 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DRAformer: Differentially Reconstructed Attention Transformer for Time-Series Forecasting
Jun 11, 2022
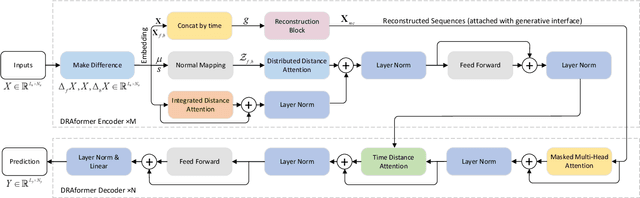
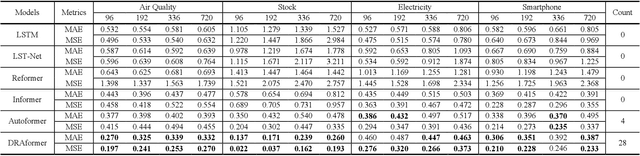
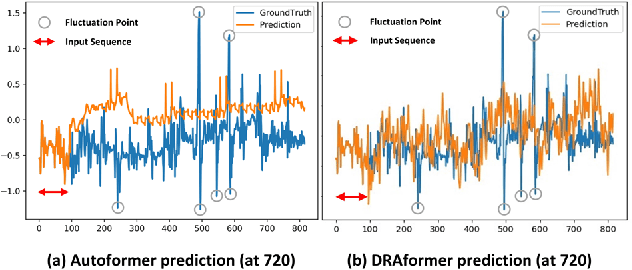

Time-series forecasting plays an important role in many real-world scenarios, such as equipment life cycle forecasting, weather forecasting, and traffic flow forecasting. It can be observed from recent research that a variety of transformer-based models have shown remarkable results in time-series forecasting. However, there are still some issues that limit the ability of transformer-based models on time-series forecasting tasks: (i) learning directly on raw data is susceptible to noise due to its complex and unstable feature representation; (ii) the self-attention mechanisms pay insufficient attention to changing features and temporal dependencies. In order to solve these two problems, we propose a transformer-based differentially reconstructed attention model DRAformer. Specifically, DRAformer has the following innovations: (i) learning against differenced sequences, which preserves clear and stable sequence features by differencing and highlights the changing properties of sequences; (ii) the reconstructed attention: integrated distance attention exhibits sequential distance through a learnable Gaussian kernel, distributed difference attention calculates distribution difference by mapping the difference sequence to the adaptive feature space, and the combination of the two effectively focuses on the sequences with prominent associations; (iii) the reconstructed decoder input, which extracts sequence features by integrating variation information and temporal correlations, thereby obtaining a more comprehensive sequence representation. Extensive experiments on four large-scale datasets demonstrate that DRAformer outperforms state-of-the-art baselines.
DSVT: Dynamic Sparse Voxel Transformer with Rotated Sets
Jan 15, 2023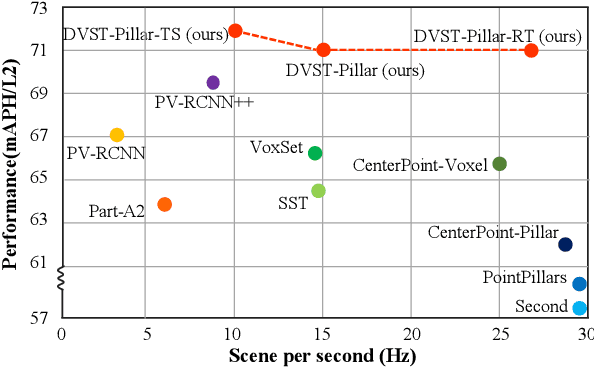
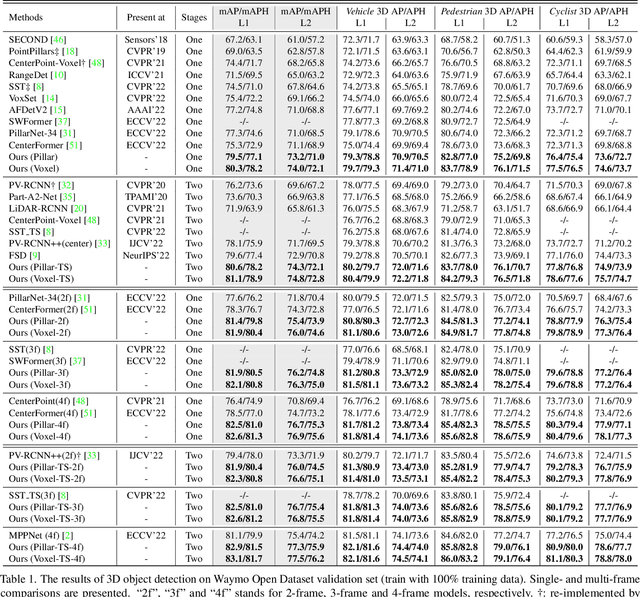
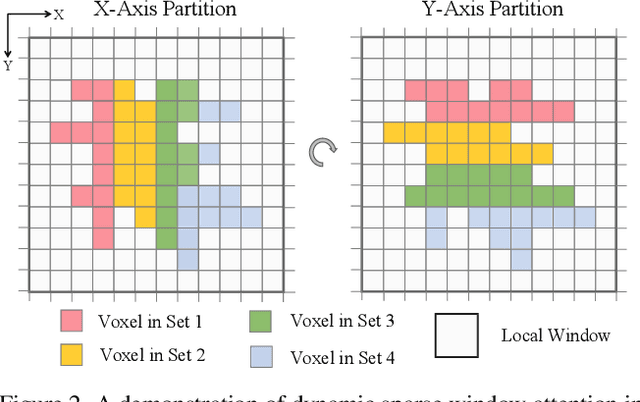
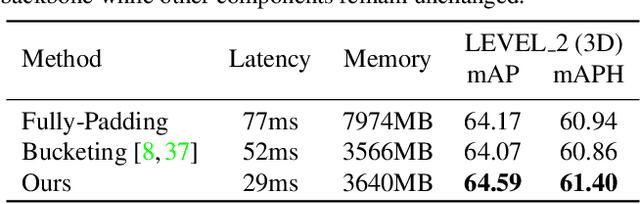
Designing an efficient yet deployment-friendly 3D backbone to handle sparse point clouds is a fundamental problem in 3D object detection. Compared with the customized sparse convolution, the attention mechanism in Transformers is more appropriate for flexibly modeling long-range relationships and is easier to be deployed in real-world applications. However, due to the sparse characteristics of point clouds, it is non-trivial to apply a standard transformer on sparse points. In this paper, we present Dynamic Sparse Voxel Transformer (DSVT), a single-stride window-based voxel Transformer backbone for outdoor 3D object detection. In order to efficiently process sparse points in parallel, we propose Dynamic Sparse Window Attention, which partitions a series of local regions in each window according to its sparsity and then computes the features of all regions in a fully parallel manner. To allow the cross-set connection, we design a rotated set partitioning strategy that alternates between two partitioning configurations in consecutive self-attention layers. To support effective downsampling and better encode geometric information, we also propose an attention-style 3D pooling module on sparse points, which is powerful and deployment-friendly without utilizing any customized CUDA operations. Our model achieves state-of-the-art performance on large-scale Waymo Open Dataset with remarkable gains. More importantly, DSVT can be easily deployed by TensorRT with real-time inference speed (27Hz). Code will be available at \url{https://github.com/Haiyang-W/DSVT}.
TextileNet: A Material Taxonomy-based Fashion Textile Dataset
Jan 15, 2023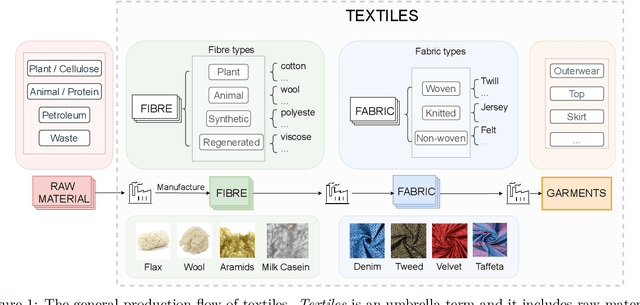
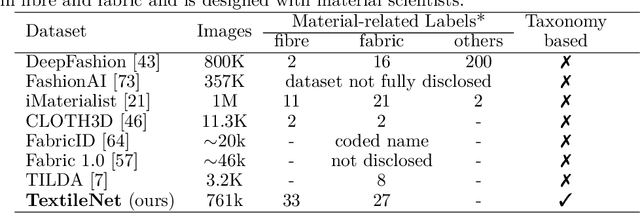
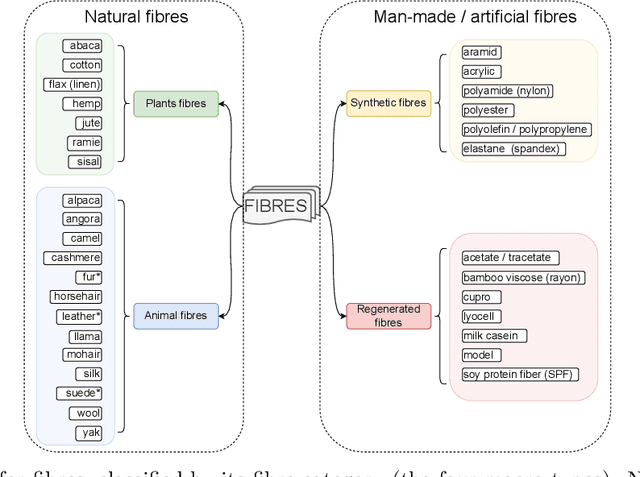

The rise of Machine Learning (ML) is gradually digitalizing and reshaping the fashion industry. Recent years have witnessed a number of fashion AI applications, for example, virtual try-ons. Textile material identification and categorization play a crucial role in the fashion textile sector, including fashion design, retails, and recycling. At the same time, Net Zero is a global goal and the fashion industry is undergoing a significant change so that textile materials can be reused, repaired and recycled in a sustainable manner. There is still a challenge in identifying textile materials automatically for garments, as we lack a low-cost and effective technique for identifying them. In light of this, we build the first fashion textile dataset, TextileNet, based on textile material taxonomies - a fibre taxonomy and a fabric taxonomy generated in collaboration with material scientists. TextileNet can be used to train and evaluate the state-of-the-art Deep Learning models for textile materials. We hope to standardize textile related datasets through the use of taxonomies. TextileNet contains 33 fibres labels and 27 fabrics labels, and has in total 760,949 images. We use standard Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) to establish baselines for this dataset. Future applications for this dataset range from textile classification to optimization of the textile supply chain and interactive design for consumers. We envision that this can contribute to the development of a new AI-based fashion platform.
Spatiotemporal Residual Regularization with Dynamic Mixtures for Traffic Forecasting
Dec 15, 2022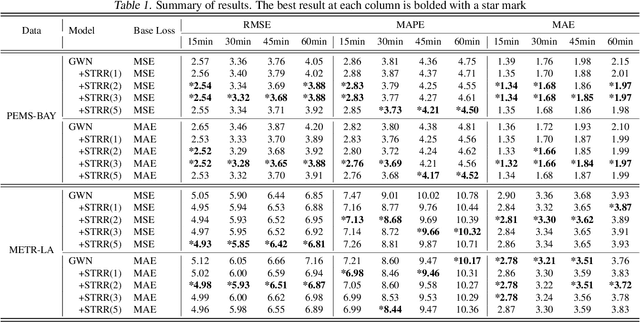
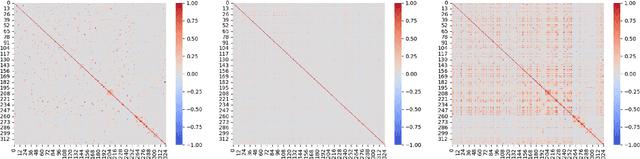
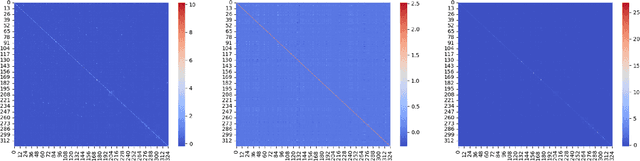
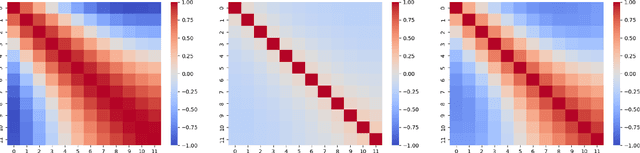
Existing deep learning-based traffic forecasting models are mainly trained with MSE (or MAE) as the loss function, assuming that residuals/errors follow independent and isotropic Gaussian (or Laplacian) distribution for simplicity. However, this assumption rarely holds for real-world traffic forecasting tasks, where the unexplained residuals are often correlated in both space and time. In this study, we propose Spatiotemporal Residual Regularization by modeling residuals with a dynamic (e.g., time-varying) mixture of zero-mean multivariate Gaussian distribution with learnable spatiotemporal covariance matrices. This approach allows us to directly capture spatiotemporally correlated residuals. For scalability, we model the spatiotemporal covariance for each mixture component using a Kronecker product structure, which significantly reduces the number of parameters and computation complexity. We evaluate the performance of the proposed method on a traffic speed forecasting task. Our results show that, by properly modeling residual distribution, the proposed method not only improves the model performance but also provides interpretable structures.
Safe Drone Flight with Time-Varying Backup Controllers
Jul 11, 2022
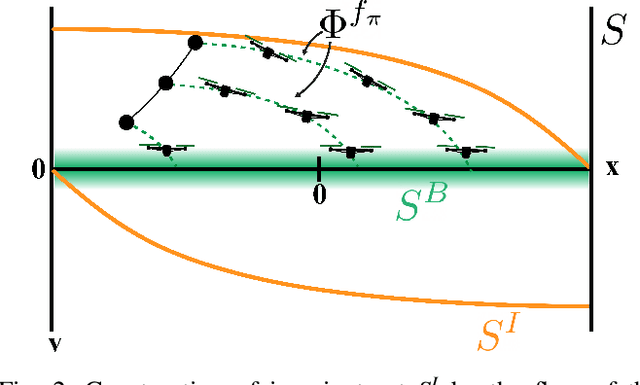
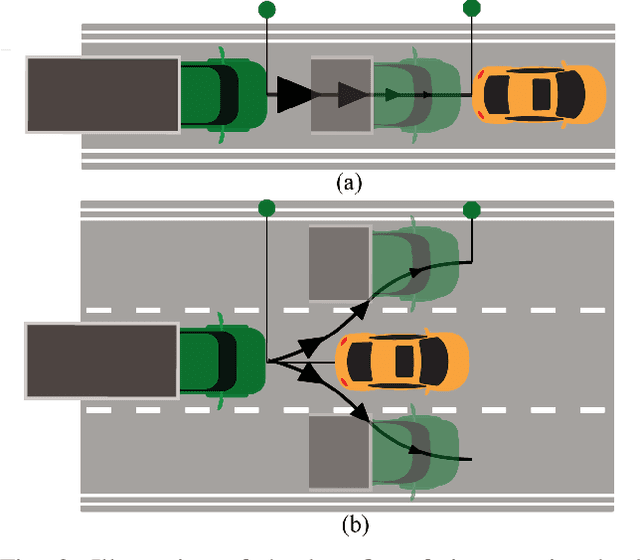
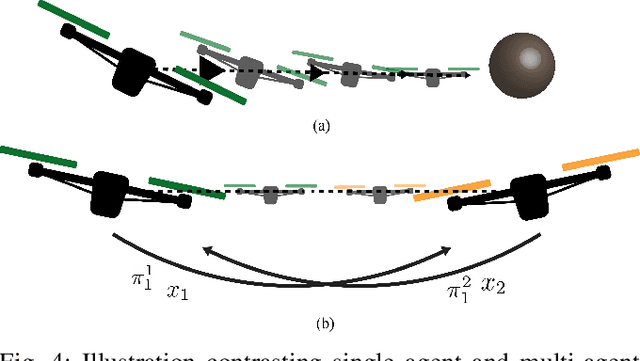
The weight, space, and power limitations of small aerial vehicles often prevent the application of modern control techniques without significant model simplifications. Moreover, high-speed agile behavior, such as that exhibited in drone racing, make these simplified models too unreliable for safety-critical control. In this work, we introduce the concept of time-varying backup controllers (TBCs): user-specified maneuvers combined with backup controllers that generate reference trajectories which guarantee the safety of nonlinear systems. TBCs reduce conservatism when compared to traditional backup controllers and can be directly applied to multi-agent coordination to guarantee safety. Theoretically, we provide conditions under which TBCs strictly reduce conservatism, describe how to switch between several TBC's and show how to embed TBCs in a multi-agent setting. Experimentally, we verify that TBCs safely increase operational freedom when filtering a pilot's actions and demonstrate robustness and computational efficiency when applied to decentralized safety filtering of two quadrotors.
The necessity of depth for artificial neural networks to approximate certain classes of smooth and bounded functions without the curse of dimensionality
Jan 19, 2023
In this article we study high-dimensional approximation capacities of shallow and deep artificial neural networks (ANNs) with the rectified linear unit (ReLU) activation. In particular, it is a key contribution of this work to reveal that for all $a,b\in\mathbb{R}$ with $b-a\geq 7$ we have that the functions $[a,b]^d\ni x=(x_1,\dots,x_d)\mapsto\prod_{i=1}^d x_i\in\mathbb{R}$ for $d\in\mathbb{N}$ as well as the functions $[a,b]^d\ni x =(x_1,\dots, x_d)\mapsto\sin(\prod_{i=1}^d x_i) \in \mathbb{R} $ for $ d \in \mathbb{N} $ can neither be approximated without the curse of dimensionality by means of shallow ANNs nor insufficiently deep ANNs with ReLU activation but can be approximated without the curse of dimensionality by sufficiently deep ANNs with ReLU activation. We show that the product functions and the sine of the product functions are polynomially tractable approximation problems among the approximating class of deep ReLU ANNs with the number of hidden layers being allowed to grow in the dimension $ d \in \mathbb{N} $. We establish the above outlined statements not only for the product functions and the sine of the product functions but also for other classes of target functions, in particular, for classes of uniformly globally bounded $ C^{ \infty } $-functions with compact support on any $[a,b]^d$ with $a\in\mathbb{R}$, $b\in(a,\infty)$. Roughly speaking, in this work we lay open that simple approximation problems such as approximating the sine or cosine of products cannot be solved in standard implementation frameworks by shallow or insufficiently deep ANNs with ReLU activation in polynomial time, but can be approximated by sufficiently deep ReLU ANNs with the number of parameters growing at most polynomially.
Pylon: Semantic Table Union Search in Data Lakes
Jan 13, 2023
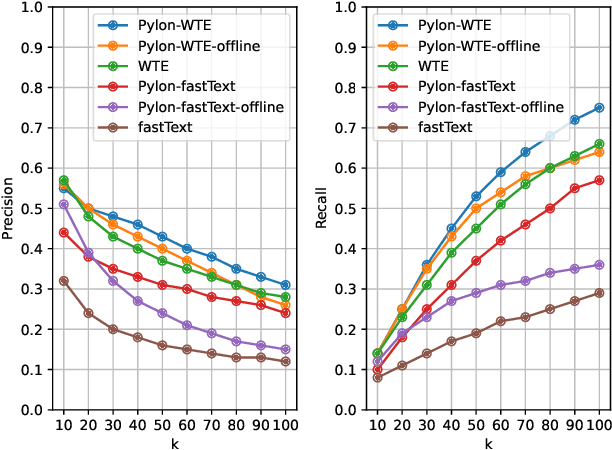
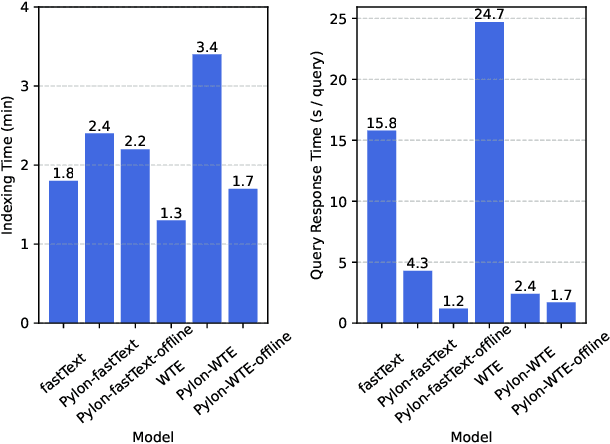
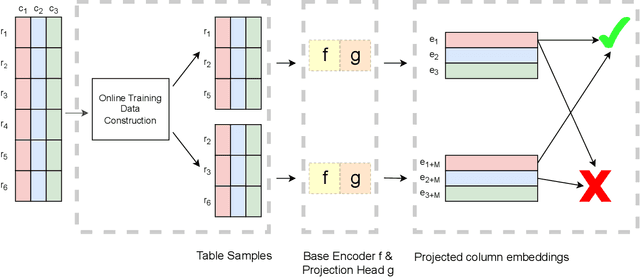
The large size and fast growth of data repositories, such as data lakes, has spurred the need for data discovery to help analysts find related data. The problem has become challenging as (i) a user typically does not know what datasets exist in an enormous data repository; and (ii) there is usually a lack of a unified data model to capture the interrelationships between heterogeneous datasets from disparate sources. In this work, we address one important class of discovery needs: finding union-able tables. The task is to find tables in a data lake that can be unioned with a given query table. The challenge is to recognize union-able columns even if they are represented differently. In this paper, we propose a data-driven learning approach: specifically, an unsupervised representation learning and embedding retrieval task. Our key idea is to exploit self-supervised contrastive learning to learn an embedding model that takes into account the indexing/search data structure and produces embeddings close by for columns with semantically similar values while pushing apart columns with semantically dissimilar values. We then find union-able tables based on similarities between their constituent columns in embedding space. On a real-world data lake, we demonstrate that our best-performing model achieves significant improvements in precision ($16\% \uparrow$), recall ($17\% \uparrow $), and query response time (7x faster) compared to the state-of-the-art.
Co-manipulation of soft-materials estimating deformation from depth images
Jan 13, 2023

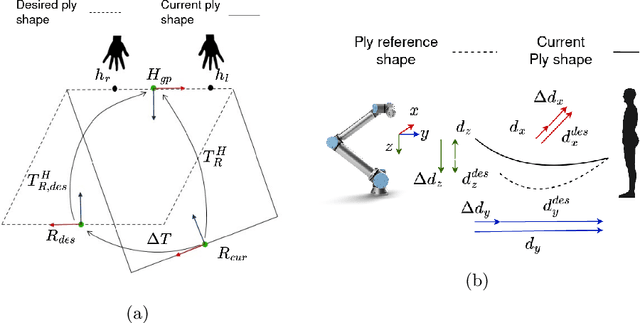
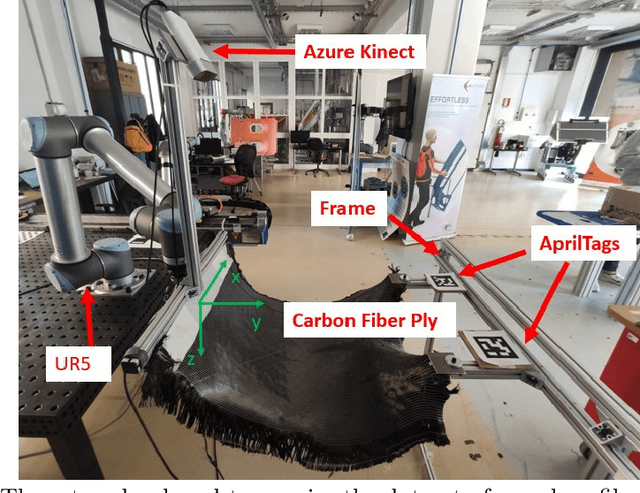
Human-robot co-manipulation of soft materials, such as fabrics, composites, and sheets of paper/cardboard, is a challenging operation that presents several relevant industrial applications. Estimating the deformation state of the co-manipulated material is one of the main challenges. Viable methods provide the indirect measure by calculating the human-robot relative distance. In this paper, we develop a data-driven model to estimate the deformation state of the material from a depth image through a Convolutional Neural Network (CNN). First, we define the deformation state of the material as the relative roto-translation from the current robot pose and a human grasping position. The model estimates the current deformation state through a Convolutional Neural Network, specifically a DenseNet-121 pretrained on ImageNet.The delta between the current and the desired deformation state is fed to the robot controller that outputs twist commands. The paper describes the developed approach to acquire, preprocess the dataset and train the model. The model is compared with the current state-of-the-art method based on a skeletal tracker from cameras. Results show that our approach achieves better performances and avoids the various drawbacks caused by using a skeletal tracker.Finally, we also studied the model performance according to different architectures and dataset dimensions to minimize the time required for dataset acquisition
RAMP: A Flat Nanosecond Optical Network and MPI Operations for Distributed Deep Learning Systems
Nov 28, 2022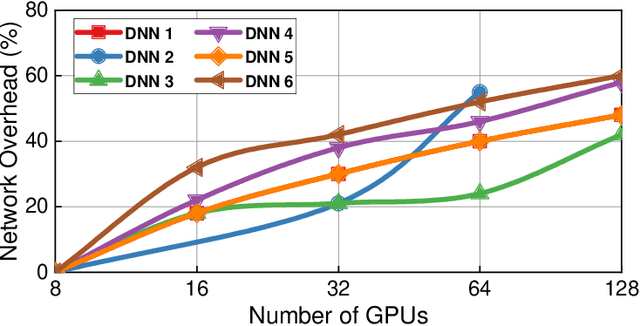
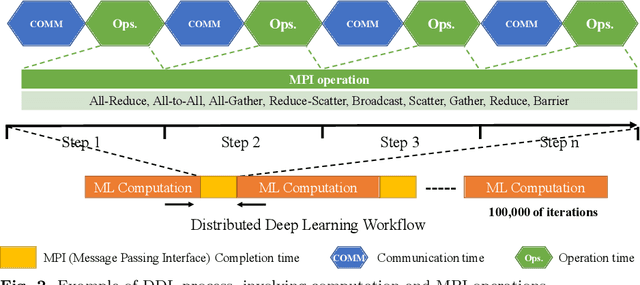
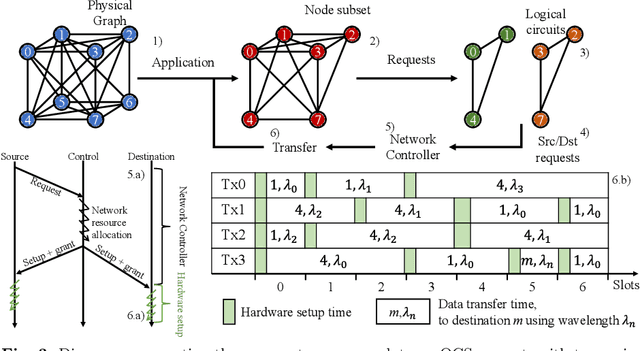
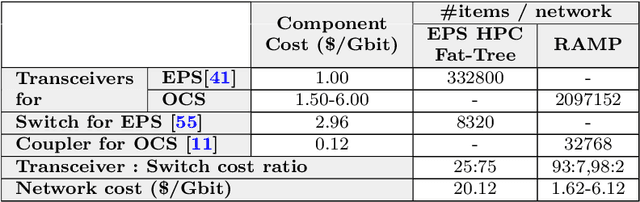
Distributed deep learning (DDL) systems strongly depend on network performance. Current electronic packet switched (EPS) network architectures and technologies suffer from variable diameter topologies, low-bisection bandwidth and over-subscription affecting completion time of communication and collective operations. We introduce a near-exascale, full-bisection bandwidth, all-to-all, single-hop, all-optical network architecture with nanosecond reconfiguration called RAMP, which supports large-scale distributed and parallel computing systems (12.8~Tbps per node for up to 65,536 nodes). For the first time, a custom RAMP-x MPI strategy and a network transcoder is proposed to run MPI collective operations across the optical circuit switched (OCS) network in a schedule-less and contention-less manner. RAMP achieves 7.6-171$\times$ speed-up in completion time across all MPI operations compared to realistic EPS and OCS counterparts. It can also deliver a 1.3-16$\times$ and 7.8-58$\times$ reduction in Megatron and DLRM training time respectively} while offering 42-53$\times$ and 3.3-12.4$\times$ improvement in energy consumption and cost respectively.
Multistep Multiappliance Load Prediction
Dec 19, 2022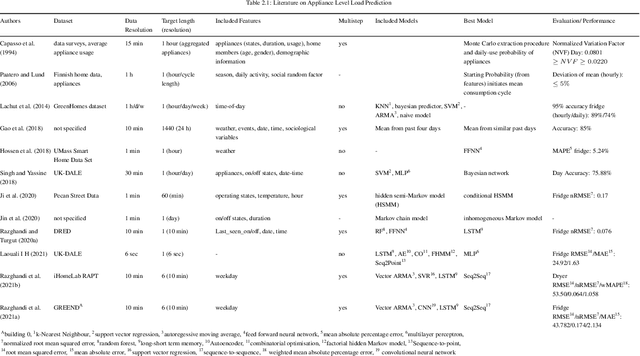
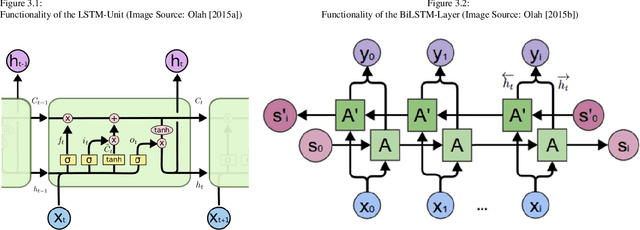
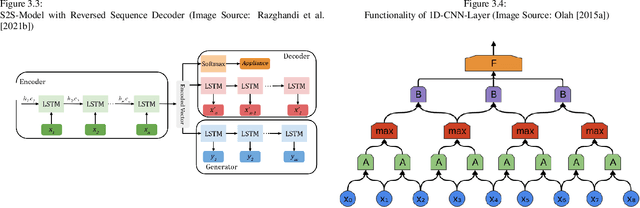
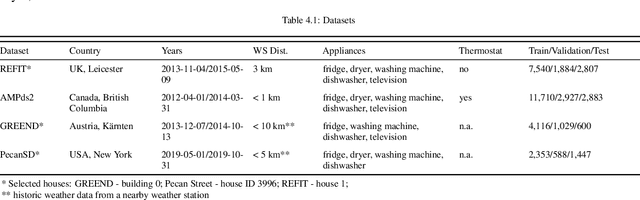
A well-performing prediction model is vital for a recommendation system suggesting actions for energy-efficient consumer behavior. However, reliable and accurate predictions depend on informative features and a suitable model design to perform well and robustly across different households and appliances. Moreover, customers' unjustifiably high expectations of accurate predictions may discourage them from using the system in the long term. In this paper, we design a three-step forecasting framework to assess predictability, engineering features, and deep learning architectures to forecast 24 hourly load values. First, our predictability analysis provides a tool for expectation management to cushion customers' anticipations. Second, we design several new weather-, time- and appliance-related parameters for the modeling procedure and test their contribution to the model's prediction performance. Third, we examine six deep learning techniques and compare them to tree- and support vector regression benchmarks. We develop a robust and accurate model for the appliance-level load prediction based on four datasets from four different regions (US, UK, Austria, and Canada) with an equal set of appliances. The empirical results show that cyclical encoding of time features and weather indicators alongside a long-short term memory (LSTM) model offer the optimal performance.