 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Small Moving Object Detection Algorithm Based on Motion Information
Jan 05, 2023

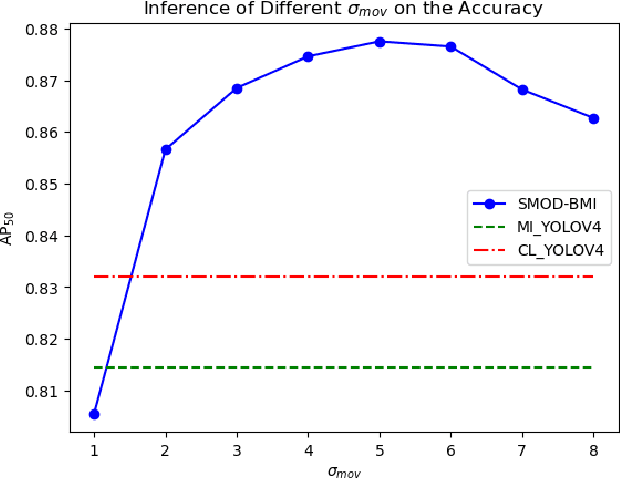
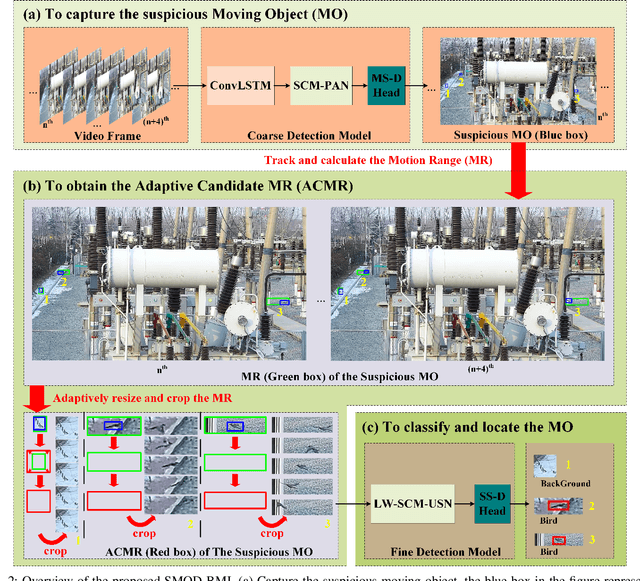
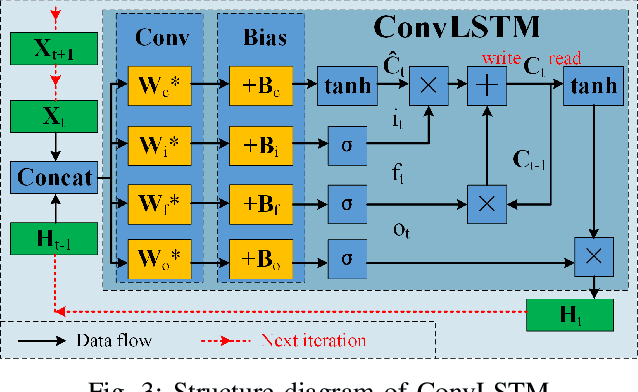
A Samll Moving Object Detection algorithm Based on Motion Information (SMOD-BMI) was proposed to detect small moving objects with low Signal-to-Noise Ratio (SNR). Firstly, To capture suspicious moving objects, a ConvLSTM-SCM-PAN model structure was designed, in which the Convolutional Long and Short Time Memory (ConvLSTM) network fused temporal and spatial information, the Selective Concatenate Module (SCM) was selected to solve the problem of channel unbalance during feature fusion, and the Path Aggregation Network (PAN) located the suspicious moving objects. Then, an object tracking algorithm is used to track suspicious moving objects and calculate their Motion Range (MR). At the same time, according to the moving speed of the suspicious moving objects, the size of their MR is adjusted adaptively (To be specific, if the objects move slowly, we expand their MR according their speed to ensure the contextual environment information) to obtain their Adaptive Candidate Motion Range (ACMR), so as to ensure that the SNR of the moving object is improved while the necessary context information is retained adaptively. Finally, a LightWeight SCM U-Shape Net (LW-SCM-USN) based on ACMR with a SCM module is designed to classify and locate small moving objects accurately and quickly. In this paper, the moving bird in surveillance video is used as the experimental dataset to verify the performance of the algorithm. The experimental results show that the proposed small moving object detection method based on motion information can effectively reduce the missing rate and false detection rate, and its performance is better than the existing moving small object detection method of SOTA.
Fractal Patterns in Music
Dec 23, 2022



If our aesthetic preferences are affected by fractal geometry of nature, scaling regularities would be expected to appear in all art forms, including music. While a variety of statistical tools have been proposed to analyze time series in sound, no consensus has as yet emerged regarding the most meaningful measure of complexity in music, or how to discern fractal patterns in compositions in the first place. Here we offer a new approach based on self-similarity of the melodic lines recurring at various temporal scales. In contrast to the statistical analyses advanced in recent literature, the proposed method does not depend on averaging within time-windows and is distinctively local. The corresponding definition of the fractal dimension is based on the temporal scaling hierarchy and depends on the tonal contours of the musical motifs. The new concepts are tested on musical 'renditions' of the Cantor Set and Koch Curve, and then applied to a number of carefully selected masterful compositions spanning five centuries of music making.
Fast Event-based Optical Flow Estimation by Triplet Matching
Dec 23, 2022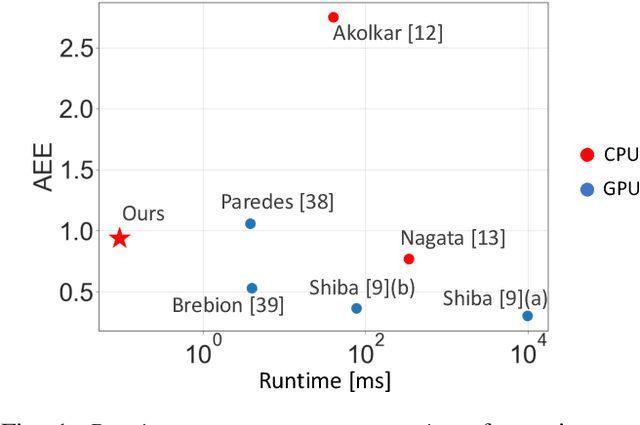
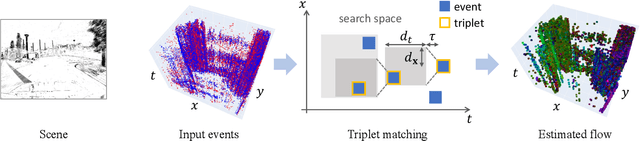

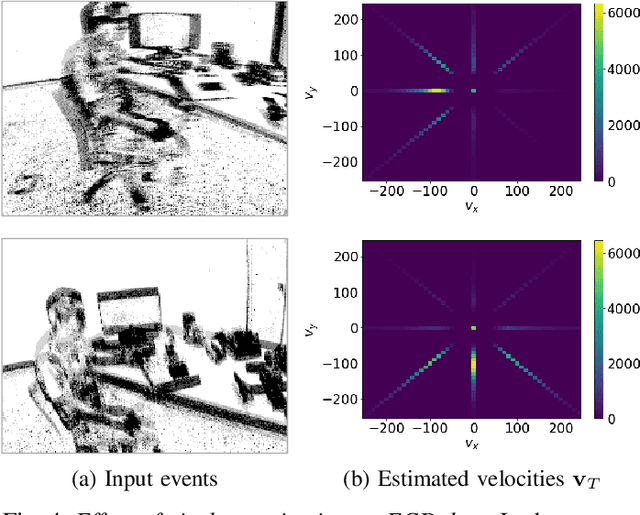
Event cameras are novel bio-inspired sensors that offer advantages over traditional cameras (low latency, high dynamic range, low power, etc.). Optical flow estimation methods that work on packets of events trade off speed for accuracy, while event-by-event (incremental) methods have strong assumptions and have not been tested on common benchmarks that quantify progress in the field. Towards applications on resource-constrained devices, it is important to develop optical flow algorithms that are fast, light-weight and accurate. This work leverages insights from neuroscience, and proposes a novel optical flow estimation scheme based on triplet matching. The experiments on publicly available benchmarks demonstrate its capability to handle complex scenes with comparable results as prior packet-based algorithms. In addition, the proposed method achieves the fastest execution time (> 10 kHz) on standard CPUs as it requires only three events in estimation. We hope that our research opens the door to real-time, incremental motion estimation methods and applications in real-world scenarios.
A Faster $k$-means++ Algorithm
Nov 28, 2022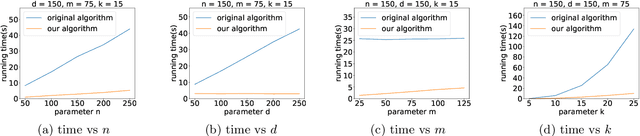
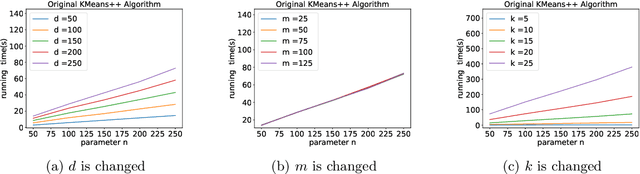
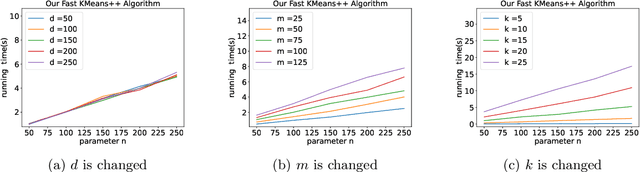
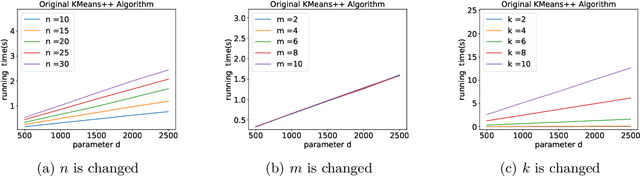
K-means++ is an important algorithm to choose initial cluster centers for the k-means clustering algorithm. In this work, we present a new algorithm that can solve the $k$-means++ problem with near optimal running time. Given $n$ data points in $\mathbb{R}^d$, the current state-of-the-art algorithm runs in $\widetilde{O}(k )$ iterations, and each iteration takes $\widetilde{O}(nd k)$ time. The overall running time is thus $\widetilde{O}(n d k^2)$. We propose a new algorithm \textsc{FastKmeans++} that only takes in $\widetilde{O}(nd + nk^2)$ time, in total.
Online Centralized Non-parametric Change-point Detection via Graph-based Likelihood-ratio Estimation
Jan 08, 2023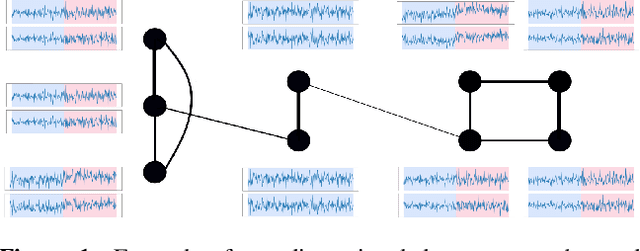
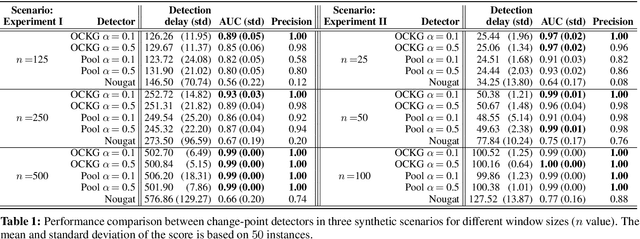
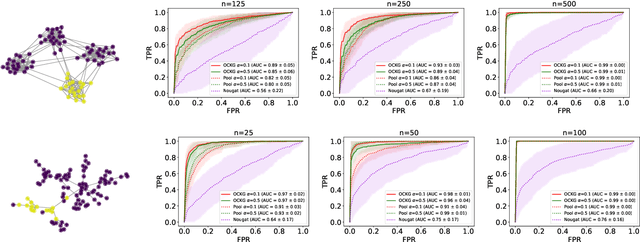
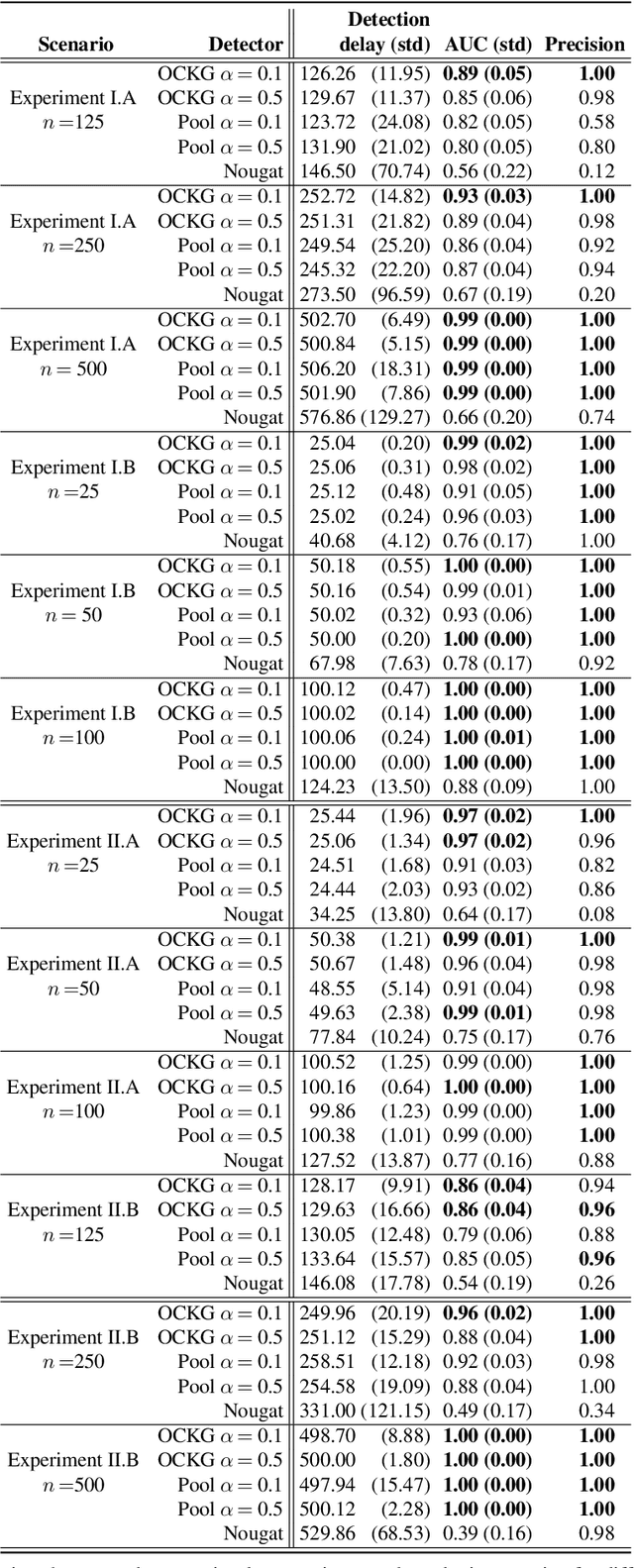
Consider each node of a graph to be generating a data stream that is synchronized and observed at near real-time. At a change-point $\tau$, a change occurs at a subset of nodes $C$, which affects the probability distribution of their associated node streams. In this paper, we propose a novel kernel-based method to both detect $\tau$ and localize $C$, based on the direct estimation of the likelihood-ratio between the post-change and the pre-change distributions of the node streams. Our main working hypothesis is the smoothness of the likelihood-ratio estimates over the graph, i.e connected nodes are expected to have similar likelihood-ratios. The quality of the proposed method is demonstrated on extensive experiments on synthetic scenarios.
Equivariant and Steerable Neural Networks: A review with special emphasis on the symmetric group
Jan 08, 2023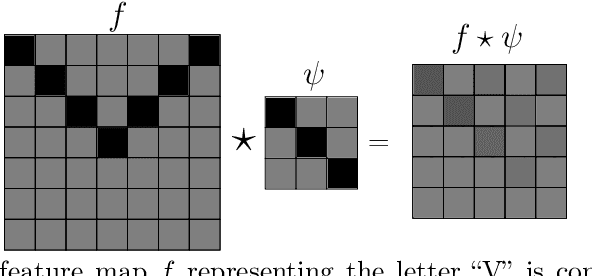

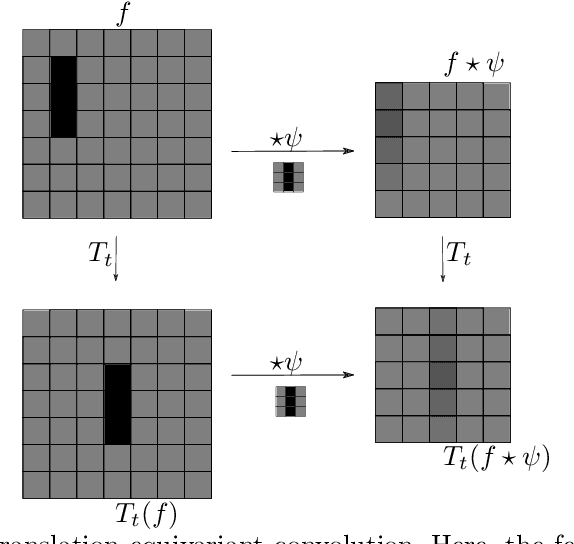

Convolutional neural networks revolutionized computer vision and natrual language processing. Their efficiency, as compared to fully connected neural networks, has its origin in the architecture, where convolutions reflect the translation invariance in space and time in pattern or speech recognition tasks. Recently, Cohen and Welling have put this in the broader perspective of invariance under symmetry groups, which leads to the concept of group equivaiant neural networks and more generally steerable neural networks. In this article, we review the architecture of such networks including equivariant layers and filter banks, activation with capsules and group pooling. We apply this formalism to the symmetric group, for which we work out a number of details on representations and capsules that are not found in the literature.
Recurrent Vision Transformers for Object Detection with Event Cameras
Dec 11, 2022
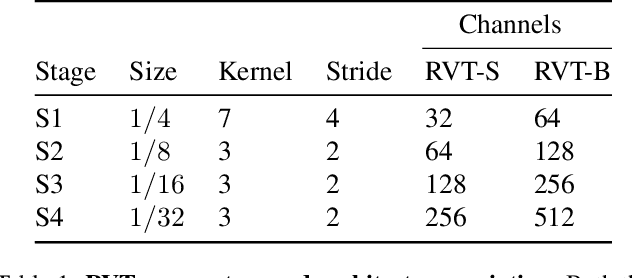
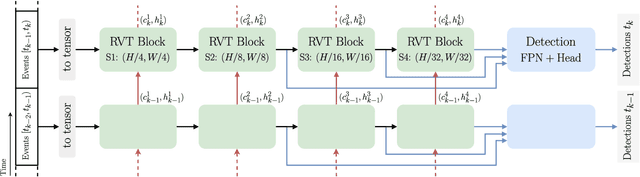
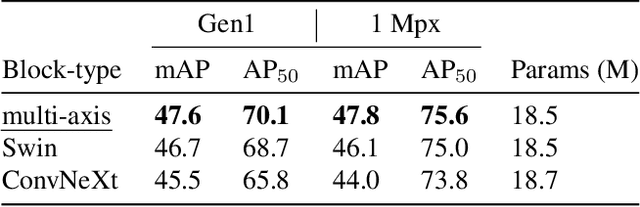
We present Recurrent Vision Transformers (RVTs), a novel backbone for object detection with event cameras. Event cameras provide visual information with sub-millisecond latency at a high-dynamic range and with strong robustness against motion blur. These unique properties offer great potential for low-latency object detection and tracking in time-critical scenarios. Prior work in event-based vision has achieved outstanding detection performance but at the cost of substantial inference time, typically beyond 40 milliseconds. By revisiting the high-level design of recurrent vision backbones, we reduce inference time by a factor of 5 while retaining similar performance. To achieve this, we explore a multi-stage design that utilizes three key concepts in each stage: First, a convolutional prior that can be regarded as a conditional positional embedding. Second, local- and dilated global self-attention for spatial feature interaction. Third, recurrent temporal feature aggregation to minimize latency while retaining temporal information. RVTs can be trained from scratch to reach state-of-the-art performance on event-based object detection - achieving an mAP of 47.5% on the Gen1 automotive dataset. At the same time, RVTs offer fast inference (13 ms on a T4 GPU) and favorable parameter efficiency (5 times fewer than prior art). Our study brings new insights into effective design choices that could be fruitful for research beyond event-based vision.
Adaptive Sequential Surveillance with Network and Temporal Dependence
Dec 05, 2022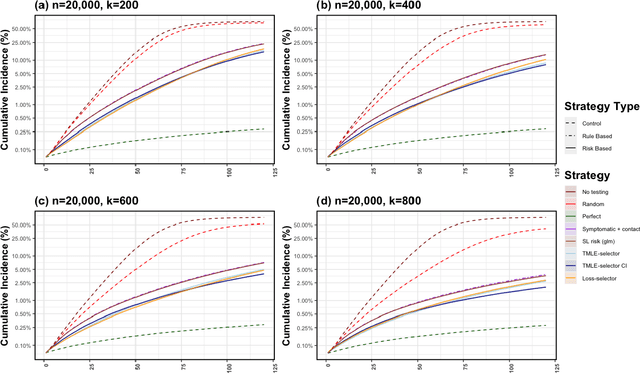

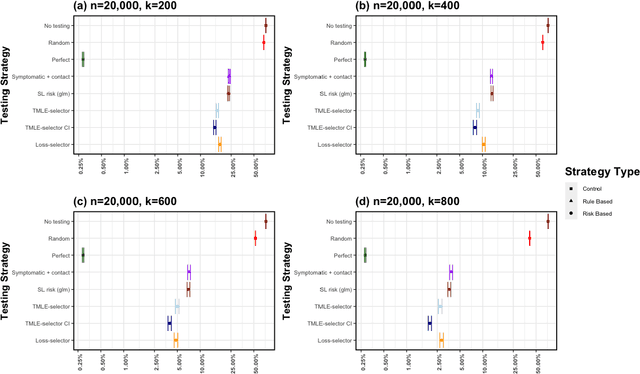
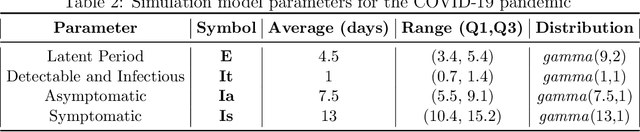
Strategic test allocation plays a major role in the control of both emerging and existing pandemics (e.g., COVID-19, HIV). Widespread testing supports effective epidemic control by (1) reducing transmission via identifying cases, and (2) tracking outbreak dynamics to inform targeted interventions. However, infectious disease surveillance presents unique statistical challenges. For instance, the true outcome of interest - one's positive infectious status, is often a latent variable. In addition, presence of both network and temporal dependence reduces the data to a single observation. As testing entire populations regularly is neither efficient nor feasible, standard approaches to testing recommend simple rule-based testing strategies (e.g., symptom based, contact tracing), without taking into account individual risk. In this work, we study an adaptive sequential design involving n individuals over a period of {\tau} time-steps, which allows for unspecified dependence among individuals and across time. Our causal target parameter is the mean latent outcome we would have obtained after one time-step, if, starting at time t given the observed past, we had carried out a stochastic intervention that maximizes the outcome under a resource constraint. We propose an Online Super Learner for adaptive sequential surveillance that learns the optimal choice of tests strategies over time while adapting to the current state of the outbreak. Relying on a series of working models, the proposed method learns across samples, through time, or both: based on the underlying (unknown) structure in the data. We present an identification result for the latent outcome in terms of the observed data, and demonstrate the superior performance of the proposed strategy in a simulation modeling a residential university environment during the COVID-19 pandemic.
Forecasting the 2016-2017 Central Apennines Earthquake Sequence with a Neural Point Process
Jan 24, 2023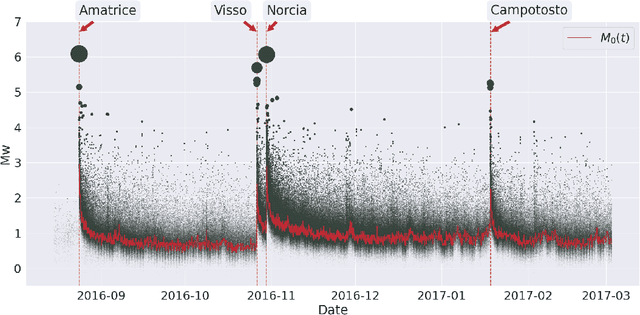
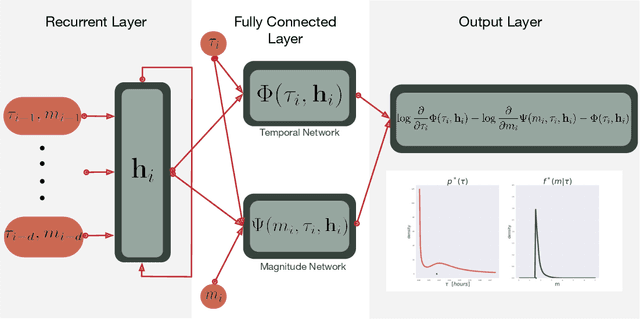
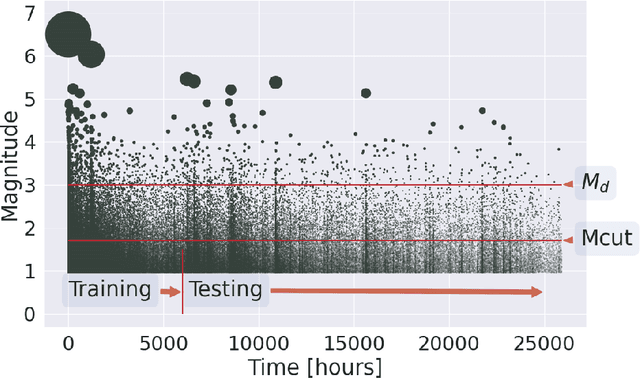
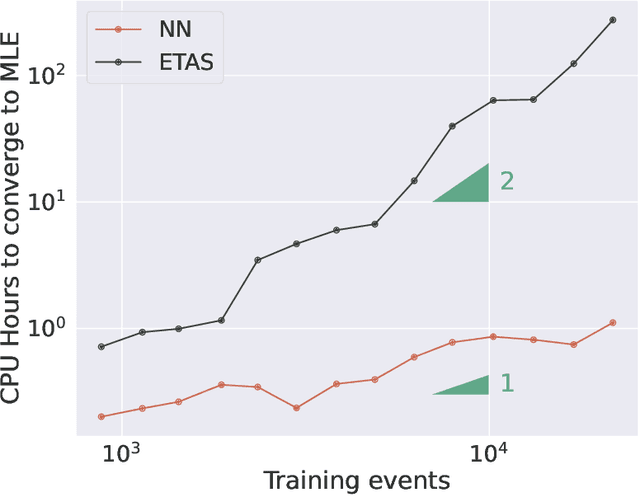
Point processes have been dominant in modeling the evolution of seismicity for decades, with the Epidemic Type Aftershock Sequence (ETAS) model being most popular. Recent advances in machine learning have constructed highly flexible point process models using neural networks to improve upon existing parametric models. We investigate whether these flexible point process models can be applied to short-term seismicity forecasting by extending an existing temporal neural model to the magnitude domain and we show how this model can forecast earthquakes above a target magnitude threshold. We first demonstrate that the neural model can fit synthetic ETAS data, however, requiring less computational time because it is not dependent on the full history of the sequence. By artificially emulating short-term aftershock incompleteness in the synthetic dataset, we find that the neural model outperforms ETAS. Using a new enhanced catalog from the 2016-2017 Central Apennines earthquake sequence, we investigate the predictive skill of ETAS and the neural model with respect to the lowest input magnitude. Constructing multiple forecasting experiments using the Visso, Norcia and Campotosto earthquakes to partition training and testing data, we target M3+ events. We find both models perform similarly at previously explored thresholds (e.g., above M3), but lowering the threshold to M1.2 reduces the performance of ETAS unlike the neural model. We argue that some of these gains are due to the neural model's ability to handle incomplete data. The robustness to missing data and speed to train the neural model present it as an encouraging competitor in earthquake forecasting.
YOLOv6 v3.0: A Full-Scale Reloading
Jan 13, 2023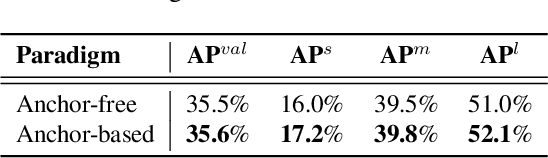
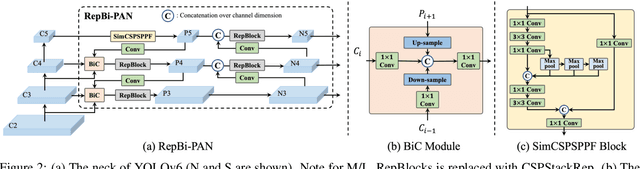
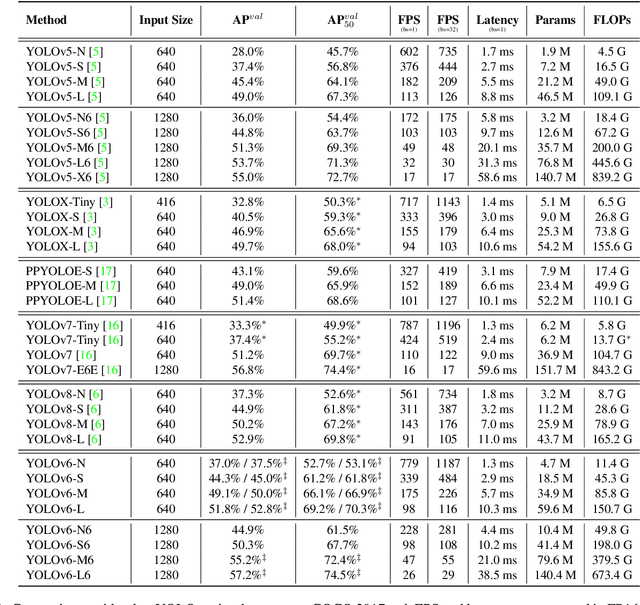
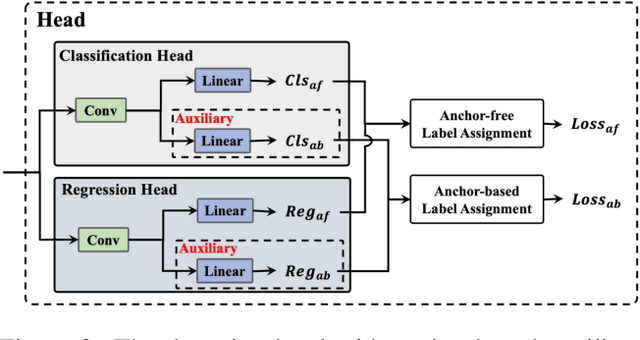
The YOLO community has been in high spirits since our first two releases! By the advent of Chinese New Year 2023, which sees the Year of the Rabbit, we refurnish YOLOv6 with numerous novel enhancements on the network architecture and the training scheme. This release is identified as YOLOv6 v3.0. For a glimpse of performance, our YOLOv6-N hits 37.5% AP on the COCO dataset at a throughput of 1187 FPS tested with an NVIDIA Tesla T4 GPU. YOLOv6-S strikes 45.0% AP at 484 FPS, outperforming other mainstream detectors at the same scale (YOLOv5-S, YOLOv8-S, YOLOX-S and PPYOLOE-S). Whereas, YOLOv6-M/L also achieve better accuracy performance (50.0%/52.8% respectively) than other detectors at a similar inference speed. Additionally, with an extended backbone and neck design, our YOLOv6-L6 achieves the state-of-the-art accuracy in real-time. Extensive experiments are carefully conducted to validate the effectiveness of each improving component. Our code is made available at https://github.com/meituan/YOLOv6.