 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comprehensive Architecture for Dynamic Role Allocation and Collaborative Task Planning in Mixed Human-Robot Teams
Jan 19, 2023
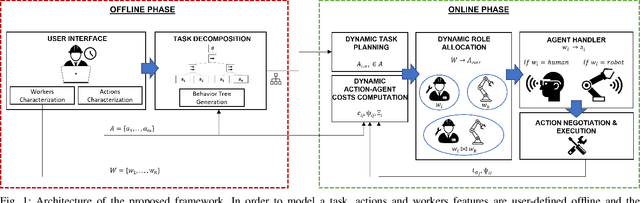

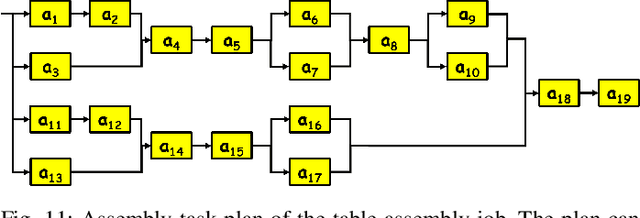
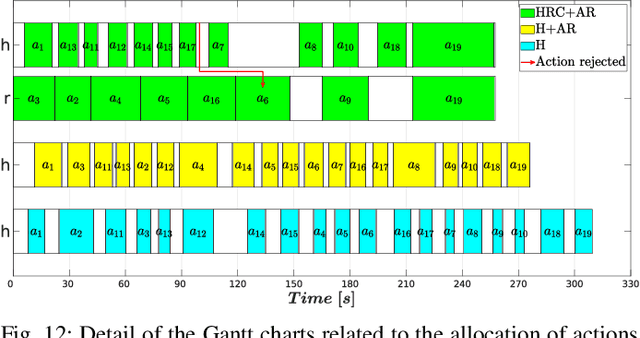
The growing deployment of human-robot collaborative processes in several industrial applications, such as handling, welding, and assembly, unfolds the pursuit of systems which are able to manage large heterogeneous teams and, at the same time, monitor the execution of complex tasks. In this paper, we present a novel architecture for dynamic role allocation and collaborative task planning in a mixed human-robot team of arbitrary size. The architecture capitalizes on a centralized reactive and modular task-agnostic planning method based on Behavior Trees (BTs), in charge of actions scheduling, while the allocation problem is formulated through a Mixed-Integer Linear Program (MILP), that assigns dynamically individual roles or collaborations to the agents of the team. Different metrics used as MILP cost allow the architecture to favor various aspects of the collaboration (e.g. makespan, ergonomics, human preferences). Human preference are identified through a negotiation phase, in which, an human agent can accept/refuse to execute the assigned task.In addition, bilateral communication between humans and the system is achieved through an Augmented Reality (AR) custom user interface that provides intuitive functionalities to assist and coordinate workers in different action phases. The computational complexity of the proposed methodology outperforms literature approaches in industrial sized jobs and teams (problems up to 50 actions and 20 agents in the team with collaborations are solved within 1\;s). The different allocated roles, as the cost functions change, highlights the flexibility of the architecture to several production requirements. Finally, the subjective evaluation demonstrating the high usability level and the suitability for the targeted scenario.
Regularizing disparity estimation via multi task learning with structured light reconstruction
Jan 19, 2023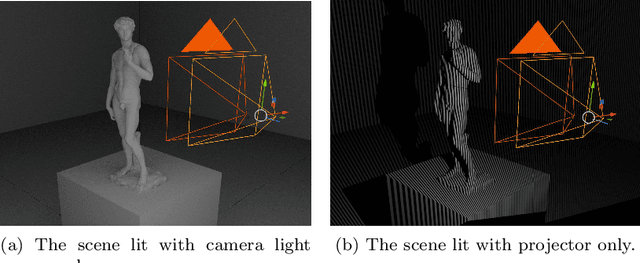

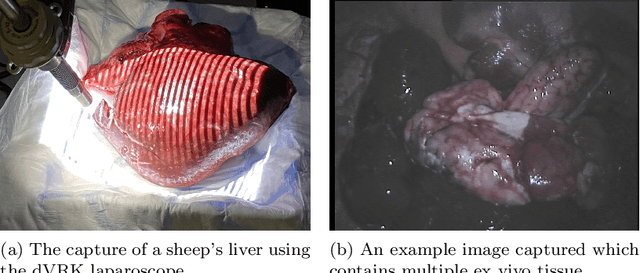
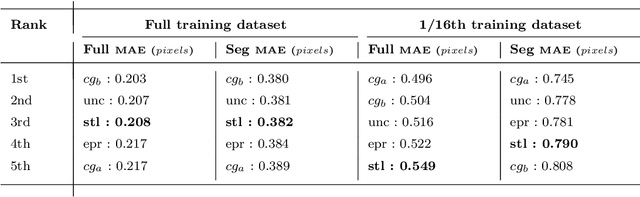
3D reconstruction is a useful tool for surgical planning and guidance. However, the lack of available medical data stunts research and development in this field, as supervised deep learning methods for accurate disparity estimation rely heavily on large datasets containing ground truth information. Alternative approaches to supervision have been explored, such as self-supervision, which can reduce or remove entirely the need for ground truth. However, no proposed alternatives have demonstrated performance capabilities close to what would be expected from a supervised setup. This work aims to alleviate this issue. In this paper, we investigate the learning of structured light projections to enhance the development of direct disparity estimation networks. We show for the first time that it is possible to accurately learn the projection of structured light on a scene, implicitly learning disparity. Secondly, we \textcolor{black}{explore the use of a multi task learning (MTL) framework for the joint training of structured light and disparity. We present results which show that MTL with structured light improves disparity training; without increasing the number of model parameters. Our MTL setup outperformed the single task learning (STL) network in every validation test. Notably, in the medical generalisation test, the STL error was 1.4 times worse than that of the best MTL performance. The benefit of using MTL is emphasised when the training data is limited.} A dataset containing stereoscopic images, disparity maps and structured light projections on medical phantoms and ex vivo tissue was created for evaluation together with virtual scenes. This dataset will be made publicly available in the future.
FWD: Real-time Novel View Synthesis with Forward Warping and Depth
Jun 21, 2022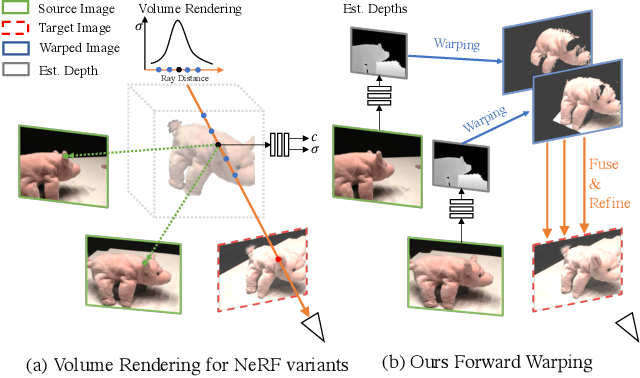


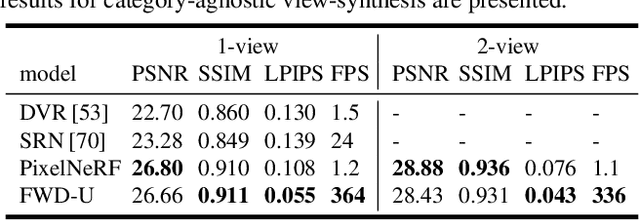
Novel view synthesis (NVS) is a challenging task requiring systems to generate photorealistic images of scenes from new viewpoints, where both quality and speed are important for applications. Previous image-based rendering (IBR) methods are fast, but have poor quality when input views are sparse. Recent Neural Radiance Fields (NeRF) and generalizable variants give impressive results but are not real-time. In our paper, we propose a generalizable NVS method with sparse inputs, called FWD, which gives high-quality synthesis in real-time. With explicit depth and differentiable rendering, it achieves competitive results to the SOTA methods with 130-1000x speedup and better perceptual quality. If available, we can seamlessly integrate sensor depth during either training or inference to improve image quality while retaining real-time speed. With the growing prevalence of depths sensors, we hope that methods making use of depth will become increasingly useful.
Modulation spectral features for speech emotion recognition using deep neural networks
Jan 14, 2023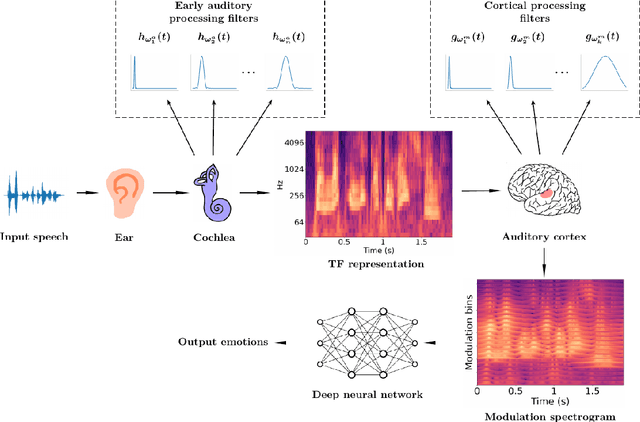
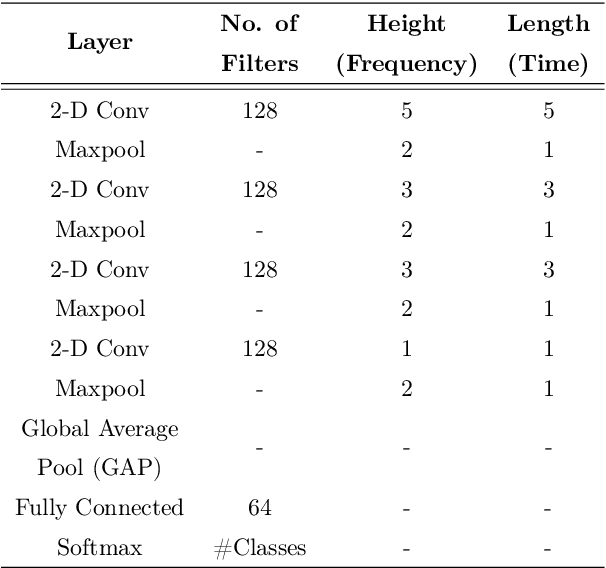


This work explores the use of constant-Q transform based modulation spectral features (CQT-MSF) for speech emotion recognition (SER). The human perception and analysis of sound comprise of two important cognitive parts: early auditory analysis and cortex-based processing. The early auditory analysis considers spectrogram-based representation whereas cortex-based analysis includes extraction of temporal modulations from the spectrogram. This temporal modulation representation of spectrogram is called modulation spectral feature (MSF). As the constant-Q transform (CQT) provides higher resolution at emotion salient low-frequency regions of speech, we find that CQT-based spectrogram, together with its temporal modulations, provides a representation enriched with emotion-specific information. We argue that CQT-MSF when used with a 2-dimensional convolutional network can provide a time-shift invariant and deformation insensitive representation for SER. Our results show that CQT-MSF outperforms standard mel-scale based spectrogram and its modulation features on two popular SER databases, Berlin EmoDB and RAVDESS. We also show that our proposed feature outperforms the shift and deformation invariant scattering transform coefficients, hence, showing the importance of joint hand-crafted and self-learned feature extraction instead of reliance on complete hand-crafted features. Finally, we perform Grad-CAM analysis to visually inspect the contribution of constant-Q modulation features over SER.
* Accepted for publication in Elsevier's Speech Communication Journal
$\texttt{tasksource}$: Structured Dataset Preprocessing Annotations for Frictionless Extreme Multi-Task Learning and Evaluation
Jan 14, 2023
The HuggingFace Datasets Hub hosts thousands of datasets. This provides exciting opportunities for language model training and evaluation. However, the datasets for a given type of task are stored with different schemas, and harmonization is harder than it seems (https://xkcd.com/927/). Multi-task training or evaluation requires manual work to fit data into task templates. Various initiatives independently address this problem by releasing the harmonized datasets or harmonization codes to preprocess datasets to the same format. We identify patterns across previous preprocessings, e.g. mapping of column names, and extraction of a specific sub-field from structured data in a column, and propose a structured annotation framework that makes our annotations fully exposed and not buried in unstructured code. We release a dataset annotation framework and dataset annotations for more than 400 English tasks (https://github.com/sileod/tasksource). These annotations provide metadata, like the name of the columns that should be used as input or labels for all datasets, and can save time for future dataset preprocessings, even if they do not use our framework. We fine-tune a multi-task text encoder on all tasksource tasks, outperforming every publicly available text encoder of comparable size on an external evaluation https://hf.co/sileod/deberta-v3-base-tasksource-nli.
Concentration of the Langevin Algorithm's Stationary Distribution
Dec 24, 2022A canonical algorithm for log-concave sampling is the Langevin Algorithm, aka the Langevin Diffusion run with some discretization stepsize $\eta > 0$. This discretization leads the Langevin Algorithm to have a stationary distribution $\pi_{\eta}$ which differs from the stationary distribution $\pi$ of the Langevin Diffusion, and it is an important challenge to understand whether the well-known properties of $\pi$ extend to $\pi_{\eta}$. In particular, while concentration properties such as isoperimetry and rapidly decaying tails are classically known for $\pi$, the analogous properties for $\pi_{\eta}$ are open questions with direct algorithmic implications. This note provides a first step in this direction by establishing concentration results for $\pi_{\eta}$ that mirror classical results for $\pi$. Specifically, we show that for any nontrivial stepsize $\eta > 0$, $\pi_{\eta}$ is sub-exponential (respectively, sub-Gaussian) when the potential is convex (respectively, strongly convex). Moreover, the concentration bounds we show are essentially tight. Key to our analysis is the use of a rotation-invariant moment generating function (aka Bessel function) to study the stationary dynamics of the Langevin Algorithm. This technique may be of independent interest because it enables directly analyzing the discrete-time stationary distribution $\pi_{\eta}$ without going through the continuous-time stationary distribution $\pi$ as an intermediary.
An optimized fuzzy logic model for proactive maintenance
Dec 24, 2022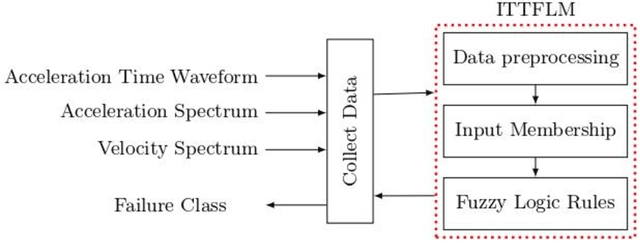
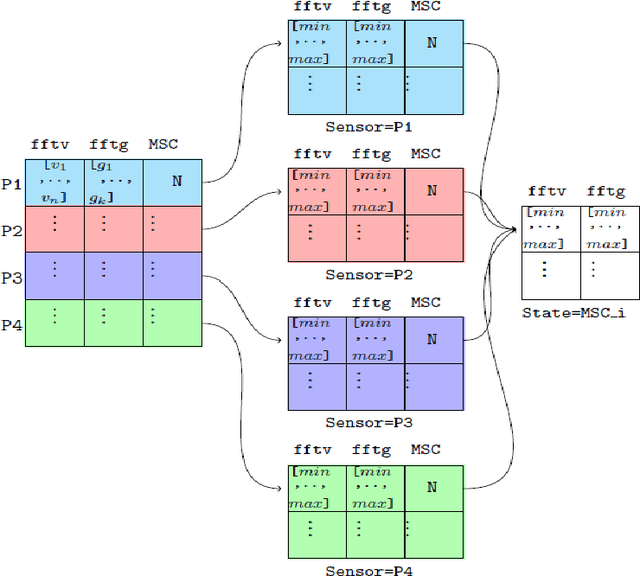

Fuzzy logic has been proposed in previous studies for machine diagnosis, to overcome different drawbacks of the traditional diagnostic approaches used. Among these approaches Failure Mode and Effect Critical Analysis method(FMECA) attempts to identify potential modes and treat failures before they occur based on subjective expert judgments. Although several versions of fuzzy logic are used to improve FMECA or to replace it, since it is an extremely cost-intensive approach in terms of failure modes because it evaluates each one of them separately, these propositions have not explicitly focused on the combinatorial complexity nor justified the choice of membership functions in Fuzzy logic modeling. Within this context, we develop an optimization-based approach referred to Integrated Truth Table and Fuzzy Logic Model (ITTFLM) that smartly generates fuzzy logic rules using Truth Tables. The ITTFLM was tested on fan data collected in real-time from a plant machine. In the experiment, three types of membership functions (Triangular, Trapezoidal, and Gaussian) were used. The ITTFLM can generate outputs in 5ms, the results demonstrate that this model based on the Trapezoidal membership functions identifies the failure states with high accuracy, and its capability of dealing with large numbers of rules and thus meets the real-time constraints that usually impact user experience.
SeqDiffuSeq: Text Diffusion with Encoder-Decoder Transformers
Dec 20, 2022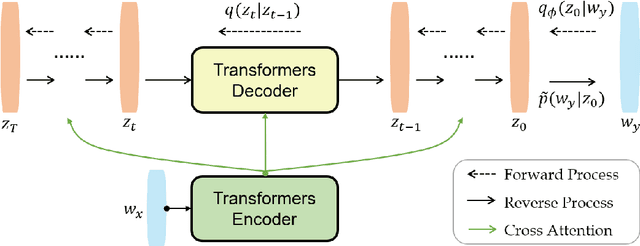
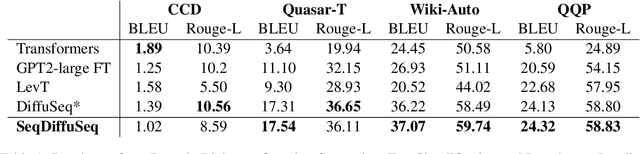

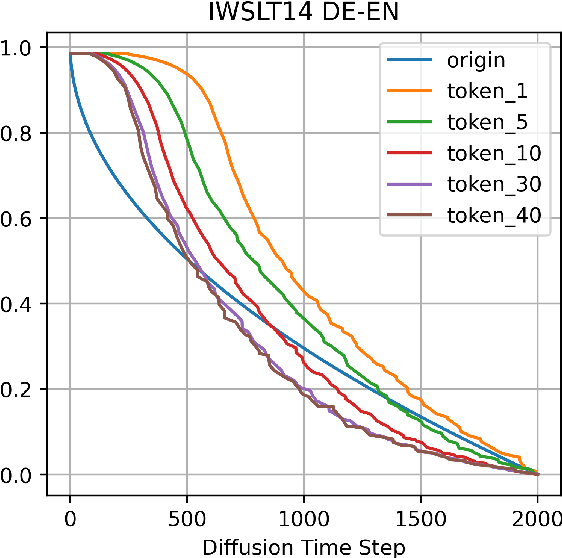
Diffusion model, a new generative modelling paradigm, has achieved great success in image, audio, and video generation. However, considering the discrete categorical nature of text, it is not trivial to extend continuous diffusion models to natural language, and text diffusion models are less studied. Sequence-to-sequence text generation is one of the essential natural language processing topics. In this work, we apply diffusion models to approach sequence-to-sequence text generation, and explore whether the superiority generation performance of diffusion model can transfer to natural language domain. We propose SeqDiffuSeq, a text diffusion model for sequence-to-sequence generation. SeqDiffuSeq uses an encoder-decoder Transformers architecture to model denoising function. In order to improve generation quality, SeqDiffuSeq combines the self-conditioning technique and a newly proposed adaptive noise schedule technique. The adaptive noise schedule has the difficulty of denoising evenly distributed across time steps, and considers exclusive noise schedules for tokens at different positional order. Experiment results illustrate the good performance on sequence-to-sequence generation in terms of text quality and inference time.
R$^3$LIVE++: A Robust, Real-time, Radiance reconstruction package with a tightly-coupled LiDAR-Inertial-Visual state Estimator
Sep 08, 2022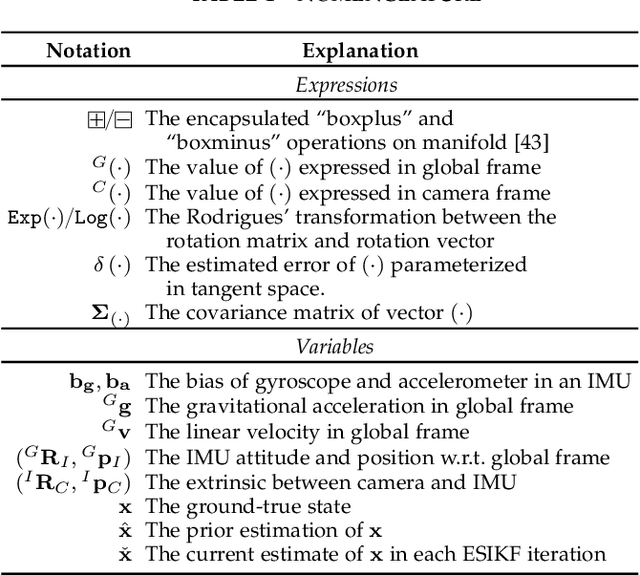

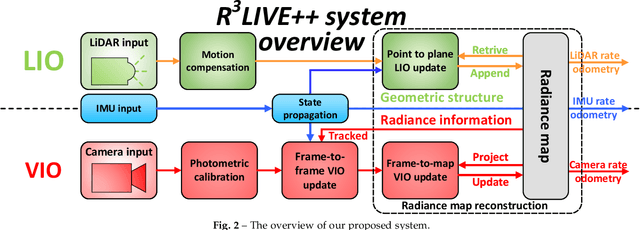
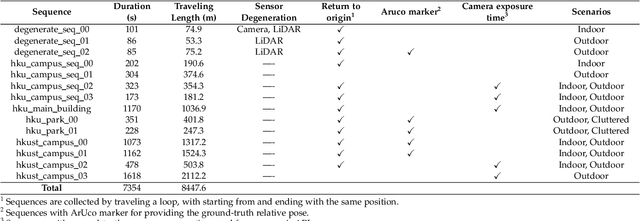
Simultaneous localization and mapping (SLAM) are crucial for autonomous robots (e.g., self-driving cars, autonomous drones), 3D mapping systems, and AR/VR applications. This work proposed a novel LiDAR-inertial-visual fusion framework termed R$^3$LIVE++ to achieve robust and accurate state estimation while simultaneously reconstructing the radiance map on the fly. R$^3$LIVE++ consists of a LiDAR-inertial odometry (LIO) and a visual-inertial odometry (VIO), both running in real-time. The LIO subsystem utilizes the measurements from a LiDAR for reconstructing the geometric structure (i.e., the positions of 3D points), while the VIO subsystem simultaneously recovers the radiance information of the geometric structure from the input images. R$^3$LIVE++ is developed based on R$^3$LIVE and further improves the accuracy in localization and mapping by accounting for the camera photometric calibration (e.g., non-linear response function and lens vignetting) and the online estimation of camera exposure time. We conduct more extensive experiments on both public and our private datasets to compare our proposed system against other state-of-the-art SLAM systems. Quantitative and qualitative results show that our proposed system has significant improvements over others in both accuracy and robustness. In addition, to demonstrate the extendability of our work, {we developed several applications based on our reconstructed radiance maps, such as high dynamic range (HDR) imaging, virtual environment exploration, and 3D video gaming.} Lastly, to share our findings and make contributions to the community, we make our codes, hardware design, and dataset publicly available on our Github: github.com/hku-mars/r3live
Semi-Supervised Learning of Monocular Depth Estimation via Consistency Regularization with K-way Disjoint Masking
Dec 22, 2022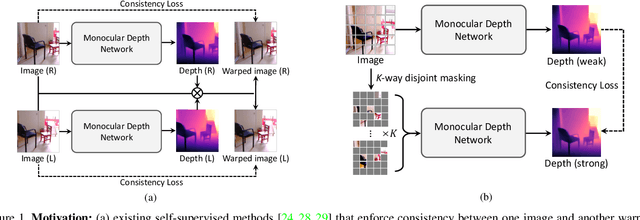
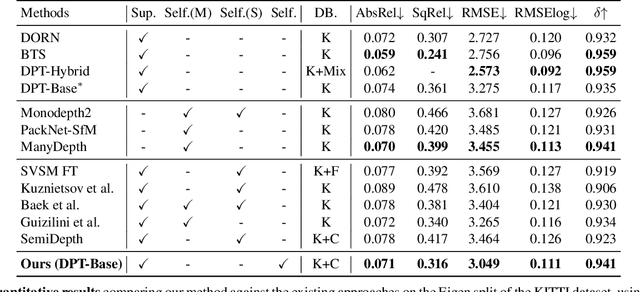
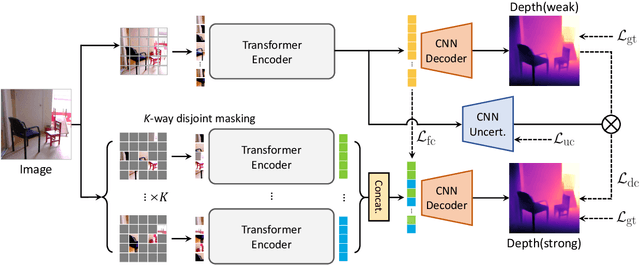
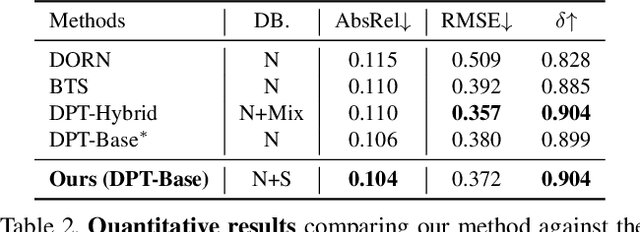
Semi-Supervised Learning (SSL) has recently accomplished successful achievements in various fields such as image classification, object detection, and semantic segmentation, which typically require a lot of labour to construct ground-truth. Especially in the depth estimation task, annotating training data is very costly and time-consuming, and thus recent SSL regime seems an attractive solution. In this paper, for the first time, we introduce a novel framework for semi-supervised learning of monocular depth estimation networks, using consistency regularization to mitigate the reliance on large ground-truth depth data. We propose a novel data augmentation approach, called K-way disjoint masking, which allows the network for learning how to reconstruct invisible regions so that the model not only becomes robust to perturbations but also generates globally consistent output depth maps. Experiments on the KITTI and NYU-Depth-v2 datasets demonstrate the effectiveness of each component in our pipeline, robustness to the use of fewer and fewer annotated images, and superior results compared to other state-of-the-art, semi-supervised methods for monocular depth estimation. Our code is available at https://github.com/KU-CVLAB/MaskingDepth.