 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatio-Temporal Super-Resolution of Dynamical Systems using Physics-Informed Deep-Learning
Dec 08, 2022
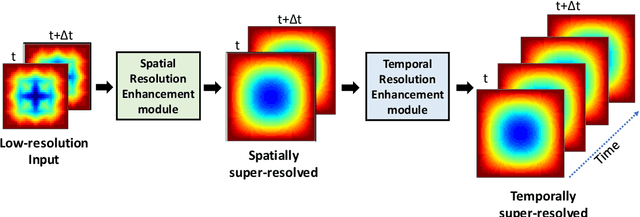
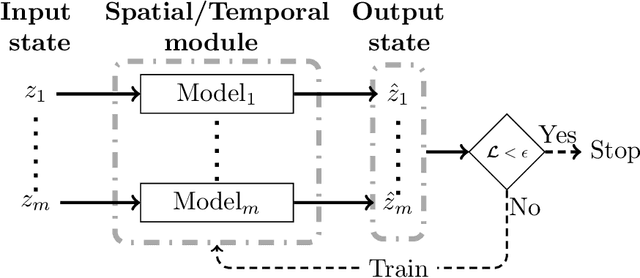
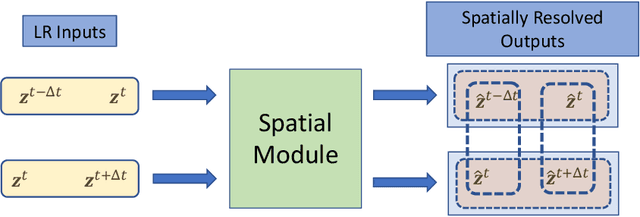
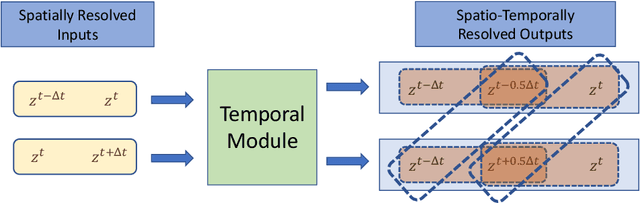
This work presents a physics-informed deep learning-based super-resolution framework to enhance the spatio-temporal resolution of the solution of time-dependent partial differential equations (PDE). Prior works on deep learning-based super-resolution models have shown promise in accelerating engineering design by reducing the computational expense of traditional numerical schemes. However, these models heavily rely on the availability of high-resolution (HR) labeled data needed during training. In this work, we propose a physics-informed deep learning-based framework to enhance the spatial and temporal resolution of coarse-scale (both in space and time) PDE solutions without requiring any HR data. The framework consists of two trainable modules independently super-resolving the PDE solution, first in spatial and then in temporal direction. The physics based losses are implemented in a novel way to ensure tight coupling between the spatio-temporally refined outputs at different times and improve framework accuracy. We analyze the capability of the developed framework by investigating its performance on an elastodynamics problem. It is observed that the proposed framework can successfully super-resolve (both in space and time) the low-resolution PDE solutions while satisfying physics-based constraints and yielding high accuracy. Furthermore, the analysis and obtained speed-up show that the proposed framework is well-suited for integration with traditional numerical methods to reduce computational complexity during engineering design.
Federated Learning-Based Cell-Free Massive MIMO System for Privacy-Preserving
Nov 30, 2022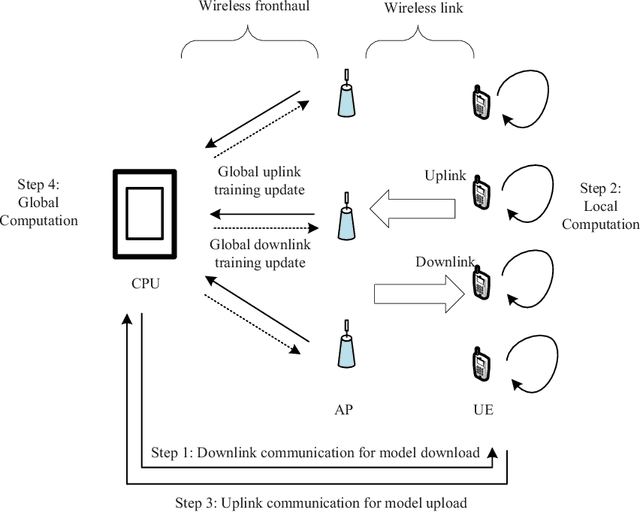
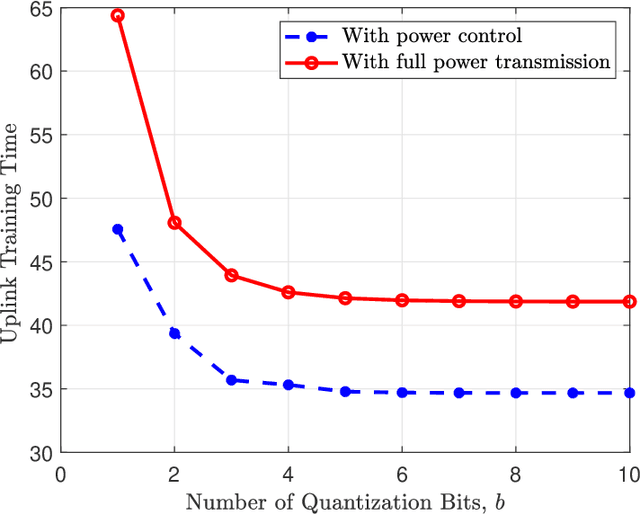
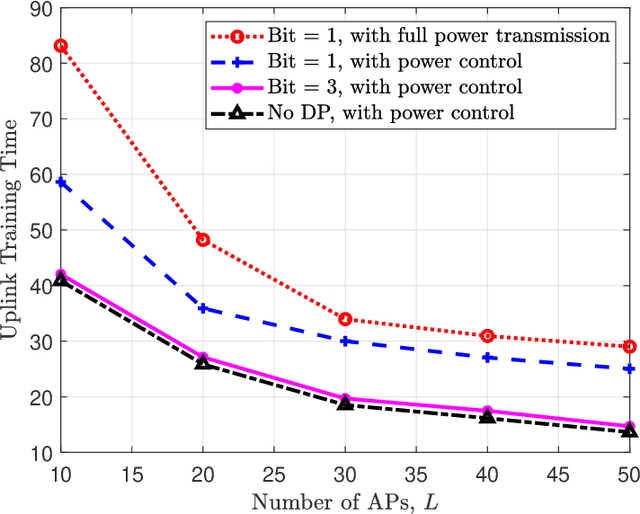
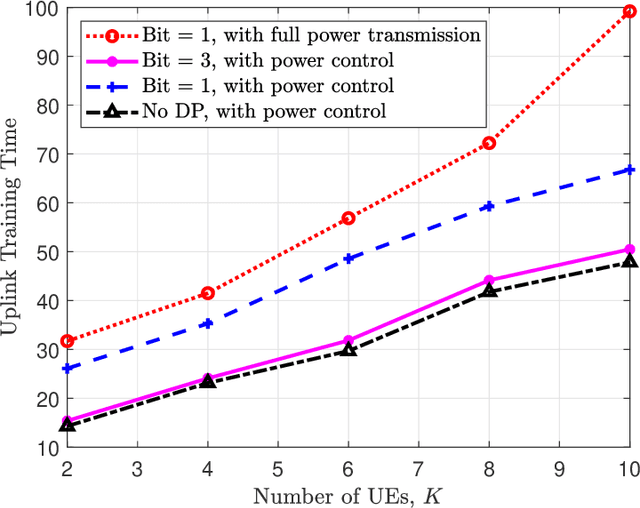
Cell-free massive MIMO (CF mMIMO) is a promising next generation wireless architecture to realize federated learning (FL). However, sensitive information of user equipments (UEs) may be exposed to the involved access points or the central processing unit in practice. To guarantee data privacy, effective privacy-preserving mechanisms are defined in this paper. In particular, we demonstrate and characterize the possibility in exploiting the inherent quantization error, caused by low-resolution analog-to-digital converters (ADCs) and digital-to-analog converters (DACs), for privacy-preserving in a FL CF mMIMO system. Furthermore, to reduce the required uplink training time in such a system, a stochastic non-convex design problem that jointly optimizing the transmit power and the data rate is formulated. To address the problem at hand, we propose a novel power control method by utilizing the successive convex approximation approach to obtain a suboptimal solution. Besides, an asynchronous protocol is established for mitigating the straggler effect to facilitate FL. Numerical results show that compared with the conventional full power transmission, adopting the proposed power control method can effectively reduce the uplink training time under various practical system settings. Also, our results unveil that our proposed asynchronous approach can reduce the waiting time at the central processing unit for receiving all user information, as there are no stragglers that requires a long time to report their local updates.
Event-Based Frame Interpolation with Ad-hoc Deblurring
Jan 12, 2023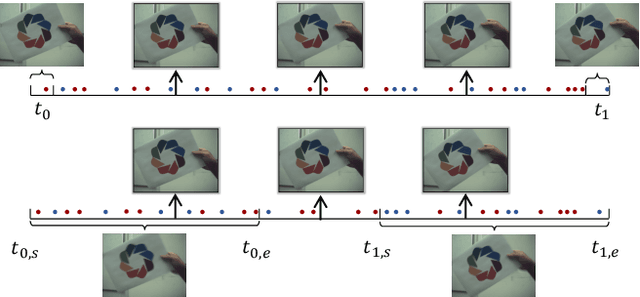
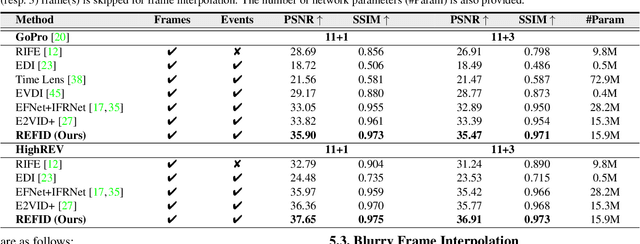
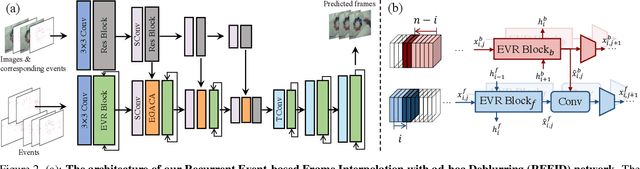
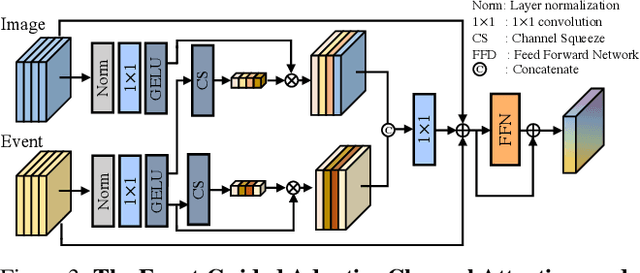
The performance of video frame interpolation is inherently correlated with the ability to handle motion in the input scene. Even though previous works recognize the utility of asynchronous event information for this task, they ignore the fact that motion may or may not result in blur in the input video to be interpolated, depending on the length of the exposure time of the frames and the speed of the motion, and assume either that the input video is sharp, restricting themselves to frame interpolation, or that it is blurry, including an explicit, separate deblurring stage before interpolation in their pipeline. We instead propose a general method for event-based frame interpolation that performs deblurring ad-hoc and thus works both on sharp and blurry input videos. Our model consists in a bidirectional recurrent network that naturally incorporates the temporal dimension of interpolation and fuses information from the input frames and the events adaptively based on their temporal proximity. In addition, we introduce a novel real-world high-resolution dataset with events and color videos named HighREV, which provides a challenging evaluation setting for the examined task. Extensive experiments on the standard GoPro benchmark and on our dataset show that our network consistently outperforms previous state-of-the-art methods on frame interpolation, single image deblurring and the joint task of interpolation and deblurring. Our code and dataset will be made publicly available.
Where to go: Agent Guidance with Deep Reinforcement Learning in A City-Scale Online Ride-Hailing Service
Dec 12, 2022
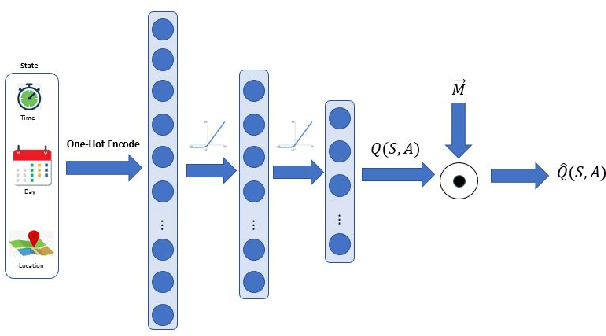
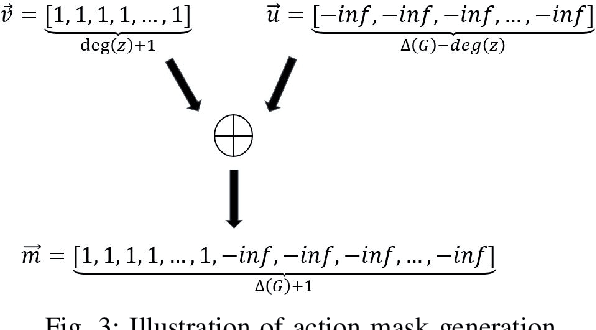
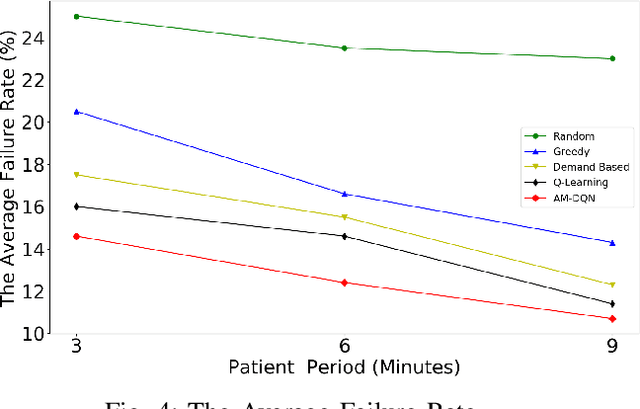
Online ride-hailing services have become a prevalent transportation system across the world. In this paper, we study a challenging problem of how to direct vacant taxis around a city such that supplies and demands can be balanced in online ride-hailing services. We design a new reward scheme that considers multiple performance metrics of online ride-hailing services. We also propose a novel deep reinforcement learning method named Deep-Q-Network with Action Mask (AM-DQN) masking off unnecessary actions in various locations such that agents can learn much faster and more efficiently. We conduct extensive experiments using a city-scale dataset from Chicago. Several popular heuristic and learning methods are also implemented as baselines for comparison. The results of the experiments show that the AM-DQN attains the best performances of all methods with respect to average failure rate, average waiting time for customers, and average idle search time for vacant taxis.
A Review and Evaluation of Elastic Distance Functions for Time Series Clustering
May 30, 2022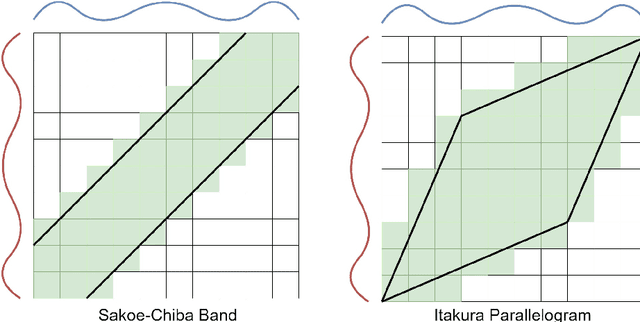
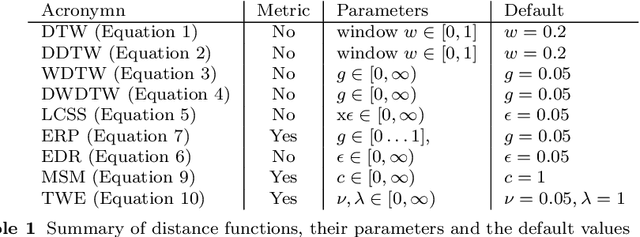
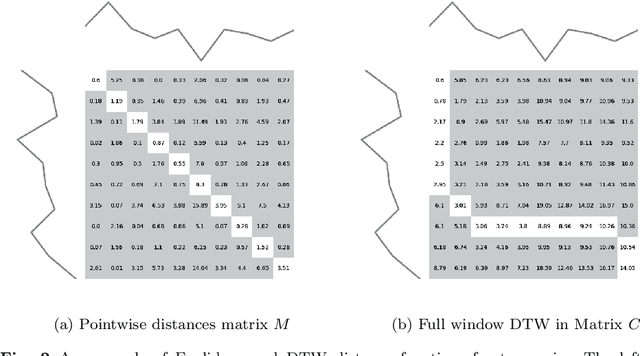
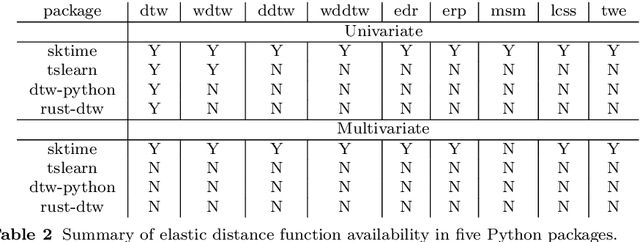
Time series clustering is the act of grouping time series data without recourse to a label. Algorithms that cluster time series can be classified into two groups: those that employ a time series specific distance measure; and those that derive features from time series. Both approaches usually rely on traditional clustering algorithms such as $k$-means. Our focus is on distance based time series that employ elastic distance measures, i.e. distances that perform some kind of realignment whilst measuring distance. We describe nine commonly used elastic distance measures and compare their performance with k-means and k-medoids clustering. Our findings are surprising. The most popular technique, dynamic time warping (DTW), performs worse than Euclidean distance with k-means, and even when tuned, is no better. Using k-medoids rather than k-means improved the clusterings for all nine distance measures. DTW is not significantly better than Euclidean distance with k-medoids. Generally, distance measures that employ editing in conjunction with warping perform better, and one distance measure, the move-split-merge (MSM) method, is the best performing measure of this study. We also compare to clustering with DTW using barycentre averaging (DBA). We find that DBA does improve DTW k-means, but that the standard DBA is still worse than using MSM. Our conclusion is to recommend MSM with k-medoids as the benchmark algorithm for clustering time series with elastic distance measures. We provide implementations, results and guidance on reproducing results on the associated GitHub repository.
Continual Test-Time Domain Adaptation
Mar 25, 2022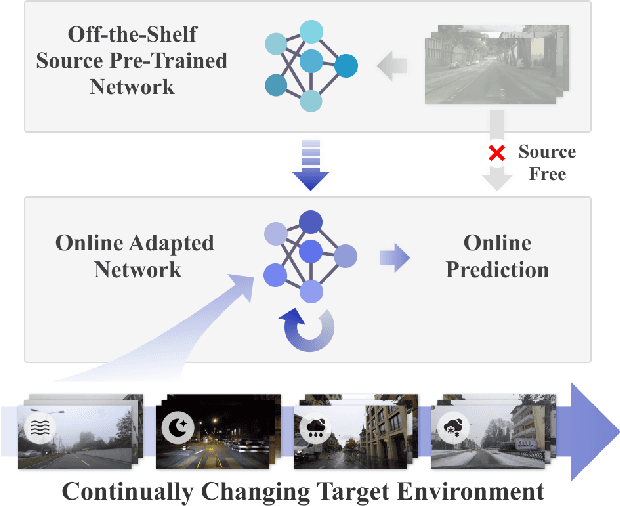

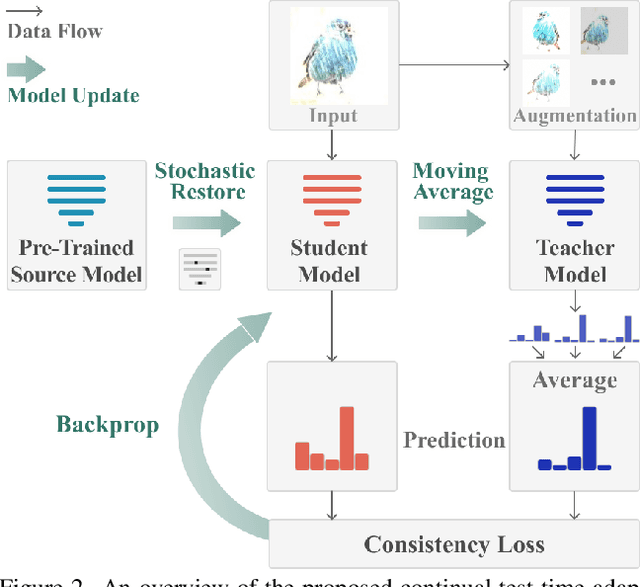

Test-time domain adaptation aims to adapt a source pre-trained model to a target domain without using any source data. Existing works mainly consider the case where the target domain is static. However, real-world machine perception systems are running in non-stationary and continually changing environments where the target domain distribution can change over time. Existing methods, which are mostly based on self-training and entropy regularization, can suffer from these non-stationary environments. Due to the distribution shift over time in the target domain, pseudo-labels become unreliable. The noisy pseudo-labels can further lead to error accumulation and catastrophic forgetting. To tackle these issues, we propose a continual test-time adaptation approach~(CoTTA) which comprises two parts. Firstly, we propose to reduce the error accumulation by using weight-averaged and augmentation-averaged predictions which are often more accurate. On the other hand, to avoid catastrophic forgetting, we propose to stochastically restore a small part of the neurons to the source pre-trained weights during each iteration to help preserve source knowledge in the long-term. The proposed method enables the long-term adaptation for all parameters in the network. CoTTA is easy to implement and can be readily incorporated in off-the-shelf pre-trained models. We demonstrate the effectiveness of our approach on four classification tasks and a segmentation task for continual test-time adaptation, on which we outperform existing methods. Our code is available at \url{https://qin.ee/cotta}.
An Architecture for Reactive Mobile Manipulation On-The-Move
Dec 14, 2022
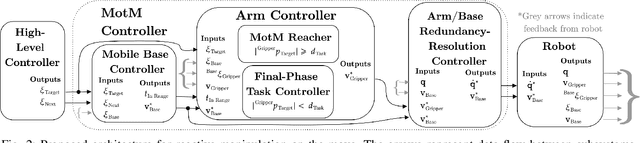
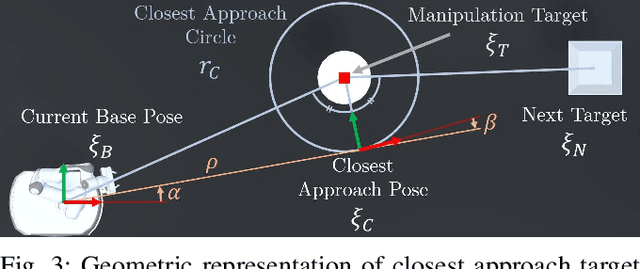

We present a generalised architecture for reactive mobile manipulation while a robot's base is in motion toward the next objective in a high-level task. By performing tasks on-the-move, overall cycle time is reduced compared to methods where the base pauses during manipulation. Reactive control of the manipulator enables grasping objects with unpredictable motion while improving robustness against perception errors, environmental disturbances, and inaccurate robot control compared to open-loop, trajectory-based planning approaches. We present an example implementation of the architecture and investigate the performance on a series of pick and place tasks with both static and dynamic objects and compare the performance to baseline methods. Our method demonstrated a real-world success rate of over 99%, failing in only a single trial from 120 attempts with a physical robot system. The architecture is further demonstrated on other mobile manipulator platforms in simulation. Our approach reduces task time by up to 48%, while also improving reliability, gracefulness, and predictability compared to existing architectures for mobile manipulation. See https://benburgesslimerick.github.io/ManipulationOnTheMove for supplementary materials.
Optimizing Predictions for Very Small Data Sets: a case study on Open-Source Project Health Prediction
Jan 16, 2023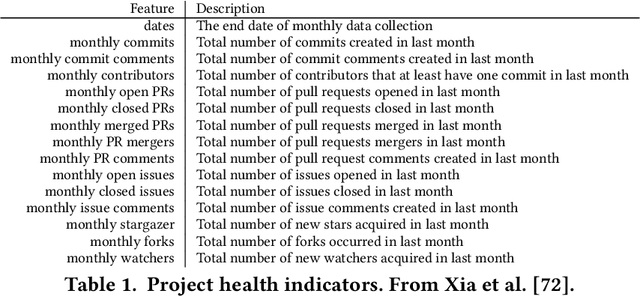



When learning from very small data sets, the resulting models can make many mistakes. For example, consider learning predictors for open source project health. The training data for this task may be very small (e.g. five years of data, collected every month means just 60 rows of training data). Using this data, prior work had unacceptably large errors in their learned predictors. We show that these high errors rates can be tamed by better configuration of the control parameters of the machine learners. For example, we present here a {\em landscape analytics} method (called SNEAK) that (a)~clusters the data to find the general landscape of the hyperparameters; then (b)~explores a few representatives from each part of that landscape. SNEAK is both faster and and more effective than prior state-of-the-art hyperparameter optimization algorithms (FLASH, HYPEROPT, OPTUNA, and differential evolution). More importantly, the configurations found by SNEAK had far less error that other methods. We conjecture that SNEAK works so well since it finds the most informative regions of the hyperparameters, then jumps to those regions. Other methods (that do not reflect over the landscape) can waste time exploring less informative options. From this, we make the following conclusions. Firstly, for predicting open source project health, we recommend landscape analytics (e.g.SNEAK). Secondly, and more generally, when learning from very small data sets, using hyperparameter optimization (e.g. SNEAK) to select learning control parameters. Due to its speed and implementation simplicity, we suggest SNEAK might also be useful in other ``data-light'' SE domains. To assist other researchers in repeating, improving, or even refuting our results, all our scripts and data are available on GitHub at https://github.com/zxcv123456qwe/niSneak
Fully Elman Neural Network: A Novel Deep Recurrent Neural Network Optimized by an Improved Harris Hawks Algorithm for Classification of Pulmonary Arterial Wedge Pressure
Jan 16, 2023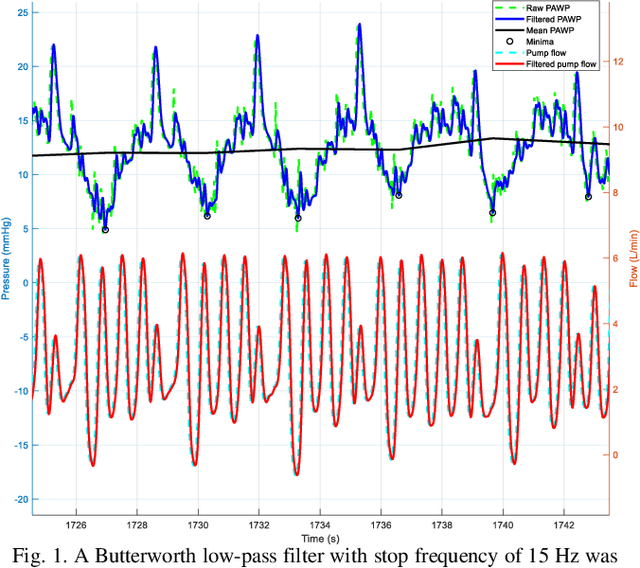
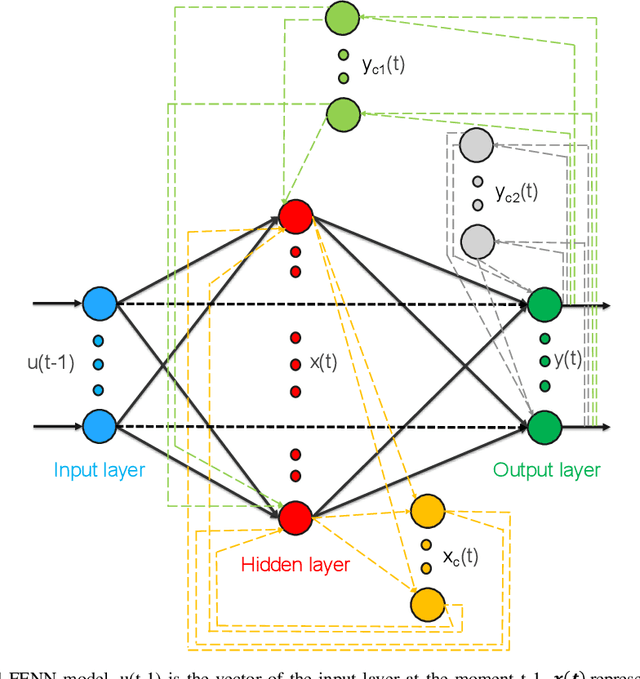
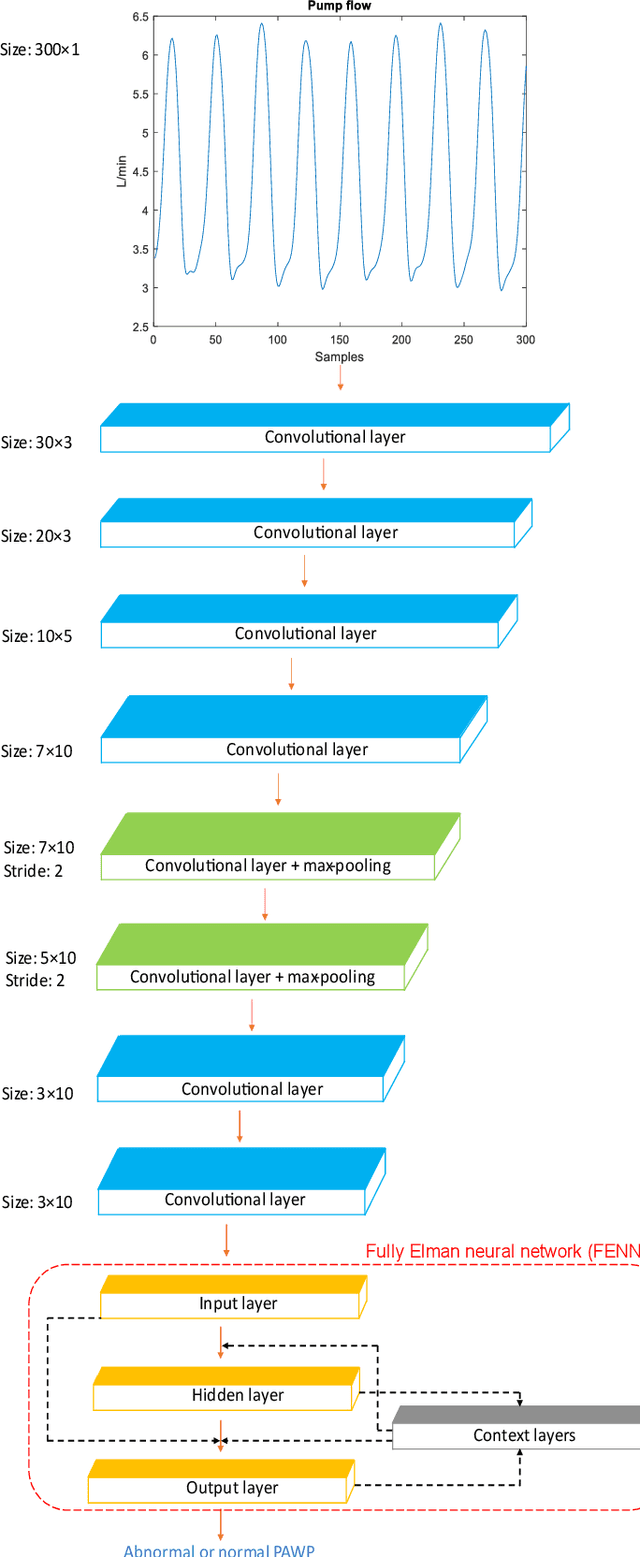
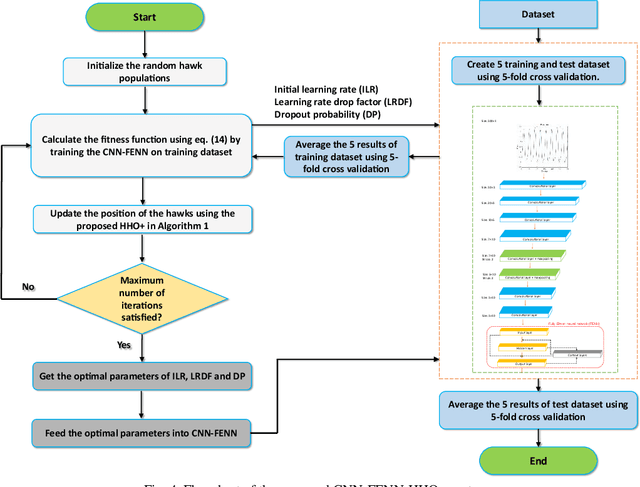
Heart failure (HF) is one of the most prevalent life-threatening cardiovascular diseases in which 6.5 million people are suffering in the USA and more than 23 million worldwide. Mechanical circulatory support of HF patients can be achieved by implanting a left ventricular assist device (LVAD) into HF patients as a bridge to transplant, recovery or destination therapy and can be controlled by measurement of normal and abnormal pulmonary arterial wedge pressure (PAWP). While there are no commercial long-term implantable pressure sensors to measure PAWP, real-time non-invasive estimation of abnormal and normal PAWP becomes vital. In this work, first an improved Harris Hawks optimizer algorithm called HHO+ is presented and tested on 24 unimodal and multimodal benchmark functions. Second, a novel fully Elman neural network (FENN) is proposed to improve the classification performance. Finally, four novel 18-layer deep learning methods of convolutional neural networks (CNNs) with multi-layer perceptron (CNN-MLP), CNN with Elman neural networks (CNN-ENN), CNN with fully Elman neural networks (CNN-FENN), and CNN with fully Elman neural networks optimized by HHO+ algorithm (CNN-FENN-HHO+) for classification of abnormal and normal PAWP using estimated HVAD pump flow were developed and compared. The estimated pump flow was derived by a non-invasive method embedded into the commercial HVAD controller. The proposed methods are evaluated on an imbalanced clinical dataset using 5-fold cross-validation. The proposed CNN-FENN-HHO+ method outperforms the proposed CNN-MLP, CNN-ENN and CNN-FENN methods and improved the classification performance metrics across 5-fold cross-validation. The proposed methods can reduce the likelihood of hazardous events like pulmonary congestion and ventricular suction for HF patients and notify identified abnormal cases to the hospital, clinician and cardiologist.
Data-aware customization of activation functions reduces neural network error
Jan 16, 2023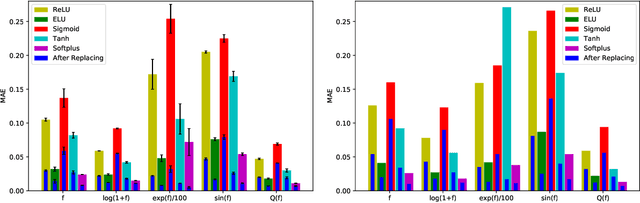
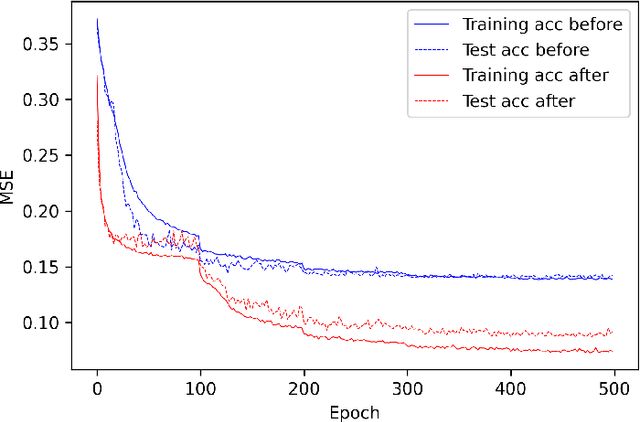
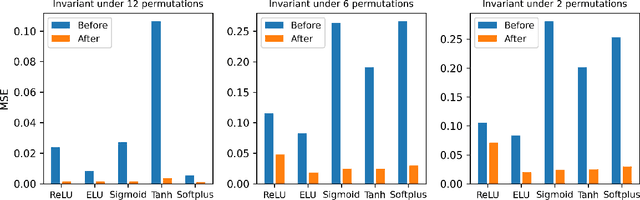
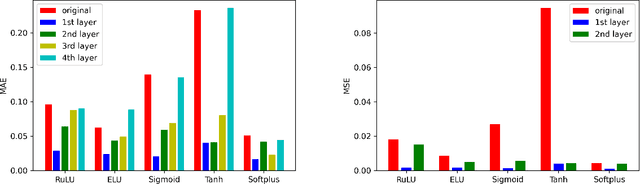
Activation functions play critical roles in neural networks, yet current off-the-shelf neural networks pay little attention to the specific choice of activation functions used. Here we show that data-aware customization of activation functions can result in striking reductions in neural network error. We first give a simple linear algebraic explanation of the role of activation functions in neural networks; then, through connection with the Diaconis-Shahshahani Approximation Theorem, we propose a set of criteria for good activation functions. As a case study, we consider regression tasks with a partially exchangeable target function, \emph{i.e.} $f(u,v,w)=f(v,u,w)$ for $u,v\in \mathbb{R}^d$ and $w\in \mathbb{R}^k$, and prove that for such a target function, using an even activation function in at least one of the layers guarantees that the prediction preserves partial exchangeability for best performance. Since even activation functions are seldom used in practice, we designed the ``seagull'' even activation function $\log(1+x^2)$ according to our criteria. Empirical testing on over two dozen 9-25 dimensional examples with different local smoothness, curvature, and degree of exchangeability revealed that a simple substitution with the ``seagull'' activation function in an already-refined neural network can lead to an order-of-magnitude reduction in error. This improvement was most pronounced when the activation function substitution was applied to the layer in which the exchangeable variables are connected for the first time. While the improvement is greatest for low-dimensional data, experiments on the CIFAR10 image classification dataset showed that use of ``seagull'' can reduce error even for high-dimensional cases. These results collectively highlight the potential of customizing activation functions as a general approach to improve neural network performance.