 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bag of States: A Non-sequential Approach to Video-based Engagement Measurement
Jan 17, 2023

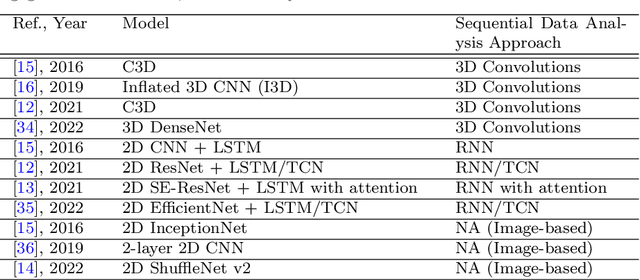
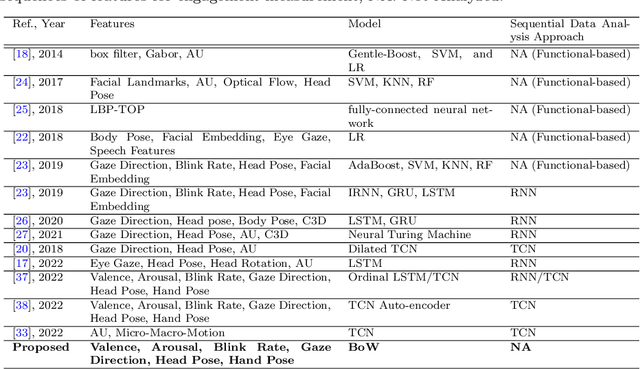
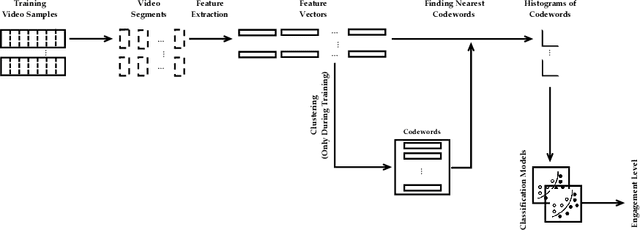
Automatic measurement of student engagement provides helpful information for instructors to meet learning program objectives and individualize program delivery. Students' behavioral and emotional states need to be analyzed at fine-grained time scales in order to measure their level of engagement. Many existing approaches have developed sequential and spatiotemporal models, such as recurrent neural networks, temporal convolutional networks, and three-dimensional convolutional neural networks, for measuring student engagement from videos. These models are trained to incorporate the order of behavioral and emotional states of students into video analysis and output their level of engagement. In this paper, backed by educational psychology, we question the necessity of modeling the order of behavioral and emotional states of students in measuring their engagement. We develop bag-of-words-based models in which only the occurrence of behavioral and emotional states of students is modeled and analyzed and not the order in which they occur. Behavioral and affective features are extracted from videos and analyzed by the proposed models to determine the level of engagement in an ordinal-output classification setting. Compared to the existing sequential and spatiotemporal approaches for engagement measurement, the proposed non-sequential approach improves the state-of-the-art results. According to experimental results, our method significantly improved engagement level classification accuracy on the IIITB Online SE dataset by 26% compared to sequential models and achieved engagement level classification accuracy as high as 66.58% on the DAiSEE student engagement dataset.
A reinforcement learning path planning approach for range-only underwater target localization with autonomous vehicles
Jan 17, 2023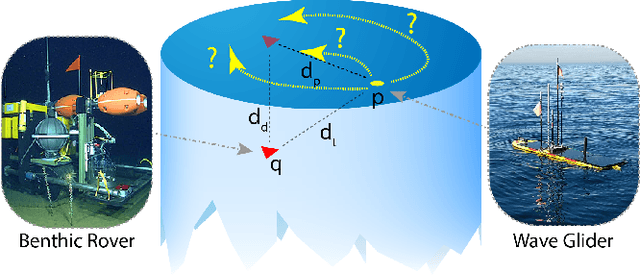
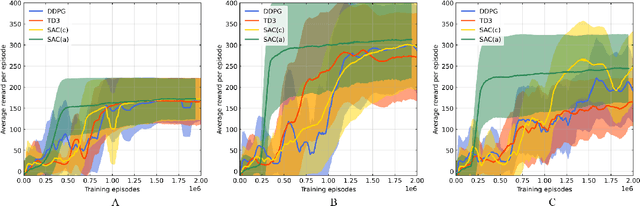
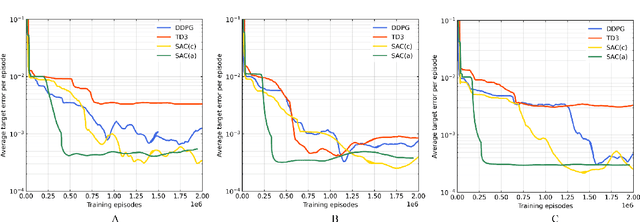
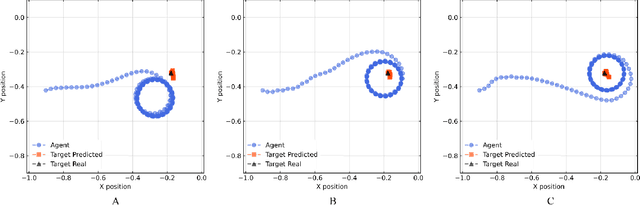
Underwater target localization using range-only and single-beacon (ROSB) techniques with autonomous vehicles has been used recently to improve the limitations of more complex methods, such as long baseline and ultra-short baseline systems. Nonetheless, in ROSB target localization methods, the trajectory of the tracking vehicle near the localized target plays an important role in obtaining the best accuracy of the predicted target position. Here, we investigate a Reinforcement Learning (RL) approach to find the optimal path that an autonomous vehicle should follow in order to increase and optimize the overall accuracy of the predicted target localization, while reducing time and power consumption. To accomplish this objective, different experimental tests have been designed using state-of-the-art deep RL algorithms. Our study also compares the results obtained with the analytical Fisher information matrix approach used in previous studies. The results revealed that the policy learned by the RL agent outperforms trajectories based on these analytical solutions, e.g. the median predicted error at the beginning of the target's localisation is 17% less. These findings suggest that using deep RL for localizing acoustic targets could be successfully applied to in-water applications that include tracking of acoustically tagged marine animals by autonomous underwater vehicles. This is envisioned as a first necessary step to validate the use of RL to tackle such problems, which could be used later on in a more complex scenarios
* Accepted at CASE2022. Code at this Github repository https://github.com/imasmitja/RLforUTracking
GraphGDP: Generative Diffusion Processes for Permutation Invariant Graph Generation
Dec 04, 2022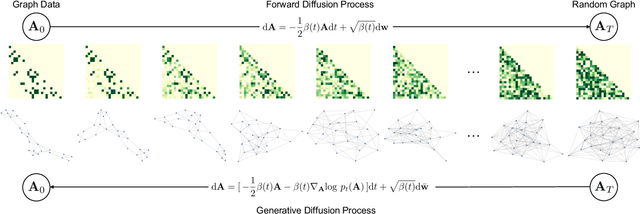
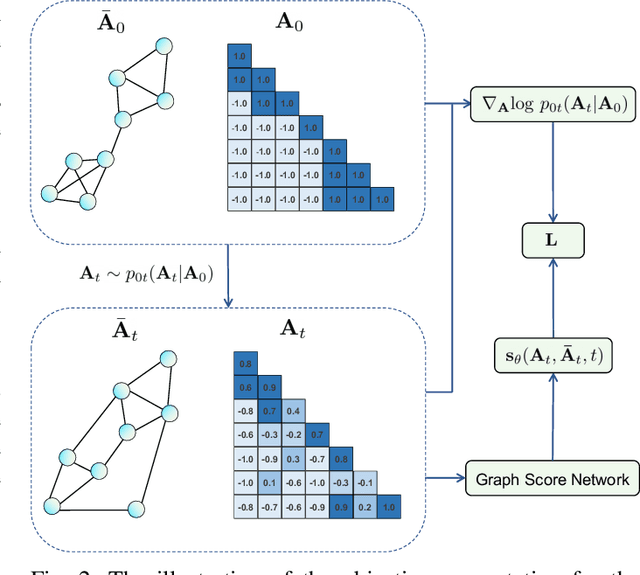
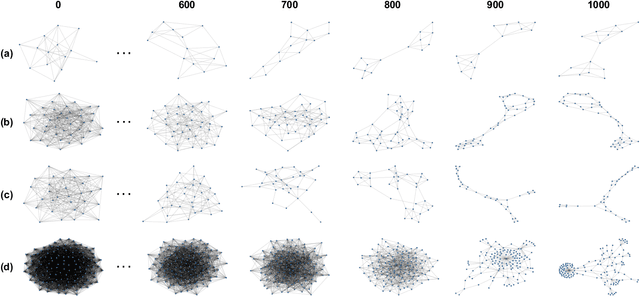
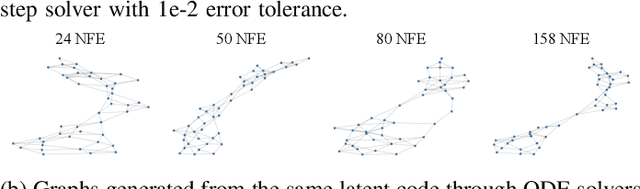
Graph generative models have broad applications in biology, chemistry and social science. However, modelling and understanding the generative process of graphs is challenging due to the discrete and high-dimensional nature of graphs, as well as permutation invariance to node orderings in underlying graph distributions. Current leading autoregressive models fail to capture the permutation invariance nature of graphs for the reliance on generation ordering and have high time complexity. Here, we propose a continuous-time generative diffusion process for permutation invariant graph generation to mitigate these issues. Specifically, we first construct a forward diffusion process defined by a stochastic differential equation (SDE), which smoothly converts graphs within the complex distribution to random graphs that follow a known edge probability. Solving the corresponding reverse-time SDE, graphs can be generated from newly sampled random graphs. To facilitate the reverse-time SDE, we newly design a position-enhanced graph score network, capturing the evolving structure and position information from perturbed graphs for permutation equivariant score estimation. Under the evaluation of comprehensive metrics, our proposed generative diffusion process achieves competitive performance in graph distribution learning. Experimental results also show that GraphGDP can generate high-quality graphs in only 24 function evaluations, much faster than previous autoregressive models.
A Strongly Polynomial Algorithm for Approximate Forster Transforms and its Application to Halfspace Learning
Dec 06, 2022The Forster transform is a method of regularizing a dataset by placing it in {\em radial isotropic position} while maintaining some of its essential properties. Forster transforms have played a key role in a diverse range of settings spanning computer science and functional analysis. Prior work had given {\em weakly} polynomial time algorithms for computing Forster transforms, when they exist. Our main result is the first {\em strongly polynomial time} algorithm to compute an approximate Forster transform of a given dataset or certify that no such transformation exists. By leveraging our strongly polynomial Forster algorithm, we obtain the first strongly polynomial time algorithm for {\em distribution-free} PAC learning of halfspaces. This learning result is surprising because {\em proper} PAC learning of halfspaces is {\em equivalent} to linear programming. Our learning approach extends to give a strongly polynomial halfspace learner in the presence of random classification noise and, more generally, Massart noise.
Learning Goal-Conditioned Policies Offline with Self-Supervised Reward Shaping
Jan 05, 2023
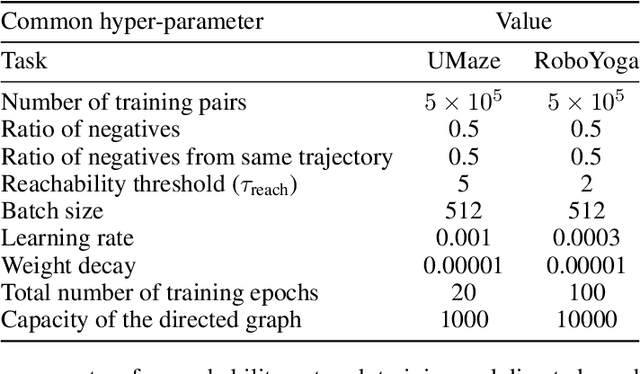
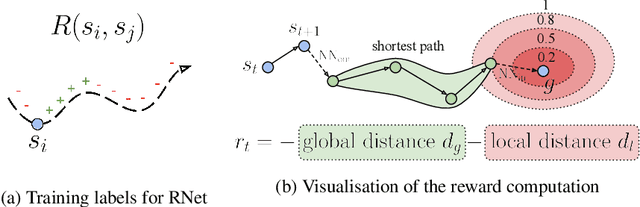

Developing agents that can execute multiple skills by learning from pre-collected datasets is an important problem in robotics, where online interaction with the environment is extremely time-consuming. Moreover, manually designing reward functions for every single desired skill is prohibitive. Prior works targeted these challenges by learning goal-conditioned policies from offline datasets without manually specified rewards, through hindsight relabelling. These methods suffer from the issue of sparsity of rewards, and fail at long-horizon tasks. In this work, we propose a novel self-supervised learning phase on the pre-collected dataset to understand the structure and the dynamics of the model, and shape a dense reward function for learning policies offline. We evaluate our method on three continuous control tasks, and show that our model significantly outperforms existing approaches, especially on tasks that involve long-term planning.
* Code: https://github.com/facebookresearch/go-fresh
Learning Representations that Enable Generalization in Assistive Tasks
Dec 05, 2022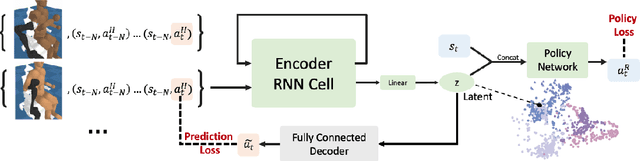
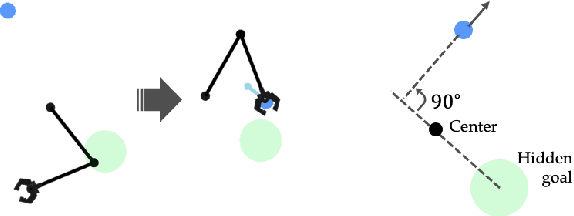
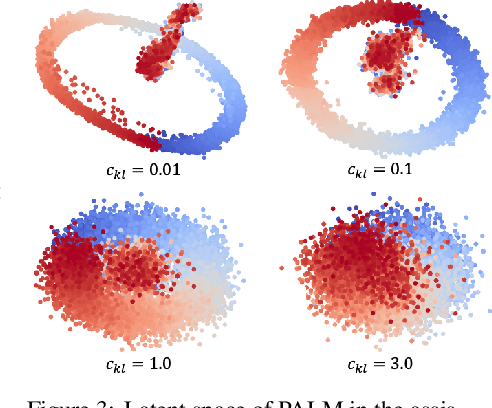
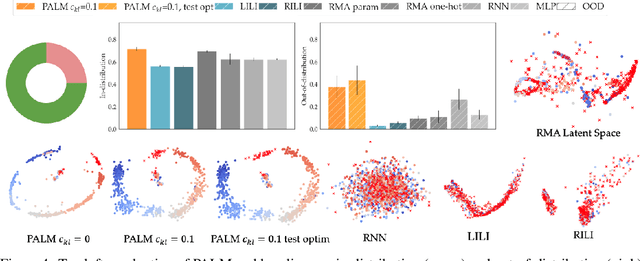
Recent work in sim2real has successfully enabled robots to act in physical environments by training in simulation with a diverse ''population'' of environments (i.e. domain randomization). In this work, we focus on enabling generalization in assistive tasks: tasks in which the robot is acting to assist a user (e.g. helping someone with motor impairments with bathing or with scratching an itch). Such tasks are particularly interesting relative to prior sim2real successes because the environment now contains a human who is also acting. This complicates the problem because the diversity of human users (instead of merely physical environment parameters) is more difficult to capture in a population, thus increasing the likelihood of encountering out-of-distribution (OOD) human policies at test time. We advocate that generalization to such OOD policies benefits from (1) learning a good latent representation for human policies that test-time humans can accurately be mapped to, and (2) making that representation adaptable with test-time interaction data, instead of relying on it to perfectly capture the space of human policies based on the simulated population only. We study how to best learn such a representation by evaluating on purposefully constructed OOD test policies. We find that sim2real methods that encode environment (or population) parameters and work well in tasks that robots do in isolation, do not work well in assistance. In assistance, it seems crucial to train the representation based on the history of interaction directly, because that is what the robot will have access to at test time. Further, training these representations to then predict human actions not only gives them better structure, but also enables them to be fine-tuned at test-time, when the robot observes the partner act. https://adaptive-caregiver.github.io.
E$^3$Pose: Energy-Efficient Edge-assisted Multi-camera System for Multi-human 3D Pose Estimation
Jan 21, 2023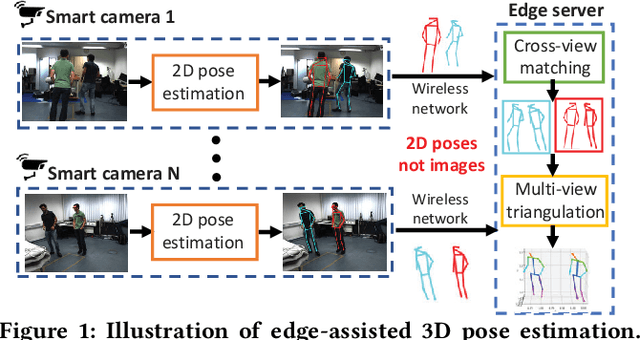
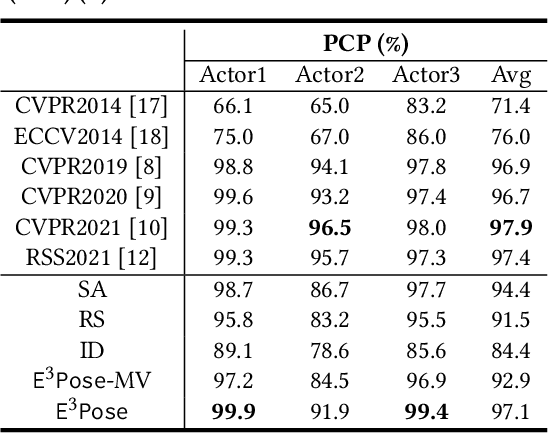
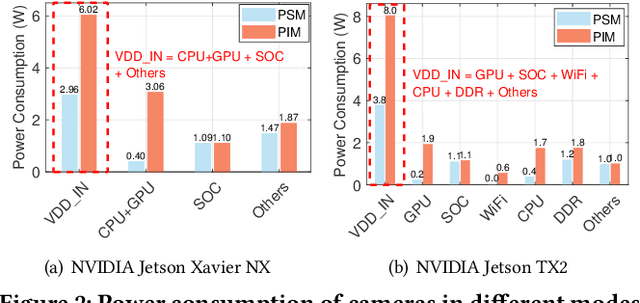
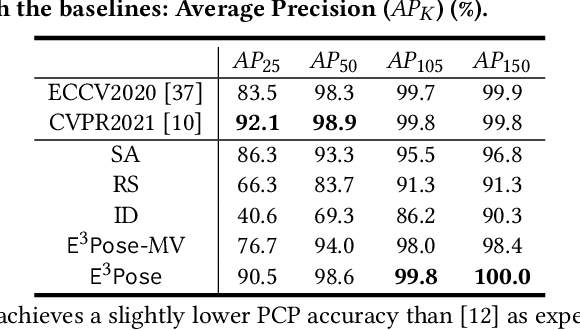
Multi-human 3D pose estimation plays a key role in establishing a seamless connection between the real world and the virtual world. Recent efforts adopted a two-stage framework that first builds 2D pose estimations in multiple camera views from different perspectives and then synthesizes them into 3D poses. However, the focus has largely been on developing new computer vision algorithms on the offline video datasets without much consideration on the energy constraints in real-world systems with flexibly-deployed and battery-powered cameras. In this paper, we propose an energy-efficient edge-assisted multiple-camera system, dubbed E$^3$Pose, for real-time multi-human 3D pose estimation, based on the key idea of adaptive camera selection. Instead of always employing all available cameras to perform 2D pose estimations as in the existing works, E$^3$Pose selects only a subset of cameras depending on their camera view qualities in terms of occlusion and energy states in an adaptive manner, thereby reducing the energy consumption (which translates to extended battery lifetime) and improving the estimation accuracy. To achieve this goal, E$^3$Pose incorporates an attention-based LSTM to predict the occlusion information of each camera view and guide camera selection before cameras are selected to process the images of a scene, and runs a camera selection algorithm based on the Lyapunov optimization framework to make long-term adaptive selection decisions. We build a prototype of E$^3$Pose on a 5-camera testbed, demonstrate its feasibility and evaluate its performance. Our results show that a significant energy saving (up to 31.21%) can be achieved while maintaining a high 3D pose estimation accuracy comparable to state-of-the-art methods.
Metaheuristic for Hub-Spoke Facility Location Problem: Application to Indian E-commerce Industry
Dec 16, 2022Indian e-commerce industry has evolved over the last decade and is expected to grow over the next few years. The focus has now shifted to turnaround time (TAT) due to the emergence of many third-party logistics providers and higher customer expectations. The key consideration for delivery providers is to balance their overall operating costs while meeting the promised TAT to their customers. E-commerce delivery partners operate through a network of facilities whose strategic locations help to run the operations efficiently. In this work, we identify the locations of hubs throughout the country and their corresponding mapping with the distribution centers. The objective is to minimize the total network costs with TAT adherence. We use Genetic Algorithm and leverage business constraints to reduce the solution search space and hence the solution time. The results indicate an improvement of 9.73% in TAT compliance compared with the current scenario.
AdvMIL: Adversarial Multiple Instance Learning for the Survival Analysis on Whole-Slide Images
Dec 13, 2022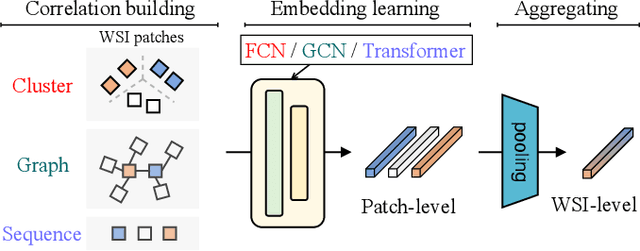
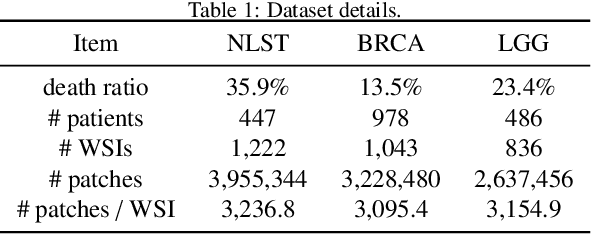
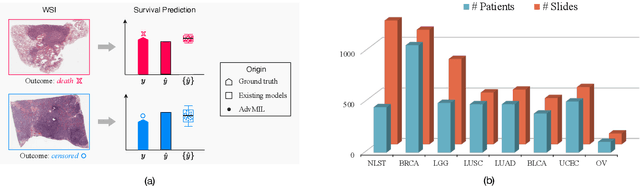

The survival analysis on histological whole-slide images (WSIs) is one of the most important means to estimate patient prognosis. Although many weakly-supervised deep learning models have been developed for gigapixel WSIs, their potential is generally restricted by classical survival analysis rules and fully-supervision requirements. As a result, these models provide patients only with a completely-certain point estimation of time-to-event, and they could only learn from the well-annotated WSI data currently at a small scale. To tackle these problems, we propose a novel adversarial multiple instance learning (AdvMIL) framework. This framework is based on adversarial time-to-event modeling, and it integrates the multiple instance learning (MIL) that is much necessary for WSI representation learning. It is a plug-and-play one, so that most existing WSI-based models with embedding-level MIL networks can be easily upgraded by applying this framework, gaining the improved ability of survival distribution estimation and semi-supervised learning. Our extensive experiments show that AdvMIL could not only bring performance improvement to mainstream WSI models at a relatively low computational cost, but also enable these models to learn from unlabeled data with semi-supervised learning. Our AdvMIL framework could promote the research of time-to-event modeling in computational pathology with its novel paradigm of adversarial MIL.
Causal Inference (C-inf) -- asymmetric scenario of typical phase transitions
Jan 02, 2023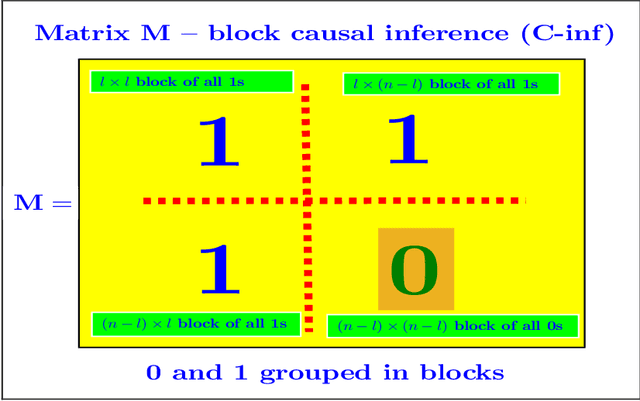
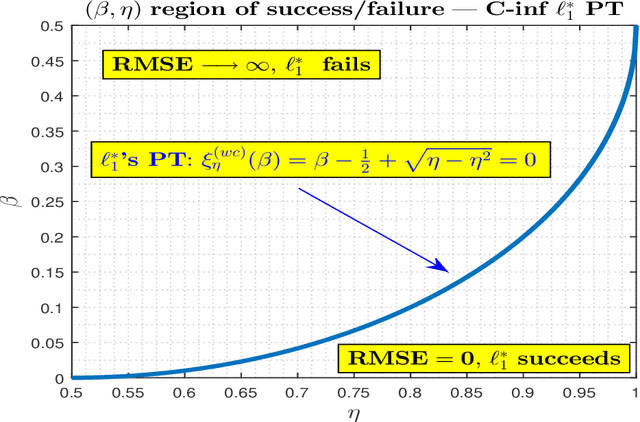
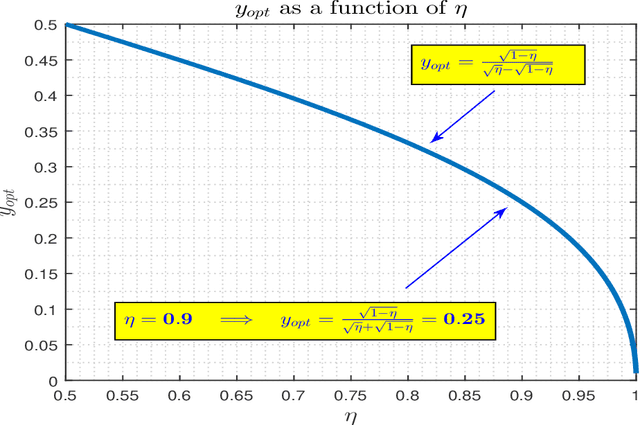
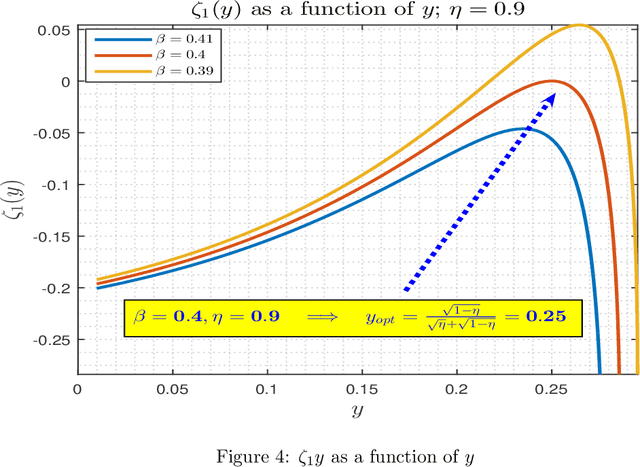
In this paper, we revisit and further explore a mathematically rigorous connection between Causal inference (C-inf) and the Low-rank recovery (LRR) established in [10]. Leveraging the Random duality - Free probability theory (RDT-FPT) connection, we obtain the exact explicit typical C-inf asymmetric phase transitions (PT). We uncover a doubling low-rankness phenomenon, which means that exactly two times larger low rankness is allowed in asymmetric scenarios compared to the symmetric worst case ones considered in [10]. Consequently, the final PT mathematical expressions are as elegant as those obtained in [10], and highlight direct relations between the targeted C-inf matrix low rankness and the time of treatment. Our results have strong implications for applications, where C-inf matrices are not necessarily symmetric.