 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Out-of-Distribution Detection in Time-Series Domain: A Novel Seasonal Ratio Scoring Approach
Jul 09, 2022
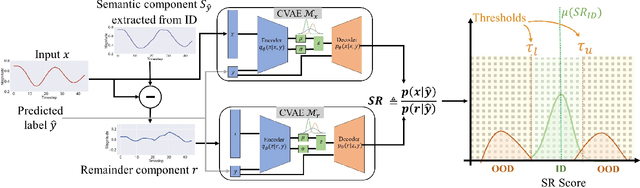


Safe deployment of time-series classifiers for real-world applications relies on the ability to detect the data which is not generated from the same distribution as training data. This task is referred to as out-of-distribution (OOD) detection. We consider the novel problem of OOD detection for the time-series domain. We discuss the unique challenges posed by time-series data and explain why prior methods from the image domain will perform poorly. Motivated by these challenges, this paper proposes a novel {\em Seasonal Ratio Scoring (SRS)} approach. SRS consists of three key algorithmic steps. First, each input is decomposed into class-wise semantic component and remainder. Second, this decomposition is employed to estimate the class-wise conditional likelihoods of the input and remainder using deep generative models. The seasonal ratio score is computed from these estimates. Third, a threshold interval is identified from the in-distribution data to detect OOD examples. Experiments on diverse real-world benchmarks demonstrate that the SRS method is well-suited for time-series OOD detection when compared to baseline methods. Open-source code for SRS method is provided at https://github.com/tahabelkhouja/SRS
Transformers as Algorithms: Generalization and Implicit Model Selection in In-context Learning
Jan 17, 2023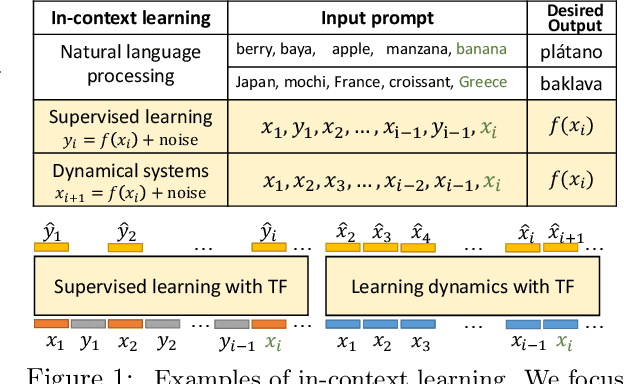
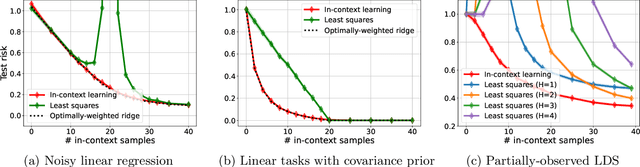
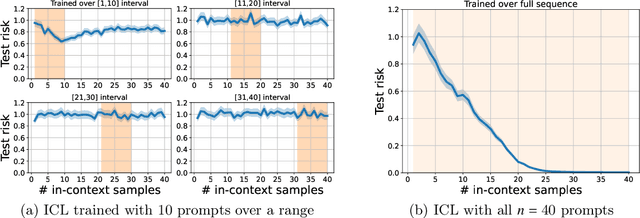
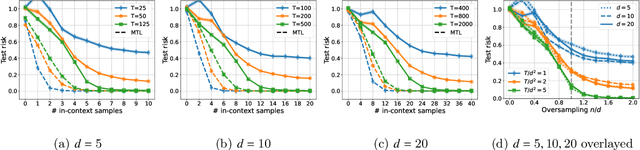
In-context learning (ICL) is a type of prompting where a transformer model operates on a sequence of (input, output) examples and performs inference on-the-fly. This implicit training is in contrast to explicitly tuning the model weights based on examples. In this work, we formalize in-context learning as an algorithm learning problem, treating the transformer model as a learning algorithm that can be specialized via training to implement-at inference-time-another target algorithm. We first explore the statistical aspects of this abstraction through the lens of multitask learning: We obtain generalization bounds for ICL when the input prompt is (1) a sequence of i.i.d. (input, label) pairs or (2) a trajectory arising from a dynamical system. The crux of our analysis is relating the excess risk to the stability of the algorithm implemented by the transformer, which holds under mild assumptions. Secondly, we use our abstraction to show that transformers can act as an adaptive learning algorithm and perform model selection across different hypothesis classes. We provide numerical evaluations that (1) demonstrate transformers can indeed implement near-optimal algorithms on classical regression problems with i.i.d. and dynamic data, (2) identify an inductive bias phenomenon where the transfer risk on unseen tasks is independent of the transformer complexity, and (3) empirically verify our theoretical predictions.
Algorithms for Acyclic Weighted Finite-State Automata with Failure Arcs
Jan 17, 2023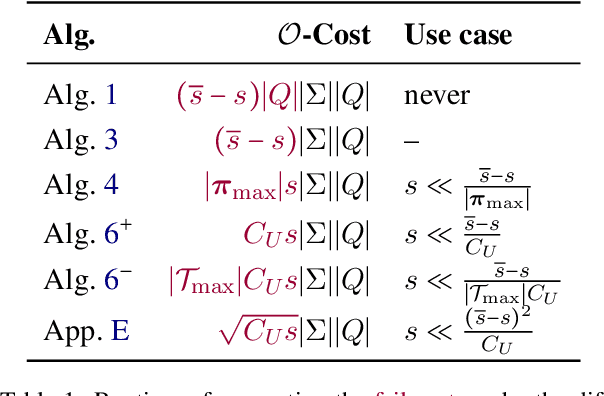
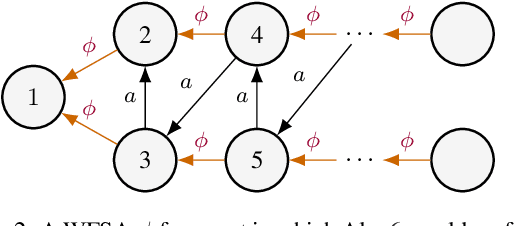
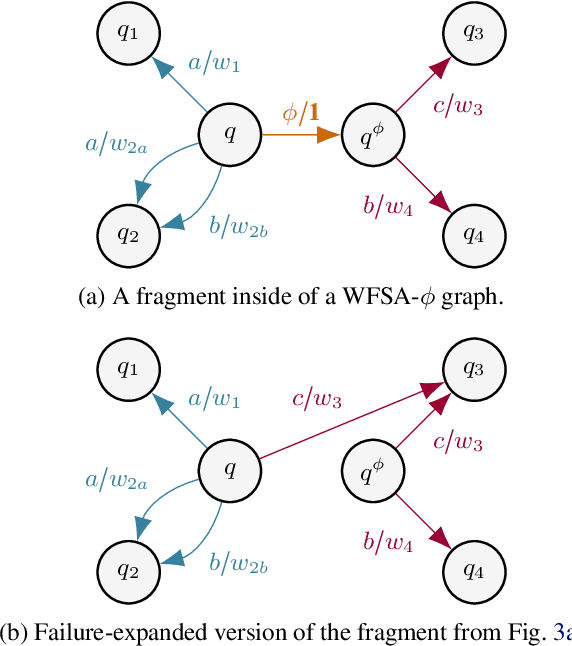
Weighted finite-state automata (WSFAs) are commonly used in NLP. Failure transitions are a useful extension for compactly representing backoffs or interpolation in $n$-gram models and CRFs, which are special cases of WFSAs. The pathsum in ordinary acyclic WFSAs is efficiently computed by the backward algorithm in time $O(|E|)$, where $E$ is the set of transitions. However, this does not allow failure transitions, and preprocessing the WFSA to eliminate failure transitions could greatly increase $|E|$. We extend the backward algorithm to handle failure transitions directly. Our approach is efficient when the average state has outgoing arcs for only a small fraction $s \ll 1$ of the alphabet $\Sigma$. We propose an algorithm for general acyclic WFSAs which runs in $O{\left(|E| + s |\Sigma| |Q| T_\text{max} \log{|\Sigma|}\right)}$, where $Q$ is the set of states and $T_\text{max}$ is the size of the largest connected component of failure transitions. When the failure transition topology satisfies a condition exemplified by CRFs, the $T_\text{max}$ factor can be dropped, and when the weight semiring is a ring, the $\log{|\Sigma|}$ factor can be dropped. In the latter case (ring-weighted acyclic WFSAs), we also give an alternative algorithm with complexity $\displaystyle O{\left(|E| + |\Sigma| |Q| \min(1,s\pi_\text{max}) \right)}$, where $\pi_\text{max}$ is the size of the longest failure path.
Quantifying and Managing Impacts of Concept Drifts on IoT Traffic Inference in Residential ISP Networks
Jan 17, 2023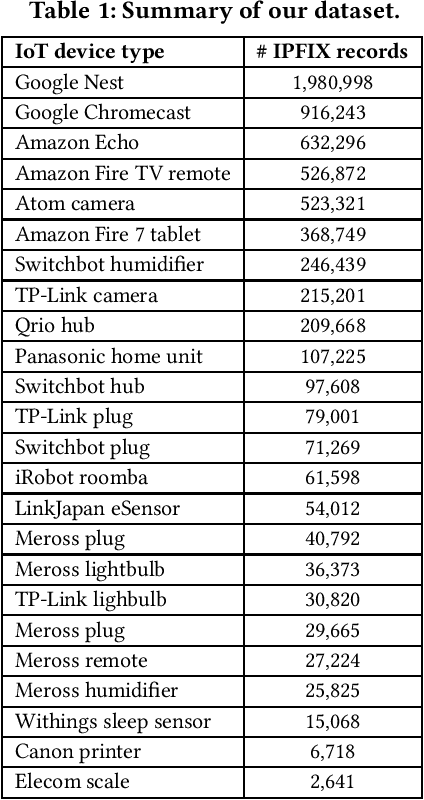
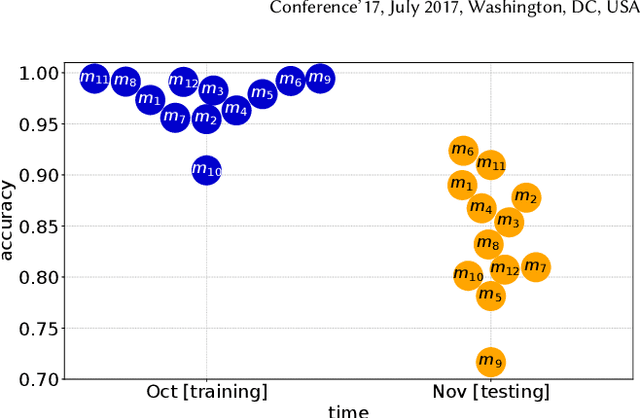
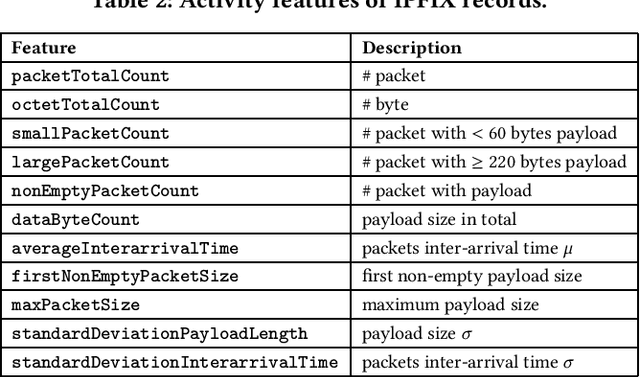
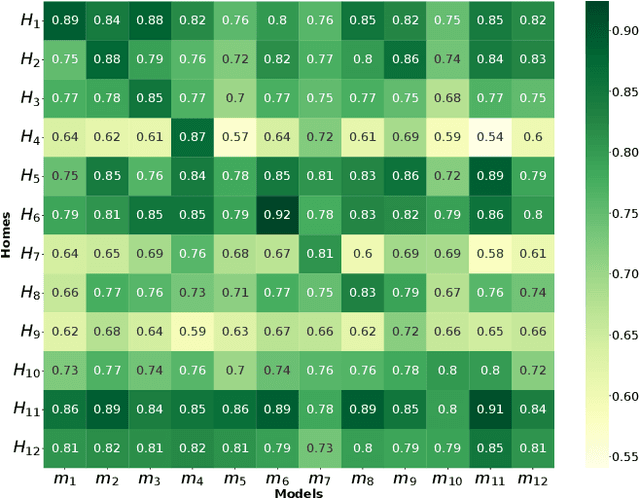
Millions of vulnerable consumer IoT devices in home networks are the enabler for cyber crimes putting user privacy and Internet security at risk. Internet service providers (ISPs) are best poised to play key roles in mitigating risks by automatically inferring active IoT devices per household and notifying users of vulnerable ones. Developing a scalable inference method that can perform robustly across thousands of home networks is a non-trivial task. This paper focuses on the challenges of developing and applying data-driven inference models when labeled data of device behaviors is limited and the distribution of data changes (concept drift) across time and space domains. Our contributions are three-fold: (1) We collect and analyze network traffic of 24 types of consumer IoT devices from 12 real homes over six weeks to highlight the challenge of temporal and spatial concept drifts in network behavior of IoT devices; (2) We analyze the performance of two inference strategies, namely "global inference" (a model trained on a combined set of all labeled data from training homes) and "contextualized inference" (several models each trained on the labeled data from a training home) in the presence of concept drifts; and (3) To manage concept drifts, we develop a method that dynamically applies the ``closest'' model (from a set) to network traffic of unseen homes during the testing phase, yielding better performance in 20% of scenarios.
RF Signal Source Search and Localization Using an Autonomous UAV with Predefined Waypoints
Jan 17, 2023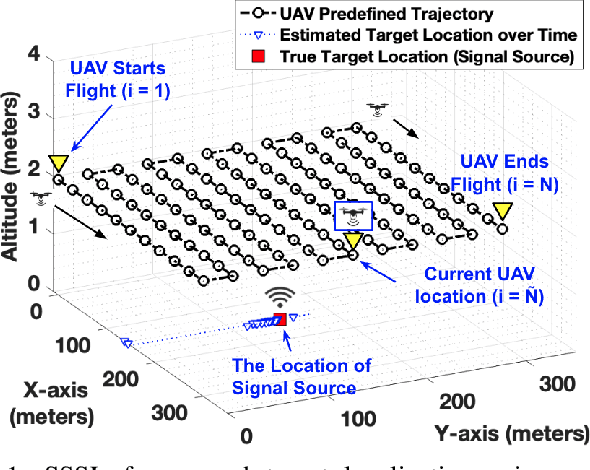
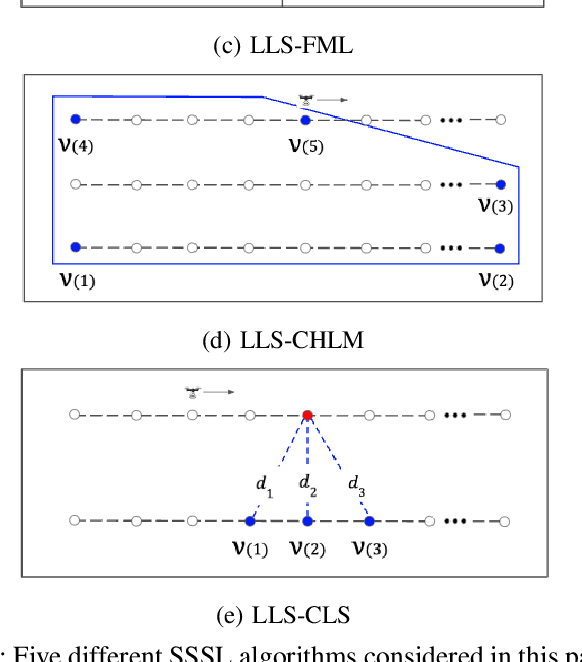
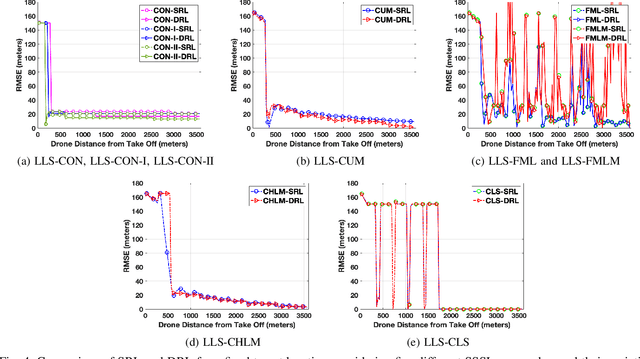
Localization of a radio frequency (RF) signal source has various use cases, ranging from search and rescue, identification and deactivation of jammers, and tracking hostile activity near borders or on the battlefield. The use of unmanned aerial vehicles (UAVs) for signal source search and localization (SSSL) can have significant advantages when compared to terrestrial-based approaches, due to the ease of capturing RF signals at higher altitudes and the autonomous 3D navigation capabilities of UAVs. However, the limited flight duration of UAVs due to battery constraints, as well as limited computational resources on board of lightweight UAVs introduce challenges for SSSL. In this paper, we study various SSSL techniques using a UAV with predefined waypoints. A linear least square (LLS) based localization scheme is considered with enhanced reference selection due to its relatively lower computational complexity. Five different LLS localization algorithms are proposed and studied for selecting anchor positions to be used for localization as the UAV navigates through an area. The performance of each algorithm is measured in two ways: 1) real-time positioning accuracy during the ongoing UAV flight, and 2) long-term accuracy measured at the end of the UAV flight. We compare and analyze the performance of the proposed approaches using computer simulations in terms of accuracy, UAV flight distance, and reliability.
Event-based Shape from Polarization
Jan 17, 2023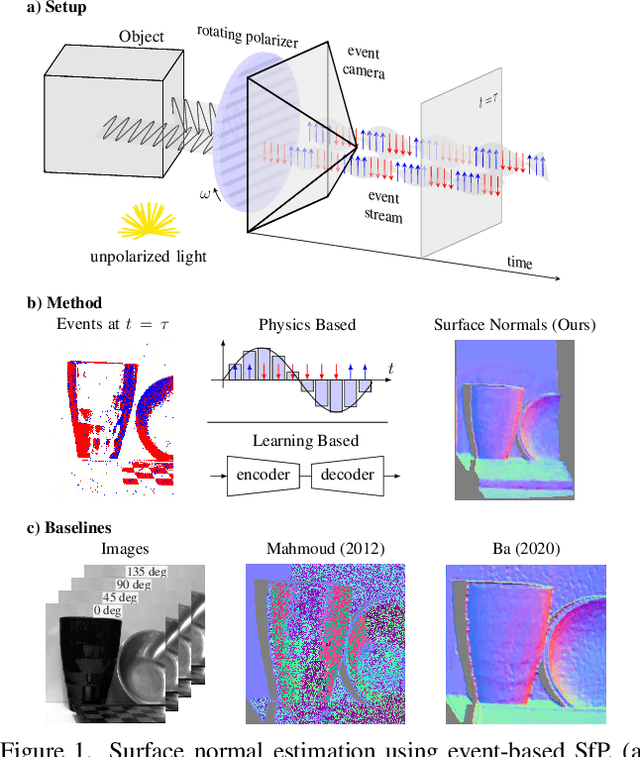

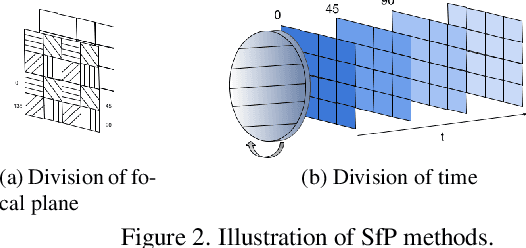
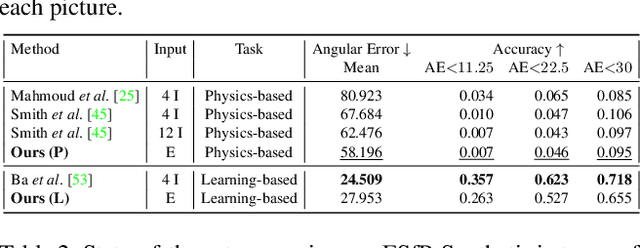
State-of-the-art solutions for Shape-from-Polarization (SfP) suffer from a speed-resolution tradeoff: they either sacrifice the number of polarization angles measured or necessitate lengthy acquisition times due to framerate constraints, thus compromising either accuracy or latency. We tackle this tradeoff using event cameras. Event cameras operate at microseconds resolution with negligible motion blur, and output a continuous stream of events that precisely measures how light changes over time asynchronously. We propose a setup that consists of a linear polarizer rotating at high-speeds in front of an event camera. Our method uses the continuous event stream caused by the rotation to reconstruct relative intensities at multiple polarizer angles. Experiments demonstrate that our method outperforms physics-based baselines using frames, reducing the MAE by 25% in synthetic and real-world dataset. In the real world, we observe, however, that the challenging conditions (i.e., when few events are generated) harm the performance of physics-based solutions. To overcome this, we propose a learning-based approach that learns to estimate surface normals even at low event-rates, improving the physics-based approach by 52% on the real world dataset. The proposed system achieves an acquisition speed equivalent to 50 fps (>twice the framerate of the commercial polarization sensor) while retaining the spatial resolution of 1MP. Our evaluation is based on the first large-scale dataset for event-based SfP
Multi-Modal and Multi-Factor Branching Time Active Inference
Jun 24, 2022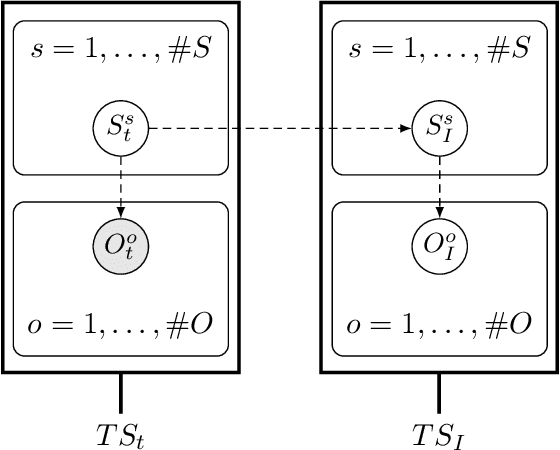
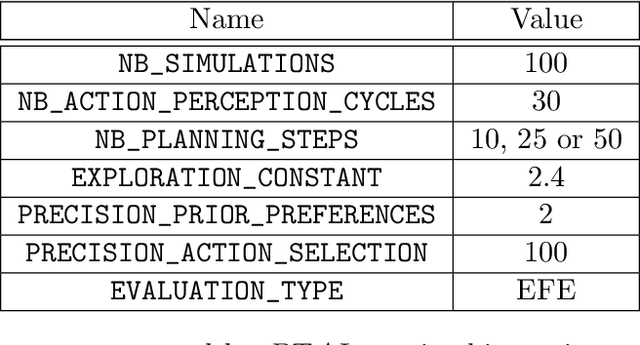
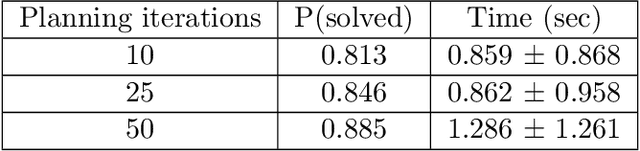
Active inference is a state-of-the-art framework for modelling the brain that explains a wide range of mechanisms such as habit formation, dopaminergic discharge and curiosity. Recently, two versions of branching time active inference (BTAI) based on Monte-Carlo tree search have been developed to handle the exponential (space and time) complexity class that occurs when computing the prior over all possible policies up to the time horizon. However, those two versions of BTAI still suffer from an exponential complexity class w.r.t the number of observed and latent variables being modelled. In the present paper, we resolve this limitation by first allowing the modelling of several observations, each of them having its own likelihood mapping. Similarly, we allow each latent state to have its own transition mapping. The inference algorithm then exploits the factorisation of the likelihood and transition mappings to accelerate the computation of the posterior. Those two optimisations were tested on the dSprites environment in which the metadata of the dSprites dataset was used as input to the model instead of the dSprites images. On this task, $BTAI_{VMP}$ (Champion et al., 2022b,a) was able to solve 96.9\% of the task in 5.1 seconds, and $BTAI_{BF}$ (Champion et al., 2021a) was able to solve 98.6\% of the task in 17.5 seconds. Our new approach ($BTAI_{3MF}$) outperformed both of its predecessors by solving the task completly (100\%) in only 2.559 seconds. Finally, $BTAI_{3MF}$ has been implemented in a flexible and easy to use (python) package, and we developed a graphical user interface to enable the inspection of the model's beliefs, planning process and behaviour.
Constant Approximation for Normalized Modularity and Associations Clustering
Dec 29, 2022We study the problem of graph clustering under a broad class of objectives in which the quality of a cluster is defined based on the ratio between the number of edges in the cluster, and the total weight of vertices in the cluster. We show that our definition is closely related to popular clustering measures, namely normalized associations, which is a dual of the normalized cut objective, and normalized modularity. We give a linear time constant-approximate algorithm for our objective, which implies the first constant-factor approximation algorithms for normalized modularity and normalized associations.
SupervisorBot: NLP-Annotated Real-Time Recommendations of Psychotherapy Treatment Strategies with Deep Reinforcement Learning
Aug 27, 2022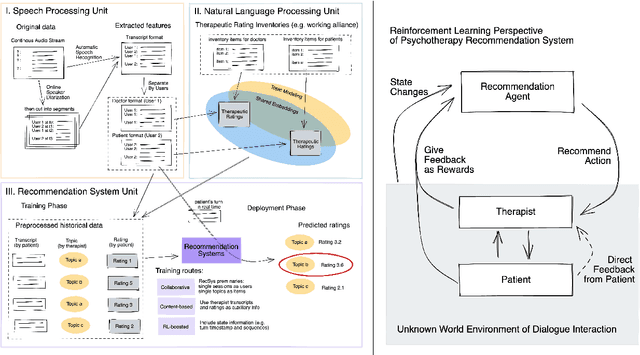

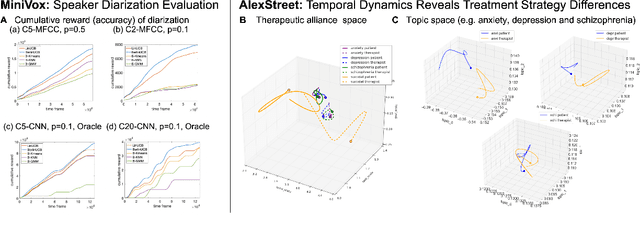

We propose a recommendation system that suggests treatment strategies to a therapist during the psychotherapy session in real-time. Our system uses a turn-level rating mechanism that predicts the therapeutic outcome by computing a similarity score between the deep embedding of a scoring inventory, and the current sentence that the patient is speaking. The system automatically transcribes a continuous audio stream and separates it into turns of the patient and of the therapist using an online registration-free diarization method. The dialogue pairs along with their computed ratings are then fed into a deep reinforcement learning recommender where the sessions are treated as users and the topics are treated as items. Other than evaluating the empirical advantages of the core components on existing datasets, we demonstrate the effectiveness of this system in a web app.
PLD-SLAM: A Real-Time Visual SLAM Using Points and Line Segments in Dynamic Scenes
Jul 22, 2022
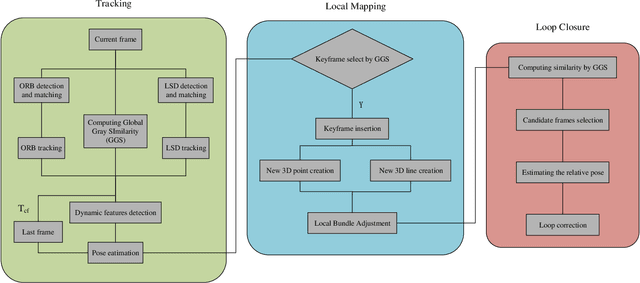
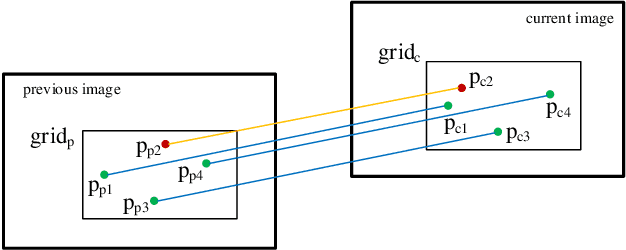

In this paper, we consider the problems in the practical application of visual simultaneous localization and mapping (SLAM). With the popularization and application of the technology in wide scope, the practicability of SLAM system has become a new hot topic after the accuracy and robustness, e.g., how to keep the stability of the system and achieve accurate pose estimation in the low-texture and dynamic environment, and how to improve the universality and real-time performance of the system in the real scenes, etc. This paper proposes a real-time stereo indirect visual SLAM system, PLD-SLAM, which combines point and line features, and avoid the impact of dynamic objects in highly dynamic environments. We also present a novel global gray similarity (GGS) algorithm to achieve reasonable keyframe selection and efficient loop closure detection (LCD). Benefiting from the GGS, PLD-SLAM can realize real-time accurate pose estimation in most real scenes without pre-training and loading a huge feature dictionary model. To verify the performance of the proposed system, we compare it with existing state-of-the-art (SOTA) methods on the public datasets KITTI, EuRoC MAV, and the indoor stereo datasets provided by us, etc. The experiments show that the PLD-SLAM has better real-time performance while ensuring stability and accuracy in most scenarios. In addition, through the analysis of the experimental results of the GGS, we can find it has excellent performance in the keyframe selection and LCD.