 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model-based Transfer Learning for Automatic Optical Inspection based on domain discrepancy
Jan 14, 2023
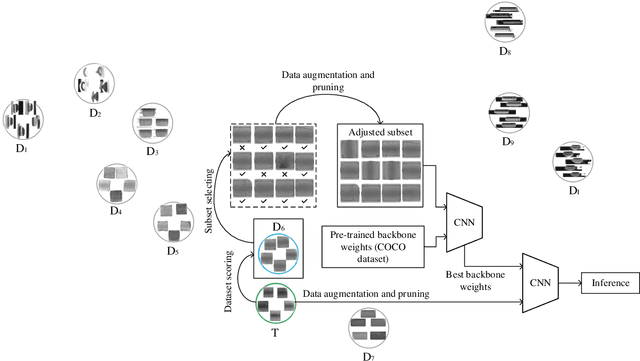

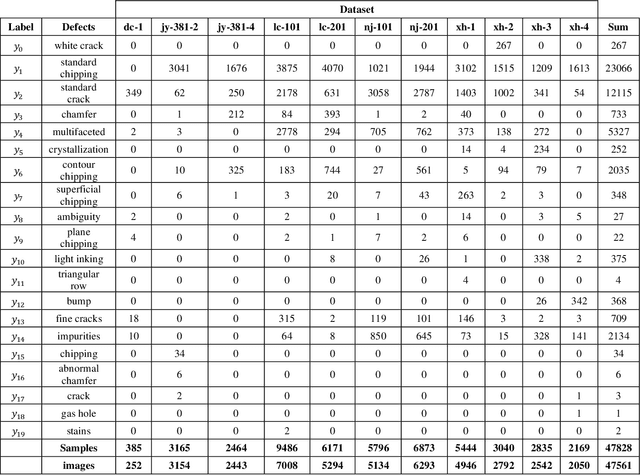
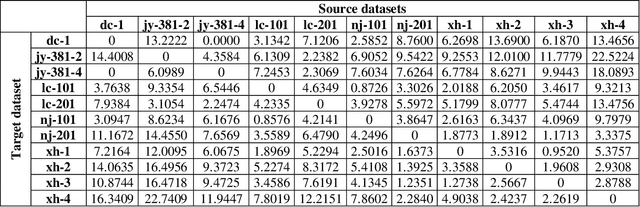
Transfer learning is a promising method for AOI applications since it can significantly shorten sample collection time and improve efficiency in today's smart manufacturing. However, related research enhanced the network models by applying TL without considering the domain similarity among datasets, the data long-tailedness of a source dataset, and mainly used linear transformations to mitigate the lack of samples. This research applies model-based TL via domain similarity to improve the overall performance and data augmentation in both target and source domains to enrich the data quality and reduce the imbalance. Given a group of source datasets from similar industrial processes, we define which group is the most related to the target through the domain discrepancy score and the number of samples each has. Then, we transfer the chosen pre-trained backbone weights to train and fine-tune the target network. Our research suggests increases in the F1 score and the PR curve up to 20% compared with TL using benchmark datasets.
* This is a fix of the published paper "Relational-based transfer learning for automatic optical inspection based on domain discrepancy"
Learning Trajectory-Conditioned Relations to Predict Pedestrian Crossing Behavior
Jan 14, 2023
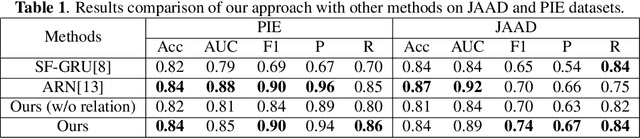
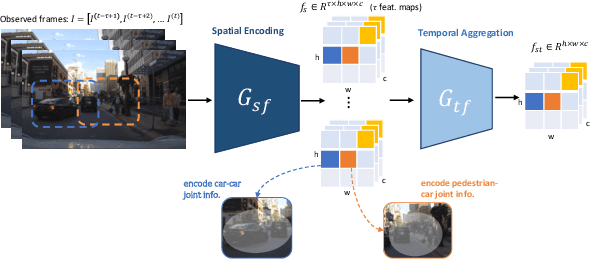
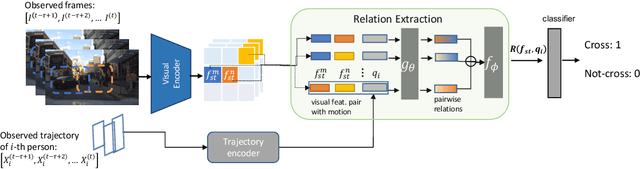
In smart transportation, intelligent systems avoid potential collisions by predicting the intent of traffic agents, especially pedestrians. Pedestrian intent, defined as future action, e.g., start crossing, can be dependent on traffic surroundings. In this paper, we develop a framework to incorporate such dependency given observed pedestrian trajectory and scene frames. Our framework first encodes regional joint information between a pedestrian and surroundings over time into feature-map vectors. The global relation representations are then extracted from pairwise feature-map vectors to estimate intent with past trajectory condition. We evaluate our approach on two public datasets and compare against two state-of-the-art approaches. The experimental results demonstrate that our method helps to inform potential risks during crossing events with 0.04 improvement in F1-score on JAAD dataset and 0.01 improvement in recall on PIE dataset. Furthermore, we conduct ablation experiments to confirm the contribution of the relation extraction in our framework.
Forecasting Soil Moisture Using Domain Inspired Temporal Graph Convolution Neural Networks To Guide Sustainable Crop Management
Dec 12, 2022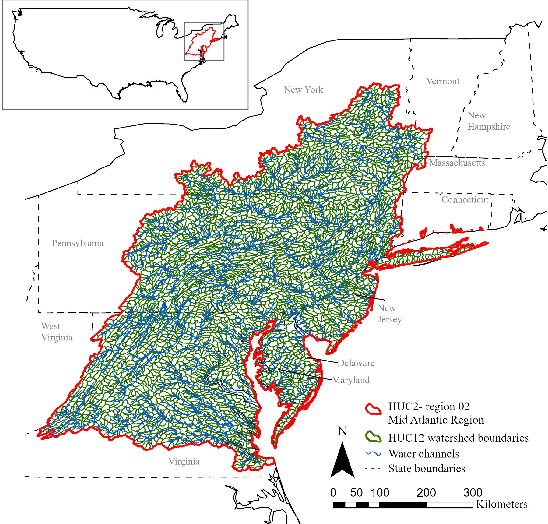
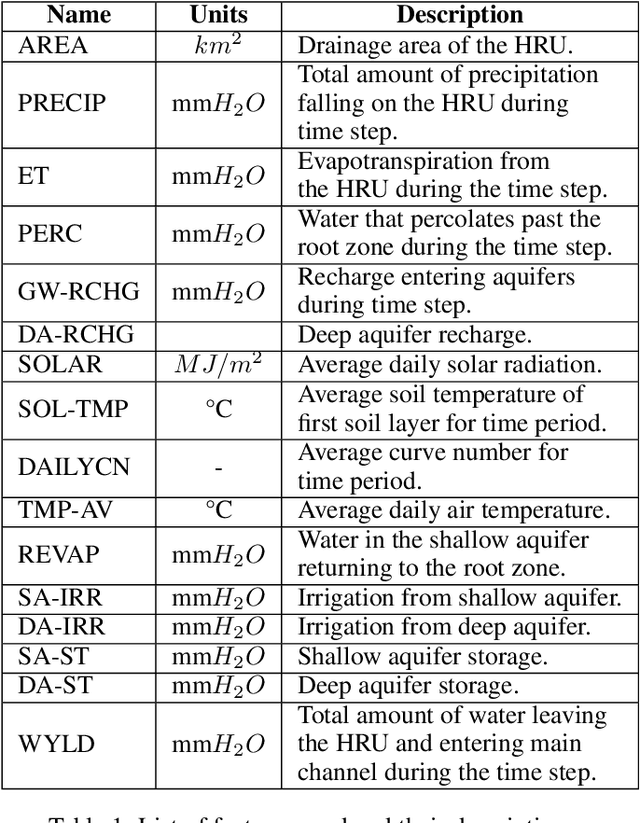
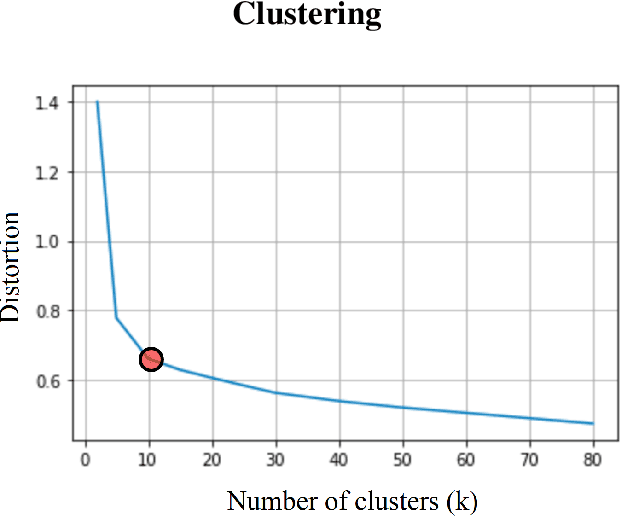
Climate change, population growth, and water scarcity present unprecedented challenges for agriculture. This project aims to forecast soil moisture using domain knowledge and machine learning for crop management decisions that enable sustainable farming. Traditional methods for predicting hydrological response features require significant computational time and expertise. Recent work has implemented machine learning models as a tool for forecasting hydrological response features, but these models neglect a crucial component of traditional hydrological modeling that spatially close units can have vastly different hydrological responses. In traditional hydrological modeling, units with similar hydrological properties are grouped together and share model parameters regardless of their spatial proximity. Inspired by this domain knowledge, we have constructed a novel domain-inspired temporal graph convolution neural network. Our approach involves clustering units based on time-varying hydrological properties, constructing graph topologies for each cluster, and forecasting soil moisture using graph convolutions and a gated recurrent neural network. We have trained, validated, and tested our method on field-scale time series data consisting of approximately 99,000 hydrological response units spanning 40 years in a case study in northeastern United States. Comparison with existing models illustrates the effectiveness of using domain-inspired clustering with time series graph neural networks. The framework is being deployed as part of a pro bono social impact program. The trained models are being deployed on small-holding farms in central Texas.
Simple Yet Surprisingly Effective Training Strategies for LSTMs in Sensor-Based Human Activity Recognition
Dec 23, 2022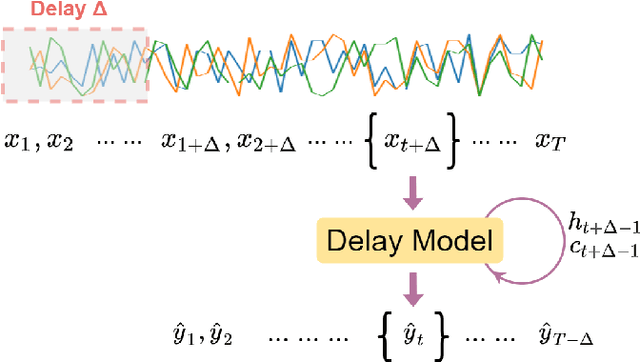
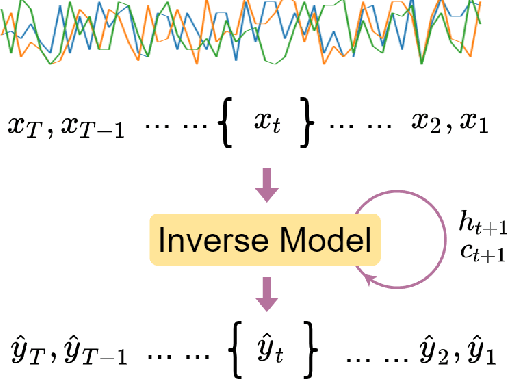
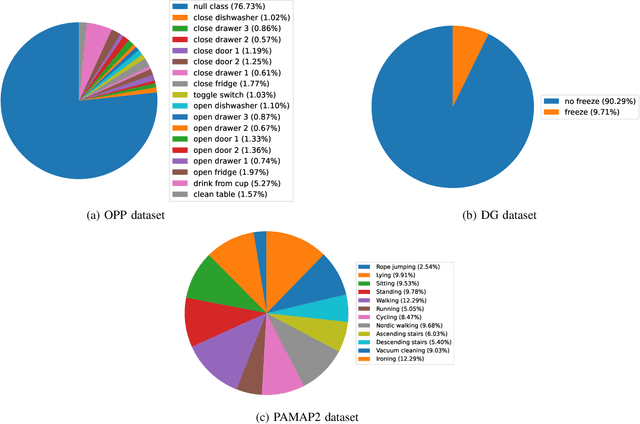
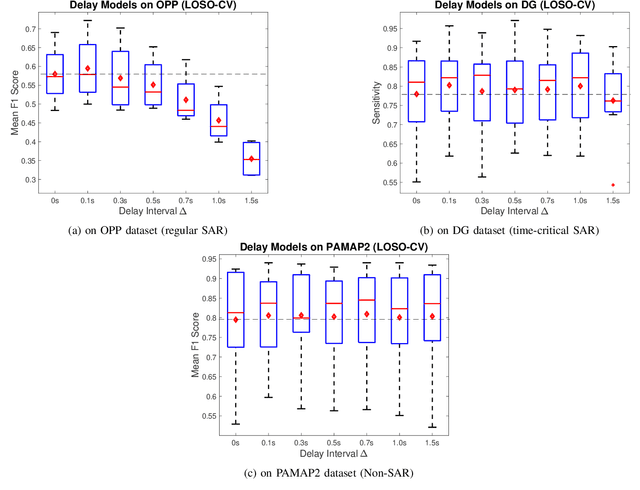
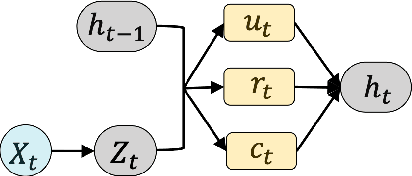
Human Activity Recognition (HAR) is one of the core research areas in mobile and wearable computing. With the application of deep learning (DL) techniques such as CNN, recognizing periodic or static activities (e.g, walking, lying, cycling, etc.) has become a well studied problem. What remains a major challenge though is the sporadic activity recognition (SAR) problem, where activities of interest tend to be non periodic, and occur less frequently when compared with the often large amount of irrelevant background activities. Recent works suggested that sequential DL models (such as LSTMs) have great potential for modeling nonperiodic behaviours, and in this paper we studied some LSTM training strategies for SAR. Specifically, we proposed two simple yet effective LSTM variants, namely delay model and inverse model, for two SAR scenarios (with and without time critical requirement). For time critical SAR, the delay model can effectively exploit predefined delay intervals (within tolerance) in form of contextual information for improved performance. For regular SAR task, the second proposed, inverse model can learn patterns from the time series in an inverse manner, which can be complementary to the forward model (i.e.,LSTM), and combining both can boost the performance. These two LSTM variants are very practical, and they can be deemed as training strategies without alteration of the LSTM fundamentals. We also studied some additional LSTM training strategies, which can further improve the accuracy. We evaluated our models on two SAR and one non-SAR datasets, and the promising results demonstrated the effectiveness of our approaches in HAR applications.
Hybrid Quantum-Classical Autoencoders for End-to-End Radio Communication
Jan 06, 2023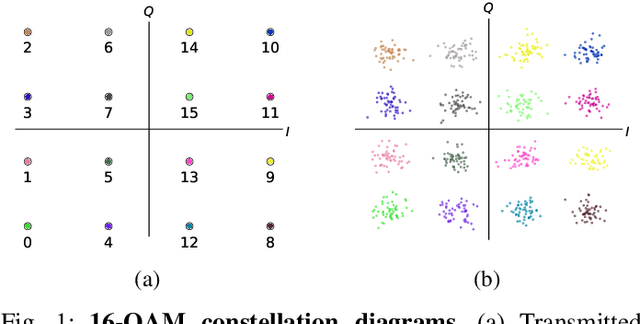

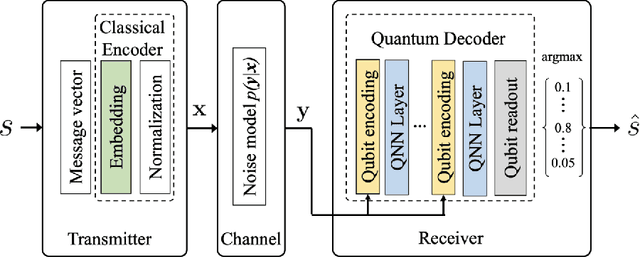
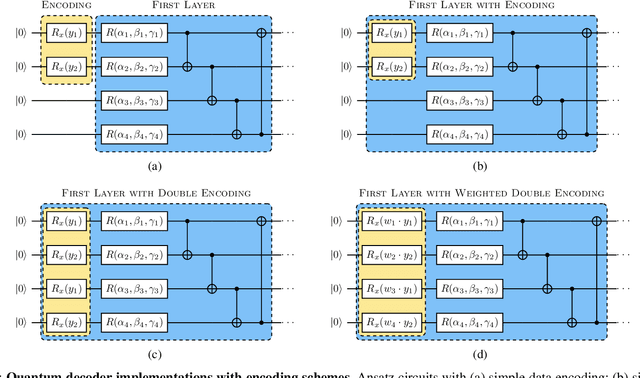
Quantum neural networks are emerging as potential candidates to leverage noisy quantum processing units for applications. Here we introduce hybrid quantum-classical autoencoders for end-to-end radio communication. In the physical layer of classical wireless systems, we study the performance of simulated architectures for standard encoded radio signals over a noisy channel. We implement a hybrid model, where a quantum decoder in the receiver works with a classical encoder in the transmitter part. Besides learning a latent space representation of the input symbols with good robustness against signal degradation, a generalized data re-uploading scheme for the qubit-based circuits allows to meet inference-time constraints of the application.
* 6 pages, 8 figures
Blind estimation of room acoustic parameters from speech signals based on extended model of room impulse response
Dec 26, 2022
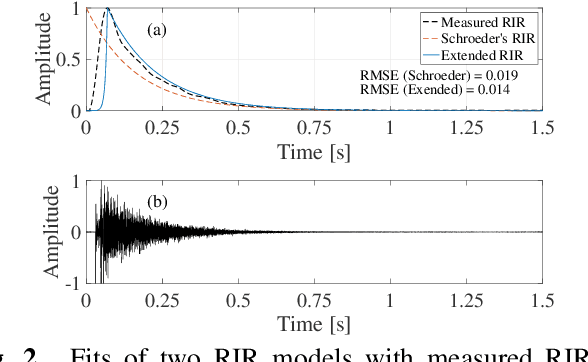
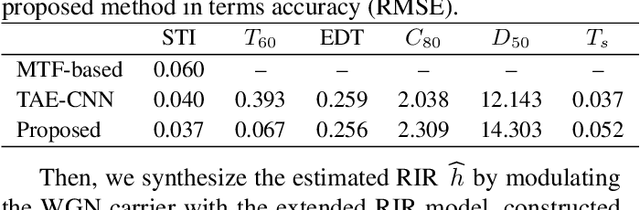
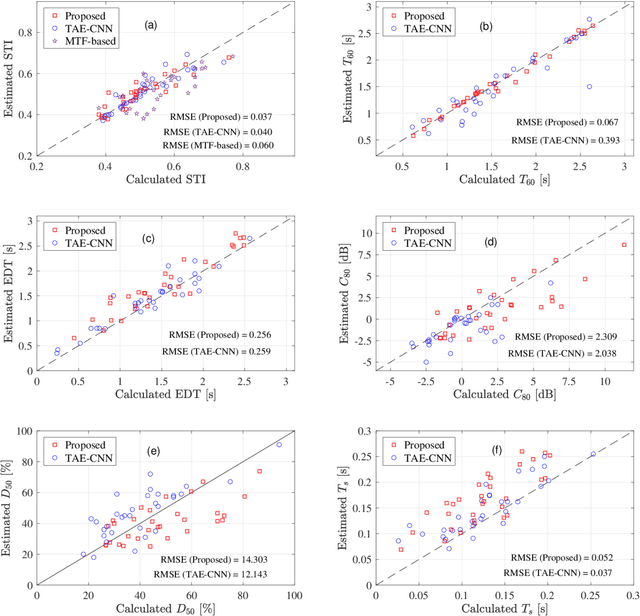
The speech transmission index (STI) and room acoustic parameters (RAPs), which are derived from a room impulse response (RIR), such as reverberation time and early decay time, are essential to assess speech transmission and to predict the listening difficulty in a sound field. Since it is difficult to measure RIR in daily occupied spaces, simultaneous blind estimation of STI and RAPs must be resolved as it is an imperative and challenging issue. This paper proposes a deterministic method for blindly estimating STI and five RAPs on the basis of an RIR stochastic model that approximates an unknown RIR. The proposed method formulates a temporal power envelope of a reverberant speech signal to obtain the optimal parameters for the RIR model. Simulations were conducted to evaluate STI and RAPs from observed reverberant speech signals. The root-mean-square errors between the estimated and ground-truth results were used to comparatively evaluate the proposed method with the previous method. The results showed that the proposed method can estimate STI and RAPs effectively without any training.
Two-Timescale Stochastic Approximation for Bilevel Optimisation Problems in Continuous-Time Models
Jun 14, 2022We analyse the asymptotic properties of a continuous-time, two-timescale stochastic approximation algorithm designed for stochastic bilevel optimisation problems in continuous-time models. We obtain the weak convergence rate of this algorithm in the form of a central limit theorem. We also demonstrate how this algorithm can be applied to several continuous-time bilevel optimisation problems.
Ontology Pre-training for Poison Prediction
Jan 20, 2023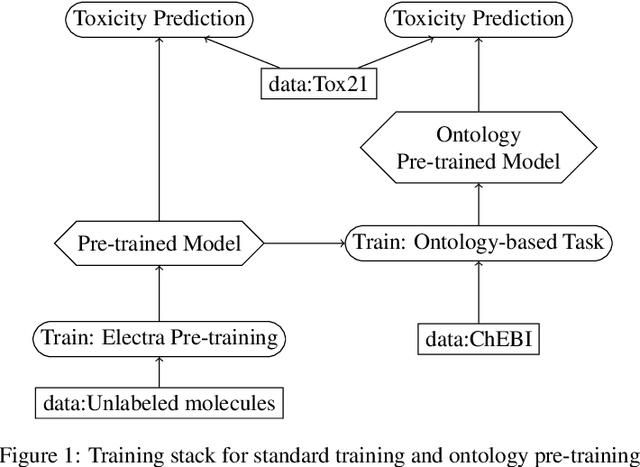
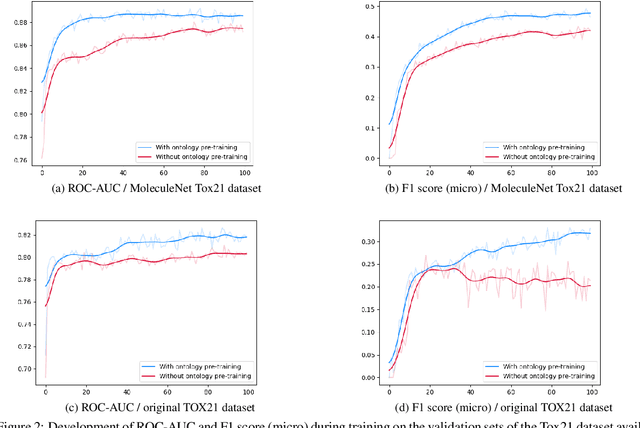
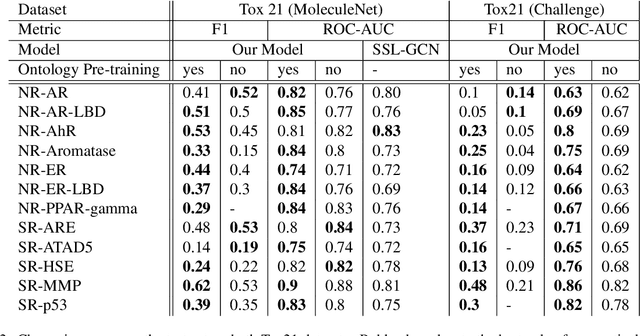
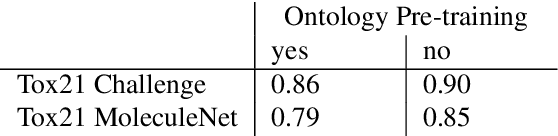
Integrating human knowledge into neural networks has the potential to improve their robustness and interpretability. We have developed a novel approach to integrate knowledge from ontologies into the structure of a Transformer network which we call ontology pre-training: we train the network to predict membership in ontology classes as a way to embed the structure of the ontology into the network, and subsequently fine-tune the network for the particular prediction task. We apply this approach to a case study in predicting the potential toxicity of a small molecule based on its molecular structure, a challenging task for machine learning in life sciences chemistry. Our approach improves on the state of the art, and moreover has several additional benefits. First, we are able to show that the model learns to focus attention on more meaningful chemical groups when making predictions with ontology pre-training than without, paving a path towards greater robustness and interpretability. Second, the training time is reduced after ontology pre-training, indicating that the model is better placed to learn what matters for toxicity prediction with the ontology pre-training than without. This strategy has general applicability as a neuro-symbolic approach to embed meaningful semantics into neural networks.
HiFlash: Communication-Efficient Hierarchical Federated Learning with Adaptive Staleness Control and Heterogeneity-aware Client-Edge Association
Jan 16, 2023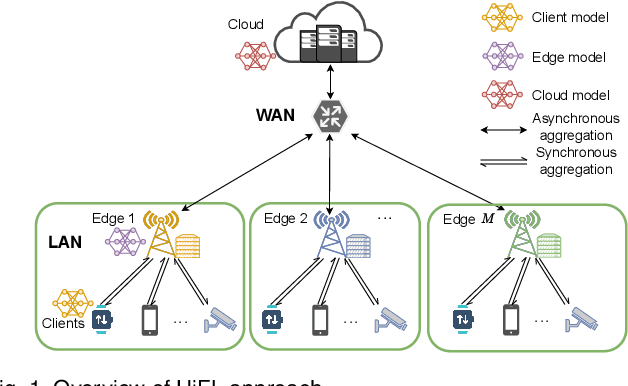

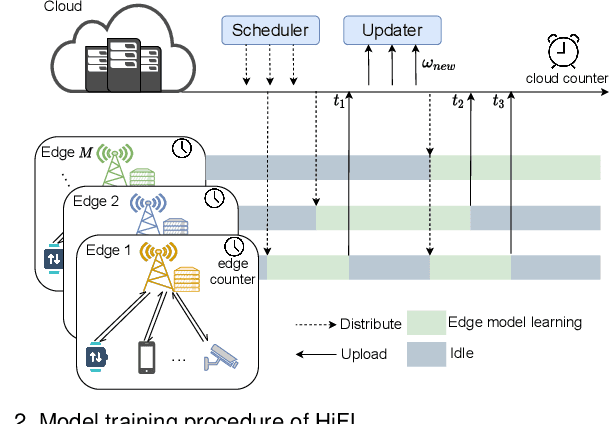
Federated learning (FL) is a promising paradigm that enables collaboratively learning a shared model across massive clients while keeping the training data locally. However, for many existing FL systems, clients need to frequently exchange model parameters of large data size with the remote cloud server directly via wide-area networks (WAN), leading to significant communication overhead and long transmission time. To mitigate the communication bottleneck, we resort to the hierarchical federated learning paradigm of HiFL, which reaps the benefits of mobile edge computing and combines synchronous client-edge model aggregation and asynchronous edge-cloud model aggregation together to greatly reduce the traffic volumes of WAN transmissions. Specifically, we first analyze the convergence bound of HiFL theoretically and identify the key controllable factors for model performance improvement. We then advocate an enhanced design of HiFlash by innovatively integrating deep reinforcement learning based adaptive staleness control and heterogeneity-aware client-edge association strategy to boost the system efficiency and mitigate the staleness effect without compromising model accuracy. Extensive experiments corroborate the superior performance of HiFlash in model accuracy, communication reduction, and system efficiency.
Deep-learning-based on-chip rapid spectral imaging with high spatial resolution
Jan 16, 2023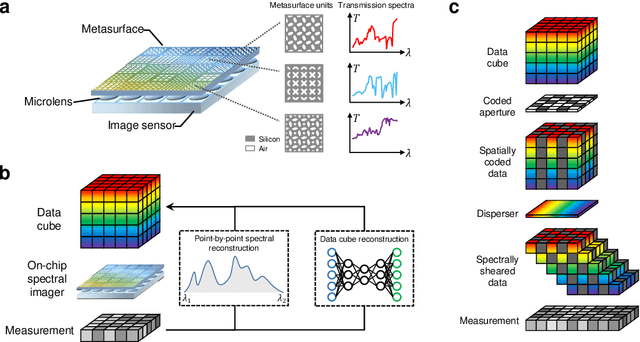
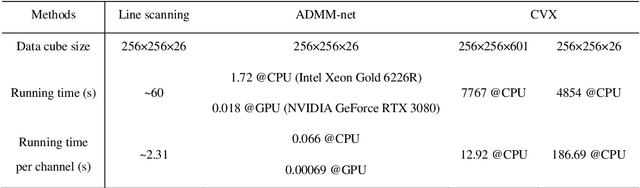
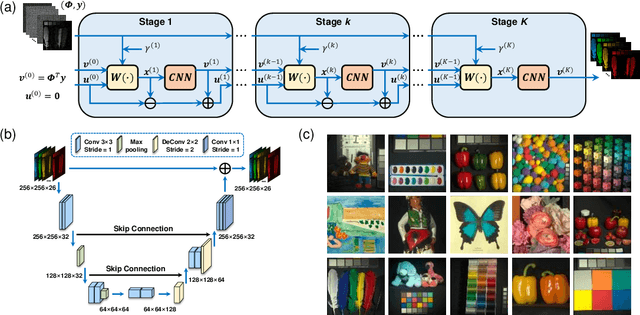
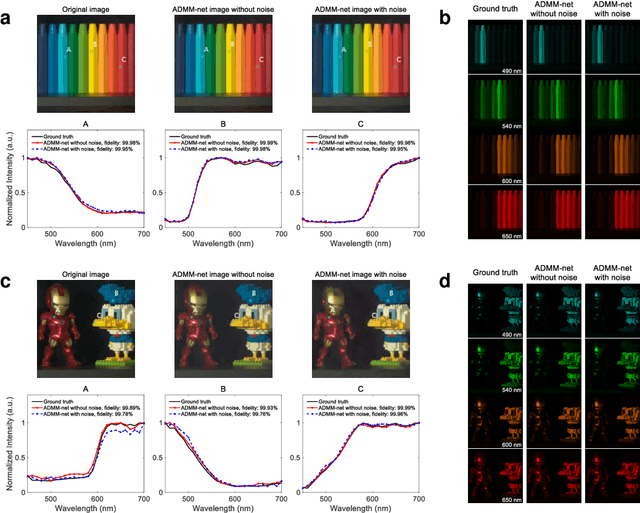
Spectral imaging extends the concept of traditional color cameras to capture images across multiple spectral channels and has broad application prospects. Conventional spectral cameras based on scanning methods suffer from low acquisition speed and large volume. On-chip computational spectral imaging based on metasurface filters provides a promising scheme for portable applications, but endures long computation time for point-by-point iterative spectral reconstruction and mosaic effect in the reconstructed spectral images. In this study, we demonstrated on-chip rapid spectral imaging eliminating the mosaic effect in the spectral image by deep-learning-based spectral data cube reconstruction. We experimentally achieved four orders of magnitude speed improvement than iterative spectral reconstruction and high fidelity of spectral reconstruction over 99% for a standard color board. In particular, we demonstrated video-rate spectral imaging for moving objects and outdoor driving scenes with good performance for recognizing metamerism, where the concolorous sky and white cars can be distinguished via their spectra, showing great potential for autonomous driving and other practical applications in the field of intelligent perception.