 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pre-training Enhanced Spatial-temporal Graph Neural Network for Multivariate Time Series Forecasting
Jun 18, 2022
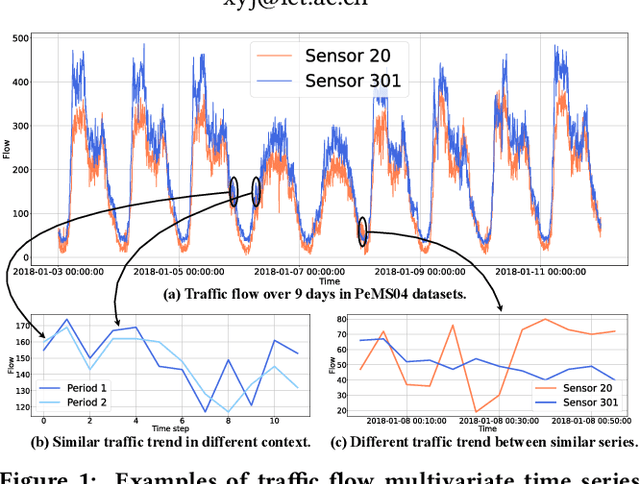
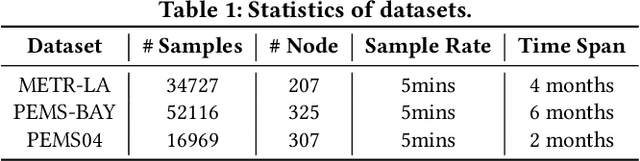
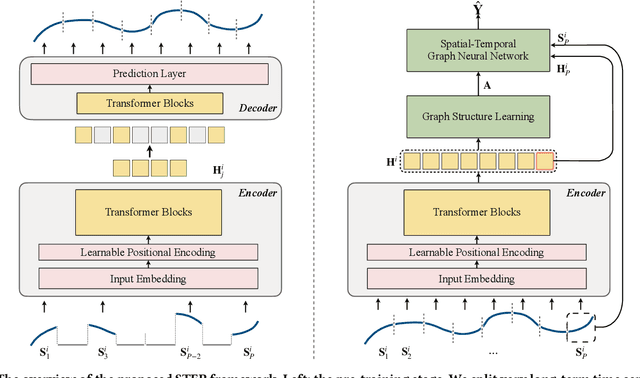
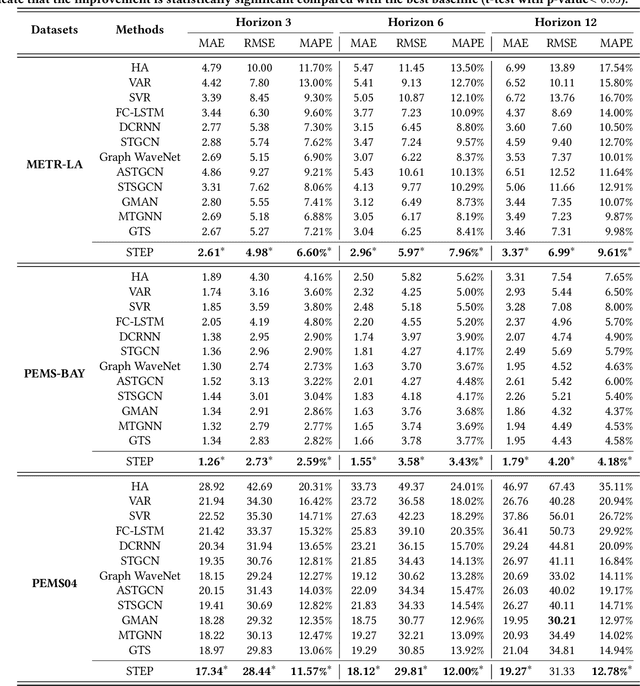
Multivariate Time Series (MTS) forecasting plays a vital role in a wide range of applications. Recently, Spatial-Temporal Graph Neural Networks (STGNNs) have become increasingly popular MTS forecasting methods. STGNNs jointly model the spatial and temporal patterns of MTS through graph neural networks and sequential models, significantly improving the prediction accuracy. But limited by model complexity, most STGNNs only consider short-term historical MTS data, such as data over the past one hour. However, the patterns of time series and the dependencies between them (i.e., the temporal and spatial patterns) need to be analyzed based on long-term historical MTS data. To address this issue, we propose a novel framework, in which STGNN is Enhanced by a scalable time series Pre-training model (STEP). Specifically, we design a pre-training model to efficiently learn temporal patterns from very long-term history time series (e.g., the past two weeks) and generate segment-level representations. These representations provide contextual information for short-term time series input to STGNNs and facilitate modeling dependencies between time series. Experiments on three public real-world datasets demonstrate that our framework is capable of significantly enhancing downstream STGNNs, and our pre-training model aptly captures temporal patterns.
Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer
Apr 07, 2022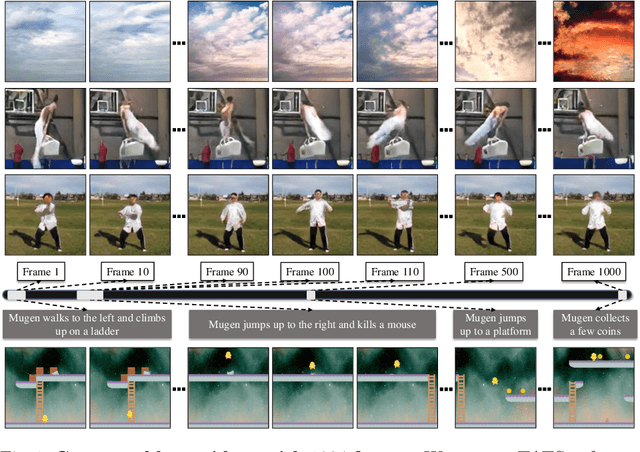
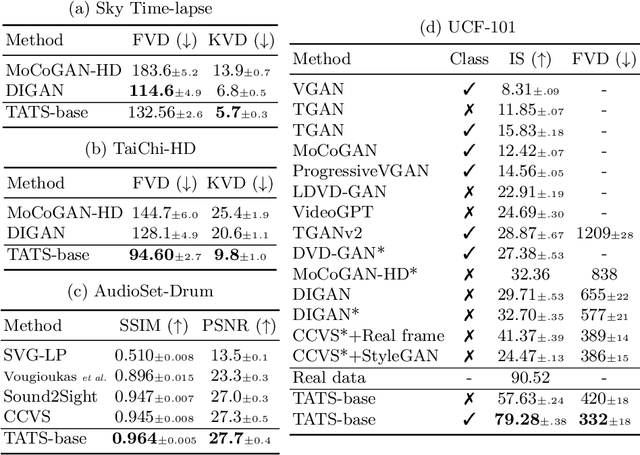

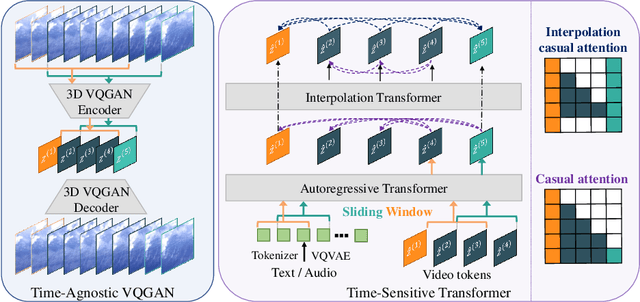
Videos are created to express emotion, exchange information, and share experiences. Video synthesis has intrigued researchers for a long time. Despite the rapid progress driven by advances in visual synthesis, most existing studies focus on improving the frames' quality and the transitions between them, while little progress has been made in generating longer videos. In this paper, we present a method that builds on 3D-VQGAN and transformers to generate videos with thousands of frames. Our evaluation shows that our model trained on 16-frame video clips from standard benchmarks such as UCF-101, Sky Time-lapse, and Taichi-HD datasets can generate diverse, coherent, and high-quality long videos. We also showcase conditional extensions of our approach for generating meaningful long videos by incorporating temporal information with text and audio. Videos and code can be found at https://songweige.github.io/projects/tats/index.html.
Conformal prediction set for time-series
Jun 15, 2022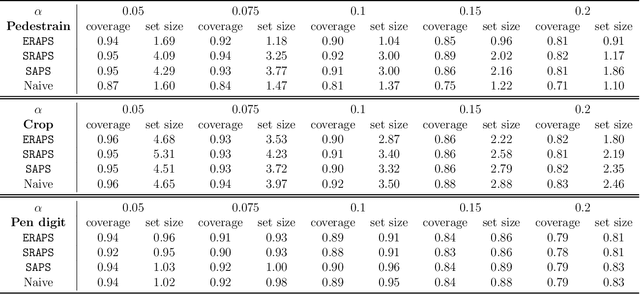
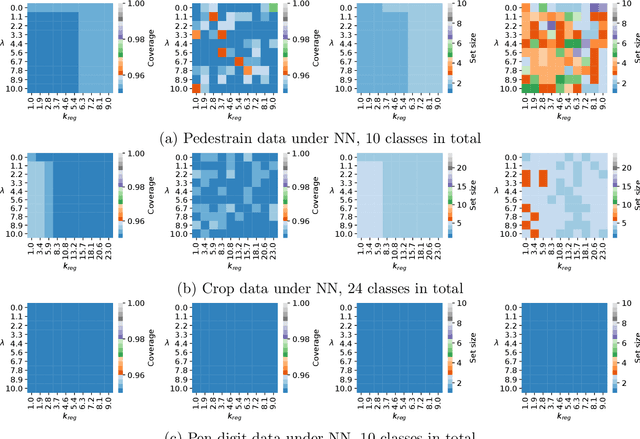
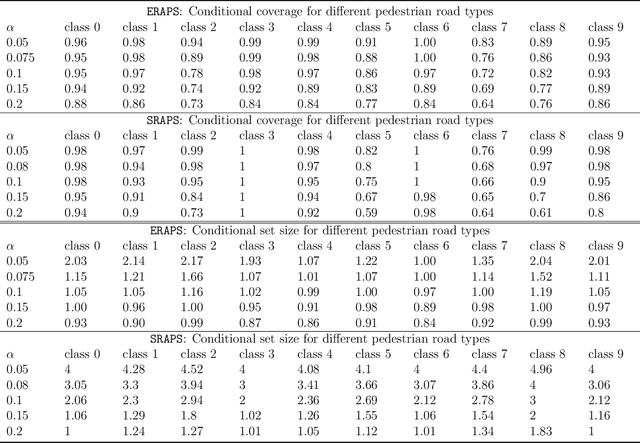
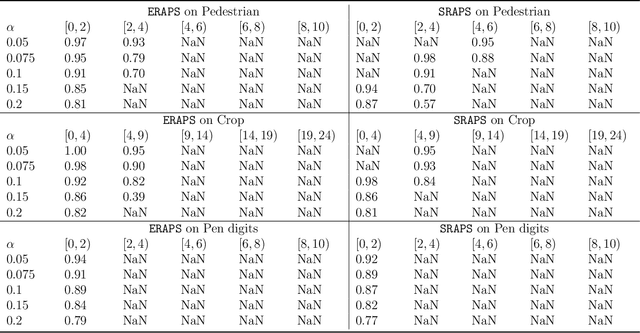
When building either prediction intervals for regression (with real-valued response) or prediction sets for classification (with categorical responses), uncertainty quantification is essential to studying complex machine learning methods. In this paper, we develop Ensemble Regularized Adaptive Prediction Set (ERAPS) to construct prediction sets for time-series (with categorical responses), based on the prior work of [Xu and Xie, 2021]. In particular, we allow unknown dependencies to exist within features and responses that arrive in sequence. Method-wise, ERAPS is a distribution-free and ensemble-based framework that is applicable for arbitrary classifiers. Theoretically, we bound the coverage gap without assuming data exchangeability and show asymptotic set convergence. Empirically, we demonstrate valid marginal and conditional coverage by ERAPS, which also tends to yield smaller prediction sets than competing methods.
Causal Inference (C-inf) -- asymmetric scenario of typical phase transitions
Jan 02, 2023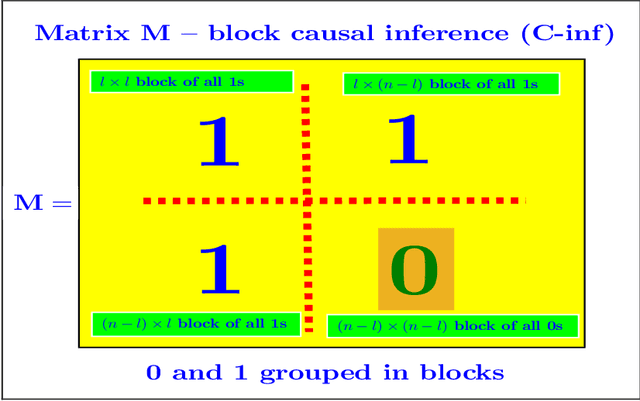
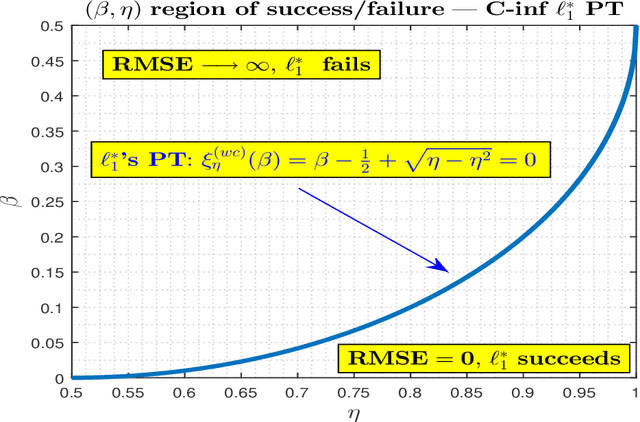
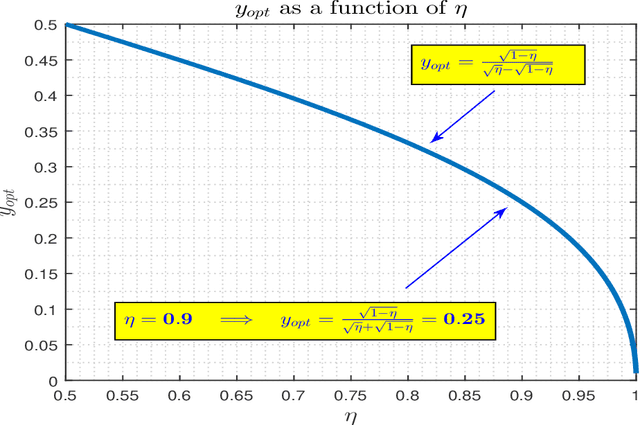
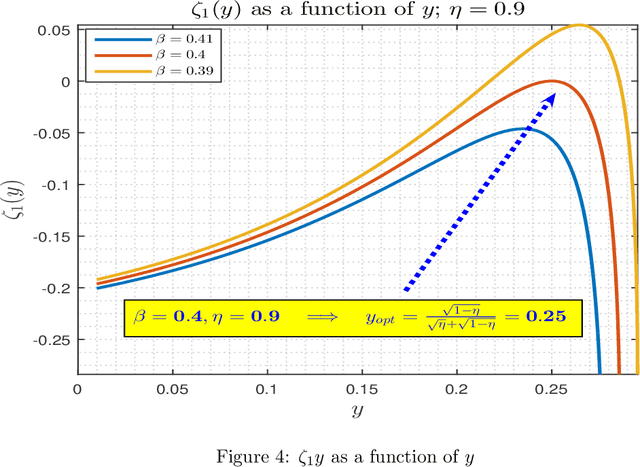
In this paper, we revisit and further explore a mathematically rigorous connection between Causal inference (C-inf) and the Low-rank recovery (LRR) established in [10]. Leveraging the Random duality - Free probability theory (RDT-FPT) connection, we obtain the exact explicit typical C-inf asymmetric phase transitions (PT). We uncover a doubling low-rankness phenomenon, which means that exactly two times larger low rankness is allowed in asymmetric scenarios compared to the symmetric worst case ones considered in [10]. Consequently, the final PT mathematical expressions are as elegant as those obtained in [10], and highlight direct relations between the targeted C-inf matrix low rankness and the time of treatment. Our results have strong implications for applications, where C-inf matrices are not necessarily symmetric.
Convolution-enhanced Evolving Attention Networks
Dec 16, 2022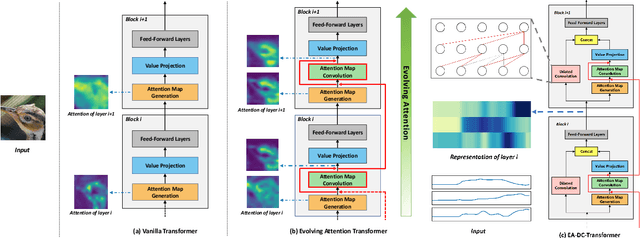

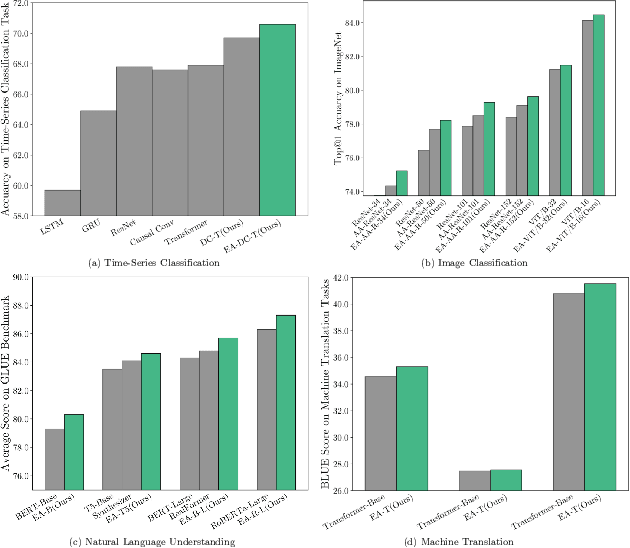
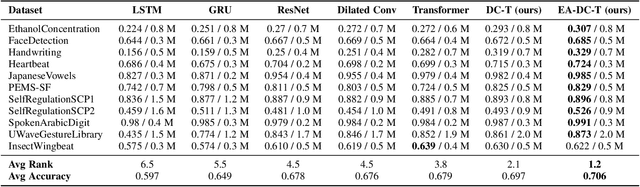
Attention-based neural networks, such as Transformers, have become ubiquitous in numerous applications, including computer vision, natural language processing, and time-series analysis. In all kinds of attention networks, the attention maps are crucial as they encode semantic dependencies between input tokens. However, most existing attention networks perform modeling or reasoning based on representations, wherein the attention maps of different layers are learned separately without explicit interactions. In this paper, we propose a novel and generic evolving attention mechanism, which directly models the evolution of inter-token relationships through a chain of residual convolutional modules. The major motivations are twofold. On the one hand, the attention maps in different layers share transferable knowledge, thus adding a residual connection can facilitate the information flow of inter-token relationships across layers. On the other hand, there is naturally an evolutionary trend among attention maps at different abstraction levels, so it is beneficial to exploit a dedicated convolution-based module to capture this process. Equipped with the proposed mechanism, the convolution-enhanced evolving attention networks achieve superior performance in various applications, including time-series representation, natural language understanding, machine translation, and image classification. Especially on time-series representation tasks, Evolving Attention-enhanced Dilated Convolutional (EA-DC-) Transformer outperforms state-of-the-art models significantly, achieving an average of 17% improvement compared to the best SOTA. To the best of our knowledge, this is the first work that explicitly models the layer-wise evolution of attention maps. Our implementation is available at https://github.com/pkuyym/EvolvingAttention
Taming Lagrangian Chaos with Multi-Objective Reinforcement Learning
Dec 19, 2022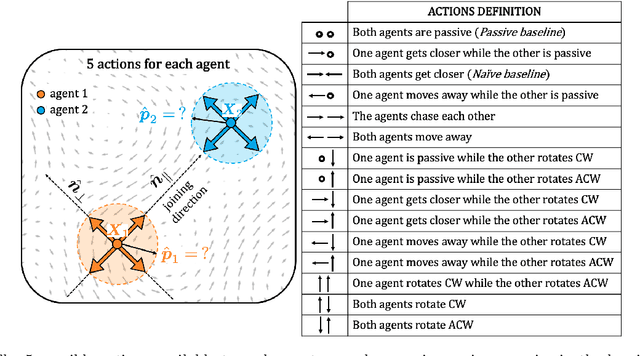

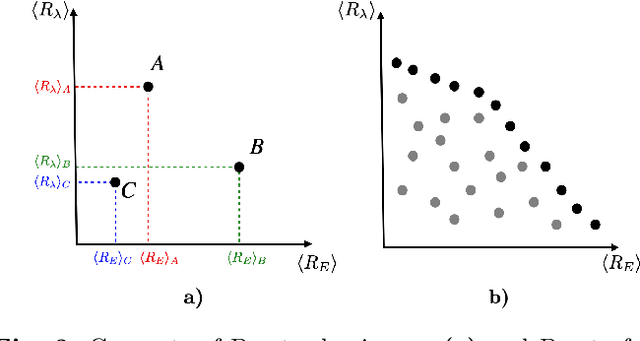
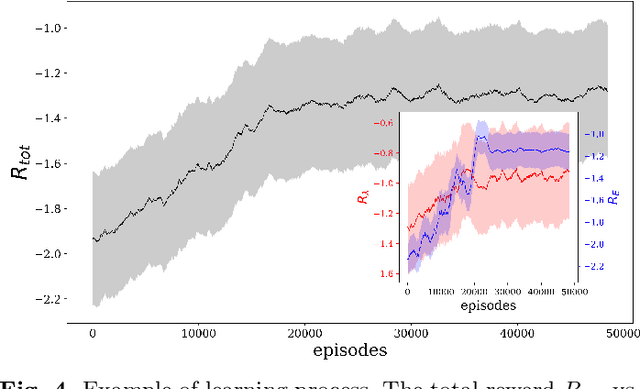
We consider the problem of two active particles in 2D complex flows with the multi-objective goals of minimizing both the dispersion rate and the energy consumption of the pair. We approach the problem by means of Multi Objective Reinforcement Learning (MORL), combining scalarization techniques together with a Q-learning algorithm, for Lagrangian drifters that have variable swimming velocity. We show that MORL is able to find a set of trade-off solutions forming an optimal Pareto frontier. As a benchmark, we show that a set of heuristic strategies are dominated by the MORL solutions. We consider the situation in which the agents cannot update their control variables continuously, but only after a discrete (decision) time, $\tau$. We show that there is a range of decision times, in between the Lyapunov time and the continuous updating limit, where Reinforcement Learning finds strategies that significantly improve over heuristics. In particular, we discuss how large decision times require enhanced knowledge of the flow, whereas for smaller $\tau$ all a priori heuristic strategies become Pareto optimal.
On the Effect of Anticipation on Reading Times
Nov 25, 2022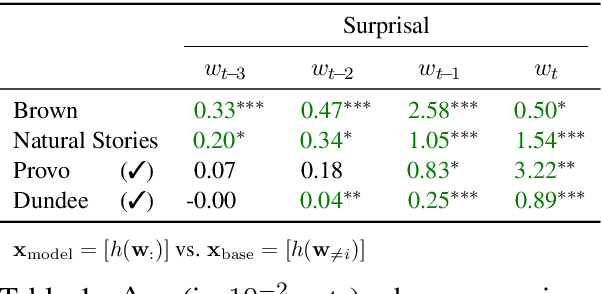
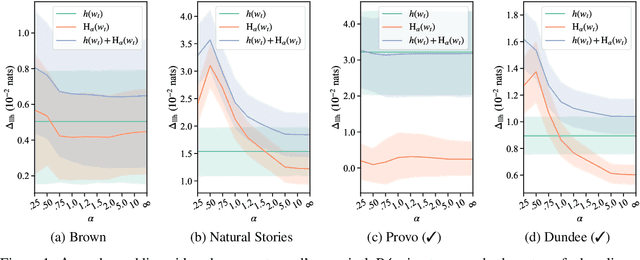
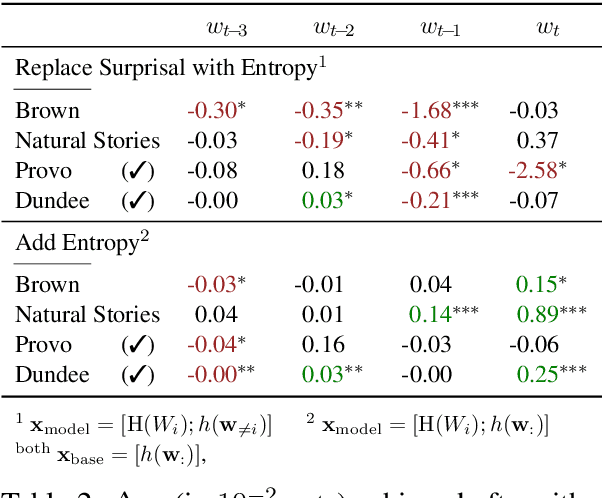
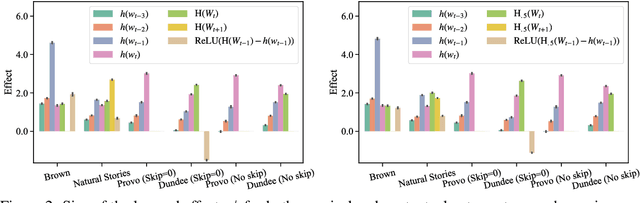
Over the past two decades, numerous studies have demonstrated how less predictable (i.e. higher surprisal) words take more time to read. In general, these previous studies implicitly assumed the reading process to be purely responsive: readers observe a new word and allocate time to read it as required. These results, however, are also compatible with a reading time that is anticipatory: readers could, e.g., allocate time to a future word based on their expectation about it. In this work, we examine the anticipatory nature of reading by looking at how people's predictions about upcoming material influence reading times. Specifically, we test anticipation by looking at the effects of surprisal and contextual entropy on four reading-time datasets: two self-paced and two eye-tracking. In three of four datasets tested, we find that the entropy predicts reading times as well as (or better than) the surprisal. We then hypothesise four cognitive mechanisms through which the contextual entropy could impact RTs -- three of which we design experiments to analyse. Overall, our results support a view of reading that is both anticipatory and responsive.
Dynamic Local Feature Aggregation for Learning on Point Clouds
Jan 07, 2023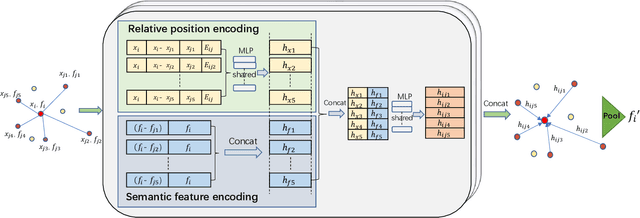
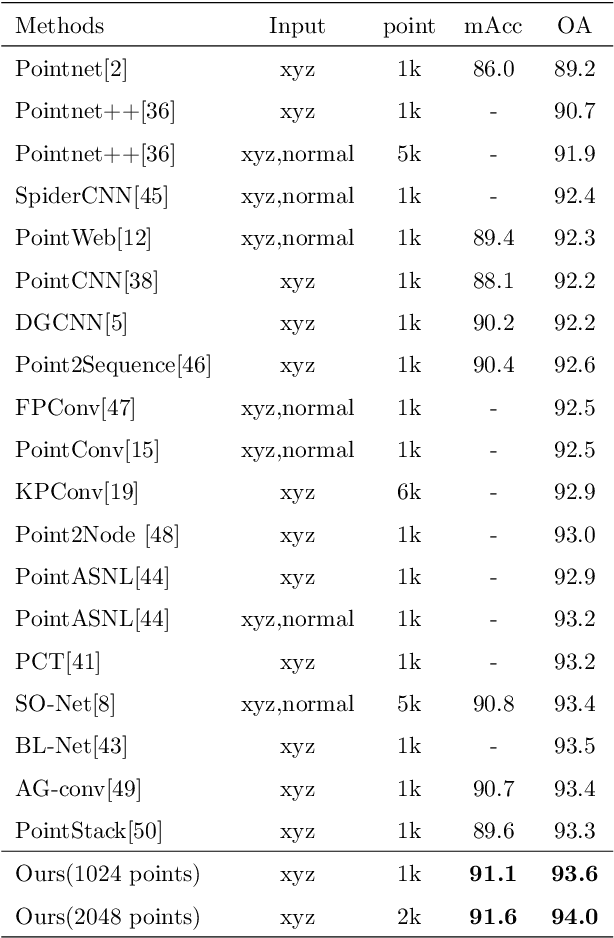
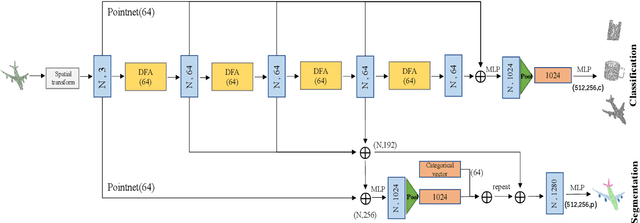

Existing point cloud learning methods aggregate features from neighbouring points relying on constructing graph in the spatial domain, which results in feature update for each point based on spatially-fixed neighbours throughout layers. In this paper, we propose a dynamic feature aggregation (DFA) method that can transfer information by constructing local graphs in the feature domain without spatial constraints. By finding k-nearest neighbors in the feature domain, we perform relative position encoding and semantic feature encoding to explore latent position and feature similarity information, respectively, so that rich local features can be learned. At the same time, we also learn low-dimensional global features from the original point cloud for enhancing feature representation. Between DFA layers, we dynamically update the constructed local graph structure, so that we can learn richer information, which greatly improves adaptability and efficiency. We demonstrate the superiority of our method by conducting extensive experiments on point cloud classification and segmentation tasks. Implementation code is available: https://github.com/jiamang/DFA.
Privacy and Efficiency of Communications in Federated Split Learning
Jan 07, 2023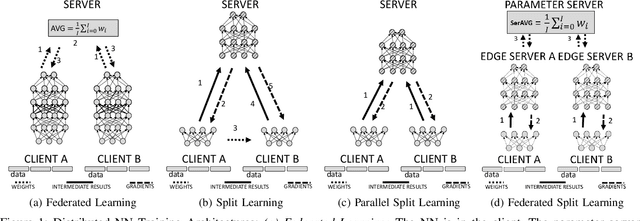
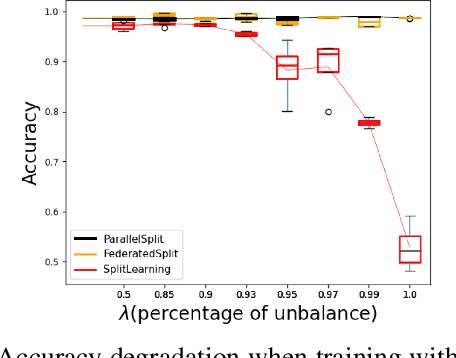
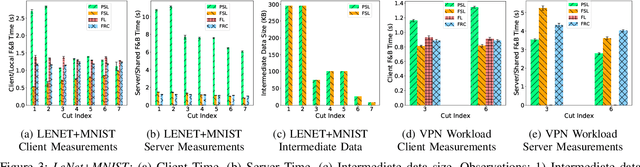
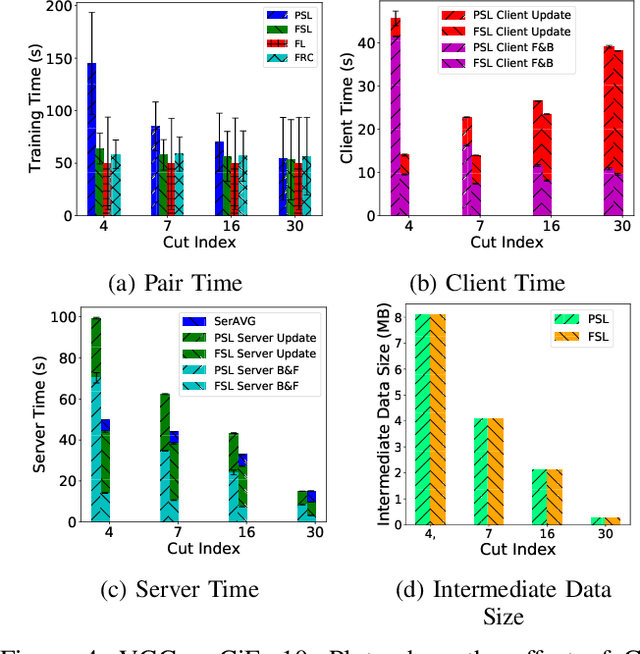
Everyday, large amounts of sensitive data is distributed across mobile phones, wearable devices, and other sensors. Traditionally, these enormous datasets have been processed on a single system, with complex models being trained to make valuable predictions. Distributed machine learning techniques such as Federated and Split Learning have recently been developed to protect user data and privacy better while ensuring high performance. Both of these distributed learning architectures have advantages and disadvantages. In this paper, we examine these tradeoffs and suggest a new hybrid Federated Split Learning architecture that combines the efficiency and privacy benefits of both. Our evaluation demonstrates how our hybrid Federated Split Learning approach can lower the amount of processing power required by each client running a distributed learning system, reduce training and inference time while keeping a similar accuracy. We also discuss the resiliency of our approach to deep learning privacy inference attacks and compare our solution to other recently proposed benchmarks.
Logic and Commonsense-Guided Temporal Knowledge Graph Completion
Nov 30, 2022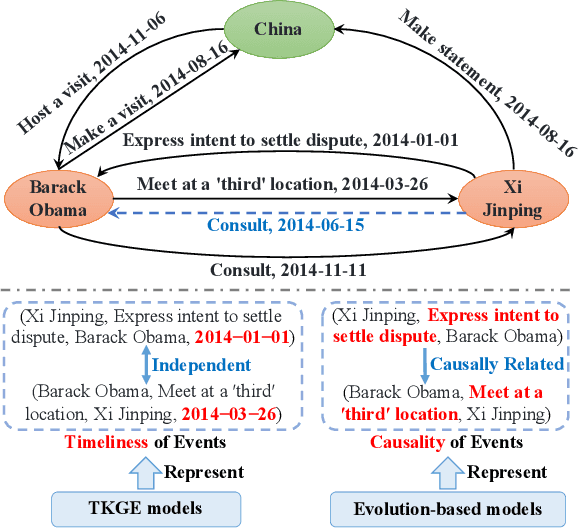

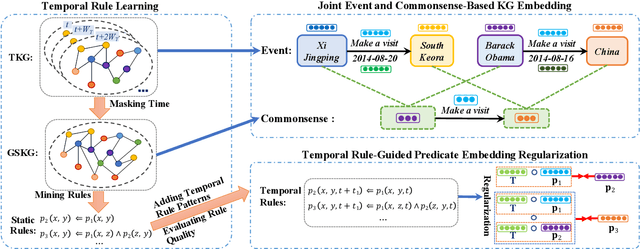

A temporal knowledge graph (TKG) stores the events derived from the data involving time. Predicting events is extremely challenging due to the time-sensitive property of events. Besides, the previous TKG completion (TKGC) approaches cannot represent both the timeliness and the causality properties of events, simultaneously. To address these challenges, we propose a Logic and Commonsense-Guided Embedding model (LCGE) to jointly learn the time-sensitive representation involving timeliness and causality of events, together with the time-independent representation of events from the perspective of commonsense. Specifically, we design a temporal rule learning algorithm to construct a rule-guided predicate embedding regularization strategy for learning the causality among events. Furthermore, we could accurately evaluate the plausibility of events via auxiliary commonsense knowledge. The experimental results of TKGC task illustrate the significant performance improvements of our model compared with the existing approaches. More interestingly, our model is able to provide the explainability of the predicted results in the view of causal inference. The source code and datasets of this paper are available at https://github.com/ngl567/LCGE.