 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Perception through Equivariance
Dec 12, 2022
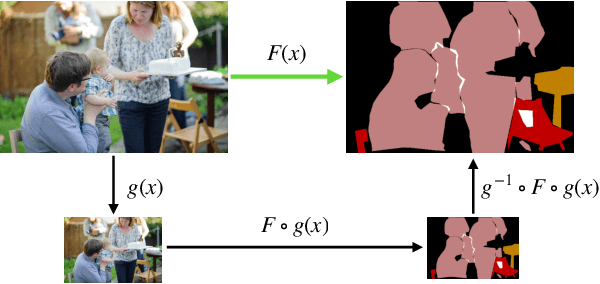
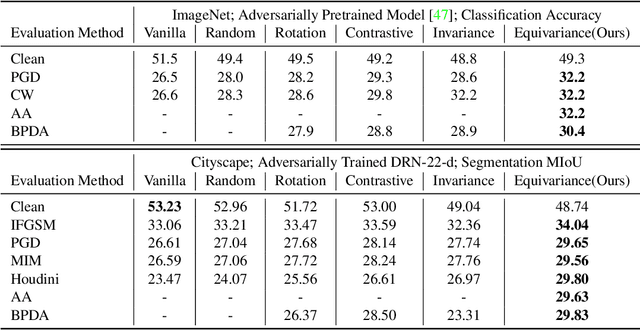

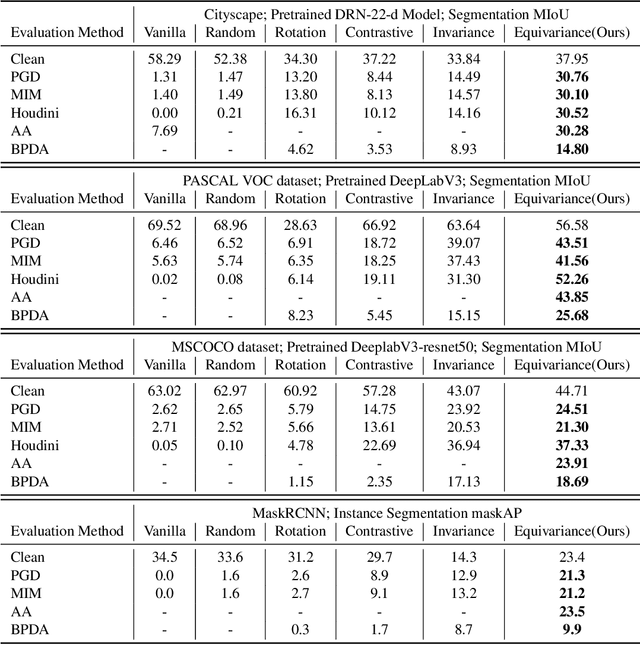
Deep networks for computer vision are not reliable when they encounter adversarial examples. In this paper, we introduce a framework that uses the dense intrinsic constraints in natural images to robustify inference. By introducing constraints at inference time, we can shift the burden of robustness from training to the inference algorithm, thereby allowing the model to adjust dynamically to each individual image's unique and potentially novel characteristics at inference time. Among different constraints, we find that equivariance-based constraints are most effective, because they allow dense constraints in the feature space without overly constraining the representation at a fine-grained level. Our theoretical results validate the importance of having such dense constraints at inference time. Our empirical experiments show that restoring feature equivariance at inference time defends against worst-case adversarial perturbations. The method obtains improved adversarial robustness on four datasets (ImageNet, Cityscapes, PASCAL VOC, and MS-COCO) on image recognition, semantic segmentation, and instance segmentation tasks. Project page is available at equi4robust.cs.columbia.edu.
Asymptotic Inference for Multi-Stage Stationary Treatment Policy with High Dimensional Features
Jan 29, 2023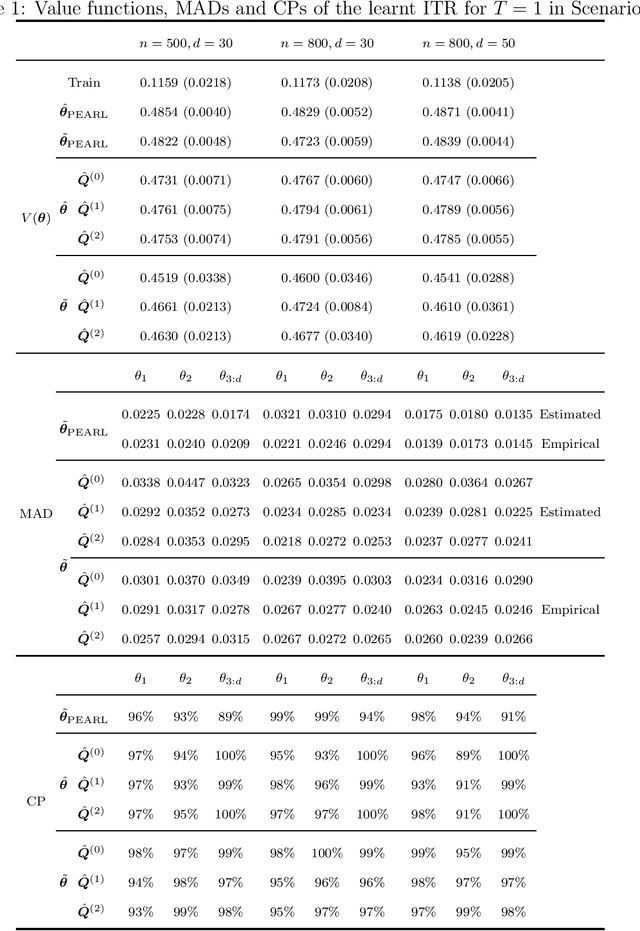
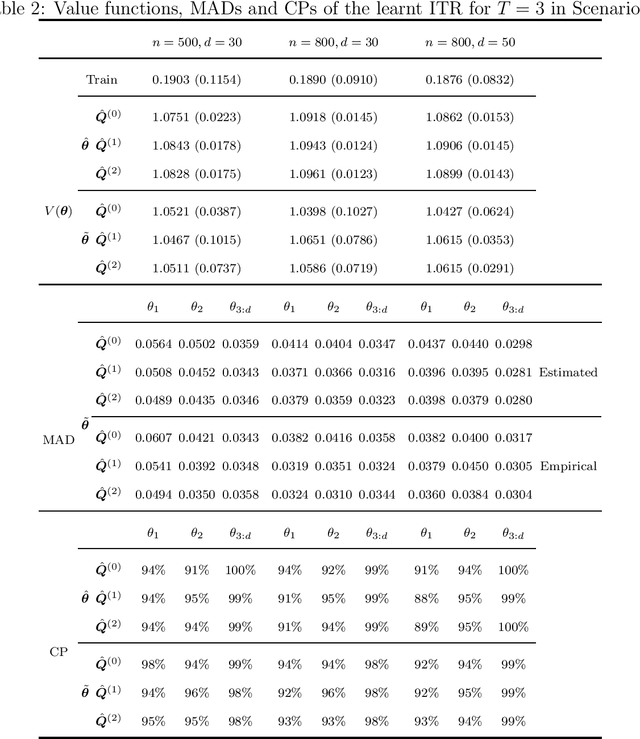
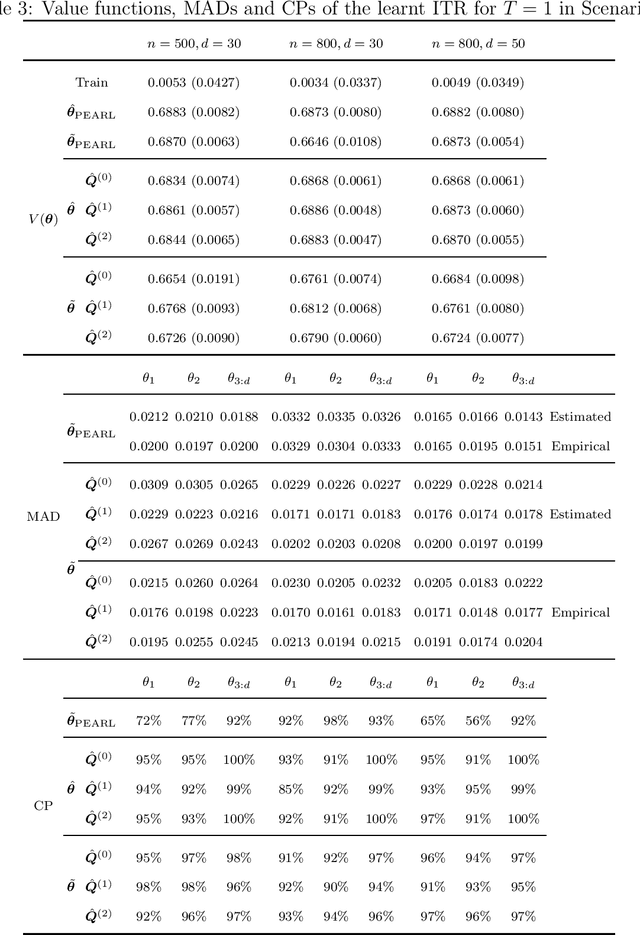
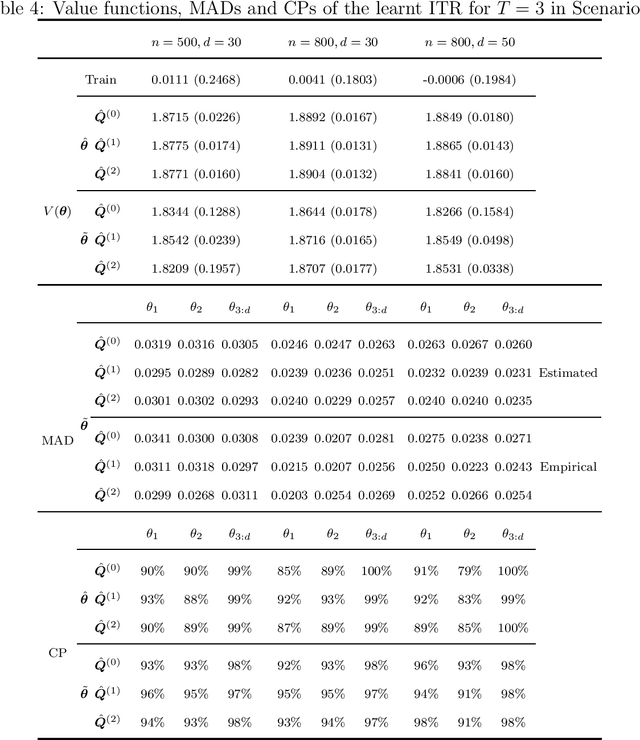
Dynamic treatment rules or policies are a sequence of decision functions over multiple stages that are tailored to individual features. One important class of treatment policies for practice, namely multi-stage stationary treatment policies, prescribe treatment assignment probabilities using the same decision function over stages, where the decision is based on the same set of features consisting of both baseline variables (e.g., demographics) and time-evolving variables (e.g., routinely collected disease biomarkers). Although there has been extensive literature to construct valid inference for the value function associated with the dynamic treatment policies, little work has been done for the policies themselves, especially in the presence of high dimensional feature variables. We aim to fill in the gap in this work. Specifically, we first estimate the multistage stationary treatment policy based on an augmented inverse probability weighted estimator for the value function to increase the asymptotic efficiency, and further apply a penalty to select important feature variables. We then construct one-step improvement of the policy parameter estimators. Theoretically, we show that the improved estimators are asymptotically normal, even if nuisance parameters are estimated at a slow convergence rate and the dimension of the feature variables increases exponentially with the sample size. Our numerical studies demonstrate that the proposed method has satisfactory performance in small samples, and that the performance can be improved with a choice of the augmentation term that approximates the rewards or minimizes the variance of the value function.
6-DoF Robotic Grasping with Transformer
Jan 29, 2023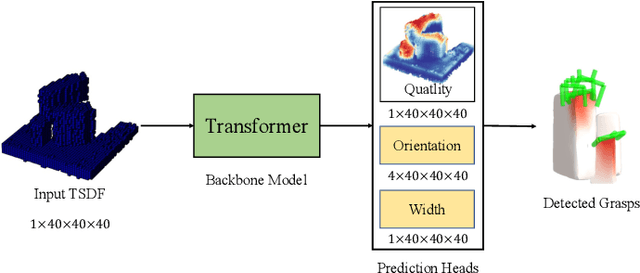
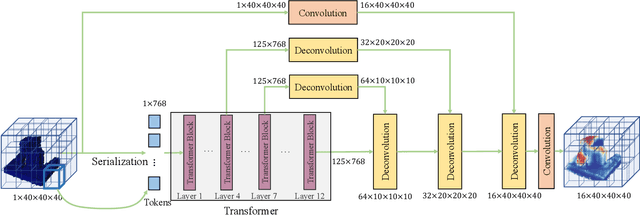
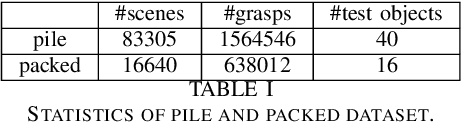
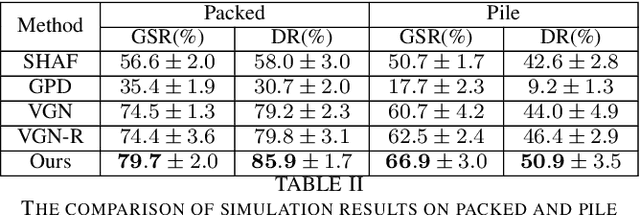
Robotic grasping aims to detect graspable points and their corresponding gripper configurations in a particular scene, and is fundamental for robot manipulation. Existing research works have demonstrated the potential of using a transformer model for robotic grasping, which can efficiently learn both global and local features. However, such methods are still limited in grasp detection on a 2D plane. In this paper, we extend a transformer model for 6-Degree-of-Freedom (6-DoF) robotic grasping, which makes it more flexible and suitable for tasks that concern safety. The key designs of our method are a serialization module that turns a 3D voxelized space into a sequence of feature tokens that a transformer model can consume and skip-connections that merge multiscale features effectively. In particular, our method takes a Truncated Signed Distance Function (TSDF) as input. After serializing the TSDF, a transformer model is utilized to encode the sequence, which can obtain a set of aggregated hidden feature vectors through multi-head attention. We then decode the hidden features to obtain per-voxel feature vectors through deconvolution and skip-connections. Voxel feature vectors are then used to regress parameters for executing grasping actions. On a recently proposed pile and packed grasping dataset, we showcase that our transformer-based method can surpass existing methods by about 5% in terms of success rates and declutter rates. We further evaluate the running time and generalization ability to demonstrate the superiority of the proposed method.
Bug Fix Time Optimization Using Matrix Factorization and Iterative Gale-Shaply Algorithms
Jul 14, 2022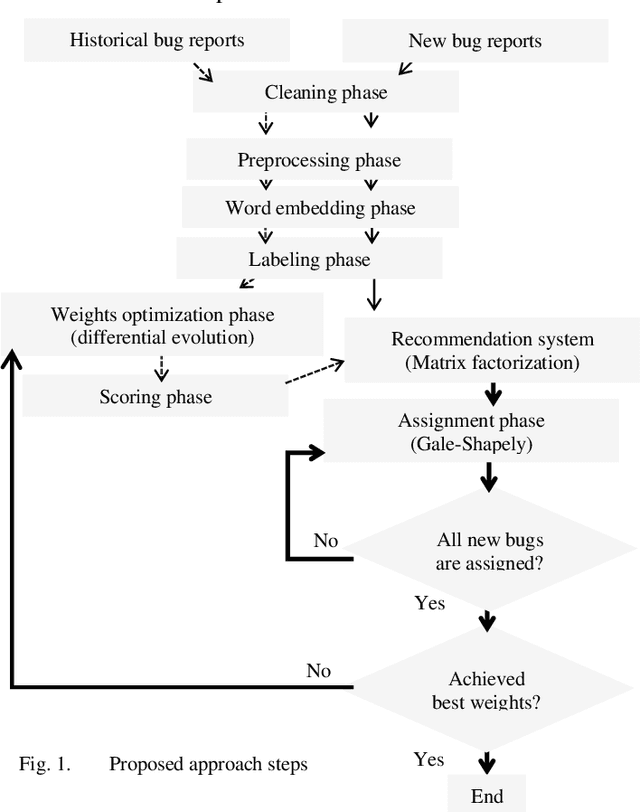
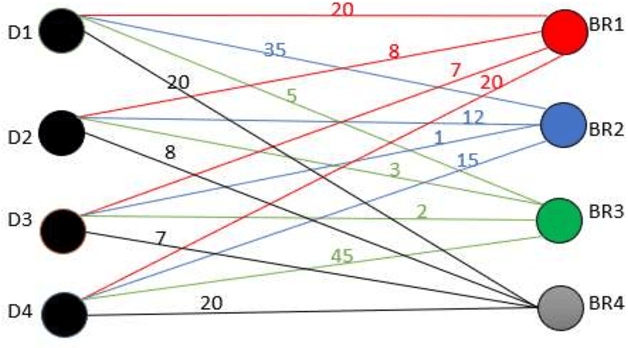
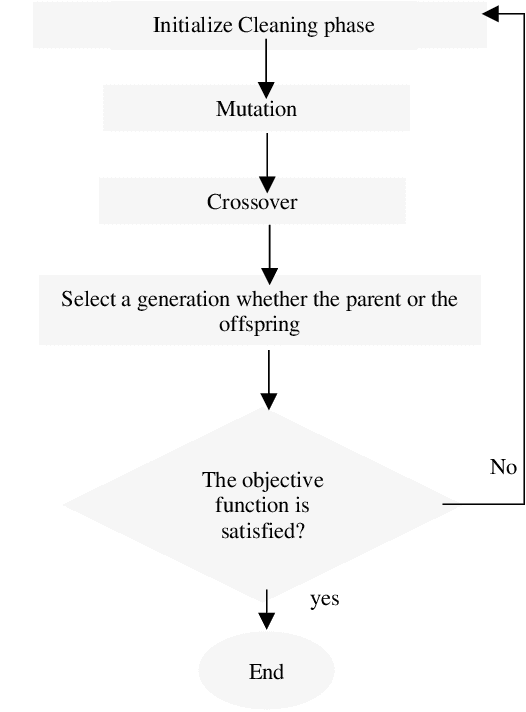
Bug triage is an essential task in software maintenance phase. It assigns developers (fixers) to bug reports to fix them. This process is performed manually by a triager, who analyzes developers profiles and submitted bug reports to make suitable assignments. Bug triaging process is time consuming thus automating this process is essential to improve the quality of software. Previous work addressed triaging problem either as an information retrieval or classification problem. This paper tackles this problem as a resource allocation problem, that aims at the best assignments of developers to bug reports, that reduces the total fixing time of the newly submitted bug reports, in addition to the even distribution of bug reports over developers. In this paper, a combination of matrix factorization and Gale Shapely algorithm, supported by the differential evolution is firstly introduced to optimize the total fix time and normalize developers work load. Matrix factorization is used to establish a recommendation system for Gale-Shapley to make assignment decisions. Differential evolution provides the best set of weights to build developers score profiles. The proposed approach is assessed over three repositories, Linux, Apache and Eclipse. Experimental results show that the proposed approach reduces the bug fixing time, in comparison to the manual triage, by 80.67%, 23.61% and 60.22% over Linux, Eclipse and Apache respectively. Moreover, the workload for the developers is uniform.
Min-Max Optimization Made Simple: Approximating the Proximal Point Method via Contraction Maps
Jan 16, 2023In this paper we present a first-order method that admits near-optimal convergence rates for convex/concave min-max problems while requiring a simple and intuitive analysis. Similarly to the seminal work of Nemirovski and the recent approach of Piliouras et al. in normal form games, our work is based on the fact that the update rule of the Proximal Point method (PP) can be approximated up to accuracy $\epsilon$ with only $O(\log 1/\epsilon)$ additional gradient-calls through the iterations of a contraction map. Then combining the analysis of (PP) method with an error-propagation analysis we establish that the resulting first order method, called Clairvoyant Extra Gradient, admits near-optimal time-average convergence for general domains and last-iterate convergence in the unconstrained case.
Multi-resolution location-based training for multi-channel continuous speech separation
Jan 16, 2023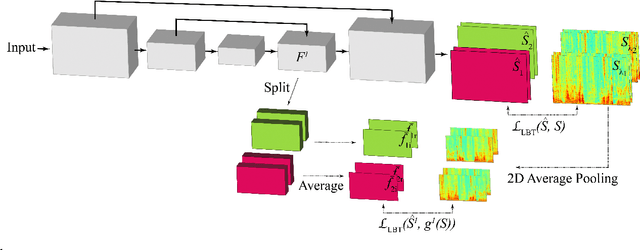
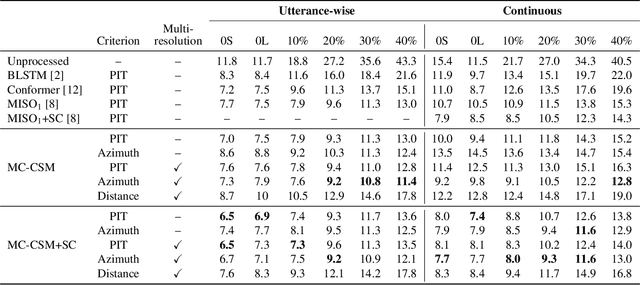
The performance of automatic speech recognition (ASR) systems severely degrades when multi-talker speech overlap occurs. In meeting environments, speech separation is typically performed to improve the robustness of ASR systems. Recently, location-based training (LBT) was proposed as a new training criterion for multi-channel talker-independent speaker separation. Assuming fixed array geometry, LBT outperforms widely-used permutation-invariant training in fully overlapped utterances and matched reverberant conditions. This paper extends LBT to conversational multi-channel speaker separation. We introduce multi-resolution LBT to estimate the complex spectrograms from low to high time and frequency resolutions. With multi-resolution LBT, convolutional kernels are assigned consistently based on speaker locations in physical space. Evaluation results show that multi-resolution LBT consistently outperforms other competitive methods on the recorded LibriCSS corpus.
Min-Path-Tracing: A Diffraction Aware Alternative to Image Method in Ray Tracing
Jan 16, 2023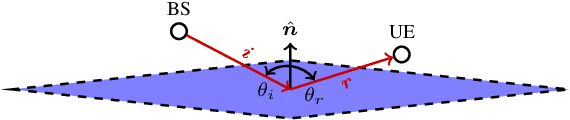
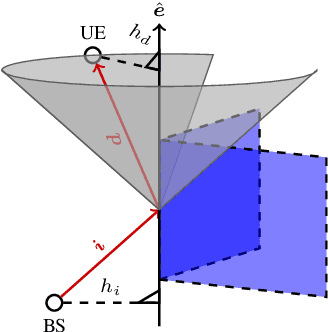
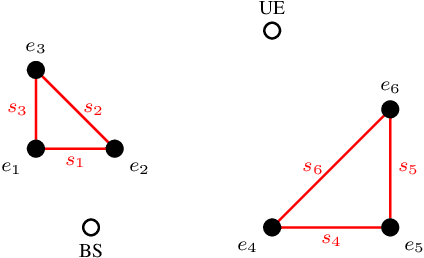
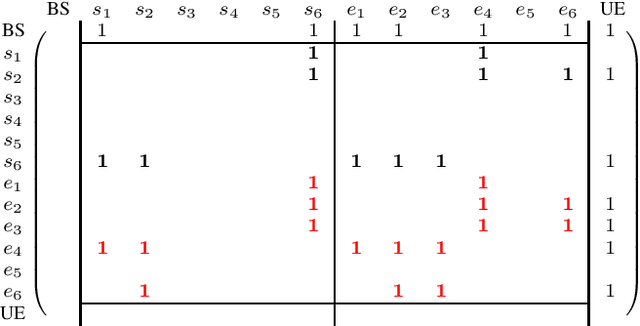
For more than twenty years, Ray Tracing methods have continued to improve on both accuracy and computational time aspects. However, most state-of-the-art image-based ray tracers still rely on a description of the environment that only contains planar surfaces. They are also limited by the number of diffractions they can simulate. We present Min-Path-Tracing (MPT), an alternative to the image method that can handle diffractions seamlessly, while also leveraging the possibility to use different geometries for surfaces or edges, such as parabolic mirrors. MPT uses implicit representations of objects to write the path finding challenge as a minimization problem. We further show that multiple diffractions can be important in some situations, which MPT is capable to simulate without increasing neither the computational nor the implementation complexity.
A review of Implementation and Challenges of Unmanned Aerial Vehicles for Spraying Applications and Crop Monitoring in Indonesia
Jan 01, 2023
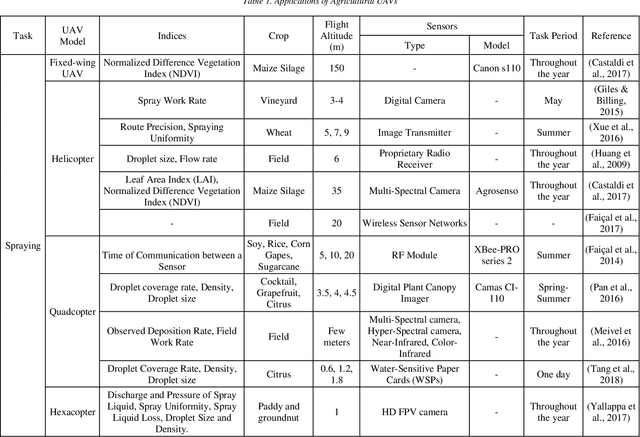
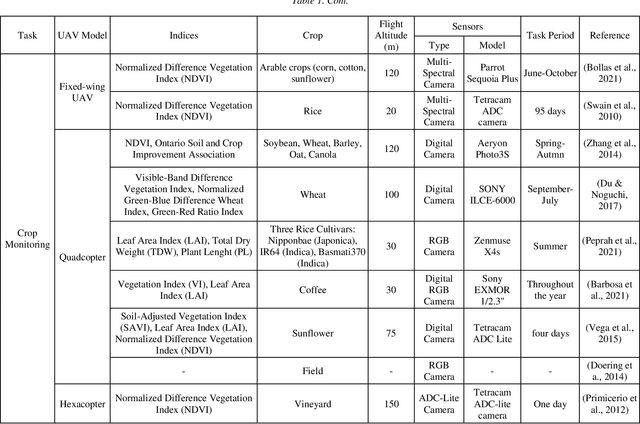
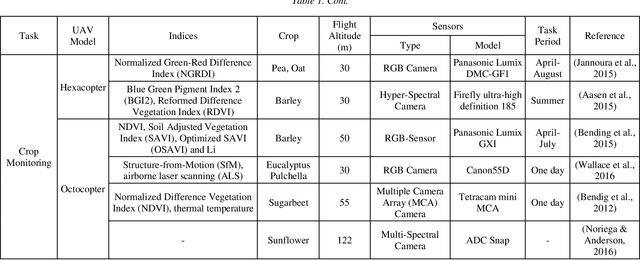
The rapid development of technology has brought unmanned aerial vehicles (UAVs) to become widely known in the current era. The market of UAVs is also predicted to continue growing with related technologies in the future. UAVs have been used in various sectors, including livestock, forestry, and agriculture. In agricultural applications, UAVs are highly capable of increasing the productivity of the farm and reducing farmers' workload. This paper discusses the application of UAVs in agriculture, particularly in spraying and crop monitoring. This study examines the urgency of UAV implementation in the agriculture sector. A short history of UAVs is provided in this paper to portray the development of UAVs from time to time. The classification of UAVs is also discussed to differentiate various types of UAVs. The application of UAVs in spraying and crop monitoring is based on the previous studies that have been done by many scientific groups and researchers who are working closely to propose solutions for agriculture-related issues. Furthermore, the limitations of UAV applications are also identified. The challenges in implementing agricultural UAVs in Indonesia are also presented.
Proof-of-concept Study of Sparse Processing Particle Image Velocimetry for Real Time Flow Observation
Jul 14, 2022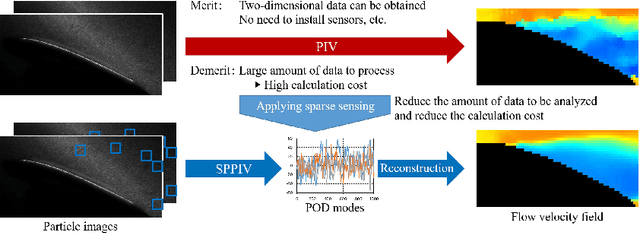

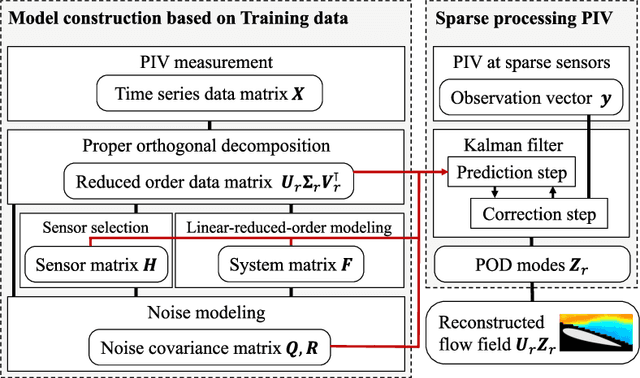

In this paper, we overview, evaluate, and demonstrate the sparse processing particle image velocimetry (SPPIV) as a real-time flow field estimation method using the particle image velocimetry (PIV), whereas SPPIV was previously proposed with its feasibility study and its real-time demonstration is conducted for the first time in this study. In the wind tunnel test, the PIV measurement and real-time measurement using SPPIV were conducted for the flow velocity field around the NACA0015 airfoil model. The off-line analysis results of the test show that the flow velocity field can be estimated from a small number of processing points by applying SPPIV, and also illustrates the following characteristics of SPPIV. The estimation accuracy improves as the number of processing points increases, whereas the processing time per step increases in proportion to the number of processing points. Therefore, it is necessary to set an optimal number of processing points. In addition, the application of the Kalman filter significantly improves the estimation accuracy with a small number of processing points while suppressing the processing time. When the flow velocity fields with different angles of attack are used as the training data with that of test data, the estimation using SPPIV is found to be reasonable if the difference in angle of attack between the training and test data is equal to or less than 2 deg and the flow phenomena of the training data are similar to that of the test data. For this reason, training data should be prepared at least every 4 deg. Finally, the demonstration of SPPIV as a real-time flow observation was conducted for the first time. In this demonstration, the real-time measurement is found to be possible at a sampling rate of 2000 Hz at 20 or less processing points in the top 10 modes estimation as expected by the off-line analyses.
QuickNets: Saving Training and Preventing Overconfidence in Early-Exit Neural Architectures
Dec 25, 2022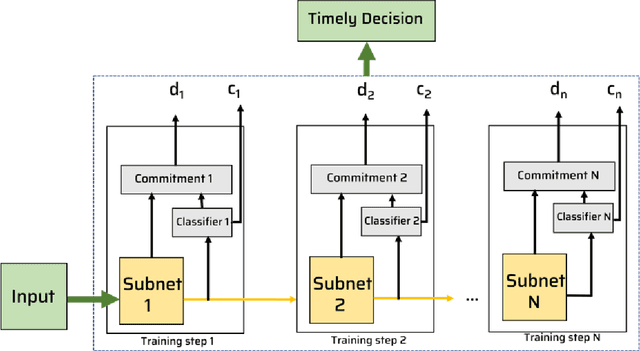
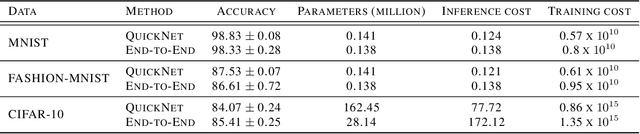
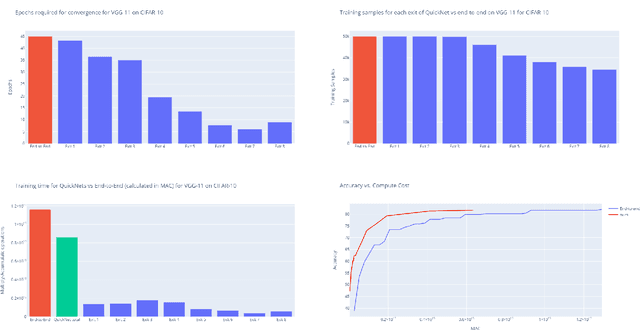

Deep neural networks have long training and processing times. Early exits added to neural networks allow the network to make early predictions using intermediate activations in the network in time-sensitive applications. However, early exits increase the training time of the neural networks. We introduce QuickNets: a novel cascaded training algorithm for faster training of neural networks. QuickNets are trained in a layer-wise manner such that each successive layer is only trained on samples that could not be correctly classified by the previous layers. We demonstrate that QuickNets can dynamically distribute learning and have a reduced training cost and inference cost compared to standard Backpropagation. Additionally, we introduce commitment layers that significantly improve the early exits by identifying for over-confident predictions and demonstrate its success.