC Challenge, the 2022 George Moody Challenge, and from the lung sound database HF_V1. We first train specialist single-task models using foreground ground truth (GT) labels from different auscultation databases to identify background sound events in the respective lung and heart auscultation databases. The pseudo-labels generated in this way were combined with the ground truth labels in a new training iteration, such that a new model was subsequently trained to detect foreground and background signals. Benchmark tests ensured that the newly trained model could detect both, lung, and heart sound events in different auscultation sites without regressing on the original task. We also established hand-validated labels for the respective background signal in heart and lung sound auscultations to evaluate the models. Results: In this work, we report for the first time results for i) a multi-class prediction for lung sound events and ii) for simultaneous detection of heart and lung sound events and achieve competitive results using only one model. The combined multi-task model regressed slightly in heart sound detection and gained significantly in lung sound detection accuracy with an overall macro F1 score of 39.2% over six classes, representing a 6.7% improvement over the single-task baseline models. Conclusion/Significance: To the best of our knowledge, this is the first approach developed to date for measuring heart and lung sound events invariant to both, the auscultation site and capturing device. Hence, our model is capable of performing lung and heart sound detection from any auscultation location.
RedBit: An End-to-End Flexible Framework for Evaluating the Accuracy of Quantized CNNs
Jan 15, 2023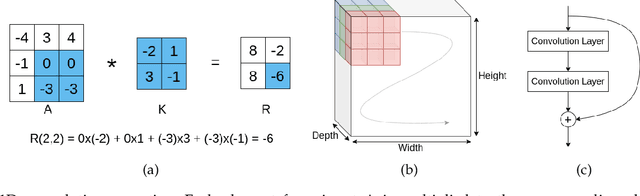
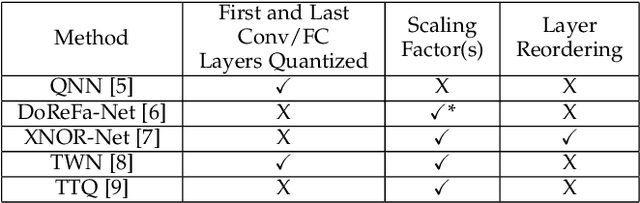
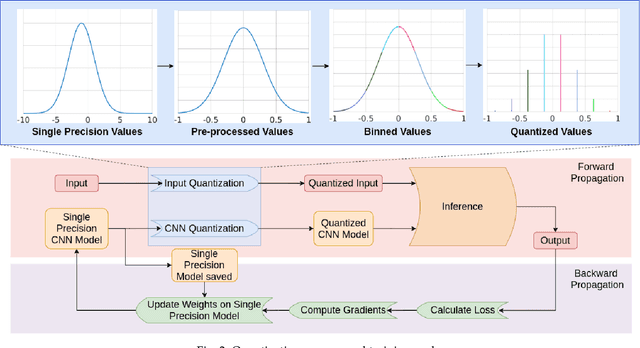
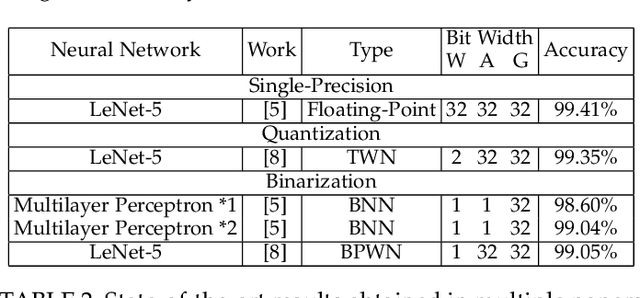
In recent years, Convolutional Neural Networks (CNNs) have become the standard class of deep neural network for image processing, classification and segmentation tasks. However, the large strides in accuracy obtained by CNNs have been derived from increasing the complexity of network topologies, which incurs sizeable performance and energy penalties in the training and inference of CNNs. Many recent works have validated the effectiveness of parameter quantization, which consists in reducing the bit width of the network's parameters, to enable the attainment of considerable performance and energy efficiency gains without significantly compromising accuracy. However, it is difficult to compare the relative effectiveness of different quantization methods. To address this problem, we introduce RedBit, an open-source framework that provides a transparent, extensible and easy-to-use interface to evaluate the effectiveness of different algorithms and parameter configurations on network accuracy. We use RedBit to perform a comprehensive survey of five state-of-the-art quantization methods applied to the MNIST, CIFAR-10 and ImageNet datasets. We evaluate a total of 2300 individual bit width combinations, independently tuning the width of the network's weight and input activation parameters, from 32 bits down to 1 bit (e.g., 8/8, 2/2, 1/32, 1/1, for weights/activations). Upwards of 20000 hours of computing time in a pool of state-of-the-art GPUs were used to generate all the results in this paper. For 1-bit quantization, the accuracy losses for the MNIST, CIFAR-10 and ImageNet datasets range between [0.26%, 0.79%], [9.74%, 32.96%] and [10.86%, 47.36%] top-1, respectively. We actively encourage the reader to download the source code and experiment with RedBit, and to submit their own observed results to our public repository, available at https://github.com/IT-Coimbra/RedBit.
Comparative Analysis of Time Series Forecasting Approaches for Household Electricity Consumption Prediction
Jul 03, 2022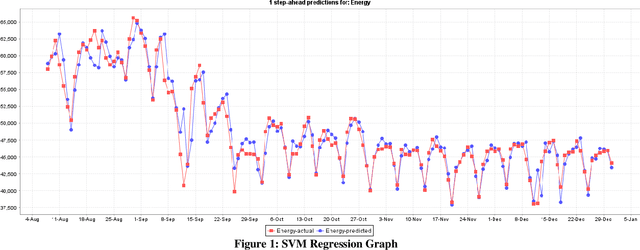
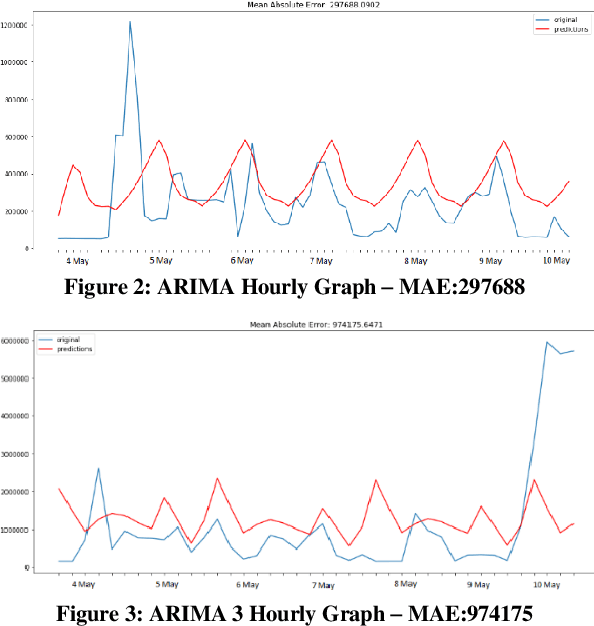
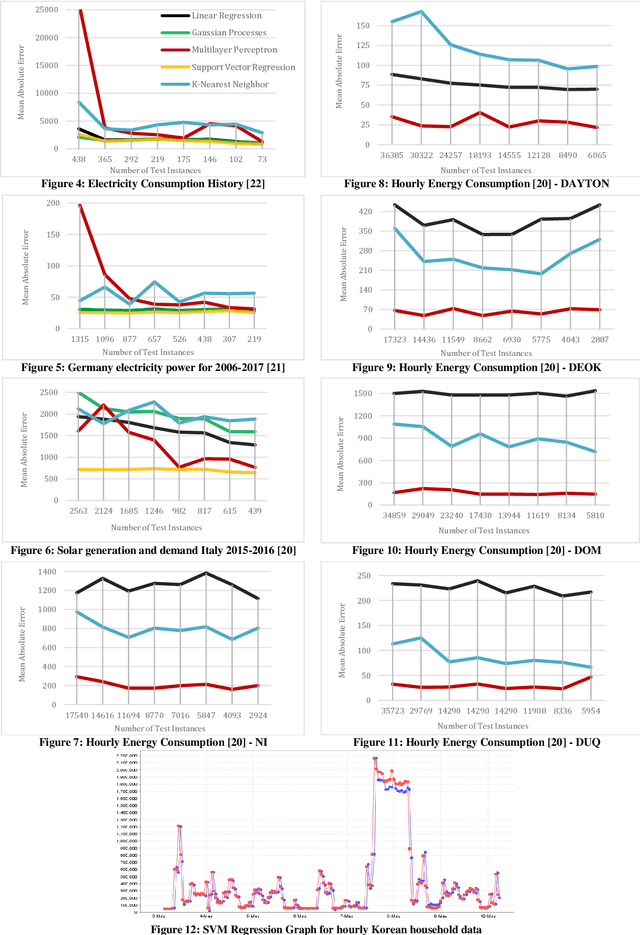
As a result of increasing population and globalization, the demand for energy has greatly risen. Therefore, accurate energy consumption forecasting has become an essential prerequisite for government planning, reducing power wastage and stable operation of the energy management system. In this work we present a comparative analysis of major machine learning models for time series forecasting of household energy consumption. Specifically, we use Weka, a data mining tool to first apply models on hourly and daily household energy consumption datasets available from Kaggle data science community. The models applied are: Multilayer Perceptron, K Nearest Neighbor regression, Support Vector Regression, Linear Regression, and Gaussian Processes. Secondly, we also implemented time series forecasting models, ARIMA and VAR, in python to forecast household energy consumption of selected South Korean households with and without weather data. Our results show that the best methods for the forecasting of energy consumption prediction are Support Vector Regression followed by Multilayer Perceptron and Gaussian Process Regression.