 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SepLUT: Separable Image-adaptive Lookup Tables for Real-time Image Enhancement
Jul 18, 2022
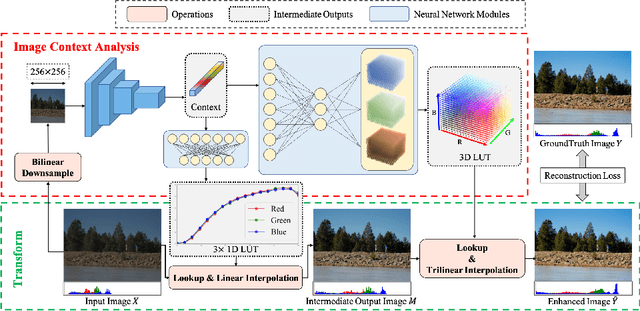
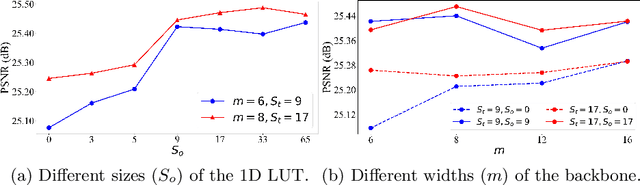
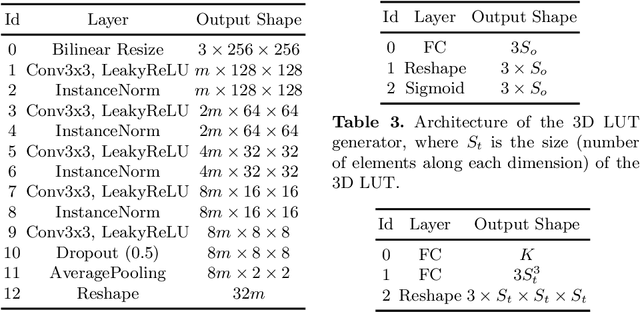
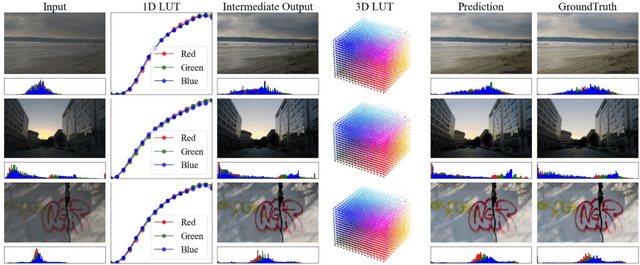
Image-adaptive lookup tables (LUTs) have achieved great success in real-time image enhancement tasks due to their high efficiency for modeling color transforms. However, they embed the complete transform, including the color component-independent and the component-correlated parts, into only a single type of LUTs, either 1D or 3D, in a coupled manner. This scheme raises a dilemma of improving model expressiveness or efficiency due to two factors. On the one hand, the 1D LUTs provide high computational efficiency but lack the critical capability of color components interaction. On the other, the 3D LUTs present enhanced component-correlated transform capability but suffer from heavy memory footprint, high training difficulty, and limited cell utilization. Inspired by the conventional divide-and-conquer practice in the image signal processor, we present SepLUT (separable image-adaptive lookup table) to tackle the above limitations. Specifically, we separate a single color transform into a cascade of component-independent and component-correlated sub-transforms instantiated as 1D and 3D LUTs, respectively. In this way, the capabilities of two sub-transforms can facilitate each other, where the 3D LUT complements the ability to mix up color components, and the 1D LUT redistributes the input colors to increase the cell utilization of the 3D LUT and thus enable the use of a more lightweight 3D LUT. Experiments demonstrate that the proposed method presents enhanced performance on photo retouching benchmark datasets than the current state-of-the-art and achieves real-time processing on both GPUs and CPUs.
Cross Reconstruction Transformer for Self-Supervised Time Series Representation Learning
May 20, 2022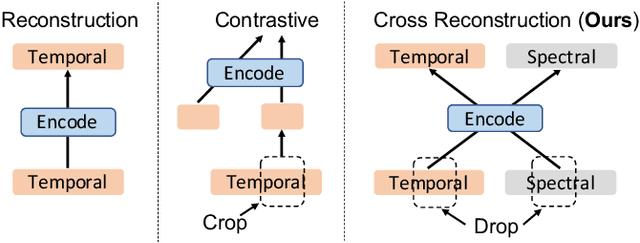
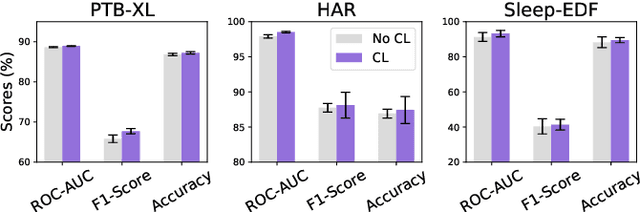
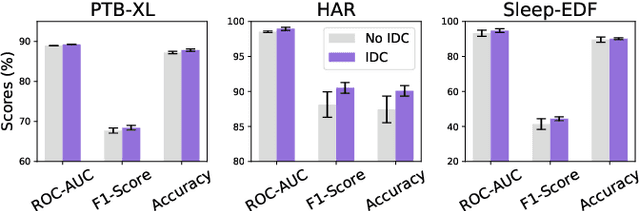
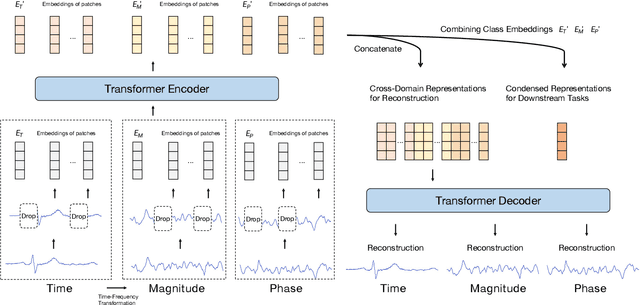
Unsupervised/self-supervised representation learning in time series is critical since labeled samples are usually scarce in real-world scenarios. Existing approaches mainly leverage the contrastive learning framework, which automatically learns to understand the similar and dissimilar data pairs. Nevertheless, they are restricted to the prior knowledge of constructing pairs, cumbersome sampling policy, and unstable performances when encountering sampling bias. Also, few works have focused on effectively modeling across temporal-spectral relations to extend the capacity of representations. In this paper, we aim at learning representations for time series from a new perspective and propose Cross Reconstruction Transformer (CRT) to solve the aforementioned problems in a unified way. CRT achieves time series representation learning through a cross-domain dropping-reconstruction task. Specifically, we transform time series into the frequency domain and randomly drop certain parts in both time and frequency domains. Dropping can maximally preserve the global context compared to cropping and masking. Then a transformer architecture is utilized to adequately capture the cross-domain correlations between temporal and spectral information through reconstructing data in both domains, which is called Dropped Temporal-Spectral Modeling. To discriminate the representations in global latent space, we propose Instance Discrimination Constraint to reduce the mutual information between different time series and sharpen the decision boundaries. Additionally, we propose a specified curriculum learning strategy to optimize the CRT, which progressively increases the dropping ratio in the training process.
AI based approach to Trailer Generation for Online Educational Courses
Jan 10, 2023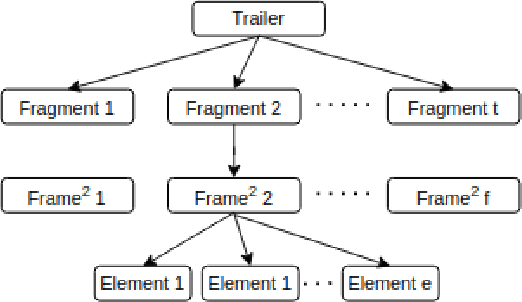
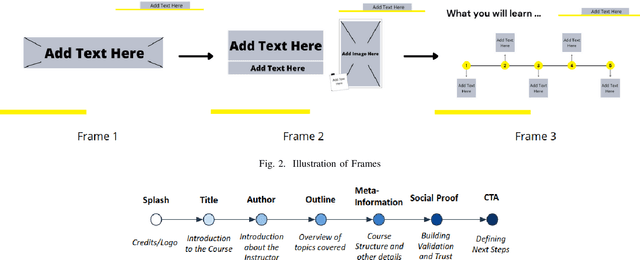
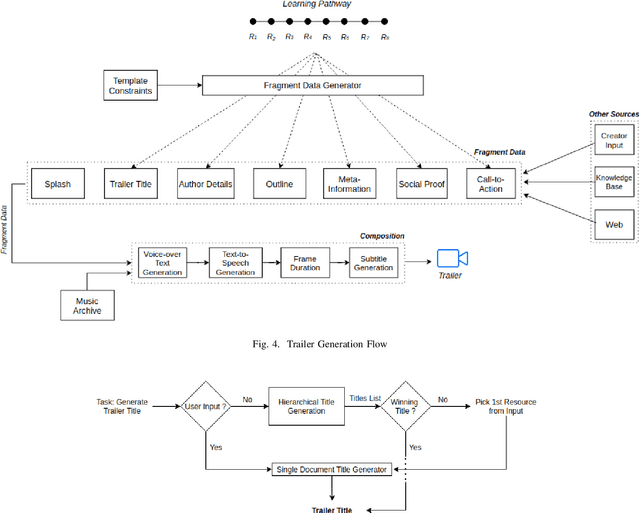
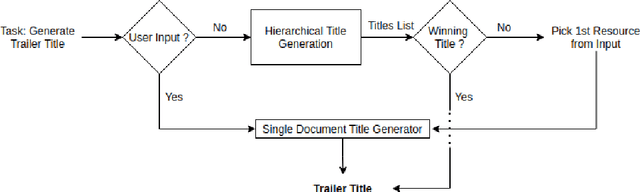
In this paper, we propose an AI based approach to Trailer Generation in the form of short videos for online educational courses. Trailers give an overview of the course to the learners and help them make an informed choice about the courses they want to learn. It also helps to generate curiosity and interest among the learners and encourages them to pursue a course. While it is possible to manually generate the trailers, it requires extensive human efforts and skills over a broad spectrum of design, span selection, video editing, domain knowledge, etc., thus making it time-consuming and expensive, especially in an academic setting. The framework we propose in this work is a template based method for video trailer generation, where most of the textual content of the trailer is auto-generated and the trailer video is automatically generated, by leveraging Machine Learning and Natural Language Processing techniques. The proposed trailer is in the form of a timeline consisting of various fragments created by selecting, para-phrasing or generating content using various proposed techniques. The fragments are further enhanced by adding voice-over text, subtitles, animations, etc., to create a holistic experience. Finally, we perform user evaluation with 63 human evaluators for evaluating the trailers generated by our system and the results obtained were encouraging.
Delving into Semantic Scale Imbalance
Jan 10, 2023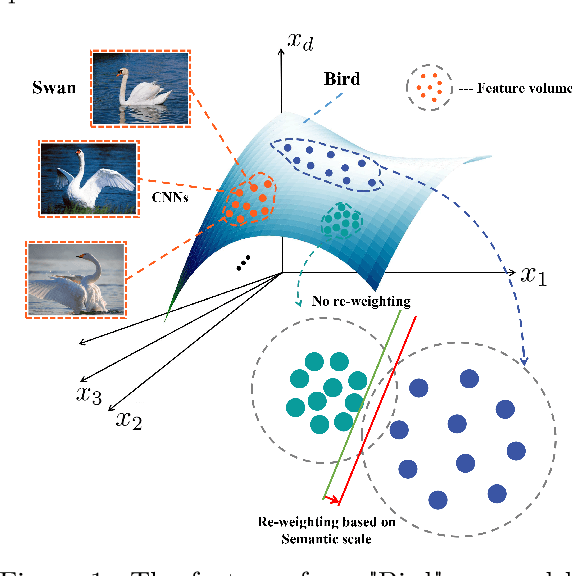
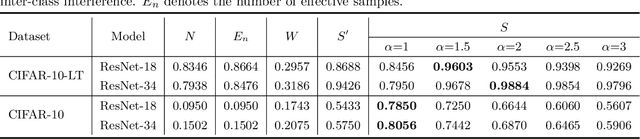
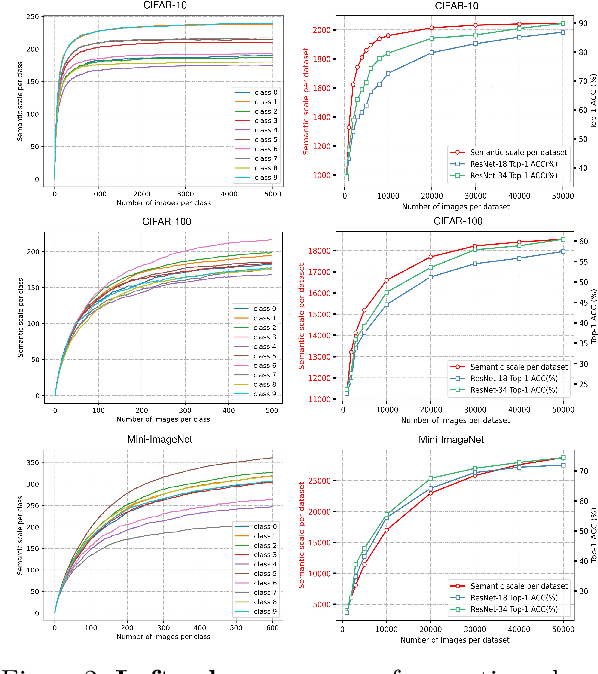
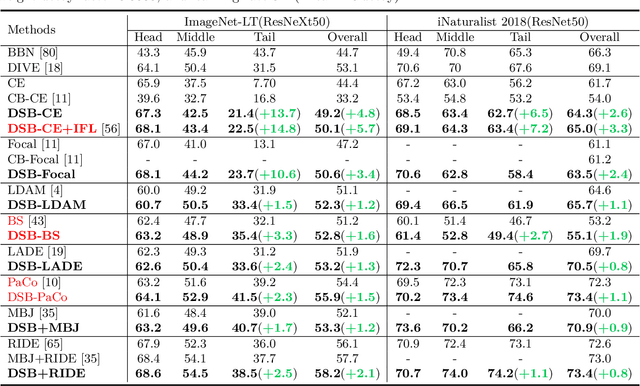
Model bias triggered by long-tailed data has been widely studied. However, measure based on the number of samples cannot explicate three phenomena simultaneously: (1) Given enough data, the classification performance gain is marginal with additional samples. (2) Classification performance decays precipitously as the number of training samples decreases when there is insufficient data. (3) Model trained on sample-balanced datasets still has different biases for different classes. In this work, we define and quantify the semantic scale of classes, which is used to measure the feature diversity of classes. It is exciting to find experimentally that there is a marginal effect of semantic scale, which perfectly describes the first two phenomena. Further, the quantitative measurement of semantic scale imbalance is proposed, which can accurately reflect model bias on multiple datasets, even on sample-balanced data, revealing a novel perspective for the study of class imbalance. Due to the prevalence of semantic scale imbalance, we propose semantic-scale-balanced learning, including a general loss improvement scheme and a dynamic re-weighting training framework that overcomes the challenge of calculating semantic scales in real-time during iterations. Comprehensive experiments show that dynamic semantic-scale-balanced learning consistently enables the model to perform superiorly on large-scale long-tailed and non-long-tailed natural and medical datasets, which is a good starting point for mitigating the prevalent but unnoticed model bias.
SAFEMYRIDES: Application of Decentralized Control Edge-Computing to Ridesharing Monitoring Services
Jan 02, 2023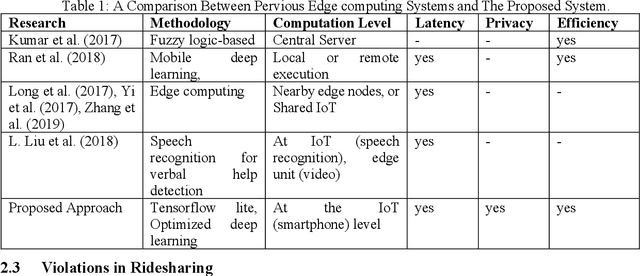
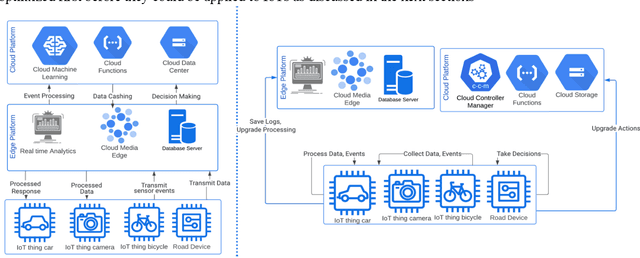
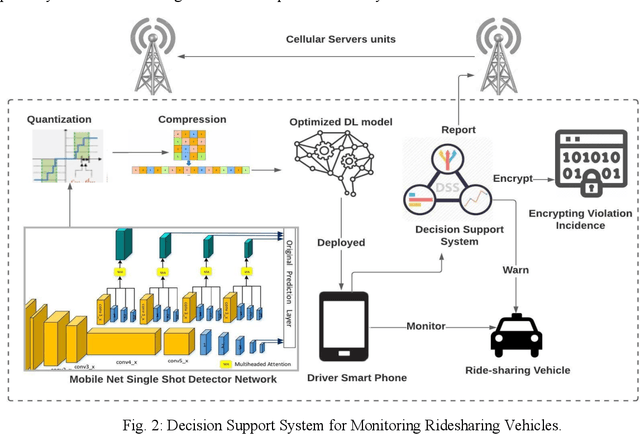
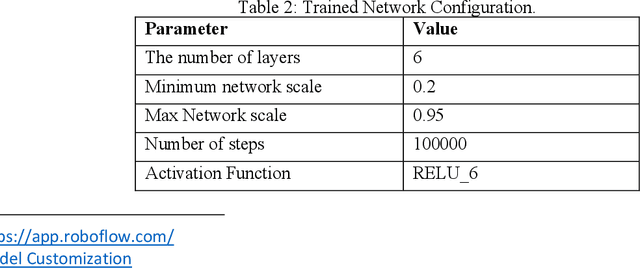
Edge computing is changing the face of many industries and services. Common edge computing models offload computing which is prone to security risks and privacy violation. However, advances in deep learning enabled Internet of Things (IoTs) to take decisions and run cognitive tasks locally. This research introduces a decentralized-control edge model where most computation and decisions are moved to the IoT level. The model aims at decreasing communication to the edge which in return enhances efficiency and decreases latency. The model also avoids data transfer which raises security and privacy risks. To examine the model, we developed SAFEMYRIDES, a scene-aware ridesharing monitoring system where smart phones are detecting violations at the runtime. Current real-time monitoring systems are costly and require continuous network connectivity. The system uses optimized deep learning that run locally on IoTs to detect violations in ridesharing and record violation incidences. The system would enhance safety and security in ridesharing without violating privacy.
GPT Takes the Bar Exam
Dec 29, 2022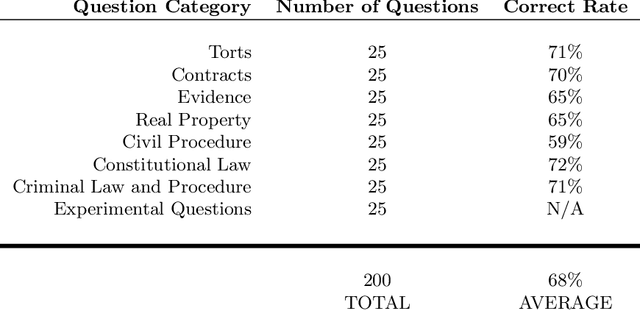
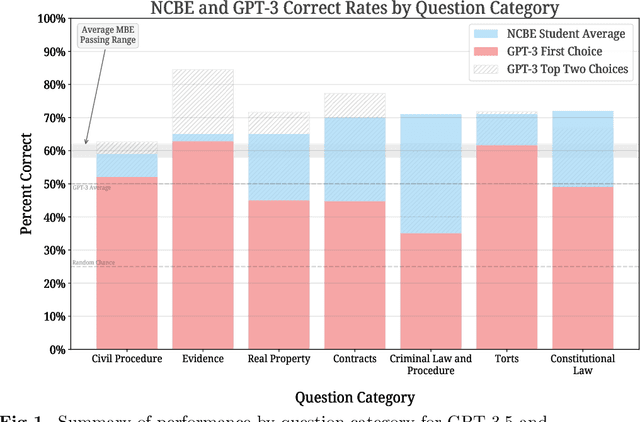
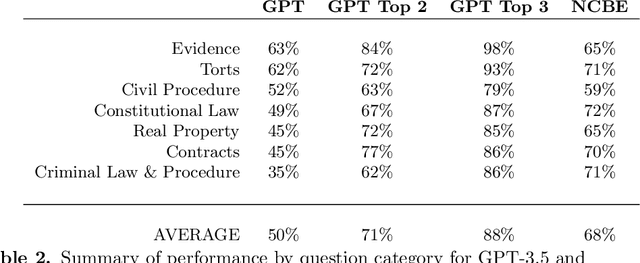
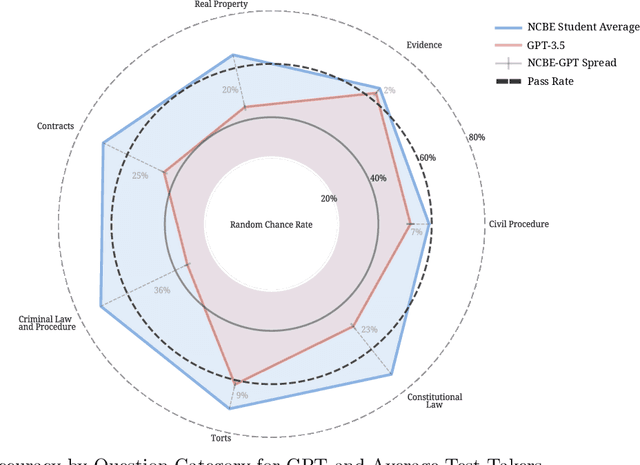
Nearly all jurisdictions in the United States require a professional license exam, commonly referred to as "the Bar Exam," as a precondition for law practice. To even sit for the exam, most jurisdictions require that an applicant completes at least seven years of post-secondary education, including three years at an accredited law school. In addition, most test-takers also undergo weeks to months of further, exam-specific preparation. Despite this significant investment of time and capital, approximately one in five test-takers still score under the rate required to pass the exam on their first try. In the face of a complex task that requires such depth of knowledge, what, then, should we expect of the state of the art in "AI?" In this research, we document our experimental evaluation of the performance of OpenAI's `text-davinci-003` model, often-referred to as GPT-3.5, on the multistate multiple choice (MBE) section of the exam. While we find no benefit in fine-tuning over GPT-3.5's zero-shot performance at the scale of our training data, we do find that hyperparameter optimization and prompt engineering positively impacted GPT-3.5's zero-shot performance. For best prompt and parameters, GPT-3.5 achieves a headline correct rate of 50.3% on a complete NCBE MBE practice exam, significantly in excess of the 25% baseline guessing rate, and performs at a passing rate for both Evidence and Torts. GPT-3.5's ranking of responses is also highly-correlated with correctness; its top two and top three choices are correct 71% and 88% of the time, respectively, indicating very strong non-entailment performance. While our ability to interpret these results is limited by nascent scientific understanding of LLMs and the proprietary nature of GPT, we believe that these results strongly suggest that an LLM will pass the MBE component of the Bar Exam in the near future.
FDA Beampattern Characteristics With Considering Time-Range Relations
Apr 14, 2022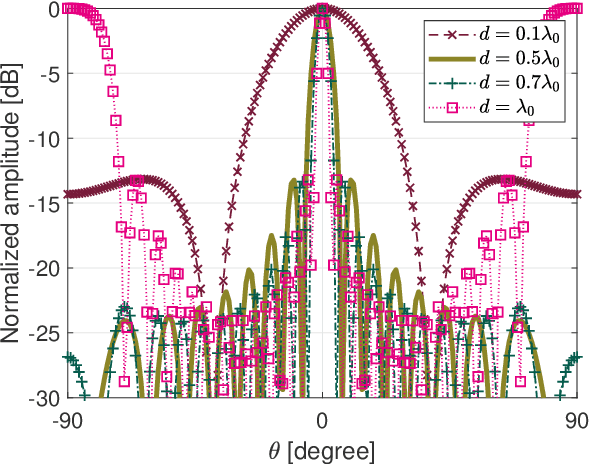
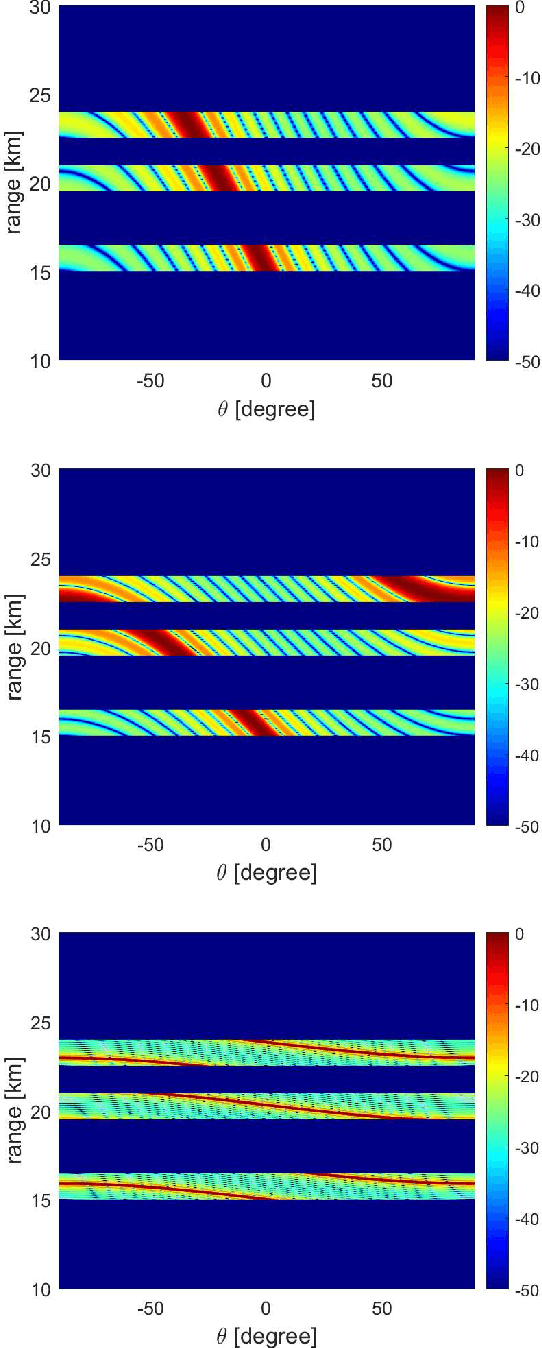
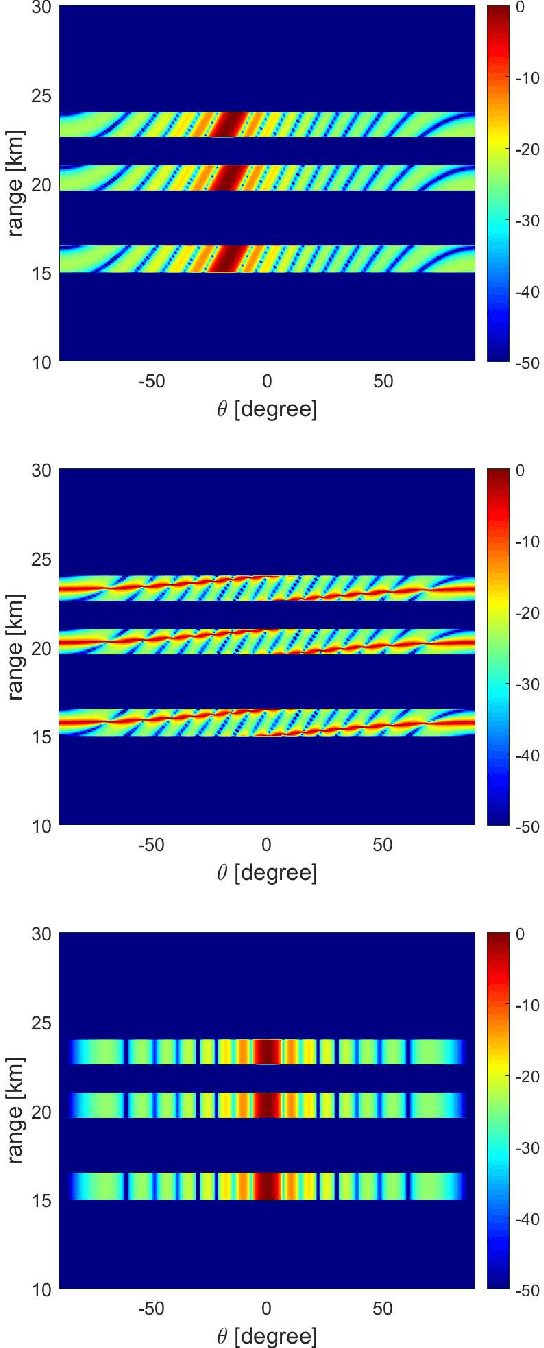
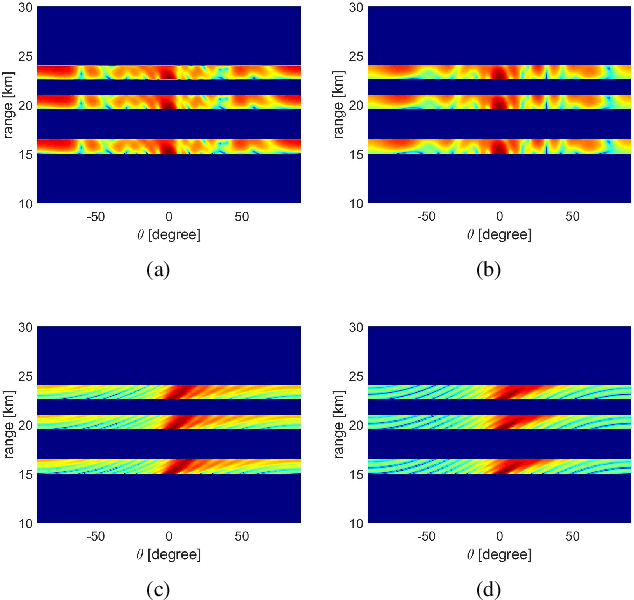
Existing investigations show that frequency diverse array (FDA) will produce angle-range-dependent and time-variant transmit beampattern, but the relations between time and range and their characteristics still are not fully investigated. In order to fully exploit the time and range dependent characteristics of FDA transmit beampattern and address the effects of FDA frequency offsets, we systematically reformulate the FDA antenna and system model with specific time-range relation consideration. Two FDA transmit beampatterns, namely, instantaneous and integral ones, are derived. Accordingly, the FDA time and range dependent characteristics together with the comparisons to conventional phased-array and co-located multiple-input multiple-output (MIMO) antennas are analyzed. Both theoretical analysis and simulation results reveal that the FDA time-range dependent characteristics actually can be regarded as auto-scanning capability, which may provide many promising applications.
Semantic rule Web-based Diagnosis and Treatment of Vector-Borne Diseases using SWRL rules
Jan 08, 2023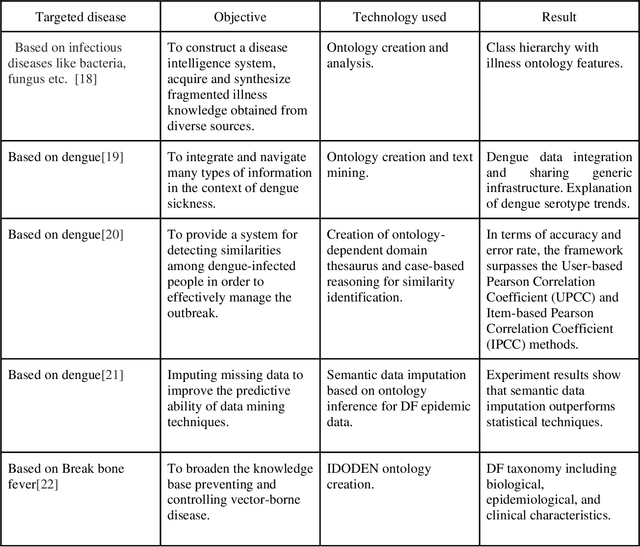
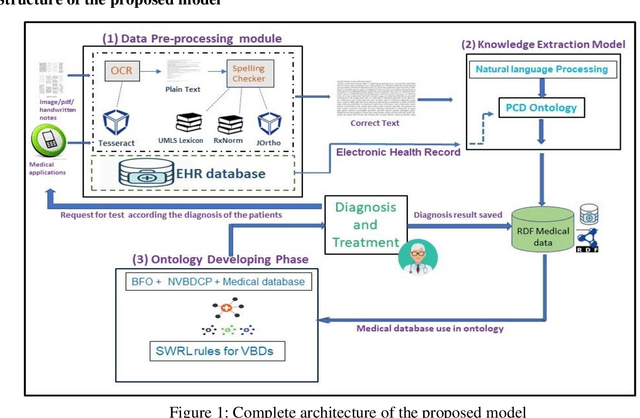
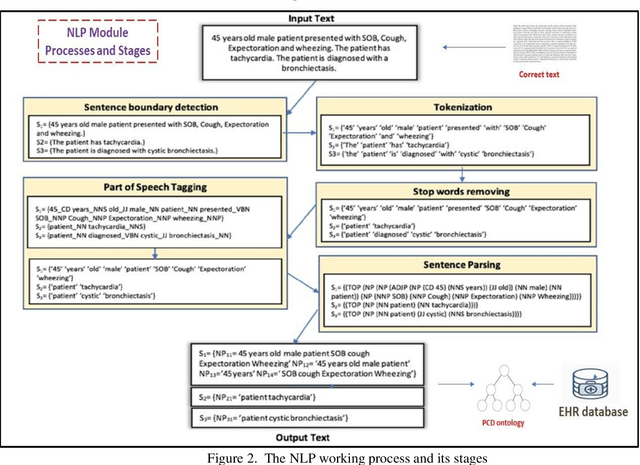

Vector-borne diseases (VBDs) are a kind of infection caused through the transmission of vectors generated by the bites of infected parasites, bacteria, and viruses, such as ticks, mosquitoes, triatomine bugs, blackflies, and sandflies. If these diseases are not properly treated within a reasonable time frame, the mortality rate may rise. In this work, we propose a set of ontologies that will help in the diagnosis and treatment of vector-borne diseases. For developing VBD's ontology, electronic health records taken from the Indian Health Records website, text data generated from Indian government medical mobile applications, and doctors' prescribed handwritten notes of patients are used as input. This data is then converted into correct text using Optical Character Recognition (OCR) and a spelling checker after pre-processing. Natural Language Processing (NLP) is applied for entity extraction from text data for making Resource Description Framework (RDF) medical data with the help of the Patient Clinical Data (PCD) ontology. Afterwards, Basic Formal Ontology (BFO), National Vector Borne Disease Control Program (NVBDCP) guidelines, and RDF medical data are used to develop ontologies for VBDs, and Semantic Web Rule Language (SWRL) rules are applied for diagnosis and treatment. The developed ontology helps in the construction of decision support systems (DSS) for the NVBDCP to control these diseases.
Deep Injective Prior for Inverse Scattering
Jan 08, 2023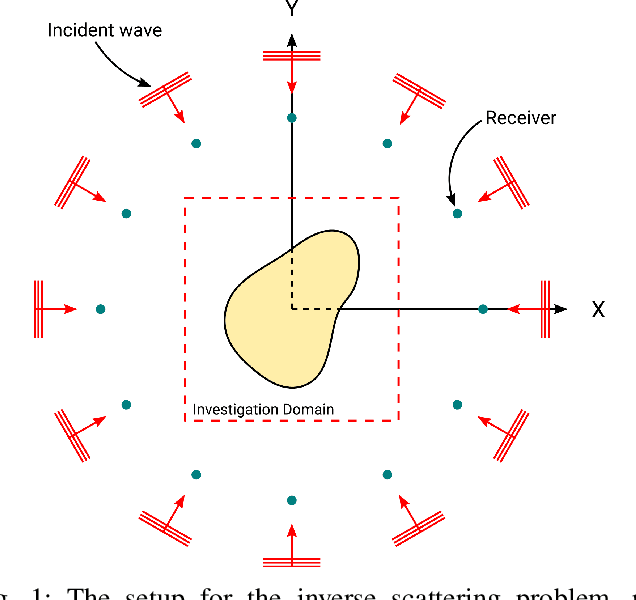
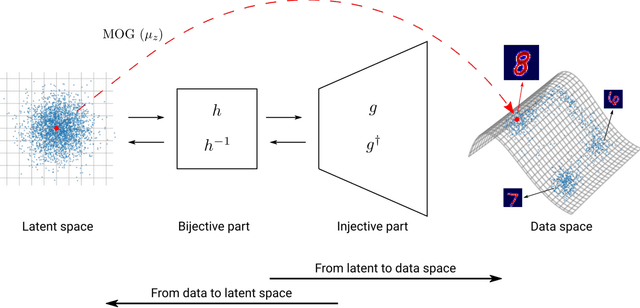
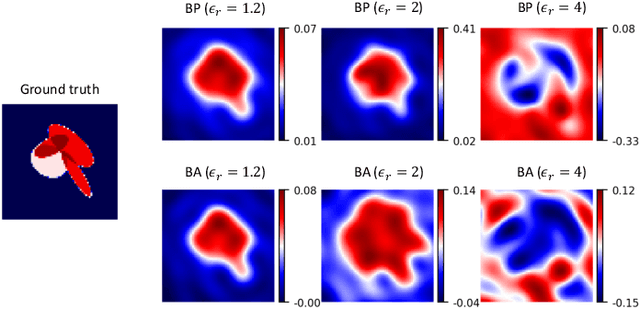
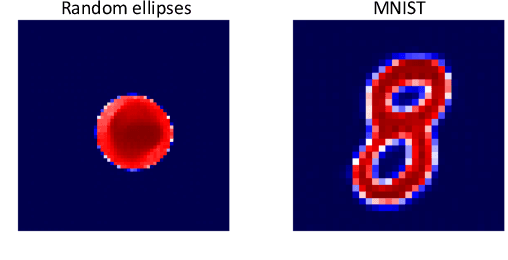
In electromagnetic inverse scattering, we aim to reconstruct object permittivity from scattered waves. Deep learning is a promising alternative to traditional iterative solvers, but it has been used mostly in a supervised framework to regress the permittivity patterns from scattered fields or back-projections. While such methods are fast at test-time and achieve good results for specific data distributions, they are sensitive to the distribution drift of the scattered fields, common in practice. If the distribution of the scattered fields changes due to changes in frequency, the number of transmitters and receivers, or any other real-world factor, an end-to-end neural network must be re-trained or fine-tuned on a new dataset. In this paper, we propose a new data-driven framework for inverse scattering based on deep generative models. We model the target permittivities by a low-dimensional manifold which acts as a regularizer and learned from data. Unlike supervised methods which require both scattered fields and target signals, we only need the target permittivities for training; it can then be used with any experimental setup. We show that the proposed framework significantly outperforms the traditional iterative methods especially for strong scatterers while having comparable reconstruction quality to state-of-the-art deep learning methods like U-Net.
Stochastic Langevin Monte Carlo for (weakly) log-concave posterior distributions
Jan 08, 2023In this paper, we investigate a continuous time version of the Stochastic Langevin Monte Carlo method, introduced in [WT11], that incorporates a stochastic sampling step inside the traditional over-damped Langevin diffusion. This method is popular in machine learning for sampling posterior distribution. We will pay specific attention in our work to the computational cost in terms of $n$ (the number of observations that produces the posterior distribution), and $d$ (the dimension of the ambient space where the parameter of interest is living). We derive our analysis in the weakly convex framework, which is parameterized with the help of the Kurdyka-\L ojasiewicz (KL) inequality, that permits to handle a vanishing curvature settings, which is far less restrictive when compared to the simple strongly convex case. We establish that the final horizon of simulation to obtain an $\varepsilon$ approximation (in terms of entropy) is of the order $( d \log(n)^2 )^{(1+r)^2} [\log^2(\varepsilon^{-1}) + n^2 d^{2(1+r)} \log^{4(1+r)}(n) ]$ with a Poissonian subsampling of parameter $\left(n ( d \log^2(n))^{1+r}\right)^{-1}$, where the parameter $r$ is involved in the KL inequality and varies between $0$ (strongly convex case) and $1$ (limiting Laplace situation).