 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Locally Optimal Estimation and Control of Cable Driven Parallel Robots using Time Varying Linear Quadratic Gaussian Control
Aug 01, 2022
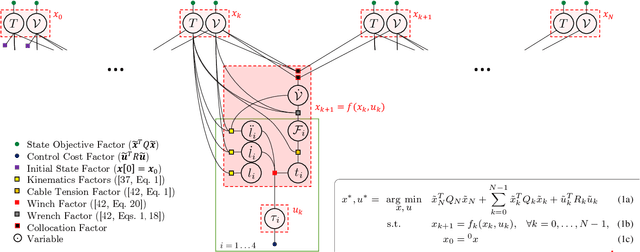
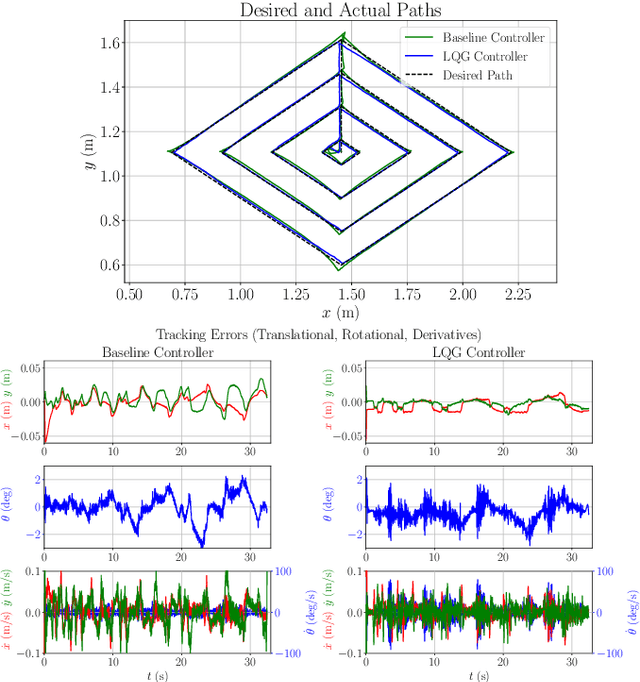
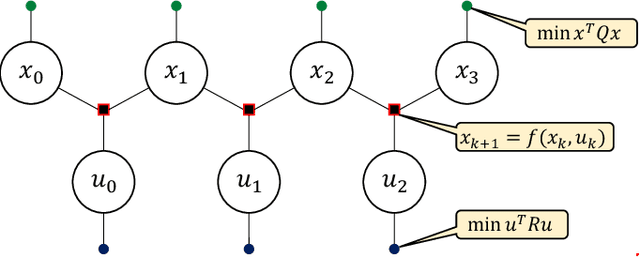
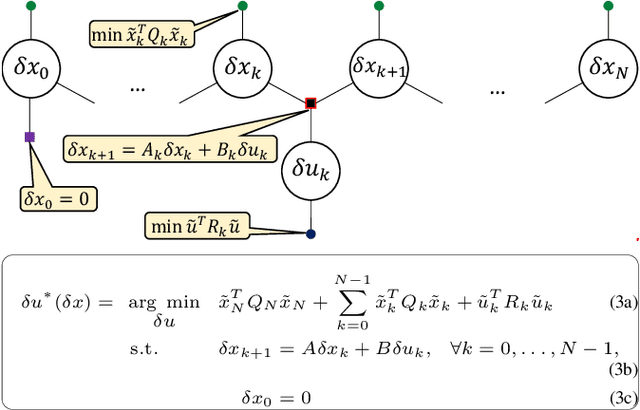
We present a locally optimal tracking controller for Cable Driven Parallel Robot (CDPR) control based on a time-varying Linear Quadratic Gaussian (TV-LQG) controller. In contrast to many methods which use fixed feedback gains, our time-varying controller computes the optimal gains depending on the location in the workspace and the future trajectory. Meanwhile, we rely heavily on offline computation to reduce the burden of online implementation and feasibility checking. Following the growing popularity of probabilistic graphical models for optimal control, we use factor graphs as a tool to formulate our controller for their efficiency, intuitiveness, and modularity. The topology of a factor graph encodes the relevant structural properties of equations in a way that facilitates insight and efficient computation using sparse linear algebra solvers. We first use factor graph optimization to compute a nominal trajectory, then linearize the graph and apply variable elimination to compute the locally optimal, time varying linear feedback gains. Next, we leverage the factor graph formulation to compute the locally optimal, time-varying Kalman Filter gains, and finally combine the locally optimal linear control and estimation laws to form a TV-LQG controller. We compare the tracking accuracy of our TV-LQG controller to a state-of-the-art dual-space feed-forward controller on a 2.9m x 2.3m, 4-cable planar robot and demonstrate improved tracking accuracies of 0.8{\deg} and 11.6mm root mean square error in rotation and translation respectively.
Same or Different? Diff-Vectors for Authorship Analysis
Jan 24, 2023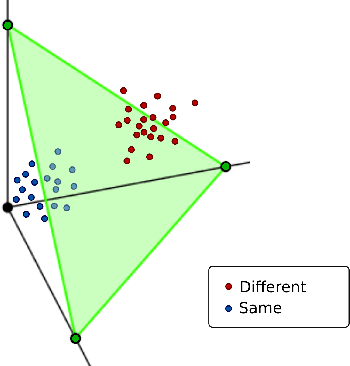
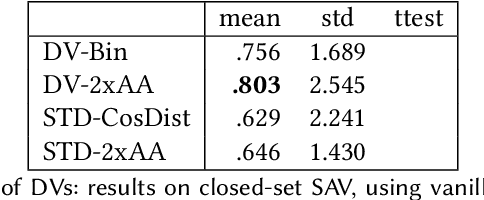
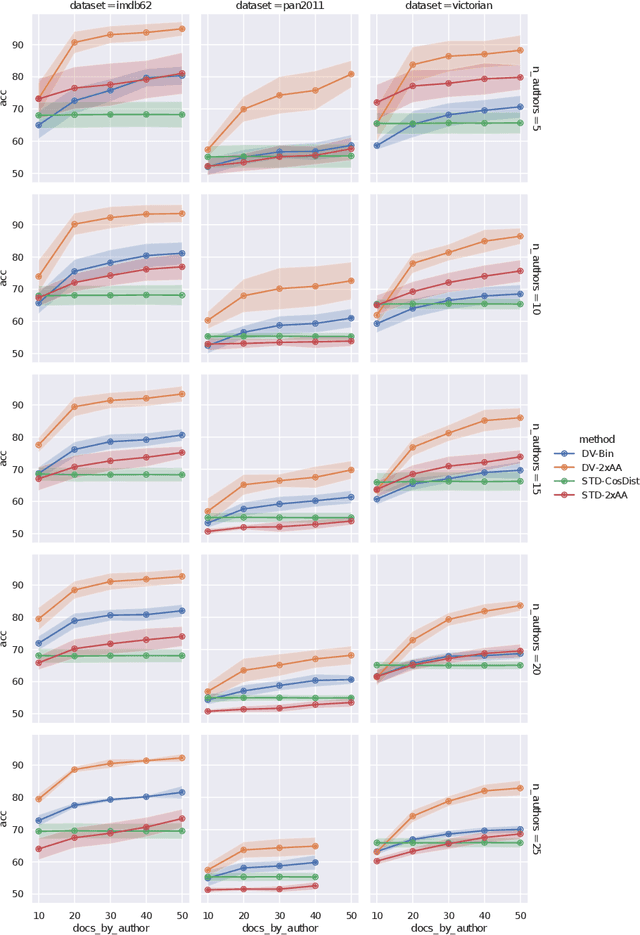
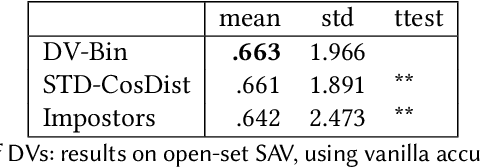
We investigate the effects on authorship identification tasks of a fundamental shift in how to conceive the vectorial representations of documents that are given as input to a supervised learner. In ``classic'' authorship analysis a feature vector represents a document, the value of a feature represents (an increasing function of) the relative frequency of the feature in the document, and the class label represents the author of the document. We instead investigate the situation in which a feature vector represents an unordered pair of documents, the value of a feature represents the absolute difference in the relative frequencies (or increasing functions thereof) of the feature in the two documents, and the class label indicates whether the two documents are from the same author or not. This latter (learner-independent) type of representation has been occasionally used before, but has never been studied systematically. We argue that it is advantageous, and that in some cases (e.g., authorship verification) it provides a much larger quantity of information to the training process than the standard representation. The experiments that we carry out on several publicly available datasets (among which one that we here make available for the first time) show that feature vectors representing pairs of documents (that we here call Diff-Vectors) bring about systematic improvements in the effectiveness of authorship identification tasks, and especially so when training data are scarce (as it is often the case in real-life authorship identification scenarios). Our experiments tackle same-author verification, authorship verification, and closed-set authorship attribution; while DVs are naturally geared for solving the 1st, we also provide two novel methods for solving the 2nd and 3rd that use a solver for the 1st as a building block.
Large-Scale Traffic Signal Control by a Nash Deep Q-network Approach
Jan 02, 2023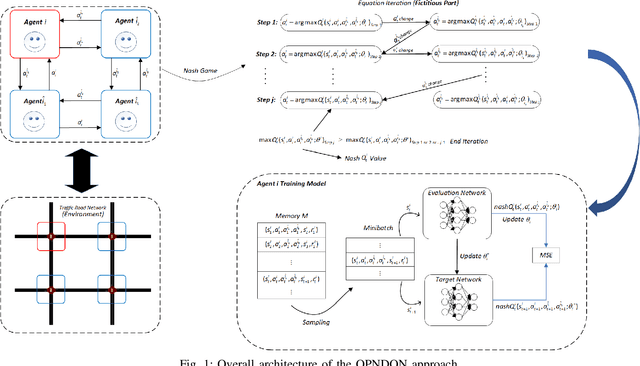
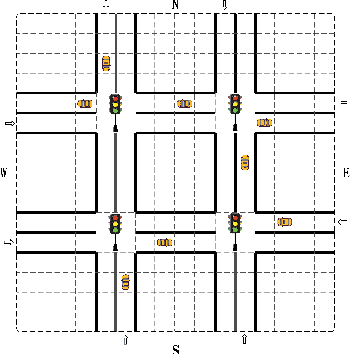
Reinforcement Learning (RL) is currently one of the most commonly used techniques for traffic signal control (TSC), which can adaptively adjusted traffic signal phase and duration according to real-time traffic data. However, a fully centralized RL approach is beset with difficulties in a multi-network scenario because of exponential growth in state-action space with increasing intersections. Multi-agent reinforcement learning (MARL) can overcome the high-dimension problem by employing the global control of each local RL agent, but it also brings new challenges, such as the failure of convergence caused by the non-stationary Markov Decision Process (MDP). In this paper, we introduce an off-policy nash deep Q-Network (OPNDQN) algorithm, which mitigates the weakness of both fully centralized and MARL approaches. The OPNDQN algorithm solves the problem that traditional algorithms cannot be used in large state-action space traffic models by utilizing a fictitious game approach at each iteration to find the nash equilibrium among neighboring intersections, from which no intersection has incentive to unilaterally deviate. One of main advantages of OPNDQN is to mitigate the non-stationarity of multi-agent Markov process because it considers the mutual influence among neighboring intersections by sharing their actions. On the other hand, for training a large traffic network, the convergence rate of OPNDQN is higher than that of existing MARL approaches because it does not incorporate all state information of each agent. We conduct an extensive experiments by using Simulation of Urban MObility simulator (SUMO), and show the dominant superiority of OPNDQN over several existing MARL approaches in terms of average queue length, episode training reward and average waiting time.
Closed-Form Diffeomorphic Transformations for Time Series Alignment
Jun 16, 2022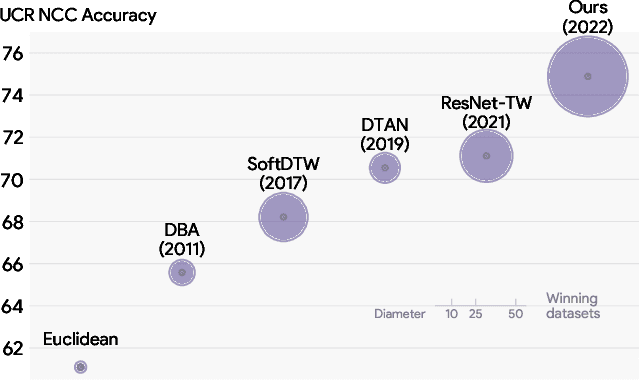
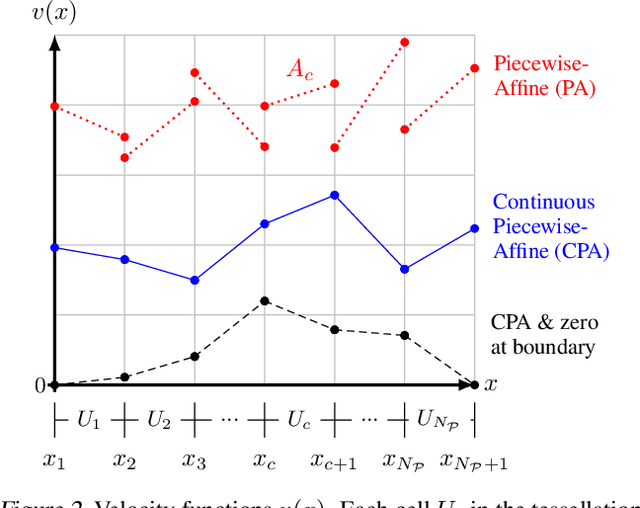
Time series alignment methods call for highly expressive, differentiable and invertible warping functions which preserve temporal topology, i.e diffeomorphisms. Diffeomorphic warping functions can be generated from the integration of velocity fields governed by an ordinary differential equation (ODE). Gradient-based optimization frameworks containing diffeomorphic transformations require to calculate derivatives to the differential equation's solution with respect to the model parameters, i.e. sensitivity analysis. Unfortunately, deep learning frameworks typically lack automatic-differentiation-compatible sensitivity analysis methods; and implicit functions, such as the solution of ODE, require particular care. Current solutions appeal to adjoint sensitivity methods, ad-hoc numerical solvers or ResNet's Eulerian discretization. In this work, we present a closed-form expression for the ODE solution and its gradient under continuous piecewise-affine (CPA) velocity functions. We present a highly optimized implementation of the results on CPU and GPU. Furthermore, we conduct extensive experiments on several datasets to validate the generalization ability of our model to unseen data for time-series joint alignment. Results show significant improvements both in terms of efficiency and accuracy.
Multi-Lingual DALL-E Storytime
Dec 22, 2022
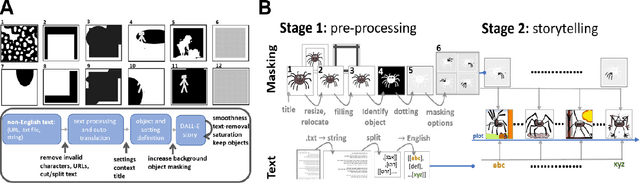
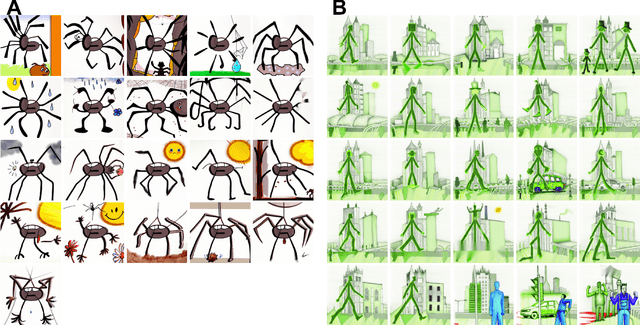

While recent advancements in artificial intelligence (AI) language models demonstrate cutting-edge performance when working with English texts, equivalent models do not exist in other languages or do not reach the same performance level. This undesired effect of AI advancements increases the gap between access to new technology from different populations across the world. This unsought bias mainly discriminates against individuals whose English skills are less developed, e.g., non-English speakers children. Following significant advancements in AI research in recent years, OpenAI has recently presented DALL-E: a powerful tool for creating images based on English text prompts. While DALL-E is a promising tool for many applications, its decreased performance when given input in a different language, limits its audience and deepens the gap between populations. An additional limitation of the current DALL-E model is that it only allows for the creation of a few images in response to a given input prompt, rather than a series of consecutive coherent frames that tell a story or describe a process that changes over time. Here, we present an easy-to-use automatic DALL-E storytelling framework that leverages the existing DALL-E model to enable fast and coherent visualizations of non-English songs and stories, pushing the limit of the one-step-at-a-time option DALL-E currently offers. We show that our framework is able to effectively visualize stories from non-English texts and portray the changes in the plot over time. It is also able to create a narrative and maintain interpretable changes in the description across frames. Additionally, our framework offers users the ability to specify constraints on the story elements, such as a specific location or context, and to maintain a consistent style throughout the visualization.
Temporal Motifs for Financial Networks: A Study on Mercari, JPMC, and Venmo Platforms
Jan 18, 2023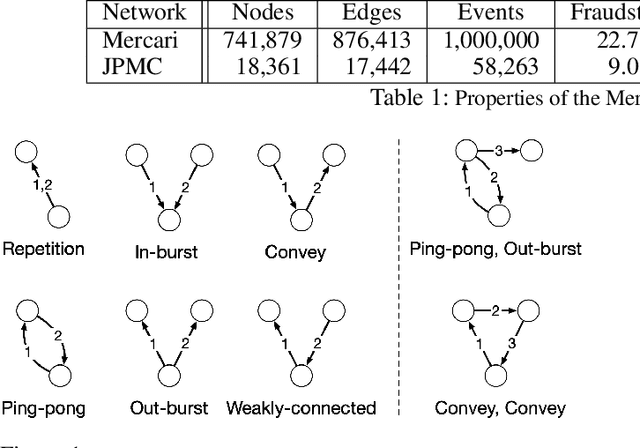
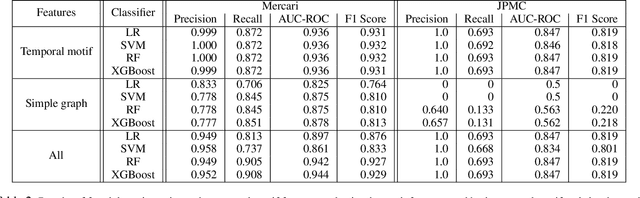
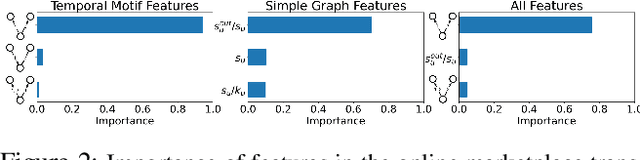
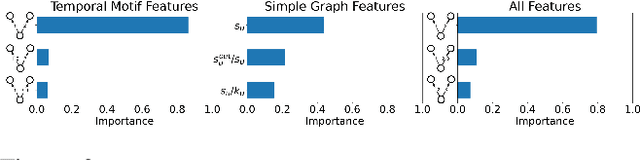
Understanding the dynamics of financial transactions among people is critically important for various applications such as fraud detection. One important aspect of financial transaction networks is temporality. The order and repetition of transactions can offer new insights when considered within the graph structure. Temporal motifs, defined as a set of nodes that interact with each other in a short time period, are a promising tool in this context. In this work, we study three unique temporal financial networks: transactions in Mercari, an online marketplace, payments in a synthetic network generated by J.P. Morgan Chase, and payments and friendships among Venmo users. We consider the fraud detection problem on the Mercari and J.P. Morgan Chase networks, for which the ground truth is available. We show that temporal motifs offer superior performance than a previous method that considers simple graph features. For the Venmo network, we investigate the interplay between financial and social relations on three tasks: friendship prediction, vendor identification, and analysis of temporal cycles. For friendship prediction, temporal motifs yield better results than general heuristics, such as Jaccard and Adamic-Adar measures. We are also able to identify vendors with high accuracy and observe interesting patterns in rare motifs, like temporal cycles. We believe that the analysis, datasets, and lessons from this work will be beneficial for future research on financial transaction networks.
CA$^2$T-Net: Category-Agnostic 3D Articulation Transfer from Single Image
Jan 05, 2023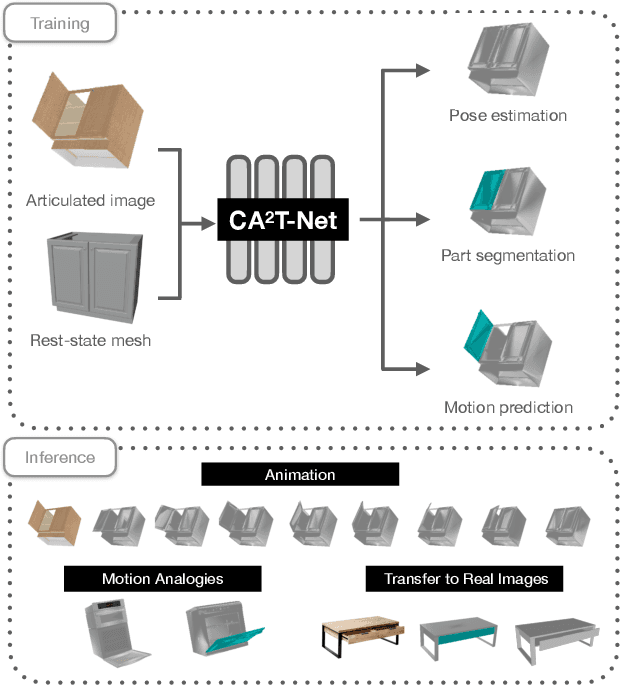
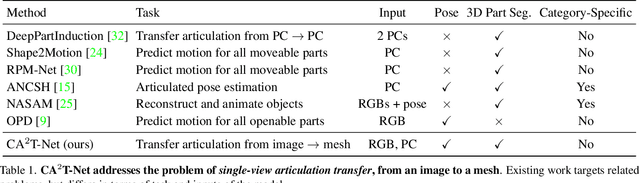
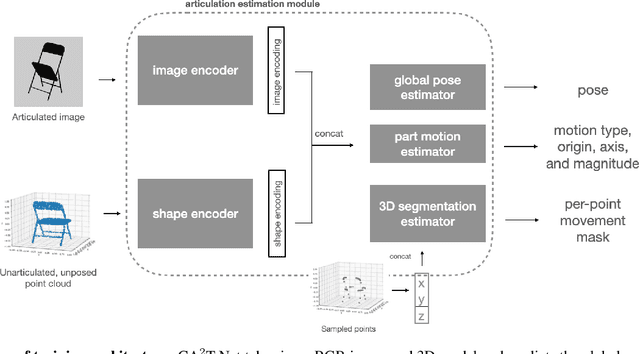
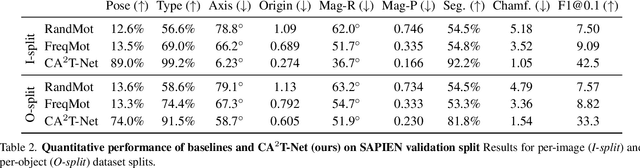
We present a neural network approach to transfer the motion from a single image of an articulated object to a rest-state (i.e., unarticulated) 3D model. Our network learns to predict the object's pose, part segmentation, and corresponding motion parameters to reproduce the articulation shown in the input image. The network is composed of three distinct branches that take a shared joint image-shape embedding and is trained end-to-end. Unlike previous methods, our approach is independent of the topology of the object and can work with objects from arbitrary categories. Our method, trained with only synthetic data, can be used to automatically animate a mesh, infer motion from real images, and transfer articulation to functionally similar but geometrically distinct 3D models at test time.
Towards Long-term Autonomy: A Perspective from Robot Learning
Jan 02, 2023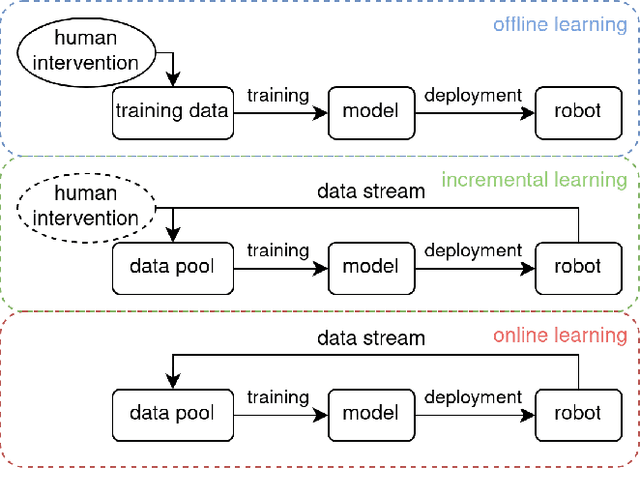
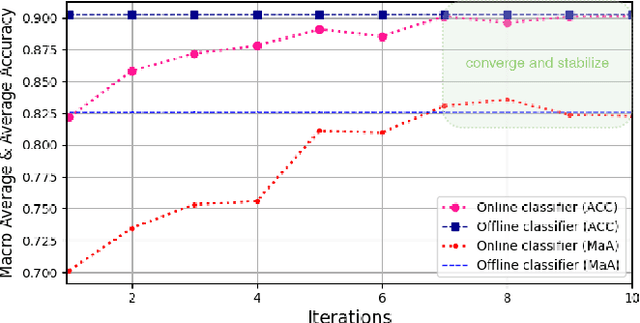
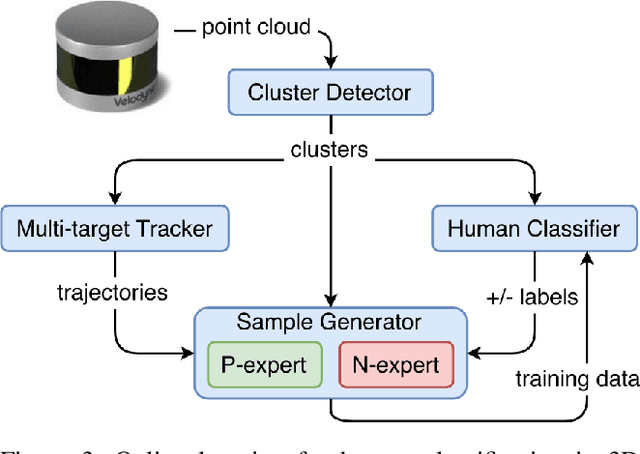
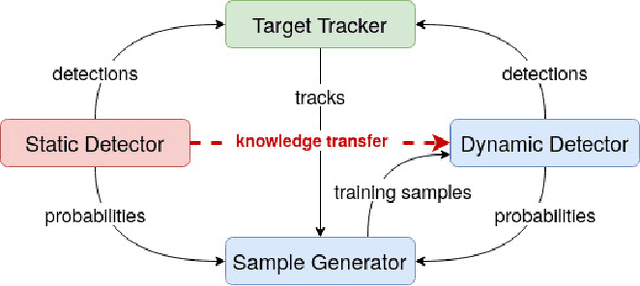
In the future, service robots are expected to be able to operate autonomously for long periods of time without human intervention. Many work striving for this goal have been emerging with the development of robotics, both hardware and software. Today we believe that an important underpinning of long-term robot autonomy is the ability of robots to learn on site and on-the-fly, especially when they are deployed in changing environments or need to traverse different environments. In this paper, we examine the problem of long-term autonomy from the perspective of robot learning, especially in an online way, and discuss in tandem its premise "data" and the subsequent "deployment".
Towards Quantum Annealing for Multi-user NOMA-based Networks
Jan 10, 2023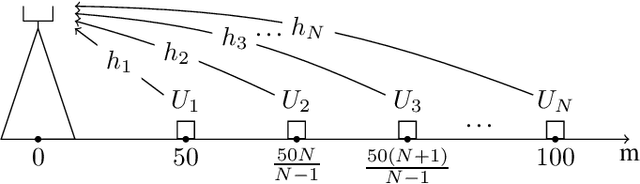
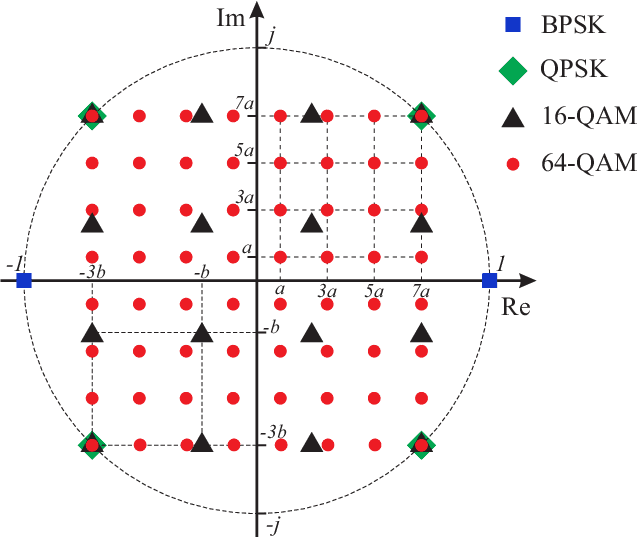
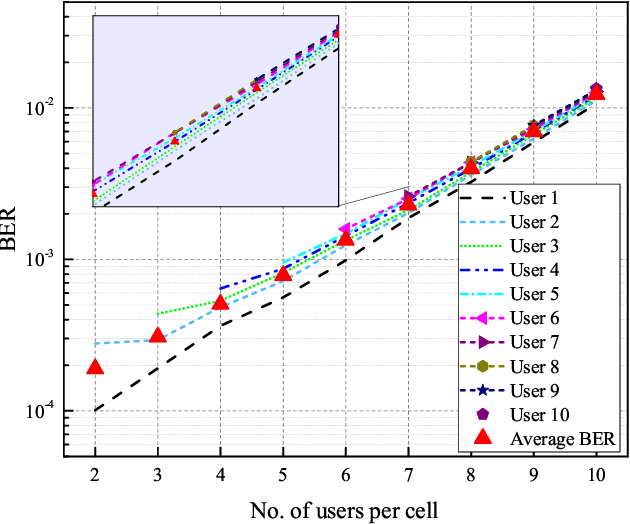
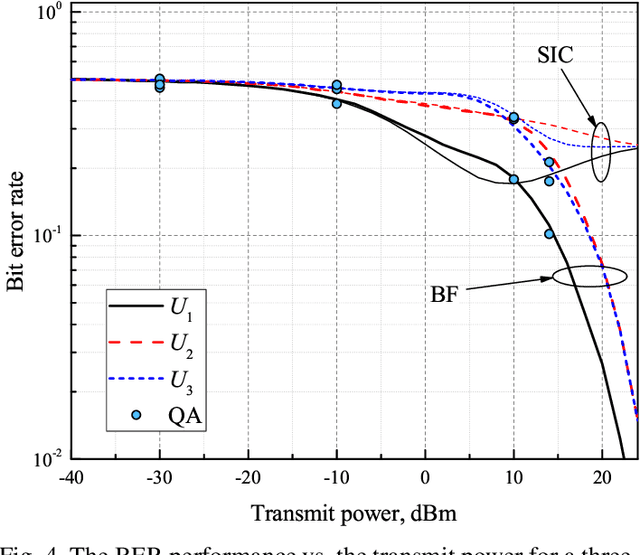
Quantum Annealing (QA) uses quantum fluctuations to search for a global minimum of an optimization-type problem faster than classical computers. To meet the demand for future internet traffic and mitigate the spectrum scarcity, this work presents the QA-aided maximum likelihood (ML) decoder for multi-user non-orthogonal multiple access (NOMA) networks as an alternative to the successive interference cancellation (SIC) method. The practical system parameters such as channel randomness and possible transmit power levels are taken into account for all individual signals of all involved users. The brute force (BF) and SIC signal detection methods are taken as benchmarks in the analysis. The QA-assisted ML decoder results in the same BER performance as the BF method outperforming the SIC technique, but the execution of QA takes more time than BF and SIC. The parallelization technique can be a potential aid to fasten the execution process. This will pave the way to fully realize the potential of QA decoders in NOMA systems.
Streaming Punctuation: A Novel Punctuation Technique Leveraging Bidirectional Context for Continuous Speech Recognition
Jan 10, 2023

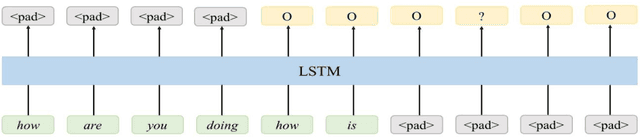

While speech recognition Word Error Rate (WER) has reached human parity for English, continuous speech recognition scenarios such as voice typing and meeting transcriptions still suffer from segmentation and punctuation problems, resulting from irregular pausing patterns or slow speakers. Transformer sequence tagging models are effective at capturing long bi-directional context, which is crucial for automatic punctuation. Automatic Speech Recognition (ASR) production systems, however, are constrained by real-time requirements, making it hard to incorporate the right context when making punctuation decisions. Context within the segments produced by ASR decoders can be helpful but limiting in overall punctuation performance for a continuous speech session. In this paper, we propose a streaming approach for punctuation or re-punctuation of ASR output using dynamic decoding windows and measure its impact on punctuation and segmentation accuracy across scenarios. The new system tackles over-segmentation issues, improving segmentation F0.5-score by 13.9%. Streaming punctuation achieves an average BLEUscore improvement of 0.66 for the downstream task of Machine Translation (MT).
* arXiv admin note: substantial text overlap with arXiv:2210.05756