 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Combinatorial Semi-Bandit Approach to Charging Station Selection for Electric Vehicles
Jan 17, 2023
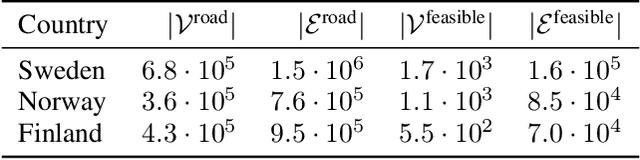
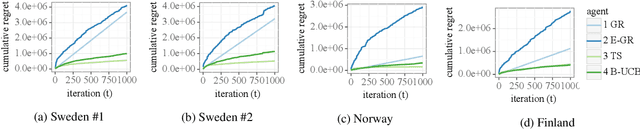

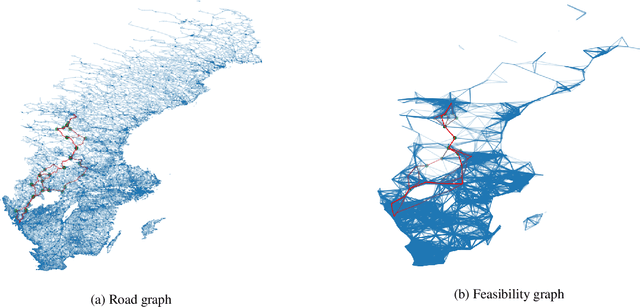
In this work, we address the problem of long-distance navigation for battery electric vehicles (BEVs), where one or more charging sessions are required to reach the intended destination. We consider the availability and performance of the charging stations to be unknown and stochastic, and develop a combinatorial semi-bandit framework for exploring the road network to learn the parameters of the queue time and charging power distributions. Within this framework, we first outline a pre-processing for the road network graph to handle the constrained combinatorial optimization problem in an efficient way. Then, for the pre-processed graph, we use a Bayesian approach to model the stochastic edge weights, utilizing conjugate priors for the one-parameter exponential and two-parameter gamma distributions, the latter of which is novel to multi-armed bandit literature. Finally, we apply combinatorial versions of Thompson Sampling, BayesUCB and Epsilon-greedy to the problem. We demonstrate the performance of our framework on long-distance navigation problem instances in country-sized road networks, with simulation experiments in Norway, Sweden and Finland.
Lowering Detection in Sport Climbing Based on Orientation of the Sensor Enhanced Quickdraw
Jan 17, 2023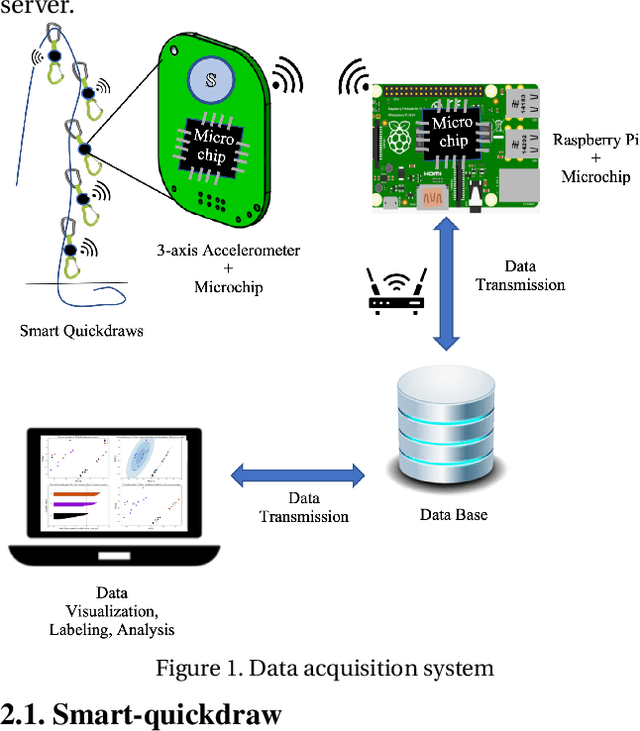
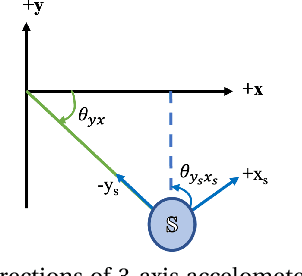
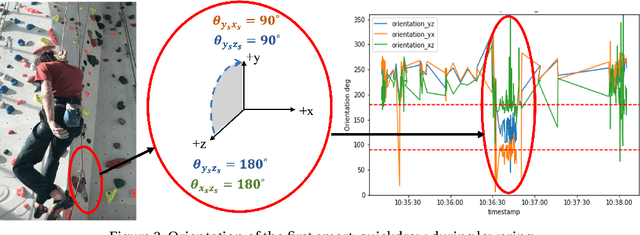
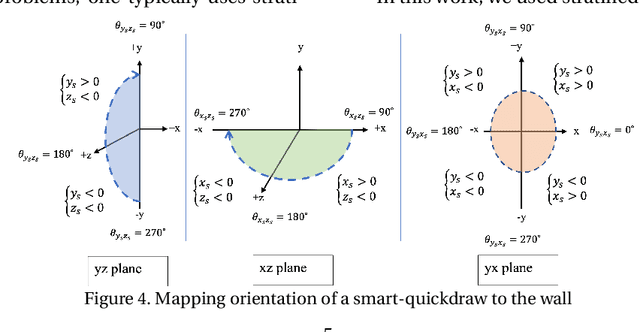
Tracking climbers' activity to improve services and make the best use of their infrastructure is a concern for climbing gyms. Each climbing session must be analyzed from beginning till lowering of the climber. Therefore, spotting the climbers descending is crucial since it indicates when the ascent has come to an end. This problem must be addressed while preserving privacy and convenience of the climbers and the costs of the gyms. To this aim, a hardware prototype is developed to collect data using accelerometer sensors attached to a piece of climbing equipment mounted on the wall, called quickdraw, that connects the climbing rope to the bolt anchors. The corresponding sensors are configured to be energy-efficient, hence become practical in terms of expenses and time consumption for replacement when using in large quantity in a climbing gym. This paper describes hardware specifications, studies data measured by the sensors in ultra-low power mode, detect sensors' orientation patterns during lowering different routes, and develop an supervised approach to identify lowering.
Look, Listen, and Attack: Backdoor Attacks Against Video Action Recognition
Jan 19, 2023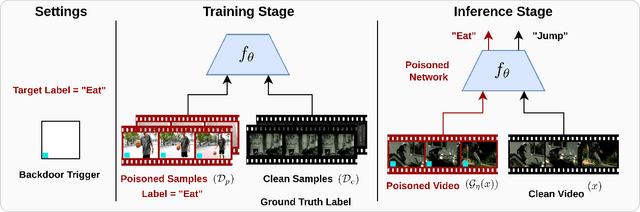
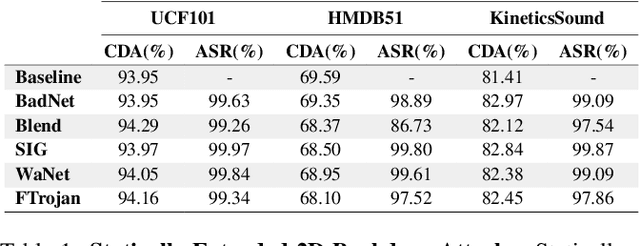

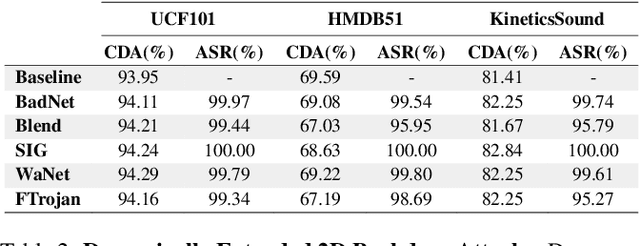
Deep neural networks (DNNs) are vulnerable to a class of attacks called "backdoor attacks", which create an association between a backdoor trigger and a target label the attacker is interested in exploiting. A backdoored DNN performs well on clean test images, yet persistently predicts an attacker-defined label for any sample in the presence of the backdoor trigger. Although backdoor attacks have been extensively studied in the image domain, there are very few works that explore such attacks in the video domain, and they tend to conclude that image backdoor attacks are less effective in the video domain. In this work, we revisit the traditional backdoor threat model and incorporate additional video-related aspects to that model. We show that poisoned-label image backdoor attacks could be extended temporally in two ways, statically and dynamically, leading to highly effective attacks in the video domain. In addition, we explore natural video backdoors to highlight the seriousness of this vulnerability in the video domain. And, for the first time, we study multi-modal (audiovisual) backdoor attacks against video action recognition models, where we show that attacking a single modality is enough for achieving a high attack success rate.
Blind as a bat: audible echolocation on small robots
Jan 19, 2023
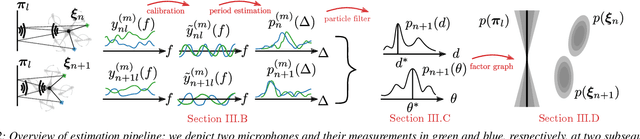
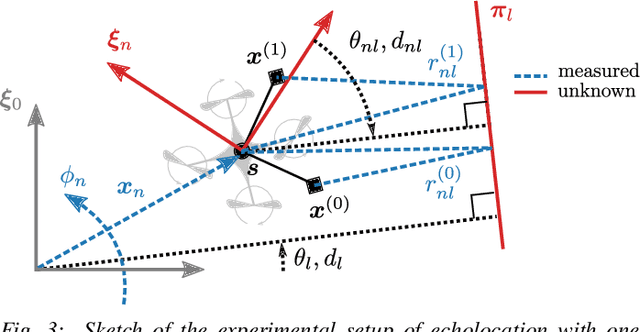
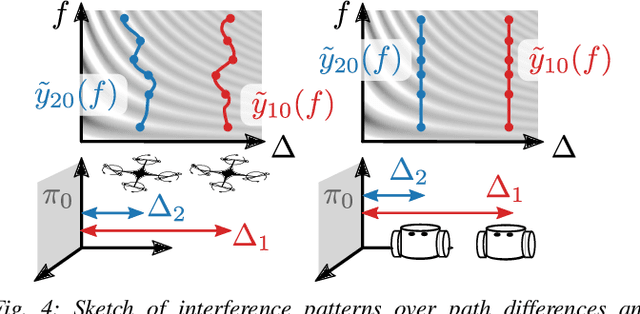
For safe and efficient operation, mobile robots need to perceive their environment, and in particular, perform tasks such as obstacle detection, localization, and mapping. Although robots are often equipped with microphones and speakers, the audio modality is rarely used for these tasks. Compared to the localization of sound sources, for which many practical solutions exist, algorithms for active echolocation are less developed and often rely on hardware requirements that are out of reach for small robots. We propose an end-to-end pipeline for sound-based localization and mapping that is targeted at, but not limited to, robots equipped with only simple buzzers and low-end microphones. The method is model-based, runs in real time, and requires no prior calibration or training. We successfully test the algorithm on the e-puck robot with its integrated audio hardware, and on the Crazyflie drone, for which we design a reproducible audio extension deck. We achieve centimeter-level wall localization on both platforms when the robots are static during the measurement process. Even in the more challenging setting of a flying drone, we can successfully localize walls, which we demonstrate in a proof-of-concept multi-wall localization and mapping demo.
Interval Reachability of Nonlinear Dynamical Systems with Neural Network Controllers
Jan 19, 2023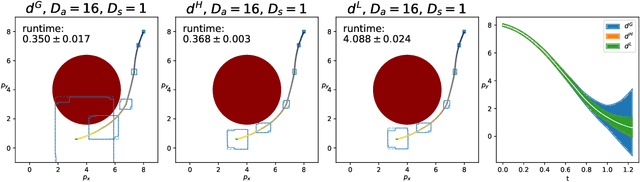
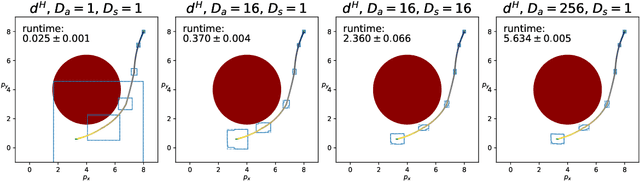
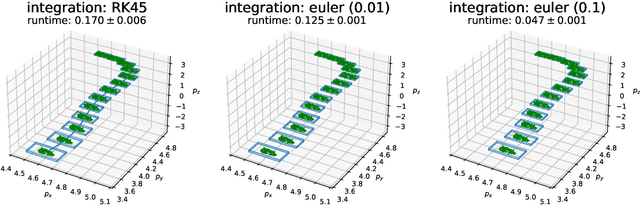
This paper proposes a computationally efficient framework, based on interval analysis, for rigorous verification of nonlinear continuous-time dynamical systems with neural network controllers. Given a neural network, we use an existing verification algorithm to construct inclusion functions for its input-output behavior. Inspired by mixed monotone theory, we embed the closed-loop dynamics into a larger system using an inclusion function of the neural network and a decomposition function of the open-loop system. This embedding provides a scalable approach for safety analysis of the neural control loop while preserving the nonlinear structure of the system. We show that one can efficiently compute hyper-rectangular over-approximations of the reachable sets using a single trajectory of the embedding system. We design an algorithm to leverage this computational advantage through partitioning strategies, improving our reachable set estimates while balancing its runtime with tunable parameters. We demonstrate the performance of this algorithm through two case studies. First, we demonstrate this method's strength in complex nonlinear environments. Then, we show that our approach matches the performance of the state-of-the art verification algorithm for linear discretized systems.
Estimating Remaining Lifespan from the Face
Jan 19, 2023
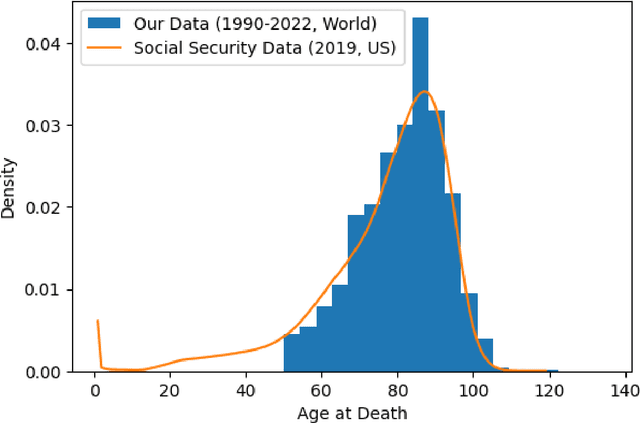

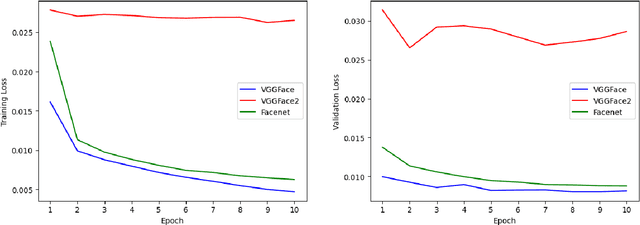
The face is a rich source of information that can be utilized to infer a person's biological age, sex, phenotype, genetic defects, and health status. All of these factors are relevant for predicting an individual's remaining lifespan. In this study, we collected a dataset of over 24,000 images (from Wikidata/Wikipedia) of individuals who died of natural causes, along with the number of years between when the image was taken and when the person passed away. We made this dataset publicly available. We fine-tuned multiple Convolutional Neural Network (CNN) models on this data, at best achieving a mean absolute error of 8.3 years in the validation data using VGGFace. However, the model's performance diminishes when the person was younger at the time of the image. To demonstrate the potential applications of our remaining lifespan model, we present examples of using it to estimate the average loss of life (in years) due to the COVID-19 pandemic and to predict the increase in life expectancy that might result from a health intervention such as weight loss. Additionally, we discuss the ethical considerations associated with such models.
From English to More Languages: Parameter-Efficient Model Reprogramming for Cross-Lingual Speech Recognition
Jan 19, 2023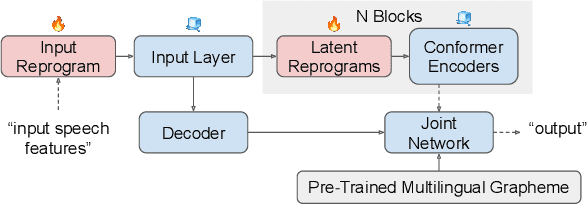

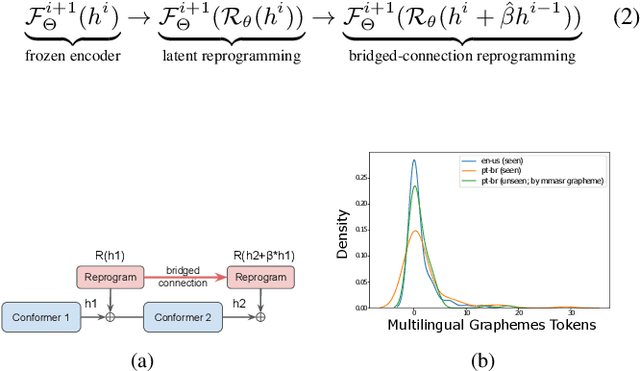
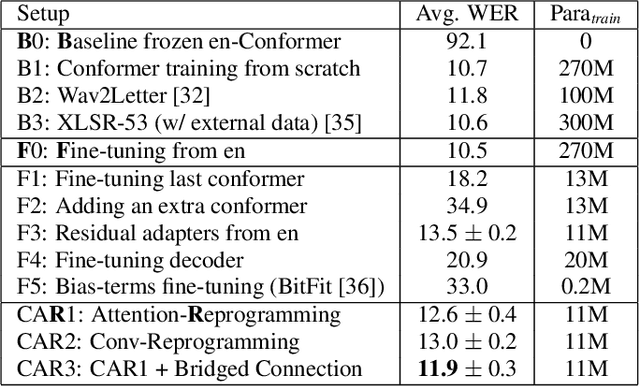
In this work, we propose a new parameter-efficient learning framework based on neural model reprogramming for cross-lingual speech recognition, which can \textbf{re-purpose} well-trained English automatic speech recognition (ASR) models to recognize the other languages. We design different auxiliary neural architectures focusing on learnable pre-trained feature enhancement that, for the first time, empowers model reprogramming on ASR. Specifically, we investigate how to select trainable components (i.e., encoder) of a conformer-based RNN-Transducer, as a frozen pre-trained backbone. Experiments on a seven-language multilingual LibriSpeech speech (MLS) task show that model reprogramming only requires 4.2% (11M out of 270M) to 6.8% (45M out of 660M) of its original trainable parameters from a full ASR model to perform competitive results in a range of 11.9% to 8.1% WER averaged across different languages. In addition, we discover different setups to make large-scale pre-trained ASR succeed in both monolingual and multilingual speech recognition. Our methods outperform existing ASR tuning architectures and their extension with self-supervised losses (e.g., w2v-bert) in terms of lower WER and better training efficiency.
Sparse Graph Learning for Spatiotemporal Time Series
May 26, 2022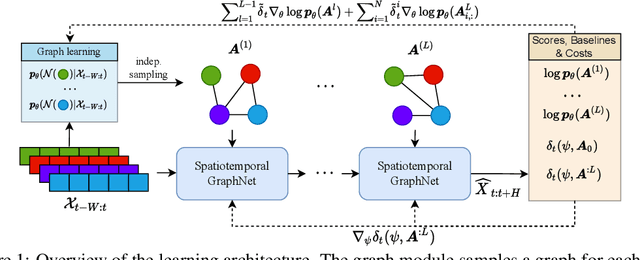
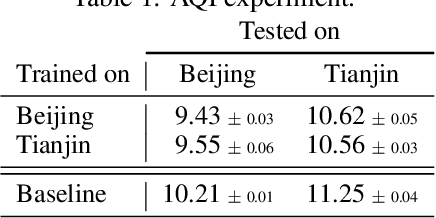
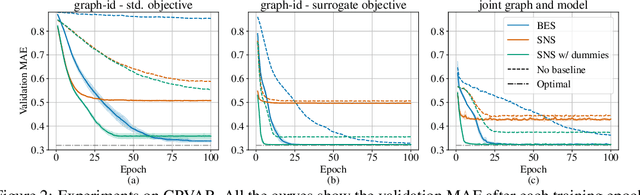
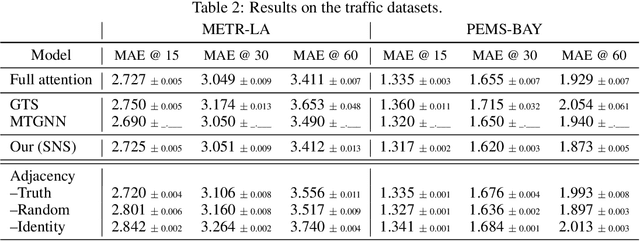
Outstanding achievements of graph neural networks for spatiotemporal time series prediction show that relational constraints introduce a positive inductive bias into neural forecasting architectures. Often, however, the relational information characterizing the underlying data generating process is unavailable; the practitioner is then left with the problem of inferring from data which relational graph to use in the subsequent processing stages. We propose novel, principled -- yet practical -- probabilistic methods that learn the relational dependencies by modeling distributions over graphs while maximizing, at the same time, end-to-end the forecasting accuracy. Our novel graph learning approach, based on consolidated variance reduction techniques for Monte Carlo score-based gradient estimation, is theoretically grounded and effective. We show that tailoring the gradient estimators to the graph learning problem allows us also for achieving state-of-the-art forecasting performance while controlling, at the same time, both the sparsity of the learned graph and the computational burden. We empirically assess the effectiveness of the proposed method on synthetic and real-world benchmarks, showing that the proposed solution can be used as a stand-alone graph identification procedure as well as a learned component of an end-to-end forecasting architecture.
Facial Misrecognition Systems: Simple Weight Manipulations Force DNNs to Err Only on Specific Persons
Jan 08, 2023
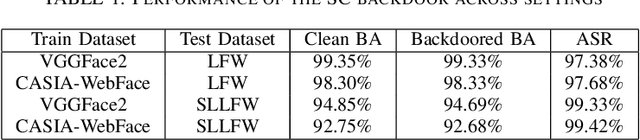
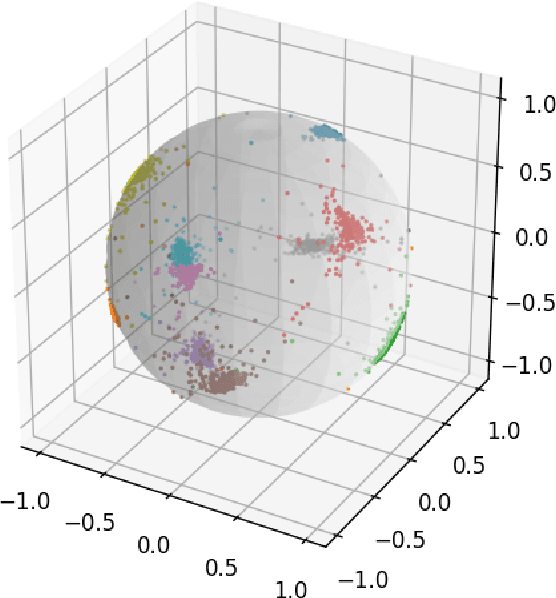
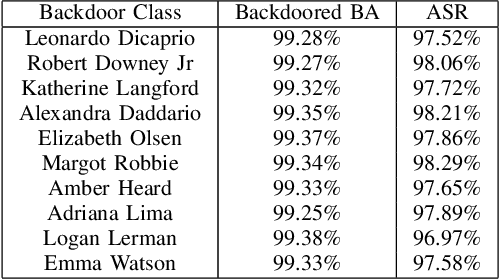
In this paper we describe how to plant novel types of backdoors in any facial recognition model based on the popular architecture of deep Siamese neural networks, by mathematically changing a small fraction of its weights (i.e., without using any additional training or optimization). These backdoors force the system to err only on specific persons which are preselected by the attacker. For example, we show how such a backdoored system can take any two images of a particular person and decide that they represent different persons (an anonymity attack), or take any two images of a particular pair of persons and decide that they represent the same person (a confusion attack), with almost no effect on the correctness of its decisions for other persons. Uniquely, we show that multiple backdoors can be independently installed by multiple attackers who may not be aware of each other's existence with almost no interference. We have experimentally verified the attacks on a FaceNet-based facial recognition system, which achieves SOTA accuracy on the standard LFW dataset of $99.35\%$. When we tried to individually anonymize ten celebrities, the network failed to recognize two of their images as being the same person in $96.97\%$ to $98.29\%$ of the time. When we tried to confuse between the extremely different looking Morgan Freeman and Scarlett Johansson, for example, their images were declared to be the same person in $91.51 \%$ of the time. For each type of backdoor, we sequentially installed multiple backdoors with minimal effect on the performance of each one (for example, anonymizing all ten celebrities on the same model reduced the success rate for each celebrity by no more than $0.91\%$). In all of our experiments, the benign accuracy of the network on other persons was degraded by no more than $0.48\%$ (and in most cases, it remained above $99.30\%$).
Simulation-Informed Revenue Extrapolation with Confidence Estimate for Scaleup Companies Using Scarce Time-Series Data
Aug 23, 2022
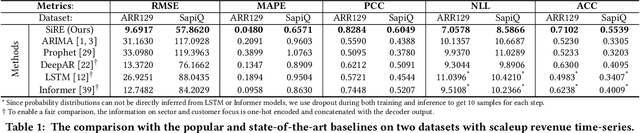
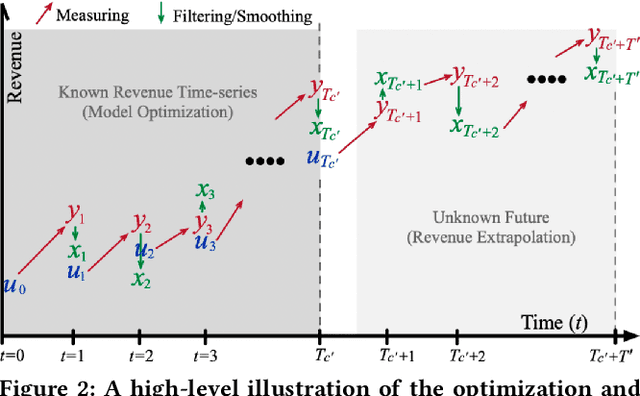
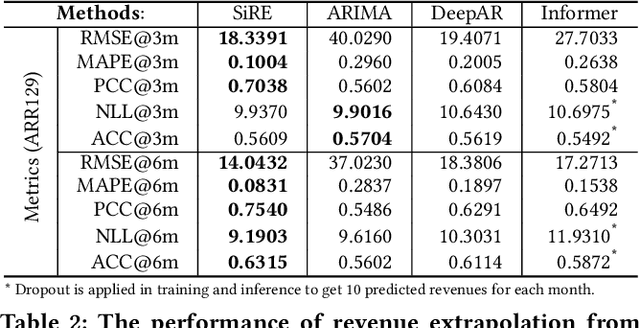
Investment professionals rely on extrapolating company revenue into the future (i.e. revenue forecast) to approximate the valuation of scaleups (private companies in a high-growth stage) and inform their investment decision. This task is manual and empirical, leaving the forecast quality heavily dependent on the investment professionals' experiences and insights. Furthermore, financial data on scaleups is typically proprietary, costly and scarce, ruling out the wide adoption of data-driven approaches. To this end, we propose a simulation-informed revenue extrapolation (SiRE) algorithm that generates fine-grained long-term revenue predictions on small datasets and short time-series. SiRE models the revenue dynamics as a linear dynamical system (LDS), which is solved using the EM algorithm. The main innovation lies in how the noisy revenue measurements are obtained during training and inferencing. SiRE works for scaleups that operate in various sectors and provides confidence estimates. The quantitative experiments on two practical tasks show that SiRE significantly surpasses the baseline methods by a large margin. We also observe high performance when SiRE extrapolates long-term predictions from short time-series. The performance-efficiency balance and result explainability of SiRE are also validated empirically. Evaluated from the perspective of investment professionals, SiRE can precisely locate the scaleups that have a great potential return in 2 to 5 years. Furthermore, our qualitative inspection illustrates some advantageous attributes of the SiRE revenue forecasts.