 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Non-autoregressive Sequence-to-Sequence Vision-Language Models
Mar 04, 2024
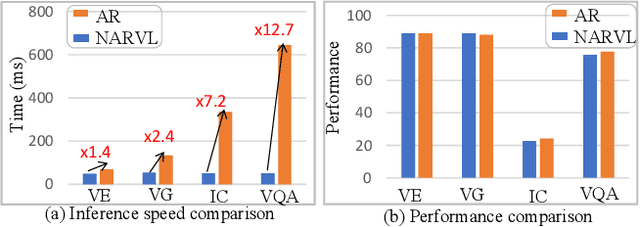
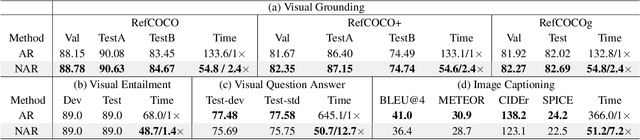
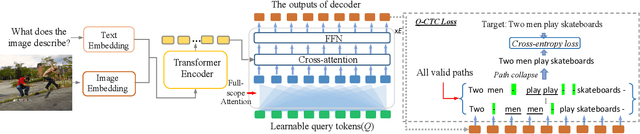
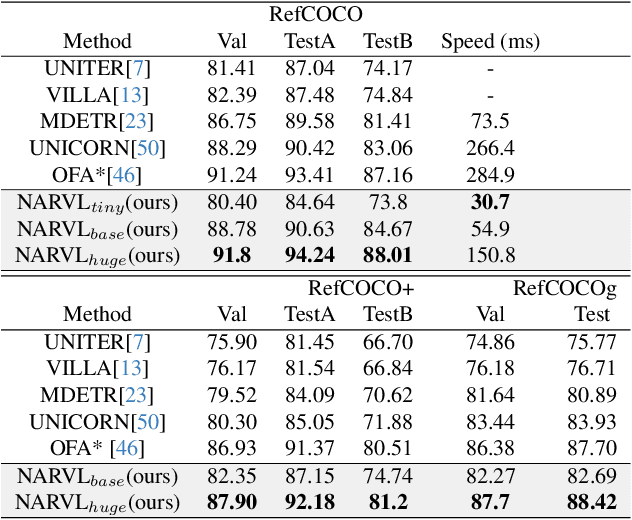
Sequence-to-sequence vision-language models are showing promise, but their applicability is limited by their inference latency due to their autoregressive way of generating predictions. We propose a parallel decoding sequence-to-sequence vision-language model, trained with a Query-CTC loss, that marginalizes over multiple inference paths in the decoder. This allows us to model the joint distribution of tokens, rather than restricting to conditional distribution as in an autoregressive model. The resulting model, NARVL, achieves performance on-par with its state-of-the-art autoregressive counterpart, but is faster at inference time, reducing from the linear complexity associated with the sequential generation of tokens to a paradigm of constant time joint inference.
Exposure-Conscious Path Planning for Equal-Exposure Corridors
Mar 04, 2024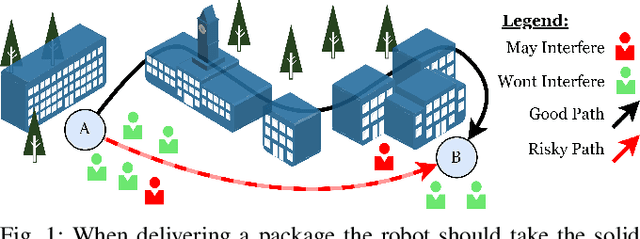
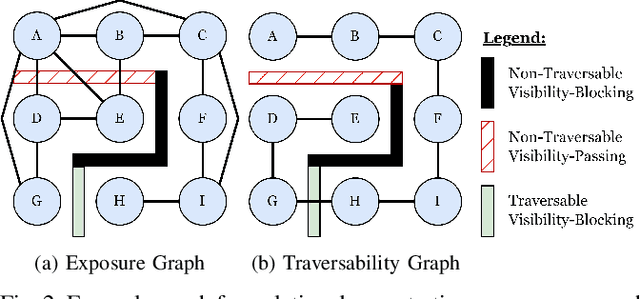
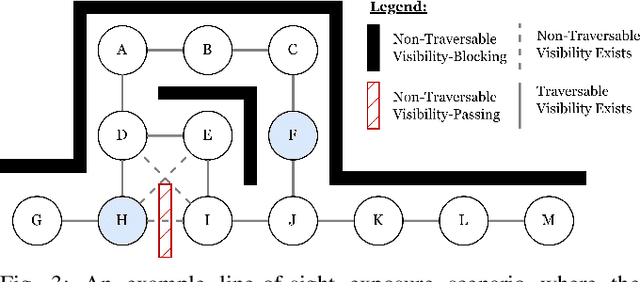
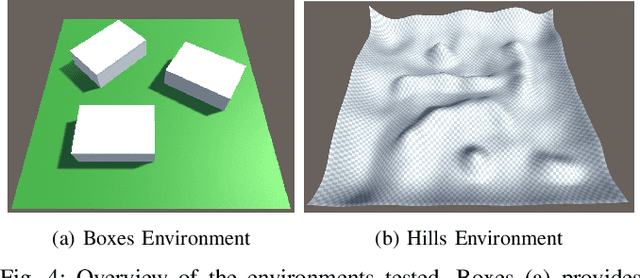
While maximizing line-of-sight coverage of specific regions or agents in the environment is a well explored path planning objective, the converse problem of minimizing exposure to the entire environment during navigation is especially interesting in the context of minimizing detection risk. This work demonstrates that minimizing line-of-sight exposure to the environment is non-Markovian, which cannot be efficiently solved optimally with traditional path planning. The optimality gap of the graph-search algorithm A* and the trade-offs in optimality vs. computation time of several approximating heuristics is explored. Finally, the concept of equal-exposure corridors, which afford polynomial time determination of all paths that do not increase exposure, is presented.
Collision Avoidance and Geofencing for Fixed-wing Aircraft with Control Barrier Functions
Mar 07, 2024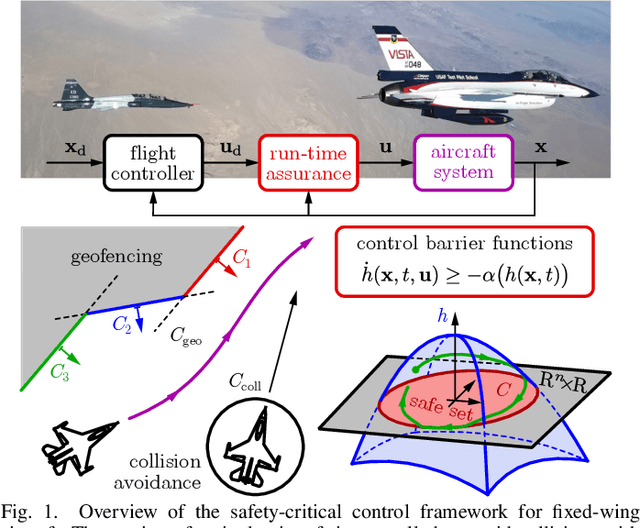
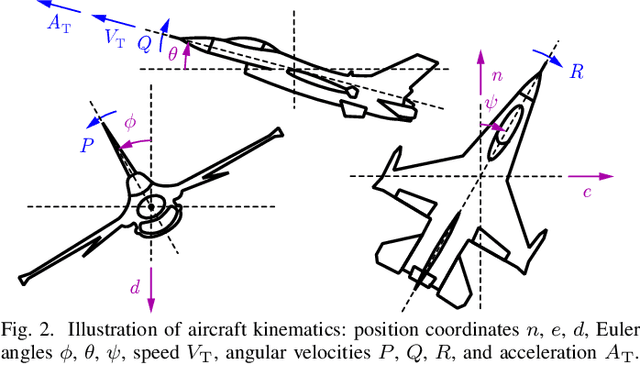
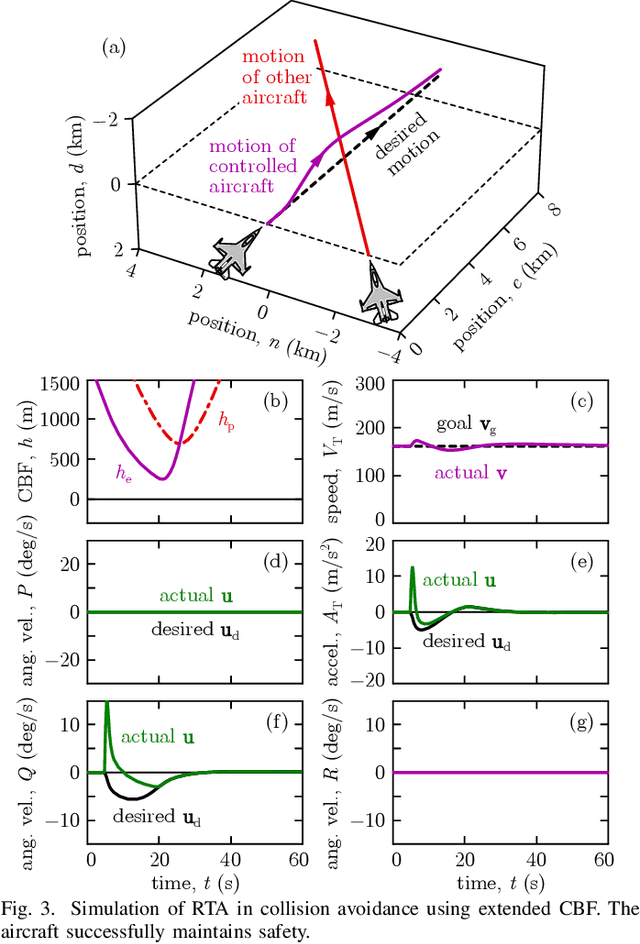
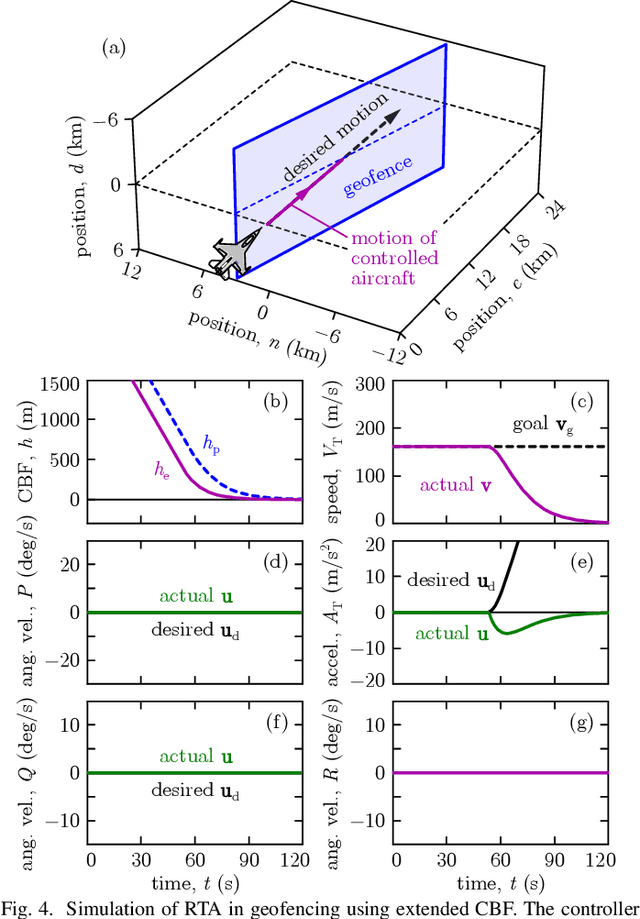
Safety-critical failures often have fatal consequences in aerospace control. Control systems on aircraft, therefore, must ensure the strict satisfaction of safety constraints, preferably with formal guarantees of safe behavior. This paper establishes the safety-critical control of fixed-wing aircraft in collision avoidance and geofencing tasks. A control framework is developed wherein a run-time assurance (RTA) system modulates the nominal flight controller of the aircraft whenever necessary to prevent it from colliding with other aircraft or crossing a boundary (geofence) in space. The RTA is formulated as a safety filter using control barrier functions (CBFs) with formal guarantees of safe behavior. CBFs are constructed and compared for a nonlinear kinematic fixed-wing aircraft model. The proposed CBF-based controllers showcase the capability of safely executing simultaneous collision avoidance and geofencing, as demonstrated by simulations on the kinematic model and a high-fidelity dynamical model.
Bidirectional Generative Pre-training for Improving Time Series Representation Learning
Feb 14, 2024Learning time-series representations for discriminative tasks has been a long-standing challenge. Current pre-training methods are limited in either unidirectional next-token prediction or randomly masked token prediction. We propose a novel architecture called Bidirectional Timely Generative Pre-trained Transformer (BiTimelyGPT), which pre-trains on time-series data by both next-token and previous-token predictions in alternating transformer layers. This pre-training task preserves original distribution and data shapes of the time-series. Additionally, the full-rank forward and backward attention matrices exhibit more expressive representation capabilities. Using biosignal data, BiTimelyGPT demonstrates superior performance in predicting neurological functionality, disease diagnosis, and physiological signs. By visualizing the attention heatmap, we observe that the pre-trained BiTimelyGPT can identify discriminative segments from time-series sequences, even more so after fine-tuning on the task.
Micro-Fracture Detection in Photovoltaic Cells with Hardware-Constrained Devices and Computer Vision
Mar 08, 2024
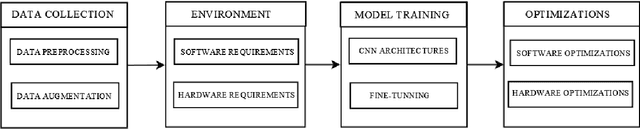

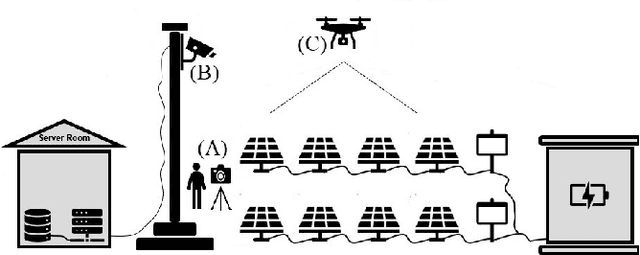
Solar energy is rapidly becoming a robust renewable energy source to conventional finite resources such as fossil fuels. It is harvested using interconnected photovoltaic panels, typically built with crystalline silicon cells, i.e. semiconducting materials that convert effectively the solar radiation into electricity. However, crystalline silicon is fragile and vulnerable to cracking over time or in predictive maintenance tasks, which can lead to electric isolation of parts of the solar cell and even failure, thus affecting the panel performance and reducing electricity generation. This work aims to developing a system for detecting cell cracks in solar panels to anticipate and alaert of a potential failure of the photovoltaic system by using computer vision techniques. Three scenarios are defined where these techniques will bring value. In scenario A, images are taken manually and the system detecting failures in the solar cells is not subject to any computationa constraints. In scenario B, an Edge device is placed near the solar farm, able to make inferences. Finally, in scenario C, a small microcontroller is placed in a drone flying over the solar farm and making inferences about the solar cells' states. Three different architectures are found the most suitable solutions, one for each scenario, namely the InceptionV3 model, an EfficientNetB0 model shrunk into full integer quantization, and a customized CNN architechture built with VGG16 blocks.
HistGen: Histopathology Report Generation via Local-Global Feature Encoding and Cross-modal Context Interaction
Mar 08, 2024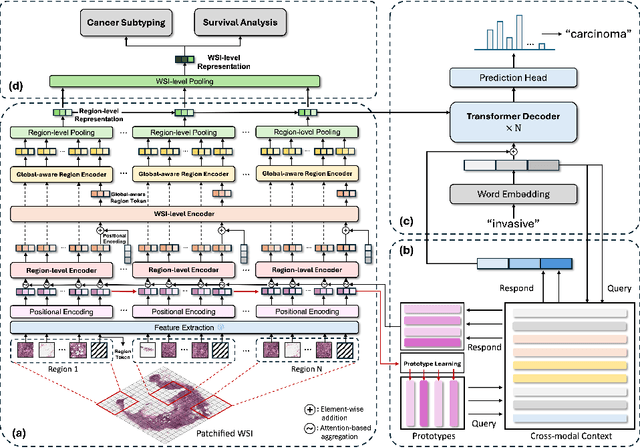
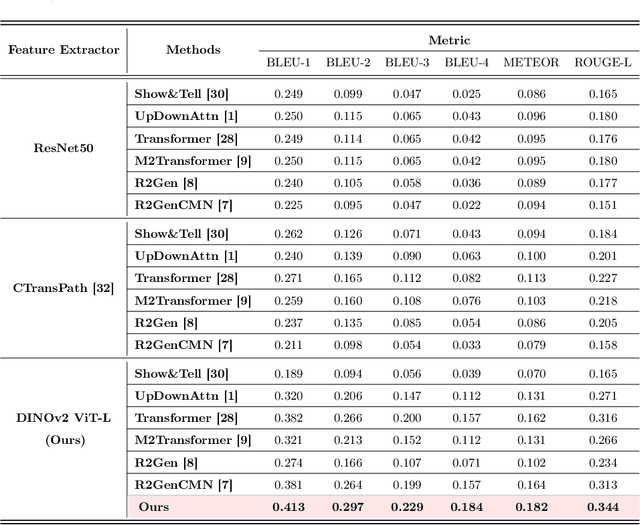
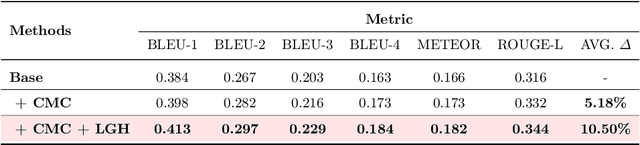
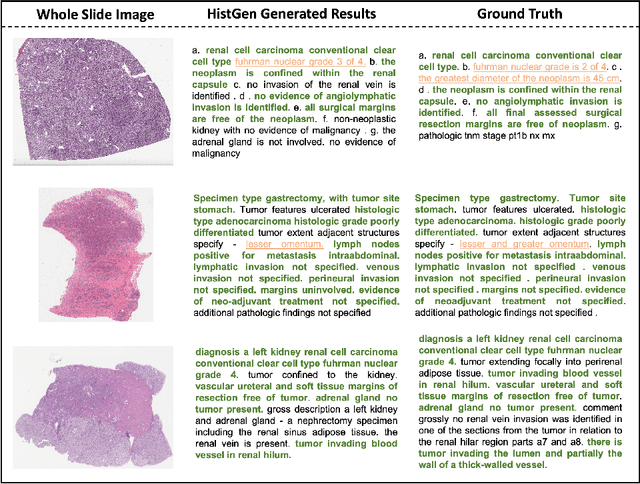
Histopathology serves as the gold standard in cancer diagnosis, with clinical reports being vital in interpreting and understanding this process, guiding cancer treatment and patient care. The automation of histopathology report generation with deep learning stands to significantly enhance clinical efficiency and lessen the labor-intensive, time-consuming burden on pathologists in report writing. In pursuit of this advancement, we introduce HistGen, a multiple instance learning-empowered framework for histopathology report generation together with the first benchmark dataset for evaluation. Inspired by diagnostic and report-writing workflows, HistGen features two delicately designed modules, aiming to boost report generation by aligning whole slide images (WSIs) and diagnostic reports from local and global granularity. To achieve this, a local-global hierarchical encoder is developed for efficient visual feature aggregation from a region-to-slide perspective. Meanwhile, a cross-modal context module is proposed to explicitly facilitate alignment and interaction between distinct modalities, effectively bridging the gap between the extensive visual sequences of WSIs and corresponding highly summarized reports. Experimental results on WSI report generation show the proposed model outperforms state-of-the-art (SOTA) models by a large margin. Moreover, the results of fine-tuning our model on cancer subtyping and survival analysis tasks further demonstrate superior performance compared to SOTA methods, showcasing strong transfer learning capability. Dataset, model weights, and source code are available in https://github.com/dddavid4real/HistGen.
Semantic Feature Learning for Universal Unsupervised Cross-Domain Retrieval
Mar 08, 2024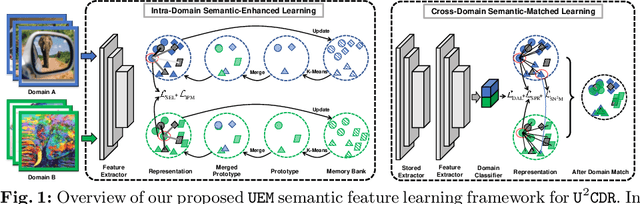
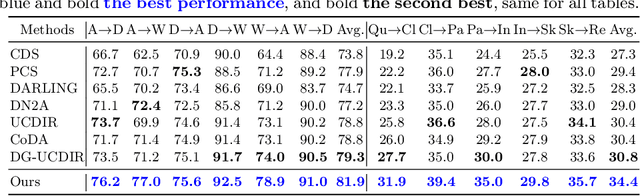
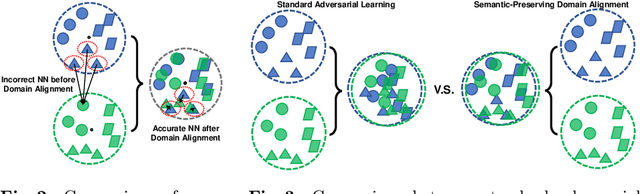
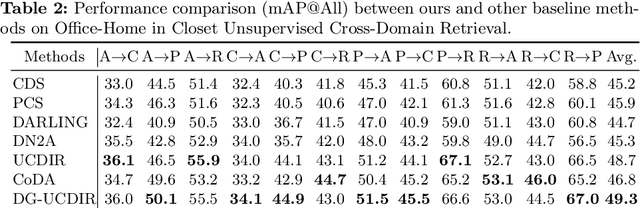
Cross-domain retrieval (CDR), as a crucial tool for numerous technologies, is finding increasingly broad applications. However, existing efforts face several major issues, with the most critical being the need for accurate supervision, which often demands costly resources and efforts. Cutting-edge studies focus on achieving unsupervised CDR but typically assume that the category spaces across domains are identical, an assumption that is often unrealistic in real-world scenarios. This is because only through dedicated and comprehensive analysis can the category spaces of different domains be confirmed as identical, which contradicts the premise of unsupervised scenarios. Therefore, in this work, we introduce the problem of Universal Unsupervised Cross-Domain Retrieval (U^2CDR) for the first time and design a two-stage semantic feature learning framework to address it. In the first stage, a cross-domain unified prototypical structure is established under the guidance of an instance-prototype-mixed contrastive loss and a semantic-enhanced loss, to counteract category space differences. In the second stage, through a modified adversarial training mechanism, we ensure minimal changes for the established prototypical structure during domain alignment, enabling more accurate nearest-neighbor searching. Extensive experiments across multiple datasets and scenarios, including closet, partial, and open-set CDR, demonstrate that our approach significantly outperforms existing state-of-the-art CDR works and some potentially effective studies from other topics in solving U^2CDR challenges.
A Miniaturized Device for Ultrafast On-demand Drug Release based on a Gigahertz Ultrasonic Resonator
Mar 05, 2024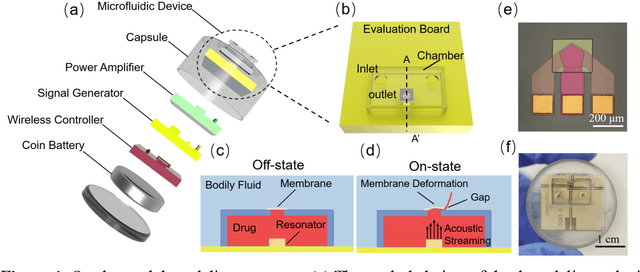
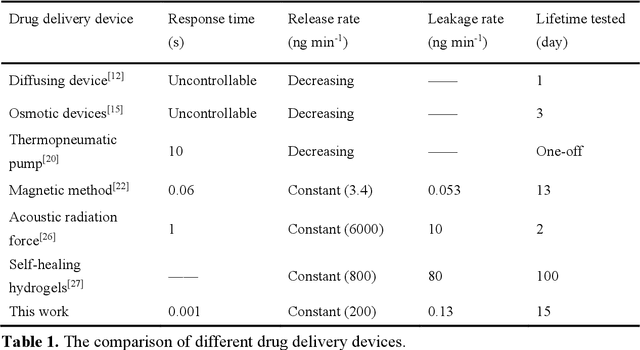
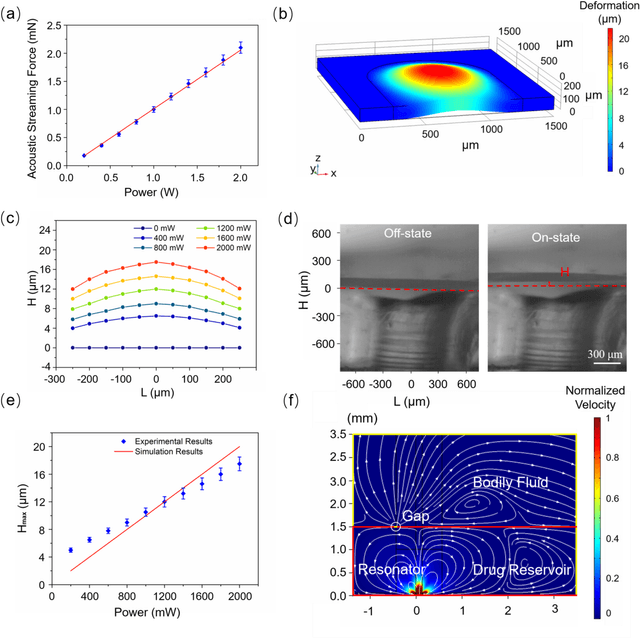
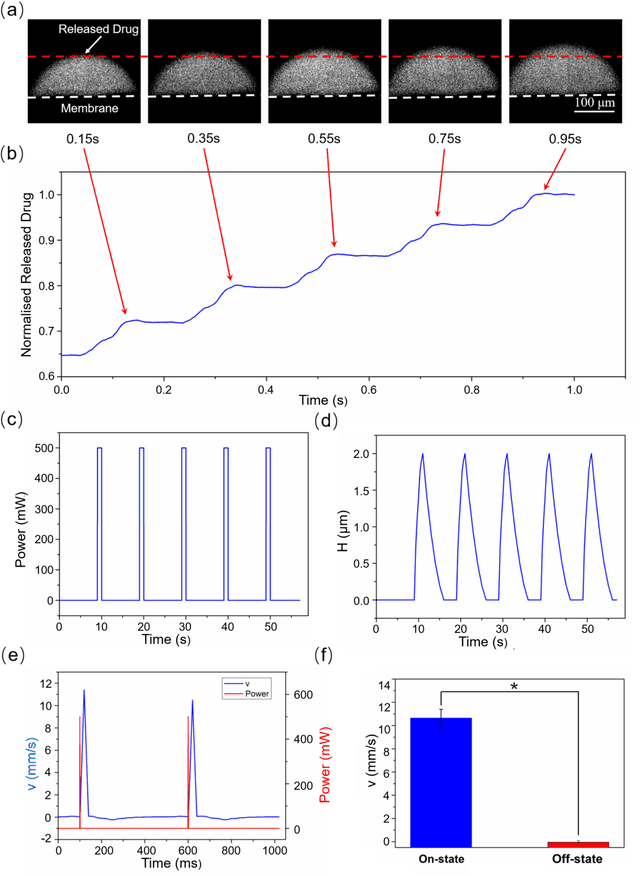
On-demand controlled drug delivery is essential for the treatment of a wide range of chronic diseases. As the drug is released at the time when required, its efficacy is boosted and the side effects are minimized. However, so far, drug delivery devices often rely on the passive diffusion process for a sustained release, which is slow and uncontrollable. Here, we present a miniaturized microfluidic device for wirelessly controlled ultrafast active drug delivery, driven by an oscillating solid-liquid interface. The oscillation generates acoustic streaming in the drug reservoir, which opens an elastic valve to deliver the drug. High-speed microscopy reveals the fast response of the valve on the order of 1 ms, which is more than three orders of magnitude faster than the start-of-the-art. The amount of the released drug exhibits a linear relationship with the working time and the electric power applied to the ultrasonic resonator. The trigger of the release is wirelessly controlled via a magnetic field, and the system shows stable output in a continuous experiment for two weeks. The integrated system shows great promise as a long-term controlled drug delivery implant for chronic diseases.
* 19 pages, 6 figures, 1 table
Towards Scene Graph Anticipation
Mar 07, 2024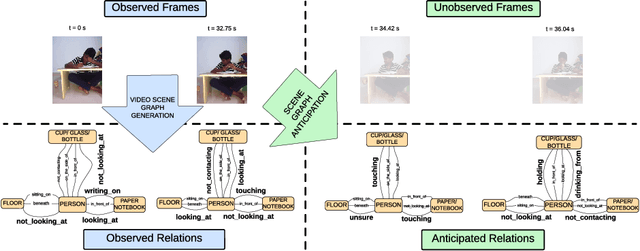
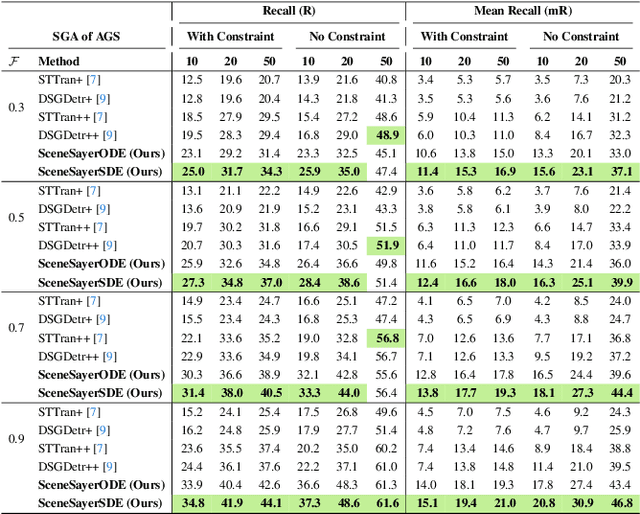
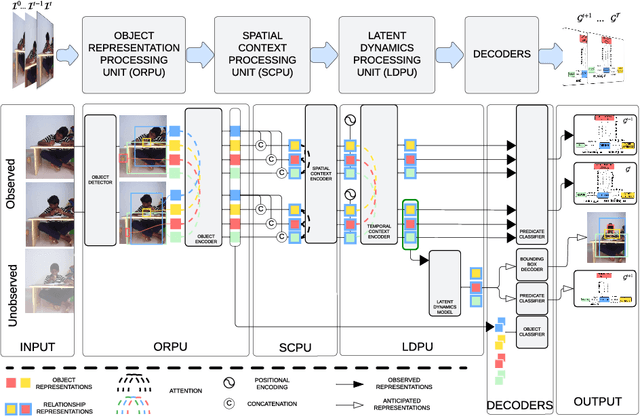
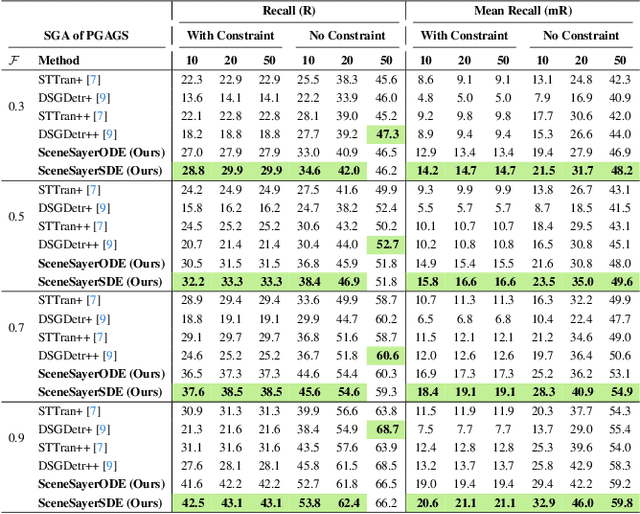
Spatio-temporal scene graphs represent interactions in a video by decomposing scenes into individual objects and their pair-wise temporal relationships. Long-term anticipation of the fine-grained pair-wise relationships between objects is a challenging problem. To this end, we introduce the task of Scene Graph Anticipation (SGA). We adapt state-of-the-art scene graph generation methods as baselines to anticipate future pair-wise relationships between objects and propose a novel approach SceneSayer. In SceneSayer, we leverage object-centric representations of relationships to reason about the observed video frames and model the evolution of relationships between objects. We take a continuous time perspective and model the latent dynamics of the evolution of object interactions using concepts of NeuralODE and NeuralSDE, respectively. We infer representations of future relationships by solving an Ordinary Differential Equation and a Stochastic Differential Equation, respectively. Extensive experimentation on the Action Genome dataset validates the efficacy of the proposed methods.
Efficient CNN-LSTM based Parameter Estimation of Levy Driven Stochastic Differential Equations
Mar 07, 2024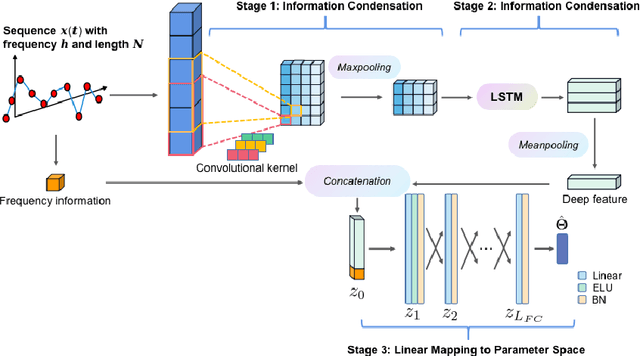
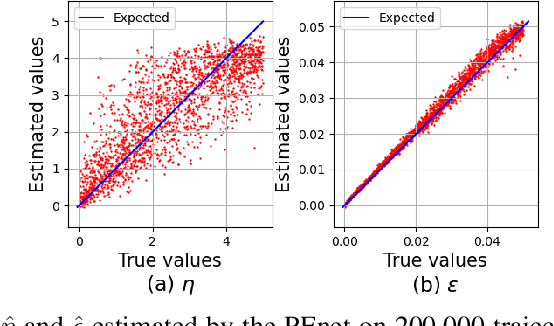
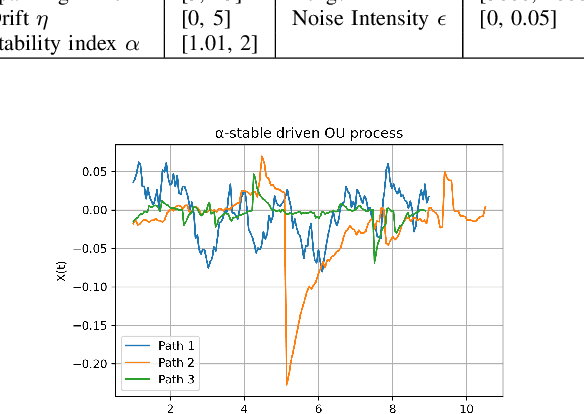
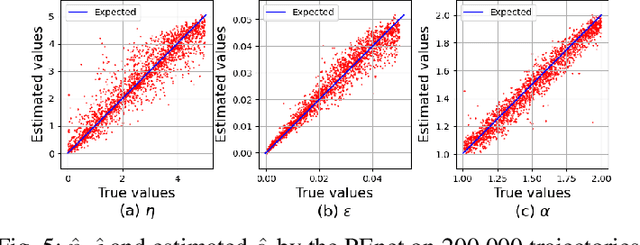
This study addresses the challenges in parameter estimation of stochastic differential equations driven by non-Gaussian noises, which are critical in understanding dynamic phenomena such as price fluctuations and the spread of infectious diseases. Previous research highlighted the potential of LSTM networks in estimating parameters of alpha stable Levy driven SDEs but faced limitations including high time complexity and constraints of the LSTM chaining property. To mitigate these issues, we introduce the PEnet, a novel CNN-LSTM-based three-stage model that offers an end to end approach with superior accuracy and adaptability to varying data structures, enhanced inference speed for long sequence observations through initial data feature condensation by CNN, and high generalization capability, allowing its application to various complex SDE scenarios. Experiments on synthetic datasets confirm PEnet significant advantage in estimating SDE parameters associated with noise characteristics, establishing it as a competitive method for SDE parameter estimation in the presence of Levy noise.