 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Conformal prediction set for time-series
Jun 15, 2022
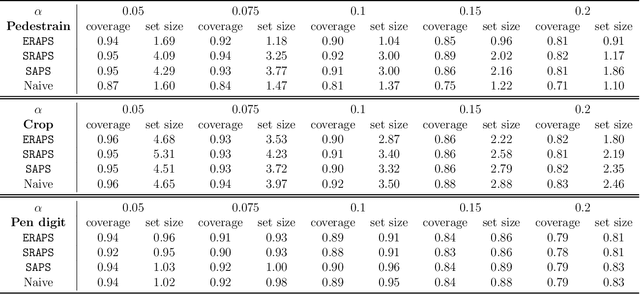
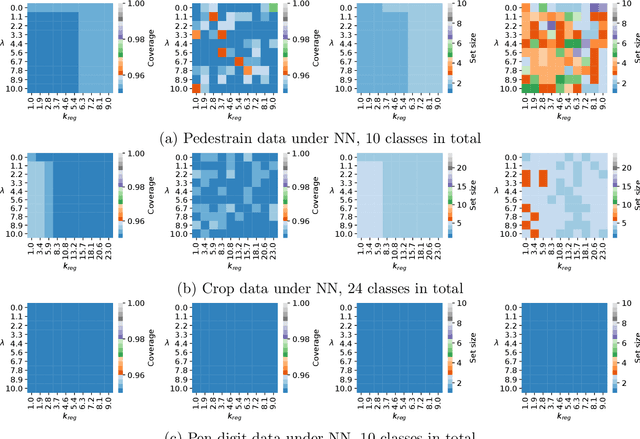
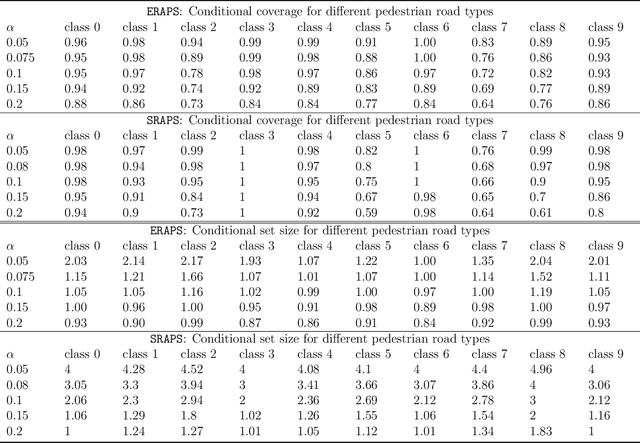
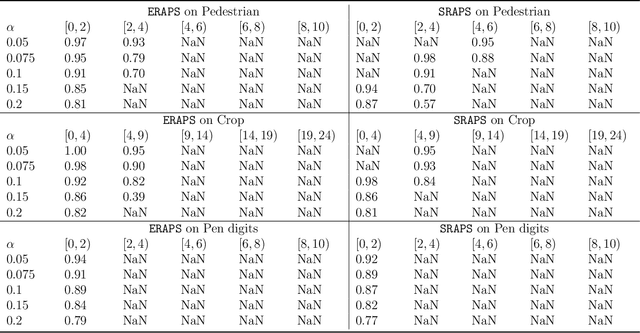
When building either prediction intervals for regression (with real-valued response) or prediction sets for classification (with categorical responses), uncertainty quantification is essential to studying complex machine learning methods. In this paper, we develop Ensemble Regularized Adaptive Prediction Set (ERAPS) to construct prediction sets for time-series (with categorical responses), based on the prior work of [Xu and Xie, 2021]. In particular, we allow unknown dependencies to exist within features and responses that arrive in sequence. Method-wise, ERAPS is a distribution-free and ensemble-based framework that is applicable for arbitrary classifiers. Theoretically, we bound the coverage gap without assuming data exchangeability and show asymptotic set convergence. Empirically, we demonstrate valid marginal and conditional coverage by ERAPS, which also tends to yield smaller prediction sets than competing methods.
Predicting Future Mosquito Habitats Using Time Series Climate Forecasting and Deep Learning
Aug 01, 2022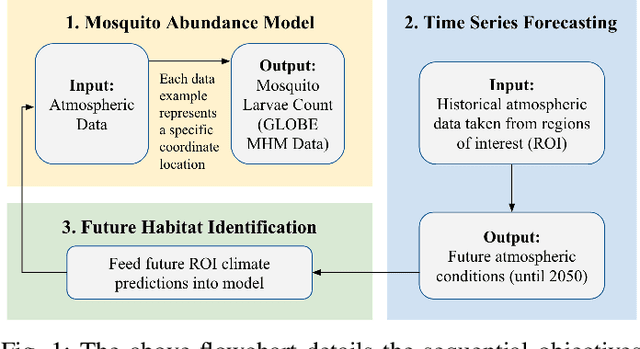
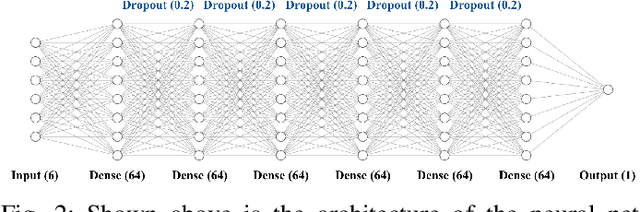
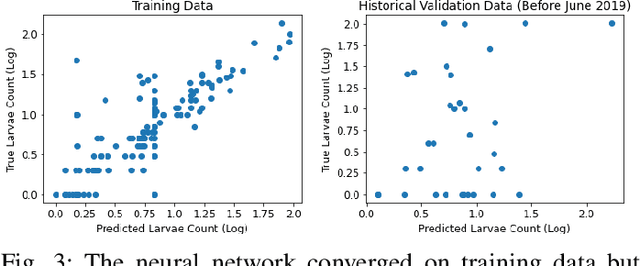
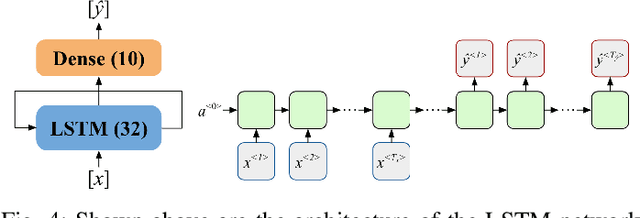
Mosquito habitat ranges are projected to expand due to climate change. This investigation aims to identify future mosquito habitats by analyzing preferred ecological conditions of mosquito larvae. After assembling a data set with atmospheric records and larvae observations, a neural network is trained to predict larvae counts from ecological inputs. Time series forecasting is conducted on these variables and climate projections are passed into the initial deep learning model to generate location-specific larvae abundance predictions. The results support the notion of regional ecosystem-driven changes in mosquito spread, with high-elevation regions in particular experiencing an increase in susceptibility to mosquito infestation.
Unsupervised Deep Learning for AC Optimal Power Flow via Lagrangian Duality
Dec 07, 2022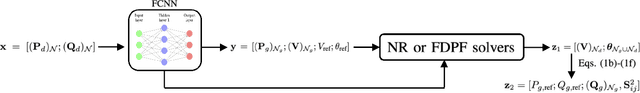
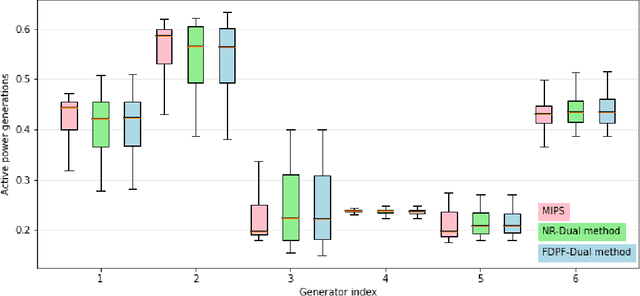
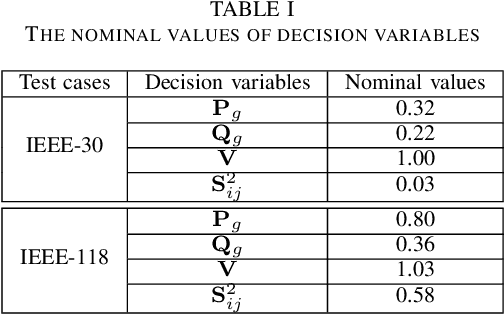
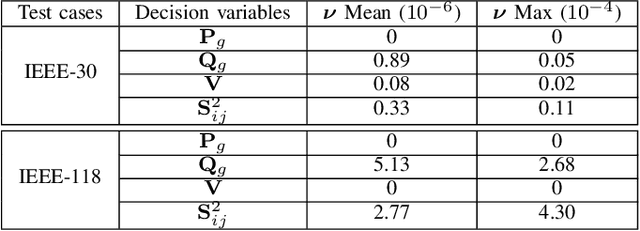
Non-convex AC optimal power flow (AC-OPF) is a fundamental optimization problem in power system analysis. The computational complexity of conventional solvers is typically high and not suitable for large-scale networks in real-time operation. Hence, deep learning based approaches have gained intensive attention to conduct the time-consuming training process offline. Supervised learning methods may yield a feasible AC-OPF solution with a small optimality gap. However, they often need conventional solvers to generate the training dataset. This paper proposes an end-to-end unsupervised learning based framework for AC-OPF. We develop a deep neural network to output a partial set of decision variables while the remaining variables are recovered by solving AC power flow equations. The fast decoupled power flow solver is adopted to further reduce the computational time. In addition, we propose using a modified augmented Lagrangian function as the training loss. The multipliers are adjusted dynamically based on the degree of constraint violation. Extensive numerical test results corroborate the advantages of our proposed approach over some existing methods.
Learning-Assisted Algorithm Unrolling for Online Optimization with Budget Constraints
Dec 03, 2022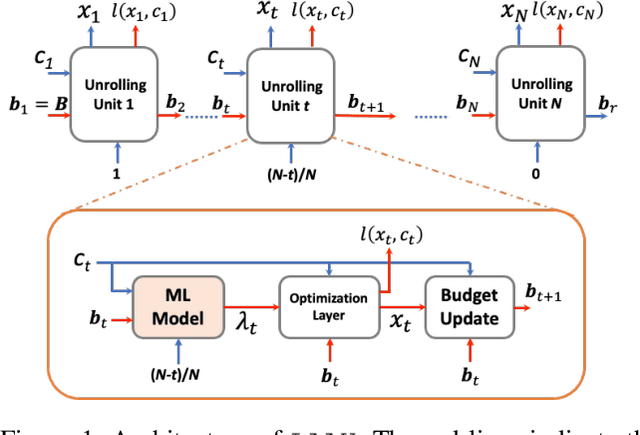
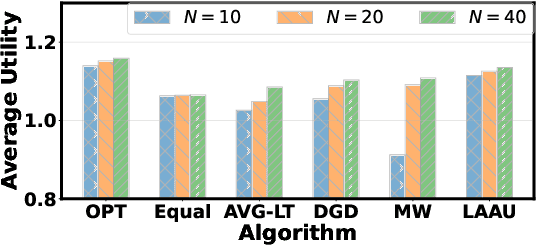
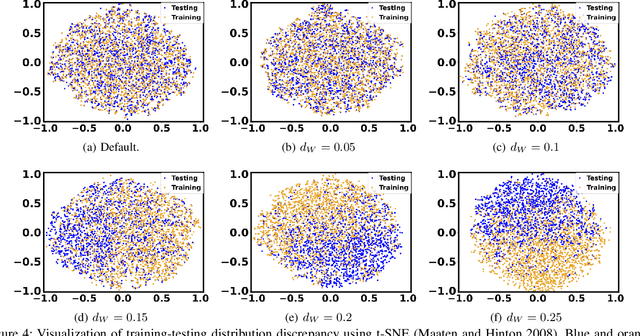
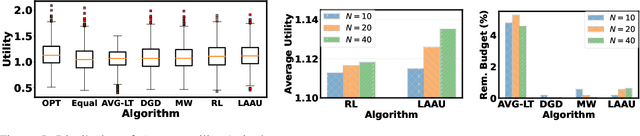
Online optimization with multiple budget constraints is challenging since the online decisions over a short time horizon are coupled together by strict inventory constraints. The existing manually-designed algorithms cannot achieve satisfactory average performance for this setting because they often need a large number of time steps for convergence and/or may violate the inventory constraints. In this paper, we propose a new machine learning (ML) assisted unrolling approach, called LAAU (Learning-Assisted Algorithm Unrolling), which unrolls the online decision pipeline and leverages an ML model for updating the Lagrangian multiplier online. For efficient training via backpropagation, we derive gradients of the decision pipeline over time. We also provide the average cost bounds for two cases when training data is available offline and collected online, respectively. Finally, we present numerical results to highlight that LAAU can outperform the existing baselines.
Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer
Apr 07, 2022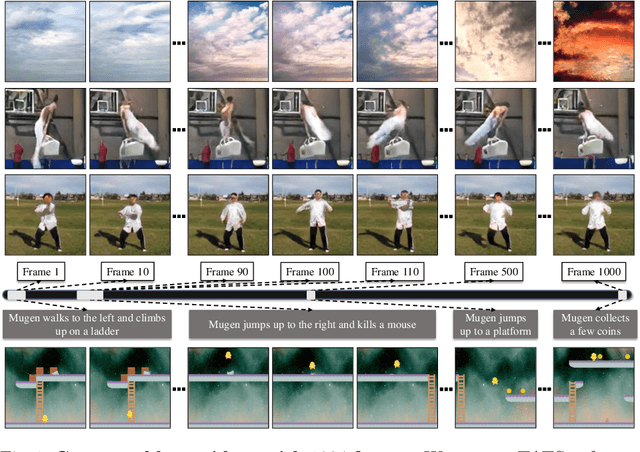
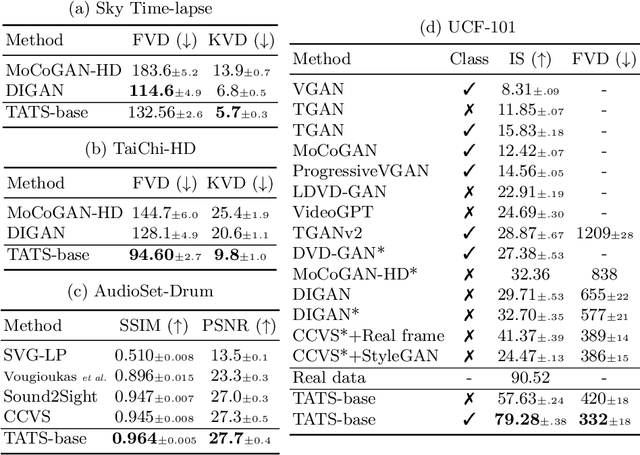

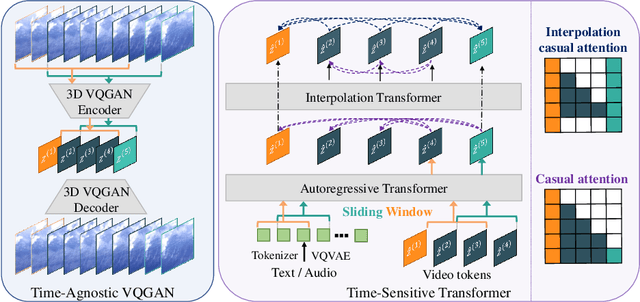
Videos are created to express emotion, exchange information, and share experiences. Video synthesis has intrigued researchers for a long time. Despite the rapid progress driven by advances in visual synthesis, most existing studies focus on improving the frames' quality and the transitions between them, while little progress has been made in generating longer videos. In this paper, we present a method that builds on 3D-VQGAN and transformers to generate videos with thousands of frames. Our evaluation shows that our model trained on 16-frame video clips from standard benchmarks such as UCF-101, Sky Time-lapse, and Taichi-HD datasets can generate diverse, coherent, and high-quality long videos. We also showcase conditional extensions of our approach for generating meaningful long videos by incorporating temporal information with text and audio. Videos and code can be found at https://songweige.github.io/projects/tats/index.html.
AlphaPose: Whole-Body Regional Multi-Person Pose Estimation and Tracking in Real-Time
Nov 07, 2022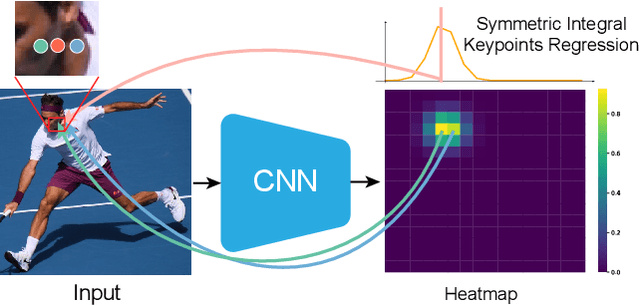
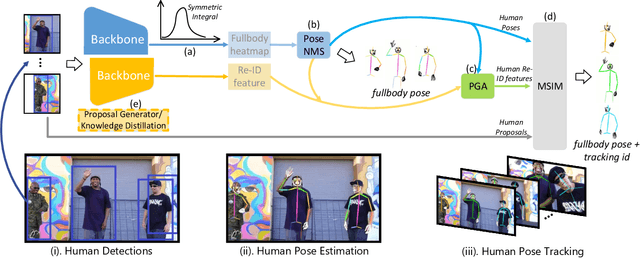
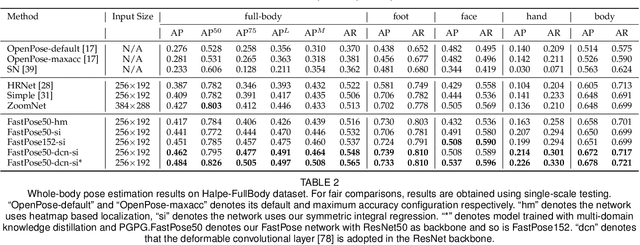
Accurate whole-body multi-person pose estimation and tracking is an important yet challenging topic in computer vision. To capture the subtle actions of humans for complex behavior analysis, whole-body pose estimation including the face, body, hand and foot is essential over conventional body-only pose estimation. In this paper, we present AlphaPose, a system that can perform accurate whole-body pose estimation and tracking jointly while running in realtime. To this end, we propose several new techniques: Symmetric Integral Keypoint Regression (SIKR) for fast and fine localization, Parametric Pose Non-Maximum-Suppression (P-NMS) for eliminating redundant human detections and Pose Aware Identity Embedding for jointly pose estimation and tracking. During training, we resort to Part-Guided Proposal Generator (PGPG) and multi-domain knowledge distillation to further improve the accuracy. Our method is able to localize whole-body keypoints accurately and tracks humans simultaneously given inaccurate bounding boxes and redundant detections. We show a significant improvement over current state-of-the-art methods in both speed and accuracy on COCO-wholebody, COCO, PoseTrack, and our proposed Halpe-FullBody pose estimation dataset. Our model, source codes and dataset are made publicly available at https://github.com/MVIG-SJTU/AlphaPose.
Matching Exemplar as Next Sentence Prediction (MeNSP): Zero-shot Prompt Learning for Automatic Scoring in Science Education
Jan 20, 2023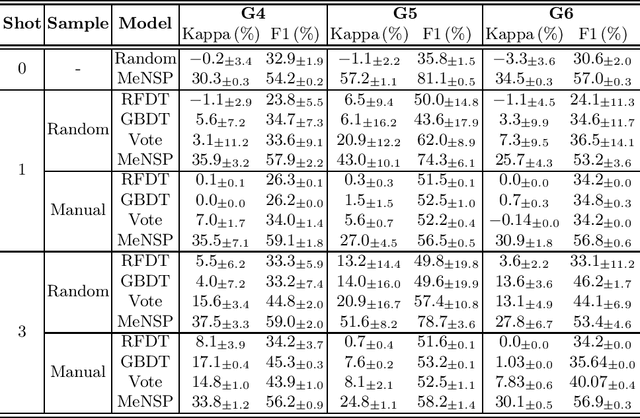
Developing models to automatically score students' written responses to science problems is critical for science education. However, collecting and labeling sufficient student responses for training models is time and cost-consuming. Recent studies suggest that pre-trained language models (PLMs) can be adapted to downstream tasks without fine-tuning with prompts. However, no research has employed such a prompt approach in science education. As student responses are presented with natural language, aligning the scoring procedure as the next sentence prediction task using prompts can skip the costly fine-tuning stage. In this study, we developed a zero-shot approach to automatically score student responses via Matching Exemplars as Next Sentence Prediction (MeNSP). This approach employs no training samples. We first apply MeNSP in scoring three assessment tasks of scientific argumentation and found machine-human scoring agreements, Cohen's Kappa ranges from 0.30 to 0.57, and F1 score ranges from 0.54 to 0.81. To improve the performance, we extend our research to the few-shots setting, either randomly selecting labeled student responses or manually constructing responses to fine-tune the models. We find that one task's performance is improved with more samples, Cohen's Kappa from 0.30 to 0.38, and F1 score from 0.54 to 0.59; for the two others, scoring performance is not improved. We also find that randomly selected few-shots perform better than the human expert-crafted approach. This study suggests that MeNSP can yield referable automatic scoring for student responses while significantly reducing the cost of model training. This method can benefit low-stakes classroom assessment practices in science education. Future research should further explore the applicability of the MeNSP in different types of assessment tasks in science education and improve the model performance.
An Interpretable and Efficient Infinite-Order Vector Autoregressive Model for High-Dimensional Time Series
Sep 02, 2022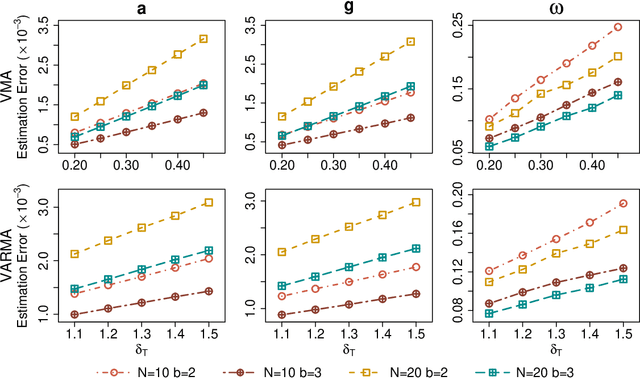
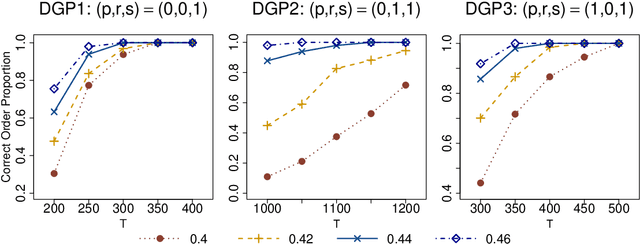
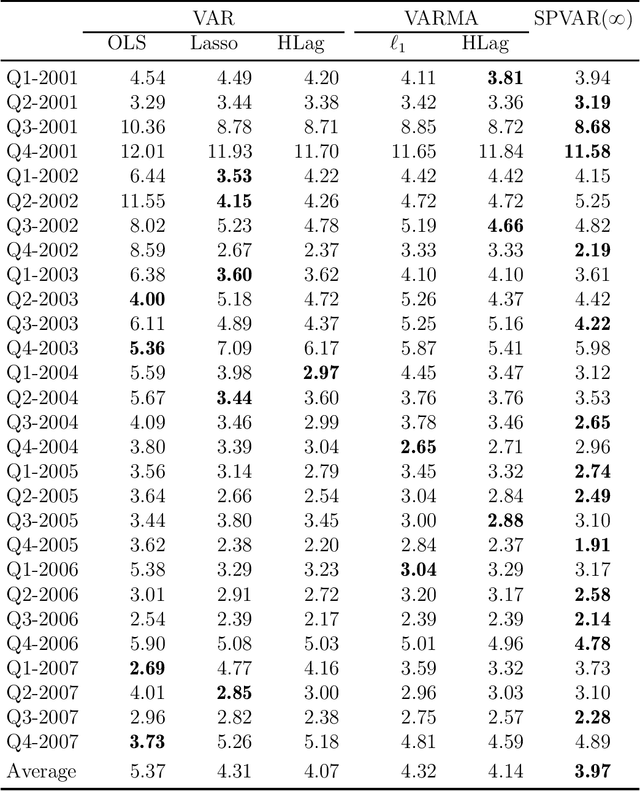
As a special infinite-order vector autoregressive (VAR) model, the vector autoregressive moving average (VARMA) model can capture much richer temporal patterns than the widely used finite-order VAR model. However, its practicality has long been hindered by its non-identifiability, computational intractability, and relative difficulty of interpretation. This paper introduces a novel infinite-order VAR model that not only avoids the drawbacks of the VARMA model but inherits its favorable temporal patterns. As another attractive feature, the temporal and cross-sectional dependence structures of this model can be interpreted separately, since they are characterized by different sets of parameters. For high-dimensional time series, this separation motivates us to impose sparsity on the parameters determining the cross-sectional dependence. As a result, greater statistical efficiency and interpretability can be achieved without sacrificing any temporal information. We introduce an $\ell_1$-regularized estimator for the proposed model and derive the corresponding non-asymptotic error bounds. An efficient block coordinate descent algorithm and a consistent model order selection method are developed. The merit of the proposed approach is supported by simulation studies and a real-world macroeconomic data analysis.
WIRE: Wavelet Implicit Neural Representations
Jan 05, 2023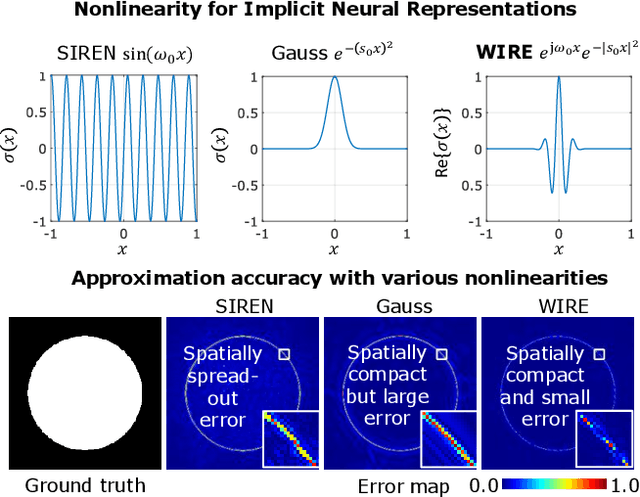
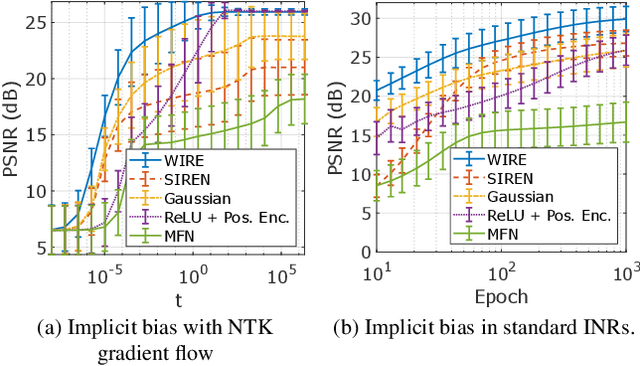
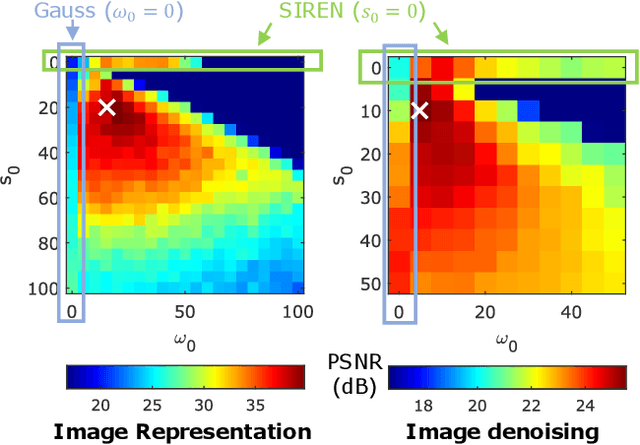
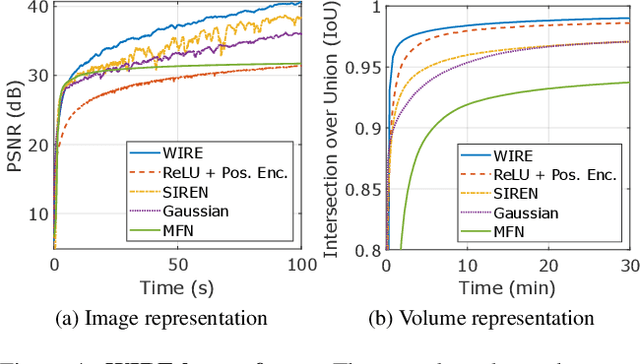
Implicit neural representations (INRs) have recently advanced numerous vision-related areas. INR performance depends strongly on the choice of the nonlinear activation function employed in its multilayer perceptron (MLP) network. A wide range of nonlinearities have been explored, but, unfortunately, current INRs designed to have high accuracy also suffer from poor robustness (to signal noise, parameter variation, etc.). Inspired by harmonic analysis, we develop a new, highly accurate and robust INR that does not exhibit this tradeoff. Wavelet Implicit neural REpresentation (WIRE) uses a continuous complex Gabor wavelet activation function that is well-known to be optimally concentrated in space-frequency and to have excellent biases for representing images. A wide range of experiments (image denoising, image inpainting, super-resolution, computed tomography reconstruction, image overfitting, and novel view synthesis with neural radiance fields) demonstrate that WIRE defines the new state of the art in INR accuracy, training time, and robustness.
Detection and Tracking of Low Observable Objects in a Sequence of Image Frames Using Particle Filter
Dec 26, 2022A track-before-detect (TBD) particle filter-based method for detection and tracking of low observable objects based on a sequence of image frames in the presence of noise and clutter is studied. At each time instance after receiving a frame of image, first, some preprocessing approaches are applied to the image. Then, it is sent to the detection and tracking algorithm which is based on a particle filter. Performance of the approach is evaluated for detection and tracking of an object in different scenarios including noise and clutter.