 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Privacy-Preserving Data Synthetisation for Secure Information Sharing
Dec 01, 2022
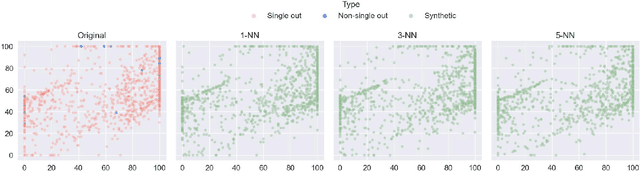
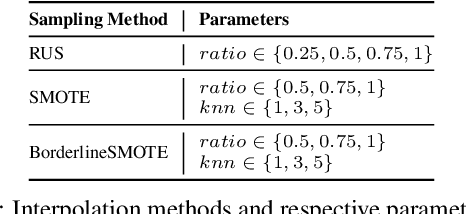
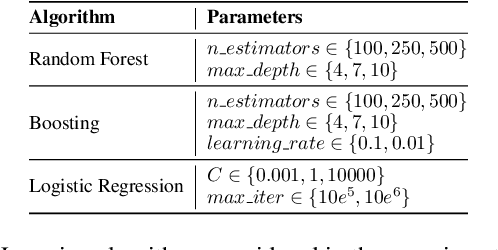
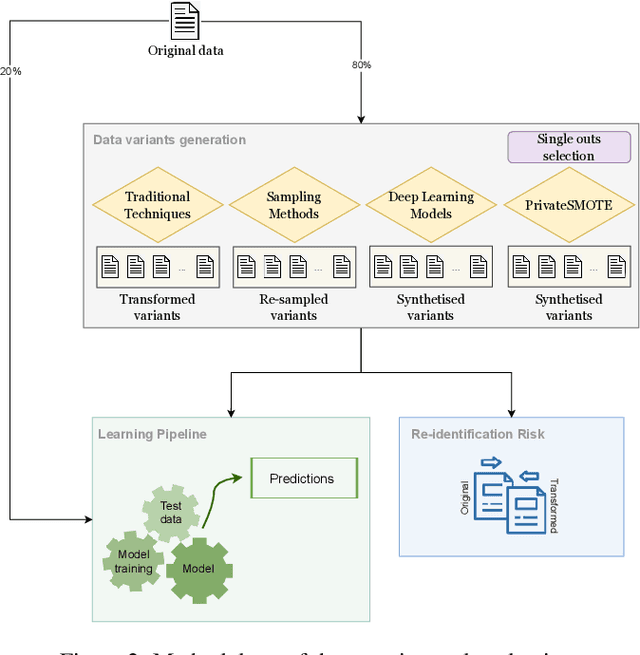
We can protect user data privacy via many approaches, such as statistical transformation or generative models. However, each of them has critical drawbacks. On the one hand, creating a transformed data set using conventional techniques is highly time-consuming. On the other hand, in addition to long training phases, recent deep learning-based solutions require significant computational resources. In this paper, we propose PrivateSMOTE, a technique designed for competitive effectiveness in protecting cases at maximum risk of re-identification while requiring much less time and computational resources. It works by synthetic data generation via interpolation to obfuscate high-risk cases while minimizing data utility loss of the original data. Compared to multiple conventional and state-of-the-art privacy-preservation methods on 20 data sets, PrivateSMOTE demonstrates competitive results in re-identification risk. Also, it presents similar or higher predictive performance than the baselines, including generative adversarial networks and variational autoencoders, reducing their energy consumption and time requirements by a minimum factor of 9 and 12, respectively.
Extreme Q-Learning: MaxEnt RL without Entropy
Jan 05, 2023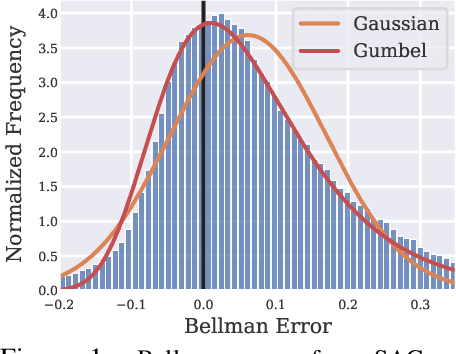
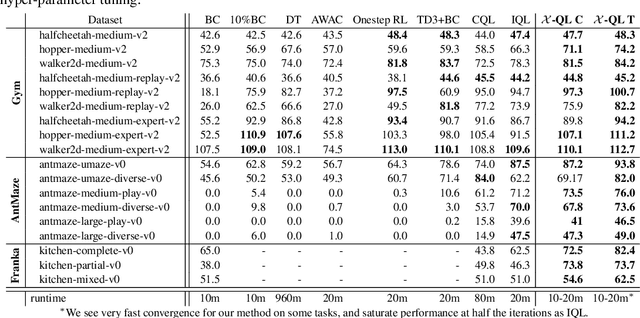
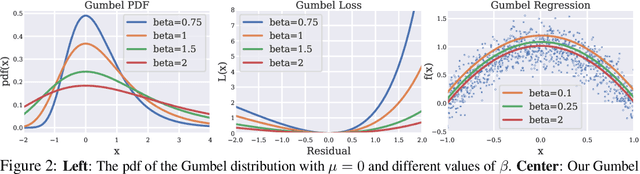
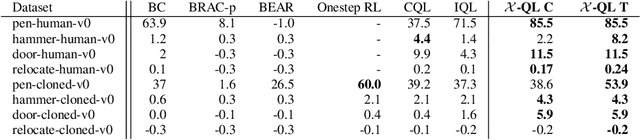
Modern Deep Reinforcement Learning (RL) algorithms require estimates of the maximal Q-value, which are difficult to compute in continuous domains with an infinite number of possible actions. In this work, we introduce a new update rule for online and offline RL which directly models the maximal value using Extreme Value Theory (EVT), drawing inspiration from Economics. By doing so, we avoid computing Q-values using out-of-distribution actions which is often a substantial source of error. Our key insight is to introduce an objective that directly estimates the optimal soft-value functions (LogSumExp) in the maximum entropy RL setting without needing to sample from a policy. Using EVT, we derive our Extreme Q-Learning framework and consequently online and, for the first time, offline MaxEnt Q-learning algorithms, that do not explicitly require access to a policy or its entropy. Our method obtains consistently strong performance in the D4RL benchmark, outperforming prior works by 10+ points on some tasks while offering moderate improvements over SAC and TD3 on online DM Control tasks.
Reservoir kernels and Volterra series
Dec 30, 2022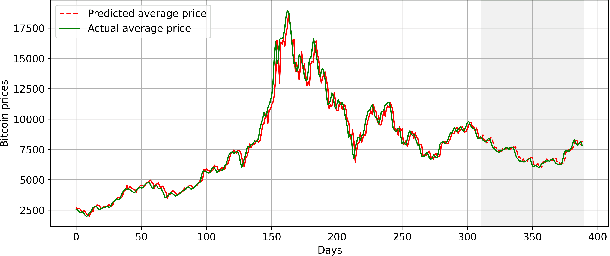
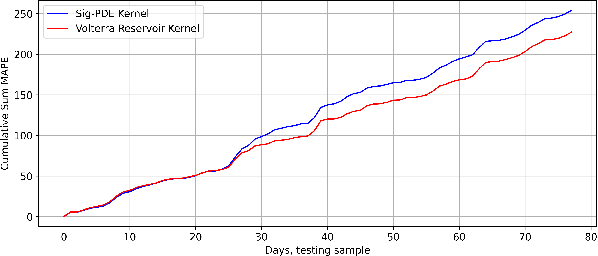
A universal kernel is constructed whose sections approximate any causal and time-invariant filter in the fading memory category with inputs and outputs in a finite-dimensional Euclidean space. This kernel is built using the reservoir functional associated with a state-space representation of the Volterra series expansion available for any analytic fading memory filter. It is hence called the Volterra reservoir kernel. Even though the state-space representation and the corresponding reservoir feature map are defined on an infinite-dimensional tensor algebra space, the kernel map is characterized by explicit recursions that are readily computable for specific data sets when employed in estimation problems using the representer theorem. We showcase the performance of the Volterra reservoir kernel in a popular data science application in relation to bitcoin price prediction.
Perceptual-Neural-Physical Sound Matching
Jan 07, 2023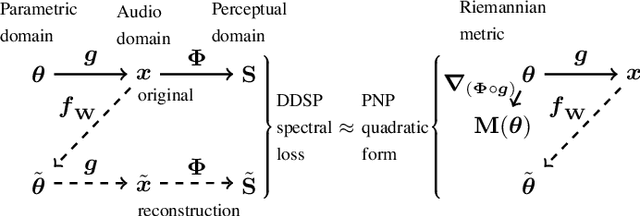
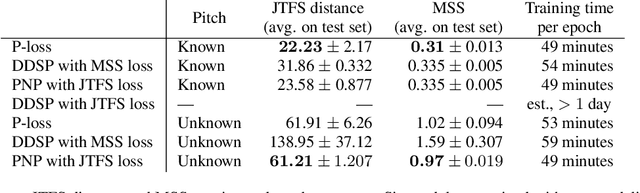
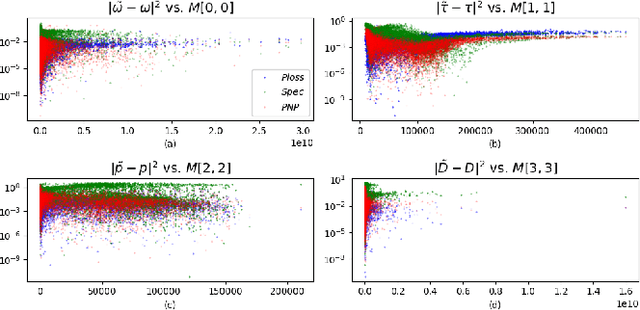
Sound matching algorithms seek to approximate a target waveform by parametric audio synthesis. Deep neural networks have achieved promising results in matching sustained harmonic tones. However, the task is more challenging when targets are nonstationary and inharmonic, e.g., percussion. We attribute this problem to the inadequacy of loss function. On one hand, mean square error in the parametric domain, known as "P-loss", is simple and fast but fails to accommodate the differing perceptual significance of each parameter. On the other hand, mean square error in the spectrotemporal domain, known as "spectral loss", is perceptually motivated and serves in differentiable digital signal processing (DDSP). Yet, spectral loss has more local minima than P-loss and its gradient may be computationally expensive; hence a slow convergence. Against this conundrum, we present Perceptual-Neural-Physical loss (PNP). PNP is the optimal quadratic approximation of spectral loss while being as fast as P-loss during training. We instantiate PNP with physical modeling synthesis as decoder and joint time-frequency scattering transform (JTFS) as spectral representation. We demonstrate its potential on matching synthetic drum sounds in comparison with other loss functions.
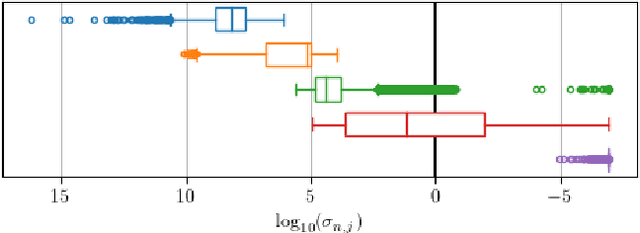
STD: A Seasonal-Trend-Dispersion Decomposition of Time Series
Apr 21, 2022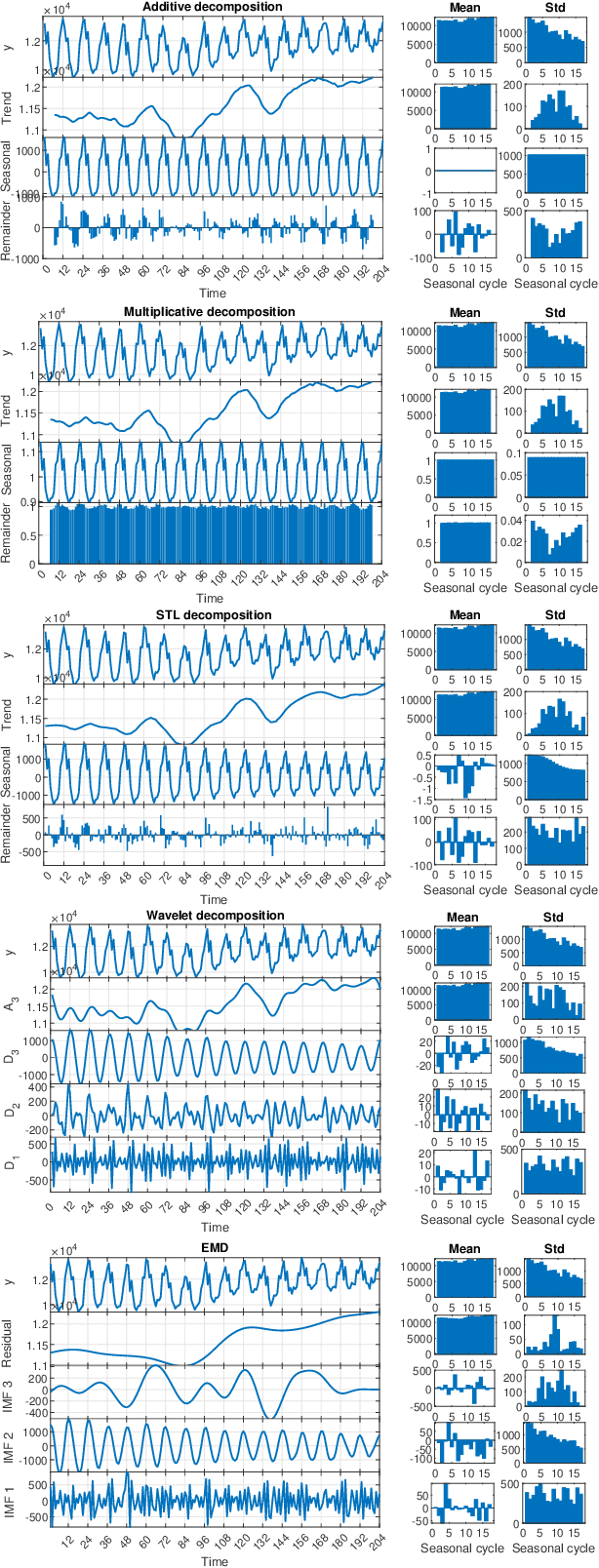
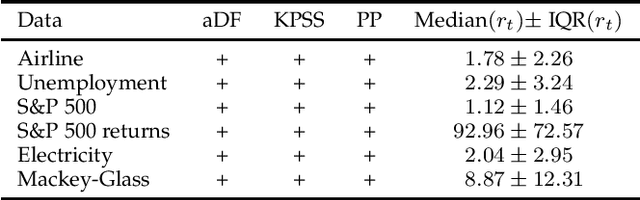
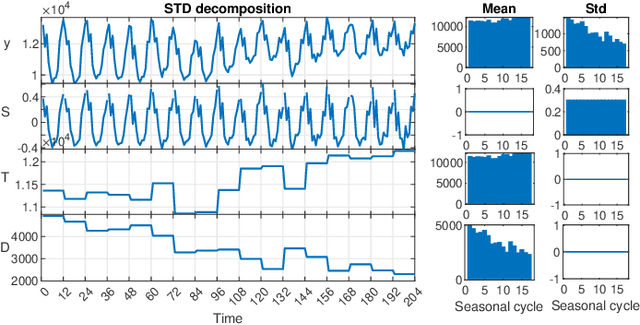
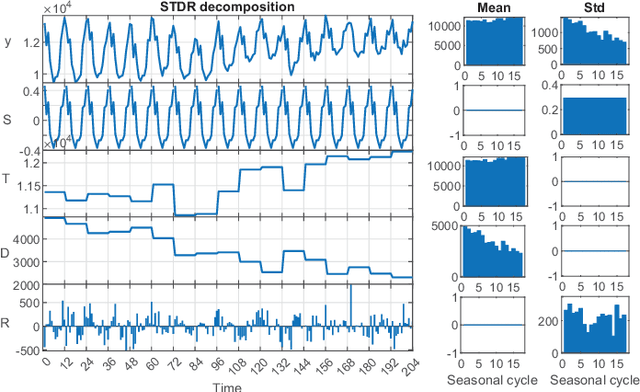
The decomposition of a time series is an essential task that helps to understand its very nature. It facilitates the analysis and forecasting of complex time series expressing various hidden components such as the trend, seasonal components, cyclic components and irregular fluctuations. Therefore, it is crucial in many fields for forecasting and decision processes. In recent years, many methods of time series decomposition have been developed, which extract and reveal different time series properties. Unfortunately, they neglect a very important property, i.e. time series variance. To deal with heteroscedasticity in time series, the method proposed in this work -- a seasonal-trend-dispersion decomposition (STD) -- extracts the trend, seasonal component and component related to the dispersion of the time series. We define STD decomposition in two ways: with and without an irregular component. We show how STD can be used for time series analysis and forecasting.
Clock and Orientation-Robust Simultaneous Radio Localization and Mapping at Millimeter Wave Bands
Dec 27, 2022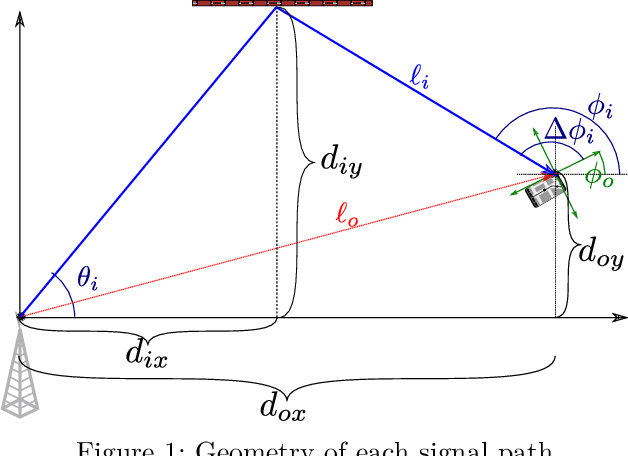
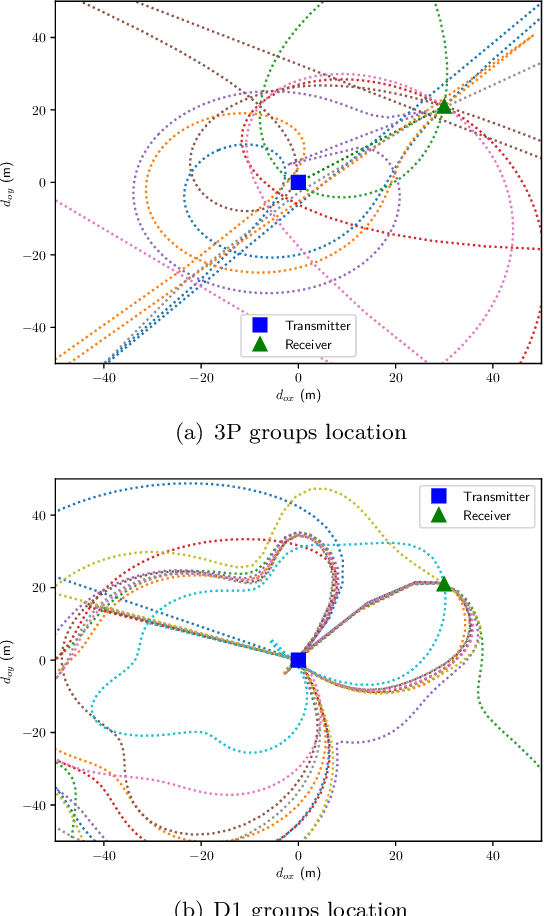
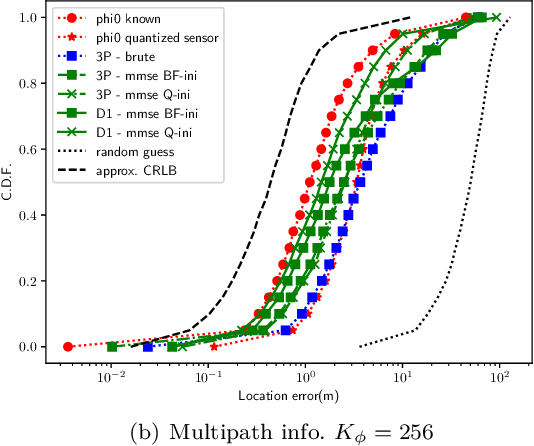
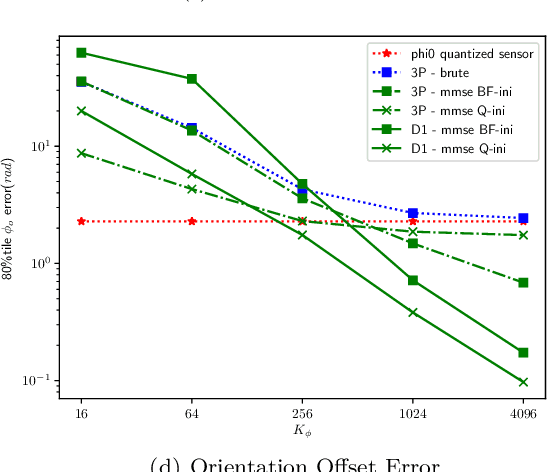
This paper proposes a radio simultaneous location and mapping (radio-SLAM) scheme based on sparse multipath channel estimation. By leveraging sparse channel estimation schemes at millimeter wave bands, namely high resolution estimates of the multipath angle of arrival (AoA), time difference of arrival (TDoA), and angle of departure (AoD), we develop a radio-SLAM algorithm that operates without any requirements of clock synchronization, receiver orientation knowledge, multiple anchor points, or two-way protocols. Thanks to the AoD information obtained via compressed sensing (CS) of the channel, the proposed scheme can estimate the receiver clock offset and orientation from a single anchor transmission, achieving sub-meter accuracy in a realistic typical channel simulation.
Real-time Neural Dense Elevation Mapping for Urban Terrain with Uncertainty Estimations
Aug 06, 2022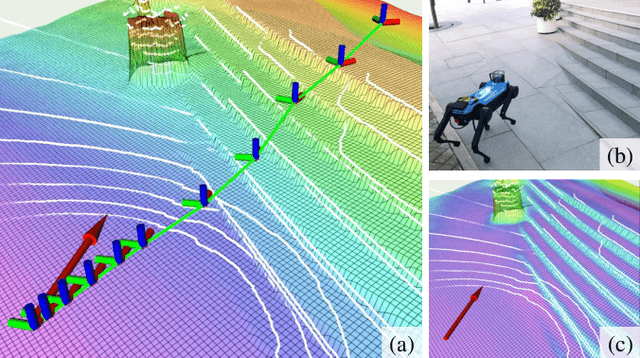
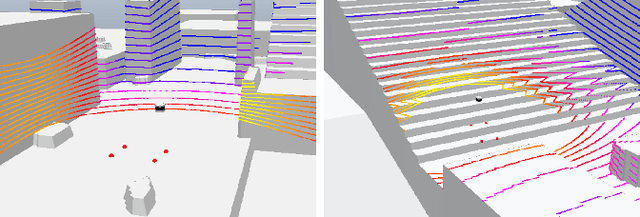
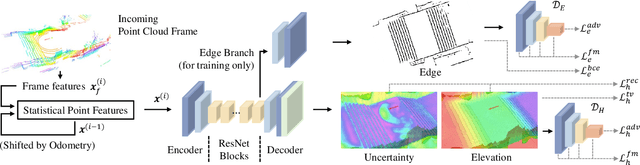

Having good knowledge of terrain information is essential for improving the performance of various downstream tasks on complex terrains, especially for the locomotion and navigation of legged robots. We present a novel framework for neural urban terrain reconstruction with uncertainty estimations. It generates dense robot-centric elevation maps online from sparse LiDAR observations. We design a novel pre-processing and point features representation approach that ensures high robustness and computational efficiency when integrating multiple point cloud frames. A Bayesian-GAN model then recovers the detailed terrain structures while simultaneously providing the pixel-wise reconstruction uncertainty. We evaluate the proposed pipeline through extensive simulation and real-world experiments. It demonstrates efficient terrain reconstruction with high quality and real-time performance on a mobile platform, which further benefits the downstream tasks of legged robots. (See https://kin-zhang.github.io/ndem/ for more details.)
Inference of Nonlinear Partial Differential Equations via Constrained Gaussian Processes
Dec 22, 2022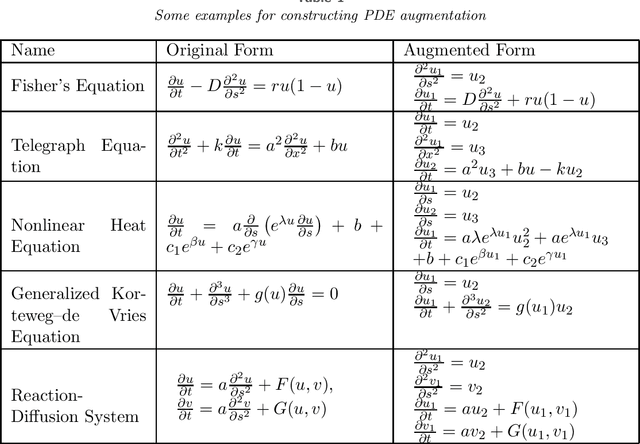
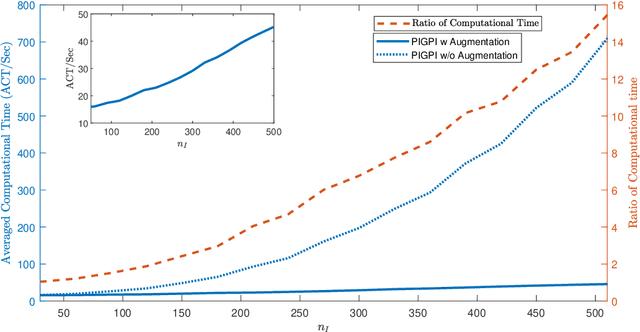
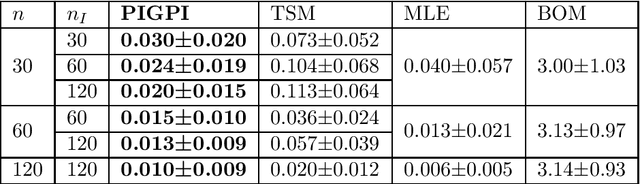

Partial differential equations (PDEs) are widely used for description of physical and engineering phenomena. Some key parameters involved in PDEs, which represents certain physical properties with important scientific interpretations, are difficult or even impossible to be measured directly. Estimation of these parameters from noisy and sparse experimental data of related physical quantities is an important task. Many methods for PDE parameter inference involve a large number of evaluations of numerical solution of PDE through algorithms such as finite element method, which can be time-consuming especially for nonlinear PDEs. In this paper, we propose a novel method for estimating unknown parameters in PDEs, called PDE-Informed Gaussian Process Inference (PIGPI). Through modeling the PDE solution as a Gaussian process (GP), we derive the manifold constraints induced by the (linear) PDE structure such that under the constraints, the GP satisfies the PDE. For nonlinear PDEs, we propose an augmentation method that transfers the nonlinear PDE into an equivalent PDE system linear in all derivatives that our PIGPI can handle. PIGPI can be applied to multi-dimensional PDE systems and PDE systems with unobserved components. The method completely bypasses the numerical solver for PDE, thus achieving drastic savings in computation time, especially for nonlinear PDEs. Moreover, the PIGPI method can give the uncertainty quantification for both the unknown parameters and the PDE solution. The proposed method is demonstrated by several application examples from different areas.
Spatio-Temporal Super-Resolution of Dynamical Systems using Physics-Informed Deep-Learning
Dec 08, 2022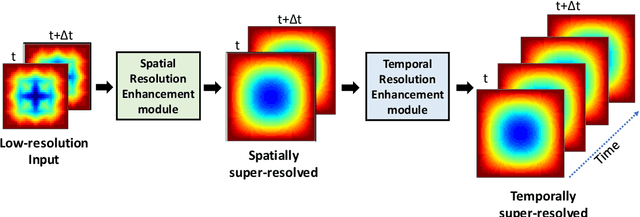
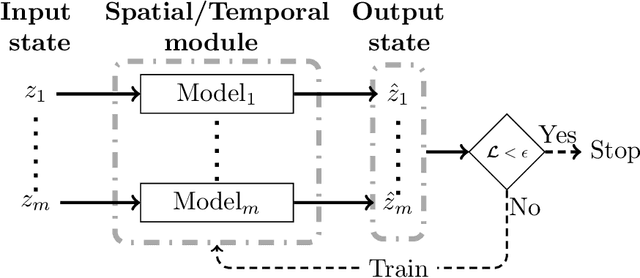
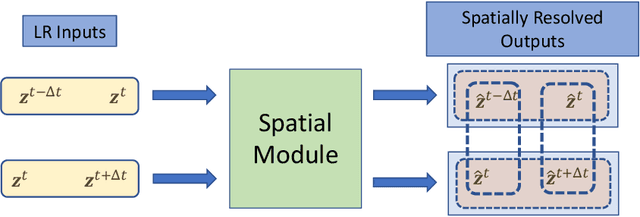
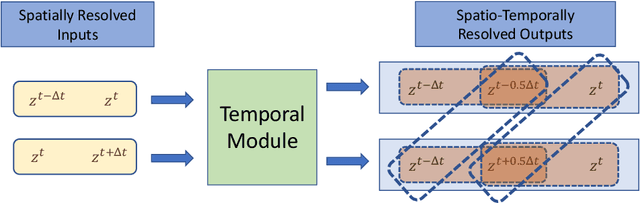
This work presents a physics-informed deep learning-based super-resolution framework to enhance the spatio-temporal resolution of the solution of time-dependent partial differential equations (PDE). Prior works on deep learning-based super-resolution models have shown promise in accelerating engineering design by reducing the computational expense of traditional numerical schemes. However, these models heavily rely on the availability of high-resolution (HR) labeled data needed during training. In this work, we propose a physics-informed deep learning-based framework to enhance the spatial and temporal resolution of coarse-scale (both in space and time) PDE solutions without requiring any HR data. The framework consists of two trainable modules independently super-resolving the PDE solution, first in spatial and then in temporal direction. The physics based losses are implemented in a novel way to ensure tight coupling between the spatio-temporally refined outputs at different times and improve framework accuracy. We analyze the capability of the developed framework by investigating its performance on an elastodynamics problem. It is observed that the proposed framework can successfully super-resolve (both in space and time) the low-resolution PDE solutions while satisfying physics-based constraints and yielding high accuracy. Furthermore, the analysis and obtained speed-up show that the proposed framework is well-suited for integration with traditional numerical methods to reduce computational complexity during engineering design.
Differentiable Time-Frequency Scattering in Kymatio
Apr 19, 2022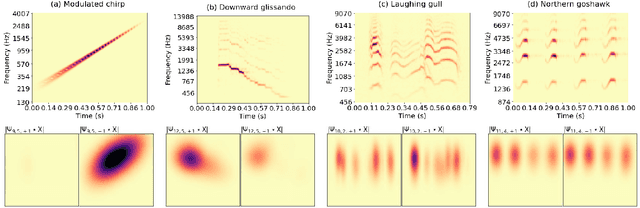

Joint time-frequency scattering (JTFS) is a convolutional operator in the time-frequency domain which extracts spectrotemporal modulations at various rates and scales. It offers an idealized model of spectrotemporal receptive fields (STRF) in the primary auditory cortex, and thus may serve as a biological plausible surrogate for human perceptual judgments at the scale of isolated audio events. Yet, prior implementations of JTFS and STRF have remained outside of the standard toolkit of perceptual similarity measures and evaluation methods for audio generation. We trace this issue down to three limitations: differentiability, speed, and flexibility. In this paper, we present an implementation of time-frequency scattering in Kymatio, an open-source Python package for scattering transforms. Unlike prior implementations, Kymatio accommodates NumPy and PyTorch as backends and is thus portable on both CPU and GPU. We demonstrate the usefulness of JTFS in Kymatio via three applications: unsupervised manifold learning of spectrotemporal modulations, supervised classification of musical instruments, and texture resynthesis of bioacoustic sounds.